Flink状态的理解
Flink是一个带状态的数据处理系统;系统在处理数据的过程中,各算子所记录的状态会随着数据的处理而不断变化;
1. 状态
所谓状态State,一般指一个具体的 Task 的状态,即线程处理过程中需要保存的历史数据或历史累计数据,默认保存在 Java 的堆内存中。

根据算子是否存在按照Key进行分区,State可以划分为keyed state 和 Non-keyed state(Operator State、算子状态)
- operator state是task级别的state,说白了就是每个task对应一个state, 在逻辑上,由算子task下所有subtask共享

Operator State的经常被用在Source或Sink算子上,用来保存流入数据的偏移量或对输出数据做缓存,以保证Flink应用的Exactly-Once语义。 - keyed state 是基于KeyedStream上的状态,这个状态是跟特定的Key 绑定的。KeyedStream流上的每一个Key,都对应一个State

2. 状态数据结构
状态数据由Flink内置状态机制管理。keyed state提供了5种数据结构
2.1 keyed state 数据结构
| 状态 | 状态描述 |
|---|---|
| ValueState | 保存一个可以更新和检索的值(如上所述,每个值都对应到当前的输入数据的key |
| ListState | 保存一个元素的列表。可以往这个列表中追加数据,并在当前的列表上进行检索 |
| MapState | 维护了一个映射列表 |
| ReducingState | 保存一个单值,表示添加到状态的所有值的聚合 |
| AggregateState | 保留一个单值,表示添加到状态的所有值的聚合。和 ReducingState 相反的是, 聚合类型可能与添加到状态的元素的类型不同 |
2.2 operator state
| 状态 | 状态描述 |
|---|---|
| ListState | ListState的快照存储数据,系统重启后,list数据的重分配模式为: round-robin 轮询平均分配 |
| UnionListState | UnionListState的快照存储数据,在系统重启后,list数据的重分配模式为: 广播模式; 在每个subtask上都拥有一份完整的数据; |
3. 状态后端
默认情况下,state会保存在taskmanager的JVM堆内存,checkpoint会存储在JobManager的内存中。然而,状态数据的存储和checkpoint的存储位置可以改变,由state Backend(状态后端)配置实现
老版本(flink-1.12版及以前) Fsstatebackend MemoryStatebackend RocksdbStateBackend
flink1.12版本之后,可用的状态后端类型有两种
HashMapStateBackend、EmbeddedRocksDBStateBackend
而且其所生成的快照文件也统一了格式,因而在job重新部署或者版本升级时,可以任意替换statebackend
-
HashMapStateBackend
※ 状态数据是以java对象形式存储在heap内存中;
※ 内存空间不够时,也会溢出部分数据到本地磁盘文件;
※ 可以支撑大规模的状态数据;(只不过在状态数据规模超出内存空间时,读写效率就会明显降低) -
EmbeddedRocksDBStateBackend
※ RocksDB使用一套日志结构的数据库引擎,它是Flink中内置的第三方状态管理器, 为了更好的性能,这套引擎是用C++编写的。 Key和value是任意大小的字节流。
※ 它需要配置一个远端的filesystem uri(一般是HDFS),在做checkpoint的时候,会把本地的数据直接复制到fileSystem中。fail over的时候从fileSystem中恢复到本地, RocksDB克服了state受内存限制的缺点,同时又能够持久化到远端文件系统中,比较适合在生产中使用。
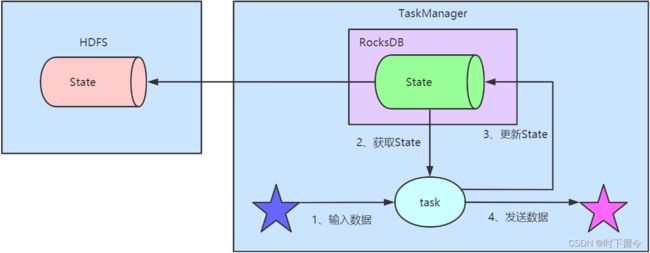
※ 使用RocksDB + HDFS进行state存储:首先
state先在taskManger的本地存储到RocksDB,然后异步写入到HDFS中,状态数量仅仅受限于本地磁盘容量限制。
4. 状态数据容错
Flink是一个stateful(带状态)的数据处理系统;系统在处理数据的过程中,各算子所记录的状态会随着数据的处理而不断变化;
一旦系统崩溃,需要重启后能够恢复出崩溃前的状态才能进行数据的接续处理;因此,必须要一种机制能对系统内的各种状态进行持久化容错;Flink用checkpoint机制实现状态数据的容错
4.1 checkpoint
Checkpoint是Flink实现容错机制最核心的功能,它能够根据配置周期性地基于Stream中各个Operator/task的状态来生成快照,从而将这些状态数据定期持久化存储下来,当Flink程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常。
-
checkpoint默认关闭,需要手工开启。开启后,默认Exactly-once快照模式。还有一种快照模式为At-least-once
-
checkPoint的位置设置
flink-conf.yaml#state.checkpoints.dir -
Flink支持不同的重启策略,以在故障发生时控制作业如何重启,集群在启动时会伴随一个默认的重启策略。配置参数
flink-conf.yaml#restart-strategy
♦ 如果没有启用 checkpointing,则使用无重启 (no restart) 策略 ♦ 如果启用了 checkpointing,但没有配置重启策略,则使用固定 间隔 (fixed-delay) 策略,尝试重启次数默认值是:Integer.MAX_VALUE。
♦ 另一种重启策略为Failure rate,某时间段内失败了N次就重启
全局配置
# 每隔3s重启一次,重试间隔为10s
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s
#5分钟内若失败了3次则认为该job失败,重试间隔为10s
restart-strategy: failure-rate
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 10 s
# 不重启
restart-strategy: none
单个JOB内配置
Configuration conf = new Configuration();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
//开启状态检查点机制(它将会定期对整个系统中各个task的状态进行快照持久化,以便失败重启后还能从失败之前的状态恢复)
env.enableCheckpointing(1000,CheckpointingMode.EXACTLY_ONCE);
// checkpoint机制触发后,持久化保存各task状态数据的存储位置(生产中用hdfs
env.getCheckpointConfig().setCheckpointStorage("hdfs://node01:8020/tmp/flink/state");
// 指定状态后端存储(内存)
env.setStateBackend(new HashMapStateBackend());
// 开启自动重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.milliseconds(2000)));
// env.setRestartStrategy(RestartStrategies.failureRateRestart(3, org.apache.flink.api.common.time.Time.seconds(100), org.apache.flink.api.common.time.Time.seconds(10)));
// env.setRestartStrategy(RestartStrategies.noRestart())
- checkpoint个数默认保留最近成功生成的一个,支持保留多个,通过参数
flink-conf.yaml#state.checkpoints.num-retained控制,如果希望回退到某个Checkpoint点,只需要指定对应的某个Checkpoint路径即可实现
flink run -t yarn-per-job -yjm 1024 -ytm 1024 -s hdfs://node01:8020/tmp/flink/state/715b120fe8736a3af7842ea0a5264c46/chk-6/_metadata
4.2 savePoint
savePoint是检查点一种特殊实现,底层其实也是使用Checkpoint的机制。
savePoint是用户以手工命令的方式触发checkpoint,并将结果持久化到指定的存储目录中。
作业升级、代码修改、任务迁移和维护,都可以使用savePoint
-
savePoint的存储位置
savePoint的存储位置flink-conf.yaml#state.savepoints.dir,不是必须设置,但设置了后, 后面创建指定Job的Savepoint时,可以不用在手动执行命令时指定Savepoint的位置。 -
savePoint的手动触发:
#【针对on standAlone模式】
bin/flink savepoint jobId [targetDirectory]#【针对on yarn模式需要指定-yid参数】
bin/flink savepoint jobId [targetDirectory] -yid yarnAppId
jobId 需要触发savepoint的jobId编号
targetDirectory 指定savepoint存储数据目录
-yid 指定yarnAppId
例如: flink savepoint 84e766231bbe4b9ff3667f9a0d80b867 -yid application_1619059559839_0001
- 查看HDFS上savepoint目录
#Savepoint directory /flink/savepoints/savepoint-:shortjobid-:savepointid/
#Savepoint file contains the checkpoint meta data /savepoints/savepoint-:shortjobid-:savepointid/_metadata

4. 触发savepoint并且停止作业
##语法: bin/flink stop jobId -yid yarnAppId
##例如: flink stop 84e766231bbe4b9ff3667f9a0d80b867 -yid application_1619059559839_0001
- 从指定的savepoint启动job
##语法: bin/flink run -s savepointPath [runArgs]
##例如: flink run -t yarn-per-job -yjm 1024 -ytm 1024
-s hdfs://node01:8020/flink/savepoints/savepoint-84e766-0591f3377ad0
-c com.loess.checkpoint.TestCheckPoint flink-study-1.0-SNAPSHOT.jar
- 清除savepoint数据
bin/flink savepoint -d savepointPath
##也可以手动删除某个savepoint,这通过常规的文件系统操作就可以做到,不影响其它的savepoints和checkpoints
- savePoint使用建议
为了能够在作业的不同版本之间以及 Flink 的不同版本之间顺利升级,推荐通过 uid(String) 方法手动的给算子赋予 ID,这些
ID 将用于确定每一个算子的状态范围。不手动给各算子指定 ID,则会由 Flink 自动给每个算子生成一个 ID。只要这些 ID 没有改变就能从保存点
(savepoint)将程序恢复回来。而这些自动生成的 ID
依赖于程序的结构,并且对代码的更改敏感。当程序改变时,ID会随之变化,所以建议用户手动设置 ID
DataStream<String> stream = env.
// Stateful source (e.g. Kafka) with ID
.addSource(new StatefulSource())
.uid("source-id") // ID for the source operator
.shuffle()
// Stateful mapper with ID
.map(new StatefulMapper())
.uid("mapper-id") // ID for the mapper
// Stateless printing sink
.print(); // Auto-generated ID
4.3 savePoint与checkPoint的区别
- checkpoint的侧重点是“容错”,即Flink作业意外失败并重启之后,能够直接从checkpoint来恢复运行,且不影响作业逻辑的准确性。而savepoint的侧重点是“维护”,即Flink作业需要在人工干预下手动重启、升级、迁移或A/B测试时,先将状态整体写入可靠存储,维护完毕之后再从savepoint恢复现场。
- savepoint是通过checkpoint机制创建的,所以savepoint本质上是特殊的checkpoint。
- checkpoint面向Flink Runtime本身,由Flink的各个TaskManager定时触发快照并自动清理,一般不需要用户干预;savepoint面向用户,完全根据用户的需要触发与清理。
- checkpoint是支持增量的(通过RocksDB),特别是对于超大状态的作业而言可以降低写入成本。savepoint并不会连续自动触发,所以savepoint没有必要支持增量。

5. checkpoint机制原理
checkPoint是所有 Operator / Task 的状态在某个时间点的一份拷贝(一份快照), 这个时间点应该是所有 Operator / Task 任务都恰好处理完一个相同的输入数据的时候。

若某个subTask挂了,则此时的状态都被清空,从checkpoint恢复最近一次的状态,重新启动应用程序,计算输入流
5.1 Barrier机制
Barrier是一种特殊事件,用来作为快照信号,由checkpoint 协调器向数据流中注入该信号,subtask任务收到该信号后,就会执行状态的快照。

- 首先是JobManager中的checkpoint Coordinator(协调器) 向任务中的所有source Task周期性发送barrier(栅栏)进行快照请求。
- source Task接受到barrier后, 会把当前自己的状态进行snapshot(可以保存在HDFS上)。
- source向checkpoint coordinator确认snapshot已经完成。
- source继续向下游transformation operator发送 barrier。
- transformation operator重复source的操作,直到sink operator向协调器确认snapshot完成。
- coordinator确认完成
本周期的snapshot已经完成。
5.2 Barrier对齐
对于下游算子来说,可能有多个与之相连的上游输入,我们将算子之间的边 称为通道。Source要将一个ID为n的Checkpoint Barrier向所有下游算子广播,这也意味着下游算子的多个输入里都有同一个Checkpoint Barrier,而且 不同输入里Checkpoint Barrier的流入进度可能不同。因此Checkpoint Barrier传播的过程需要进行对齐(Barrier Alignment)

算子对齐分为四部:
(1). 算子子任务在某个输入通道中收到第一个ID为n的Checkpoint Barrier,但是其他输入通道中ID为n的Checkpoint Barrier还未到达,该算子子任务开始准备进行对齐。
(2). 算子子任务将第一个输入通道的数据缓存下来,同时继续处理其他输入通道的数据,这个过程被称为对齐。
(3). 第二个输入通道的Checkpoint Barrier抵达该算子子任务,该算子子任务执行快照,将状态写入State Backend,然后将ID为n的Checkpoint Barrier向下游所有输出通道广播。
(4). 对于这个算子子任务,快照执行结束,继续处理各个通道中新流入数据,包括刚才缓存起来的数据。

6.快照性能优化方案
每次进行Checkpoint前,都需要暂停处理新流入数据,然后开始执行快照,假如状态比较大,一次快照可能长达几秒甚至几分钟。
Checkpoint Barrier对齐时,必须等待所有上游通道都处理完,假如某个上游通道处理很慢,这可能造成整个数据流堵塞。
两种优化方案
① Flink提供了异步快照(Asynchronous Snapshot)的机制。当实际执行快照时,Flink可以立即向下广播Checkpoint Barrier,表示自己已经执行完自己部分的快照。一旦数据同步完成,再给Checkpoint Coordinator发送确认信息。通过基于 Chandy-Lamport 算法的分布式快照,将检查点的保存和数据处理分离开,不暂停整个应用。
② Flink允许跳过对齐这一步,或者说一个算子子任务不需要等待所有上游通道的Checkpoint Barrier,直接将Checkpoint Barrier广播,执行快照并继续处理后续流入数据。为了保证数据一致性,Flink必须将那些较慢的数据流中的元素也一起快照,一旦重启,这些元素会被重新处理一遍