精华总结 |「跨越疫情之境,迈向新的征程」盘点一下2022年度我们开发团队对于云原生的技术体系的变革历程
云原生发展历程
-
- 「2022年已过去,最开心的两件事」
- 「盘点2022年的其他的重大的事件」
- 「直奔主题-云原生的改革之路」
-
- 【Kubernetes的版本升级】
-
- 版本升级大纲
- 升级版本
-
- 升级版本的必要性
- 更换可视化界面
-
- Rancher(摒弃选择)
-
- 中文官网首页(最新)
- Kuboard(最终选择)
- 【Kubernetes的配置优化调整】
-
- 探针经常会无缘无故Killed我们的服务
-
- 探针的种类
- 问题1 — 致命的143编码
- 配置结论心得
- 问题2 — 预警突然失效,无法进行内存预警
- 问题3 — pod频繁会被OOM Killed -137
- 问题4 — pod频繁会被Node进行驱逐(CPU过高/内存问题/硬盘问题)
- Kubernetes的对应Kill容器Pod的编码分析
- Kubernetes的Yaml文件配置优化阶段
-
- 时区问题调整
- 探针种类选取
- Kubernetes内存问题分析
-
- Heap堆内存出现过高的问题
- Native内存分析问题VM进程不一致问题
- K8s探测Java进程与堆内存不相符, 导致含有未知内存占用
- Grafana+Prometheus实例层级监控
- 云原生技术升级
-
- Dubbo云原生之路-升级到Dubbo 3, 并且对接K8s
-
- Dubbo3部署
-
- 配置Service.yml
- 配置Deployment.yml
- Apache APISIX 云原生网关服务
-
- Apache APISIX的优势是什么?
- 全平台
- 多协议
- K8s升级Autoscaling
-
- Kubernetes的Autoscaling
- AWS的Autoscaling
-
- Karpenter与Kubernetes的Autoscaling的区别
- 【2023年探索的方向】
-
- Rainbond
-
- 面向云原生应用的容器混合云—KubeSphere
-
- 企业级功能扩展
- 功能对比
- 开源社区活跃度对比
- 容器化能力对比
- CI/CD的对比
- 其他平台的云原生技术环境
-
- Google Computer Engine
- AWS EC2
- Azure
世界上并没有完美的程序,但是我们并不因此而沮丧,因为写程序就是一个不断追求完美的过程。
「2022年已过去,最开心的两件事」
一转眼,2022年就这么悄无声息的过去了,对我而言,最高兴的就是新冠疫情已经不是那么可怕了,大家不需要再担心天天怎么去排队做核酸了,哈哈…,相信你也有同感吧!同时也见证了足球史上非常伟大的一幕,梅老板终于圆梦,举起了期盼已久的大力神杯,再次回味一下这个时刻,如下图所示。

PS:来看梅西笑的多开心啊,哈哈…。
「盘点2022年的其他的重大的事件」
除了上面的两大事件之外,2022年还发生了很多其他引起国内外重视的的重大事件,国际社会波谲云诡,猴痘疫情又一波又起。此外,俄乌危机爆发、英国女王逝世等等,那么我就给大家列举一下我较为关注的一些事件。
当然了除了上述的事件之外还有很多其他的事件呢,在这里我就不一一列举了,不过未来的哪一天大家仍然可以通过这篇文章回顾这几项重大的事件,还是极好的。
「直奔主题-云原生的改革之路」
接下来我们就要进入本篇文章的重中之重,那就是我们2022年度,我们公司的技术团队在面向于云原生方向做了很多方面的变革和优化以及针对于技术方向的选取做了相关的调整,如下图所示,我梳理了整体的全盘计划。
接下来我们先来看看第一个板块【Kubernetes的版本升级】。
注意:看到了上面的图(由于图片的大小,以及内容较多)相信很多人都会抱怨看不清,对吧?没关系,我们抽丝剥茧为大家逐个拆分进行细化内容,大家就会很容易知道具体我们做了哪些调整和升级以及采坑。
【Kubernetes的版本升级】
版本升级大纲
总体的版本级别的改造大纲如下图所示。
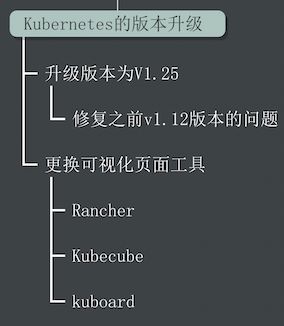
升级版本
升级Kubernetes集群版本是整个云原生变革体系中最关键的一环,也是最为谨慎对待的操作。我们将公司的Kubernetes服务从非常古老的版本(1.12版本)升级到了较新的(1.25版本),接下来我会大概阐述一下升级的原因以及大致的因素内容。
升级版本的必要性
针对于Kubernetes版本升级的必要性总体分为以下几个原因
-
【版本太低,官方无法维护、问题较多】 1.12版本过于古老,很多后续修复的安全、功能扩展,此版本尚且没有得到相关的修正且官方不支持修复,只能使用新版本了!
-
【安全问题,以及workaround的问题较多】 其实新版本与旧版本区别主要在于应用了社区中经过cherrypick挑选出来的PR以及修复了安全性漏洞、没有workaround(临时解决办法)的bug。
-
【稳定性能力】NGINX-Ingress 更加的稳定(v1.22开始) ,大家都知道Ingress是作为服务请求代理的必要入口,它的性能以及功能的扩展性决定着服务的运行能力,所以对他的升级也是很有必要的,而且他的bug也是对于我们服务的运行有着决定性的影响,下面就是Ingress与K8s的版本映射关系(新版本关系)

-
【新增功能】以下是我们较为关注和需要的K8s的主要功能
- 「卷快照的支持(v1.17版本开始)」 目前我们迫切需要,否则数据卷的恢复能力,完全不能用啊!每次我们都需要考虑自己去实现备份。
- 「准入Webhook(v1.19版本开始)」 将自定义策略或验证与 Kubernetes 集成的主要方式。 从 v1.19 开始,Admission Webhook 可以返回警告消息, 传递给发送请求的 API 客户端。警告可以与允许或拒绝的响应一起返回。
- 「Exec探测超时处理(v1.20版本开始)」 针对于嗅探机制的超时处理机制
- 「添加了对 Pod 层面启动探针和活跃性探针的控制(v1.20版本开始)」 向探针添加initializationFailureThreshold,允许在容器的初始启动期间出现更多的失败。
-
【可移植能力】Volume快照操作的标准体系,并允许用户以可移植的方式在任何 Kubernetes 环境和支持的存储提供程序上合并快照操作。
-
【容器能力扩展】在v1.20版本开始它移除 dockershim ,从而就实现了可以扩展为其他容器实现的急促
tips:维护dockershim 已经成为 Kubernetes 维护者肩头一个沉重的负担。 创建 CRI 标准就是为了减轻这个负担,同时也可以增加不同容器运行时之间平滑的互操作性。 但反观 Docker 却至今也没有实现 CRI,所以麻烦就来了。
更换可视化界面
主要是目前K8s容器管理而言主要采用了以下这三个可视化页面工具:分别是Rancher、kuboard和Kubernetes Dashboard。接下来分别介绍一下这三个工具。
Rancher(摒弃选择)
Rancher是一个开源的企业级多集群Kubernetes管理平台,实现了Kubernetes集群在混合云+本地数据中心的集中部署与管理,以确保集群的安全性,加速企业数字化转型。
中文官网首页(最新)
在升级到高版本K8s集群版本之前,我们使用的都是Rancher管理工具,如下图所示。
Kuboard(最终选择)
kuboard是一款专为 Kubernetes 设计的免费管理界面,兼容 Kubernetes 版本 1.13 及以上。看到这里相信大家应该知道了我们为什么改为kuboard了吗?1.13版本才能用哦。低版本不行滴。
那你会说为什么选择kuboard,而放弃了之前一直使用的Rancher呢?首先我归纳一下理由哈。
- 【使用体验】rancher访问速度过慢,因为要加载的组件和渲染的很多,虽然新版本已经优化了。
- 【dashboard看板】rancher在dashboard部分做的还是不如kubernetes dashboard或者kuboard更加直观。
- 【资源耗费】对比了以下我们的开发环境的使用效果之后,发现kuboard是三者(kubernetes dashboard、kuboard和rancher)之中最少的。
对于kubernetes dashboard而言我就不多说了,大家都用过,对于后续版本的页面效果和优化也还好一般,比起Rancher差不多少,细节做的优势不多,综合了一下最后选择了资源耗费最小的kuboard。
当然哈,还有很多其他的K8s的可视化管理工具,例如:lens、octant、weave-scope、还有我本人最喜欢的面向云原生应用的容器混合云的管理工具kubesphere、KuberLogic及 Kubecube等等,在这里就不一一介绍了。
最终我们将开开心心与kuboard度过一段较长的旅程。
在这里给没有接触过kuboard的小伙伴一些资料。可以学习一下哈。
- Github地址:https://github.com/eip-work/kuboard-press
- Kuboard教程:http://press.demo.kuboard.cn/
还有对应的demo演示服务,可以让您快速上手做练习工作,多么方便,你可以不需要搭建自己的Kuboard服务,如下图所示。

我们讲完了我们大致升级了对应的版本升级之后,想跟大家在分享一下,我们在升级过程中所出现的问题,但是由于篇幅所限,在这里就不列举了,后面有机会再跟大家分享。而我们接下来要介绍一下发生在老版本K8s的时候所出现的种种问题。
【Kubernetes的配置优化调整】
2022年技术团队针对于Kubernetes的配置优化调整主要做了4个方面的问题的调整和优化工作路线,当然这只是面向于研发层面的哈。
- 探针经常会无缘无故Killed我们的服务
- Kubernetes的对应Kill容器Pod的编码分析
- Kubernetes的Yaml文件配置优化阶段
- kubernetes的应用故障排查
探针经常会无缘无故Killed我们的服务
探针的种类
-
livenessProbe:指示容器是否正在运行。如果存活态探测失败,则 kubelet 会杀死容器, 并且容器将根据其重启策略决定未来。如果容器不提供存活探针, 则默认状态为 Success。
-
readinessProbe:指示容器是否准备好为请求提供服务。如果就绪态探测失败, 端点控制器将从与 Pod 匹配的所有服务的端点列表中删除该 Pod 的 IP 地址。 初始延迟之前的就绪态的状态值默认为 Failure。 如果容器不提供就绪态探针,则默认状态为 Success。
-
startupProbe:指示容器中的应用是否已经启动。如果提供了启动探针,则所有其他探针都会被 禁用,直到此探针成功为止。如果启动探测失败,kubelet 将杀死容器, 而容器依其重启策略进行重启。 如果容器没有提供启动探测,则默认状态为 Success。
而总体所出现的原因大致有这么几种:
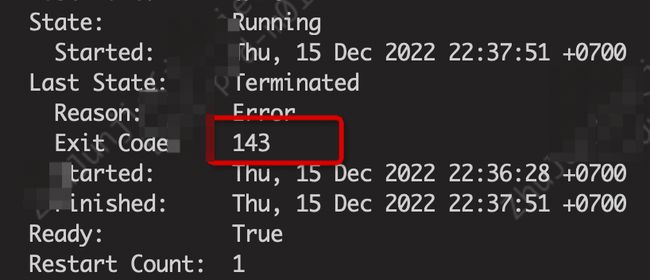
问题1 — 致命的143编码
探针检测导致进程会出现直接kill -15,被直接Shutdown掉(K8s的exit code是143),因为探针请求超时并且抄过来所配置的阈值范围内,即可出现这个问题,最终频繁让我们的业务系统自动被干掉或者自动下线,用户体验度很差!我们总称之位这就是致命的143编码,如下图所示。
【探针配置参数调整】在系统负载过高的时候以及针对于对于响应速度和吞吐不同场景的服务需要分别去处理和考虑对应的参数,而不能同日而语!
这就是我们常规的探针配置,主要关注的就是:timeout(超时时间)、间隔、失败阈值。三者贯穿的概念就是在间隔N秒情况下,当超时/失败的次数超过了失败阈值之后,就会被Kill掉。
![]()
- initialDelaySeconds:容器启动后要等待多少秒后才启动启动、存活和就绪探针, 默认是 0 秒,最小值是 0。
- periodSeconds:执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1。
- timeoutSeconds:探测的超时后等待多少秒。默认值是 1 秒。最小值是 1。
- successThreshold:探针在失败后,被视为成功的最小连续成功数。默认值是 1。 存活和启动探测的这个值必须是 1。最小值是 1。
- failureThreshold:当探测失败时,Kubernetes 的重试次数。 对存活探测而言,放弃就意味着重新启动容器。 对就绪探测而言,放弃意味着 Pod 会被打上未就绪的标签。默认值是 3。最小值是 1。
配置结论心得
-
面向于注重吞吐的服务或者计算相关的服务,最好不要加入K8s的相关探针,而是加入其他监控,否则很容易再负载较高的时候,把你的服务直接干掉。我们采用了加入了预警,通过对比业务数据来确认是否真正服务假死或者夯住了。
-
面向于注重用户体验和响应时间的相关服务,我们是将根据量的大小,在不同的时间范围内切换不同的配置,降低探针出现的误判问题。当然你也可以是定义 TCP 的存活探测代替Http探测!
问题2 — 预警突然失效,无法进行内存预警
给大家看一下我们的配置容器配置:

相信这两个选项大家并不陌生,主要配置的最大内存就是3G。而我们的预警阈值是90%,那么预警的内存大小就是2.7G,而我们的JVM参数是1.8G。
![]()
这会导致我们JVM都crash了,这边还没有达到预警呢!所以这边我们调整了一下我们的计算公式。
我们的Pod(容器)内存>JVM内存>预警内存(90%)。
问题3 — pod频繁会被OOM Killed -137
这个与上面的不一样哦!OOM Killed是容器内部的内存溢出,而不是JVM的。所以这地方主要的原因是什么呢。经过我们的长期考证,最后得出的结论就是直接内存导致,一直处于RSS中,不会被回收,虽然我们的一直在执行GC,但是因为很久没有执行FGC,所以就没有办法进行回收Off Heap Space。所以如果感兴趣的小伙伴可以参考我的之前的分析文章。
- 【JVM故障问题排查心得】「内存诊断系列」JVM内存与Kubernetes中pod的内存、容器的内存不一致所引发的OOMKilled问题总结(上)
问题4 — pod频繁会被Node进行驱逐(CPU过高/内存问题/硬盘问题)
后续的针对于某一个Pod的资源过高所引起的Node驱逐实现,我们使用以下标志来配置软驱逐条件:
- eviction-soft:一组驱逐条件,如 memory.available<1.5Gi, 如果驱逐条件持续时长超过指定的宽限期,可以触发 Pod 驱逐。
- eviction-soft-grace-period:一组驱逐宽限期, 如 memory.available=1m30s,定义软驱逐条件在触发 Pod 驱逐之前必须保持多长时间。
- eviction-max-pod-grace-period:在满足软驱逐条件而终止 Pod 时使用的最大允许宽限期(以秒为单位)。
Kubernetes的对应Kill容器Pod的编码分析

-
(Exit Codes 0)docker run hello-world 进程结束,exit code为0
-
(Exit Codes 1)程序自身崩溃报错,或者人工把dockerfile中的启动命令写错,都会报exit code 1
-
(Exit Codes 137)程序收到了SIGKILL (signal kill)信号,被手动干预杀死进程,或者违反系统限制被杀 都会报错 exit code 137
-
(Exit Codes 139)程序 segmentation fault,程序试图访问不被允许访问的内存地址,可能是程序代码或者是基础镜像的错误,可能报错 exit code 139
-
(Exit Codes 143)容器收到了 SIGTERM 指令,也就是停止的指令,例如docker stop 或者 docker-compose down , docker stop 也可能会出 137 的exit code (当程序不恰当处理SIGTERM错误)
后面我没就通过以上的这些exit code的分类和归纳,就像相应的问题处理。在这里无论是137、143的这个编码都是通过128+kill -(N)算出来的,137 就是 -9 杀掉的进程,143则是 -15。
Kubernetes的Yaml文件配置优化阶段
其实针对于Yaml文件配置优化的地方我们调整了很多很多,在这里我们就单纯的叙述几个改动点吧。
时区问题调整
问题原因是我们的服务是跨国的,垮了很多的时区位置,甚至在墨西哥的时候还需要考虑的是冬令时和夏令时的缘故,所以对时间特别的敏感,所以这就需要再K8s在不同的地区建立不同的指定时区才可以,例如下图所示。

所以我们需要通过环境变量ENV,在不同的环境进行优化,之前没有考虑到这一点,导致很多环境的时间竟然还用的是东八区的时间,太离谱了哈!
探针种类选取
还是源于上面的探针竟然把我们的业务服务给shutdown了,主要原因就是请求超时,那超时的直接原因主要就是容器的线程池满了,根本原因是请求处理的时间过长,那么这时候有什么workaround方案吗?
好我们选取了主要就是将探针的探测方式改为Exec模式与Tcp模式。不知道大家对这两个方式了解的多吗?主要就是为了考虑http资源池满了所引发的超时问题哈。
-
exec:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
-
tcpSocket:对容器的 IP 地址上的指定端口执行 TCP 检查。如果端口打开,则诊断被认为是成功的。 如果远程系统(容器)在打开连接后立即将其关闭,这算作是健康的。
最后我们选择了tcpSocket模式进行监控了我们很多的流式计算以及吞吐较高的容器服务,果真容器Down的几率降低了很多,当然还有很多很多优化的配置,由于篇幅所限,所以更多的分享我会出专门的专栏为大家详细分享。
Kubernetes内存问题分析
本次内容和云原生和k8s暂时没有太多直接关系。

Heap堆内存出现过高的问题
主要原因是日志打印过多所导致的,会导致进程的内存一直处于一个条平衡线。所以建议搭建少打无用日志,尽可能打印精确信息,而不是整个对象的信息哈!如下图所示。

Native内存分析问题VM进程不一致问题
主要就是针对于直接内存中的类空间的预占用资源达到了1G之多,这个太不符合常理了,所以这个比较的明细,所以这个地方算是我们后面改造的方案,加入了 direct ByteBuffer -> -XX:MaxDirectMemorySize的控制。以及定时执行System.gc()。

K8s探测Java进程与堆内存不相符, 导致含有未知内存占用
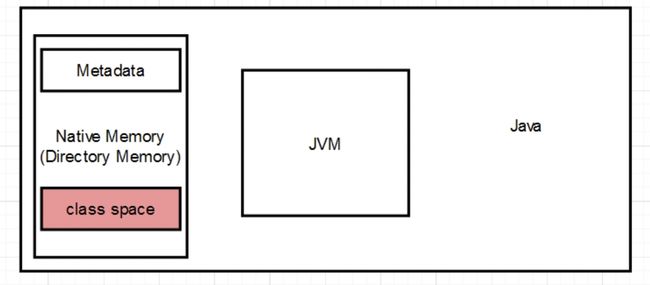
两者都是和直接内存有关系,如果大家想了解为什么,可以参考我下面的这篇文章的下集。
- 【JVM故障问题排查心得】「内存诊断系列」JVM内存与Kubernetes中pod的内存、容器的内存不一致所引发的OOMKilled问题总结(下)
Grafana+Prometheus实例层级监控
主要是为了针对于容器化进行建立容器机制监控。主要建立了pod内存监控、docker容器内存监控和CPU负载能力的监控,如下图所示。

有了这个我们就可以观察任何时间范围内内存以及CPU相关的资源使用信息了。
云原生技术升级
在今年我们三个方向的技术升华,其中对应的k8s集群升级上面基本介绍过了,接下来主要介绍【Dubbo云原生之路-升级到Dubbo 3, 并且对接K8s】和【Apache APISI 云原生网关服务】

Dubbo云原生之路-升级到Dubbo 3, 并且对接K8s
在云原生时代,底层基础设施的变革正深刻影响应用的部署、运维甚至开发过程,往上也影响了 Dubbo3 微服务技术方案的选型与部署模式。我们公司也一直在不断推进和落地K8s云原生方向。
Dubbo3部署
Dubbo3 开发的应用可以原生部署到 Kubernetes 平台,Dubbo3 在地址、生命周期等已设计可与 Kubernetes 等容器调度平台对齐;对于要进一步复用 Kubernetes 底层基础设施能力的用户来说,Dubbo3 也已对接到了原生的 Kubernetes Service 体系。主要就是依靠这三个部分。
- 部署 Dubbo 应用到 Kubernetes
- 基于 Kubernetes 内置 Service 实现服务发现
- 将 Dubbo 应用对接到 Kubernetes 生命周期
配置Service.yml
apiVersion: v1
kind: Service
metadata:
name: apiserver-consumer
namespace: dubbo-namespace
spec:
clusterIP: None
selector:
app: apiserver-consumer
ports:
- protocol: TCP
port: 20880
targetPort: 20880
配置Deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: apiserver-consumer
namespace: dubbo-demo
spec:
replicas: 1
selector:
matchLabels:
app: apiserver-consumer
template:
metadata:
labels:
app: apiserver-consumer
spec:
containers:
- name: server
image: XXX/dubbo:apiserver-consumer_0.0.1
ports:
- containerPort: 20880
livenessProbe:
httpGet:
path: /live
port: 22222
initialDelaySeconds: 5
periodSeconds: 5
readinessProbe:
httpGet:
path: /ready
port: 22222
initialDelaySeconds: 5
periodSeconds: 5
startupProbe:
httpGet:
path: /startup
port: 22222
failureThreshold: 30
periodSeconds: 10
Apache APISIX 云原生网关服务
我们代理端选型为APISIX作为我们的云原生网关代替之前的Nginx,具体而言给大家介绍一下Apache APISIX的优势是什么?
Apache APISIX的优势是什么?
APISIX是一个动态、实时、高性能的云原生 API 网关,提供了负载均衡、动态上游、灰度发布、服务熔断、身份认证、可观测性等丰富的流量管理功能。它能够在云原生和微服务的技术环境下,帮助企业解决一些新的问题。比如通过全动态特性将业务的流量进行自动扩缩容、通过一次性修改进行更方便地集群化管理等。

全平台
- 云原生: 平台无关,没有供应商锁定,无论裸机还是 Kubernetes,APISIX 都可以运行。
- 运行环境: OpenResty 和 Tengine 都支持。
- 支持 ARM64: 不用担心底层技术的锁定。
多协议
- TCP/UDP 代理: 动态 TCP/UDP 代理。
- Dubbo 代理: 动态代理 HTTP 请求到 Dubbo 后端。
- 动态 MQTT 代理: 支持用 client_id 对 MQTT 进行负载均衡,同时支持 MQTT 3.1.* 和 5.0 两个协议标准。
- gRPC 代理:通过 APISIX 代理 gRPC 连接,并使用 APISIX 的大部分特性管理你的 gRPC 服务。
- gRPC 协议转换:支持协议的转换,这样客户端可以通过 HTTP/JSON 来访问你的 gRPC API。
- Websocket 代理
- Proxy Protocol
- Dubbo 代理:基于 Tengine,可以实现 Dubbo 请求的代理。
- HTTP(S) 反向代理
- SSL:动态加载 SSL 证书。
K8s升级Autoscaling

目前我们正在针对于云原生的变革工作很重要的一步就是将逐步更换K8s自带的Autoscaling机制,从而使用AWS的Autoscaling,它叫做Karpenter,是新一代 Kubernetes auto scaling 工具。为什么会这么做?我们先来分一下两者区别。
Kubernetes的Autoscaling
Kubernetes已经实现集群自动缩放的工具,有Cluster Autoscaler、Escalator和Cerebral等。
K8s集群根据需求的增长而自动扩容;通过有效整合利用资源和终止不必要的节点而较少基础架构带来的成本;其开发者是中立的,支持所有主流的公有云厂商;应用广泛,通过了实战的考验;支持大约1000个节点的集群。
AWS的Autoscaling
Karpenter 是一个为 Kubernetes 构建的开源自动扩缩容项目。 它提高了 Kubernetes 应用程序的可用性,而无需手动或过度配置计算资源。
它旨在通过观察不可调度的 Pod 的聚合资源请求并做出启动和终止节点的决策,以最大限度地减少调度延迟,从而在几秒钟内(而不是几分钟)提供合适的计算资源来满足您的应用程序的需求。
Karpenter与Kubernetes的Autoscaling的区别
Karpenter取消了节点组的概念,这是它与Cluster Autoscaler 的根本区别,节点组通常是效率较低的原因之一,此外Karpenter更加有优势的特点如下:
-
Karpenter 直接提供计算资源,动态的计算pod需要何种大小的EC2实例类型作为节点。
-
从Cluster Autocaler 的静态模版到 Karpenter 的动态生成模版,不必去创建节点组来确定实例的各种属性,从而降低了配置的复杂性。
-
Cloud Provider的API负载也会大大减少,在Cluster Autocaler 中,Auto Scaling group总会不断请求Cloud Provider来确认状态,在集群庞大以后,很可能碰到API调用限制,造成整个系统停止响应。
-
Karpenter只在创建和删除容量时调用API,这种设计可以支持更高的API吞吐量。没有了节点组,调度的复杂程度也被降低,因为Cluster Autoscaler 不同节点组有不同属性,需要考虑pod被调度到哪个节点组。
综合一下,我们会慢慢转移选择性能更好,切换速度更快的Karpenter,此外因为后面我们也要更加全方面介入到AWS中,所以Karpenter是必然之选。
【2023年探索的方向】

Rainbond
计划采用云原生时代的“应用级别”多云管理平台Rainbond,这个是一个较为新颖的平台。

Rainbond是一个云原生应用管理平台,使用简单,不需要懂容器、Kubernetes和底层复杂技术,支持管理多个Kubernetes集群,和管理企业应用全生命周期。它深度整合应用开发、微服务架构、应用交付、应用运维、资源管理,管理高度自动化,实现统一管理所有应用、所有基础设施和所有IT流程。

面向云原生应用的容器混合云—KubeSphere
KubeSphere 是在 Kubernetes 之上构建的面向云原生应用的分布式操作系统,完全开源,支持多云与多集群管理,提供全栈的 IT 自动化运维能力,简化企业的 DevOps 工作流。作为全栈的多租户容器平台,KubeSphere 提供了运维友好的向导式操作界面,帮助企业快速构建一个强大和功能丰富的容器云平台。
企业级功能扩展
多云与多集群管理、Kubernetes 资源管理、DevOps、应用生命周期管理、微服务治理(服务网格)、日志查询与收集、服务与网络、多租户管理、监控告警、事件与审计查询、存储管理、访问权限控制、GPU 支持、网络策略、镜像仓库管理以及安全管理等。

功能对比
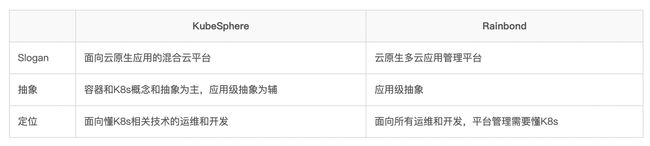
开源社区活跃度对比

容器化能力对比

CI/CD的对比

未来我们将要放弃kuboard/kubernetes dashboard管理工具,从而选择KubeSphere 和Rainbond。两者相比而言各有千秋,对于多云以及云原生扩展角度而言我们会侧重Rainbond,而对于私有云而言我们会侧重于KubeSphere。
其他平台的云原生技术环境
Google Computer Engine
未来发展到Google云平台服务部署K8s集群部署我们的服务。
AWS EC2
未来发展到亚马逊AWS云平台服务部署K8s集群部署我们的服务。
Azure
未来发展到微软Azure云平台服务部署K8s集群部署我们的服务。
写不动了,就写到这里吧,谢谢大家多多支持和多多指正!