Zookeeper初识
序
Zookeeper是什么,Zookeeper有什么用?因为在研究Zookeeper源码之后,就要去研究Dubbo源码,而Dubbo必然用到了Zookeeper,而我在写这篇博客时,我也是一个Zookeeper小白,我也有7年开发经验了,对于一门技术,如果只会简单的使用,已经满足不了我了,而框架的内部实现原理才深深吸引我的地方,如果要研究一套源码,首先是对他的理论知识有大概的了解,然后通过理论知识的引导,写一些例子,以例子为引,进入源码内部分析,理论和源码知识是相辅相成的, 如果只看理论,你可能容易忘记,并且你自己都不敢相信这些知识是真的,如果一开始就打断点调试,你肯定是从入门到放弃,进入源码的深入,没有理论的引导,你可能需要很长的时间或者你根本猜不透代码的用意,因此研究源码的过程,先看理论,再通过例子证实理论,只有这样反复折腾,最后,你对源码的理解就变得通达,因此这篇博客主要是对Zookeeper理论的研究,以及基本的使用,撑握了这些以后,下一篇博客,我们将研究Zookeeper源码了。 当然很多的理论知识都来自于图灵学院 ,当然,还是那句话,如果你觉得自己无法突破,可以去网上找一套视频或者去报个培训班都可以,当然这些视频都只是开阔你的视野,同时让你将时间花在学习上,而真正的成就还是在自己的学习上,就像我们高中,为什么一样的老师,一样的学习环境,为什么有些人考重本,而有些人二本都没有考上呢? 原因就是“师傅引进门,修行在个人”,你去学习一套视频,如果只是看完了,老师说完,你当时感动得不行不行的,但没有自己去研究一番,那你也是不会的,只有自己去研究了,并且得到从老师那多得多的东西,对一套源码自成体系,你的技能才会有所突破,不然,你总会徘徊在之前学习过的知识上,一本书永远前面几十页都翻烂了,但后面都是新的,Spring源码学习了十来遍,依然觉得自己不懂Spring源码,这都是你没有系统的去学习研究所致。废话不多说,先来看Zookeeper的理论及实践知识 。
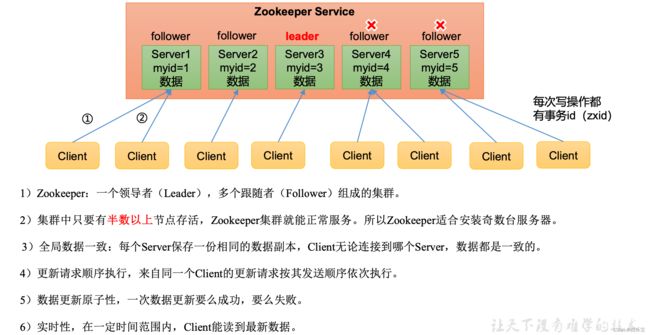
Zookeeper工作机制
Zookeeper从设计模式上来理解
Zookeeper是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生了变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
Zookeeper特点
- 什么是Zookeeper?
ZooKeeper 是一个开源的分布式协调框架,是Apache Hadoop 的一个子项目,主要用来解决分布式集群中应用系统的一致性问题。Zookeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
官方:https://zookeeper.apache.org/
ZooKeeper本质上是一个分布式的小文件存储系统(Zookeeper=文件系统+监听机制)。提供基于类似于文件系统的目录树方式的数据存储,并且可以对树中的节点进行有效管理,从而用来维护和监控存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理、统一命名服务、分布式配置管理、分布式消息队列、分布式锁、分布式协调等功能。
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper 就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。

Zookeeper实战
Zookeeper安装
下载地址:https://zookeeper.apache.org/releases.html
运行环境:jdk8
- 修改配置文件
解压安装包后进入conf目录,复制zoo_sample.cfg,修改为zoo.cfg
# cp zoo_sample.cfg zoo.cfg
修改 zoo.cfg 配置文件,将 dataDir=/tmp/zookeeper 修改为指定的data目录
zoo.cfg中参数含义:
# zookeeper 通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
tickTime=2000

#允许follower初始化连接到leader最大时长,它表示tickTime时间倍数,即:initLimit*tickTime
initLimit=10

# 允许follower与leader数据同步最大时长 , 它表示tickTime时间倍数。
syncLimit=5

# zookeper数据存储目录及日志保存目录(如果没有指明dataLogDir,则日志也保存在这个文件中)
dataDir=/tmp/zookeeper

# 对客户端提供的端口号。
clientPort=2181

# 单个客户端与zookeeper最大并发连接数。
maxClientCnxns=60
#保存的数据快照数量,之外的将会被清除 。
autopurgesnapRetainCount=3
#自动触发清除任务时间间隔,小时为单位, 默认为0 , 表示不自动清除 。
autopurge.purgeInterval=1
- 启动zookeeper server
# 可以通过bin/zkServer.sh 来查看都支持哪此参数
# 默认加载配置的路径为conf/zoo.cfg
bin/zkServer.sh start conf/zoo.cfg
# 查看zookeeper状态
bin/zkServer.sh status
- 启动zookeeper client 连接Zookeeper server
bin/zkCli.sh
# 连接远程的zookeeper server
bin/zkCli.sh -server ip:port
客户端命令行的操作
输入命令help 查看zookeeper支持所有的命令

常见的cli命令
https://zookeeper.apache.org/doc/r3.8.0/zookeeperCLI.html
| 命令的基本用法 | 功能描述 |
|---|---|
| help | 显示所有的操作命令 |
| ls [-s] [-w] [-R] path | 使用ls命令来查看当前znode的子节点[可监听] -w 监听子节点的变化 , -s 节点状态信息(时间戳,版本号,数据大小等) ,-R 表示递归的获取 |
| create [-s][-e][-c][-t ttl] path [data][acl] | 创建节点 ,-s : 创建有序节点, -e : 创建临时节点,-c 创建一个容器节点 , t ttl] : 创建一个TTL节点,-t 时间(单位毫秒),data :节点的数据,可选, 如果不使用时,节点数据就是null ,acl:访问控制 |
| get[-s][-w] path | 获取节点的数据信息,-s : 节点状态信息 时间戳 版本号,数据大小等, -w :监听节点变化 |
| set[-s][-v version] path data | 设置节点数据 ,-s 表示点为顺序节点 -v ,指定版本号 |
| getAcl[-s] path | 获取节点访问控制信息, -s 节点状态信息, 时间戳,版本号, 数据大小等 |
| setAcl [-s] [-v version] [-R ] path acl | 设置节点访问控制列表 , -s 节点状态信息,时间戳, 版本号, 数据大小 等,-v 指定版本号, -R 递归的设置 |
| stat [-w ] path | 查看节点状态信息 |
| delete [-v version] path | 删除某一个节点,只能删除无子节点的节点,-v 表示节点的版本号 |
| deleteall path | 递归删除某一个节点及其子节点 |
| setquota -n | -b val path | 对节点增加限制 , n 表示子节点的最大个数 , b 数据值的最大长度 , -1 表示无限制 |
Zookeeper核心概念
上面的解释还是有点抽象的, 暂时可以理解为Zookeeper是一个用于存储少量数据的基于内存数据库,主要有如下的两个核心概念, 文件系统数据结构,监听通知机制 。
文件系统数据结构
Zookeeper维护一个类似文件系统的数据结构

每个子目录项都被称为znode(目录节点),和文件系统类似,我们能够自由的增加,删除znode,在一个znode下增加,删除子znode 。
ZooKeeper的数据模型是层次模型 , 层次模型常见于文件系统,层次模型和key-value模型是两种主流的数据模型,Zookeeper使用文件系统模型主要是基于以下两点考虑。
- 文件系统的权形结构便于表达数据之间的层次关系 。
- 文件系统的树形结构便于为不同的应用分配独立的命名空间(namespace)
Zookeeper 的层次模型称为Data Tree ,Data Tree 的每个节点叫作Znode ,不同于文件系统 , 每个节点都可以保存数据,每一个节点ZNode默认能够存储1MB的数据, 每个ZNode都可以通过其路径唯一标识,每个节点都有一个版本(version) ,版本号从0开始计数。
public class DataTree {
private final ConcurrentHashMap nodes =
new ConcurrentHashMap();
private final WatchManager dataWatches = new WatchManager();
private final WatchManager childWatches = new WatchManager();
}
public class DataNode implements Record {
byte data[];
Long acl;
public StatPersisted stat;
private Set children = null;
}
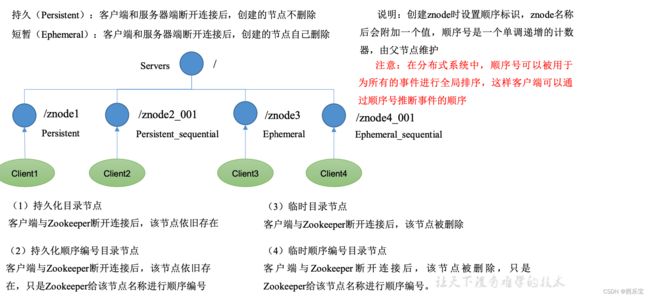
节点分类
zookeeper主要用到的是以上4种节点。
一个znode可以使持久性, 也可以是临时性的。
- 持久节点(PERSISTENT) : 这样的znode在创建之后即使发生Zookeeper集群宕机或者client宕机也不会丢失 。
- 临时节点(EPHEMERAL ): client宕机或者client在指定的timeout时间内没有给ZooKeeper集群发消息,这样的znode就会消失。
如果上面两种znode具备顺序性,又有以下两种znode :
- 持久顺序节点(PERSISTENT_SEQUENTIAL) : znode除了具备持久性znode的特点之外,znode的名字具备顺序性。
- 临时顺序节点(EPHEMERAL_SEQUENTIAL): znode除了具备临时性znode的特点之外,zorde的名字具备顺序性。
- Container节点(3.5.3 版本后新增,如果Container节点下面没有子节点,则Container节点在未来被Zookeeper自动清除,定时任务默认为60s 检查一次) 。和持久节点的区别是 ZK 服务端启动后,会有一个单独的线程去扫描,所有的容器节点,当发现容器节点的子节点数量为 0 时,会自动删除该节点。可以用于 leader 或者锁的场景中。
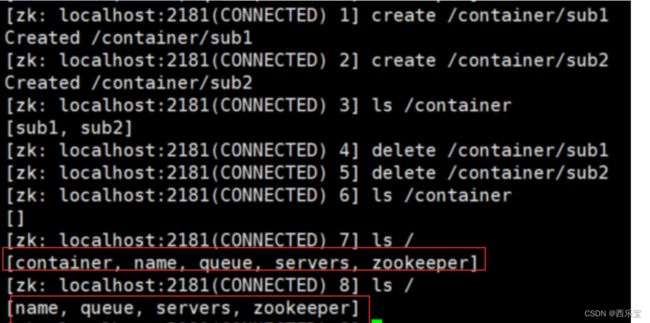
- TLL节点(默认禁用,只能通过系统配置, zookeeper.exetendedTypesEnabled=true开启),不稳定 注意:ttl不能用于临时节点

# 创建持久节点
create /servers xxx
# 创建临时节点
create -e /servers/host xxx
# 创建临时有序节点
create -e -s /servers/host xxx
# 创建容器节点
create -c /container xxx
# 创建ttl节点
create -t 10 /ttl
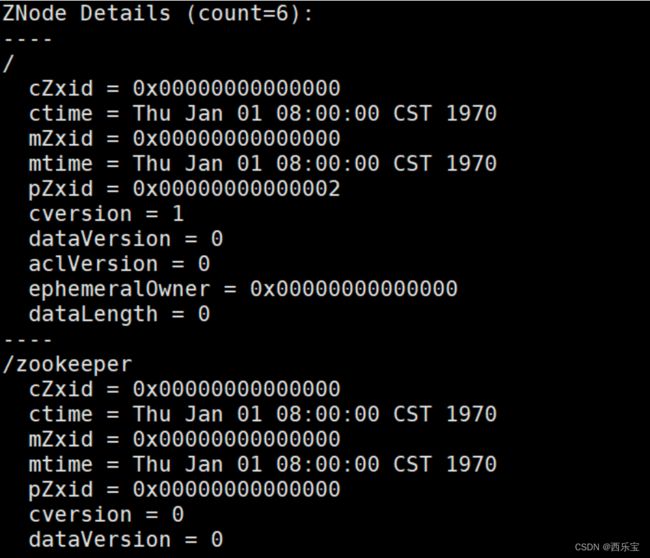
节点状态信息查看
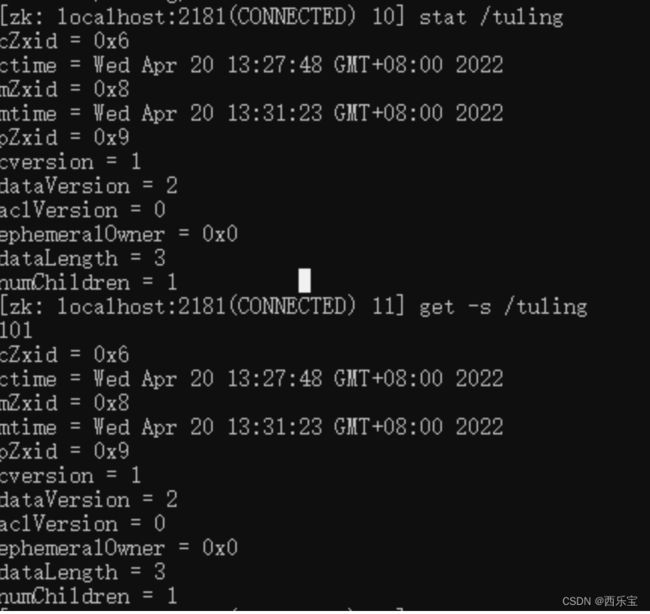
- cZid : Znode创建事务的id。
- ctime : 节点创建的时间戳
- mZxid : Znode 被修改的事务id, 即每次znode的修改都会更新mZxid。
对于zk来说,每次的变化都会产生一个唯一的事务id,zxid(ZooKeeper Transaction Id),通过zxid,可以确定更新操作的先后顺序。例如,如果zxid1小于zxid2,说明zxid1操作先于zxid2发生,zxid对于整个zk都是唯一的,即使操作的是不同的znode。
- pZxid: 表示该节点的子节点列表最后一次修改的事务ID,添加子节点或删除子节点就会影响子节点列表,但是修改子节点的数据内容则不影响该ID(注意: 只有子节点列表变更了才会变更pzxid,子节点内容变更不会影响pzxid)
- mtime: 节点最新一次更新发生的时间戳
- cversion: 子节点的版本号,当znode的子节点有变化时, cversion 的值就会增加1 。
- dataVersion: 数据版本号 , 每次对节点进行set操作时,dataVersion的值都会增加1,即使设置的是相同的数据,有效避免了数据更新时出现的先后顺序问题。
- ephemeralOwner:如果该节点为临时节点,ephemeralOwner 的值表示该节点绑定的session id ,如果不是 , ephemeralOwner 的值为0 ,持久节点 。
在client和server通信之前,首先需要建立连接,该连接为session,连接建立后,如果发生连接超时,授权失败,或者显式关闭连接,连接便于处理closed状态,此时session结束 。
- dataLength : 数据的长度
- numChildren : 子节点的数量(只统计直接子节点的数量)
监听通向机制
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、节点删除、子目 录节点增加删除)时,ZooKeeper 会通知客户端。监听机制保证 ZooKeeper 保存的任何的数 据的任何改变都能快速的响应到监听了该节点的应用程序。
监听器原理

客户端注册监听它关心的任意节点,或者目录节点及递归子目录节点 。
- 如果注册的是对某个节点的监听,则当这个节点被删除,或者被修改时, 对应的客户端将被通知 。
- 如果注册的是某个目录的监听 , 则当这个目录有子节点被创建,或者有子节点被删除,对应的客户端将被通知 。
- 如果注册的是对某个目录递归子节点进行监听,则当这个目录下面的任意子节点有目录结构的变化(有子节点被创建或被删除 ), 或者根节点有数据变化时, 对应的客户端将被通知 。
注意 : 所有的通知都是一次性的, 及无论是对节点还是对目录进行监听 , 一旦触发,对应的监听即被移除,递归子节点,监听是对所有的子节点,所以,每个子节点下面的事件同样只会被触发一次。
一个Watch事件是一个一次性的触发器,当被设置了Watch的数据发生改变时,则服务器将这个改变发送给设置了Watch的客户端,以便通知他们 。
- Zookeeper采用了Watcher机制实现了数据的发布和订阅, 多个订阅者可以同时监听某一个特定的主题,当该主题对象的自身状态发生变化时,例如节点内容改变,节点下的子节点列表改变,会实时,主动通知所有的订阅者 。
- watcher 机制事件上与观察者模式类似 ,也可以看作是一种观察者模式在分布式场景下的实现方式 。
watcher 的过程
- 客户端向服务端注册了watcher
- 服务端事件发生触发watcher
- 客户端回调watcher 得到触发的事件情况
注意 : Zookeeper 中的watch机制,必须客户端先去服务器注册监听 , 这样事件发送才会触发监听。 通知客户端 。
Zookeeper事件类型
- None: 连接建立事件
- NodeCreated : 节点创建
- NodeDeleted : 节点删除
- NodeDataChanged : 节点数据变化
- NodeChildrenChanged: 节点列表变化
- DataWatchRemoved :节点监听被移除
- ChildWatchRemoved : 节点监听被移除
| 特性 | 说明 |
|---|---|
| 一次性触发 | watcher是一次性的, 一旦触发就会被移除,再次使用时需要重新注册 |
| 客户端顺序回调 | watcher 回调是顺序串行执行的, 只有回调后客户端才能看到最新的数据状态 , 一个watcher回调逻辑不应该太多 , 以免影响到另的watcher执行 |
| 轻量级 | WatcherEvent是最小的通信单位 , 结构上只包含了通知状态 , 事件类型和节点路径,并不会告诉数据节点变化前后的具体内容 |
| 时效性 | watcher只有在当前session彻底失效时才会无效, 若在session有效期内快速重连成功,则watcher依然存在,仍然可以接收到通知 |


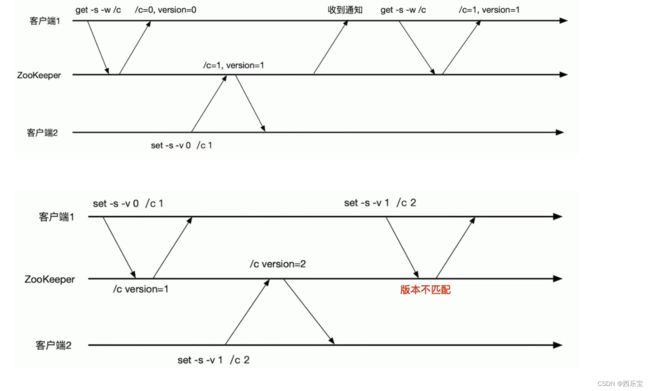
使用场景——条件更新
设想用2/c实现一个counter,使用set命令来实现自增1操作。条件更新场景∶
- 客户端1把/c更新到版本1,实现/c的自增1。
- 客户端2把/c更新到版本2,实现/c的自增1。
- 客户端1不知道/c已经被客户端⒉更新过了,还用过时的版本1是去更新/c,更新失败。如果客户端1使用的是无条件更新,/c就会更新为2,没有实现自增1。
使用条件更新可以避免出现客户端基于过期的数据进行数据更新的操作。
Zookeeper 节点特性总结
-
同一级节点 key 名称是唯一的

已存在/lock节点,再次创建会提示已经存在 -
创建节点时,必须要带上全路径
-
session 关闭,临时节点清除
-
自动创建顺序节点

-
watch 机制,监听节点变化
事件监听机制类似于观察者模式,watch 流程是客户端向服务端某个节点路径上注册一个 watcher,同时客户端也会存储特定的 watcher,当节点数据或子节点发生变化时,服务端通知客户端,客户端进行回调处理。特别注意:监听事件被单次触发后,事件就失效了。 -
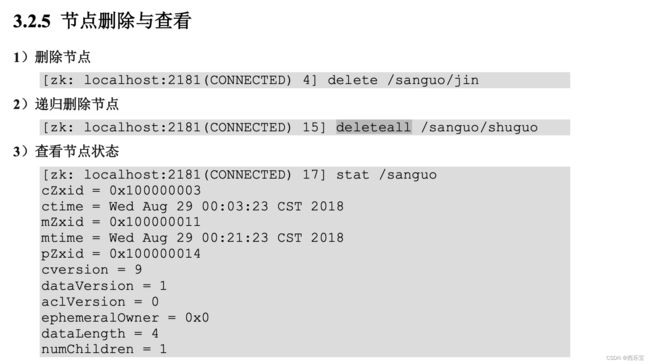
delete 命令只能一层一层删除。提示:新版本可以通过 deleteall 命令递归删除。
统一命名服务
在分布式环境下,经常需要对应用/服务进行统一命名, 便于识别。
例如 :IP不容易记住, 而域名容易记住

利用Zookeeper顺序节点的特性, 制作分布式序列号的生成器, 或者叫id生成器(分布式环境下使用作为数据库id ,另外一种是UUID ,缺点(没有规律) ,Zookeeper可以生成顺序的容易理解的同时支持分布式环境的编号 )。
服务器动态上下线

软负载均衡
数据发布/订阅
数据发布/订阅是一个常见的场景是配置中心, 发布者可以把数据发布到Zookeeper一个或一系列的节点上供订阅者进行数据订阅, 达到动态获取数据的目的 。
配置信息一般有几个特点 。
- 数据量小的KV
- 数据内容在运行时发生动态变化 。
- 集群机器共享 , 配置一致
Zookeeper采用的是推拉式结合的方式 。
- 推: 服务端会推给注册了监控节点的客户端Watcher事件通知 。
- 拉, 客户端获得通知后, 然后主动到服务端拉取最新的数据 。

统一集群管理
分布式环境中, 实时掌握每一个节点的状态是必要的, 可以根据节点实时状态做出一些调整。 Zookeeper可以实现实时监控节点的状态变化 。
- 可以将节点信息写入到ZooKeeper上的Znode .
- 监听这个ZNode 可获取它的实时状态变化 。

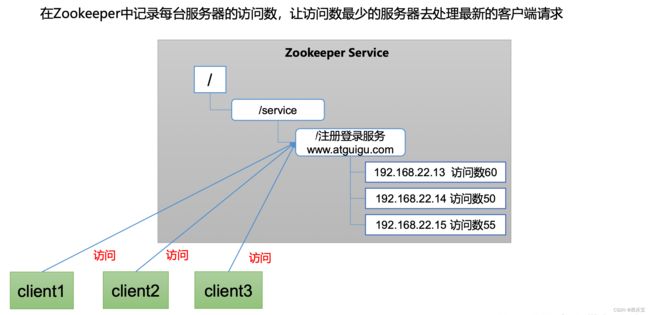
负载均衡
在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求。
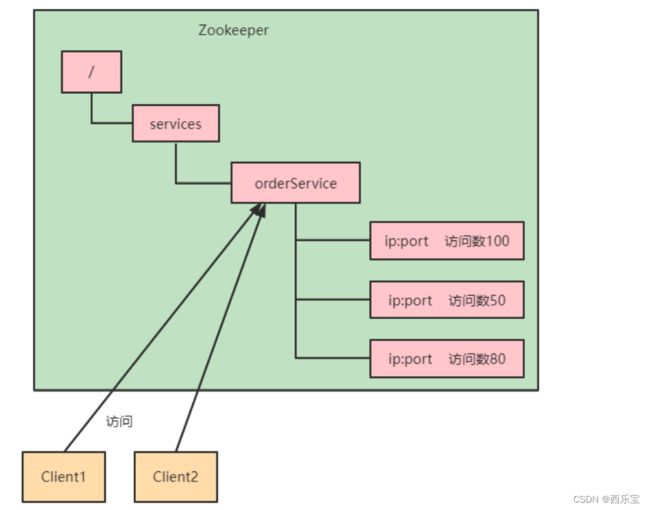
补充知识点:
永久性Watch
在被触发之后,仍然保留, 可以继续监听ZNode的变更, 是Zookeeper 3.6.0 版本新增加的功能 。
addWatch [-m mode] path
addWatch的作用是针对指针节点添加事件监听 , 支持两种模式 。
- PERSISTENT:持久化订阅,针对当前节点的修改和删除事件,以及当前节点的子节点的删除和新增事件 。
- PERSISTENT_RECURSIVE:持久化递归订阅,在PERSISTENT的基础上, 增加了子节点的修改事件触发 , 以及子节点的数据变化都会触发相关的事件 (满足递归订阅特性)
3. Zookeeper 实战
3.1. zookeeper安装
Step1:配置JAVA环境,检验环境:
# java‐version
Step2: 下载解压 zookeeper
# wget https://mirror.bit.edu.cn/apache/zookeeper/zookeeper‐3.5.8/apache‐zookeeper‐3.5.8‐bin.tar.gz
# tar ‐zxvf apache‐zookeeper‐3.5.8‐bin.tar.gz
# cd apache‐zookeeper‐3.5.8‐bin
Step3: 重命名配置文件 zoo_sample.cfg
# cp zoo_sample.cfg zoo.cfg
Step4: 启动zookeeper
# 可以通过 bin/zkServer.sh 来查看都支持哪些参数
# bin/zkServer.sh start conf/zoo.cfg
Step5: 检测是否启动成功
# echo stat | nc 192.168.109.200 // 前提是配置文件中中讲 stat 四字命令设置了了白名单
如:
# 4lw.commands.whitelist=stat
Step6: 连接服务器
# bin/zkCli.sh ‐server ip:port
3.2. 使用命令行操作zookeeper
[zk:localhost:2181(CONNECTED)80]help ZooKeeper‐serverhost:portcmdargs
addauth scheme auth
close
config [‐c] [‐w] [‐s]
connect host:port
create [‐s] [‐e] [‐c] [‐t ttl] path [data] [acl]
delete [‐v version] path
deleteall path
delquota [‐n|‐b] path
get [‐s] [‐w] path
getAcl [‐s] path
history
listquota path
ls [‐s] [‐w] [‐R] path
ls2 path [watch]
printwatches on|off
quit
reconfig [‐s] [‐v version] [[‐file path] | [‐members serverID=host:port1:port
2;port3[,…]]] | [‐add serverId=host:port1:port2;port3[,…]] [‐remove serverI
d[,…]*]
redo cmdno
removewatches path [‐c|‐d|‐a] [‐l]
rmr path
set [‐s] [‐v version] path data
setAcl [‐s] [‐v version] [‐R] path acl
setquota ‐n|‐b val path
stat [‐w] path
sync path
创建zookeeper命令
# create[‐s][‐e][‐c][‐tttl]path[data][acl]
中括号为可选项,没有则默认创建持久化节点
- -s :顺序节点
- -e: 临时节点
- -c: 容器节点
- -t : 可以给节点添加过期时间,默认禁用,需要通过系统参数启用
-Dzookeeper.extendedTypesEnabled=true, znode.container.checkIntervalMs : (Java system
property only) New in 3.5.1: The time interval in milliseconds for each check of candidate container and ttl nodes. Default is “60000”.)
创建节点:
# create/test‐node some‐data
如上:没有加任何可选参数,创建的就是持久化节点
![]()
查看节点:
# get /test‐node
![]()
修改节点数据:
# set/test‐node some‐data‐changed

查看节点状态信息
stat /test-node

Stat
- cZxid : 创建znode的事务ID(Zxid的值) ,每次修改ZooKeeper状态都会产生一个ZooKeeper事务ID。事务ID是ZooKeeper中所 有修改总的次序。每次修改都有唯一的 zxid,如果 zxid1 小于 zxid2,那么 zxid1 在 zxid2 之 前发生。
- mZxid : znode 最后更新的事务 zxid
- pZxid : 最后添加或删除子节点的事务ID(子节点列表发生变化才会发生改变),znode 最后更新的子节点 zxid
- ctime : znode 被创建的毫秒数(从 1970 年开始)
- mtime : znode最近修改时间
- dataVersion: znode的当前数据版本 , znode 数据变化号
- cversion: znode的子节点结果集版本(一个节点的子节点增加,删除都会影响这个版本) ,znode 子节点版本号,znode 子节点修改次数
- aclVersion : 表示对此znode的acl版本, znode 访问控制列表的变化号
- ephemeralOwner: znode是临时znode时,表示znode所有者的session ID , 如果znode不是临时znode , 则该字段设置为零。
- dataLength : znode数据字段的长度
- numChildren : znode的子znode的数量 。
根据状态数据中的版本号有并发修改数据实现乐观锁的功能 。
比如: 客户端首先获取版本信息, get -s /node-test
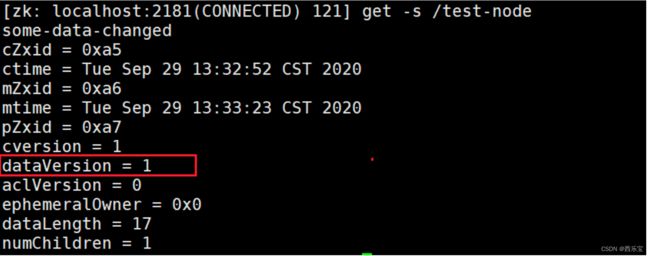
/test-node 当前数据版本是1 , 这时客户端用set命令修改数据的时候可以把版本号带上
![]()
如果执行上面的set命令前, 有人修改了数据,zookeeper会递增版本号, 这个时候,如果再用以前的版本号去修改, 将会导致修改失败, 报以下错误 。
![]()
创建子节点,这里需要注意 , zookeeper是以节点组织数据的,没有相对路径一说, 所以有的节点一定是以/开头 。
# create /test‐node/test‐sub‐node
![]()
查看子节点的信息 , 比如根节点下所有的子节点,加一个大写的R 可以查看递归子节点的列表
# ls /

查看 /test-node 下所有的子节点
![]()
创建临时节点
# create‐ e /ephemeral data
create 后跟一个-e 创建临时节点,临时节点不能创建子节点 。
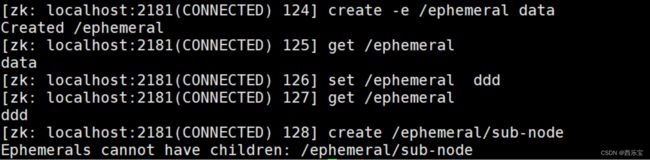
创建序号节点,加参数 -s
# create /seq‐parent data//创建父目录,单纯为了分类,非必须
# create ‐s /seq‐parent/ data // 创建顺序节点。顺序节点将再seq‐parent 目录下面,顺序 递增
为了容纳子节点,创建父目录/seq-parent

也可以再序号节点前面加一个前缀

创建临时顺序节点其他增删改查和其他节点无异,不再贴图
create ‐s ‐e /ephemeral‐node/前缀‐
创建容器节点
create‐c/container
容器节点主要用来容纳子节点,如果没有给其创建子节点,容器节点表现和持久化节点一样, 如果给给容器节点创建了子节点,后续又把子节点清空, 容器节点也会被zookeeper删除 。
事件监听机制 。
针对节点的监听 , 一定事件触发,对应的注册立即被移除,所以事件监听是一次性的。
# get ‐w /path //注册监听的同时获取数据
# stat ‐w /path //对节点进行监听,且获取元数据信息

针对目录的监听,如下图,目录的变化,会触发事件,且一旦触发,对应的监听也会被移除,后
续对节点的创建没有触发监听事件
# ls ‐w /path

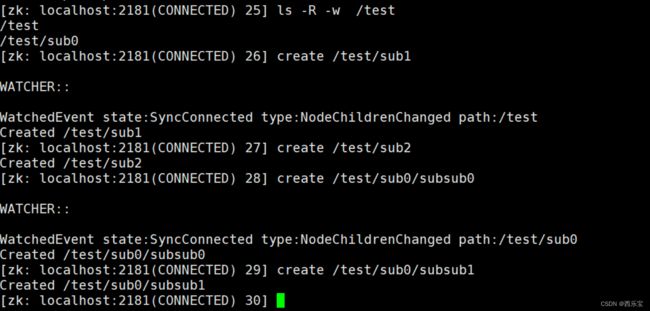
针对递归子目录的监听
# ls -R -w /path : -R 区分大小写, 一定用大写
如下对/test 节点进行递归监听,但是每个目录下也是一次性的,如第一次在/test目录下创建节点时, 触发监听事件,第二次则没有,同样,因为递归目录监听,所以在/test/sub0下进行节点创建时 , 触发事件,但是再次创建/test/sub0/subsub1节点,没有触发事件 。
ACL权限控制
Zookeeper 的 ACL 权限控制( Access Control List )
Zookeeper的ACL权限控制,可以控制节点的读写操作,保证数据的安全性。 Zookeeper ACL 权限设置分为3部分组成,分别是权限模式(Scheme),授权操作(ID) ,权限信息(Permission),最终组成一条例如 scheme: id:permission 格式的ACL请求信息, 下面我们看一下具体的3 部分代表什么意思 。
Scheme(权限模式):用来设置Zookeeper服务器进行权限验证的方式,Zookeeper 的权限验证方式大体分为两种类型。
scheme:授权的模式,代表采用的某种权限机制,包括 world、auth、digest、ip、super 几种。
一种是范围验证,所谓的范围验证就是说Zookeepr可以针对一个IP或者一段IP地址授予某种权限,比如我们可以让一个IP地址为"IP:192.168.0.110" 的机器对服务器上的某个数据节点具有写入的权限,或者可以通过"ip:192.168.0.1/24"给一段IP地址的机器赋权。
另一种是权限模式也就是口令验证, 也可以理解为用户名和密码方式,在Zookeeper中这种验证方式是Digest认证,而Digest这种认证方式首先在客户端传送"username:password" ,这种形式的权限表示符后, Zookeeper服务端也会对密码,部分使用SHA-1 和BASE64算法进行加密 。 以保证数据安全。
还有和中是Supper权限模式,Super可以认为的是一种特殊的Digest认证,具有Super权限的客户端可以对Zookeeper上的任意数据节点进行任意操作。
| 模式 | 描述 |
|---|---|
| world | 授权对象只有一个anyone , 代表登录到服务器的所有客户端都能对该节点执行某种权限 |
| ip | 对连接客户端使用IP地址认识方式进行认证 |
| auth | 使用以添加认证的用户进行认证 |
| digest | 使用用户:密码方式验证 |
授权对象(ID)
授权对象就是说我们要把权限赋予谁, 而对应于4种不同的权限模式来说,如果我们选择采用IP方式,使用授权对象可以是一个IP地址或IP地址段 ,而如果使用Digest或 Super方式,则对应于一个用户名, 如果是World模式,是授权系统中所有的用户 。
授权对象,代表允许访问的用户。如果我们选择采用 IP 方式,使用的授权对象可以是一个 IP 地址或 IP 地址段;而如果使用 Digest 或 Super 方式,则对应于一个用户名。如果是 World 模式,是授权系统中所有的用户。
权限信息(Permission)
权限就是指我们可以在数据节点上执行操作的各类,如下所示 : 在Zookeeper中已经定义好了5种权限。
授权的权限,权限组合字符串,由 cdrwa 组成,其中每个字母代表支持不同权限, 创建权限 create©、删除权限 delete(d)、读权限 read( r)、写权限 write(w)、管理权限admin(a)。
- 数据节点(c:create) 创建权限 ,授予权限的对象可以在数据节点下创建子节点
- 数据节点(w:write) 更新权限 , 授予权限的对象可以更新该数据节点 。
- 数据节点(r:read) 读取权限 , 授予权限的对象可以读取节点的内容以及子节点的列表信息
- 数据节点(d:delete ) 删除权限, 授予权限的对象可以删除该数据节点的子节点 。
- 数据节点(a:admin) 管理者权限 , 授予权限对象可以对该数据节点体进行ACL权限设置 。
| 权限类型 | ACL简写 | 描述 |
|---|---|---|
| read | r | 读取节点及显示子节点列表的权限 |
| write | w | 设置节点数据的权限 |
| create | c | 创建子节点的权限 |
| delete | d | 删除子节点的权限 |
| admin | a | 设置该节点ACL权限的权限 |
命令:
- getAcl : 获取某个节点的acl权限信息
- setAcl: 设置某个节点的acl权限信息
- addauth : 输入认证授权信息,相当于注册用户信息 , 注册时输入明文密码,zk将以密文形式存储 。
| 授权命令 | 用法 | 描述 |
|---|---|---|
| getAcl | getAcl path | 读取节点的ACL |
| setAcl | setAcl path acl | 设置节点的ACL |
| create | create path data acl | 创建节点时设置acl |
| addAuth | addAuth scheme auth | 添加认证用户,类似于登录操作 |
测试 :
取消节点的读取权限后, 读取/name 节点没有权限
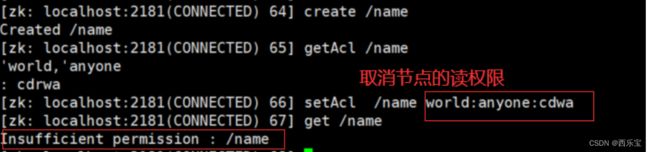
取消节点的删除子节点的权限

可以通过系统参数zookeeper.skipACL=yes进行配置, 默认是no,可以配置为true , 则配置过的ACL将不再进行权限检测 。
生成授权ID的两种方式 。
a.代码生成ID
@Test
publicvoidgenerateSuperDigest()throwsNoSuchAlgorithmException{
String sId = DigestAuthenticationProvider.generateDigest(“gj:test”);
System.out.println(sId);// gj:X/NSthOB0fD/OT6iilJ55WJVado=
}
auth授权模式
创建用户
# addauth digest fox:123456
设置权限
# setAcl /name auth:fox:123456:cdrwa
# 加密
# echo -n fox:123456 | openssl dgst -binary -sha1 | openssl base64
# setAcl /name auth:fox:ZsWwgmtnTnx1usRF1voHFJAYGQU=:cdrwa
![]()
退出客户端,重新连接之后获取/name会没权限,需要添加授权用户。

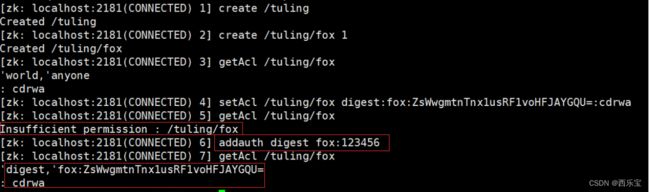
digest授权模式
# 设置权限
# setAcl /tuling/fox digest:fox:ZsWwgmtnTnx1usRF1voHFJAYGQU=:cdrwa
IP授权模式 :
# setAcl /node-ip ip:192.168.109.128:cdwra
# create /node-ip data ip:192.168.109.128:cdwra
多个指定IP可以通过逗号分隔, 如 setAcl /node-ip ip:IP1:rw,ip:IP2:a
Super 超级管理员模式
这是一种特殊的Digest模式 ,在Super模式下超级管理员用户可以对Zookeeper上的节点进行任何操作。 需要在启动上通过JVM系统参数开启。
DigestAuthenticationProvider中定义
‐Dzookeeper.DigestAuthenticationProvider.superDigest=super:
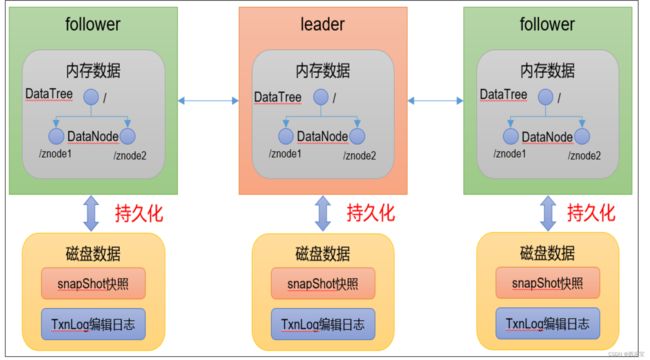
Zookeeper内存数据和持久化
Zookeeper数据的组织形式是一个类似文件系统的数据结构,而这些数据是存储在内存中的,所以我们认为,Zookeeper是一个基于内存的小型数据库。
内存中的数据:
public class DataTree{
private final ConcurrentHashMap
private final WatchManager dataWatches = new WatchManager();
private final WatchManager childWatches = new WatchManager();
}
DataNode 是Zookeeper存储节点数据的最小单位
publicclassDataNodeimplementsRecord{ byte data[];
Long acl;
public StatPersisted stat;
private Set
}
事务日志
针对每一次客户端的事务操作,Zookeeper都会将他们的记录到事务日志中, 当然,Zookeeper也会将数据变更到内存数据库中,我们可以在Zookeeper的主配置文件zoo.cfg中配置内存中的数据持久化目录 , 也就是事务日志的存储路径dataLogDir,如果没有配置dataLogDir(非必填),事务日志将存储到dataDir必填目录 。
org.apache.zookeeper.server.LogFormatter
java‐classpath.:slf4j‐api‐1.7.25.jar:zookeeper‐3.5.8.jar:zookeeper‐jute‐ 3.5.8.jar org.apache.zookeeper.server.LogFormatter /usr/local/zookeeper/apache‐z okeeper‐3.5.8‐bin/data/version‐2/log.1
如下是我本地的日志文件格式化效果

从左到右分别记录了操作时间,客户端会话ID,CXID,ZXID,操作类型,节点路径,节点数据(用 #+ascii 码表示),节点版本。
Zookeeper进行事务日志文件操作的时候会频繁的进行磁盘IO操作, 事务日志不断的追加写操作会触发底层磁盘IO为文件开辟新的磁盘块,即磁盘Seek,因此,为了提升磁盘IO的效率,Zookeeper在创建事务日志文件的时候就进行了文件空间的预分配,即在创建文件的时候,就向操作系统申请了一块大一点的磁盘块, 这个预分配的磁盘大小可以通过系统参数zookeeper.preAllocSize 进行配置。
事务日志文件名: log.<当时最大事务ID>,应为日志文件时顺序写入, 所以这个最大事务ID也将是整个事务日志文件中,最小的事务ID,日志装满了即进行下一次事务日志文件的创建 。
数据快照
数据快照用于记录Zookeeper服务器上某一时刻的全量数据,并将其写入到指定的磁盘文件中, 可以通过配置snapCount配置每间隔事务请求个数,生成快照,数据存储在dataDir指定的目录中。
可以通过如下方式进行查看快照数据(为了避免集群中的所有机器同一时间进行快照,实际快照生成的时机为事务达到[snapCount/2 + 随机数(随机数范围1 ~ snapCount/2 )])个数时开始快照 。
java‐classpath.:slf4j‐api‐1.7.25.jar:zookeeper‐3.5.8.jar:zookeeper‐jute‐ 3.5.8.jar org.apache.zookeeper.server.SnapshotFormatter /usr/local/zookeeper/apa he‐zookeeper‐3.5.8‐bin/data‐dir/version‐2/snapshot.0
快照事务日志文件名为: snapshot.<当时最大事务ID>,日志满了即进行下一次事务日志文件的 创建
有了事务日志,为什么还要快照数据 。
快照数据主要是为了快速恢复,事务日志文件是每次事务请求都会进行追加操作, 而快照是达到某种设定的条件下的内存全量数据,所以通常数据是反应当时内存数据的状态 , 事务日志是更全面的数据,所以恢复数据的时候,可以先恢复快照数据,再通过快照数据,再通过增量事务日志中的数据即可。
Zookeeper集群
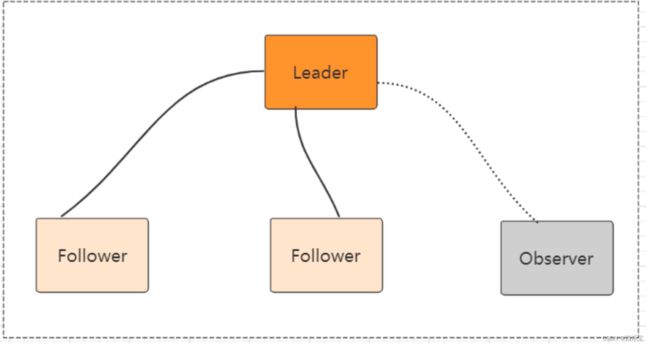
集群角色
- Leader: 领导者
事务请求(写操作)的唯一调度者和处理者,保证集群事务处理的顺序性,集群内部各个服务器的调试者, 对于create ,setData , delete 等有写操作的请求,则要统一转发给leader处理, leader需要决定编号 ,执行操作,这个过程称为事务 。
- Follower: 跟随者
处理客户端非事务(读操作)请求(可以直接响应) ,转发给事务请求给Leader ,参与集群Leader选举投票
- Observer: 观察者
对于非事务请求可以独立处理(读操作) , 对于事务请求会转发给leader处理, Observer节点接收来自leader的inform信息,更新自己本地存储 ,不参与提交和选举投票 , 通常不在影响集群事务处理能力的前提下提升集群的非事务处理能力 。
Observer应用场景:
- 提升集群的读性能 , 因为Observer和不参与提交和选举投票过程 , 所以可以通过往集群里面添加observer节点来提高整个集群的读性能 。
- 跨数据中心部署。 比如需要部署一个北京和香港两地都可以使用的zookeeper集群服务 , 并且要求北京和香港客户的读请求延迟都很低 ,解决方案就是把香港的节点设置为observer 。
集群架构
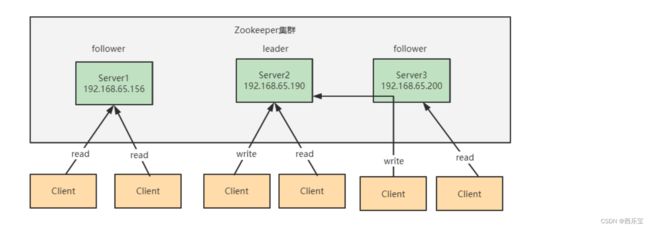
leader 节点可以处理读写请求, follower只可以处理读请求, follower在接到写请求时会把写请求转发给leader来处理
zookeeper 数据一致性保证
全局可线性化(Linearizable)写入, 先达到leader的写请求会被先处理, leader决定写请求的执行顺序 。
客户端FIFO 顺序 ,来自给定客户端的请求按照发送顺序执行。
Zookeeper集群模式一共有三种类型的角色
Leader : 处理所有的事务请求(写请求),可以处理读请求, 集群中只有一个Leader
Follower : 只能处理读请求 , 同时作为Leader的候选节点,即如Leader 宕机 。 Follower节点要参与到新的Leader 选举中, 有可能成为新的Leader 节点 。
Observer : 只能处理读请求, 不能参与选举。
Zookeeper集群模式的安装
本例搭建的是伪集群模式,即一台机器上启动4个zookeeper实例组成集群, 真正的集群模式无非就是实例的IP地址不同, 搭建的方式没有什么区别
- 配置JAVA环境,检验环境:保证是jdk7 及以上即可
# java‐version
- 下载并解压zookeeper
# wget https://mirror.bit.edu.cn/apache/zookeeper/zookeeper‐3.5.8/apache‐zookee er‐3.5.8‐bin.tar.gz
# tar ‐zxvf apache‐zookeeper‐3.5.8‐bin.tar.gz
# cd apache‐zookeeper‐3.5.8‐bin
- 重命名 zoo_sample.cfg文件
# cp conf/zoo_sample.cfg conf/zoo‐1.cfg
- 修改配置文件zoo-1.cfg,原配置文件里有的,修改成下面的值,没有的则加上
# vim conf/zoo‐1.cfg
# dataDir=/usr/local/data/zookeeper‐1
# clientPort=2181
# server.1=127.0.0.1:2001:3001:participant // participant 可以不用写,默认就是part icipant
# server.2=127.0.0.1:2002:3002:participant
# server.3=127.0.0.1:2003:3003:participant
# server.4=127.0.0.1:2004:3004:observer
配置说明
- tickTime : 用于配置Zookeeper中最小的单位长度 ,很多运行的时间间隔都是tickTime的倍数来表示的。
- initLimit : 该参数用于配置Leader服务器等待Follower启动,并完成数据同步的时间 , Follower服务器再启动过程中,会与Leader 建立连接并完成数据同步,从而确定自己对外提供的服务起始状态 , Leader服务器允许Follower再initLimit时间内完成这个工作 。
- syncLimit : Leader 与Follower心跳检测的最大延时时间 。
- dataDir : 顾名思义就是Zookeeper保存数据的目录 , 默认情况下, Zookeeper将写数据的日志文件也保存到这个目录里。
- clientPort : 这个端口就是客户端连接Zookeeper服务器的端口, Zookeeper会监听这个端口, 接受客户端的访问请求。
- server.A = B:C:D:E 其中A是一个数字, 表示这个是第几号服务器, B是这个服务器的IP地址 , C 表示是这个服务器与集群中的Leader 服务器交换信息端口, D 表示的是万一集群中的Leader 服务器挂了 , 需要一个端口来重新进行选举, 选出一个新的Leader,而这个端口就是用来执行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器互相通信的端口, 如果是伪集群配置方式,由于 B是一样的, 所以不同的Zookeeper实例通信端口信号不能一样 , 所以要给它们分配不同的端口号, 如果需要通过添加不参加集群选举以及事务请求的过半机制的它们分配不同的端口号, 如果需要添加不参与集群选举以及事务请求的过半机制的Observer节点 , 可以在E的位置 , 添加observer标识 。
- 再从zoo-1.cfg 复制三个配置文件 zoo-2.cfg , zoo-3.cfg 和zoo-4.cfg ,只需要修改dataDir和clientPort不同即可。
# cp conf/zoo1.cfg conf/zoo2.cfg
# cp conf/zoo1.cfg conf/zoo3.cfg
# cp conf/zoo1.cfg conf/zoo4.cfg
# vim conf/zoo2.cfg
# dataDir=/usr/local/data/zookeeper2
# clientPort=2182
# vim conf/zoo3.cfg
# dataDir=/usr/local/data/zookeeper3
# clientPort=2183
# vim conf/zoo4.cfg
# dataDir=/usr/local/data/zookeeper4
# clientPort=2184
Step5: 标识Server ID 创建四个文件夹/usr/local/data/zookeeper-1,/usr/local/data/zookeeper- 2,/usr/local/data/zookeeper-3,/usr/local/data/zookeeper-4,在每个目录中创建文件 myid 文件,写入当前实例的server id,即1,2,3,4
cd /usr/local/data/zookeeper‐1
vi myid
1
cd /usr/local/data/zookeeper‐2
vi myid
2
cd /usr/local/data/zookeeper‐3
vi myid
3
cd /usr/local/data/zookeeper‐4
vi myid
4
启动三个zookeeper实例
# bin/zkServer.sh startconf/zoo1.cfg
# bin/zkServer.sh startconf/zoo2.cfg
# bin/zkServer.sh startconf/zoo3.cfg
检测集群状态 , 也可以直接用命令zkServer.sh status conf/zoo1.cfg 进行每台服务器的状态查询
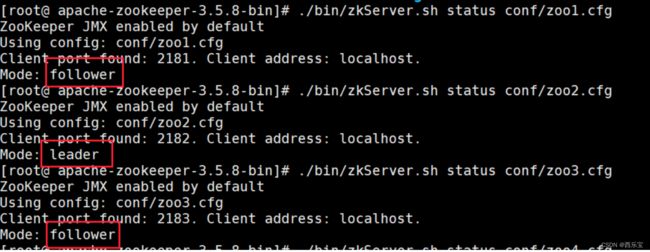
可以通过查看/zookeeper/config 节点数据来查看集群配置。
Zookeeper 3.5.0 新特性: 集群动态配置
Zookeeper 3.5.0 以前, Zookeeper 集群角色要发生改变的话, 只能通过停止掉所有的Zookeeper 服务,修改集群配置,重启服务来完成,这样集群服务将有一段不可用状态 ,为了应对高可用的需求 , Zookeeper 3.5.0 提供了支持动态扩容/缩空的新特性, 但是通过客户端API可以变更服务端集群状态是件很危险的事情, 所以在zookeeper 3.5.3 版本要用动态配置, 需要开启超级管理员身份验证模式ACLS,如果在一个安全的环境中也可以通过配置参数Dzookeeper.skipACL=yes 来避免配置维护acl权限配置。
第一步 : 按照上节课的方式 , 先配置一个超级管理员 (如果不配置管理员,也可以设置系统参数 -Dzookeeper.skipACL=yes )如 :
在zookeeper 启动脚本中添加超级管理员授权模式 :
# echo -n gj:123 | openssl dgst -binary -sha1 | openssl base64
# RRCKWv2U2e99M6UmsFaJiQ2xStw=
# ‐Dzookeeper.DigestAuthenticationProvider.superDigest=gj:RRCKWv2U2e99M6UmsFaJi 2xStw=
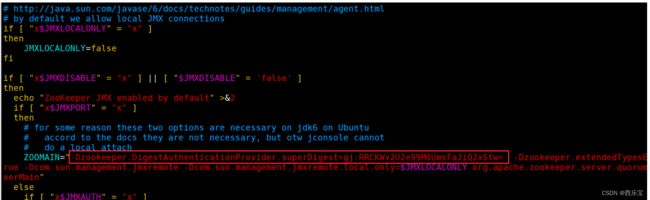
配置动态文件
修改配置zoo1.cfg
注意这里先除去端口号 , 添加了
reconfigEnabled : 设置为true 开启动态配置
dynamicConfigFile : 指定动态配置文件的路径
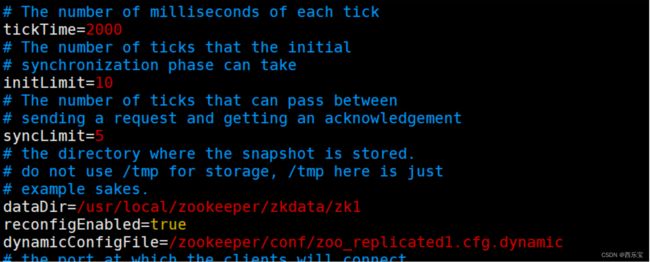
创建文件 zoo_replicated1.cfg.dynamic
动态配置文件加入了集群信息
server.A=B.C.D.E;F
A : 服务器的唯一标识
B :服务器对应的IP地址
C :集群通信端口
D :集群选举端口
E : 角色 , 默认是participant , 即参与过半机制的角色,选举,事务请求过半提交,还有一个是observer 观察者, 不参与选举及过半机制 。
之后是一个分号,一定是一个分号。

服务端IP : 端口
server.1=192.168.109.200:2001:3001:participant;192.168.109.200:2181
server.2=192.168.109.200:2002:3002:participant;192.168.109.200:2182
server.3=192.168.109.200:2003:3003:participant;192.168.109.200:2183
依次配置其他服务 , zoo2.cfg , zoo3.cfg 注意数据文件的路径 。
依次启动所有服务
# ./bin/zkServer.sh start conf/zoo1.cfg
查看集群状态:
# ./bin/zkServer.sh status conf/zoo1.cfg

Zookeeper四字命令
用户可以使用Zookeeper四字命令获取 zookeeper 服务的当前状态及相关信息
zookeeper支持某些特定的四字命名与其交互,用户获取zookeeper服务的当前状态及相关信息, 用户在客户端可以通过telenet或者nc(netcat)向zookeeper提交相应的命令。
安装 nc 命令:
yum install nc
四字命令格式
echo [command] | nc [ip] [port]
Zookeeper 常用的四字命令主要如下 :
| 四字命令 | 功能描述 |
|---|---|
| conf | 3.3.0版本引入的,打印出服务相关的配置的详细信息 |
| cons | 3.3.0 版本引入的, 列出所有的连接到这台服务器的客户端全部连接/会话详细信息,包括接受,发送的包数据量,会话id,操作延迟,最后的操作执行等信息 |
| crst | 3.3.0 版本引入的,重置所有的连接和连接和会话统计信息 |
| dump | 列出那些比较重要会话的临时节点,这个命令只能在leader节点上有用 |
| envi | 打印出服务器环境的详细信息 |
| reqs | 列出未经过处理的请求 |
| ruok | 测试服务器是否处理正确状态 , 如果确实如此 ,那么服务器返回 “imok” ,否则不做任何相应 |
| stat | 输出关于性能和连接的客户端列表 |
| srst | 重置服务器的统计 |
| srvr | 3.3.0 版本引入的,列出连接服务器的详细信息 |
| wchs | 3.3.0 版本引入的,列出服务器watch的详细信息 |
| wchc | 3.3.0 版本引入的, 通过session 列出服务器watch 的详细信息, 它输出了一个与session相关的路径 |
| mntr | 3.4.0 版本引入的,输出可用于检测集群健康状态变量列表 |
https://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_4lw
开启四字命令
方法1 : 在zoo.cfg 文件中加入了配置让这些指令放行。
# 开启四字命令
# 4lw.commands.whitelist=*
方法2 , 在zk的启动脚本zkServer.sh中新增放行指令
# 添加VM环境变量-Dzookeeper.4lw.commands.whitelist=*
# ZOOMAIN=“-Dzookeeper.4lw.commands.whitelist=* ${ZOOMAIN}”
stat 命令
stat 命令用于查看 zk 的状态信息,实例如下:
$ echo stat | nc 192.168.65.156 2181
Zookeeper Leader 选举原理
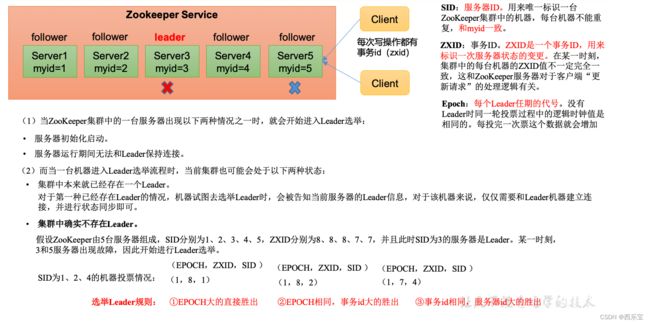
zookeeper 的leader 选举存在两个阶段,一个是服务器启动时leader选举, 另一个是运行过程中leader服务器宕机 。
在分析选举原理之前,先介绍几个重要的参数 :
- 服务器Id(myid): 编号越大在选举算法中的权重越大 。
- 事务ID(zxid) : 值越大说明数据越新, 权重越大。
- 逻辑时钟(epoch-logicalclock): 同一轮投票中的逻辑时钟值是相同的, 每投完一次值就会增加
选举状态:
- LOOKING:竞选状态
- FOLLOWING:随从状态 , 同步leader状态,参与投票
- OBSERVING:观察状态,同步leader状态 ,不参与投票。
- LEADING: 领导者状态
服务器启动时的leader选举
每个节点启动的时候都LOOKING观望状态,接下来就是开始进行选举的流程了,这里选三台机器组成的集群为例,第一台服务器server1启动时, 无法进行leader选举,当第二台服务器server2启动时, 两台机器可以相互通信 , 进入leader选举过程 。

- 每台server发出一个投票, 由于初始情况,server1和server2都将自己作为leader服务器进行投票,每次投票包含所推举服务器myid,zxid,epoch ,使用(myid , zxid) 表示 , 此时server1投票(1,0) ,server2投票为(2,0 ),然后将各自投票发送给集群中的其他机器 。
- 接收来自各个服务器的投票,集群中每个服务器收到投票后,首先判断投票的有效性, 如检查是否是本轮投票(epoch) ,是否来自LOOKING 状态的服务器。
- 分别处理投票,针对每一次投票,服务器都需要将其他服务器和自己的投票进行对比,对比规则如下 。
a) 优先比较epoch
b) 检查zxid,zxid比较大的服务器优先作为leader
c) 如果zxid相同,那么就比较myid,myid较大的服务器作为Leader - 统计投票,每次投票后,服务器统计投票信息,判断是否都有过半的机器接收相同的投票信息,server1,server2都统计出集群中有两台机器接受了(2,0)的投票信息, 此时已经选出了server2为leader节点 。
- 改变服务器状态,一旦确定了leader,每个服务器响应更新自己的状态,如果follower,那么就变更FOLLOWING,如果是Leader就变更为LEADING,此时server3继续启动,直接加入变更自己的FOLLOWING。

运行过程中的Leader选举
当集群中leader服务器出现宕机或者不可用的情况 , 整个集群将无法对外提供服务,进入新一轮的leader选举。
- 变更状态,leader挂后,其他非Oberver服务器将自身服务器的状态变更为LOOKING
- 每个server发出一个投票,在运行期间,每个服务器上的zxid可能不同 。
- 处理投票,规则同启动过程
- 统计投票,与启动过程相同 。
- 改变服务器的状态,与启动过程相同 。
Zookeeper数据同步流程
在Zookeeper中,主要依赖ZAB协议来实现分布式数据一致性。
ZAB协议有两部分。
- 消息广播
- 崩溃恢复
消息广播
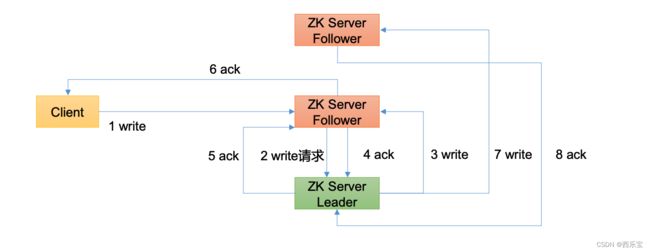
Zookeeper使用单一的主进程Leader来接收和处理客户端所有的事务请求, 并采用了ZAB协议原子广播协议,将事务请求以Proposal提议广播到所有的Follower节点,当集群中有过半的Follower服务器进行正确的ACK反馈,那么Leader 就会再次向所有的Follower服务器发送commit消息, 将此提案进行提交 ,这个过程可以简称为2pc事务提交 , 整个流程可以参考下图 。 注意Observer节点只负责同步 Leader数据,不参与2PC数据同步 。

ZAB 协议的消息广播过程使用的是一个原子广播协议,类似一个 二阶段提交过程。对于客户端发送的写请求,全部由 Leader 接收,
Leader 将请求封装成一个事务 Proposal,将其发送给所有 Follwer ,然后,根据所有 Follwer 的反馈,如果超过半数成功响应,则执行 commit 操作。
整个广播流程如下:
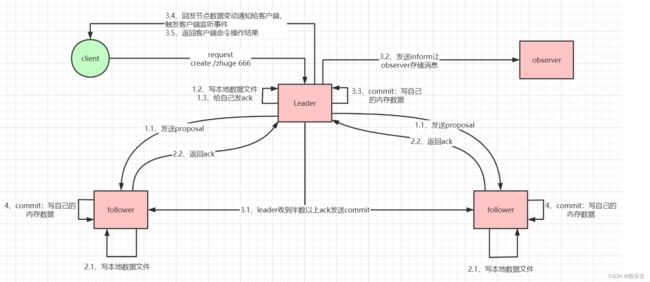
通过以上步骤,就能保持集群之间数据的一致性
还有一些细节:
- Leader 在收到客户端请求之后,会将这个请求封装成一个事务,并给这个事务分配一个全局递增的唯一 ID,称为事务 ID(ZXID),ZAB 协议需要保证事务的顺序,因此必须将每一个事务按照 ZXID 进行先后排序然后处理,主要通过消息队列实现。
- 在 Leader 和 Follwer 之间还有一个消息队列,用来解耦他们之间的耦合,解除同步阻塞。
- zookeeper集群中为保证任何所有进程能够有序的顺序执行,只能是 Leader 服务器接受写请求,即使是 Follower 服务器接受到 客户端的写请求,也会转发到 Leader 服务器进行处理,Follower只能处理读请求。
- ZAB协议规定了如果一个事务在一台机器上被处理(commit)成功,那么应该在所有的机器上都被处理成功,哪怕机器出现故障 崩溃。

崩溃恢复
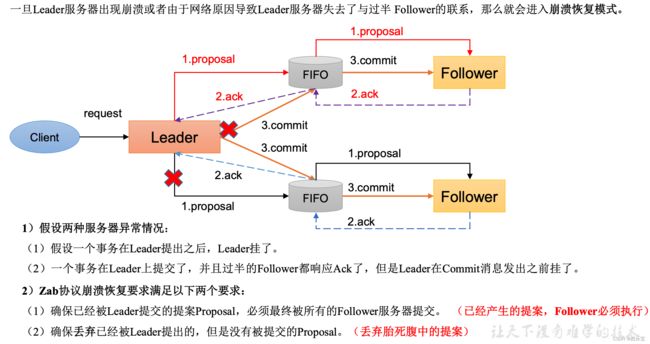
在正常情况下消息下的广播能运行很好,但是一旦Leader服务器出现了崩溃,或者由于网络原理导致Leader服务器失去过半的Follower的通信 ,那么就会进入崩溃恢复模式,需要选举出一个新的Leader服务器, 在这个过程中可能会出现两种数据不一致隐患, 需要ZAB协议的特性进行避免 。
刚刚我们说消息广播过程中, Leader崩溃怎么办 ? 还能保证数据一致性吗? 如果Leader 先本地提交了, 然后commit请求没有发送出去,怎么办。
实际上, 当Leader 崩溃,即进入我们开头所说的崩溃恢复模式,崩溃即:Leader 失去过半Follwer的联系,下面来详细的讲述 。
- 假设1:Leader 在复制数据给所有 Follwer 之后,还没来得及收到Follower的ack返回就崩溃,怎么办?
- 假设2:Leader 在收到 ack 并提交了自己,同时发送了部分 commit 出去之后崩溃怎么办?
针对这些问题,ZAB 定义了 2 个原则:
- ZAB 协议确保丢弃那些只在 Leader 提出/复制,但没有提交的事务。
- ZAB 协议确保那些已经在 Leader 提交的事务最终会被所有服务器提交。
所以 ,ZAB 设计了下面这样一个选举算法。
能够确保提交已经被Leader 提交的事务 , 同时丢弃已经被跑过的事务 。
针对这个要求 , 如果让Leader 选举算法能够保证新选举出来的Leader 服务器拥有了集群中的所有机器 , 那么就能够保证这个新选举出来的Leader 一定具有所有已经提交的提案 。
而且这么做的一个好处就是可以活动Leader 服务器检测事务的提交和丢弃工作的这一步骤了。
- Leader 服务器将消息commit发出之后,立即崩溃
- Leader 服务器刚提出proposal后,立即崩溃
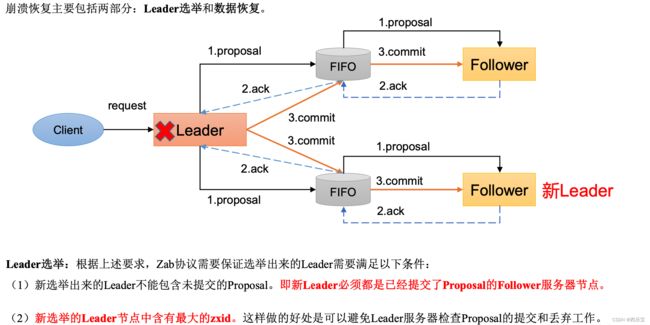
ZAB 协议的恢复模式使用了以下的策略。
- 选举zxid最大的节点作为新的leader
- 新leader将事务日志中尚未提交的消息进行处理。
崩溃恢复——异常假设
崩溃恢复——Leader选举
崩溃恢复——数据恢复
崩溃恢复——异常提案处理

数据同步
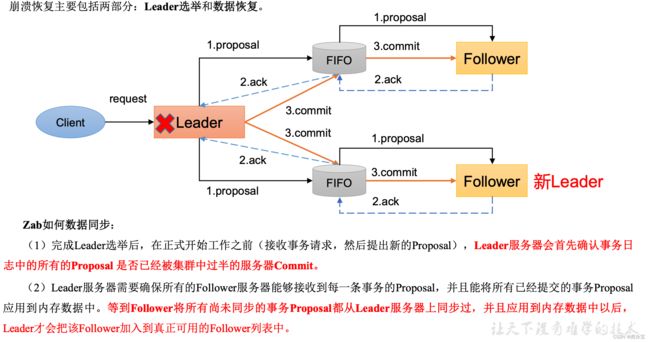
当崩溃恢复后,需要在正式工作之前接收客户端请求, Leader 服务器首先确认事务是否已经过半的Follwer提交了, 即是否完成了数据同步,目的就是为了保证数据一致 。
当Follower服务器成功同步之后,Leader 会将这些服务器加入到服务器列表 中。
实际上, Leader 服务器处理或丢弃事务都是依赖着ZXID的,那么ZXID如何生成的呢 ?
答 ,在ZAB协议的事务编号ZXID 设计中, ZXID 是一个64位的数字 , 其低32位可以看作是一个简单的递增计数器,针对客户端的每一个请求,Leader 都会产生一个新的事务Proposal并对该计数器进行加1操作。
而高32位则代表了Leader 服务器上取出本地日志中最大事务Proposal的ZXID , 并从该ZXID中解析出对应的epoch值(leader选举周期),当一轮新的选举结束后,会对这个值加1 , 并且事务id又从0开始自增。

高32位代表每代Leader 的唯一性,低32位代表每代Leader中事务的唯一性,同时,也能让Follower通过高32位识别不同的Leader,简化了数据恢复流程。
基于这样的策略,当Follower连接上了Leader之后,Leader 服务器会根据自己服务器上的最后被提交的ZXID 和Folloer上的ZXID进行比对,比对结果要么回滚,要么和Leader同步 。
如上借助于临时顺序节点,可以避免同时多个节点的并发竞争锁, 缓解服务端压力 。
整个Zookeeper就是一个多节点分布式一致性算法的实现, 底层采用实现协议是ZAB .
ZAB协议介绍
ZAB 协议全称是 : Zookeeper Atomic Broadcast(Zookeeper 原子广播协议)。
Zookeeper是一个分布式应用提供了高效且可靠的分布式协调服务 , 在解决分布式一致性方面,Zookeeper并没有使用Paxos ,而是用了ZAB 协议 , ZAB 协议是Paxos算法的一种简单的实现。
ZAB 协议的定义 , ZAB 协议是分布式协调服务Zookeeper专门设计的一种支持崩溃恢复和原子广播协议 , 下面我们会重点讲这两个东西 。 基于该协议 , Zookeeper实现了一种主备模式的系统架构来保持集群中各个副本数据的一致性, 具体如下图所示 :
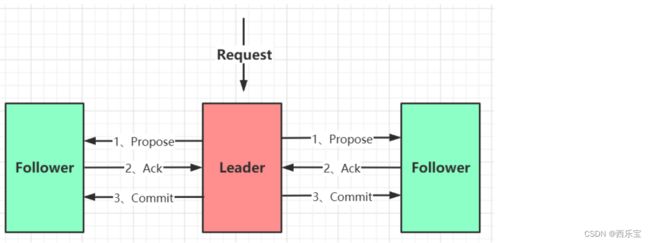
上图显示了 Zookeeper 如何处理集群中的数据。所有客户端写入数据都是写入到 主进程(称为 Leader)中,然后,由 Leader 复制到备 份进程(称为 Follower)中。从而保证数据一致性。
那么复制过程又是如何的呢?复制过程类似 2PC,ZAB 只需要 Follower 有一半以上返回 Ack 信息就可以执行提交,大大减小了同步阻 塞。也提高了可用性。
写流程之写入请求直接发送给Leader节点

写流程之写入请求发送给follower节点
Zookeeper整合Java实战
Zookeeper应用开发主要通过Java客户端API去连接操作Zookeeper集群, 可供选择的Java客户端API有 :
- Zookeeper官方的Java客户端API
- 第三方Java客户端API , 比如Curator
Zookeeper的官方客户端API提供了基本的操作,例如创建会话,创建节点,读取节点,更新数据,删除节点和检查节点是否存在等, 不过,对于实际开发来说,Zookeeper官方API有一些不足之处,具体如下 。
- Zookeeper的Watcher监测是一次性的,每次触发之后都需要进行注册。
- 会话超时之后没有实现重连机制 。
- 异常处理烦琐,Zookeeper提供了很多的异常, 对于开发人员来说可能根本不知道如何处理这些抛出的异常。
- 仅提供了简单的byte[]数组类型接口,没有提供Java POJO级别的序列化数据处理接口。
- 创建节点时如果抛出异常。 需要自行检查节点是否存在 。
- 无法实现级联删除 。
总之 , Zookeeper官方API功能比较简单, 在实际开发过程中比较笨重 ,一般不推荐使用
zookeeper官方的客户端没有和服务端代码分离 ,他们为同一个jar文件,所以我们直接引入zookeeper的maven即可。 这里的版本请保持与服务端版本一致,不然会有很多的兼容性问题。
Zookeeper 原生的客户端主要使用org.apache.zookeeper.Zookeeper这个类来使用Zookeeper服务 。
ZooKeeper常用构造器
ZooKeeper (connectString, sessionTimeout, watcher)
创建客户端实例:
为了便于测试,直接在初始化方法前中创建zookeeper实例。
public class ZkClientDemo {
private static final String CONNECT_STR = "localhost:2181";
private final static String CLUSTER_CONNECT_STR = "192.168.65.156:2181,192.168.65.190:2181,192.168.65.200:2181";
public static void main(String[] args) throws Exception {
final CountDownLatch countDownLatch = new CountDownLatch(1);
ZooKeeper zooKeeper = new ZooKeeper(CLUSTER_CONNECT_STR, 4000, new Watcher() {
@Override
public void process(WatchedEvent event) {
if (Event.KeeperState.SyncConnected == event.getState() && event.getType() == Event.EventType.None) {
//如果收到了服务端的响应事件,连接成功
countDownLatch.countDown();
System.out.println("连接建立");
}
}
});
System.out.printf("连接中");
countDownLatch.await();
//CONNECTED
System.out.println(zooKeeper.getState());
//创建持久节点
zooKeeper.create("/user", "fox".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
创建Zookeeper实例的方法:
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher)
throws IOException{
this(connectString, sessionTimeout, watcher, false);
}
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher,
ZKClientConfig conf) throws IOException {
}
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher,
boolean canBeReadOnly, HostProvider aHostProvider)
throws IOException {
}
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher,
boolean canBeReadOnly, HostProvider aHostProvider,
ZKClientConfig clientConfig) throws IOException {
}
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher,
boolean canBeReadOnly) throws IOException {
}
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher,
boolean canBeReadOnly, ZKClientConfig conf) throws IOException {
}
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher,
long sessionId, byte[] sessionPasswd) throws IOException{
}
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher,
long sessionId, byte[] sessionPasswd, boolean canBeReadOnly,
HostProvider aHostProvider, ZKClientConfig clientConfig) throws IOException {
}
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher,
long sessionId, byte[] sessionPasswd, boolean canBeReadOnly)
throws IOException {
}
| 参数名称 | 含义 |
|---|---|
| connectString | Zookeeper服务器列表,由英文的逗号分开host:port字符串组成, 每一个都代表一台 Zookeeper机器,如host1:port1,host2:port2,host3:port3,另外,也可以在connectString中设置客户端连接上的Zookeeper 。 后的根目录,方法是在host:port字符串之后添加这个根目录,例如,host1:port1,host2:port2,host3:port3/zk-base ,这样就指定了该客户端连接上Zookeeper服务器之后,所有对Zookeeper的操作,都会基于这个根目录, 例如 ,客户端对/sub-node的操作, 最终创建/zk-node/sub-node这个目录也叫Chroot,即客户端隔离命名空间 |
| sessionTimeout | 会话的概念,在一个会话周期内, Zookeepr客户端和服务器之间会通过心跳检测机制来维持会话的有效性, 一旦在sessionTimeOut时间内没有进行有效的心跳检测,会话就会失效 |
| watcher | Zookeeper 允许客户端在构造方法中传入了一个watcher(org.apache.zookeeper.Watcher)的实现类对象来作为默认的Watcher事件通知处理器,当然,该参数可以设置为null,表明不需要设置默认的Watcher处理器 |
| canBeReadOnly | 这是一个boolean类型的参数,用于标识当前会话是否支持,read-only只读模式 , 默认情况下,在Zookeeper集群中, 一个机器如果能集群中过半及以上机器失去网络链接,那么这个机器将不再处理客户端请求, 包括读写请求, 但是在某些使用场景下 , 当Zookeeper服务器发生 此类故障时候,我们还是希望Zookeepr服务器能够提供读服务(当然写服务肯定无法提供) 这就是Zookeeper的read-only模式 |
| sessionId和sessionPasswd | 分别代表会话ID和会话秘钥, 这两个参数能够唯一确定一个会话, 同时客户端使用这两个参数可以实现客户端会话复用,从而达到恢复会话的效果,具体使用方法是,第一次连接Zookeeper服务器时, 通过调用Zookeeper对象实例的以下两个接口,即可获得当前会话的ID和秘钥: long getSessionId() ,byte[] getSessionPassword() ; 获取到这两个参数后,就可以在下次创建Zookeeper对象实例的时候传入构造方法了 |
Zookeeper的主要方法
- create(final String path, byte data[], List acl,CreateMode createMode) : 创建一个给定路径的znode,并在znode保存data[]的数据,createMode 指定的znode类型。
- delete(final String path, int version): 如果给定path上的znode 的版和给定的version配置,删除znode
- exists(String path, boolean watch) :判断给定的path上的znode是否存在,并在znode设置一个watch
- getData(final String path, Watcher watcher, Stat stat): 返回给定path上的znode数据,并在znode设置一个watch
- setData(final String path, byte data[], int version): 如果给定path上的znode的版本和给定的version配置,设置znode配置。
- getChildren(final String path, Watcher watcher): 返回给定path上的znode的孩子 znode名字,并在znode设置一个watch
- sync(final String path, VoidCallback cb, Object ctx): 把客户端的session连接节点和leader节点进行同步 。
方法特点
- 所有获取znode数据的api都可以设置一个watch来监控znode的节点变化 。
- 所有更新znode数据的api都有两个版本,无条件更新版本和条件更新版本,如果version为-1 , 更新为无条件更新,否则只给定的version和znode当前的version一样, 才会进行更新,这样的更新是条件更新 。
- 所有的方法都是有同步和异步两个版本, 同步版本的方法发送请求给Zookeeper并等待服务器的响应, 异步版本把请求放到客户端的请求队列,然后马上返回,异步版本通过callback来接受来自服务器端的响应。
public class ZooKeeperTest {
// 注意:逗号前后不能有空格
private static String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
private static int sessionTimeout = 2000;
private ZooKeeper zkClient = null;
@Before
// 创建 ZooKeeper 客户端
public void init() throws Exception {
zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
// 收到事件通知后的回调函数(用户的业务逻辑)
System.out.println(watchedEvent.getType() + "--" + watchedEvent.getPath());
// 再次启动监听
try {
List children = zkClient.getChildren("/", true);
for (String child : children) {
System.out.println(child);
}
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
// 创建子节点
@Test
public void create() throws Exception {
// 参数 1:要创建的节点的路径; 参数 2:节点数据 ; 参数 3:节点权限 ; 参数 4:节点的类型
String nodeCreated = zkClient.create("/atguigu", "shuaige".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
// 测试:在 hadoop102 的 zk 客户端上查看创建节点情况
// [zk: localhost:2181(CONNECTED) 16] get -s /atguigu shuaige
}
@Test // 获取子节点并监听节点变化
public void getChildren() throws Exception {
List children = zkClient.getChildren("/", true);
for (String child : children) {
System.out.println(child);
}
// 延时阻塞
Thread.sleep(Long.MAX_VALUE);
}
//1)在 IDEA 控制台上看到如下节点:
// (2)在 hadoop102 的客户端上创建再创建一个节点/atguigu1,观察 IDEA 控制台 [zk: localhost:2181(CONNECTED) 3] create /atguigu1 "atguigu1"
// (3)在 hadoop102 的客户端上删除节点/atguigu1,观察 IDEA 控制台 [zk: localhost:2181(CONNECTED) 4] delete /atguigu1
// 判断 znode 是否存在
@Test
public void exist() throws Exception {
Stat stat = zkClient.exists("/atguigu", false);
System.out.println(stat == null ? "not exist" : "exist");
}
}
同步创建节点:
@Test
publicvoidcreateTest()throwsKeeperException,InterruptedException{
String path = zooKeeper.create(ZK_NODE, “data”.getBytes(), ZooDefs.Ids.OPEN_ CL_UNSAFE, CreateMode.PERSISTENT);
log.info(“created path: {}”,path); 5
}
异步创建节点:
@Test publicvoidcreateAsycTest()throwsInterruptedException{
zooKeeper.create(ZK_NODE, "data".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT,(rc, path, ctx, name) ‐> log.info("rc {},path {},ctx {},name
{}",rc,path,ctx,name),"context");
TimeUnit.SECONDS.sleep(Integer.MAX_VALUE);
}
修改节点数据
@Test
public void setTest() throws KeeperException,InterruptedException{
Stat stat = new Stat();
byte[] data = zooKeeper.getData(ZK_NODE, false, stat);
log.info(“修改前: {}”,new String(data));
zooKeeper.setData(ZK_NODE, “changed!”.getBytes(), stat.getVersion());
byte[] dataAfter = zooKeeper.getData(ZK_NODE, false, stat);
log.info(“修改后: {}”,new String(dataAfter));
}
Curator开源客户端使用
什么是Curator
Curator 是一套由netflix 公司开源的, Java 语言编程的Zookeepr客户端框架,Curator项目是现在Zookeeper客户端中使用最多, 对Zookeeper 版本支持最好的第三方客户端, 并推荐使用Curator把我们平时常用的很多的Zookeeper 服务开发功能做到封装,例如Leader选举,分布式计数器,分布式锁,这就减少了技术人员在使用Zookeeper时的大部分谨慎细节开发工作,在会话重新连接,Watch反复注册,多种异常处理等使用场景中,用原生的Zookeeper处理比较复杂,而在使用Curator时,由于其对这些功能都做了高度的封装,使用起来更加简单,不但减少了开发时间,而且还增加了程序的可靠性。
Curator是Apache基金会的顶级项目之一,Curator具有更加完善的文档,另外还提供了一套易用性和可读性更强的Fluent风格的客户端API框架。
Curator还为ZooKeeper客户端框架提供了一些比较普遍的、开箱即用的、分布式开发用的解决方案,例如Recipe、共享锁服务、Master选举机制和分布式计算器等,帮助开发者避免了“重复造轮子”的无效开发工作。
在实际的开发场景中,使用Curator客户端就足以应付日常的ZooKeeper集群操作的需求。
官网:https://curator.apache.org/
Curator实战
这里我们以Maven 工程为例,首先要引入Curator框架相关的开发包, 这里为了方便测试引入了junit,lombok,由于Zookeepr 本身以来了log4j日志框架,所以这里可以创建log4j配置文件后直接使用, 如下面的代码所示 , 我们通过将Curator相关的引用包配置到Maven 工程的pom文件中, 将Curator框架引用到工程项目里,在配置文件中分别引用了两个curator相关的包, 第一个是curator-framework包,该包是对Zookeeper 底层API的一些封装, 另一个是curator-recipes包,该包装了一些Zookeeper服务的高级特性, 如Cache 事件监听,选举,分布式锁,分布式Barrier 。
引入依赖
Curator 包含了几个包:
- curator-framework是对ZooKeeper的底层API的一些封装。
- curator-client提供了一些客户端的操作,例如重试策略等。
- curator-recipes封装了一些高级特性,如:Cache事件监听、选举、分布式锁、分布式计数器、分布式Barrier等。
org.apache.curator curator-recipes 5.0.0 org.apache.zookeeper zookeeper org.apache.curator curator-x-discovery 5.0.0 org.apache.zookeeper zookeeper org.apache.zookeeper zookeeper 3.5.8 junit junit 4.13 org.projectlombok lombok 1.18.12 com.fasterxml.jackson.core jackson-databind 2.8.3
会话创建
要进行客户端服务器交互,第一步就是要创建会话 ,Curator提供了多种方式创建会话 , 比如静态工厂方式创建 。
public static void main(String[] args) throws Exception {
RetryPolicy retryPolicy=new ExponentialBackoffRetry( 5*1000, 10 );
String connectStr = "192.168.109.200:2181,192.168.109.200:2182,192.168.109.200:2183,192.168.109.200:2184";
CuratorFramework curatorFramework = CuratorFrameworkFactory.newClient(connectStr, retryPolicy);
curatorFramework.start();
String pathWithParent = "/test";
byte[] bytes = curatorFramework.getData().forPath(pathWithParent);
System.out.println(new String(bytes));
while (true) {
try {
byte[] bytes2 = curatorFramework.getData().forPath(pathWithParent);
System.out.println(new String(bytes2));
TimeUnit.SECONDS.sleep(5);
} catch (Exception e) {
e.printStackTrace();
}
}
}
使用工厂类CuratorFrameworkFactory的静态builder构造者方法。
public void init() {
RetryPolicy retryPolicy = new ExponentialBackoffRetry(5000, 30);
curatorFramework = CuratorFrameworkFactory.builder().connectString(getConnectStr())
.retryPolicy(retryPolicy)
.sessionTimeoutMs(sessionTimeoutMs)
.connectionTimeoutMs(connectionTimeoutMs)
.canBeReadOnly(true)
.build();
curatorFramework.getConnectionStateListenable().addListener((client, newState) -> {
if (newState == ConnectionState.CONNECTED) {
log.info("连接成功!");
}
});
log.info("连接中......");
curatorFramework.start();
}
这段代码编码风格采用了流式方式,最核心的类是CuratorFramework类。 该类作用是定义一个Zookeeper客户端对象,并在之后的上下文中使用, 在定义CuratorFramework对象实例的时候,我们使用了CuratorFrameworkFactory工厂方法,并指定了connectionString服务器地址列表,retryPolicy重试策略,sessionTimeoutMs会话超时时间, connectionTimeoutMs会话创建超时时间,下面我们分别对这几个参数进行讲解 。
connectionString :
服务器地址列表 , 在指定的服务器地址列表的时候可以是一个地址,也可以是多个地址,如果是多个地址,那么每个服务器地址列表用逗号分隔,如host1:port1, host2:port2,host3:port3。
retryPolicy : 重试策略
当客户端异常退出或者与服务端失去连接的时候,可以通过设置客户端重新链接Zookeeper服务端,而Curator提供了一次重试,多次重试等不各类的实现方式,在Curator内部,可以通过判断服务器返回的keeperExcetion的状态码来判断是否进行重试处理, 如果返回的是ok表示一切操作没有问题,而SYSTEMERROR 端错误 。
| 策略名称 | 描述 |
|---|---|
| ExponentialBackoffRetry | 重试一组次数,重试之间的睡眠时间增加 |
| RetryNTimes | 重试最大次数 |
| RetryOneTime | 只重试一次 |
| RetryUntilElapsed | 在给定的时间结束之前重试 |
- 超时时间: Curator客户端创建过程中, 有两个超时时间的设置 。 一个是sessionTimeoutMs会话超时时间,用来设置该条会话在Zookeeper 服务端的失效时间,另一个是connectionTimeoutMs 客户端创建会话的超时时间,用来限制客户端发起一个会话连接到接收Zookeeper服务端应答时间,sessionTimeoutMs 作用在服务端,而connectionTimeoutMs作用在客户端 。
创建节点
创建节点的方式如下面的代码所示 , 回顾我们之前的讲到的内容,描述一个节点要包括节点的类型, 即临时节点还是持久节点,节点的数据信息,节点是否有序节点等属性性质 。
public void testCreate()throwsException{
String path = curatorFramework.create().forPath(“/curator‐node”);
// curatorFramework.create().withMode(CreateMode.PERSISTENT).forPath(“/curatr‐node”,“some‐data”.getBytes())
log.info(“curator create node :{} successfully.”,path);
}
在Curator中,可以使用create 函数创建数据节点,并通过withMode函数指定节点类型,持久化节点,临时节点,顺序节点持久化顺序节点,默认是持久化节点,之后调用forPath函数来指定节点的路径和数据信息。
一次性创建带层级结构的节点
@Test
public void testCreateWithParent()throwsException{
String pathWithParent=“/node‐parent/sub‐node‐1”;
String path = curatorFramework.create().creatingParentsIfNeeded().forPath(pa
hWithParent);
log.info(“curator create node :{} successfully.”,path);
}
获取数据
@Test
public void testGetData()throwsException{
byte[] bytes = curatorFramework.getData().forPath(“/curator‐node”);
log.info(“get data from node :{} successfully.”,new String(bytes));
}
更新节点
我们可以通过实例的setData()方法更新Zookeeper服务上的数据节点,在setData方法后边,通过forPath函数来指定节点路径以及更新的数据 。
@Test
public void testSetData()throwsException{
curatorFramework.setData().forPath(“/curator‐node”,“changed!”.getBytes());
byte[] bytes = curatorFramework.getData().forPath(“/curator‐node”);
log.info(“get data from node /curator‐node :{} successfully.”,new String(byts));
}
删除节点
@Test
public void testDelete()throwsException{
String pathWithParent=“/node‐parent”;
curatorFramework.delete().guaranteed().deletingChildrenIfNeeded().forPath(pa hWithParent);
}
guaranteed:该函数的功能如字面意思一样, 主要起到一个保障删除成功的作用, 其底层工作方式,只要该客户端会话有效,就会在后台持续发起删除请求,直到该数据节点在ZooKeeper服务端被删除 。
deletingChildrenIfNeeded: 指定了该函数后,系统在删除该数据节点的时候会以递归的方式直接删除掉其子节点,以及子节点的子节点 。
异步接口
Curator 引入了BackgroundCallback 接口,用来处理服务器端返回来的信息,这个处理过程是 在异步线程中调用,默认在 EventThread 中调用,也可以自定义线程池。
publicinterfaceBackgroundCallback 2{
/**
Called when the async background operation completes
@param client the client
@param event operation result details
@throws Exception errors
*/
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception;
}
如下接口,主要参数为client客户端和服务端事件event inBackground 异步处理默认在EventThread中执行。
@Test
public void test()throws Exception{
curatorFramework.getData().inBackground((item1, item2) ‐> {
log.info(" background: {}", item2);
}).forPath(ZK_NODE);
TimeUnit.SECONDS.sleep(Integer.MAX_VALUE);
}
指定线程池
@Test
public void testThreadPool() throws Exception {
CuratorFramework curatorFramework = getCuratorFramework();
ExecutorService executorService = Executors.newSingleThreadExecutor();
String ZK_NODE="/zk-node";
curatorFramework.getData().inBackground((client, event) -> {
log.info(" background: {}", event);
},executorService).forPath(ZK_NODE);
}
Curator 监听器:
public interface CuratorListener{
/**
* Called when a background task has completed or a watch has triggered
*
* @param client client
* @param event the event
* @throws Exception any errors
*/
public void eventReceived(CuratorFramework client, CuratorEvent event) throws Exception;
}
针对background通知错误通知,使用此监听器后, 调用inBackground方法会异步获得监听 。
Curator Caches:
Curator引入了Cache来实现对Zookeeper服务端事件监听 , Cache事件监听可以理解为一个本地缓存视图与远程Zookeeper视图的对比过程 , Cache提供了反复注册的功能,Cache分为两类注册类型, 节点监听和子节点监听 。
node cache:
NodeCache 对某一个节点进行监听
public class NodeCache implements Closeable{
private final Logger log = LoggerFactory.getLogger(getClass());
private final WatcherRemoveCuratorFramework client;
private final String path;
}
可以通过注册监听器来实现,对当前节点数据变化的处理
public class NodeCacheTest extends CuratorStandaloneBase{
public static final String NODE_CACHE="/node-cache";
@Test
public void testNodeCacheTest() throws Exception {
CuratorFramework curatorFramework = getCuratorFramework();
createIfNeed(NODE_CACHE);
NodeCache nodeCache = new NodeCache(curatorFramework, NODE_CACHE);
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
log.info("{} path nodeChanged: ",NODE_CACHE);
printNodeData();
}
});
nodeCache.start();
}
public void printNodeData() throws Exception {
CuratorFramework curatorFramework = getCuratorFramework();
byte[] bytes = curatorFramework.getData().forPath(NODE_CACHE);
log.info("data: {}",new String(bytes));
}
}
path Cache
PathChildrenCache会对子节点进行监听 ,但不会对二级子节点进行监听
public class PathChildrenCache implements Closeable
{
private final Logger log = LoggerFactory.getLogger(getClass());
private final WatcherRemoveCuratorFramework client;
private final String path;
}
可以通过注册监听器来实现,对当前节点的子节点数据变化的处理
@Slf4j
public class PathCacheTest extends CuratorBaseOperations{
public static final String PATH="/path-cache";
@Test
public void testPathCache() throws Exception {
CuratorFramework curatorFramework = getCuratorFramework();
createIfNeed(PATH);
PathChildrenCache pathChildrenCache = new PathChildrenCache(curatorFramework, PATH, true);
pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {
log.info("event: {}",event);
}
});
// 如果设置为true则在首次启动时就会缓存节点内容到Cache中
pathChildrenCache.start(true);
}
}
tree cache
TreeCache使用了一个内部类TreeNode来维护这个一个树结构,并将这个树结构与ZK节点进行了映射, 所以TreeCache可以监听当前节点下所有节点的事件 。
@Slf4j
public class TreeCacheTest extends CuratorBaseOperations{
public static final String TREE_CACHE="/tree-path";
@Test
public void testTreeCache() throws Exception {
CuratorFramework curatorFramework = getCuratorFramework();
createIfNeed(TREE_CACHE);
TreeCache treeCache = new TreeCache(curatorFramework, TREE_CACHE);
treeCache.getListenable().addListener(new TreeCacheListener() {
@Override
public void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {
log.info(" tree cache: {}",event);
Map currentChildren = treeCache.getCurrentChildren(TREE_CACHE);
log.info("currentChildren: {}",currentChildren);
}
});
treeCache.start();
}
}
Zookeeper在分布式命名服务中的实践
命名服务是为系统中的资源提供标识能力。ZooKeeper的命名服务主要是利用ZooKeeper节点的树形分层结构和子节点的顺序维护能力,来为分布式系统中的资源命名。
哪些应用场景需要用到分布式名称服务呢 ? 典型的有
- 分布式API目录
- 分布式节点命名
- 分布式ID生成器。
分布式API目录
为分布式系统中各种API接口服务名称,链接地址,提供了类似于JNDI(Java 命名和目录接口)中的文件系统的功能 。借助于Zookeeper的树形分层结构就能提供分布式API调用功能 。
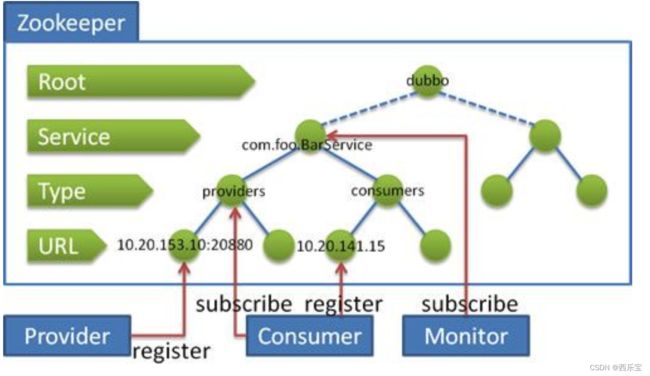
莫名的Doubbo分布式框架就是应用了Zookeeper的分布式JNDI的功能,在Doubbo中,使用了Zookeeper维护了全局服务器接口的API的地址列表 , 大致的思路为:
- 服务提供者(Service Provider)在启动的时候,向Zookeeper上的指定节点/dubbo/${serviceName}/providers 写入了自己的API地址,这个操作就相当于对服务的公开
- 服务消费者(Consumer)启动的时候,调用订阅节点/dubbo/{serverName}/providers下的服务器提供者的URL地址,获得所有的服务提供者的 API
分布式节点的命名
一个分布式系统通常会由很多的节点组成,节点的数量不是固定的, 而是不断的变化的, 比如说,当业务不断膨胀和流量洪峰到来时, 大量的节点会动态的加入到集群中,而一旦流量的洪峰过去,就需要大量的节点,再比如说, 由于机器或者网络原因,一些节点会主动离开集群。
如何大量的动态节点命名呢? 一个简单的办法就是可以通过配置文件,手动为每一个节点命名, 但是,如果节点的数据量太大,或者说变动频繁,手动命名则不现实 , 这就需要用到分布式命名服务 。
可用的生成集群节点的编号的方案:
- 使用数据库自增ID 特性, 用数据表存储机器的MAC地址或者IP来维护
- 使用Zookeeper持久顺序节点的顺序特性来维护节点的NodeId编号 。
在第2种方案中,集群节点命名服务的基本流程是
- 启动节点服务,连接Zookeeper,检查命名服务根节点是否存在 ,如果不存在 ,就创建系统的根节点 。
- 在根节点下创建一个临时顺序ZNode节点,取回ZNode的编号把它作为分布式系统的节点NODEID .
- 如果临时节点太多, 可以根据删除的临时顺序ZNode节点 。
分布式的ID生成器
在分布式系统中, 分布式ID生成器的使用场景非常之多 。
- 大量的数据记录,需要分布式ID
- 大量的系统消息,需要分布式ID
- 大量的请求日志,如restful的操作记录,需要唯一标识,以便进行后续的用户行为分析的调用链路分析
- 分布式节点命名服务,往往也需要分布式ID。
- 。。。
传统的数据库自增主键已经不能满足需求 , 在分布式系统环境中, 迫切需要一种全新的唯一ID 系统 , 这种系统需要满足以下的需求 。
- 全局唯一 ,不能出现重复的ID
- 高可用 , ID生成系统是基础系统,被许多的系统调用,一旦出现宕机 ,就会造成严重的影响 。
哪些分布式的ID生成器方案呢? 大致如下
- Java 的UUID
- 分布式缓存Redis生成ID:利用Redis的原子操作INCR和INCRBY,生成全局唯一的ID。
- Twitter的SnowFlake算法。
- ZooKeeper生成ID:利用ZooKeeper的顺序节点,生成全局唯一的ID。
- MongoDb的ObjectId:MongoDB是一个分布式的非结构化NoSQL数据库,每插入一条记录会自动生成全局唯一的一个“_id”字段值,它是一个12字节的字符串,可以作为分布式系统中全局唯一的ID。
基于Zookeeper 实现分布式ID 生成器
在Zookeeper节点的四种类型中, 其中以下两种类型具有自动编号的能力 。
- PERSISTENT_SEQUENTIAL持久化顺序节点。
- EPHEMERAL_SEQUENTIAL临时顺序节点。
Zookeeper的每一个节点都会成为它的第一个级子节点维护一份顺序编号,会记录每一个子节点的创建先后顺序,这个顺序编号是分布式同步的, 也是全局唯一的。
可以通过创建Zookeeper的临时顺序节点的方法 , 生成全局唯一的ID .
@Slf4j
public class IDMaker extends CuratorBaseOperations {
private String createSeqNode(String pathPefix) throws Exception {
CuratorFramework curatorFramework = getCuratorFramework();
//创建一个临时顺序节点
String destPath = curatorFramework.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.EPHEMERAL_SEQUENTIAL)
.forPath(pathPefix);
return destPath;
}
public String makeId(String path) throws Exception {
String str = createSeqNode(path);
if(null != str){
//获取末尾的序号
int index = str.lastIndexOf(path);
if(index>=0){
index+=path.length();
return index<=str.length() ? str.substring(index):"";
}
}
return str;
}
}
测试
@Test
public void testMarkId() throws Exception {
IDMaker idMaker = new IDMaker();
idMaker.init();
String pathPrefix = "/idmarker/id-";
for(int i=0;i<5;i++){
new Thread(()->{
for (int j=0;j<10;j++){
String id = null;
try {
id = idMaker.makeId(pathPrefix);
log.info("{}线程第{}个创建的id为{}",Thread.currentThread().getName(),
j,id);
} catch (Exception e) {
e.printStackTrace();
}
}
},"thread"+i).start();
}
Thread.sleep(Integer.MAX_VALUE);
}
测试结果

基于Zookeeper实现SnowFlakeID算法
Twitter(推特)的SnowFlake算法是一种著名的分布式服务器用户ID生成算法。SnowFlake算法所生成的ID是一个64bit的长整型数字,如图10-2所示。这个64bit被划分成四个部分,其中后面三个部分分别表示时间戳、工作机器ID、序列号。

SnowFlakeID的四个部分,具体介绍如下:
(1)第一位 占用1 bit,其值始终是0,没有实际作用。
(2)时间戳 占用41 bit,精确到毫秒,总共可以容纳约69年的时间。
(3)工作机器id占用10 bit,最多可以容纳1024个节点。
(4)序列号 占用12 bit。这个值在同一毫秒同一节点上从0开始不断累加,最多可以累加到4095。
在工作节点达到1024顶配的场景下,SnowFlake算法在同一毫秒最多可以生成的ID数量为: 1024 * 4096 =4194304,在绝大多数并发场景下都是够用的。
SnowFlake算法的优点:
- 生成ID时不依赖于数据库,完全在内存生成,高性能和高可用性。
- 容量大,每秒可以生成几百万个ID
- ID呈趋势递增,后续插入的数据库索引树,性能较高
SnowFlake算法的缺点:
- 依赖于系统时钟的一致性,如果某台机器的系统时钟回拨了,有可能造成ID冲突,或者ID乱序。
- 在启动之前,如果这台机器的系统时间回拨过,那么有可能出现ID重复的危险。
基于zookeeper实现雪花算法:
package zookeeper.client;
public class SnowflakeIdGenerator {
//单例
public static SnowflakeIdGenerator instance = new SnowflakeIdGenerator();
/**
* 初始化单例
* @param workerId 节点Id,最大8091
* @return the 单例
*/
public synchronized void init(long workerId) {
if (workerId > MAX_WORKER_ID) {
// zk分配的workerId过大
throw new IllegalArgumentException("woker Id wrong: " + workerId);
}
instance.workerId = workerId;
}
private SnowflakeIdGenerator() {
}
/**
* 开始使用该算法的时间为: 2017-01-01 00:00:00
*/
private static final long START_TIME = 1483200000000L;
/**
* worker id 的bit数,最多支持8192个节点
*/
private static final int WORKER_ID_BITS = 13;
/**
* 序列号,支持单节点最高每毫秒的最大ID数1024
*/
private final static int SEQUENCE_BITS = 10;
/**
* 最大的 worker id ,8091
* -1 的补码(二进制全1)右移13位, 然后取反
*/
private final static long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);
/**
* 最大的序列号,1023
* -1 的补码(二进制全1)右移10位, 然后取反
*/
private final static long MAX_SEQUENCE = ~(-1L << SEQUENCE_BITS);
/**
* worker 节点编号的移位
*/
private final static long WORKER_ID_SHIFT = SEQUENCE_BITS;
/**
* 时间戳的移位
*/
private final static long TIMESTAMP_LEFT_SHIFT = WORKER_ID_BITS + SEQUENCE_BITS;
/**
* 该项目的worker 节点 id
*/
private long workerId;
/**
* 上次生成ID的时间戳
*/
private long lastTimestamp = -1L;
/**
* 当前毫秒生成的序列
*/
private long sequence = 0L;
public Long nextId() {
return generateId();
}
/**
* 生成唯一id的具体实现
*/
private synchronized long generateId() {
long current = System.currentTimeMillis();
if (current < lastTimestamp) {
// 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过,出现问题返回-1
return -1;
}
if (current == lastTimestamp) {
// 如果当前生成id的时间还是上次的时间,那么对sequence序列号进行+1
sequence = (sequence + 1) & MAX_SEQUENCE;
if (sequence == MAX_SEQUENCE) {
// 当前毫秒生成的序列数已经大于最大值,那么阻塞到下一个毫秒再获取新的时间戳
current = this.nextMs(lastTimestamp);
}
} else {
// 当前的时间戳已经是下一个毫秒
sequence = 0L;
}
// 更新上次生成id的时间戳
lastTimestamp = current;
// 进行移位操作生成int64的唯一ID
//时间戳右移动23位
long time = (current - START_TIME) << TIMESTAMP_LEFT_SHIFT;
//workerId 右移动10位
long workerId = this.workerId << WORKER_ID_SHIFT;
return time | workerId | sequence;
}
/**
* 阻塞到下一个毫秒
*/
private long nextMs(long timeStamp) {
long current = System.currentTimeMillis();
while (current <= timeStamp) {
current = System.currentTimeMillis();
}
return current;
}
}
Zookeeper的经典使用场景
什么是分布式锁。
在单体应用开发场景中涉及并发同步的时候,大家往往采用Synchronized(同步),或者其他同一个JVM内Lock机制来解决多线程间的同步问题, 在分布式集群工作开发场景中,就需要一种更高级的锁机制来处理跨机器进程之间的数据同步问题,这种跨机器锁就是分布式锁。
目前分布式锁,比较成熟,主流的方案。
- 基于数据库的分布式锁,db操作性能较差, 并且有锁表的风险 , 一般不考虑
- 基于Redis的分布式锁, 适用于并发量大,性能要求很高而且可靠性可以通过其他方案去弥补的场景 。
- 基于Zookeeper的分布式锁, 适用于高可靠高可用 , 而且并发量不是太高的场景 。
基于数据库设计思路
可以利用数据库的唯一索引来实现,唯一索引天然具有排他性
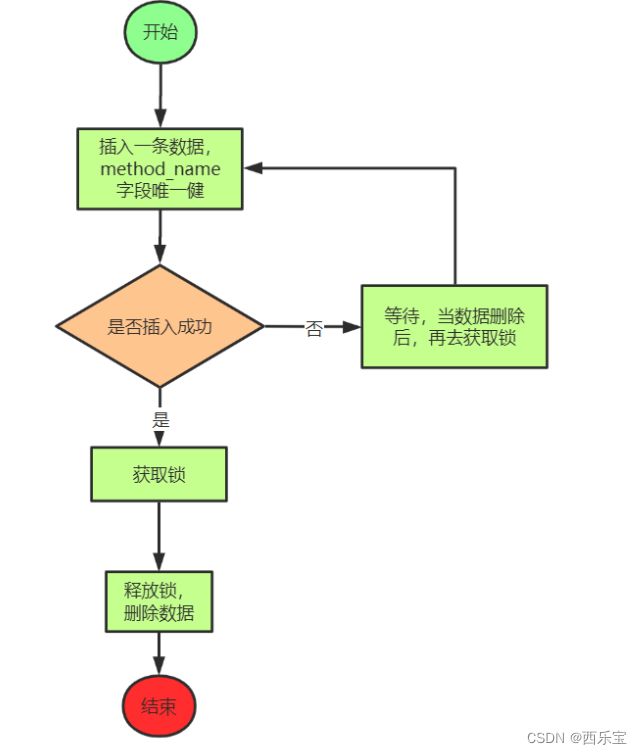
思考:基于数据库实现分布式锁存在什么问题?
基于Zookeeper设计思路一
使用临时 znode 来表示获取锁的请求,创建 znode成功的用户拿到锁。
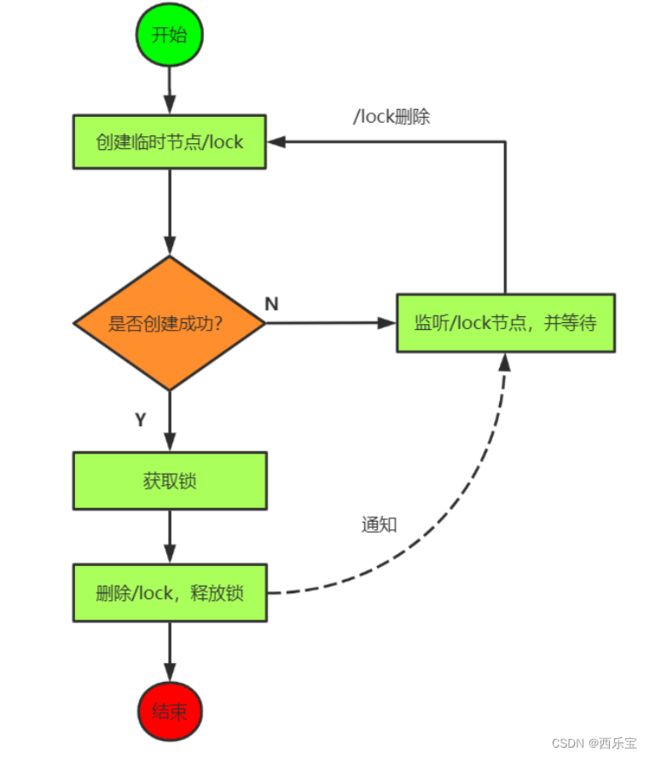
思考:上述设计存在什么问题?
如果所有的锁请求者都 watch 锁持有者,当代表锁持有者的 znode 被删除以后,所有的锁请求者都会通知到,但是只有一个锁请求者能拿到锁。这就是羊群效应。
基于Zookeeper设计思路二
使用临时顺序 znode 来表示获取锁的请求,创建最小后缀数字 znode 的用户成功拿到锁。
公平锁的实现
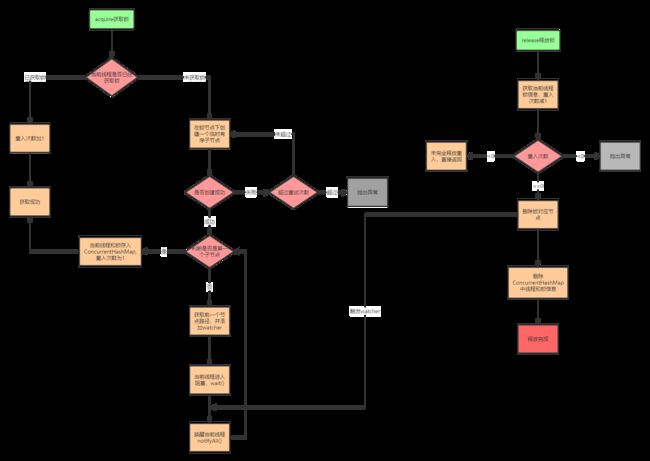
在实际的开发中,如果需要使用到分布式锁,不建议去自己“重复造轮子”,而建议直接使用Curator客户端中的各种官方实现的分布式锁,例如其中的InterProcessMutex可重入锁。
Curator 可重入分布式锁工作流程
https://www.processon.com/view/link/5cadacd1e4b0375afbef4320
总结
优点:ZooKeeper分布式锁(如InterProcessMutex),具备高可用、可重入、阻塞锁特性,可解决失效死锁问题,使用起来也较为简单。
缺点:因为需要频繁的创建和删除节点,性能上不如Redis。
在高性能、高并发的应用场景下,不建议使用ZooKeeper的分布式锁。而由于ZooKeeper的高可用性,因此在并发量不是太高的应用场景中,还是推荐使用ZooKeeper的分布式锁。
Zookeeper注册中心实战
用于服务注册和服务发现 CP
基于 ZooKeeper 本身的特性可以实现注册中心
https://spring.io/projects/spring-cloud-zookeeper#learn
第一步:在父pom文件中指定Spring Cloud版本
org.springframework.boot spring-boot-starter-parent 2.3.2.RELEASE 1.8 Hoxton.SR8 org.springframework.cloud spring-cloud-dependencies ${spring-cloud.version} pom import
注意: springboot和springcloud的版本兼容问题
第二步:微服务pom文件中引入Spring Cloud Zookeeper注册中心依赖
org.springframework.cloud spring-cloud-starter-zookeeper-discovery org.apache.zookeeper zookeeper org.apache.zookeeper zookeeper 3.8.0
注意: zookeeper客户端依赖和zookeeper sever的版本兼容问题
Spring Cloud整合Zookeeper注册中心核心源码入口: ZookeeperDiscoveryClientConfiguration
第三步: 微服务配置文件application.yml中配置zookeeper注册中心地址
spring:
cloud:
zookeeper:
connect-string: localhost:2181
discovery:
instance-host: 127.0.0.1
注册到zookeeper的服务实例元数据信息如下:

注意:如果address有问题,会出现找不到服务的情况,可以通过instance-host配置指定
第四步:整合feign进行服务调用
@RequestMapping(value = "/findOrderByUserId/{id}")
public R findOrderByUserId(@PathVariable("id") Integer id) {
log.info("根据userId:"+id+"查询订单信息");
//feign调用
R result = orderFeignService.findOrderByUserId(id);
return result;
}
测试:http://localhost:8040/user/findOrderByUserId/1
ZooKeeper 分布式锁案例
什么叫做分布式锁呢?
比如说"进程 1"在使用该资源的时候,会先去获得锁,"进程 1"获得锁以后会对该资源保持独占,这样其他进程就无法访问该资源,"进程 1"用完该资源以后就将锁释放掉,让其 他进程来获得锁,那么通过这个锁机制,我们就能保证了分布式系统中多个进程能够有序的 访问该临界资源。那么我们把这个分布式环境下的这个锁叫作分布式锁。
非公平锁:
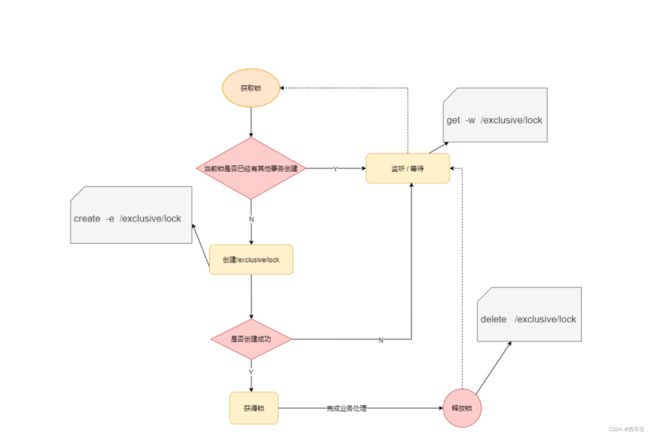
如上实现方式在并发比较严重的情况下, 性能会下降得比较厉害,主要原因是, 所有的连接都在同一个节点进行监听 , 当服务器检测到删除事件时,要通知所有的连接, 所有的连接同时收到事件,再次并发竞争,这就是羊群效应,如何避免呢? 我们看下面的这种方式 。
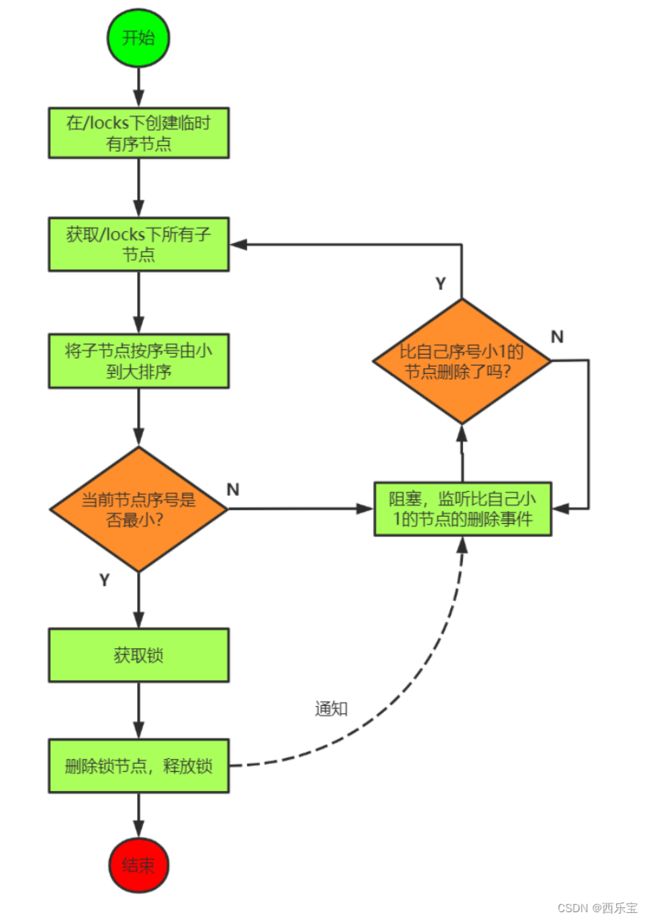
公平锁:

- 请求进来 , 直接在/lock节点下创建一个临时顺序节点 。
- 判断自己是不是lock节点下的最小节点 。
a. 是最小的,获得锁。
b.不是,对前面的节点进行监听(watch) - 获得锁的请求同,处理完释放锁, 即delete节点,然后后继第一个节点将收到通知,重复第2步的判断 。
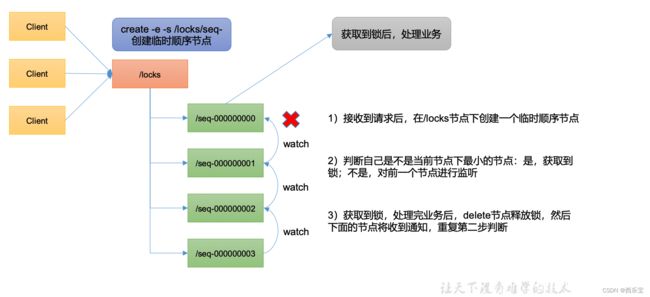
原生 Zookeeper 实现分布式锁案例
public class DistributedLock {
// zookeeper server 列表
private String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
// 超时时间
private int sessionTimeout = 2000;
private ZooKeeper zk;
private String rootNode = "locks";
private String subNode = "seq-"; // 当前 client 等待的子节点
private String waitPath;
//ZooKeeper 连接
private CountDownLatch connectLatch = new CountDownLatch(1);
//ZooKeeper 节点等待
private CountDownLatch waitLatch = new CountDownLatch(1);
// 当前 client 创建的子节点
private String currentNode;
// 和 zk 服务建立连接,并创建根节点
public DistributedLock() throws IOException, InterruptedException, KeeperException {
zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
// 连接建立时, 打开 latch, 唤醒 wait 在该 latch 上的线程
if (event.getState() == Event.KeeperState.SyncConnected) {
connectLatch.countDown();
}
// 发生了 waitPath 的删除事件
if (event.getType() == Event.EventType.NodeDeleted && event.getPath().equals(waitPath)) {
waitLatch.countDown();
}
}
});
// 等待连接建立
connectLatch.await();
//获取根节点状态
Stat stat = zk.exists("/" + rootNode, false);
//如果根节点不存在,则创建根节点,根节点类型为永久节点
if (stat == null) {
System.out.println("根节点不存在");
zk.create("/" + rootNode, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
// 加锁方法
public void zkLock() {
try {
//在根节点下创建临时顺序节点,返回值为创建的节点路径
currentNode = zk.create("/" + rootNode + "/" + subNode, null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// wait 一小会, 让结果更清晰一些
Thread.sleep(10);
// 注意, 没有必要监听"/locks"的子节点的变化情况
List childrenNodes = zk.getChildren("/" + rootNode, false);
// 列表中只有一个子节点, 那肯定就是 currentNode , 说明 client 获得锁
if (childrenNodes.size() == 1) {
return;
} else { //对根节点下的所有临时顺序节点进行从小到大排序
Collections.sort(childrenNodes);
//当前节点名称
String thisNode = currentNode.substring(("/" + rootNode + "/").length()); //获取当前节点的位置 client 获得锁
int index = childrenNodes.indexOf(thisNode);
if (index == -1) {
System.out.println("数据异常");
} else if (index == 0) {
// index == 0, 说明 thisNode 在列表中最小, 当前
return;
} else {
// 获得排名比 currentNode 前 1 位的节点
this.waitPath = "/" + rootNode + "/" + childrenNodes.get(index - 1);
// 在 waitPath 上注册监听器, 当 waitPath 被删除时, zookeeper 会回调监听器的 process 方法
zk.getData(waitPath, true, new Stat()); //进入等待锁状态
waitLatch.await();
return;
}
}
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 解锁方法
public void zkUnlock() {
try {
zk.delete(this.currentNode, -1);
} catch (InterruptedException | KeeperException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws InterruptedException, IOException, KeeperException {
// 创建分布式锁 1
final DistributedLock lock1 = new DistributedLock(); // 创建分布式锁 2
final DistributedLock lock2 = new DistributedLock();
new Thread(new Runnable() {
@Override
public void run() { // 获取锁对象
try {
lock1.zkLock();
System.out.println("线程 1 获取锁");
Thread.sleep(5 * 1000);
lock1.zkUnlock();
System.out.println("线程 1 释放锁");
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {// 获取锁对象
try {
lock2.zkLock();
System.out.println("线程 2 获取锁");
Thread.sleep(5 * 1000);
lock2.zkUnlock();
System.out.println("线程 2 释放锁");
} catch (
Exception e) {
e.printStackTrace();
}
}
}).start();
}
}
2)观察控制台变化:
线程1获取锁
线程1释放锁
线程2获取锁
线程2释放锁
Curator 框架实现分布式锁案例
public class CuratorLockTest {
private String rootNode = "/locks";
// zookeeper server 列表
private String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
// connection超时时间
private int connectionTimeout = 2000;
// session 超时时间
private int sessionTimeout = 2000;
public static void main(String[] args) {
new CuratorLockTest().test();
}
// 测试
private void test() {
// 创建分布式锁 1
final InterProcessLock lock1 = new InterProcessMutex(getCuratorFramework(), rootNode);
// 创建分布式锁 2
final InterProcessLock lock2 = new InterProcessMutex(getCuratorFramework(), rootNode);
new Thread(new Runnable() {
@Override
public void run() { // 获取锁对象
try {
lock1.acquire();
System.out.println("线程 1 获取锁");
// 测试锁重入
lock1.acquire();
System.out.println("线程 1 再次获取锁");
Thread.sleep(5 * 1000);
lock1.release();
System.out.println("线程 1 释放锁");
lock1.release();
System.out.println("线程 1 再次释放锁");
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() { // 获取锁对象
try {
lock2.acquire();
System.out.println("线程 2 获取锁");
// 测试锁重入
lock2.acquire();
System.out.println("线程 2 再次获取锁");
Thread.sleep(5 * 1000);
lock2.release();
System.out.println("线程 2 释放锁");
lock2.release();
System.out.println("线程 2 再次释放锁");
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
// 分布式锁初始化
public CuratorFramework getCuratorFramework() {
//重试策略,初试时间 3 秒,重试 3 次
RetryPolicy policy = new ExponentialBackoffRetry(3000, 3);
//通过工厂创建 Curator
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString(connectString).connectionTimeoutMs(connectionTimeout).sessionTimeoutMs(sessionTimeout).retryPolicy(policy).build();
//开启连接
client.start();
System.out.println("zookeeper 初始化完成...");
return client;
}
}
2)观察控制台变化:
线程1获取锁
线程 1 再次获取锁
线程1释放锁
线程 1 再次释放锁
线程2获取锁
线程 2 再次获取锁
线程2释放锁
线程 2 再次释放锁
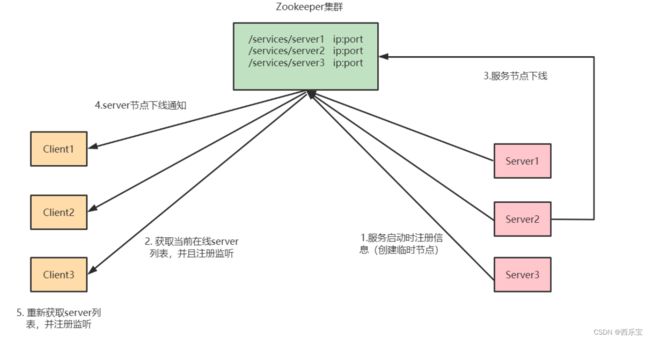
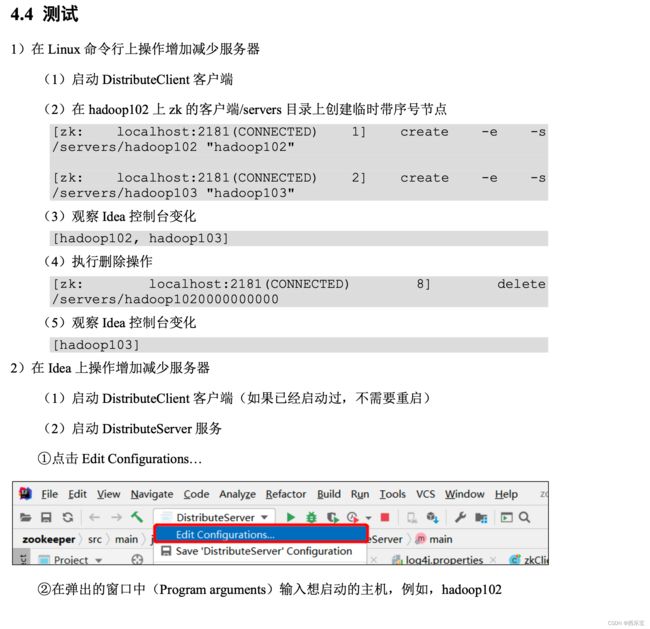
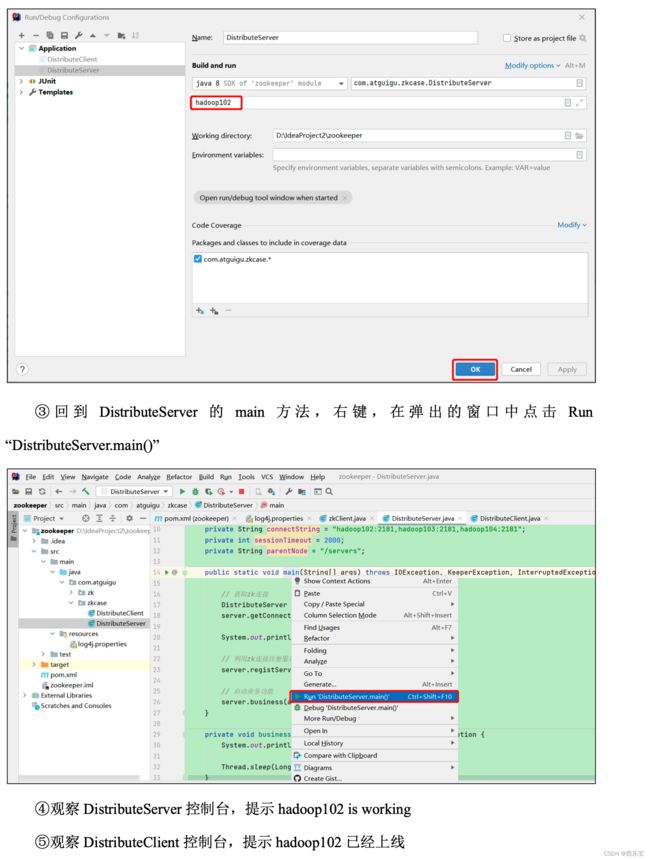
服务器动态上下线


public class DistributeServer {
private static String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
private static int sessionTimeout = 2000;
private ZooKeeper zk = null;
private String parentNode = "/servers";
// 创建到 zk 的客户端连接
public void getConnect() throws IOException {
zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
}
});
}
// 注册服务器
public void registServer(String hostname) throws Exception {
String create = zk.create(parentNode + "/server", hostname.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println(hostname + " is online " + create);
}
// 业务功能
public void business(String hostname) throws Exception {
System.out.println(hostname + " is working ...");
Thread.sleep(Long.MAX_VALUE);
}
public static void main(String[] args) throws Exception {
// 1获取zk连接
DistributeServer server = new DistributeServer();
server.getConnect();
// 2 利用 zk 连接注册服务器信息
server.registServer(args[0]);
// 3 启动业务功能
server.business(args[0]);
}
}
客户端代码
public class DistributeClient {
private static String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
private static int sessionTimeout = 2000;
private ZooKeeper zk = null;
private String parentNode = "/servers";
// 创建到 zk 的客户端连接
public void getConnect() throws IOException {
zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
// 再次启动监听
try {
getServerList();
} catch (
Exception e) {
e.printStackTrace();
}
}
});
}
// 获取服务器列表信息
public void getServerList() throws Exception {
// 1获取服务器子节点信息,并且对父节点进行监听
List children = zk.getChildren(parentNode, true);
// 2存储服务器信息列表
ArrayList servers = new ArrayList<>();
// 3遍历所有节点,获取节点中的主机名称信息
for (String child : children) {
byte[] data = zk.getData(parentNode + "/" + child, false, null);
servers.add(new String(data));
}
// 4打印服务器列表信息
System.out.println(servers);
}
// 业务功能
public void business() throws Exception {
System.out.println("client is working ...");
Thread.sleep(Long.MAX_VALUE);
}
public static void main(String[] args) throws Exception {
// 1获取zk连接
DistributeClient client = new DistributeClient();
client.getConnect();
// 2获取servers的子节点信息,从中获取服务器信息列表 client.getServerList();
// 3业务进程启动
client.business();
}
}
CAP&Base理论
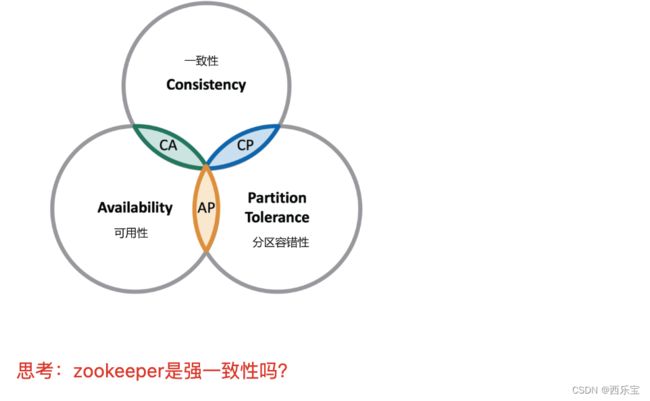
CAP理论指出对于一个分布式系统而言, 不可能同时满足以下三点:
- 一致性: 在分布式环境中,一致性是指数据在多个副本之间是否能够保持一致性的特性,等同于所有的节点访问同一份最新数据副本 , 在一致性的需求下, 当一个系统在数据一致性的状态下执行更新操作后,应该保证系统的数据仍然处于一致性的状态 。
- 可用性,每次请求都能获取到正确的响应, 但是不保证获取的数据为最新数据 。
- 分区容错性: 分布式系统在遇到任何网络分区故障的时候,仍然需要能够保持对外提供满足一致性和可用性服务 , 除非是整个网络环境都发生了故障 。
一个分布式系统最多只能同时满足一致性(Consistency),可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项 。
在这三个需求中, 最多同时满足其中的两项,P是必须的,因此只能在CP和AP中选择,zookeeper保证的是CP , 对比Spring Clound 系统中的注册中心是eureka实现的AP 。


BASE理论
BASE 是Basically Available(基本可用),Soft-state(软状态 )和Eventually Consistent(最终一致性)三个短语的缩写 。
- 基本可用 : 在分布式系统出现故障,允许损失部分可用性(服务降级, 页面降级) 。
- 软状态 : 允许分布式系统出现中间状态, 而且中间状态不影响系统的可用性, 这里的中间状态是指不同的data replication(数据备份节点) 之间的数据更新可以出现延迟的最终一致性。
- 最终一致性: data replications 经过一段时间达到一致性。
BASE 理论是对CAP 中的一致性和可用性进行了一次权衡的结果,理论的核心思想就是我们无法做到强一致,但是每个应用都可以根据自身业务的特点,采用适当的方式来达到最终一致性。
强一致性:又称为线程一致性(linearizability )
- 任意时刻,所有节点中的数据是一样的,
- 一个集群需要对外部提供强一致性,所以只要集群内部某一台服务器的数据发生了改变,那么就需要等待集群内其他服务器的数据同步完成后,才能正常的对外提供服务
- 保证了强一致性,务必会损耗可用性
弱一致性:
- 系统中的某个数据被更新后,后续对该数据的读取操作可能得到更新后的值,也可能是更改前的值。
- 即使过了不一致时间窗口,后续的读取也不一定能保证一致。
最终一致性:
- 弱一致性的特殊形式,不保证在任意时刻任意节点上的同一份数据都是相同的,但是随着时间的迁移,不同节点上的同一份数据总是在向趋同的方向变化
- 存储系统保证在没有新的更新的条件下,最终所有的访问都是最后更新的值
顺序一致性:
- 任何一次读都能读到某个数据的最近一次写的数据。
- 对其他节点之前的修改是可见(已同步)且确定的,并且新的写入建立在已经达成同步的基础上。
Zookeeper写入是强一致性,读取是顺序一致性。
在了解Zookeeper之前,需要对分布式相关的知识有一定的了解,什么是分布式系统呢? 通常情况下,单个物理节点很容易达到性能,计算或容量的瓶颈,所以这个时候就需要多个物理节点来共同完成某个任务,一个分布式系统本质是分布在不同的网络或计算上的程序组件,彼此通过信息传递来协同工作的系统 ,而Zookeeper正是一个分布式应用协调框架,在分布式系统架构中有广泛的应用场景 。
拜占庭将军问题
拜占庭将军问题是一个协议问题,拜占庭帝国军队的将军们必须全体一致的决定是否攻击某一支敌军。问题是这些将军在地理上是分隔开来的,并且将 军中存在叛徒。叛徒可以任意行动以达到以下目标:欺骗某些将军采取进攻行动;促成一个不是所有将军都同意的决定,如当将军们不希望进攻时促成进攻 行动;或者迷惑某些将军,使他们无法做出决定。如果叛徒达到了这些目的之一,则任何攻击行动的结果都是注定要失败的,只有完全达成一致的努力才能 获得胜利。
Paxos算法——解决什么问题
Paxos算法:一种基于消息传递且具有高度容错特性的一致性算法。
Paxos算法解决的问题:就是如何快速正确的在一个分布式系统中对某个数据值达成一致,并且保证不论发生任何异常, 都不会破坏整个系统的一致性。

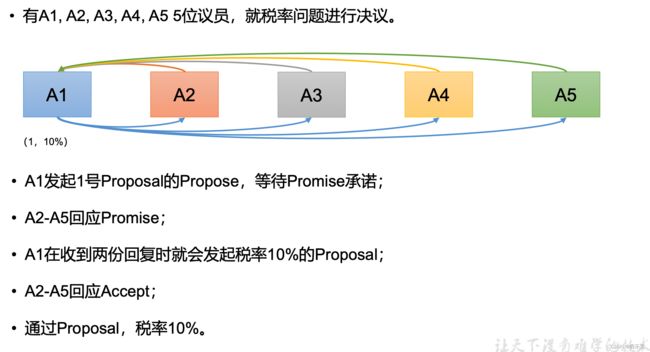
Paxos算法描述:

Paxos算法流程

情况1:
情况2:
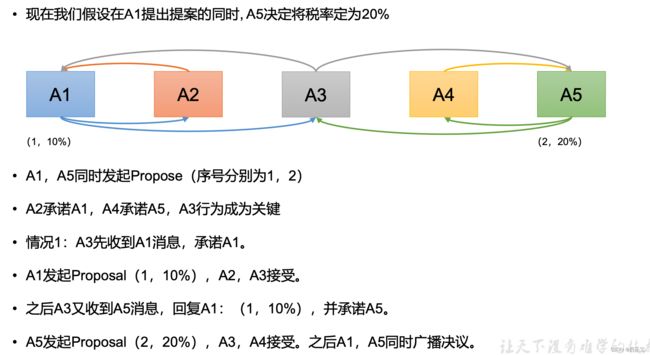
情况3:

代码地址
https://gitee.com/quyixiao/apache-curator.git