SQL Server中的聚集索引和非聚集索引有什么区别?
Indexes are used to speed-up query process in SQL Server, resulting in high performance. They are similar to textbook indexes. In textbooks, if you need to go to a particular chapter, you go to the index, find the page number of the chapter and go directly to that page. Without indexes, the process of finding your desired chapter would have been very slow.
索引用于加快SQL Server中的查询过程,从而提高性能。 它们类似于教科书索引。 在教科书中,如果需要转到特定的章节,请转到索引,找到该章节的页码,然后直接转到该页面。 没有索引,查找所需章节的过程将非常缓慢。
The same applies to indexes in databases. Without indexes, a DBMS has to go through all the records in the table in order to retrieve the desired results. This process is called table-scanning and is extremely slow. On the other hand, if you create indexes, the database goes to that index first and then retrieves the corresponding table records directly.
这同样适用于数据库中的索引。 没有索引,DBMS必须遍历表中的所有记录才能检索所需的结果。 此过程称为表扫描,并且非常慢。 另一方面,如果创建索引,则数据库将首先转到该索引,然后直接检索对应的表记录。
There are two types of Indexes in SQL Server:
SQL Server中有两种类型的索引:
- Clustered Index 聚集索引
- Non-Clustered Index 非聚集索引
聚集索引 (Clustered Index)
A clustered index defines the order in which data is physically stored in a table. Table data can be sorted in only way, therefore, there can be only one clustered index per table. In SQL Server, the primary key constraint automatically creates a clustered index on that particular column.
聚集索引定义了数据在表中的物理存储顺序。 表数据只能以某种方式排序,因此,每个表只能有一个聚集索引。 在SQL Server中,主键约束自动在该特定列上创建聚簇索引。
Let’s take a look. First, create a “student” table inside “schooldb” by executing the following script, or ensure that your database is fully backed up if you are using your live data:
让我们来看看。 首先,通过执行以下脚本在“ schooldb”内部创建“学生”表,或者如果您正在使用实时数据,请确保数据库已完全备份 :
CREATE DATABASE schooldb
CREATE TABLE student
(
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
DOB datetime NOT NULL,
total_score INT NOT NULL,
city VARCHAR(50) NOT NULL
)
Notice here in the “student” table we have set primary key constraint on the “id” column. This automatically creates a clustered index on the “id” column. To see all the indexes on a particular table execute “sp_helpindex” stored procedure. This stored procedure accepts the name of the table as a parameter and retrieves all the indexes of the table. The following query retrieves the indexes created on student table.
注意,在“学生”表中,我们在“ id”列上设置了主键约束。 这将在“ id”列上自动创建聚簇索引。 若要查看特定表上的所有索引,请执行“ sp_helpindex”存储过程。 此存储过程接受表的名称作为参数,并检索表的所有索引。 以下查询检索在学生表上创建的索引。
USE schooldb
EXECUTE sp_helpindex student
The above query will return this result:
上面的查询将返回以下结果:
| index_name | index_description | index_keys |
| PK__student__3213E83F7F60ED59 | clustered, unique, primary key located on PRIMARY | id |
| index_name | index_description | index_keys |
| PK__学生__3213E83F7F60ED59 | 位于PRIMARY上的集群唯一主键 | ID |
In the output you can see the only one index. This is the index that was automatically created because of the primary key constraint on the “id” column.
在输出中,您只能看到一个索引。 这是由于“ id”列上的主键约束而自动创建的索引。
Another way to view table indexes is by going to “Object Explorer-> Databases-> Database_Name-> Tables-> Table_Name -> Indexes”. Look at the following screenshot for reference.
查看表索引的另一种方法是转到“对象资源管理器->数据库->数据库名称->表->表名称->索引”。 请看以下屏幕截图以供参考。
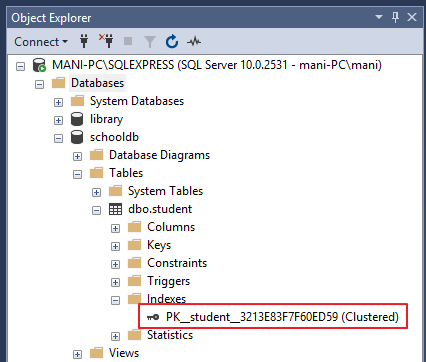
This clustered index stores the record in the student table in the ascending order of the “id”. Therefore, if the inserted record has the id of 5, the record will be inserted in the 5th row of the table instead of the first row. Similarly, if the fourth record has an id of 3, it will be inserted in the third row instead of the fourth row. This is because the clustered index has to maintain the physical order of the stored records according to the indexed column i.e. id. To see this ordering in action, execute the following script:
该聚集索引以“ id”的升序将记录存储在学生表中。 因此,如果插入记录具有5的ID,该记录将被表代替第一行的第 5行中的插入。 同样,如果第四条记录的ID为3,它将被插入第三行而不是第四行。 这是因为聚簇索引必须根据索引列(即id)来维护存储记录的物理顺序。 要查看此顺序的执行情况,请执行以下脚本:
USE schooldb
INSERT INTO student
VALUES
(6, 'Kate', 'Female', '03-JAN-1985', 500, 'Liverpool'),
(2, 'Jon', 'Male', '02-FEB-1974', 545, 'Manchester'),
(9, 'Wise', 'Male', '11-NOV-1987', 499, 'Manchester'),
(3, 'Sara', 'Female', '07-MAR-1988', 600, 'Leeds'),
(1, 'Jolly', 'Female', '12-JUN-1989', 500, 'London'),
(4, 'Laura', 'Female', '22-DEC-1981', 400, 'Liverpool'),
(7, 'Joseph', 'Male', '09-APR-1982', 643, 'London'),
(5, 'Alan', 'Male', '29-JUL-1993', 500, 'London'),
(8, 'Mice', 'Male', '16-AUG-1974', 543, 'Liverpool'),
(10, 'Elis', 'Female', '28-OCT-1990', 400, 'Leeds');
The above script inserts ten records in the student table. Notice here the records are inserted in random order of the values in the “id” column. But because of the default clustered index on the id column, the records are physically stored in the ascending order of the values in the “id” column. Execute the following SELECT statement to retrieve the records from the student table.
上面的脚本在学生表中插入了十条记录。 请注意,此处记录是按照“ id”列中值的随机顺序插入的。 但是由于id列上的默认聚集索引,记录实际上按照“ id”列中值的升序存储。 执行以下SELECT语句以从Student表检索记录。
USE schooldb
SELECT * FROM student
The records will be retrieved in the following order:
将按以下顺序检索记录:
| id | name | gender | DOB | total_score | city |
| 1 | Jolly | Female | 1989-06-12 00:00:00.000 | 500 | London |
| 2 | Jon | Male | 1974-02-02 00:00:00.000 | 545 | Manchester |
| 3 | Sara | Female | 1988-03-07 00:00:00.000 | 600 | Leeds |
| 4 | Laura | Female | 1981-12-22 00:00:00.000 | 400 | Liverpool |
| 5 | Alan | Male | 1993-07-29 00:00:00.000 | 500 | London |
| 6 | Kate | Female | 1985-01-03 00:00:00.000 | 500 | Liverpool |
| 7 | Joseph | Male | 1982-04-09 00:00:00.000 | 643 | London |
| 8 | Mice | Male | 1974-08-16 00:00:00.000 | 543 | Liverpool |
| 9 | Wise | Male | 1987-11-11 00:00:00.000 | 499 | Manchester |
| 10 | Elis | Female | 1990-10-28 00:00:00.000 | 400 | Leeds |
| ID | 名称 | 性别 | DOB | 总成绩 | 市 |
| 1个 | 欢乐 | 女 | 1989-06-12 00:00:00.000 | 500 | 伦敦 |
| 2 | 乔恩 | 男 | 1974-02-02 00:00:00.000 | 545 | 曼彻斯特 |
| 3 | 萨拉 | 女 | 1988-03-07 00:00:00.000 | 600 | 利兹 |
| 4 | 劳拉 | 女 | 1981-12-22 00:00:00.000 | 400 | 利物浦 |
| 5 | 艾伦 | 男 | 1993-07-29 00:00:00.000 | 500 | 伦敦 |
| 6 | 凯特 | 女 | 1985-01-03 00:00:00.000 | 500 | 利物浦 |
| 7 | 约瑟夫 | 男 | 1982-04-09 00:00:00.000 | 643 | 伦敦 |
| 8 | 老鼠 | 男 | 1974-08-16 00:00:00.000 | 543 | 利物浦 |
| 9 | 明智的 | 男 | 1987-11-11 00:00:00.000 | 499 | 曼彻斯特 |
| 10 | 埃利斯 | 女 | 1990-10-28 00:00:00.000 | 400 | 利兹 |
创建自定义聚集索引 (Creating Custom Clustered Index)
You can create your own custom index as well the default clustered index. To create a new clustered index on a table you first have to delete the previous index.
您可以创建自己的自定义索引以及默认的聚集索引。 要在表上创建新的聚集索引,您首先必须删除先前的索引。
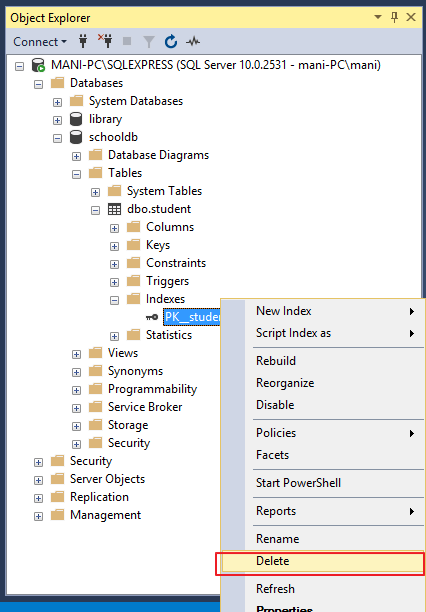
To delete an index go to “Object Explorer-> Databases-> Database_Name-> Tables-> Table_Name -> Indexes”. Right click the index that you want to delete and select DELETE. See the below screenshot.
要删除索引,请转到“对象资源管理器->数据库->数据库名称->表->表名称->索引”。 右键单击要删除的索引,然后选择“删除”。 请参见下面的屏幕截图。
Now, to create a new clustered Index, execute the following script:
现在,要创建新的聚集索引,请执行以下脚本:
use schooldb
CREATE CLUSTERED INDEX IX_tblStudent_Gender_Score
ON student(gender ASC, total_score DESC)
The process of creating clustered index is similar to a normal index with one exception. With clustered index, you have to use the keyword “CLUSTERED” before “INDEX”.
创建聚集索引的过程与普通索引相似,但有一个例外。 对于聚集索引,必须在“ INDEX”之前使用关键字“ CLUSTERED”。
The above script creates a clustered index named “IX_tblStudent_Gender_Score” on the student table. This index is created on the “gender” and “total_score” columns. An index that is created on more than one column is called “composite index”.
上面的脚本在学生表上创建了一个名为“ IX_tblStudent_Gender_Score”的聚集索引。 该索引在“性别”和“总计分数”列上创建。 在多个列上创建的索引称为“复合索引”。
The above index first sorts all the records in the ascending order of the gender. If gender is same for two or more records, the records are sorted in the descending order of the values in their “total_score” column. You can create a clustered index on a single column as well. Now if you select all the records from the student table, they will be retrieved in the following order:
上面的索引首先按性别的升序对所有记录进行排序。 如果两个或多个记录的性别相同,则记录在其“ total_score”列中按值的降序排序。 您也可以在单个列上创建聚簇索引。 现在,如果您从学生表中选择所有记录,则将按以下顺序检索它们:
| id | name | gender | DOB | total_score | city |
| 3 | Sara | Female | 1988-03-07 00:00:00.000 | 600 | Leeds |
| 1 | Jolly | Female | 1989-06-12 00:00:00.000 | 500 | London |
| 6 | Kate | Female | 1985-01-03 00:00:00.000 | 500 | Liverpool |
| 4 | Laura | Female | 1981-12-22 00:00:00.000 | 400 | Liverpool |
| 10 | Elis | Female | 1990-10-28 00:00:00.000 | 400 | Leeds |
| 7 | Joseph | Male | 1982-04-09 00:00:00.000 | 643 | London |
| 2 | Jon | Male | 1974-02-02 00:00:00.000 | 545 | Manchester |
| 8 | Mice | Male | 1974-08-16 00:00:00.000 | 543 | Liverpool |
| 5 | Alan | Male | 1993-07-29 00:00:00.000 | 500 | London |
| 9 | Wise | Male | 1987-11-11 00:00:00.000 | 499 | Manchester |
| ID | 名称 | 性别 | DOB | 总成绩 | 市 |
| 3 | 萨拉 | 女 | 1988-03-07 00:00:00.000 | 600 | 利兹 |
| 1个 | 欢乐 | 女 | 1989-06-12 00:00:00.000 | 500 | 伦敦 |
| 6 | 凯特 | 女 | 1985-01-03 00:00:00.000 | 500 | 利物浦 |
| 4 | 劳拉 | 女 | 1981-12-22 00:00:00.000 | 400 | 利物浦 |
| 10 | 埃利斯 | 女 | 1990-10-28 00:00:00.000 | 400 | 利兹 |
| 7 | 约瑟夫 | 男 | 1982-04-09 00:00:00.000 | 643 | 伦敦 |
| 2 | 乔恩 | 男 | 1974-02-02 00:00:00.000 | 545 | 曼彻斯特 |
| 8 | 老鼠 | 男 | 1974-08-16 00:00:00.000 | 543 | 利物浦 |
| 5 | 艾伦 | 男 | 1993-07-29 00:00:00.000 | 500 | 伦敦 |
| 9 | 明智的 | 男 | 1987-11-11 00:00:00.000 | 499 | 曼彻斯特 |
非聚集索引 (Non-Clustered Indexes)
A non-clustered index doesn’t sort the physical data inside the table. In fact, a non-clustered index is stored at one place and table data is stored in another place. This is similar to a textbook where the book content is located in one place and the index is located in another. This allows for more than one non-clustered index per table.
非聚集索引不会对表内的物理数据进行排序。 实际上,非聚集索引存储在一个位置,表数据存储在另一位置。 这类似于教科书,其中书本内容位于一个位置,索引位于另一个位置。 每个表允许一个以上的非聚集索引。
It is important to mention here that inside the table the data will be sorted by a clustered index. However, inside the non-clustered index data is stored in the specified order. The index contains column values on which the index is created and the address of the record that the column value belongs to.
重要的是要在这里提及,表中的数据将按聚簇索引排序。 但是,非聚集索引数据以指定顺序存储在内部。 索引包含在其上创建索引的列值以及该列值所属的记录的地址。
When a query is issued against a column on which the index is created, the database will first go to the index and look for the address of the corresponding row in the table. It will then go to that row address and fetch other column values. It is due to this additional step that non-clustered indexes are slower than clustered indexes.
当针对要在其上创建索引的列发出查询时,数据库将首先转到索引并在表中查找对应行的地址。 然后它将转到该行地址并获取其他列值。 由于此附加步骤,非聚集索引比聚集索引慢。
创建非聚集索引 (Creating a Non-Clustered Index)
The syntax for creating a non-clustered index is similar to that of clustered index. However, in case of non-clustered index keyword “NONCLUSTERED” is used instead of “CLUSTERED”. Take a look at the following script.
创建非聚集索引的语法与聚集索引的语法相似。 但是,在非聚集索引的情况下,使用关键字“ NONCLUSTERED”代替“ CLUSTERED”。 看一下下面的脚本。
use schooldb
CREATE NONCLUSTERED INDEX IX_tblStudent_Name
ON student(name ASC)
The above script creates a non-clustered index on the “name” column of the student table. The index sorts by name in ascending order. As we said earlier, the table data and index will be stored in different places. The table records will be sorted by a clustered index if there is one. The index will be sorted according to its definition and will be stored separately from the table.
上面的脚本在学生表的“名称”列上创建了一个非聚集索引。 索引按名称升序排序。 如前所述,表数据和索引将存储在不同的位置。 如果有,表记录将按聚簇索引排序。 索引将根据其定义进行排序,并将与表分开存储。
Student Table Data:
学生表数据:
| id | name | gender | DOB | total_score | City |
| 1 | Jolly | Female | 1989-06-12 00:00:00.000 | 500 | London |
| 2 | Jon | Male | 1974-02-02 00:00:00.000 | 545 | Manchester |
| 3 | Sara | Female | 1988-03-07 00:00:00.000 | 600 | Leeds |
| 4 | Laura | Female | 1981-12-22 00:00:00.000 | 400 | Liverpool |
| 5 | Alan | Male | 1993-07-29 00:00:00.000 | 500 | London |
| 6 | Kate | Female | 1985-01-03 00:00:00.000 | 500 | Liverpool |
| 7 | Joseph | Male | 1982-04-09 00:00:00.000 | 643 | London |
| 8 | Mice | Male | 1974-08-16 00:00:00.000 | 543 | Liverpool |
| 9 | Wise | Male | 1987-11-11 00:00:00.000 | 499 | Manchester |
| 10 | Elis | Female | 1990-10-28 00:00:00.000 | 400 | Leeds |
| ID | 名称 | 性别 | DOB | 总成绩 | 市 |
| 1个 | 欢乐 | 女 | 1989-06-12 00:00:00.000 | 500 | 伦敦 |
| 2 | 乔恩 | 男 | 1974-02-02 00:00:00.000 | 545 | 曼彻斯特 |
| 3 | 萨拉 | 女 | 1988-03-07 00:00:00.000 | 600 | 利兹 |
| 4 | 劳拉 | 女 | 1981-12-22 00:00:00.000 | 400 | 利物浦 |
| 5 | 艾伦 | 男 | 1993-07-29 00:00:00.000 | 500 | 伦敦 |
| 6 | 凯特 | 女 | 1985-01-03 00:00:00.000 | 500 | 利物浦 |
| 7 | 约瑟夫 | 男 | 1982-04-09 00:00:00.000 | 643 | 伦敦 |
| 8 | 老鼠 | 男 | 1974-08-16 00:00:00.000 | 543 | 利物浦 |
| 9 | 明智的 | 男 | 1987-11-11 00:00:00.000 | 499 | 曼彻斯特 |
| 10 | 埃利斯 | 女 | 1990-10-28 00:00:00.000 | 400 | 利兹 |
IX_tblStudent_Name Index Data
IX_tblStudent_Name索引数据
Notice, here in the index every row has a column that stores the address of the row to which the name belongs. So if a query is issued to retrieve the gender and DOB of the student named “Jon”, the database will first search the name “Jon” inside the index. It will then read the row address of “Jon” and will go directly to that row in the “student” table to fetch gender and DOB of Jon.
注意,索引中的每一行都有一列,用于存储名称所属的行的地址。 因此,如果发出查询以检索名为“ Jon”的学生的性别和DOB,则数据库将首先在索引内搜索名称“ Jon”。 然后它将读取“ Jon”的行地址,并将直接转到“学生”表中的该行以获取Jon的性别和DOB。
结论 (Conclusion)
From the discussion we find following differences between clustered and non-clustered indexes.
从讨论中,我们发现聚簇索引和非聚簇索引之间存在以下差异。
- There can be only one clustered index per table. However, you can create multiple non-clustered indexes on a single table. 每个表只能有一个聚集索引。 但是,您可以在单个表上创建多个非聚集索引。
- Clustered indexes only sort tables. Therefore, they do not consume extra storage. Non-clustered indexes are stored in a separate place from the actual table claiming more storage space. 聚集索引仅对表进行排序。 因此,它们不会消耗额外的存储空间。 非聚集索引存储在与实际表不同的位置,从而占用更多存储空间。
- Clustered indexes are faster than non-clustered indexes since they don’t involve any extra lookup step. 聚簇索引比非聚簇索引要快,因为它们不涉及任何额外的查找步骤。
本的其他精彩文章 (Other great articles from Ben)
| Difference between Identity & Sequence in SQL Server |
| What is the difference between Clustered and Non-Clustered Indexes in SQL Server? |
© 2020 Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy

| SQL Server中身份和序列之间的区别 |
| SQL Server中的聚集索引和非聚集索引有什么区别? |
©2020 Quest Software Inc.保留所有权利。 | GDPR | 使用条款 | 隐私
翻译自: https://www.sqlshack.com/what-is-the-difference-between-clustered-and-non-clustered-indexes-in-sql-server/