Python爬虫实战-详细讲解爬取安居客房价数据
最近在尝试用python爬取安居客房价数据,在这里给需要的小伙伴们提供代码,并且给出一点小心得。
首先是爬取之前应该尽可能伪装成浏览器而不被识别出来是爬虫,基本的是加请求头,但是这样的纯文本数据爬取的人会很多,所以我们需要考虑更换代理IP和随机更换请求头的方式来对房价数据进行爬取。(下面没有给出这两种方式的代码,如果有需要可以看我别的博客,将代码加入到其中)
其次是爬取规则的选择,理想的房价数据应该是这样的,结构化的。
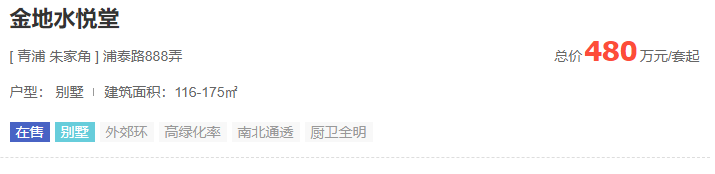
但是实际上遇到的会是下面的情况,户型和房价数据会缺失,所以这就导致了爬取规则的不确定性,用xpath对于格式一致的数据爬取会比较简单,但是这样结构不一致的数据爬取出来就比较困难,所以这里我采用的是正则表达式来进行爬取,因为正则表达式可以对每个块进行处理,什么意思呢?也就是将爬取范围缩小到每一块的范围,从而对每一块的数据进行精确处理,而不是处理所有块的数据,在这里就是对每一个小区的数据进行单独的处理。
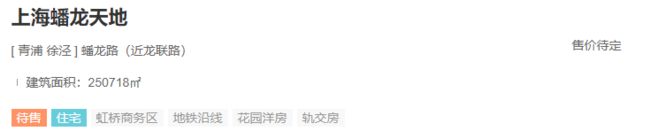

正则表达式提取房价:
1.Note:因为小区,地址数据是结构化的,不需要单独进行处理,所以下面的特殊处理针对的是面积、价格和户型。
2.缩小范围(大致定位):将面积、价格、户型分别缩小到一小块源代码中,具体代码如下:
huxing_mianji_prices = re.findall('',res.text,re.S)
我们打印出来这个列表的长度是60,也就是用这一行代码可以将每一页的60个小区都包含进来,所以这一步完成了将户型、面积、价格确定在一小块源代码中了。
3.具体定位:之后我们要操作的是对这里面的数据进行具体定位,对这六十个元素根据索引进行遍历,如果某一个小区的户型缺失了,那么,就用无户型这个字符串来填充,同理面积和价格也一样,具体的代码可以见下面的details()函数。
4.清洗数据:接下来就是清洗数据了,具体定位之后可能会有数据包含了标签,最常见的就是span标签了,这个时候需要用replace()函数来进行替换了,注意replace()前面的引号是旧字符串,后面的引号是新字符串,不要弄混淆了。具体的代码可以见下面的select_datas()函数。
5.写入表格:写入表格操作采用的是xlwt库,这里的写法逻辑是先创建空表,再创建表头,最后写入数据。具体的代码可以见下面的write_to_excel()函数。
import random
import re
import requests
import xlwt
from user_agent import get_user_agent
book = xlwt.Workbook(encoding='utf-8') #0.创建一个工作簿
sheet = book.add_sheet("安居客",cell_overwrite_ok=True) ## 1.创建空表
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'),
'Accept-Encoding': 'gzip, deflate',
'referer': 'https://shanghai.anjuke.com/',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2', }
##请求网站信息
def req():
response = requests.get('https://sh.fang.anjuke.com/',headers=headers) ##加请求头,如果需要加随机请求头和代理ip的可以看我的别的博客
return response
#解析网站
def crawl():
res = req()
names = re.findall('(.*?)',res.text,re.S)
places = re.findall('\[ (.*?) (.*?) \] (.*?)',res.text,re.S)
huxing_mianji_prices = re.findall('',res.text,re.S)
return names,places,huxing_mianji_prices
##具体定位户型等详细信息
def details():
names,places,huxing_mianji_prices = crawl()
huxing_list = []
mianji_list = []
prices_list = []
for content in huxing_mianji_prices: ##对每一块进行操作,方便对后续缺失、非结构化数据进行处理。
strings = '户型:'
strings1 = '建筑面积:'
if strings in content: #在小范围内查找
huxing = re.findall('户型:.*?(.*?) ',content,re.S)[0]
else:
huxing = "无户型"
huxing_list.append(huxing)
if strings1 in content: #在每一块里寻找面积
mianji= re.findall('建筑面积:(.*?)',content,re.S)[0]
else:
mianji = "无面积"
mianji_list.append(mianji)
price = re.findall(',
content, re.S)[0]
prices_list.append(price)
return names,places,huxing_list,mianji_list,prices_list #返回户型,面积,价格
#清洗数据,因为是用正则表达式提取的,所以要将无关的符号去掉
def select_datas():
names,places,huxing_list,mianji_list,prices_list = details()
final_huxing = []
final_mianji = mianji_list
final_prices = []
# print(prices_list)
for i in range(len(huxing_list)):
if "span" in huxing_list[i]:
huxing_list[i]=huxing_list[i].replace('','、').replace('/','')
else:
pass
final_huxing.append(huxing_list[i])
if '-txt">' in prices_list[i]:
prices_list[i] = prices_list[i].replace('-txt">','')
if 'span' in prices_list[i]:
prices_list[i] = prices_list[i].replace('',':').replace('','')
if '">' in prices_list[i]:
prices_list[i] = prices_list[i].replace('">','')
final_prices.append(prices_list[i])
return names,places,huxing_list,mianji_list,prices_list
#写入表格
def write_to_excel():
names,places,huxing_list,mianji_list,prices_list=select_datas() ##调用处理之后的数据
sheet.write(0, 0, '小区名') ##2. 创建表头
sheet.write(0, 1, '地址')
sheet.write(0, 2, '户型')
sheet.write(0, 3, '面积')
sheet.write(0, 4, '价格')
for i in range(len(names)):
name = names[i]
place = places[i]
huxing = huxing_list[i]
mianji = mianji_list[i]
price = prices_list[i]
sheet.write(i+1 ,0 , name) ##3.写入数据
sheet.write(i + 1, 1, place)
sheet.write(i + 1, 2, huxing)
sheet.write(i + 1, 3, mianji)
sheet.write(i + 1, 4, price)
book.save('上海安居客房价数据' + '.xls')
def main():
write_to_excel()
if __name__ == "__main__":
main()
总结:
1.在爬取数据之前要多思考。思考之后那基本动手写代码就是体力活了。
2.尽量和浏览器访问网站一致,防止被对方服务器给检测到。另外在选择代理之后尽量选择高匿代理,否则你使用了代理之后对于安居客这种网站还是会被检测到本机ip的。
3.多使用函数,在每一段代码编写时候输出看一下,防止在后面会出现大问题,又得从前面开始检查。