Linux C语言高级
软件包管理
file命令
file后面加文件名可以查看文件信息,也可以查看文件夹(目录)
在线软件包管理
在设置里面找到系统设置,点击进去找到software&update图标,点击进去可以更换软件源。
在路径/etc/apt里面可以查看软件源(例如:sources.list)可以把链接地址复制到软件源里面进行修 改软件源
apt命令
在线软件包管理

dpkg命令
离线软件包管理

Linux shell脚本编程
简单shell命令
sudo shutdown -h now立即关机
sudo shutdown -r now或sudo reboot now立即重启
sudo shutdown -h +45定时关机
sudo shutdown -r +60定时重启
权限相关命令
su -l root切换到超级用户(exit或者ctrl+D也可以退出超级用户)加-l的意思是环境同步切换到超级 用户环境下,不加-l只是用户切换到超级用户;也可以直接su不加任何东西,默认切换到root用户下,或者su - 等同于su -l root;
passward修改当前用户密码
passward username修改username密码
修改文件权限命令:字母法:chmod (u g o a)(+ - =)(r w x) (文件名)(例如:chmod u-x test意思是为自己减掉test文件的执行权限)(chmod u=rx test意思为用户自己对文件test只有读执行权限)
:数字法:chmod 数字 文件名(数字意思为有权限写为1无权限为0,最后转换成八进制,例如-rwx写为二进制就是111,转换成八进制就是07,在chemod后面的数字前面要加上0因为是八进制)
输入输出相关操作
echo输入命令可以直接在终端显示(echo 自带换行符,如果不想换行可以加-n,例如echo -n "hello"输出之后不换行)(-e可以转译换行符,比如echo -e “hello\n”不会打印\n,会转行。)
输入输出重定向
是指改变shell命令或程序默认的标准输入/输出目标,重新定向到新的目标。
默认输入输出的位置:

输出重定向:例如:有文件file,ls file查看文件信息,默认是把文件信息打印到终端,如果要打印到一个文件里面,需要使用ls file > log把文件信息打印到文件log里面,当要打印错误信息是需要在>前面加上2(2>),如果文件信息和错误信息都要打印到文件log里面,需要这样写:ls file >log 2>&1(可以简写为ls file &>log);
输入重定向:

通配符

管道符‘|’
可以把一系列命令连接起来,意味着第一个命令的输出将作为第二个命令的输入,通过管道传递给第二个命令,第二个命令的输出又将作为第三个命令的输入。
history:历史查询功能,可以查询历史上使用过的命令,默认保存五千条
!g可以查询上一条晗这个字母的命令
命令置换:符号为` `,作用是不把结果输出到终端上,而是保存起来,可以赋给一个变量或者给一个命令进行使用;例如:ls `pwd`意思是查看当前目录下的文件
文件处理相关命令
cat命令:查看文件的内容cat file
tac命令:查看文件的内容反向打印文件内容
more命令:查看文件的内容一次只显示一页,按回车键会继续往下显示,但不可以返回往上显示
less命令:查看文件的内容一次只显示一页,按上下键可翻阅
head命令:查看文件的内容只显示前十行;
硬链接和软链接

ln命令:创建硬链接(可以通过链接操作原文件)
ln -s命令:创建软连接
硬链接软连接区别

文件处理相关命令
查找文件命令
find -search for files in a directory hierarchy
语法:find [其实目录]寻找条件 操作
find相关选项
-name‘字串’查找文件名匹配给字串的所有文件,字串内可用通配符*、?、[]。
-iname‘字串’忽略大小写的方式查找
-type x查找类型为x的文件
-exec命令名称{}对符合条件的文件执行所给的Linux命令,而不询问用户是否需要执行该命令。{}表示命令的参数即为所找到的文件;命令的末尾必须以“\:”结束。

查找文件内容命令

cut命令

shell脚本的本质
编译型语言是C语言
shell脚本是解释型语言
shell脚本的本质就是shell命令的有序集合
shell编程的基本过程
建立shell文件
包含任意多行操作系统命令或shell命令的文本文件(shell文件后缀名为.sh)
赋予shell文件执行权限
用chmod命令修改权限
执行shell文件
直接在命令行上调用shell程序.执行文件的两种方式(./filename)(bash filename)
shell脚本写法为首行输入#! /bin/bash, 然后需按esc结束输入状态,按o键进行下行输入。
shell变量
shell允许用户建立变量存储数据,但不支持数据类型(比如整型、字符、浮点型),将任何赋给变量的值都解释为一串字符
variable=value
count=1//把1赋给count
echo $count//echo读取count的值
DATE='date'
echo $DATE
(unste加变量名为取消变量)
Bourne Shell有如下四种变量
用户自定义变量(也叫预定义变量)
位置变量即命令行参数
$0 与键入的命令行一样,包含脚本文件名
$1,$2,......$9 分别包含第一个到第九个命令行参数
$# 包含命令行参数的个数
$@包括所有命令行参数:"$1,$2,......$9"
$?包含前一个命令的退出状态
$*包含所有命令行参数:"$1,$2,......$9"
$$包含正在执行进程的ID号;
预定义变量
环境变量
HOME:/etc/passwd文件中列出的用户主目录
IFS:Internal Field Separator,默认为空格,tap及换行符
PATH:shell搜索路径
PS1, PS2:默认提示符($)及换行提示符(>)
TERM:终端类型,常用的有vt100,ansi,vt200,exterm等。
shell脚本-功能语句
shell程序由零或多条shell语句构成。shell语句包括三类:说明性语句、功能性语句和结构性语句。
说明性语句
以#号开始到该行结束,不被执行解释(等同于注释)
功能性语句
任意的shell命令、用户程序或其他shell程序。
read命令
read从标准输入读入一行,并赋值给后面的变量,其语法为:
read var:把读入的数据全部赋给var;
read var1 var2 var3:把读入行中的第一个单词(Word)赋给var1,第二个单词赋给var2,把其余所有的词赋给最后最后一个变量(read -p "提示语句" 变量)
如果执行read语句是标准输入无数据,则程序在此停留等候到数据的到来或被终止运行。
expr命令
算数运算命令expr主要用于进行简单的整数预算包括加减乘除和求余数(%)(乘法运算的时候符号为\*)
结构语句
条件测试语句、多路分支语句、循环语句、循环控制语句等。
测试语句
test语句:此语句可测试三种对象,分别为字符串 整数 文件属性
每种测试对象都有若干测试操作符
字符串测试:
test -z判断字符串是否为0
test -n判断字符串长度是否不为0
整数测试:
a -eq b 测试a与b是否相等
a -ne b测试a 与b是否不相等
a -gt b测试a是否大于b
a -ge b 测试a是否大于等于b
a -lt b 测试a是否小于b
a -le b 测试a是否小于等于b
文件测试:
-d name 测试name是否为一个目录
-e name 测试一个文件是否存在
-f name 测试name文件是否为普通文件
-L name 测试name文件是否为符号链接
-r name 测试name文件是否存在且为可读
-w name 测试name文件是否存在且为可写
-x name 测试name文件是否存在且为可执行
-s name 测试name文件是否存在且长度不为0
f1 -nt f2 测试文件f1是否比文件f2更新
f1 -ot f2 测试文件f1是否比文件f2更旧
例如:
test "$answer" = "yes"
变量answer的值是否为字符串yes
test $num -eq 18
变量num的值是否为整数18
test -d tmp
测试tmp是否为一个目录名
shell脚本-分支语句
结构性语句
结构性语句主要根据程序的运行状态、输入数据、变量的取值、控制信号以及运行时间等因素来控制程序的运行流程。
主要包括:条件测试语句(两路分支)、多路分支语句、循环语句、循环控制语句和后台执行语句等。
条件语句
写法为 if 表达式
then
命令表
fi
如果表达式为真,则执行命令表中的命令;否则退出if语句,执行fi后面的语句
if和fi是条件语句的语句,括号必须成对使用;
命令表中的命令可以是一条,也可以是若干条
多路分支语句
case...esac
多路分支语句case用于多重条件测试,语法结构清晰自然,其语法为
case 字符串变量 in
模式1)
命令表1
;;
模式2|模式3)
命令表2
;;
......
模式n)
命令表n
;;
注(case语句只检测字符串变量,各模式中可用文件名元字符,以右括号结束,一次可以匹配多个模式,用符号“|”隔开,命令表以单独的双分号行结束,退出case语句,模式n常写为字符“*”表示其他所有模式,最后一个双分号行可省略)
shell脚本-循环语句
for循环语句
当循环次数已知或确定时,使用for循环语句来多次执行一条或一组命令。循环体由由语句括号do和done来限定,格式为:
for 变量名 in 单词表
do
命令表
done
变量依次取单词表中的各个单词,每取一次单词就执行一次循环体重的命令。循环次数由单词表中的单词数确定。命令表中的命令可以是一条,也可以是由分号或换行符分开的多条。
如果单词表是命令上的所有位置参数时,可以在for语句中省略“in 单词表”部分
while循环语句
while循环语法结构为:
while 命令或表达式
do
命令表
done
while语句首先测试其后的命令或表达式的值,如果为真,就执行一次循环体中的命令,然后再测试该命令或表达式的值,执行循环体,直到该命令或表达式为假时退出循环
while语句退出状态为命令表中被执行的最后一条命令的退出状态
循环控制语句
break 判断条件满足,结束循环
continue 判断满足条件之后跳过此条件的循环
shell编程-函数
shell函数调用
函数书写规格为 <函数名>()
{
A=$1
B=$2
C=$3
NUM=`expr $A +$B +$C`
echo "$NUM"
}
调用 <函数名> 1 2 3
输出结果为6
函数变量调用域
函数内部的变量外部也可以使用,可以局部使用,可以内部使用,如果想要只在局部应用,需在前面加local ;例如:lacal A=$1,$1的值只能在函数内部使用,不能在外部使用。
C语言高级编程
gcc编译器
简介
全称GNU CC,GUN项目中符合ANSI C标准的编译系统。可编译三十多种语言
GCC是可以在多种硬体平台上编译出可执行程序的超级编译器,其效率比一般编译器高20%~30%
GCC是一个交叉平台编译器,适合在嵌入式领域的开发编译
gcc所支持后缀名解释

编译器的主要组件
分析器:分析器将源语言程序代码转换成汇编语言。因为要从一种格式转换成另一种格式,(C到汇 编),所以分析器需要知道目标机器的汇编语言
汇编器:链接器将汇编语言代码转换成CPU可以执行的字节码。
链接器:链接器将汇编器生成的单独的目标文件组合成可执行的应用程序,链接器需要知道这种目标格 式,以便工作
标准C库:核心的C函数都有一个主要的C库来提供。如果在应用程序中用到了C库中的函数,这个库就会通过链接器和源代码连接来生成最终的可执行程序。
GCC基本用法和选项
gcc最基本用法是:gcc [options][filenames]
-c,只编译,不连接成为可执行文件,编译器只是由输入的.c等源代码文件生成.o为后缀的目标文件,通常用于编译不包含主程序的子程序文件。
-o output_filename,确定输出文件的名称为output_filename,同时这个名称不能和源文件同名。如果不给出这个选项,gcc就给出预设的可执行文件a.out
-g,产生符号调试工具(GNU的gdb)所必要的符号咨询,要想对源代码进行调试,我们必须加入这个选项。
-O,对程序进行优化编译、连接,采用这个选项,整个源代码都会在编译、连接过程中进行优化处理,这样产生的可执行文件的效率可以提高,但是编译、连接的速度就相应的要慢一些。
-O2,比-O更好的优化编译、连接,当然整个编译、连接过程会更慢。
-I dirname,将diename所指出的目录加入到程序头文件目录列表中,是在预编译过程中使用的参数。
-L dirname, 将dirname所指出的目录加入到程序函数档案库文件的目录列表中,是在链接过程中使用的参数。
gcc编译过程:编辑器→预处理器→编译器→汇编处理→链接,生成预处理代码需要-E,例如:
gcc -E test.c -o test.i预处理阶段。编译阶段用-S:例如gcc -S test.c -o test.s; 最后汇编阶段用.s文件生成.o文件,需用到-c
wc可以查看文件信息:例如:wc test.c test.i 。

gdb调试工具
调试流程
首先使用gcc对test.c进行编译,注意一定要加上选项‘-g’,只有在代码处于“运行”
或暂停状态时才能查看变量的值;设置断点后程序在指定行之前停止。
例如:#gcc -g test.c -o test
#gdb test
l命令显示程序内容,一次只能显示10行,想继续显示只能继续输入l命令
b命令设置断点,方式为b加行号,意思为在次行号位置设置断点
r命令运行程序
n命令运行下一步
s命令进入函数
c命令自动剩余未执行的部分全部执行
q命令退出调试
help可以查看帮助
条件编译和结构体
条件编译
条件编译:编译器根据条件的真假决定是否编译相关的代码
常见的条件编译有两种方法
一、根据宏是否定义,其语法如下:
#ifdef
.........
#else
.......
#endif
例如:
#include
#define _debug_ //定义宏
int main()
{
#ifdef _debug_ //判断是否定义了宏,如果定义了就输出下面语句(如果想写成没定义执行下面的语句,用ifndef)
printf("hello");
#else
printf("welcome");//判断是否定义了宏,如果没有定义,就输出这句
#endif
return 0;
}//此程序输出结果为“hello”(注意,条件编译的ifdef else endif前面都需加#,
且ifdef与end if必须成对出现。) 二、根据宏的值,其语法如下:
#if
......
#else
......
#endif
#include
#define _debug_ 0//定义宏的值
int main()
{
#ifdef _debug_ //因为宏的值定位为0 就是假,所以执行else下面的语句
printf("hello");
#else
printf("welcome");
#endif
return 0;
}//此程序输出结果为“hello”(注意,条件编译的ifdef else endif前面都需加#,
且ifdef与end if必须成对出现。) 结构体
基本框架为:#include
struct <结构体名字>
{
};
int main()
{
return 0;
}
其中struct为固定输入。结构体名字在结构体后面直接给变量赋值的时候可以省略,但不建议
结构体例子:
#include
#include
struct student//struct为结构体语句,必须写,student为结构体名称
{
int num;//结构体的内容,可以无限多个不同类型的变量
char name[30];
float great;
}stu3 = {3, "xiaohong", 100};//3、可以直接在结构体后面为结构体里面的值赋值,此时可以省略结构体名称
int main(int argc, const char *argv[])
{
struct student stu1,stu2 = {2, "xiaozhang", 98.5};//定义变量时直接给结构体里面的变量赋值
stu1.num = 1;//单个赋值,方式为主函数变量名称.结构体变量名称
strcpy(stu1.name,"xiaoming");
stu1.great = 89.4;
printf("%d %s %f\n", stu1.num, stu1.name, stu1.great);
printf("%d %s %f\n", stu2.num, stu2.name, stu2.great);
printf("%d %s %f\n", stu3.num, stu3.name, stu3.great);
printf("%d\n",sizeof(struct student));//计算结构体大小,也可以用sizeof(struct student)/sizeof(int)
return 0;
}

结构体大小可以可以用sizeof(struct 结构体名称)或者sizeof(stu(其中一个变量))算出来;其中要注意的是字节对齐;比如int4个字节,char[18] 18个字节,则结构体的大小就是24个字节。
结构体数组和结构体指针
结构体后面的变量可以换成数组,通变量用法相同。
#include
#include
结构体指针输出时有两种方法:第一种(以后常用的方式)
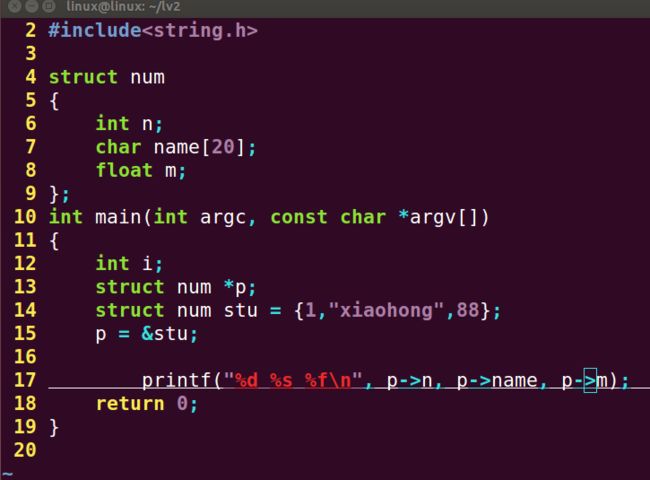
第二种
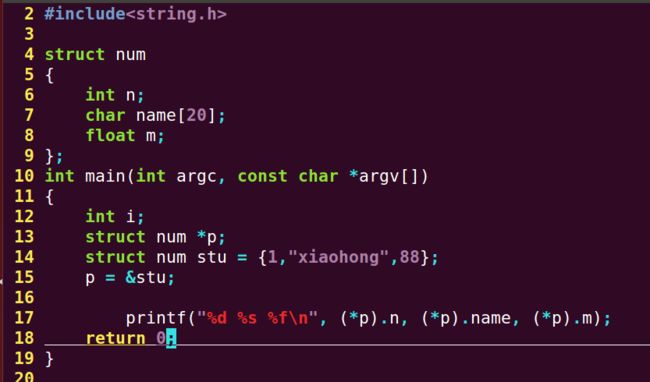
共用体及typedf
共用体概念
在C语言中,不同数据类型的数据可以使用共同的存储区域,这种数据构造类型称为共用体,简称共用,又称联合体。共用体在定义、说明和形式上与结构体相似。两者本质上的不同仅在于内存的方式上
定义一个共用体类型的一般方式为:
union共用体名
{
成员列表
};
例如:在共用体中第两个变量分别为int a; char b;
如果a=0x12345678
b='a'
则输出a,b的值为a=0x12345661;b=0x61(这是因为两个共用一个地址;nuion gy 的大小为4字节。
typedef
在C语言中,允许使用关键字typedef定义新的数据类型,其语法如下:
typedef <已有数据类型> <新数据类型>;
如:typedef int INTEGER;
这里重新定义了数据类型INTEGER,其等价于int
INTEGER I; <==> int i;
typedef 定义结构体或者共用体可以省略结构体或共用体的名字
方式为:typedef struct /union
{
int a;
char b;
}str;
内存管理
C/C++定义了4个内存区间:
代码区/全局变量与静态变量区/局部变量区即栈区/动态存储区,即堆区
静态存储分配
通常定义变量,编译器在编译时都可以根据该变量的类型知道所需内存空间的大小,从而系统在适当的时候为他们分配确定的存储空间。
在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置与处理器的指令集中,效率很高,但是分配的内存容量有限。
动态存储分配
有些对象只有在程序运行时才能确定,这样编译器在编译时就无法为他们预定存储空间,只有在程序运行时,系统根据运行时的要求进行内存分配,这种方法称为动态分配
所有的动态内存分配都在堆中进行
从堆上分配,也称动态内存分配。程序在运行的时候用malloc申请任意多少的内存,程序员自己负责在何时用free释放内存。动态内存的生存期由我们决定,使用非常灵活,但问题也多。
堆内存的分配与释放
当程序运行到需要一个动态分配的变量或对象时,必须向系统申请取得堆中的一块所需大小的存储空间,用于存储该变量或对象。当不再使用该变量或对象时,也就是它的声明结束时,要显示释放它所占用的存储空间,这样系统就能对该堆空间进行再次分配,做到重复使用有限的资源。
堆区是不会自动在分配的时候做初始化的(包括清零),所以必须用初始化式(initializer)来显示初始化。
malloc/free
void * malloc(size_t num)
void free(void *p)
malloc函数本身并不识别要申请的内存是什么类型的,它只关心内存的总字节数。
malloc申请到的是一块连续的内存,有时可能申请的空间较大,有时会申请不到空间,返回NULL。
malloc返回值的类型是void*,所以在调用malloc时要显示地进行类型转换,将void*转换成所需要的指针类型。
如果free的参数是NULL的话,没有任何效果
释放一块内存中的一部分是不被允许的。
malloc/free注意事项
删除 一个指针p(free(p);),实际意思是删除了p所指的目标(变量或对象等),释放了它所占的空间,而不是删除了p本身,释放堆空间后,p成空悬指针
动态分配失败,返回一个空指针(NULL)表示发生了异常,堆资源不足,分配失败。
malloc与free是配对使用的,free只能释放空间。如果malloc返回的指针值丢失,则所分配的堆空间无法回收,称为内存泄露,同一空间重复释放也是危险的,因为该空间可能已经另有分配,所以必须妥善保存malloc返回的指针,以抱枕不发生内存泄露,也必须保证不会重复释放堆内存空间。
#include
#include
#include
int main()
{
char *p;
p = (char *)malloc(20);//因为malloc返回类型为void,p的类型为char*,因此需要强制交换
if(p == NULL)//判断地址是否分配成功
{
printf("地址分配失败");
return -1;
}
strcpy(p, "hello");//把“hello”的值复制到地址p
printf("%s\n", p);
free(p);//释放p的地址
p = NULL;
return 0;
} Make
工程管理器,顾名思义,就是管理较多的文件
Make工程管理器就是一个“自动编译管理器”,这里的“自动”是指它能根据文件时间戳自动发现更新过的文件而减少编译的工作,同时,它通过读入Makefile文件的内容来执行大量编译工作。
Make只编译改动的代码文件,而不用完全编译
Makefile基本结构
Makefile是Make读入的唯一配置文件
有make工具创建的目标体(target),通常是目标文件或可执行文件
要创建的目标体所依赖的文件(dependency_file)
创建每个目标时需要运行的命令(command)
注意:命令行前必须是一个TAB键,否则编译错误为:***missing separator .Stop
target:dependency_file//由dependency_files文件生成target文件
command//命令行,前面需加TAP键,负责会产生错误
例如:
hello.o:hello.c hello.h
gcc -c hello.c hello.h
复杂一点的例子:
sunp:kang.o yul.o
gcc kang.o yul.o -o sunp
kang.o:kang.c kang.h
gcc -Wall -O -g -c kang.c kang.o
yul.h:yul.c
gcc -Wall -O -g -c yul.c -o yul.o
注释:-Wall表示允许发出gcc所有有用的报警信息。
-c只是编译不链接,生成目标文件“.o”
-o file:表示把输出文件输出到file里Makefile变量的创建和使用
创建变量的目的:用来代替一个文本字符串:
以下情况需要定义变量
系列文件的名字
传递给编译器的参数
需要运行的程序
需要查找源代码的目录
你需要输出信息的目录
你想做的其他事情
定义变量的两种方式
递归展开方式VAR=var
简单方式VAR: =var
变量使用$(VAR)
用$表示变量名,则用$$来表示
类似于编程语言中的宏
列如:
OBJS = kang.o yul.o
CC = gcc
CFLAGS = -Wall -O -g
sunq:$(OBJS)
$(CC)$(OBJS) -o sunq
kang.o:kang.c kang.h
$(CC) $(CFLAGS) -c kang.c -o kang.o
yul.o:yul.c yul.h
$(CC) $(CFLAGS) -c yul.c -o yul.o
递归展开方式VAR=var
例子:
foo = $(bar)
bar = $(ugh)
ugh = Huh?
$(foo)的值为?
echo $(foo)来进行查看
递归方式的优点是:它可以向后引用变量
缺点是:不能对该变量进行任何扩展,例如:
CFLAGS=$(CFLAGS) -O
会造成死循环。
简单方式VAR: =var
m: =mm
x: =$(m)
y: =$(x) bar
echo $(x) $(y)
看看打印什么信息?
简单方式:用这种方式定义的变量,会在变量的定义点,按照被引用的变量的当前值进行展开
这种定义变量的方式更适合在大的编程项目中使用,因为它更像我们一般的编程语言
用 ?=定义变量
比如 dir :=/foo bar
FOO ?= bar
FOO是?
意思是在前面是否定义过FOO,如果没定义过,则把FOO定义成bar
为变量添加值:意思为可以通过+=为已定义的变量添加新的值
例如:Main = hello.o hello-1.o
Main+=hello-2.o
最终Main=hello.o hello-1.o hello-2.o
预定义变量
AR 库文件维护程序的名称,默认值为ar。AS汇编程序的名称,默认值为as
CC C编译器的名称,默认值为cc。 CPP C预编译器的名称,默认值为$(CC) -E.
CXX C++编译器的名称,默认值为g++
FC FORTRAN编译器的名称,默认值为f77
RM 文件删除程序的名称,默认值为rm -f
Hello:main.c mian.h
$(CC) -O hello main.c
clean:
$(RM) hello预定义变量
ARFLAGS 库文件维护程序的选项,无默认值
ASFLAGS 汇编程序的选项,无默认值
CFLAGS C编译器的选项,无默认值
CPPFLAGS C预编译的选项,无默认值。
CXXFLAGS C++编译器的选项,无默认值
FFLAGS FORTRAN编译器的选项,无默认值
自动变量
$* 不包含扩展名的目标文件名称
$+ 所有的依赖文件,以空格分开,并以出现的先后为序,可能包含重复的依赖文件
$< 第一个依赖文件的名称
$? 所有时间戳比目标文件晚的依赖文件,并以空格分开
$@ 目标文件的完整名称
$^ 所有不重复的目标依赖文件,以空格分开
$% 如果目标是归档成员,则该变量表示目标的归档成员名称
比如:test : f1.o f2.o main.o ($*可以代替f1,f1.o可以写成$*.o;f1.o f2.o main.o都是依赖文件,test为目标文件。)
环境变量
make在启动时会自动读取系统当前已经定义了的环境变量,并且会创建与之具有相同名称和数值的变量
如果用户在Makefile中定义了相同名称的变量,那么用户自定义变量将会覆盖同名的环境变量。
直接运行make,有以下选项
-C dir 读入指定目录下的Makefile
-f file 读入当前目录下的file文件作为Makefile
-l忽略所有的命令执行错误
-l dir 指定被包含的Makefile所在目录
-n只打印要执行的命令,但不执行这些命令
-p 显示make变量数据库和隐含规则
-s 在执行命令时不显示命令
-w如果make在执行过程中改变目录,打印当前目录名。
Makefile的隐含规则
规则1:编译C程序的隐含规格:"
.o"的目标会自动推导为" .c",并且其生成命令是“$(CC) -c $(CPPFLAGS) $(CFLAGS)”
规则2:链接Object文件的隐含规则:"
"目标依赖于“ .o”,通过运行C的编译器来进行链接程序生成(一般是"ld"),其生成命令是:"$(CC) $(LDFLAGS) .o $(LOADLIBES) $(LDLIBS)".这个规则对于只有一个源文件的工程有效,同时也对多个Object文件(由不同的源文件生成)的也有效。列如如下规则:
Makefile的VPATH
VPATH是一个虚路径
在一些大的工程中,有大量的源文件,我们通常的做法是把这许多的源文件分类,并存放在不同的目录中。所以,当make需要去找寻文件的依赖关系时,你可以在文件前加上路径,但最好的方法是把一个路径告诉make,让make再自动寻找。
Makefile文件中的特殊变量“VPATH”就是完成这个功能的,如果没有指明这个变量,make只会在当前的目录中去找寻依赖文件和目标文件。如果定义了这个变量,那么,make就会在当前目录找不到的情况下,到所指定的目录中去找寻文件了。
VPATH=src:../headers
上面的定义是指定 两个目录,“src”和“../headers”,mak会按照这个顺序进行搜索。目录由“冒号”分隔。(当然,当前目录永远是最高有限搜素的地方)