(十八)FLUX查询优化
以下内容来自 尚硅谷,写这一系列的文章,主要是为了方便后续自己的查看,不用带着个PDF找来找去的,太麻烦!
第 18 章 FLUX查询优化
18.1 使用谓词下推的查询
1、谓词下推常见于SQL查询中,一个SQL中的谓词,通常指的是where条件。我们看一个最简单的SQL语句。它从一个名为A的表中查询数据,并按照n>10的条件对数据进行过滤。
select *
from A
where n > 10
2、你可以想象一下这条SQL语句在计算机中的执行流程。大体上有下面两种方式。
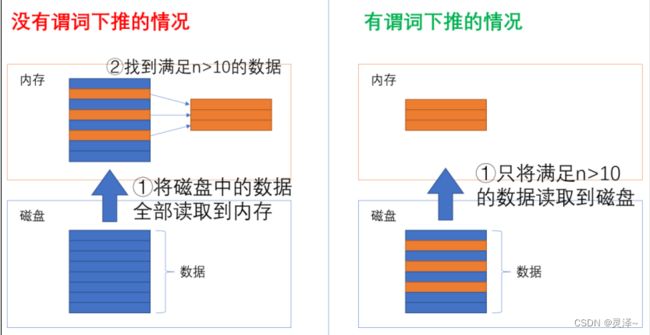
3、一种是将磁盘里的数据全部读到内存中,再在内存中进行过滤。这种方式我们通常说它没有内存下推
4、另一种是在查询时,就只从磁盘取自己需要的数据到内存中,再进行下一步的操作。通常,我们说这种方式实现了谓词下推。
5、虽然说FLUX语言表面上是一个脚本语言,但在查询这件事上,它并不是老老实实一行行执行的,而是有了优化器的参与。FLUX语言在执行时,会尽可能实现谓词下推的优化,什么样的查询可以实现谓词下推,可以参考官网文档的优化查询一节
https://docs.influxdata.com/influxdb/v2.4/query-data/optimize-queries/

6、另外,后面我们会告诉大家如何去查看一个查询的执行计划。
18.2 避免将窗口宽度设得过小
1、 窗口(基于时间间隔对数据进行分组)通常用于聚合和降采样数据。将窗口设长一点可以提高性能。窗口过窄会导致需要更多的算力来评估每条数据应该分配到哪个窗口,合理的窗口宽度应该根据查询的总时间宽度来决定。
18.3 避免使用“沉重”的功能
1、下面的这些函数对于FLUX来说会比较很重,这些函数会使用更多的内存和CPU,使用这些函数时要想要是否必要。不过官方又说,InfluxData一直在优化FLUX的性能,所以当前的列表不一定是将来的情况
- map()
- reduce()
- join()
- union()
- pivot()
18.4 尽可能使用set()而不是map()
1、如果你要给数据查一个静态常量,那么set比map要有很大的性能优势。map是我们上篇说的沉重操作。在后面的示例,我们会比较两种操作的差距。
18.5 平衡数据的时间范围和数据精度
1、想要保证查询的性能良好,应该平衡好查询的时间范围和数据精度。如果,有一个measurement的数据每秒入库一条,你一次请求 6 个月的数据,那么一个序列就能包含1550 万点数据。如果序列数再多一些,那么数据很可能会变成数十亿点。Flux必须将这些数据拉到内存再返回给用户。所以一方面做好谓词下推尽量减少对内存的使用。另外,如果必须要查询很长时间范围的数据,那应该创建一个定时任务来对数据进行降采样,然后将查询目标从原始数据改为降采样数据。
18.6 使用FLUX性能分析工具查看查询性能
1、执行FLUX查询时,你可以导入一个名为profiler的包,然后添加一个option选项以查看当前FLUX语句的执行计划。比如:
option profiler.enabledProfilers = ["query", "operator"]
2、这里的query和operator是查询计划的两个选项,query表示你要查看整个执行脚本的的执行情况,operator表示你要查看一个FLUX查询各个算子的执行情况。
18.6.1 query(查询)
1、query提供有关整个 Flux脚本执行的统计信息。启用后,结果将多出一个表,其中包含以下信息:
- TotalDuration:查询总持续时间(以纳秒为单位)
- CompileDuration:编译查询脚本所花费的时间(以纳秒为单位)
- QueueDuration:排队所花费的时间(以纳秒为单位)
- RequeueDration:重新排队花费的时间(以纳秒为单位)
- PlanDuration:计划查询所花费的时间(以纳秒为单位)
- ExecuteDuration:执行查询所花费的时间(以纳秒为单位)
- Concurrency:并发,分配给处理查询的goroutines。
- MaxAllocated:查询分配的最大字节数(内存)
- TotalAllocated:查询时分配的总字节数(包括释放然后再次使用的内存)
- RuntimeErrors:查询执行期间返回的错误消息
- flux/query-plan:flux查询计划
- influxdb/scanned-values:数据库扫描磁盘的数据条数
- influxdb/scanned-buytes:数据库扫描磁盘的字节数
18.6.2 operator(算子)
1、有关一个查询脚本中每个操作的统计信息。在存储层中执行的操作将作为单个操作返回。启用此配置后,返回的结果将多出一个表,并包含以下内容
- Type:操作类型
- Label:标签
- Count:执行这个操作的总次数
- MinDuration:操作被执行多次中,最快的一次花费的时间(以纳秒为单位)
- MaxDuration:操作被执行多次中,最慢的一次花费的时间(以纳秒为单位)
- DurationSum:当前操作完成的总持续时间(以纳秒为单位)。
- MeanDuration:操作被执行多次的平均持续时间(以纳秒为单位)。
18.7 示例:使用profile优化查询
18.7.1 编写查询
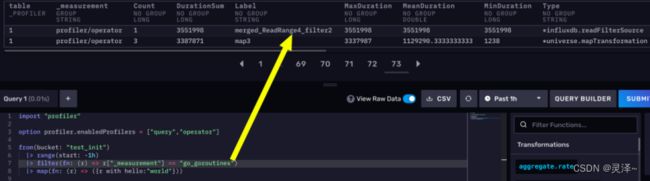
1、首先,打开DataExplorer。写下如下代码。
from(bucket: "test_init")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "go_goroutines")
|> map(fn: (r) => ({r with hello:"world"}))
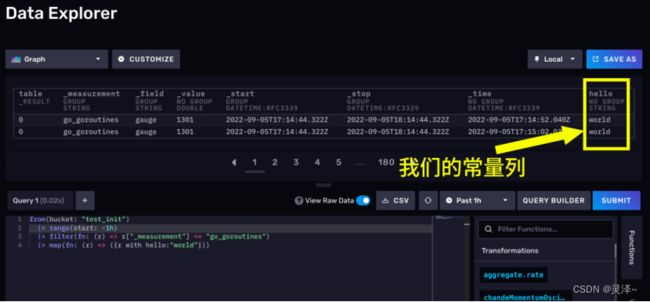
2、这段代码,会从test_init存储桶查询一个名为go_goroutines的measurement,这个测量下没有tag,所以我们只有一个序列。
map函数帮我们在filter后的数据上加了一个常量列,列名是hello,值是字符串world。
18.7.2 执行查询
1、现在,SUBMIT一下上面的代码,然后点击View Raw Data。数据应该如下所示,可以看到有一个常量列
18.7.3 修改代码查看性能指标和执行计划
1、现在,我们对代码做出修,以方便我们观察执行计划。
import "profiler"
option profiler.enabledProfilers = ["query","operator"]
from(bucket: "test_init")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "go_goroutines")
|> map(fn: (r) => ({r with hello:"world"}))
2、代码解释:
- option profiler.enabledProfilers,这其实是个开关选项,当后面的列表出现“query”时,就显示整个查询的性能和执行计划,当然出现"operator"时,会具体显示每个算子的性能指标。
- import “profiler”,引包,enabledProfilers是profiler中的开关,不引没法用。
3、现在,再次点击SUBMIT,同样还是观察原始数据。一上来展示的还是我们查询出来的数据,需要切换到页尾才能看到性能指标和执行计划。
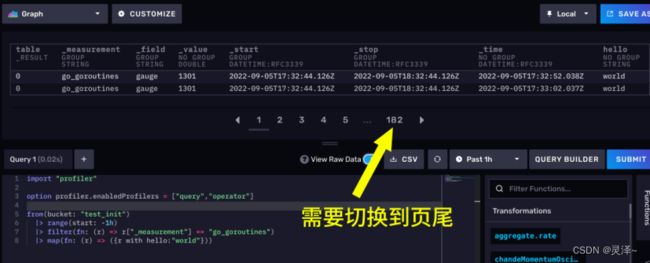
4、现在,我们看到两张表,有一个_measurement为profiler/query,这是我们整个查询的性能指标和执行计划。还有一个_measurement为profiler/operator的,这是我们每个算子的性能指标。里面包括某个算子运行了多长时间等信息。
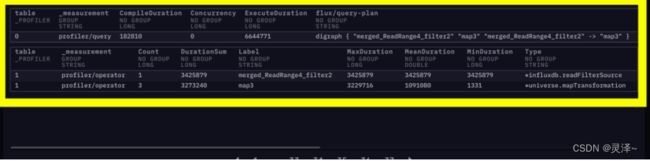
18.7.4 如何判断谓词下推
1、按照官方文档的说法,如果实现了谓词下推,那么多个 operator会合并成一个。我们可以看到现在操作列表里,有一个叫做 merged_ReadRange4_filter2的算子操作,后面紧跟的是我们的map操作。这说明from -> range -> filter被合并了。它们是一步操作。
18.7.5 查看查询性能
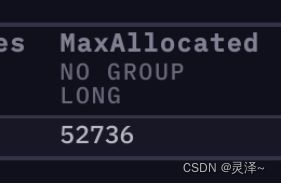
1、查询性能有很多指标,但是我们现在只关注两个指标,一个是 MaxAllocated。它表示的是我们为了完成查询,总共使用过的内存(包含释放后又申请的内存)。现在这个指标的数值是 52736 ,也就是说为了完成这个查询,我们前后用了大概 50 kb
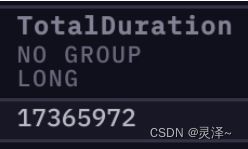
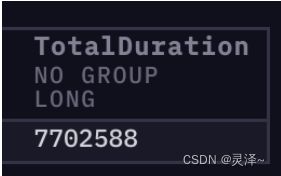
的内存。另一个是TotalDuration,表示执行这个操作的总时间,现在是 17365972 纳秒
18.7.6 在map后增加AggregateWindow
1、现在,我们在map后面加上一个AggregateWindow函数。整体代码如下:
import "profiler"
option profiler.enabledProfilers = ["query","operator"]
from(bucket: "test_init")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "go_goroutines")
|> map(fn: (r) => ({r with hello:"world"}))
|> aggregateWindow(column: "_value", every: 1h,fn:mean)
18.7.7 查看查询性能
1、首先关注我们的operator表,可以看到,操作数从之前的 2 个变成了 3 个。map的后面,多了一个聚合窗口操作。

2、查询的MaxAllocated依然是 52736 ,没有变。

3、 因为之前需要返回几百条数据,现在开窗聚合,只需要返回两条数据,所以查询的持续时间有所缩短。
18.7.8 将AggregateWindow移至map前
1、现在,我们将AggregateWindow移到map之前filter之后。修改后的代码整体如下:
import "profiler"
option profiler.enabledProfilers = ["query","operator"]
from(bucket: "test_init")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "go_goroutines")
|> aggregateWindow(column: "_value", every: 1h,fn:mean)
|> map(fn: (r) => ({r with hello:"world"}))
18.7.9 查看查询性能
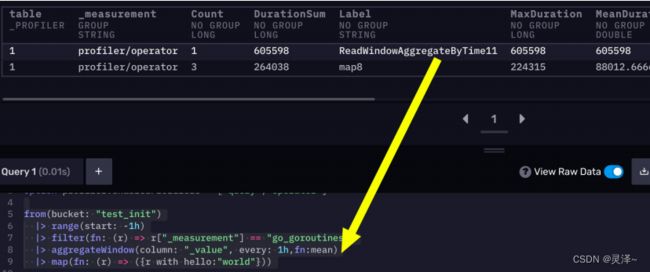
1、首先还是关注operator表,这张表里之前是 3 个操作,现在变成了两个。map之前,有一个ReadWindowAggregateByTime操作。也就是说,我们的aggreagteWindow操作实现了谓词下推。
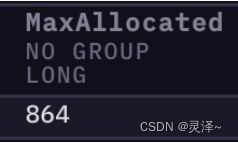
2、当读磁盘的操作完成后,内存中只会存在聚合后的两条数据。现在我们关注查询性能指标。可以看到 MaxAllocated变成了 864 ,之前这一指标的数值还是 52736 。之前要消耗50KB,现在却 1 KB都不到。查询的持续时间也有进一步缩短。
18.7.10 将map改为set
1、最后值得说一下,我们的map操作数据的原理是对数据集中的数据一行一行处理。此处,我们用它实现了添加常量的功能。其实还有一个同样能完成此类任务的算子叫set,它操作数据的逻辑是直接操作整个数据集。数据量越大,这两个算子的性能差距就越明显。此处,我们将aggregateWindow算子去掉,并将map改成set。与第一次查看性能时的代码做比较,当时我们还没有做聚合操作。改完的代码整体如下:
import "profiler"
option profiler.enabledProfilers = ["query","operator"]
from(bucket: "test_init")
|> range(start: |> filter(fn: (r) => r["_measurement"] == "go_goroutines")-1h) (^)
|> set(key: "hello", value: "world")
18.7.11 查看查询性能
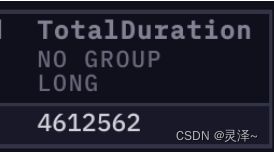
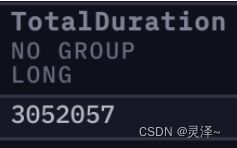
1、运行之后,查看查询性能。可以看到用Set版的MaxAllocated是 51712 ,这跟map版的 52736 几乎没啥区别。

2、但是,我们看一下TotalDuration这个指标 4612562 。之前的map版在这个指标上可是17365972 。这说明set操作要比map要快。