开源主流分布式文件系统简单介绍
文章目录
- 一、分布式文件系统简介
-
- 1.特点
- 2.主要指标及分类对比
- 3.AFS与NFS
- 二、开源分布式文件系统
-
- 1.GFS
-
- (1)GFS与NFS,AFS的区别
- (2)BigTable
- (3)Chubby
- (4)特点1
- 2.HDFS
-
- (1)HDFS与Ceph对比
- (2)特点1
- (3)特点2
- 3. Ceph
-
- (1)Ceph特点1
- (2)Ceph特点2
- (3)特点3
- 4. Lustre
-
- (1)特点1
- (2)特点2
- 5.MogileFS
-
- (1)特点1
- (2)特点2
- (3)特点3
- 6.mooseFS
-
- (1)mooseFS简介
- 7.FastDFS
-
- (1)特点1
- (2)特点2
- (3)特点3
- 8.TFS
-
- (1)特点1
- (2)特点2
- 9.GridFS文件系统
- 10.NFS
-
- (1)多服务器存储
- (2)pNFS
- (3)AFS
- 11.PFS(parallel file system)
- 12.OpenStack Swift
-
- (1)OpenStack Swift 和Ceph对比
- 13.GlusterFS
-
- (1)特点简介1
- (1)特点简介2
- 三、参考:
一、分布式文件系统简介
1.特点
-
数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 。
-
是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。
-
通透性。 让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。
-
容错。 即使系统中有某些节点脱机,整体来说系统仍然可以持续运作而不会有数据损失。
-
GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS等。各自适用于不同的领域。它们都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务。
-
可以组建包含大量廉价服务器的海量存储系统。
-
通过内部的冗余复制,保证文件的可以用性,在海量存储系统中,容错能力非常重要
-
可扩展性强,增加存储节点和追踪器都比较容易
-
在对个文件副本之间就进行负载均衡,可以通过横向扩展来确保性能的提升
-
进行特定的索引文件计算
普通存储方案:Rsync、DAS(IDE/SATA/SAS/SCSI等块)、NAS(NFS、CIFS、SAMBA等文件系统)、SAN(FibreChannel, iSCSI, FoE存储网络块),Openfiler、FreeNas(ZFS快照复制)由于生产环境中往往由于对存储数据量很大,而SAN存储价格又比较昂贵,因此大多会选择分布式
存储来解决以下问题
- 海量数据存储问题
- 数据高可用问题(冗余备份)问题
- 较高的读写性能和负载均衡问题
- 支持多平台多语言问题
- 高并发问题
数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 。
是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。
通透性。让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。
容错。即使系统中有某些节点脱机,整体来说系统仍然可以持续运作而不会有数据损失。
分布式文件管理系统很多,hdfs只是其中一种。适用于一次写入多次查询的情况,不支持并发写情况,小文件不合适。
为什么小文件不适合呢?瓶颈在于存储元数据信息。元数据信息存放在namenode上,为保证数据安全和快速读写,namenode把信息放到磁盘一份和内存一份。
业界对于分布式文件系统应用,大致有以下场景
- 大文件冷数据,比如片库
- 并行读写,高though put,比如HPC 和视频在线编辑
- 海量write once read many 的小文件
- mapreduce 或者ml /dl 任务的输入和输出
对于开源的分布式文件系统,多说几句
1.GlusterFS 文件系统标准的posix接口支持,可以做分布式的软件NAS,效果莫的HPC共享存储,k8s/openstack共享存储;主要特点如下
- 实现了一个stack式可插拔的plugin模式,将文件系统的各种feature做成了不同的插件,比如stripe,replicate,hashErasureCode,consistent-hash等。胖客户端的设计导致了client的cpu利用率会比较高,虽然用c语言实现了协程做以应对网络io的高并发。
- 成熟的3.x版本,服务器端没有强一致性的元数据设计,最新的4.x版本变化很大,主要是解决强者一性、集群扩展性瓶颈等问题
- 扩容麻烦,副本rebalance效果不好,坑比较大
- 国内有中科院高能所的刘爱贵博士出来做这方面的创业,提供商业化支持
2.cephfs,其底层是一个对象存储系统,即ceph的rados对象存储,主要特点如下
- rados的crush算法比较有特点,是一种伪随机算法,既考虑了硬件的物理拓扑,也考虑了单点失败后,数据修复或者复制过程中,最小化data migrate。相对于一致性hash等副本allocation算法,在大规模的场景下,效果比较要好;
- rados的基础上,ceph支持块存储ceph RBD,对象ceph RGW,文件系统cephfs;ceph RBD和ceph RGW比较成熟,ceph最初是跟着openstack一起火起来。ceph也可以作为openstack/k8s社区有用来共享存储,不过RBD只支持ReadWrite once,不支持多个共享写;
- 回到cephfs上。cephfs设计的比较理想化,对目录树做了动态分区,每个分区是主备高可用,metadata server只是内存cache,持久化在rados中。cephfs的特性过于复杂,bug比较多。后期社区修改了bug,但是稳定性方面有待加强。目前只有单目录树的主备方式是可用的,三节点多活问题很多。社区方面,国内也一些创业公司和传统厂家在做ceph相关的产品,比如北京的xsky吧。
- 目前ceph社区的关注点主要是本地存储引擎bluestore,以及用户态的block io stack(intel的spdk)。据说国内主流云数据库解决方案也是在ceph rbd基础上做的分布式存储引擎。
3.Lustre,比较老牌的分布式文件系统,部署在多个san阵列上,不支持副本,支持分布式锁,主要做HPC高性能计算;luster对posix的语义应该支持的比较好。之前intel在维护社区,主要目的是为了卖自己的cpu给一些HPC用户,后来intel是退出了。
4.HDFS只支持追加写,设计中没有考虑修改写、截断写、稀疏写等复杂的posix语义,目的并不是通用的文件系统,一般作为hadoop ecosystem的存储引擎;HDFS在bigdata领域使用很广泛,但其实big data用s3也是可以的。
5.moosefs 比较接近GoogleFS的c++实现,通过fuse支持了标准的posix,算是通用的文件系统,社区不是太活跃;
7.还有一些专有的文件系统,比如早年的fastDFS,tfs,BeeFS。大致思想跟facebook Haystack比较像,一个专有的图片存储系统的原型,适合小文件和worm场景(write once read many)。一般大型网站,搞视频流媒体之类,都会有一套类似的解决方案。
8. 京东开源了一个ContainerFS,主要是给k8s用。
2.主要指标及分类对比



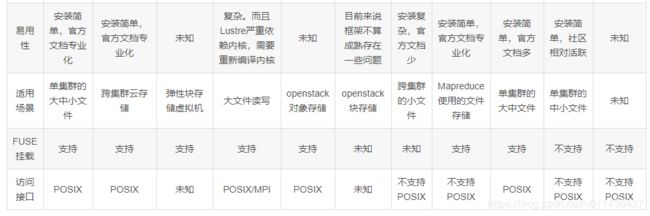

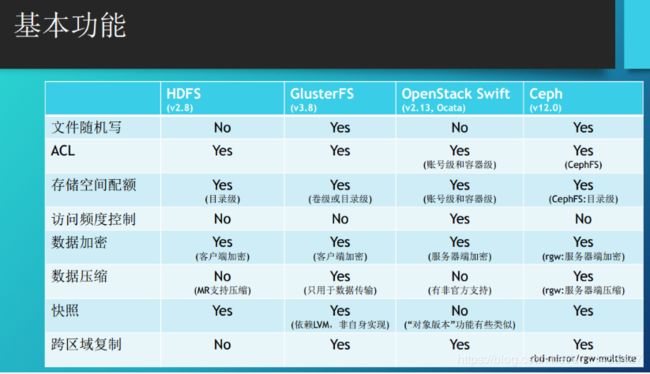

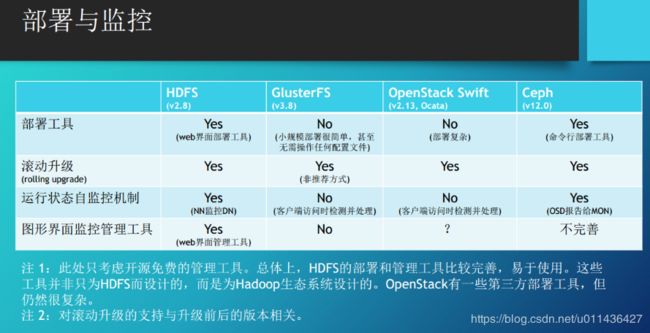




3.AFS与NFS
网络文件系统
早期的unix和nethud也是一种网络操作系统,网络操作系统和网络文件系统是一种包含关系。
(NFS) 最早由Sun微系统公司作为TCP/IP网上的文件共享系统开发。Sun公司估计现在大约有超过310万个系统在运行NFS,大到大型计算机、小至PC机,其中至少有80%的系统是非Sun平台。
Andrew文件系统
(AFS) 结构与NFS相似,由卡内基·梅隆大学信息技术中心(ITC)开发、现由前ITC职员组成的Transarc公司负责开发和销售。AFS较NFS有所增强。
分布式文件系统
(DFS) 是AFS的一个版本,作为开放软件基金会(OSF)的分布式计算环境(DCE)中的文件系统部分。
如果文件的访问仅限于一个用户,那么分布式文件系统就很容易实现。可惜的是,在许多网络环境中这种限制是不现实的,必须采取并发控制来实现文件的多用户访问,表现为如下几个形式:
只读共享 任何客户机只能访问文件,而不能修改它,这实现起来很简单。
受控写操作 采用这种方法,可有多个用户打开一个文件,但只有一个用户进行写修改。而该用户所作的修改并不一定出现在其它已打开此文件的用户的屏幕上。
并发写操作 这种方法允许多个用户同时读写一个文件。但这需要操作系统作大量的监控工作以防止文件重写,并保证用户能够看到最新信息。这种方法即使实现得很好,许多环境中的处理要求和网络通信量也可能使它变得不可接受。
NFS和AFS的区别在于对并发写操作的处理方法上。当一个客户机向服务器请求一个文件(或数据库记录),文件被放在客户工作站的高速缓存中,若另一个用户也请求同一文件,则它也会被放入那个客户工作站的高速缓存中。当两个客户都对文件进行修改时,从技术上而言就存在着该文件的三个版本(每个客户机一个,再加上服务器上的一个)。有两种方法可以在这些版本之间保持同步:
无状态系统 在这个系统中,服务器并不保存其客户机正在缓存的文件的信息。因此,客户机必须协同服务器定期检查是否有其他客户改变了自己正在缓存的文件。这种方法在大的环境中会产生额外的LAN通信开销,但对小型LAN来说,这是一种令人满意的方法。NFS就是个无状态系统。
回呼(Callback)系统 在这种方法中,服务器记录它的那些客户机的所作所为,并保留它们正在缓存的文件信息。服务器在一个客户机改变了一个文件时使用一种叫回叫应答(callbackpromise)的技术通知其它客户机。这种方法减少了大量网络通信。AFS(及OSFDCE的DFS)就是回叫系统。客户机改变文件时,持有这些文件拷贝的其它客户机就被回叫并通知这些改变。
无状态操作在运行性能上有其长处,但AFS通过保证不会被回叫应答充斥也达到了这一点。方法是在一定时间后取消回叫。客户机检查回叫应答中的时间期限以保证回叫应答是当前有效的。回叫应答的另一个有趣的特征是向用户保证了文件的当前有效性。换句话说,若一个被缓存的文件有一个回叫应答,则客户机就认为文件是当前有效的,除非服务器呼叫指出服务器上的该文件已改变了
二、开源分布式文件系统
1.GFS
(1)GFS与NFS,AFS的区别
首先来说一下GFS和NFS、AFS的区别:NFS、GFS都是Remote Access Model,需要用RPC进行,每次对文件的修改立马会反馈给服务器。AFS使用的是Upload/ Download Model,拷贝文件到本地,只有关闭本地文件的时候才会把所有的更新返回,同时使用了callback函数,只有callback说本地缓存有效才能使用。
GFS用单一主控机+多台工作机的模式,由一台主控机(Master)存储系统全部元数据,并实现数据的分布、复制、备份决策,主控机还实现了元数据的checkpoint和操作日志记录及回放功能。工作机存储数据,并根据主控机的指令进行数据存储、数据迁移和数据计算等。其次,GFS通过数据分块和复制(多副本,一般是3)来提供更高的可靠性和更高的性能。当其中一个副本不可用时,系统都提供副本自动复制功能。同时,针对数据读多于写的特点,读服务被分配到多个副本所在机器,提供了系统的整体性能。最后,GFS提供了一个树结构的文件系统,实现了类似与Linux下的文件复制、改名、移动、创建、删除操作以及简单的权限管理等
(2)BigTable
Bigtable是一个为管理大规模结构化数据而设计的分布式存储系统,可以扩展到PB级数据和上千台服务器。本质上说,Bigtable是一个键值(key-value)映射。按作者的说法,Bigtable是一个稀疏的,分布式的,持久化的,多维的排序映射。稀疏的意思是行列时间戳的维度可以不一样,分布式是以为BigTable本身就是建立在GFS上,持久化就是它在GFS上建立可以保持数据的稳定性。用GFS来存储日志和数据文件;按SSTable文件格式存储数据;用Chubby管理元数据。主服务器负责将片分配给片服务器,监控片服务器的添加和删除,平衡片服务器的负载,处理表和列族的创建等。注意,主服务器不存储任何片,不提供任何数据服务,也不提供片的定位信息。
客户端需要读写数据时,直接与片服务器联系。因为客户端并不需要从主服务器获取片的位置信息,所以大多数客户端从来不需要访问主服务器,主服务器的负载一般很轻。
(3)Chubby
Consensus:在一个分布式系统中,有一组的Process,它们需要确 定一个Value。于是每个Process都提出了一个Value,consensus就是指只有其中的一个Value能够被选中作为最后确定的值,并且 当这个值被选出来以后,所有的Process都需要被通知到。
在GFS中,进行数据传递的时候,Master需要选择一个chunkserver作为临时的Master响应客户端的请求,这个就是一个consensus的问题。
Chubby是一个 lock service,一个针对松耦合的分布式系统的lock service。所谓lock service,就是这个service能够提供开发人员经常用的“锁”,“解锁”功能。通过Chubby,一个分布式系统中的上千个client都能够 对于某项资源进行“加锁”,“解锁”。
那么,Chubby是怎样实现这样的“锁”功能的?就是通过文件。
Chubby中的“锁”就是文件,在上例 中,创建文件其实就是进行“加锁”操作,创建文件成功的那个server其实就是抢占到了“锁”。用户通过打开、关闭和读取文件,获取共享锁或者独占锁; 并且通过通信机制,向用户发送更新信息。
(4)特点1
- Google公司为了满足本公司需求而开发的基于Linux的专有分布式文件系统。。尽管Google公布了该系统的一些技术细节,但Google并没有将该系统的软件部分作为开源软件发布。
下面分布式文件系统都是类 GFS的产品。 - Goolge的法宝:GFS、BigTable、Chubby、MapReduce。
- chunkserver提供存储。GFS会将文件划分为定长数据块,每个数据块都有一个全局唯一不可变的id(chunk_handle),数据块以普通Linux文件的形式存储在chunkserver上,出于可靠性考虑,每个数据块会存储多个副本,分布在不同chunkserver。
- GFS master就是GFS的元数据服务器,负责维护文件系统的元数据,包括命名空间、访问控制、文件-块映射、块地址等,以及控制系统级活动,如垃圾回收、负载均衡等。
2.HDFS
(1)HDFS与Ceph对比
Ceph对比HDFS优势在于易扩展,无单点。HDFS是专门为Hadoop这样的云计算而生,在离线批量处理大数据上有先天的优势,而Ceph是一个通用的实时存储系统。虽然Hadoop可以利用Ceph作为存储后端(根据Ceph官方的教程死活整合不了,自己写了个简洁的步骤: http://www.kai-zhang.com/cloud-computing/Running-Hadoop-on-CEPH/), 但执行计算任务上性能还是略逊于HDFS(时间上慢30%左右 Haceph: Scalable Meta- data Management for Hadoop using Ceph)。
(2)特点1
- 适用于一次写入多次查询的情况,不支持并发写情况,小文件不合适。
- Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。 Hadoop是Apache Lucene创始人Doug Cutting开发的使用广泛的文本搜索库。它起源于Apache Nutch,后者是一个开源的网络搜索引擎,本身也是Luene项目的一部分。Aapche Hadoop架构是MapReduce算法的一种开源应用, 是Google开创其帝国的重要基石。
(3)特点2
HDFS是GoogleFS的开源实现。HDFS1.0版本架构是一种经典的分布式文件系统架构,包括个部分:独立的元数据服务器(name node),客户端(client),数据节点(data node)。文件被切分为大小相同的chunk分布在不同的data node上。Name node维护file与chunk的映射关系以及chunk的位置信息。Client跟data node交互进行数据读写。
这里主要看下HDFS2.0版本的架构改进,主要是亮点:
-
NameNode HA- 1
HDFS1.0中mds是一个单点故障,虽然很多厂家有自己的HA方案,但是并不同意。HDFS2.0版本推出了官方的HA方案,主要思路是主备两个MDS,两个MDS共享一个san,用这个san来存储mds的日志文件。这种HA方案依赖于第三方san的可靠性。

2. MDS federation
相当于MDS cluster。每个namenode都可以单独向外提供服务。每个namenode都管理所有的datanode。缺点是根目录下的某个子目录的所有文件只能位于一个namenode上。跟ZXDFS目前分域的方案实现比较像,只是没主域的概念。Client启动时要扫描所有的MDS以获取根目录下子目录跟namenode的对应关系。
3. Ceph
(1)Ceph特点1
- 是加州大学圣克鲁兹分校的Sage weil攻读博士时开发的分布式文件系统。并使用Ceph完成了他的论文。说 ceph 性能最高,C++编写的代码,支持Fuse,并且没有单点故障依赖, 于是下载安装, 由于 ceph 使用 btrfs 文件系统, 而btrfs 文件系统需要 Linux 2.6.34 以上的内核才支持。
可是ceph太不成熟了,它基于的btrfs本身就不成熟,它的官方网站上也明确指出不要把ceph用在生产环境中。
(2)Ceph特点2
Ceph是一个可以按对象/块/文件方式存储的开源分布式文件系统,其设计之初,就将单点故障作为首先要解决的问题,因此该系统具备高可用性、高性能及可 扩展等特点。该文件系统支持目前还处于试验阶段的高性能文件系统BTRFS(B-Tree文件系统),同时支持按OSD方式存储,因此其性能是很卓越的, 因为该系统处于试商用阶段,需谨慎引入到生产环境
特性
1)Ceph底层存储是基于RADOS(可靠的、自动的分布式对象存储),它提供了LIBRADOS/RADOSGW/RBD/CEPH FS方式访问底层的存储系统,如下图所示
2)通过FUSE,Ceph支持类似的POSIX访问方式;Ceph分布式系统中最关键的MDS节点是可以部署多台,无单点故障的问题,且处理性能大大提升
3)Ceph通过使用CRUSH算法动态完成文件inode number到object number的转换,从而避免再存储文件metadata信息,增强系统的灵活性
优点
1)支持对象存储(OSD)集群,通过CRUSH算法,完成文件动态定位, 处理效率更高
2)支持通过FUSE方式挂载,降低客户端的开发成本,通用性高
3)支持分布式的MDS/MON,无单点故障
4)强大的容错处理和自愈能力5)支持在线扩容和冗余备份,增强系统的可靠性
缺点
1)目前处于试验阶段,系统稳定性有待考究
应用场景
1)全网分布式部署的应用
2)对实时性、可靠性要求比较高官方宣传,存储容量可轻松达到PB级别
源码路径:https://github.com/ceph/ceph
参考
http://ceph.com/
(3)特点3
Ceph主要架构来自于加州大学SantaCruz. 分校Sage Weil的博士论文。07年毕业后全职投入ceph的开发。12年才有stable版本发布。目前开发者社区是由Inktank公司主导并提供商业支持。
特点1.
采用集中式元数据管理,整体架构包括client(在kernel实现),MDS和OSD。文件目录树由MDS维护。文件被切分为大小相同的object,每个object被hash到不同的OSD(数据节点)上,OSD负责维护具体的文件数据。
特点2.
支持元数据服务器集群,将目录树动态划分为若干子树,每个子树都有两个副本在两个MDS上提供服务,一个MDS同时支持多个不同的子树:

特点3
统一存储架构,支持多种接口。去掉MDS并增加若干Http proxy server后,就是P2P的对象存储,支持S3接口。去掉MDS并增加iSICSI Target Server还可以对外提供block接口。
特点4
Ceph中的一致性通过primary副本来保护。每个对象有一个主副本,客户端只跟主副本打交道,主副本所在的OSD负责把数据写到其他副本。
特点5
虚拟化环境的集成,支持多种元计算框架例如OpenStack、CloudStack、OpenNebula,Ceph已经可以集成到openstack作为cinder(弹性块存储,类似amazon的EBS)的一种实现。
商业应用:
目前ceph被视为一种实验性的文件系统,目前并无大型商业应用。根据Inktank公司公布的调查结果,目前在一些中小型的企业和组织中有商业应用,生产环境尚未有超过1P的案例。目前有些openstack厂家也在验证使用ceph为云计算环境提供虚拟化存储的可行性。
4. Lustre
(1)特点1
- Lustre是一个大规模的、安全可靠的,具备高可用性的集群文件系统,它是由SUN公司开发和维护的。
该项目主要的目的就是开发下一代的集群文件系统,可以支持超过10000个节点,数以PB的数据量存储系统。
目前Lustre已经运用在一些领域,例如HP SFS产品等。
适合存储小文件、图片的分布文件系统研究
(2)特点2
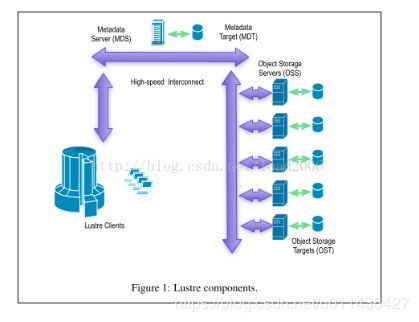
Lustre是linux+cluster的缩写。Lustre是一个并行的分布式文件系统,主要应用领域是HPC(high performance compute)。目前Top100的超级计算机中,超过60的都是在使用lustre。
特点1:
传统的体系结构:MDS(元数据服务器) OSS(数据服务器)Client。MDS、OSS分别将元数据信息、数据信息持久化存储到本地文件系统中,本地文件系统采用的是ext4。每个文件会被切分成多个大小相等的object,多个object条带化到多个OSS上。MDS负责存储和管理file跟object映射关系。
特点2:
支持上万个客户端的并发读写。HPC领域的重要应用场景是多个客户端并发读写同一个文件。Lustre通过Distributed Lock Manager解决多客户端并发读写的问题。Lock包括两种,一个种是fileinode的锁,一种是file data的锁。Inode锁由mds统一管理,file data锁则由OSS管理,file data锁支持字节范围的锁。
商业支持发展:
最初组织Lustre开发的公司先被sun收购。Sun被oracle收购后大部分开发人员离开并组织了新公司,目前新公司已经被intel收购。由于lustre本身开源,传统SAN硬件厂家例如HDS、Dell、netapp也将lustre捆绑自己的硬件提供解决方案,并提供lustre技术支持。每年都会召一次全球Lustre用户大会LUG(lustre user group)。
5.MogileFS
(1)特点1
- 由memcahed的开发公司danga一款perl开发的产品,目前国内使用mogielFS的有图片托管网站yupoo等。
MogileFS是一套高效的文件自动备份组件,由Six Apart开发,广泛应用在包括LiveJournal等web2.0站点上。 - MogileFS由3个部分组成:
第1个部分是server端,包括mogilefsd和mogstored两个程序。前者即是 mogilefsd的tracker,它将一些全局信息保存在数据库里,例如站点domain,class,host等。后者即是存储节点(store node),它其实是个HTTP Daemon,默认侦听在7500端口,接受客户端的文件备份请求。在安装完后,要运行mogadm工具将所有的store node注册到mogilefsd的数据库里,mogilefsd会对这些节点进行管理和监控。
第2个部分是utils(工具集),主要是MogileFS的一些管理工具,例如mogadm等。
第3个部分是客户端API,目前只有Perl API(MogileFS.pm)、PHP,用这个模块可以编写客户端程序,实现文件的备份管理功能。
(2)特点2
开发语言:perl
开源协议:GPL
依赖数据库
Trackers(控制中心):负责读写数据库,作为代理复制storage间同步的数据
Database:存储源数据(默认mysql)
Storage:文件存储
除了API,可以通过与nginx集成,对外提供下载服务
源码路径:https://github.com/mogilefs
参考
https://code.google.com/p/mogilefs/wiki/Start?tm=6
其它参考
http://blog.csdn.net/qiangweiloveforever/ariticle/details/7566779
http://weiruoyu.blog.51cto.com/951650/786607
http://m.blog.csdn.net/blog/junefsh/18079733
(3)特点3
MooseFS本质上是GoogleFS或HDFS的c实现。
集中式元数据管理,元数据服务器主备。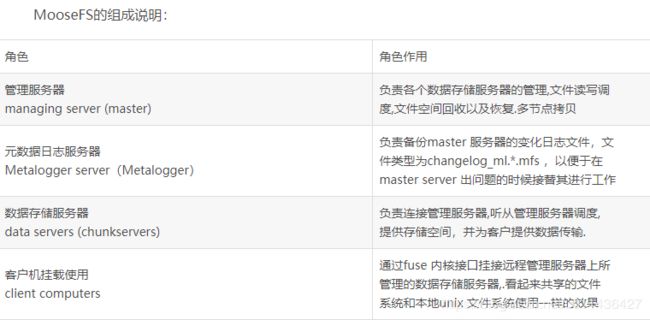
oosefs的功能特点:
支持snapshot
实现了文件回收站
支持动态扩容
小文件读写优化
Client支持多种操作系统包括:LinuxFreeBSD OpenSolaris和MacOS
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
商业应用:
中小型企业,学校、web网站。
- 1
存放普通文件、img、weblog等分结构化数据。
Web server备份 。
Kvm xen虚拟机镜像文件。
6.mooseFS
- 持FUSE,相对比较轻量级,对master服务器有单点依赖,用perl编写,性能相对较差,国内用的人比较多
(1)mooseFS简介
MooseFS是一个高可用的故障容错分布式文件系统,它支持通过FUSE方式将文件挂载操作,同时其提供的web管理界面非常方便查看当前的文件存储状态。
特性
1)从下图中我们可以看到MooseFS文件系统由四部分组成:Managing Server 、Data Server 、Metadata Backup Server 及Client
2)其中所有的元数据都是由Managing Server管理,为了提高整个系统的可用性,Metadata Backup Server记录文件元数据操作日志,用于数据的及时恢复
3)Data Server可以分布式部署,存储的数据是以块的方式分布至各存储节点的,因此提升了系统的整体性能,同时Data Server提供了冗余备份的能力,提升系统的可靠性
4)Client通过FUSE方式挂载,提供了类似POSIX的访问方式,从而降低了Client端的开发难度,增强系统的通用性
元数据服务器(master):负责各个数据存储服务器的管理,文件读写调度,文件空间回收以及恢复
元数据日志服务器(metalogger):负责备份master服务器的变化日志文件,以便于在master server出问题的时候接替其进行工作
数据存储服务器(chunkserver):数据实际存储的地方,由多个物理服务器组成,负责连接管理服务器,听从管理服务器调度,提供存储空间,并为客户提供数据传输;多节点拷贝;在数据存储目录,看不见实际的数据
优点
1)部署安装非常简单,管理方便
2)支持在线扩容机制,增强系统的可扩展性
3)实现了软RAID,增强系统的 并发处理能力及数据容错恢复能力
4)数据恢复比较容易,增强系统的可用性5)有回收站功能,方便业务定制
缺点
1)存在单点性能瓶颈及单点故障
2)MFS Master节点很消耗内存
3)对于小于64KB的文件,存储利用率较低
应用场景
1)单集群部署的应用
2)中、大型文件
参考
http://portal.ucweb.local/docz/spec/platform/datastore/moosefsh
http://www.moosefs.org/
http://sourceforge.net/projects/moosefs/?source=directory
7.FastDFS
(1)特点1
- 是一款类似Google FS的开源分布式文件系统,是纯C语言开发的。
FastDFS是一个开源的轻量级分布式文件系统,它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
官方论坛 http://bbs.chinaunix.net/forum-240-1.html
FastDfs google Code http://code.google.com/p/fastdfs/
分布式文件系统FastDFS架构剖析 http://www.programmer.com.cn/4380/
(2)特点2
FastDFS是国人开发的一款分布式文件系统,目前社区比较活跃。如上图所示系统中存在三种节点:Client、Tracker、Storage,在底层存储上通过逻辑的分组概念,使得通过在同组内配置多个Storage,从而实现软RAID10,提升并发IO的性能、简单负载均衡及数据的冗余备份;同时通过线性的添加新的逻辑存储组,从容实现存储容量的线性扩容。
文件下载上,除了支持通过API方式,目前还提供了apache和nginx的插件支持,同时也可以不使用对应的插件,直接以Web静态资源方式对外提供下载。
目前FastDFS(V4.x)代码量大概6w多行,内部的网络模型使用比较成熟的libevent三方库,具备高并发的处理能力。
特性
1)在上述介绍中Tracker服务器是整个系统的核心枢纽,其完成了访问调度(负载均衡),监控管理Storage服务器,由此可见Tracker的作用至关重要,也就增加了系统的单点故障,为此FastDFS支持多个备用的Tracker,虽然实际测试发现备用Tracker运行不是非常完美,但还是能保证系统可用。
2)在文件同步上,只有同组的Storage才做同步,由文件所在的源Storage服务器push至其它Storage服务器,目前同步是采用Binlog方式实现,由于目前底层对同步后的文件不做正确性校验,因此这种同步方式仅适用单个集群点的局部内部网络,如果在公网上使用,肯定会出现损坏文件的情况,需要自行添加文件校验机制。
3)支持主从文件,非常适合存在关联关系的图片,在存储方式上,FastDFS在主从文件ID上做取巧,完成了关联关系的存储。
优点
1)系统无需支持POSIX(可移植操作系统),降低了系统的复杂度,处理效率更高
2)支持在线扩容机制,增强系统的可扩展性
3)实现了软RAID,增强系统的并发处理能力及数据容错恢复能力
4)支持主从文件,支持自定义扩展名
5)主备Tracker服务,增强系统的可用性
缺点
1)不支持断点续传,对大文件将是噩梦(FastDFS不适合大文件存储)
2)不支持POSIX通用接口访问,通用性较低
3)对跨公网的文件同步,存在较大延迟,需要应用做相应的容错策略
4)同步机制不支持文件正确性校验,降低了系统的可用性
5)通过API下载,存在单点的性能瓶颈
应用场景
1)单集群部署的应用
2)存储后基本不做改动
3)小中型文件根据
目前官方提供的材料,现有的使用FastDFS系统存储容量已经达到900T,物理机器已经达到100台(50个组)
安装指导_FastDFS
源码路径:https://github.com/happyfish100/fastdfs
参考
https://code.google.com/p/fastdfs/
http://bbs.chinaunix.net/forum-240-1.html
http://portal.ucweb.local/docz/spec/platform/datastore/fastdfs
(3)特点3

Fast DFS是一种纯轻量级的分布式文件系统,主要有国内开发者贡献。主要特点是结构简单,维护成本低,一般用于小型网站。架构特点:
-
不维护目录树,client每次新建文件的时候由负载均衡器Tracker Server生成一个file id和path给client- 1
-
没有file和chunk概念,Tracker server只是负责轮选storage server给client使用。- 1
-
Storage server分成不同的group,每个group之间是简单的镜像关系。- 1
-
读写文件时tracker负责不同组以及组内的负载均衡。- 1
-
Strage server就是把文件写入到本地的文件系统中。- 1
8.TFS
- TFS(Taobao !FileSystem)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器 集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用 在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化 了文件的访问流程,一定程度上为TFS提供了良好的读写性能。
官网 : http://code.taobao.org/p/tfs/wiki/index/
(1)特点1
TFS(Taobao File System)是由淘宝开发的一个分布式文件系统,其内部经过特殊的优化处理,适用于海量的小文件存储,目前已经对外开源;
TFS采用自有的文件系统格式存储,因此需要专用的API接口去访问,目前官方提供的客户端版本有:C++/JAVA/PHP。
特性
1)在TFS文件系统中,NameServer负责管理文件元数据,通过HA机制实现主备热切换,由于所有元数据都是在内存中,其处理效率非常高效,系统架构也非常简单,管理也很方便;
2)TFS的DataServer作为分部署数据存储节点,同时也具备负载均衡和冗余备份的功能,由于采用自有的文件系统,对小文件会采取合并策略,减少数据碎片,从而提升IO性能;
3)TFS将元数据信息(BlockID、FileID)直接映射至文件名中,这一设计大大降低了存储元数据的内存空间;
优点
1)针对小文件量身定做,随机IO性能比较高;
2)支持在线扩容机制,增强系统的可扩展性;
3)实现了软RAID,增强系统的并发处理能力及数据容错恢复能力;
4)支持主备热倒换,提升系统的可用性;
5)支持主从集群部署,其中从集群主要提供读/备功能;
缺点
1)TFS只对小文件做优化,不适合大文件的存储;
2)不支持POSIX通用接口访问,通用性较低;
3)不支持自定义目录结构,及文件权限控制;
4)通过API下载,存在单点的性能瓶颈;
5)官方文档非常少,学习成本高;
应用场景
1)多集群部署的应用
2)存储后基本不做改动
3)海量小型文件
根据目前官方提供的材料,对单个集群节点,存储节点在1000台以内可以良好工作,如存储节点扩大可能会出现NameServer的性能瓶颈,目前淘宝线上部署容量已达到1800TB规模(2009年数据)
安装及使用
安装指导
TFS_配置使用
源代码路径:http://code.taobao.org/p/tfs/src/
参考
别人总结的:https://www.bbsmax.com/A/o75NxYxzW3/
https://www.bbsmax.com/A/GBJr77kZ50/
https://blog.csdn.net/wangxingqian/article/details/8932378
很好
http://rdc.taobao.com/blog/cs/?p=128
http://elf8848.iteye.com/blog/1724423
http://baike.baidu.com/view/1030880.htm
http://blog.yunnotes.net/index.php/install_document_for_tfs/
(2)特点2

TFS的总体架构也是仿照HDFS,这里看下区别:
-
HDFS中一个file由多个chunk组成。TFS反过来,一个64Mchunk会存放多个file。相当于小文件聚合。- 1
-
TFS的filename包含了很多元数据信息力例如文件的chunkid和fileid,这样显著减轻了MDS的压力。- 1
-
文件在chunk中的偏移量mds不需要关心,具体维护是datanode来做的,减少了mds维护的元数据信息。- 1
-
为了防止磁盘碎片,datanode利用ext4的一些特性,例如fallocate,首先利用fallocate为每个chunk文件分配好空间。- 1
-
Mds在为每个新文件分配chunk时,采用的是一致性hash的方法定位新chunk的位置。这样有利于集群的线性扩容。- 1
9.GridFS文件系统
- MongoDB是一种知名的NoSql数据库,GridFS是MongoDB的一个内置功能,它提供一组文件操作的API以利用MongoDB存储文件,GridFS的基本原理是将文件保存在两个Collection中,一个保存文件索引,一个保存文件内容,文件内容按一定大小分成若干块,每一块存在一个Document中,这种方法不仅提供了文件存储,还提供了对文件相关的一些附加属性(比如MD5值,文件名等等)的存储。文件在GridFS中会按4MB为单位进行分块存储。
MongoDB GridFS 数据读取效率 benchmark
http://blog.nosqlfan.com/html/730.html
nginx + gridfs 实现图片的分布式存储 安装(一年后出问题了)
http://www.cnblogs.com/zhangmiao-chp/archive/2011/05/05/2038285.html
基于MongoDB GridFS的图片存储
http://liut.cc/blog/2010/12/about-imsto_my-first-open-source-project.html
nginx+mongodb-gridfs+squid
http://1008305.blog.51cto.com/998305/885340
10.NFS
NFS 是Network File System的缩写,即网络文件系统。一种使用于分散式文件系统的协定,由Sun公司开发,于1984年向外公布。功能是通过网络让不同的机器、不同的操作系统能够彼此分享个别的数据,让应用程序在客户端通过网络访问位于服务器磁盘中的数据,是在类Unix系统间实现磁盘文件共享的一种方法。
NFS 的基本原则是“容许不同的客户端及服务端通过一组RPC分享相同的文件系统”,它是独立于操作系统,容许不同硬件及操作系统的系统共同进行文件的分享。
nfsd:它是基本的NFS守护进程,主要功能是管理客户端是否能够登录服务器;mountd:它是RPC安装守护进程,主要功能是管理NFS的文件系统。当客户端顺利通过nfsd登录NFS服务器后,在使用NFS服务所提供的文件前,还必须通过文件使用权限的验证。它会读取NFS的配置文件/etc/exports来对比客户端权限;idmapd:主要功能是进行端口映射工作。当客户端尝试连接并使用RPC服务器提供的服务(如NFS服务)时,rpcbind会将所管理的与服务对应的端口提供给客户端,从而使客户可以通过该端口向服务器请求服务。
使用NFS mount到了客户端之后,客户端访问远程文件就像访问本地文件一样。mount之后,路径访问每次只能访问当前目录,需要一次RPC,所以用户端最好进行缓存。为什么不能直接把整个目录全部返回,因为服务器不知道用户端在该目录下的文件有没有mount别的文件系统,这样贸然返回全部,很浪费资源,而且客户端不一定用得到。当然也存在有时候需要返回全部的情况,但是NFS v4.2才有,目前该版本还在开发中。
在NFSv3维护缓存一致性的时候,采用的是30s原则。使用了一个叫做租约的东西。AFS是读取最近关闭的版本的数据。Unix是能够获得最近多有的写操作;HTTP:没有进行一致性操作,每次读取数据,都要判断是否是最新的数据。在30s内服务器不会做出改变,客户端使用write-through 缓存,并且再超过30s以后检查缓存。客户端提供会话和缓存,服务器做了一个本地服务器能够做的一切。(属于无状态缓存,stateless)
有无状态的保存(服务器需要保存客户端状态么?)
无状态:简单,更快速,容易从崩溃之后恢复;不会有因为追踪状态而消耗资源的问题;
有状态:更快,可能。能够提供更好的语义操作。
客户端访问分布式文件时需要handle,这个handle来自于服务器,有inode number,还有根据当前inode随机生成的数字。
(1)多服务器存储
如果只有一个服务器来响应请求的话,那么负载过大,这个服务器会变成瓶颈。考虑到负载均衡和调度更新,可以使用多服务器。
NFSv3中,每个服务器都存了不同的文件,并且都有自己的NFS命名空间。具体怎么挂载就是客户端的事情。每次用户端访问一个文件,需要遍历命名空间来找到mount的节点。负载均衡方面系统管理员手动地将文件子树赋给另外一个。
(2)pNFS
直接送到存储媒介而不需要通过文件系统。
Storage Devices是保存文件实际数据的设备,由一台或者多台数据服务器构成。当Clients获得了文件的layout后,就可以直接向Storage Devices发送数据了。由于Storage Devices包含多台数据服务器 Clients可以同时执行多个I/O请求,从而提升了系统吞吐量。pNFS只是Clients和Server之间的通信协议,Clients和Storage Devices传输数据时需要使用专门的存储协议。目前RFC定义了三种存储协议:file layout(RFC5661)、block layout(RFC5663)、object layout(RFC5664)
Server是支持pNFS特性的一台NFS服务器,Server中保存了文件的布局结构(layout)。文件布局是对文件在Storage Devices中存储方式的一种说明,Clients在读写数据前需要先向Server请求文件的layout,通过layout,Clients就可以知道文件存储在哪个Storage Device中了,以及是如何存储的。读写操作完成后,Clients需要将layout返还给Server。如果是写操作,Clients可能会修改layout,写操作完成后需要更新Server中的layout。
(3)AFS
客户端获取整个文件并从服务器获得回调函数,在v3版本的时候是使用64KB的chunk,当然也支持整个文件。服务器使用回调当数据发生了变化。客户端使用write-back整个文件关闭的时候。(cache+callback)
AFS中,服务器也是服务独立的文件集合,但是在命名空间上只有一个。AFS内部会进行连接,帮客户找到文件在的服务器volumn,而不需要用户进行。遍历命名空间,就可以找到对应的volumn进行管理。在负载均衡上面,使用轮流改变volumn来获得。
11.PFS(parallel file system)
IBM GPFS文件系统是一种专门为群集环境设计的高性能、可扩展的并行文件系统。GPFS可以在群集中的多个节点间实现对共享文件系统中文件的快速存取操作,并提供稳定的故障恢复和容错机制。主要就是HPC,超算进行。
解决metadata服务器瓶颈的方法:IBM GPFS并行文件系统与其它并行文件系统之间最大的区别在于GPFS不需要专用的元数据(Meta Data)管理服务器,所有元数据分散在磁盘阵列中,并可以由任何I/O节点管理。这样的设计避免了并行文件系统中最可能产生性能瓶颈的因素——Meta Data Server。
在文件系统层面,每个GPFS集群中可以创建最多256个文件系统,每个文件系统都对应多个管理服务器(可以由任何I/O节点承担)。当任何一个文件系统管理服务器宕机时,都会有另外一个服务器自动接替其工作,保证并行文件系统的高可用性。
12.OpenStack Swift
(1)OpenStack Swift 和Ceph对比
网友qfxhz:” Ceph虽然也有一些缺点问题,但是瑕不掩瑜,还是感觉Ceph更好一点, Ceph存储集成了对象存储和块存储,而Swift系统只能处理对象存储,不支持块存储和文件存储。“
网友momo: “还是选择Swift吧。Ceph很重要的一个短板就是安全性。云计算节点上的RADOS客户端直接与RADOS服务器交互所使用的网络与Ceph用于未加密复制流量的网络相同。如果某个Ceph客户端节点被入侵,攻击者便能得到存储网络的所有流量。“
网友yehuafeilang:“ceph毕竟不是一个专门的对象存储系统,其对象存储服务其实是在block服务上模拟出来的,所以和专门的对象存储swift比起来,在部署规模,使用成本上会有比较大的差距;但是,因为不是所有的云都需要大规模的对象存储,考虑到跨地域场景时,swift的部署也很复杂,所以在刚开始搭建openstack云服务时,或者是对象存储业务量不是很大时,为了节省系统搭建时间,使用ceph提供S3服务也是个不错的选择。“
网友fatelyliang:存储不像服务器,它承载的内容是企业最重要的数据和信息,对他的可靠性、完整性、可用性、安全性、运行性能、与企业中的云计算平台关系、存储特征的可定义性等各部分的要求都应该是企业信息化基础架构中最重要的一个判断。存储设备的损坏、更换等都是对企业影响非常大的一个事情!除非系统可以轻易停机!因此,在目前的状态下,开源的存储我会更建议应用在开发测试环境、容灾环境等重要性级别相对稍低的地方,充分验证在以上几个判断依据的结论之后,结合企业的实际指标判断应该选取那一个!
Ceph这样的系统一般不支持跨机房,跨地域的大规模部署。如果部署只在单一地域,没有计划扩展到多个地域时,Ceph会是很好的选择。但是,如果要考虑大规模部署的话,Swift可能更为适合。因为它的多地域能力会胜过 Ceph。从安全角度来看,Swift封闭的复制网络更为安全,但是,如果云基础架构本身已经很安全,存储安全性优先级便会降低,这时可能Ceph更适合。其实,在同一个云基础架构里同时拥有这两种选择也是可行的。比如说,可以使用Ceph作为本地高性能存储,而Swift则作为多地域Glance后台,但是,拥有这两种选择的解决方案花费必然更多,对于资金雄厚的企业来说为了避免长时间纠结,可以一试。 对于中小企业来讲还是得悉心衡量利弊以及自身的需求,做好整体把控为妙。关于Swift和Ceph二者的选择,更重要的是要从两者的架构角度分析各自的优缺点,并且需要结合自身的应用场景、技术实力、运营实力来进行评估,具体问题具体分析,不必纠结,正所谓寸有所长,尺有所短,选择最合适的才是最好的。
Ceph用C++编写而Swift用Python编写,性能上应当是Ceph占优。但是与Ceph不同,Swift专注于对象存储,作为OpenStack组件之一经过大量生产实践的验证,与OpenStack结合很好,目前不少人使用Ceph为OpenStack提供块存储,但仍旧使用Swift提供对象存储。
13.GlusterFS
(1)特点简介1
GlusterFS是Red Hat旗下的一款开源分布式文件系统,它具备高扩展、高可用及高性能等特性,由于其无元数据服务器的设计,使其真正实现了线性的扩展能力,使存储总容量可 轻松达到PB级别,支持数千客户端并发访问;对跨集群,其强大的Geo-Replication可以实现集群间数据镜像,而且是支持链式复制,这非常适用 于垮集群的应用场景
特性
1)目前GlusterFS支持FUSE方式挂载,可以通过标准的NFS/SMB/CIFS协议像访问本体文件一样访问文件系统,同时其也支持HTTP/FTP/GlusterFS访问,同时最新版本支持接入Amazon的AWS系统
2)GlusterFS系统通过基于SSH的命令行管理界面,可以远程添加、删除存储节点,也可以监控当前存储节点的使用状态
3)GlusterFS支持集群节点中存储虚拟卷的扩容动态扩容;同时在分布式冗余模式下,具备自愈管理功能,在Geo冗余模式下,文件支持断点续传、异步传输及增量传送等特点
Yuyj GlusterFS.png
优点
1)系统支持POSIX(可移植操作系统),支持FUSE挂载通过多种协议访问,通用性比较高
2)支持在线扩容机制,增强系统的可扩展性
3)实现了软RAID,增强系统的 并发处理能力及数据容错恢复能力
4)强大的命令行管理,降低学习、部署成本
5)支持整个集群镜像拷贝,方便根据业务压力,增加集群节点
6)官方资料文档专业化,该文件系统由Red Hat企业级做维护,版本质量有保障
缺点
1)通用性越强,其跨越的层次就越多,影响其IO处理效率
2)频繁读写下,会产生垃圾文件,占用磁盘空间
应用场景
1)多集群部署的应用
2)中大型文件根据目前官方提供的材料,现有的使用GlusterFS系统存储容量可轻松达到PB
术语:
brick:分配到卷上的文件系统块;
client:挂载卷,并对外提供服务;
server:实际文件存储的地方;
subvolume:被转换过的文件系统块;
volume:最终转换后的文件系统卷。
参考
http://www.gluster.org/
http://www.gluster.org/wp-content/uploads/2012/05/Gluster_File_System-3.3.0-Administration_Guide-en-US.pdf
http://blog.csdn.net/liuben/article/details/6284551
(1)特点简介2

特点1:去中心化的分布式元数据架构
采用DHT的方式将每个file按照filename映射到节点上,
通过Davies Meyer hash函数对filename取hash值
如果file被rename,那么按照新的name计算hash后的新节点上会新建一个pointer,指向原来文件元数据所在节点。
- 1
- 2
- 3
- 4
- 5
特点2:模块化、协议栈式的文件系统
目前支持三种基本的功能和属性:
Replicator 副本,相当于raid1
Stripe 条带,相当于raid0
Distributed 分布式,相当于DHT
- 1
- 2
- 3
- 4
- 5
以上任意两个模块可以组合在一起。当时系统一旦选择其中一个属性,后面不能再修改。
目前主要的用法是Distributed+Replicator。选择了Distributed+Replicator后,某个文件就会在Gluster集群的两个节点上各有一份镜像。
其他:
存储节点上支持多种文件系统ext3、ext4、xfs、zfs
存储节点的硬件可以是JBOD,也可以是FC san
NAS集群功能通过CTDB实现
通过一个用户态的轻量级的nfsserver提供NFS接口
CIFS通过linux自带的Samba实现
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
全兼容Hadoop,可以替代HDFS
Client端提供最新的KVM的补丁,可以为KVM的虚拟机提供存储能力。
商业应用:
最初GlusterFS由Gluster INC提供商业服务。被intel收购后将全部源码开源。也有第三方的存储厂家提供基于GlusterFS的解决方案
三、参考:
(1)https://blog.csdn.net/faychu/article/details/47124271
(2)https://blog.csdn.net/qq_33314107/article/details/80978669
(3)https://blog.csdn.net/c602273091/article/details/78643889#%E6%99%AE%E9%80%9A%E7%9A%84%E5%AD%98%E5%82%A8%E6%96%B9%E6%B3%95
(4)https://blog.csdn.net/Prepared/article/details/72491036
(5)https://blog.csdn.net/zzq900503/article/details/80020725
(6)https://blog.csdn.net/enweitech/article/details/82414361
(7)https://blog.csdn.net/load2006/article/details/14119025
(8)https://blog.csdn.net/qq_33314107/article/details/80978669
(9)链接:https://www.zhihu.com/question/26993542/answer/129451667