【MySQL】索引是什么东东?
书中的目录,就是充当索引的角色,方便我们快速查找书中的内容,所以索引是以空间换时间的设计思想。
索引和数据位于存储引擎中,MySQL默认的存储引擎是InnoDB。
1 为什么MySQL采用B+树作为索引?
1.1 其他数据结构为什么不合适?
MySQL的数据是持久化的,即数据(索引+记录)保存在磁盘上,即使断电,数据也不会丢失。
因此,当我们通过索引查找某行数据的时候,实际上是:
- 先从磁盘读取索引到内存
- 通过索引从磁盘中找到某行数据读入到内存
查询过程中会发生多次磁盘IO,而磁盘非常非常非常慢,我们希望索引的数据结构能在尽可能少的磁盘的 I/O 操作中完成查询工作:
一次磁盘访问的代价大约是几十万条指令。这意味着为了节省一次磁盘访问,我们愿意进行大量的运算。《数据结构与算法设计——Java语言描述》
因此,适合MySQL索引的数据结构,应该满足:在尽可能少的磁盘IO操作中查询某个记录 / 执行范围查找。
哈希?只适合等值查询,不适合范围查询。
二分查找?NoNoNo,插入和删除需要移动后续元素, O ( n ) O(n) O(n)的代价对磁盘来说太大太大。
二叉查找树?想法不错,但存在退化成链表的可能性。
平衡二叉查找树 / 红黑树 ?不管平衡二叉查找树还是红黑树,都会随着插入的元素增多,而导致树的高度变高,相较于多叉树,其需要访问的节点数更多,这就意味着磁盘 I/O 操作次数多,会影响整体数据查询的效率。对于磁盘来说,当树的节点数很大时, log 2 N \log_2 N log2N远大于 log M N \log_M N logMN,增加一个节点能够保存的索引数M,可以使树变得更矮胖。
B树?B 树的每一个节点最多可以包括 M − 1 M-1 M−1个数据项和 M M M个子节点,超过这些要求的话就会分裂节点。B树的每个节点都包含数据(索引+记录),而用户的记录数据的大小很有可能远远超过了索引数据,在查询过程中会将无用的记录数据加载进内存,这就需要花费更多的磁盘 I/O 操作次数来读到有用的索引数据。
B树参考:http://t.csdn.cn/kYHFi
1.2 B+树和B树的区别是什么?
是B树的变体,一棵M阶的B+树主要有这些特点:
- 每个结点至多有 M M M个子女,每个节点里的数据按主键顺序存放
- 非根节点关键值个数范围(?感觉按照USFCA的在线模拟,删除时并不一定要满足这个): M 2 ≤ k ≤ M − 1 \frac{M}{2} \le k \le M - 1 2M≤k≤M−1
- 相邻叶子节点是通过指针连起来的,并且通过关键字大小排序
因此,我们可以知道,二者的主要区别:
- B树内部节点保存数据,但B+树内部节点只保存索引。B+Tree 存储千万级的数据只需要 3-4 层高度就可以满足,千万级的表查询目标数据最多需要 3-4 次磁盘 I/O。对于单点查询来说,B 树进行单个索引查询时,最快可以在 O(1) 的时间代价内就查到,平均时间代价会比B树稍快一些,但是B树的查询波动会比较大,因为每个节点既存索引又存记录。
- B+树相邻的叶子节点通过链表指针连接,这种设计对于范围查找非常有帮助。比如查找12月1日至12月12日之间的订单,可以找到链表头,然后利用链表向后遍历,无需从根节点进行查询。而B树没有将叶子节点串联起来的结构,只能通过树的遍历完成范围查询,范围查询效率不如B+树。
- 查找过程中,B树在找到具体数值以后就结束,B+树需要通过索引找到叶子节点中的数据。
- B树中一个关键字出现且只出现在一个节点中,而B+树可以出现多次。即B+树有大量的冗余节点,删除时有时可以直接从叶结点中删除,甚至可以不动,或者很简单地修改非叶节点。
1.3 B+树的插入删除过程
原理说明:https://juejin.cn/post/6929833495082565646?searchId=202307261122017B0C2F66AFF8CF77995A
在线模拟:https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
插入:
- 插入都是在叶节点进行,找到要插入的叶节点
- 如果插入后,关键字数等于阶数M,分裂为两个 ⌈ m 2 ⌉ \lceil \frac{m}{2} \rceil ⌈2m⌉和 ⌊ m 2 ⌋ \lfloor \frac{m}{2} \rfloor ⌊2m⌋的节点,将第 ⌈ m 2 ⌉ \lceil \frac{m}{2} \rceil ⌈2m⌉个关键字上移到父节点。
- 如果父节点包含的关键字数等于M,继续分裂。

删除:找到包含关键值的节点,如果关键值是当前节点的最大/最小值且存在于父节点中,则删除时需要相应调整父节点的值。
2 索引的分类分类
2.1 数据结构分类
从数据结构的角度来看,MySQL 常见索引有 B+Tree 索引、HASH 索引、Full-Text 索引。
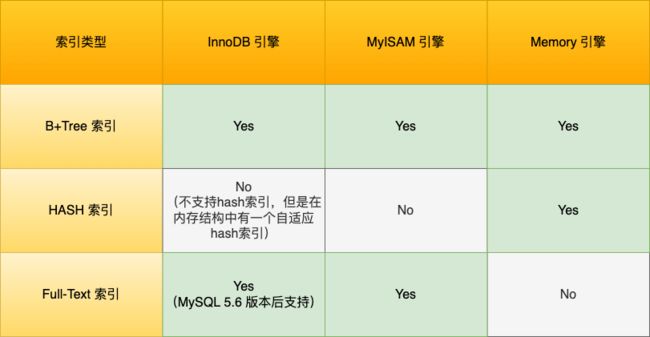
2.2 物理存储分类
在创建表时,InnoDB存储引擎会根据不同的场景选择不同的列作为聚簇索引的索引列:
- 有主键,使用主键
- 没有主键,选择第一个NOT NULL和UNIQUE的列
- 否则,自动生成隐式自增ID列
其他索引都属于辅助索引(Secondary Index),也叫做二级索引或者非聚簇索引。
主键索引的 B+Tree 和二级索引的 B+Tree 区别如下:
- 主键索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里;
- 二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据,检索时,如果查询的数据能在二级索引里查找到,就不需要回表,否则需要查找2个B+Tree。
2.3 字段特性分类
从字段特性的角度来看,索引分为主键索引、唯一索引、普通索引、前缀索引。
- 主键索引:建立在主键字段上的索引,通常在创建表的时候一起创建,一张表最多只有一个主键索引,索引列不允许有空值。
CREATE TABLE table_name (
....
PRIMARY KEY (index_column_1) USING BTREE
);
- 唯一索引:建立在 UNIQUE 字段上的索引,一张表可以有多个唯一索引,索引列的值必须唯一,但是允许有空值。
CREATE TABLE table_name (
....
UNIQUE KEY(index_column_1,index_column_2,...)
);
- 普通索引:建立在普通字段上的索引,既不要求字段为主键,也不要求字段为 UNIQUE。
CREATE TABLE table_name (
....
INDEX(index_column_1,index_column_2,...)
);
CREATE INDEX index_name
ON table_name(index_column_1,index_column_2,...);
- 前缀索引:前缀索引是指对字符类型字段的前几个字符建立的索引,而不是在整个字段上建立的索引,前缀索引可以建立在字段类型为 char、 varchar、binary、varbinary 的列上。
2.4 按字段个数分类
从字段个数的角度来看,索引分为单列索引、联合索引。
联合索引具有最左匹配原则,即按照最左优先的方式进行索引的匹配。使用联合索引进行查询的时候,如果不遵循最左匹配原则,联合索引会失效。
比如(a, b, c)联合索引,是先按 a 排序,在 a 相同的情况再按 b 排序,在 b 相同的情况再按 c 排序。所以,b 和 c 是全局无序,局部相对有序的,这样在没有遵循最左匹配原则的情况下,是无法利用到索引的。
Q1:
select * from t_table where a > 1 and b = 2,联合索引(a, b)哪一个字段用到了联合索引的 B+Tree?A1:只有a,进行索引扫描时,可以定位到符合a>1的第一条记录,然后沿着记录所在链表向后扫描
Q2:
select * from t_table where a >= 1 and b = 2,联合索引(a, b)哪一个字段用到了联合索引的 B+Tree?A2: a和b,可以定位到a=1、b=2的第一条记录,再向后扫描
实际开发工作中建立联合索引时,要把区分度大的字段排在前面,这样区分度大的字段越有可能被更多的 SQL 使用到。
3 什么时候需要/不需要创建索引?
由于索引占用空间,且创建、维护索引需要耗费时间,比如进行插入、更新、删除时,MySQL不仅要保存数据,还要维护索引,所以需要合理地选择使用索引。
什么时候适合使用索引?
-
主键自动建立唯一索引
-
字段唯一,比如UUID
-
经常使用Where查询的字段,这样能够提高整个表的查询速度
-
经常使用GROUP BY和ORDER BY的字段,这样查询时不用再做一次排序
-
查询中排序的字段,排序的字段如果通过索引访问将大大提高排序速度
什么时候不需要创建索引?
- where、group by、order by用不到的字段
- 字段中存在大量重复数据,查询优化器发现某个值出现在表的数据行中的百分比(惯用的百分比界线是"30%")很高的时候,会忽略索引,进行全表扫描。
- 表记录太少的时候,不需要创建索引
4 索引的失效与优化
-
like语句的前导模糊查询不能使用索引,like查询是以%开头,索引会失效
-
负向条件查询不能使用索引,负向条件有:
!=、<>、not in、not exists、not like等,优化案例:select * from doc where status != 1 and status != 2; --优化前 select * from doc where status in (0,3,4); --优化后 -
查询条件中带有or,除非所有的查询条件都建有索引
-
如果列类型是字符串,那在查询条件中需要将数据用引号引用起来,否则索引失效,因为强制类型转换会导致全表扫描:
select * from user where phone=13800001234; select * from user where phone='13800001234'; -
索引列上参与计算,索引失效,尽量不要在索引列上做任何操作(计算、函数),例子:
select * from doc where YEAR(create_time) <= '2016'; --优化前 select * from doc where create_time <= '2016-01-01'; --优化后 -
违背最左匹配原则,索引失效:
select * from employees.titles where emp_no < 10010' and title='Senior Engineer'and from_date between '1986-01-01' and '1986-12-31'; (empno、title、fromdate),emp_no 可以用到索引,而title 和 from_date 则使用不到索引 -
如果MySQL估计全表扫描要比使用索引要快,索引失效
-
如果明确知道只有一条结果返回,limit 1 能够提高效率
select * from user where login_name=?; select * from user where login_name=? limit 1