【数据结构】手写单链表【纯C语言版】
摘要:本章主要讲述线性表的链式表示和用C语言实现单链表
目录
-
-
- 1. 链表
-
- 1.1 什么是单链表
- 1.2 单链表的逻辑图
- 1.3 顺序表和单链表物理结构的对比
- 2.单链表的代码实现
-
- 2.1 定义单链表的存储结构
- 2.2 单链表结点的空间开辟
- 2.3 单链表查尾
- 2.4 单链表尾插法
- 2.5 打印链表
- 2.6 单链表头插法
- 2.7 单链表头删法
- 2.8 单链表的查找
- 2.9 单链表的修改
- 2.10 单链表的插入
- 2.11 单链表的删除
- 2.12 计算链表长度
- 2.13 销毁单链表
- 3. 源码链接(含测试代码)
- 文章索引
- 后记
-
正文开始
1. 链表
1.1 什么是单链表
线性表链表存储结构的特点是:用一组任意的存储单元存储其数据元素;在逻辑上相邻,但在物理上一般不相邻。
因此,为了表示每个数据元素 ai 与其直接后继数据元素 ai+1 之间的逻辑关系,对于数据元素 ai 来说,出来存储本身信息置为,还应该存储应该指示其直接后继的信息(即直接后继的存储位置)。这两部分信息组数据元素 ai 的存储映射,称为结点(node)。
每个结点包括两个域:其中存储数据元素信息的域称为数据域;存储直接后继地址的域称为指针域。n(n≥1)个通过指针域链接成一个链表,即为线性表的链式存储结构。故线性表又称为线性链表或单链表
1.2 单链表的逻辑图


1.3 顺序表和单链表物理结构的对比
- 顺序表是利用
realloc一次性动态调整出一大块空间,所以这一大块空间中的每个单元,地址都是连续的。 - 单链表每一次都是用的
malloc开辟的一个空间,那么每个空间的地址一定是不一样且不连续的。
2.单链表的代码实现
2.1 定义单链表的存储结构
// 定义单链表数据域类型
typedef int SListDataType;
// 定义单链表存储结构
typedef struct SListNode
{
SListDataType data; // 数据域,用于存储数据
struct SListNode* next; // 指针域,用于存储直接后继的地址
} SListNode;
2.2 单链表结点的空间开辟
【算法步骤】
- 使用malloc申请一块SListNode大小的空间;
- 判断是否申请成功,如申请失败则结束程序;
- 为新结点的数据域赋值,且指针域指向空
- 将新结点地址返回
【算法描述】
// 创建新节点
SListNode * BuySListData(SListDataType* elem)
{
// 申请一个节点的空间
SListNode* newNode = (SListNode*)malloc(sizeof(SListNode));
if (!newNode)
{
perror("BuySListData");
exit(-1);
}
newNode->data = *elem;
// 节点指向空
newNode->next = NULL;
// 返回新节点
return newNode;
}
2.3 单链表查尾
查找最后一个结点的地址,即尾结点
尾结点:非空表的尾结点的指针域为NULL
【算法步骤】
- 判断链表是否为空,为空则中断程序;
- 定义指针变量tail,用于记录点当前结点;
- 循环使用tail不断后移,直到tail的指针域为空找到为结点时停止。
【算法描述】
// 查找最后一个结点,最后一个结点的指针域指向NULL
SListNode * SListLast(SListNode *phead)
{
// 链表为空则程序中断
assert(phead);
// 创建一个结点指针,用于保存当前结点
SListNode* tail = phead;
// 当 cur->next 为空的时候停止循环
while (tail->next)
{
tail = tail->next;
}
return tail;
}
2.4 单链表尾插法
【算法分析】
尾插法分2种情况:
-
空表时:

-
非空表时
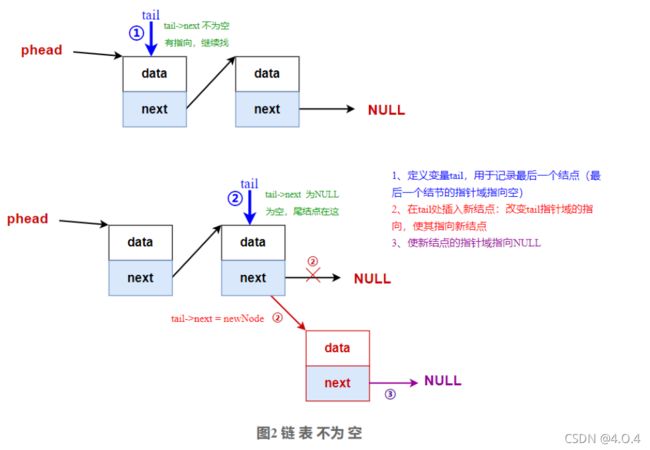
【算法步骤】
我相信大家仔细看了上述的图片后下来自己画一遍就能理解怎么做了
【算法描述】
// 尾插
void SListPushBack(SListNode** pphead, SListDataType* elem)
{
// 0.创建新节点
SListNode* newNode = BuySListData(elem);
// 第一次使用链表
if ( *pphead == NULL )
{
// 头节点为新创建的节点
*pphead = newNode;
}
// 插入节点
else
{
// 1.找尾
SListNode* tail = SListLast(*pphead);
// 2.使新节点和原来的尾结点连接起来,新节点作为新的尾结点
tail->next = newNode;
}
}
思考
为什么要传递二级指针作为形参数呢?
原因是这样的,因为我们的头结点本身就是一个指针,也叫头指针,如果我们希望改变其内部结构,就需要传递二级指针,这就是参数传址;如果我们形参使用一级指针,那就是参数传值。
2.5 打印链表
【算法步骤】
- 创建一个结点指针cur用于记录当前结点
- 如果当前结点不为空则打印,且cur指向下一个结点,以此循环往复
【算法描述】
// 打印
void SListPrint(SListNode* phead)
{
// 创建一个结点指针,用于保存当前结点
SListNode* cur = phead;
// cur不为空时执行循环
while (cur)
{
printf("%d --> ", cur->data);
// cur指向下一个节点,以为next作为指针域,保存着下一个节点的地址
cur = cur->next;
}
printf("NULL\n");
}
思考
结合尾插法,思考一下为什么这里的参数使用一级指针?
【测试】
int main()
{
SListNode* phead = NULL;
SListDataType elems[] = { 0,1,2,3,4,5,6,7,8,9 };
SListPushBack(&phead, &elems[1]);
SListPushBack(&phead, &elems[3]);
SListPrint(phead); // 1 3
return 0;
}
2.6 单链表头插法
头插法也分2种情况:
-
空表时:

-
非空表时:

【算法步骤】
同样的,大家仔细研究上图,然后自己在画出来理解一下就行了
【算法描述】
// 头插
void SListPushFront(SListNode** pphead, SListDataType* elem)
{
// 1.创建新结点
SListNode* newNode = BuySListData(elem);
// 2.新结点指向头结点
newNode->next = *pphead;
// 3.头结点指向新结点
*pphead = newNode;
}
2.7 单链表头删法
【算法步骤】
如图:只有一个结点和多个结点的情况

【算法描述】
/ 头删
void SListPopFront(SListNode** pphead)
{
// 1.链表为空
if (*pphead == NULL)
{
return;
}
// 2.只有一个结点
// 3.一个以上结点
else
{
// 保存头结点的下一个结点
SListNode* next = (*pphead)->next;
// 将头结点释放,即删除
free(*pphead);
// 头结点指向next
*pphead = next;
// 完成头删
}
}
2.8 单链表的查找
【分析】
根据指定数据进行查找,如果找到则返回该结点的地址;找不到则返回NULL
【算法描述】
SListNode* SListFind(SListNode* phead, SListDataType* elem)
{
// 当前结点为空时结束循环
while (phead != NULL)
{
if (phead->data == *elem)
{
// 找到指定元素,直接返回该结点
return phead;
}
// 指针后移
phead = phead->next;
}
return NULL;
}
2.9 单链表的修改
【分析】
找到指定数据的结点,然后修改数据域
【算法描述】
void SListModify(SListNode* phead, SListDataType* src, SListDataType* dest)
{
// 调用 SListFind 函数查找src所在结点
SListNode* destNode = SListFind(phead, src);
// 如果链表中没有src
if (!destNode) return;
// 修改值
destNode->data = *dest;
}
【思考】
这里我们也需要修改链表的值,那为什么形参为一级指针呢?
很简单,因为我们去查找具有指定数据的结点时,返回的是一个指针,那我们都拿到了一个结点的地址了,还有什么是做不到的呢?
2.10 单链表的插入
【算法步骤】
在单链表的pos位置后插入新结点
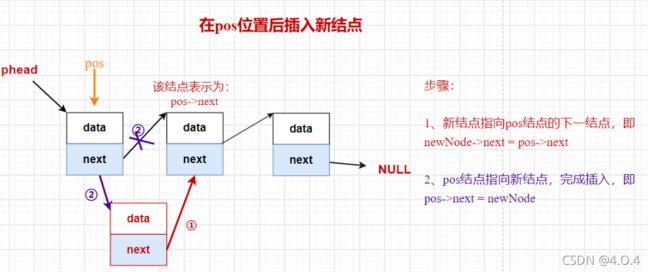
【算法描述】
// 单链表在pos之后插入elem,pos从[0,size-1]
void SListInsertAfter(SListNode* phead, size_t pos, SListDataType* elem)
{
// 查找指定位置pos处的结点
SListNode* posNode = SListFindByPos(phead, pos);
// 创建新结点
SListNode* newNode = BuySListData(elem);
if (!newNode)
{
perror("Insert Malloc");
exit(-1);
}
// 新结点指向当前结点的下一个结点
newNode->next = posNode->next;
// 当前结点指向新结点
posNode->next = newNode;
}
2.11 单链表的删除
【算法步骤】

【算法描述】
// 单链表在删除pos之后的一个结点,pos从[0,size-1]
void SListEraseAfter(SListNode* phead, size_t pos)
{
// 查找指定位置pos处的结点
SListNode* posNode = SListFindByPos(phead, pos);
// 使用next保存posNode后的结点,next就是我们要删除的元素
SListNode* next = posNode->next;
// 使用nextNext保存next后的结点
SListNode* nextNext = next->next;
// 将next释放
free(next);
// 使用posNode链接nextNext
posNode->next = nextNext;
// 删除完成
}
2.12 计算链表长度
【算法步骤】
使用一个变量记录当前结点,如果当前结点不为空,则指向下一结点;如果为空,则结束循环
【算法描述】
/ 计算当前链表长度
size_t SListSize(SListNode* phead)
{
SListNode* cur = phead;
size_t size = 0;
while (cur)
{
cur = cur->next;
size++;
}
return size;
}
2.13 销毁单链表
【算法步骤】
因为单链表的每个结构的内存空间都是独立的且不连续,所以我们需要一个接着一个的边遍历边释放
具体步骤大家可以看注释
【算法描述】
// 销毁链表
void SListDestory(SListNode** pphead)
{
assert(*pphead);
// 用于记录当前结点,并将其释放
SListNode* cur = *pphead;
// 用于记录当前结点的下一结点
SListNode* next = NULL;
// 如果当前结点不为空
while (cur != NULL)
{
// 记录当前结点的下一结点
next = cur->next;
// 释放当前结点
free(cur);
// 将next赋值给当前结点
cur = next;
}
// 完成所有结点的释放后,头指针变成了野指针,
// 需要将其置为NULL,这就是该函数需要二级指针的原因
*pphead = NULL;
}
3. 源码链接(含测试代码)
点击查看源码
【文件说明】
| 文件名 | 说明 |
|---|---|
| SList.h | 链表的类型定义和函数声明 |
| SList.c | 具体函数的实现 |
| test.c | 测试代码 |
文章索引
双链表
顺序表
后记
我水平有限,错误难免,还望各位加以指正。
关于单链表的内容到此结束,感谢您的阅读!!!如果内容对你有帮助的话,记得给我三连丫(点赞、收藏、关注)
【参考资料】
[1] 严蔚敏,李冬梅,吴伟民. 数据结构(C语言版)北京:人民邮电出版社,2015.2
本人博客所有文章,均为原创。部分文章中或引用相关资料,但均已著明来源出处。可随意转载、分享,但需加本文链接,以及版权说明。