tshark在流量分析中的绝佳应用(超详细)
目录
- 简介
- 参数
- tshark与wireshark对比
- 基本命令
-
- 获取数据包摘要信息
- 显示时间格式
- 捕获过滤器
- 捕获并保存数据包
- 显示过滤器
-
- 区分显示过滤器和读取过滤器
- 一些好用的显示过滤器
- -e参数的应用
-
- HTTP中的应用案例
- mysql中的应用案例
- -z参数的应用
-
- 专家信息:**-z expert**
- 追踪流:**-z follow**
- -z http
- 统计数据包信息
- 统计会话
- 统计出所有IP
- 显示每个协议树的具体信息
- 导出对象
- 追踪流
-
- 追踪tcp流/http流
-
- 追踪流数量
- 读取TCP流-纯16进制
- 读取TCP流-16进制
- 读取TCP流-ascii
- 获取TCP流,并保存为pcap文件
- 追踪udp流
- 实战
-
- 1:统计出所有的会话IP组
- 2:获取数据包中的所有IP
- 3:拆分数据包
- 4:批量开发IPS规则
- 5: 基于流量分析IPS告警&误报
- 参考
中文互联网上关于tshark的文章,鲜有比我这篇更全的了。整理了工具的常见命令,以及在IPS中的一些应用案例,希望能大家有所帮助!
由于我是把语雀笔记把导出放到CSDN的,而语雀笔记是私人笔记,导致他人无法直接在这个博客上下载附件,请知悉。可以自己随便抓个数据包自行练习。
简介
tshark相当于是命令行版的wireshark,不需要额外安装,在安装wireshark的时候就会安装上这个工具。建议把tshark加入到环境变量中,方便后续使用!
测试用到的三个文件(删除pdf后缀即可):test.pcap.pdf、存储型XSS.pcap.pdf、testnew.pcap.pdf
补充:涉及到3个ip,192.169.40.1(物理机-python3开启web服务)、192.168.40.128(kali-apache2提供web服务)、192.168.40.129(win7-phpstudy提供web服务)
关于tshark:
- tshark的位置:请使用Everything等工具直接搜索出来。
- 使用
tshark.exe -D命令查看电脑上有哪些网卡。

\Device\NPF_{FA29BC17-7BFC-4CE8-BB48-71174A6BDA54},这串东西是接口名称,通过wireshark可以看到,如下图,点击一下“管理接口”即可看到。
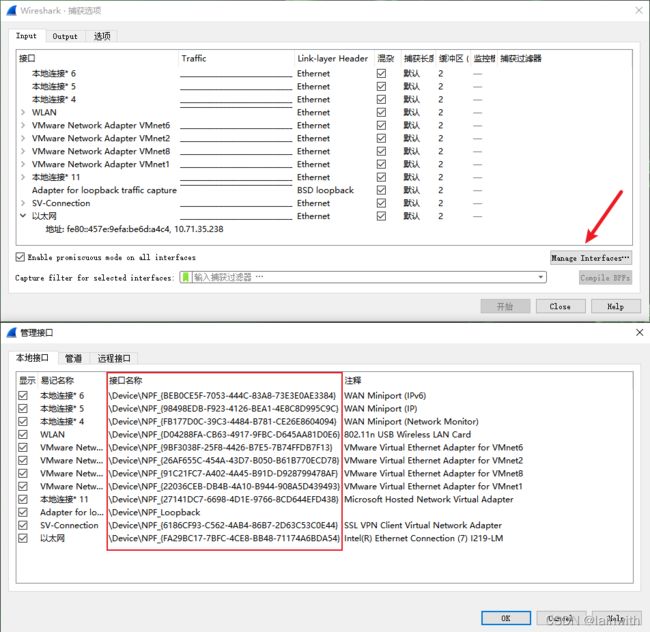
获取官方使用手册
方法1:tshark.exe -h
方法2:访问在线地址:tshark(1) Manual Page
方法3:帮助-说明文档-TShark(此处的说明文档与方法2的文档内容一致)
参数
1. 抓包接口类
-i 设置抓包的网络接口,不设置则默认为第一个非自环接口。
-D 列出当前存在的网络接口。在不了解OS所控制的网络设备时,一般先用“tshark -D”查看网络接口的编号以供-i参数使用。
-f 设定抓包过滤表达式(capture filter expression)。抓包过滤表达式的写法雷同于tcpdump,可参考tcpdump man page的有关部分。
-s 设置每个抓包的大小,默认为65535,多于这个大小的数据将不会被程序记入内存、写入文件。(这个参数相当于tcpdump的-s,tcpdump默认抓包的大小仅为68)
-p 设置网络接口以非混合模式工作,即只关心和本机有关的流量。
-B 设置内核缓冲区大小,仅对windows有效。
-y 设置抓包的数据链路层协议,不设置则默认为-L找到的第一个协议,局域网一般是EN10MB等。
-L 列出本机支持的数据链路层协议,供-y参数使用。
2. 抓包停止条件
-c 抓取的packet数,在处理一定数量的packet后,停止抓取,程序退出。
-a 设置tshark抓包停止向文件书写的条件,事实上是tshark在正常启动之后停止工作并返回的条件。条件写为test:value的形式,如“-a duration:5”表示tshark启动后在5秒内抓包然后停止;“-a filesize:10”表示tshark在输出文件达到10kB后停止;“-a files:n”表示tshark在写满n个文件后停止。(windows版的tshark0.99.3用参数“-a files:n”不起作用——会有无数多个文件生成。由于-b参数有自己的files参数,所谓“和-b的其它参数结合使用”无从说起。这也许是一个bug,或tshark的man page的书写有误。)
3. 文件输出控制
-b 设置ring buffer文件参数。ring buffer的文件名由-w参数决定。-b参数采用test:value的形式书写。“-b duration:5”表示每5秒写下一个ring buffer文件;“-b filesize:5”表示每达到5kB写下一个ring buffer文件;“-b files:7”表示ring buffer文件最多7个,周而复始地使用,如果这个参数不设定,tshark会将磁盘写满为止。
4. 文件输入
-r 设置tshark分析的输入文件。tshark既可以抓取分析即时的网络流量,又可以分析dump在文件中的数据。-r不能是命名管道和标准输入。
5. 处理类
-R 设置读取(显示)过滤表达式(read filter expression)。不符合此表达式的流量同样不会被写入文件。注意,读取(显示)过滤表达式的语法和底层相关的抓包过滤表达式语法不相同,它的语法表达要丰富得多,请参考http://www.ethereal.com/docs/dfref/和http://www.ethereal.com/docs/man-pages/ethereal-filter.4.html。类似于抓包过滤表达式,在命令行使用时最好将它们quote起来。
-n 禁止所有地址名字解析(默认为允许所有)。
-N 启用某一层的地址名字解析。“m”代表MAC层,“n”代表网络层,“t”代表传输层,“C”代表当前异步DNS查找。如果-n和-N参数同时存在,-n将被忽略。如果-n和-N参数都不写,则默认打开所有地址名字解析。
-d 将指定的数据按有关协议解包输出。如要将tcp 8888端口的流量按http解包,应该写为“-d tcp.port==8888,http”。注意选择子和解包协议之间不能留空格。
6. 输出类
-w 设置raw数据的输出文件。这个参数不设置,tshark将会把解码结果输出到stdout。“-w-”表示把raw输出到stdout。如果要把解码结果输出到文件,使用重定向“>”而不要-w参数。
-F 设置输出raw数据的格式,默认为libpcap。“tshark -F”会列出所有支持的raw格式。
-V 设置将解码结果的细节输出,否则解码结果仅显示一个packet一行的summary。
-x 设置在解码输出结果中,每个packet后面以HEX dump的方式显示具体数据。
-T 设置解码结果输出的格式,包括text,ps,psml和pdml,默认为text。
-t 设置解码结果的时间格式。“ad”表示带日期的绝对时间,“a”表示不带日期的绝对时间,“r”表示从第一个包到现在的相对时间,“d”表示两个相邻包之间的增量时间(delta)。
-S 在向raw文件输出的同时,将解码结果打印到控制台。
-l 在处理每个包时即时刷新输出。
-X 扩展项。
-q 设置安静的stdout输出(例如做统计时)
-z 设置统计参数。
7. 其它
-h 显示命令行帮助。
-v 显示tshark的版本信息。
-o 重载选项。
tshark与wireshark对比
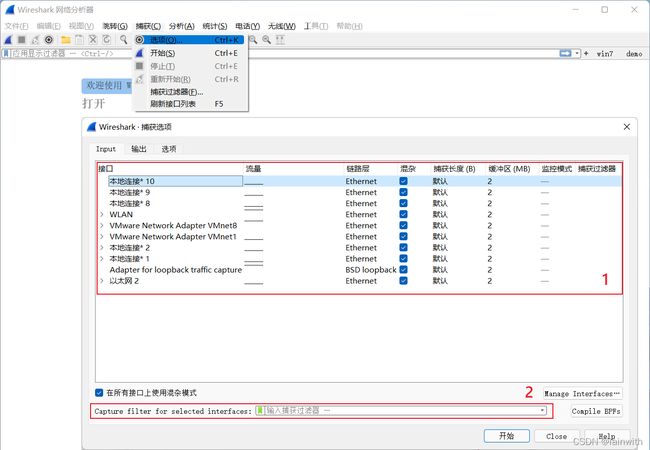
- 上图红框1中的接口,对应tshark中的
-i参数,表示需要捕获数据的网卡名称。 - 上图红框1中的链路层头类型对应tshark中的
-y参数,可以自行在GUI中设置。 - 上图红框1中的混杂对应tshark中的
-p参数,表示是否使用混杂模式。 - 上图红框1中的**捕获长度(snap长度)**对应
-s参数,设置每一片报文的最大捕获长度,我在这里有针对该字段的解释说明。 - 上图红框1中的缓冲区对应
-B参数,设置内核缓存的大小,默认2M。 - 上图红框1中的监控模式对应
-I参数。 - 上图红框1中的捕获过滤器对应
-f参数,这里。当然也可以在上图中的红框2设置捕获过滤器。 -D和-L表示打印接口名称和链路类型,是一些帮助型的参数,在不知道如何设置链路层头类型以及接口名称,可以通过该命令查看tshark -D或者thshark -L查看。
基本命令
获取数据包摘要信息
tshark.exe -r 源文件.pcap
tshark.exe -r 源文件.pcap -V # 获取更详细的内容,输出的内容很多
tshark.exe -r 源文件.pcap -c5 # 获取指定数量的内容

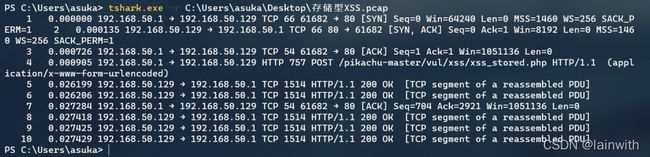
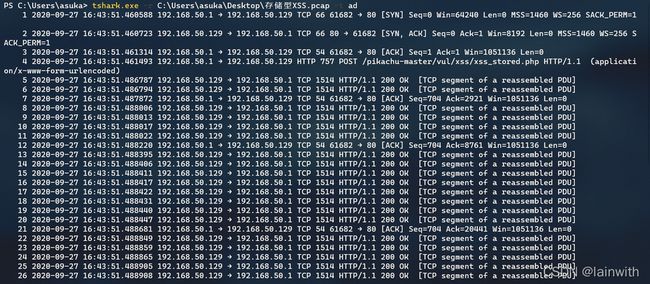
显示时间格式
tshark.exe -r 源文件.pcap -t ad
捕获过滤器
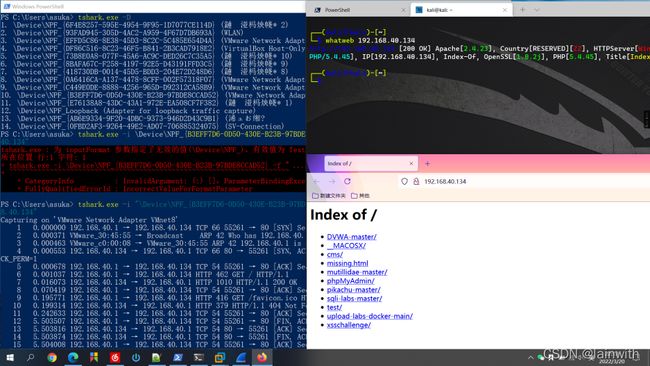
使用-D查看当前设备上有哪些网卡:
tshark.exe -D
设置过滤器(方法1):
-i用来指定网卡;-f设置捕获过滤器
tshark.exe -i "\Device\NPF_{B3EFF7D6-0D50-430E-B23B-97BDE8CCAD52}" -f "host 192.168.40.1 and host 192.168.40.134"
设置过滤器(方法2):
tshark.exe -i 10 -f "host 192.168.40.1 and host 192.168.40.134"
如下图所示,使用了捕获过滤器之后,捕获到的数据包只有192.168.40.1和192.168.40.134。
捕获并保存数据包
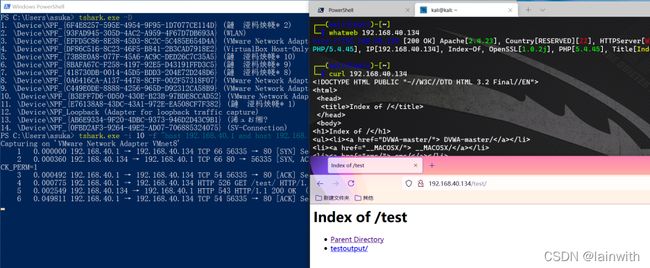
设置捕获数据包的大小约为3KB时停止抓包,并把结果保存下来。
tshark.exe -i 10 -f "host 192.168.40.1 and host 192.168.40.134" -a filesize:3 -w C:\Users\asuka\Desktop捕获.pcap
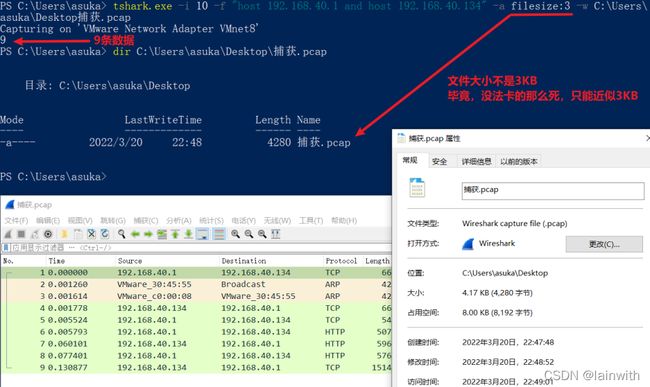
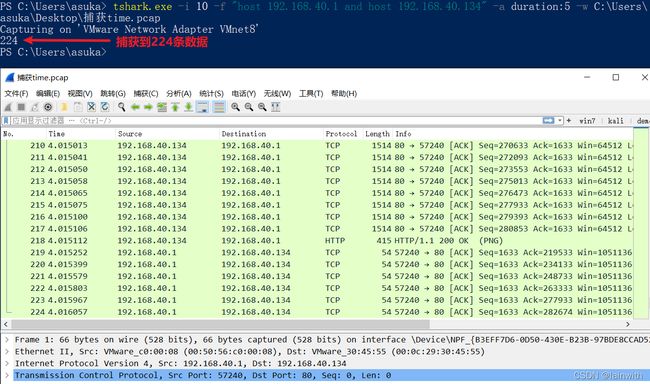
设置捕获数据包5秒时停止抓包,并把结果保存下来。但是有点懵,因为数据包中显示,只捕获了4秒左右。
tshark.exe -i 10 -f "host 192.168.40.1 and host 192.168.40.134" -a duration:5 -w C:\Users\asuka\Desktop\捕获time.pcap
显示过滤器
区分显示过滤器和读取过滤器
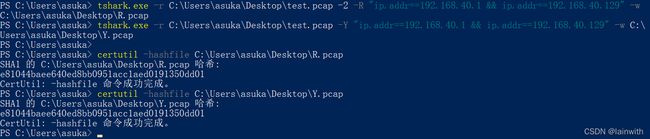
可以使用 -R 和 -Y 参数过滤数据包,在过滤出效果上略有不同之处。过滤结果导出的数据包是一致的。
根据tshark的帮助手册,暂时没太看懂-R参数和-Y参数的区别。根据手册的解释,-R是读取过滤器,-Y是显示过滤器,有点懵,只听说过捕获过滤器和显示过滤器,不知道这个读取过滤器是怎么个东东,在测试效果上如下图
tshark.exe -r C:\Users\asuka\Desktop\test.pcap -Y "ip.addr==192.168.40.1 && ip.addr==192.168.40.129"
tshark.exe -r C:\Users\asuka\Desktop\test.pcap -2 -R "ip.addr==192.168.40.1 && ip.addr==192.168.40.129"
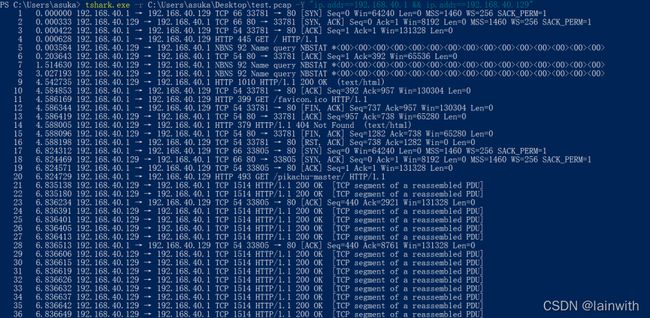
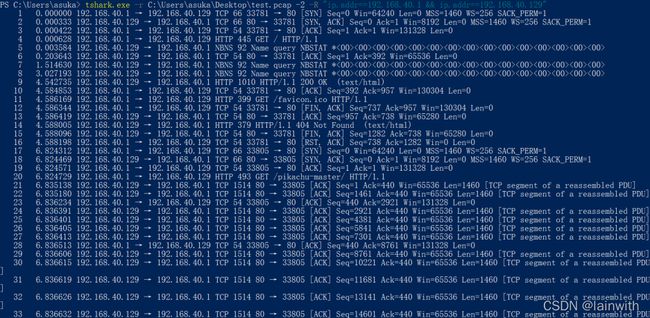
如果非要较真的话,使用文件对比工具,会发现在显示效果上还是略有不同的

那么,还有一个小小的疑问,如果我分别使用这两种方法读取数据包并把结果保存到新的数据包中,新的数据包会一样吗?经过测试,导出的文件是一致的。
一些好用的显示过滤器
http.host==magentonotes.com
http.host contains magentonotes.com
//过滤经过指定域名的http数据包,这里的host值不一定是请求中的域名
http.response.code==302
//过滤http响应状态码为302的数据包
http.response==1
//过滤所有的http响应包
http.request==1
//过滤所有的http请求,貌似也可以使用http.request
//测试显示,上面的2条命令和下面的3条命令是等价的(样本有限,未必准确):
//http.host and http.request.uri
//http.host
//http.request.uri
http.request.method==POST
//wireshark过滤所有请求方式为POST的http请求包,注意POST为大写
http.cookie contains guid
//过滤含有指定cookie的http数据包
http.request.uri==”/online/setpoint”
//过滤请求的uri,取值是域名后的部分
http.request.full_uri==” http://task.browser.360.cn/online/setpoint”
//过滤含域名的整个url则需要使用http.request.full_uri
http.server contains “nginx”
//过滤http头中server字段含有nginx字符的数据包
http.content_type == “text/html”
//过滤content_type是text/html的http响应、post包,即根据文件类型过滤http数据包
http.content_encoding == “gzip”
//过滤content_encoding是gzip的http包
http.transfer_encoding == “chunked”
//根据transfer_encoding过滤
http.content_length == 279
http.content_length_header == “279″
//根据content_length的数值过滤
http.server
//过滤所有含有http头中含有server字段的数据包
http.request.version == “HTTP/1.1″
//过滤HTTP/1.1版本的http包,包括请求和响应
http.response.phrase == “OK”
//过滤http响应中的phrase
-e参数的应用
使用-T参数可以把读取到的数据包以 ek|fields|json|jsonraw|pdml|ps|psml|tabs|text 格式输出,如果希望对输出结果进行更细腻的过滤,就可以使用-e参数。
HTTP中的应用案例
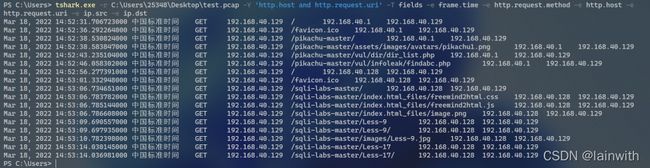
tshark.exe -r C:\Users\25348\Desktop\test.pcap -Y 'http.host and http.request.uri' -T fields -e frame.time -e http.request.method -e http.host -e http.request.uri -e ip.src -e ip.dst
- 使用过滤器,过滤出http请求的流量:
-Y 'http.host and http.request.uri'
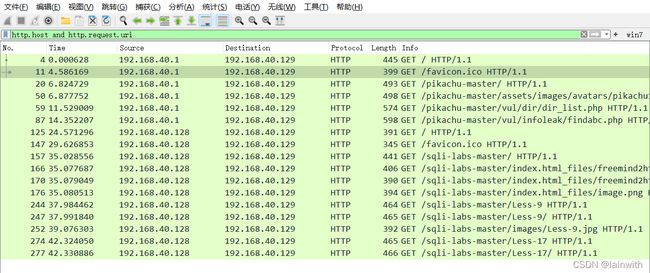
- 使用
-T fields查看解码数据包数据时输出的格式,把输出格式设置为fields,这样就可以借助-e参数实现更细腻的显示效果 - 使用命令:-e frame.time -e http.request.method -e http.host -e http.request.uri -e ip.src -e ip.dst
查看触发流量的时间,http的请求方法,web主机地址,请求的uri、请求ip地址、目的ip地址。
- 应用效果如下:
mysql中的应用案例
缺乏相关数据包,不做举例
tshark -i eth1 -d tcp.port==3306,mysql -T fields -e mysql.query 'port 3306'
tshark -i lo -d tcp.port==3306,mysql -T fields -e mysql.query 'port 3306'
指定类型
tshark -i lo -d tcp.port==3306,mysql -T fields -e mysql.query 'port 3306' -R 'mysql matches "SELECT|INSERT|DELETE|UPDATE"'
-z参数的应用
-z参数主要是关于各种统计的。当-z后面跟错误的参数的时候,会提示-z所能提供的功能。如下将介绍一些常见的基础参数。除了http协议之外,还提供了例如smb,dcerpc,icmp,sip等协议的统计展示,使用方法类似。
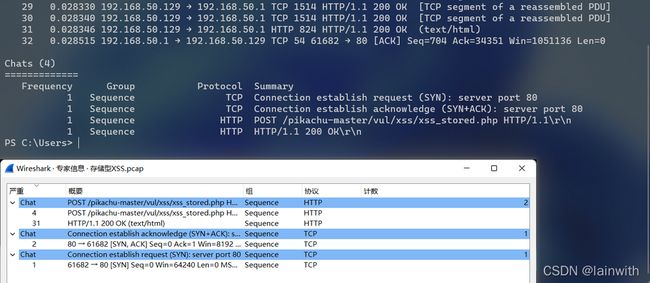
专家信息:-z expert
tshark.exe -r C:\Users\25348\Desktop\存储型XSS.pcap -z expert
追踪流:-z follow
在下文中有详细介绍,此处略过。
-z http
tshark.exe -r C:\Users\25348\Desktop\test.pcap -z http,stat -q
tshark.exe -r C:\Users\25348\Desktop\test.pcap -z http_req,tree -q
tshark.exe -r C:\Users\25348\Desktop\test.pcap -z http_srv,tree -q
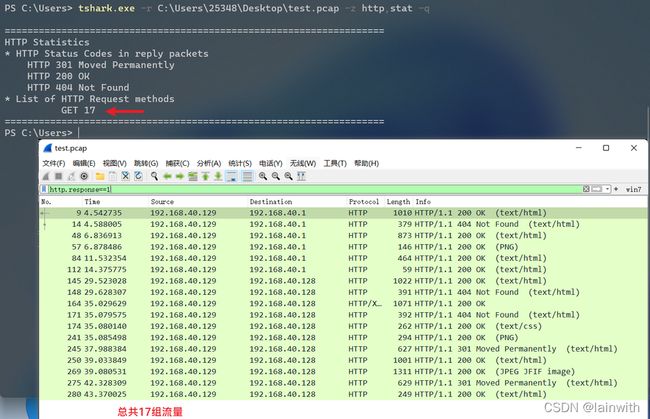
统计数据包信息
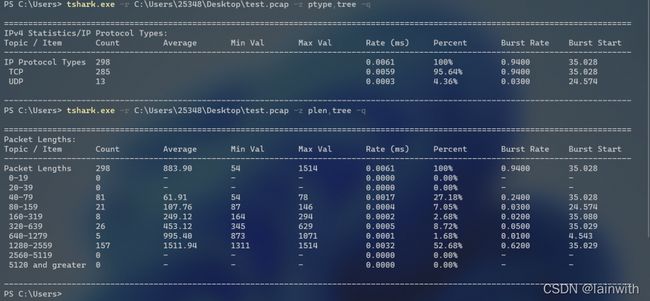
tshark.exe -r C:\Users\25348\Desktop\test.pcap -z ptype,tree -q
tshark.exe -r C:\Users\25348\Desktop\test.pcap -z plen,tree -q
统计会话
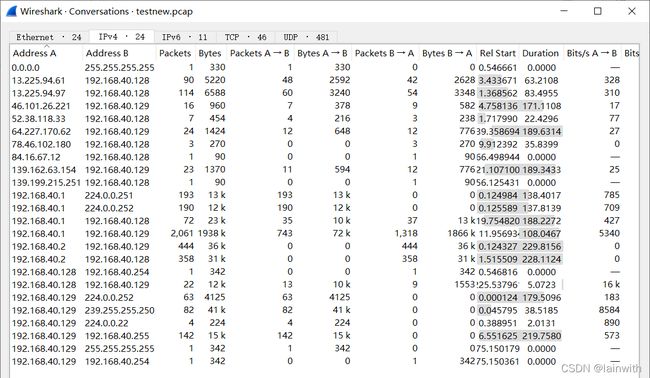
通过conv选项,可以查看wireshark中的统计->conversation选项。
工作中最常用的是统计数据包中有多少组ipv4会话,命令如下:
tshark.exe -r C:\Users\25348\Desktop\test.pcap -z conv,ip -q
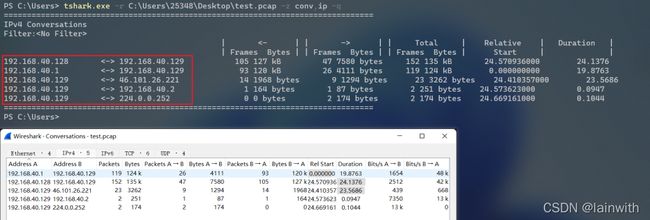
统计出所有IP
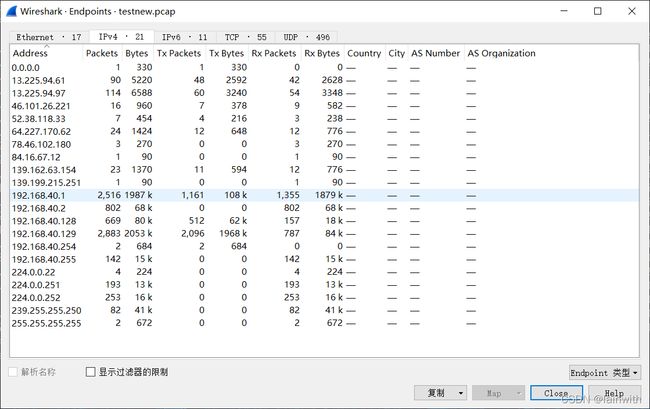
通过endpoints选项,可以查看wireshark中的统计->Endpoints选项。即:查看到数据包中总共涉及到了哪些IP
tshark.exe -r C:\Users\asuka\Desktop\testnew.pcap -z endpoints,ip -q
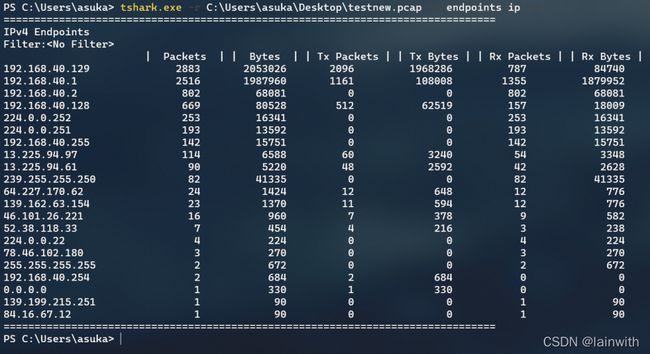
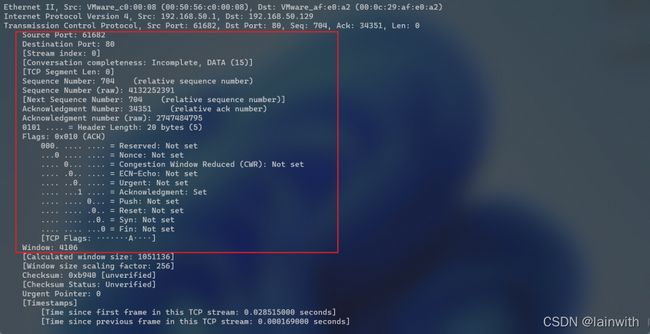
显示每个协议树的具体信息
用到了-O参数,后面跟上具体的协议表示只展开对应协议层的协议树,如果使用-V则默认展开所有的协议树。
tshark.exe -r C:\Users\25348\Desktop\存储型XSS.pcap -O tcp
数据包视图:

命令行视图:
导出对象
有的时候想要还原数据包中传输的文件,如下图是wireshark UI的操作:
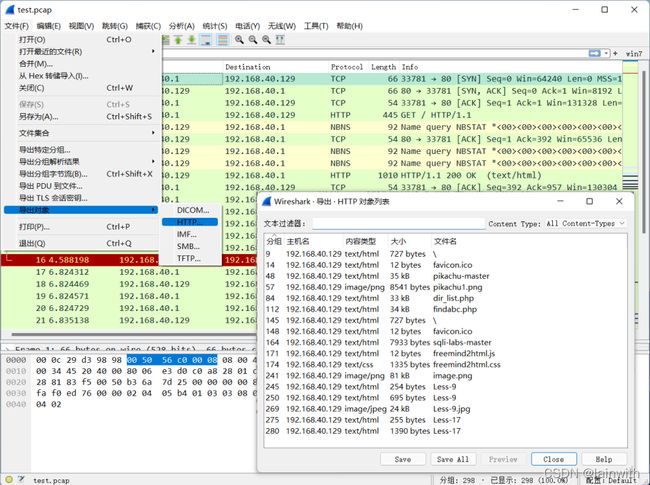
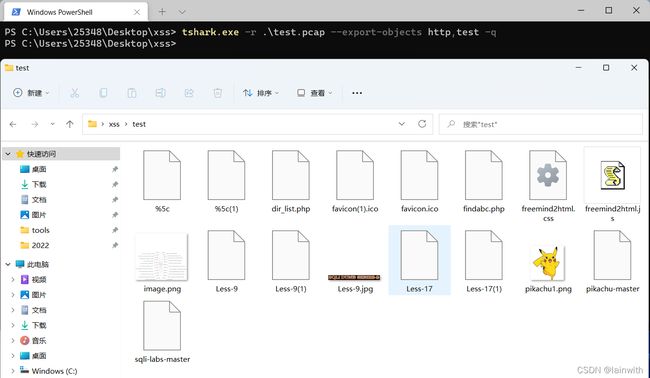
可以将HTTP协议请求中的文件存成指定的格式,该条操作对应的命令如下:
tshark.exe -r .\test.pcap --export-objects http,test -q
这样就会在tshark工作的目录中生成test文件夹,文件夹中会生成对应传输的数据,文件名为传输中指定的文件名。有的时候想要批量的提取数据包中的文件,可用这种方法进行操作。
追踪流
追踪tcp流/http流
不大清楚wireshark中追踪tcp流和http流有什么区别,从过往的经验中得知一下情况:
- 二者使用的过滤语法一致:
tcp.stream eq 0
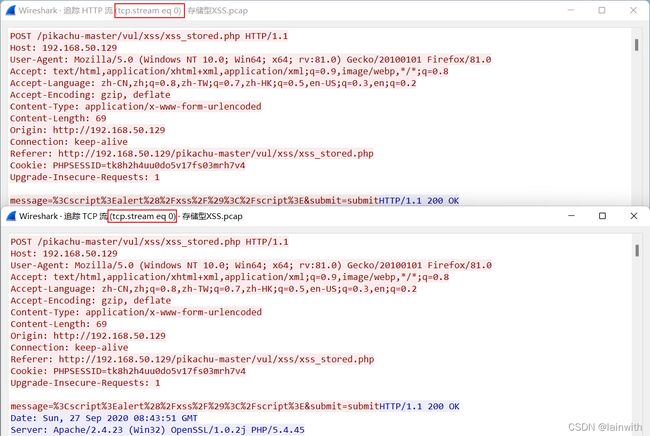
- 极少数的情况下,会出现tcp追踪流与http追踪流看到的内容不一样!遇到过,两种追踪流看到了两种可阅读的ascii码内容;两种追踪流,一种看到的是乱码,一种是可阅读的ascii码内容
追踪流数量
从下图中得知,此数据包共6个tcp追踪流(从0开始计算的)
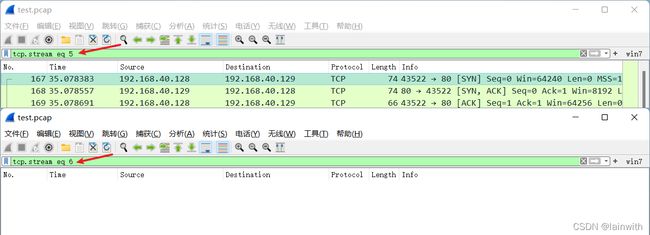
使用命令获知文件有多少个追踪流。运行命令后,终端会打印很多行,正序排序后,最后一位数字就是追踪流的数量(需要手工加1,因为追踪流是从0开始算的)
tshark.exe -r 源文件.pcap -Tfields -e tcp.stream
读取TCP流-纯16进制
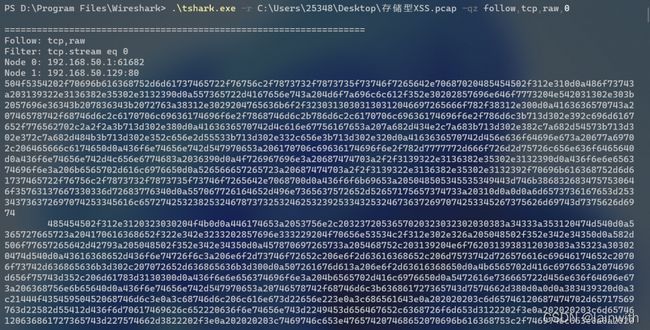
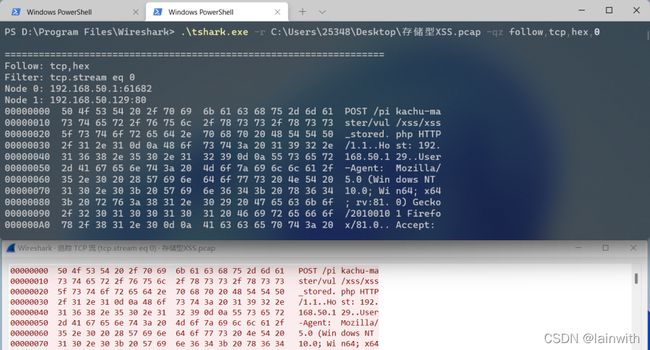
tshark -r 源文件.pcap -qz follow,tcp,raw,tcp流的编号
你可以使用重定向来获取结果到文本中。下面得到的就是16进制的追踪流内容。随便找个在线网站转码后即可阅读。
图中tcp表示的是协议,还可以是udp以及ssl等协议。tshark提供了按照hex,raw,ascii,ebcdic 等格式进行显示,可以根据需要进行使用,上图是按照raw格式进行显示,可以和UI中的功能操作对应起来的。其中的0表示流的编号,wireshark内部对于流的编号进行了处理,可以直接使用流编号进行过滤。该参数选项可以按照指定的格式进行输出。-x参数具有和hex选项同样的功能,只是-x参数会将应用层以下的所有信息都会输出。

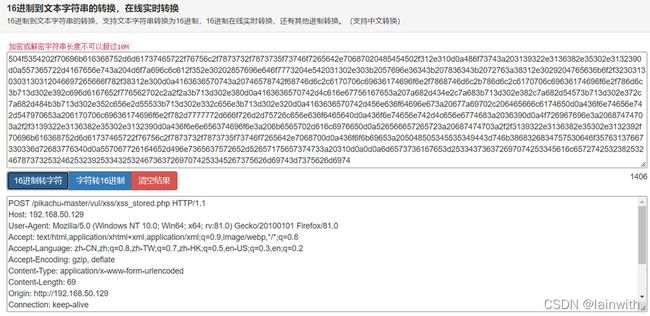
或者使用如下的python代码:
import base64
'''
批量把16进制转为ascii
'''
word = [] # 存储用户输入的内容
while True:
char = input()
char = char.strip()
if char == '':
continue
if 'quit' in char:
break
word.append(char)
for i in word:
try:
hex_str = i
a = str(base64.b16decode(hex_str.upper()))
b = a.replace(r"\r\n'", '').replace("b'", '').replace(r'\r\n', '\n') # 解码规范化之后的
print(b)
except Exception as e:
pass
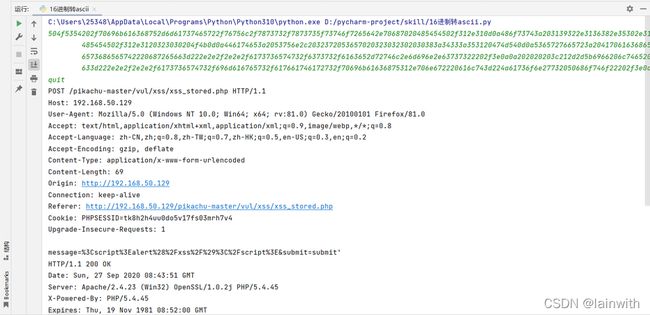
读取TCP流-16进制
tshark -r 源文件.pcap -qz follow,tcp,hex,tcp流的编号
可以说是经典还原了。
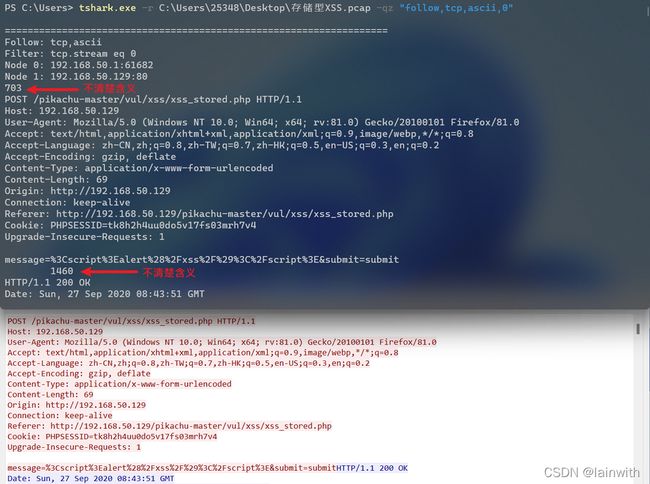
读取TCP流-ascii
tshark.exe -r C:\Users\25348\Desktop\存储型XSS.pcap -qz "follow,tcp,ascii,0"
获取TCP流,并保存为pcap文件
作用:类似于wireshark中导出特定分组。
执行下面的命令会发现,test.pcap 中第一个追踪流的内容(不止1个追踪流)和 22.pcap(只有一个追踪流)的内容完全一致。
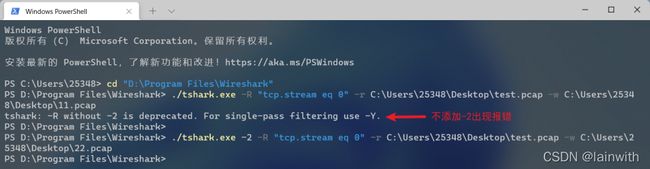
tshark -2 -R "tcp.stream eq 0" -r 源文件.pcap -w 目标文件名.pcap
注意:-R前面需要添加-2,否则会报错。-R后面跟的过滤规则其实就是wireshark里面写的过滤规则,这里tcp.stream eq 0表示第一个追踪流。
想一想,略加改动不就能拆分数据包了吗?使用如下命令,就实现了数据包拆分,新数据包只有一组会话!
tshark.exe -r C:\Users\25348\Desktop\test.pcap -2 -R "ip.addr==192.168.40.1 && ip.addr==192.168.40.129" -w C:\Users\25348\Desktop\win7.pcap

追踪udp流
方法同tcp流的处理方式,只不过把命令里面的所以“tcp”,改成“udp”
实战
1:统计出所有的会话IP组
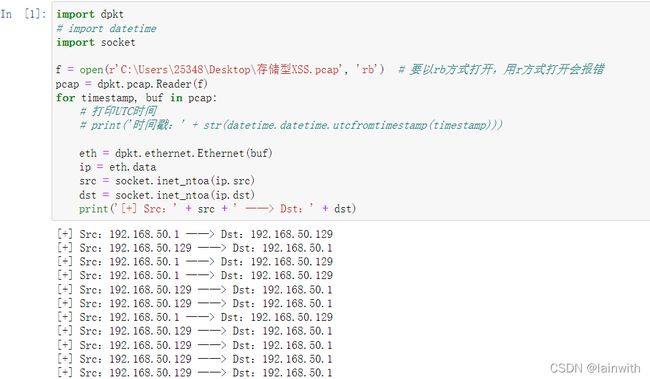
方法1:使用dpkt和socket模块
import dpkt
# import datetime
import socket
f = open(r'C:\Users\25348\Desktop\存储型XSS.pcap', 'rb') # 要以rb方式打开,用r方式打开会报错
pcap = dpkt.pcap.Reader(f)
for timestamp, buf in pcap:
# 打印UTC时间
# print('时间戳:' + str(datetime.datetime.utcfromtimestamp(timestamp)))
eth = dpkt.ethernet.Ethernet(buf)
ip = eth.data
src = socket.inet_ntoa(ip.src)
dst = socket.inet_ntoa(ip.dst)
print('[+] Src:' + src + ' ——> Dst:' + dst)
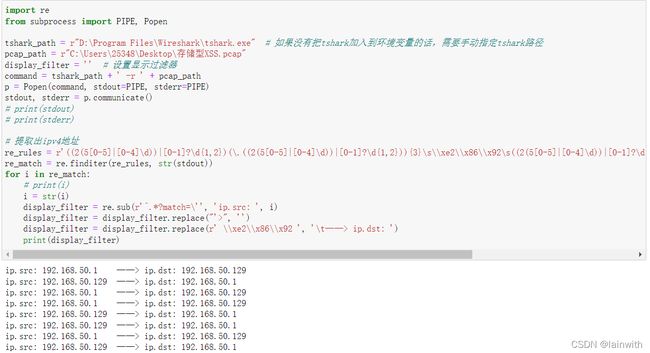
方法2:使用tshark
import re
from subprocess import PIPE, Popen
tshark_path = r"D:\Program Files\Wireshark\tshark.exe" # 如果没有把tshark加入到环境变量的话,需要手动指定tshark路径
pcap_path = r"C:\Users\25348\Desktop\存储型XSS.pcap"
display_filter = '' # 设置显示过滤
command = tshark_path + ' -r ' + pcap_path
p = Popen(command, stdout=PIPE, stderr=PIPE)
stdout, stderr = p.communicate()
# print(stdout)
# print(stderr)
# 提取出ipv4地址
re_rules = r'((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}\s\\xe2\\x86\\x92\s((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}'
re_match = re.finditer(re_rules, str(stdout))
for i in re_match:
# print(i)
i = str(i)
display_filter = re.sub(r'^.*?match=\'', 'ip.src: ', i)
display_filter = display_filter.replace("'>", '')
display_filter = display_filter.replace(r' \\xe2\\x86\\x92 ', '\t——> ip.dst: ')
print(display_filter)
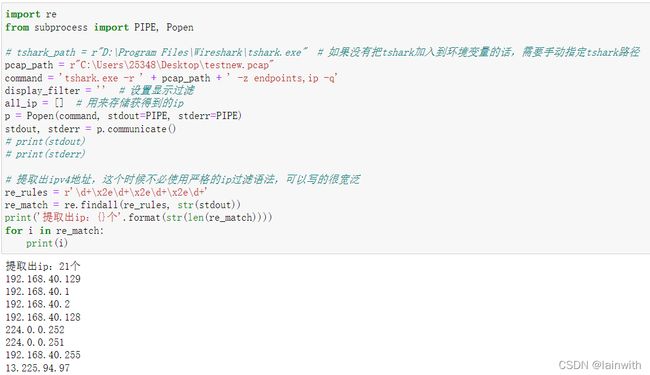
2:获取数据包中的所有IP
思路:通过endpoints选项,可以查看wireshark中的统计->Endpoints选项。即:查看到数据包中总共涉及到了哪些IP。
import re
from subprocess import PIPE, Popen
# tshark_path = r"D:\Program Files\Wireshark\tshark.exe" # 如果没有把tshark加入到环境变量的话,需要手动指定tshark路径
pcap_path = r"C:\Users\25348\Desktop\testnew.pcap"
command = 'tshark.exe -r ' + pcap_path + ' -z endpoints,ip -q'
display_filter = '' # 设置显示过滤
all_ip = [] # 用来存储获得到的ip
p = Popen(command, stdout=PIPE, stderr=PIPE)
stdout, stderr = p.communicate()
# print(stdout)
# print(stderr)
# 提取出ipv4地址,这个时候不必使用严格的ip过滤语法,可以写的很宽泛
re_rules = r'\d+\x2e\d+\x2e\d+\x2e\d+'
re_match = re.findall(re_rules, str(stdout))
print('提取出ip:{}个'.format(str(len(re_match))))
for i in re_match:
print(i)
威力加强版:获取指定文件夹下的所有数据包,并从中提取出所有去重后的IP
import re
from subprocess import PIPE, Popen
import os
from rich.progress import track
def get_ip(pcap_path, f):
command = 'tshark.exe -r ' + pcap_path + ' -z endpoints,ip -q'
p = Popen(command, stdout=PIPE, stderr=PIPE)
stdout, stderr = p.communicate()
# print(stdout)
# print(stderr)
# 提取出ipv4地址,这个时候不必使用严格的ip过滤语法,可以写的很宽泛
re_rules = r'\d+\x2e\d+\x2e\d+\x2e\d+'
re_match = re.findall(re_rules, str(stdout))
# print('数据包:'+f+',提取出ip:{}个'.format(str(len(re_match))))
for i in re_match:
# print(i)
if i not in all_ip:
all_ip.append(i)
path = input('请给我一个文件夹,我会获取所有数据包里面的所有IP:')
all_ip = [] # 用来存储所有捕获到的IP
for current_folder, list_folders, files in track(os.walk(path)):
for f in files: # 用来遍历所有的文件,只取文件名,不取路径名
if f.endswith('pcap') or f.endswith('pcapng'): # 判断文件是不是数据包
path_f = current_folder + '\\' + f # 给出数据包的的绝对路径
get_ip(path_f, f)
print('从所有数据包中提取出IP:{}个'.format(str(len(all_ip))))
for i in all_ip:
print(i)
# os.system('pause') # 在脚本中运行时可以删除此行
3:拆分数据包
目的:把一个数据包,根据一组IP拆分出一个数据包,如下图,根据24个ip组拆分出24个数据包
import re
from subprocess import PIPE, Popen
import os
'''
脚本功能: 把一个数据包根据会话ip进行拆分,得到仅包含一组会话ip的小数据包
注意事项:
1. 需要手动指定大数据包的路径
2. 需要手动指定存储小数据包的文件夹的路径
3. 需要把tshark加入到环境变量
'''
pcap_path = r"C:\Users\25348\Desktop\testnew.pcap" # 指定数据包的路径
save_pcap_path = r"C:\Users\25348\Desktop\test" # 用来保存拆分出来的小包
ip_list = [] # 用来存储ip组
command = 'tshark.exe -r ' + pcap_path + ' -z conv,ip -q'
p = Popen(command, stdout=PIPE, stderr=PIPE)
stdout, stderr = p.communicate()
# print(stdout)
# print(stderr)
# 提取出ipv4地址,这个时候不必使用严格的ip过滤语法,可以写的很宽泛
re_rules = r'\d+\x2e\d+\x2e\d+\x2e\d+\s+<->\s+\d+\x2e\d+\x2e\d+\x2e\d+'
re_match = re.finditer(re_rules, str(stdout))
for i in re_match:
# print(i)
i = str(i)
display_filter = re.sub(r'^.*?match=\'', 'ip.addr==', i)
display_filter = re.sub(r'\s+<->\s+', ' && ip.addr==', display_filter)
display_filter = display_filter.replace("'>", '')
# print(display_filter)
ip_list.append(display_filter)
print('[+] 检测到{}组会话,预计导出{}个数据包'.format(str(len(ip_list)), str(len(ip_list))))
print('[+] 开始拆分数据包……')
# 开始拆包
count = 1 # 用来实现进度条的功能
warning_pcap = 0 # 用来记录异常的拆包
for i in ip_list:
ii = i.replace('ip.addr==', '').replace(' && ', 'to') # 修改保存的数据包的文件名
ii = ii + '.pcap'
ii_path = os.path.join(save_pcap_path, ii) # 拼接出保存的数据包的绝对路径
command1 = 'tshark.exe -r ' + pcap_path + ' -Y "' + i + '"' + ' -w ' + ii_path
# print(command1)
p1 = Popen(command1, stdout=PIPE, stderr=PIPE)
stdout1, stderr1 = p1.communicate()
# print(stdout1)
# print(stderr1)
if len(stderr1) == 0:
print("[正常] 完成进度: {}\t导出第{}个数据包: {}".format("%.2f%%" % (count / len(ip_list) * 100), str(count), ii))
else:
warning_pcap = warning_pcap + 1
print("[异常] 完成进度: {}\t导出第{}个数据包异常: {}\t异常信息{}".format("%.2f%%" % (count / len(ip_list) * 100), str(count), ii, str(stderr1)))
count = count + 1
print('[+] 数据包全部拆分完毕!')
if warning_pcap > 0:
print('[+] 警告,发现{}条异常拆包信息'.format(str(warning_pcap)))

4:批量开发IPS规则
使用的样本(删除pdf后缀解压即可):【禁止对外提供】
假设拿到的数据包如下图,开发规则的话显然就是根据16进制编写,自动化的思路就是读取数据包的16进制内容,然后转换为规则。由于这种工作量分到一个人手里也就百十条数据包,而一个数据包一般都是2kb左右的,因此脚本怎么写都行,不用在意性能、效率的问题。样本有限,只开发了针对tcp的脚本。
开发的脚本针对的是如下图这种流量,用到的命令其实就是使用上文提到的“读取TCP流-纯16进制”,只不过这里借助python实现了一个自动化的效果,这种脚本的常见应用场景是固网等项目支撑,可以根据实际情况调整脚本内容。

import re
from subprocess import PIPE, Popen
import os
import csv
def work(f, pcap_path, rules_name_id):
# 1:读取数据包
command = 'tshark.exe -r "' + pcap_path + '" -qz follow,tcp,raw,0' # 一般只有1个追踪流,此处我只提取tcp流
# print(command)
p = Popen(command, stdout=PIPE, stderr=PIPE)
stdout, stderr = p.communicate()
# print(stdout)
# print(stderr)
# 2:提取出读取到的16进制内容
regex = r"\\r\\n\w+\\r\\n" # 编写提取出16进制负载的正则过滤器,面对不同项目支撑时需要调整此内容
original_hex = re.findall(regex, str(stdout))
# 少数情况下,一条数据流里面可能出现多个http会话(可能一组访问网站,一组访问ico图标),因此选择original_hex[0],具体情况具体分析,一般项目支撑的只有一个追踪流(只包含一组会话)
choice_hex = original_hex[0].replace('\\r\\n', '')
# 3:封装规则
# 封装16进制字符
change_hex = re.findall(".{2}", choice_hex)
need_hex = " ".join(change_hex)
# 封装规则
snort_rule = 'alert tcp any any -> any any (msg:"' + rules_name_id + '''"; flow:to_server; content:"|''' + need_hex + '|"; metadata:service http; sid:' + rules_name_id + '; rev:1;)'
# return snort_rule
print(f + ':\t' + snort_rule)
write.writerow([f, snort_rule])
if __name__ == '__main__':
print('''
脚本功能: 批量开发IPS规则
注意事项:
1. 需要把tshark加入到环境变量
2. 此脚本是提取tcp追踪流中第一段内容的16进制,进而封装的规则
3. 脚本会穿透指定文件夹下的所有文件,获取出所有数据包(pcap和pcapng后缀)的绝对路径
''')
files_path = input('请输入数据包所在文件夹:')
rules_path = os.path.join(files_path, '规则信息.csv') # 给出csv格式的结果,方便展示
file = open(rules_path, 'w', newline='') # 创建并打开CSV文件
write = csv.writer(file)
write.writerow(['数据包名字', '规则内容'])
rules_name_id = 0 # 规则的名字和id号递增
for current_folder, list_folders, files in os.walk(files_path):
for f in files: # 用来遍历所有的文件,只取文件名,不取路径名
if f.endswith('pcap') or f.endswith('pcapng'): # 操作数据包
file_path = current_folder + '\\' + f # 获取数据包的绝对路径
rules_name_id = rules_name_id + 1
rules_name_id1 = str(rules_name_id)
work(f, file_path, rules_name_id1)
file.close()
print('规则开发完成,请查收导出的结果文件')
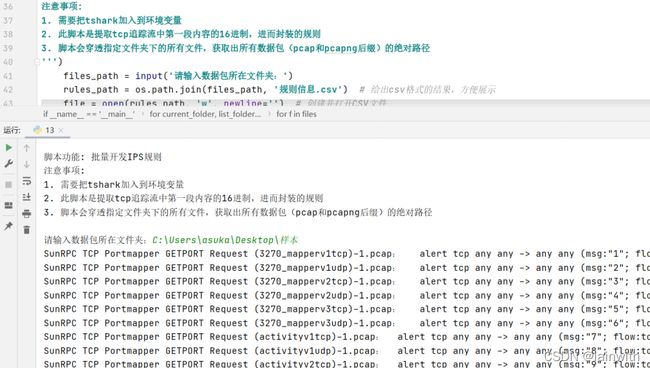
批量测试一下,snort全部告警!

5: 基于流量分析IPS告警&误报
https://blog.csdn.net/weixin_44288604/article/details/124501085
参考
tshark linux 命令 在线中文手册
tshark 使用技巧
[centos7][nginx][tshark] 基于 tshark 的页面流量统计
tshark(1) Manual Page
python实现——windows下批量抓包
WireShark 过滤http请求
wireshark图形操作对应的命令行操作