探秘MySQL底层架构:设计与实现流 程一览
点赞还是要求一下的,万一屏幕前的大漂亮,还有大帅哥就点赞了呢!!!!

Author: 源码时代 Raymon老师
说在前头
Mysql,作为一款优秀而广泛使用的数据库管理系统,对于众多Java工程师来说,几乎是日常开发中必不可少的一环。无论是存储海量数据,还是高效地检索和管理数据,Mysql都扮演着重要的角色。然而,除了使用Mysql进行日常开发之外,我们是否真正了解它的底层架构以及设计实现的流程呢?本篇博客将带您深入探索Mysql底层架构的设计与实现流程,帮助您更好地理解和应用这个强大的数据库系统。让我们一同揭开Mysql底层的神秘面纱,探寻其中的奥秘。
1.你眼中的Mysql是什么样子?
MySQL,在大部分普通Java工程师的眼中,往往被视为一种用于存储和操作数据的工具。我们常常将其用于建立数据库、创建表和索引,以便进行数据的增删改查操作。这些基本的使用方法已经成为我们日常工作中与MySQL打交道的常规操作。(就像下图一样)
然而,在日常开发中,我们往往只关注于如何正确地使用MySQL进行数据操作,而很少深入了解MySQL的底层架构和实现原理。我们可能对存储引擎、查询优化器、事务管理等底层机制知之甚少,对于如何优化性能、保证数据一致性、备份恢复等方面的知识掌握有限。
正因如此,了解MySQL底层架构设计和实现流程对我们来说至关重要。它不仅可以帮助我们更全地理解MySQL的内部机制,还能够提升我们的工作效率和质量。在接下来的内容中,我们将深入探讨MySQL底层架构的各个组件和技术,希望能够为大家带来更深入、更全面的MySQL知识。让我们一同揭开MySQL底层的面纱,探索其中的奥秘
2.Java系统是如何连接Mysql的?
在Java中,连接MySQL数据库通常需要通过JDBC(Java Database Connectivity)来实现。JDBC是Java提供的一套用于访问数据库的API,它提供了一种标准的接口,使得我们可以通过Java代码与各种数据库进行交互。
要连接MySQL数据库,首先需要确保系统中已经安装了MySQL数据库,并且在Java项目中导入了适当的MySQL JDBC驱动。Mysql驱动为我们搭建了Java系统到Msyql数据库之间的桥梁:
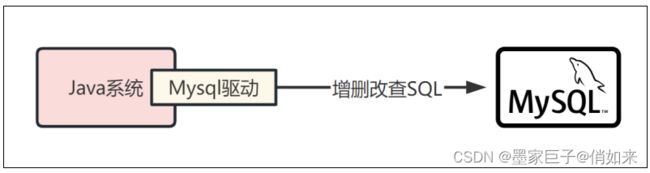
因此,当我们在实现业务代码的时候,如果需要执行相关的SQL语句,就可以由Mysql驱动帮我们传递SQL语句到Mysql数据库进行落地执行:
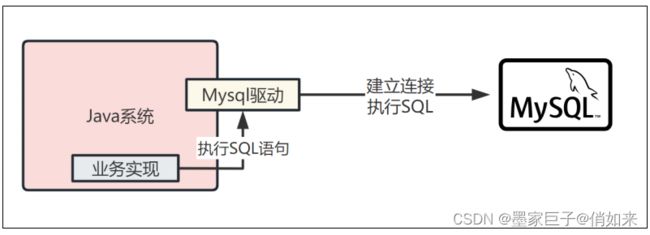
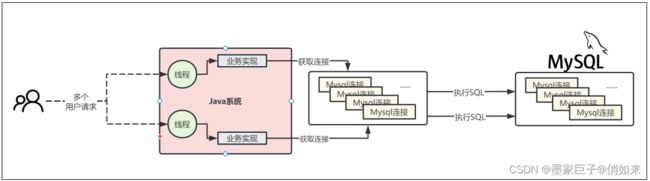
接着我们来思考一个问题,一个Java系统难道只会跟数据库建立一个连接吗?这个肯定是不行的,因为我们要明白一个道理,假设我们用Java开发了一个Web系统,是部署在Tomcat中的,那么Tomcat本身肯定是有多个线程来并发处理接收到的多个请求的,我们看下图:
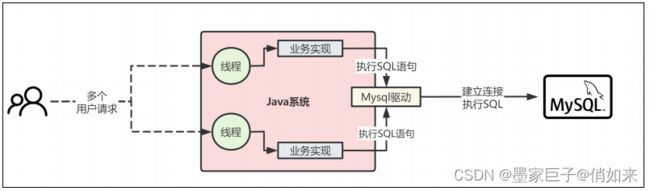
因此,当有多个业务请求的时候,每一个请求我们可以单独建立一个数据库连接进行单独使用,如下:
但是在高并发场景下,如果每个Tomcat线程在访问数据库时都创建一个数据库连接、执行SQL语句,然后销毁连接,这样的做法行得通吗?可能有几百个线程会频繁执行这一过程。这种方式是不可取的。每次建立数据库连接都需要耗费时间,当连接建立完成,SQL语句执行完毕后就销毁连接,再重新建立连接。这样的效率非常低下。
因此我们需要引入连接池的概念可以解决这个问题。连接池会维护一组可重用的数据库连接,并对连接进行有效管理。Tomcat线程在需要访问数据库时可以从连接池中获取一个可用连接,执行完毕后将连接归还给连接池。这样可以减少连接的频繁创建和销毁,提升性能。如下所示:

3.Mysql为什么也需要连接池?
你知道去银行办业务时,有时候需要排队等待吗?假设每个人都需要等待银行的工作人员为他们办理业务,这样会很浪费时间和资源对吧?MySQL连接池就像是银行办理业务的排队系统,它帮助我们更有效地管理和利用数据库连接。
-
提高连接效率:在MySQL中,建立数据库连接需要进行一些准备工作,就像是银行工作人员办理业务前需要做一些准备。如果每次都重新创建连接,就像每个人都要去银行排队取号、办理业务,那将非常低效。连接池会提前创建一些连接,就像是银行提前准备好几个窗口供业务办理,这样只需从连接池获取一个可用连接,减少了等待时间,提高了连接效率。
-
节约系统资源:数据库连接是有限的资源,就像银行的工作人员有限。如果每个人都占用一个工作人员办理业务,银行很快就会瘫痪。连接池可以管理和控制连接的数量,类似于银行控制窗口的数量,确保不会创建过多的连接,从而避免数据库和服务器资源的浪费。
-
简化连接管理:连接池可以让我们更轻松地管理连接,就像银行的排队系统让银行工作人员可以集中处理客户业务一样。通过连接池,我们无需手动创建和释放连接,只需从连接池获取连接并使用,完成后归还给连接池。这样简化了连接管理的工作,提高了开发效率。综上所述,MySQL连接池就像银行排队系统,它能够提高连接效率、节约系统资源、管理连接的可靠性,并简化连接的管理。接池在高并发的数据库操作中起着重要的作用,帮助我们更有效、更方便地与MySQL数据库进行连接和交互。
4.Mysql如何处理连接请求的?
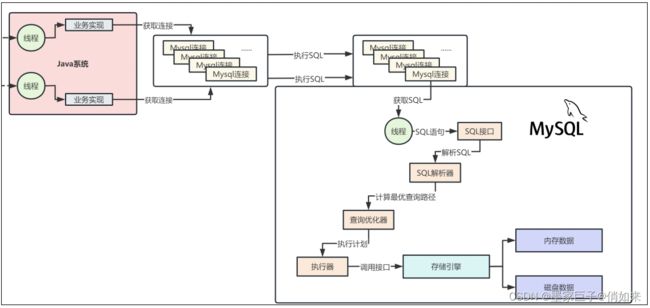
当Mysql接收到一个网络连接请求后,它是如何去处理该请求的,以及如何将SQL最终执行的,我们一起来看看整个过程链路中会经历哪些步骤。
首先:
- 网络连接必须得分配给一个线程去进行处理,由一个线程来监听请求以及读取请求数据,比如从网络连接中读取和解析出来一条Java系统发送过去的SQL语
句。 - Mysql内部提供了一个组件:SQL接口(SQL Interface),用来专门执行SQL语句的接口
- 然后通过查询优化器:选择最优的查询路径来执行,作用:针对你编写的几十行、几百行甚至上千行的复杂SQL语句生成查询路径树,然后从里面选择一条最优的查询路径出来。
- 调用执行器:根据执行计划调用存储引擎的接口
- 调用存储引擎接口,真正执行SQL语句,作用: 执行器会根据优化器选择的执行方案,去调用存储引擎的接口按照一定的顺序和步骤,就把SQL语句的逻辑给执行了
- 存储引擎:管理和存储数据,支持各种各样的存储引擎比如:InnoDB、MyISAM、Memory,我们可以自己选择使用哪种存储引擎来负责具体的SQL语句执行现在MySQL一般都是默认使用InnoDB存储引擎
以上整个执行过程大家感兴趣的可以深入研究,本篇文章就不做细节介绍了。我们接着来分析InnoDB存储引擎是如何管理和存储我们的数据。
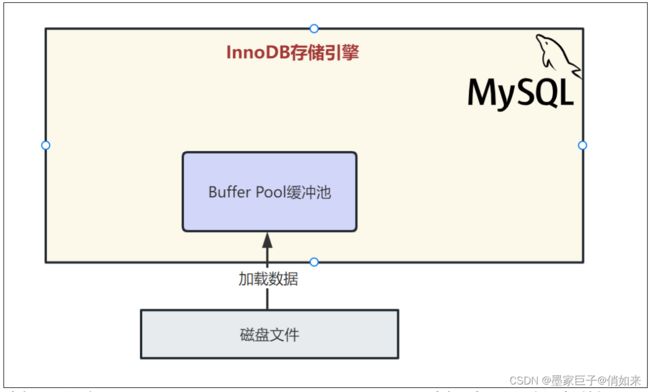
5.InnoDB的重要内存结构:缓冲池
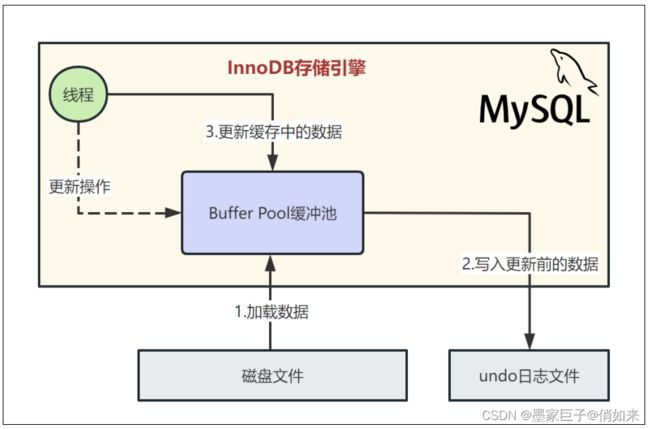
InnoDB存储引擎中有一个非常重要的放在内存里的组件,就是缓冲池(BufferPool),这里面会缓存很多的数据,以便于以后在查询的时候,万一你要是内存缓冲池里有数据,就可以不用去查磁盘了,我们看下图。
比如SQL语句:update users set name=‘xxx’ where id=1,比如对“id=1”这一行数据,他其实会先将“id=1”这一行数据看看是否在缓冲池里,如果不在的话,那么会直接从磁盘里加载到缓冲池里来,而且接着还会对这行记录加独占锁。
缓冲池使用LRU(Least Recently Used,最近最少使用)算法来管理内存中的数据页。当查询需要访问数据时,InnoDB首先检查缓冲池中是否存在相应的数据页。如果存在,它会直接从内存中获取数据,而不是从磁盘中读取,这大大提高了查询性能。如果数据页不在缓冲池中,InnoDB会将其读取到缓冲池,并将其保留在内存中供后续查询使用。
通过适当配置缓冲池的大小,可以使常用的数据页始终在内存中,提高查询效率。较大的缓冲池通常适用于具有大量内存的服务器
6.undo日志文件:让更新的数据可以回滚
Undo日志文件用于记录数据库中正在进行的事务的操作,以便在需要回滚事务时提供回滚数据。当有更新、删除或插入操作发生时,InnoDB引擎会将相关信息记录到Undo日志文件中。
当需要撤销事务时,InnoDB引擎使用Undo日志来还原数据到事务开始之前的状态。它通过逆向操作来撤销对数据的修改,并将数据还原为先前的状态。
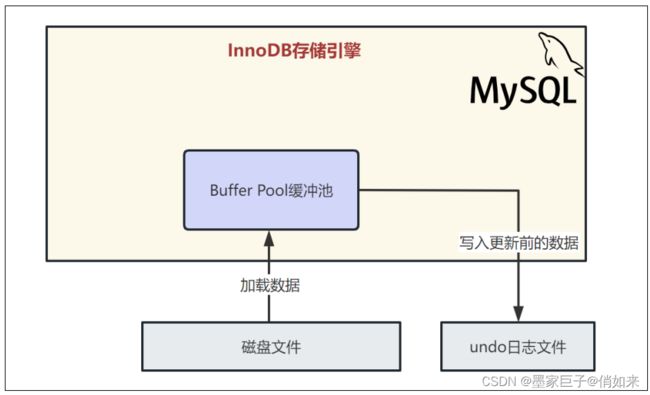
当我们把要更新的那行记录从磁盘文件加载到缓冲池,同时对他加锁之后,而且还把更新前的旧值写入undo日志文件之后,我们就可以正式开始更新这行记录了,更新的时候,先是会更新缓冲池中的记录,此时这个数据就是脏数据了。
这里所谓的更新内存缓冲池里的数据,意思就是把内存里的“id=1”这行数据的name字
段修改为“xxx”:
7.redo日志文件:保证数据的一致性和持久性
现在我们试想下,上图中的修改操作如果已经写入缓存中,但是还未来得及同步到磁盘进行持久化;此时,msyql的机器宕机了,挂了,那么缓存中的数据必然也会丢失,那么本次更新的数据也就丢失了。因此为了保障Mysql数据的一致性和持久性,innodb引擎引入了redo 日志文件。
Redo Log日志是一种物理日志,主要用于记录在事务提交前对数据库进行的修改操作。当数据库崩溃或发生故障时,通过Redo Log可以恢复到最后一次提交的状态,保证数据的持久性。
Redo Log的作用主要体现在以下两个方面:
- 数据恢复:当数据库发生故障时,通过Redo Log可以将未提交的修改操作重新应用到数据库中,从而恢复到最后一次提交的状态。
- 提高性能:通过将修改操作记录到Redo Log中,可以将磁盘IO操作转化为顺序写操作,大幅提高了数据库的写入性能。
因此,当更新操作执行后,Mysql会把对内存所做的修改写入到一个Redo Log Buffer里去,这也是内存里的一个缓冲区,是用来存放redo日志的。所谓的redo日志,就是记录下来你对数据做了什么修改,比如对“id=10这行记录修改了name字段的值为xxx”,这就是一个日志。如下图所示:
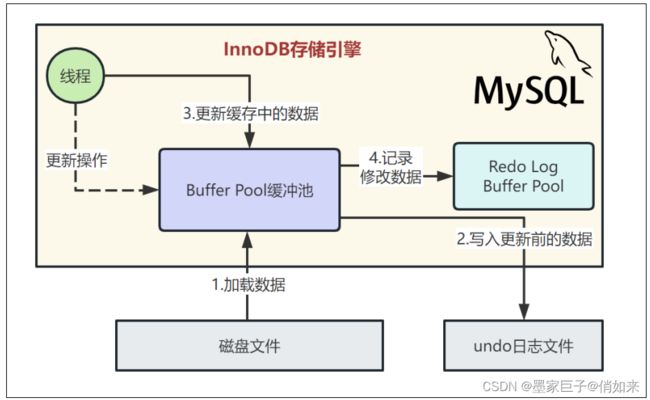
备注:innodb_log_buffer_size:指定Redo Log的缓冲区大小,默认为8MB。较大的值
可以减少频繁的刷新操作,提高性能,但同时也会占用更多的内存。
8.提交事务:redo日志刷盘
当提交事务的时候,redolog中缓存区中的数据才会被刷入到磁盘。那么此时数据丢失要紧吗?
其实是不要紧的,因为你一条更新语句,没提交事务,就代表他没执行成功,此时MySQL宕机虽然导致内存里的数据都丢失了,但是你会发现,磁盘上的数据依然还停留在原样子。
redo日志写入磁盘的三种策略
刷盘策略是通过innodb_flush_log_at_trx_commit来配置的,他有几个选项:
- 参数值为0,redo log不进磁盘表示不刷写Redo Log到磁盘,即异步写入策略。事务提交时,Redo Log的修改操作只会写入到操作系统的页缓存中,并不会马上刷写到磁盘。这样可以提供最好的写入性能,但在数据库崩溃或发生故障时,可能会造成一定程度的数据丢失。
- 参数值为1,redo log进磁盘【默认值】表示同步刷写Redo Log到磁盘。事务提交时,Redo Log的修改操作会立即写入磁盘并等待IO操作完成。确保数据持久性的同时,也会对性能产生一定的影响。这是最常用的设置,适合大多数应用场景。

- 参数值为2,redo log进os cache缓存
表示每次事务提交时将Redo Log的修改操作写入磁盘,但不会等待IO操作完成。事务提交时,Redo Log会先写入到操作系统的页缓存,然后由后台线程异步地将数据刷写到磁盘。这种设置可以提供较好的性能和一定程度的数据保护,但仍然存在一定的风险。
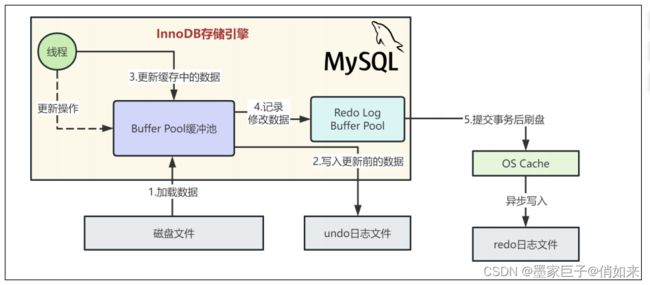
刷盘策略选择
选择适当的innodb_flush_log_at_trx_commit值取决于对数据的持久性和性能的需求。如果对数据的持久性要求非常高,可以将其设置为1。如果对性能要求较高且可以接受一定程度的数据丢失,可以将其设置为0。如果在保证一定程度的数据保护的同时追求更好的性能,可以选择设置为2。
可以通过修改MySQL配置文件中的参数设置来调innodb_flush_log_at_trx_commit值,并重启MySQL服务使其生效。
我们通常建议是设置为1。也就是说,提交事务的时候,redo日志必须是刷入磁盘文件里的。这样可以严格的保证提交事务之后,数据是绝对不会丢失的,因为有redo日志在磁盘文件里可以恢复你做的所有修改。
9.binlog到底是什么东西
实际上我们之前说的redo log,他是一种偏向物理性质的重做日志,因为他里面记录的是类似这样的东西,“对哪个数据页中的什么记录,做了个什么修改”。
而且redo log本身是属于InnoDB存储引擎特有的一个东西。而binlog叫做归档日志,他里面记录的是偏向于逻辑性的日志,类似于“对users表中的id=1的一行数据做了更新操作,更新以后的值是什么”,binlog不是InnoDB存储引擎特有的日志文件,是属于mysql server自己的日志文件。因此在提交事务的时候,同时会写入binlog: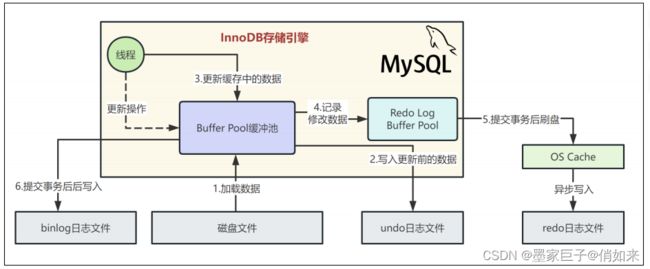
binlog日志的刷盘策略分析
对于binlog日志,其实也有不同的刷盘策略,有一个sync_binlog参数可以控制binlog的刷盘策略,他的默认值是0,此时你把binlog写入磁盘的时候,其实不是直接进入磁盘文件,而是进入os cache内存缓存。所以跟之前分析的一样,如果此时机器宕机,那么你在os cache里的binlog日志是会丢失的:
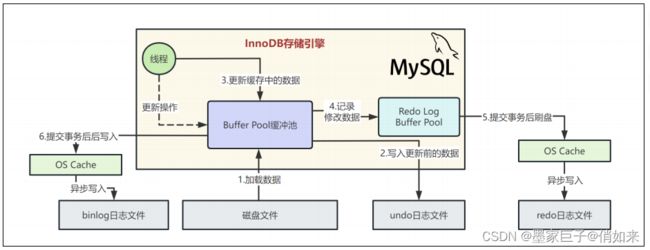
如果要是把sync_binlog参数设置为1的话,那么此时会强制在提交事务的时候,把binlog直接写入到磁盘文件里去,那么这样提交事务之后,哪怕机器宕机,磁盘上的binlog是不会丢失的。
基于binlog和redo log完成事务的提交
当我们把binlog写入磁盘文件之后,接着就会完成最终的事务提交,此时会把本次更新对应的binlog文件名称和这次更新的binlog日志在文件里的位置,都写入到redo log日志文件里去,同时在redo log日志文件里写入一个commit标记。在完成这个事情之后,才算最终完成了事务的提交,我们看下图的示意:
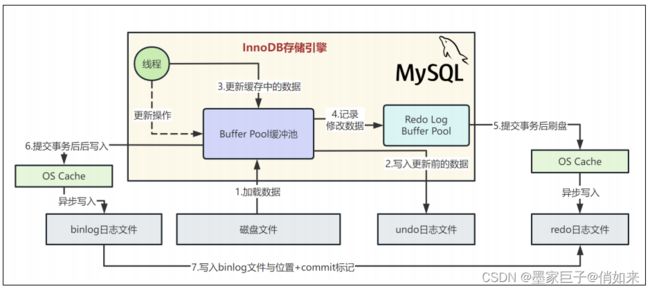
最后一步redo日志中写入commit标记的意义是什么?
用来保持redo log日志与binlog日志一致的,必须是在redo log中写入最终的事务commit标记了,然后此时事务提交成功,而且redo log里有本次更新对应的日志,binlog里也有本次更新对应的日志 ,redo log和binlog完全是一致的
后台IO线程随机将内存更新后的脏数据刷回磁盘
MySQL有一个后台的IO线程,会在之后某个时间里,随机的把内存buffer pool中的修改后的脏数据给刷回到磁盘上的数据文件里去,我们看下图:

在你IO线程把脏数据刷回磁盘之前,哪怕mysql宕机崩溃也没关系,因为重启之后,会根据redo日志恢复之前提交事务做过的修改到内存里去,然后等适当时机,IO线程自然还是会把这个修改后的数据刷到磁盘上的数据文件里去的。
10.总结
InnoDB存储引擎主要就是包含了一些buffer pool、redo log buffer等内存里的缓存数据,同时还包含了一些undo日志文件,redo日志文件等东西,同时mysql server自己还有binlog日志文件。
在你执行更新的时候,每条SQL语句,都会对应修改buffer pool里的缓存数据、写undo日志、写redo log buffer几个步骤;但是当你提交事务的时候,一定会把redo log刷入磁盘,binlog刷入磁盘,完成redo log中的事务commit标记;最后后台的IO线程会随机的把buffer pool里的脏数据刷入磁盘里去。
文章结束,点赞还是要求一下的,万一屏幕前的大漂亮,还有大帅哥就点赞了呢!!!!
