全国大学生数据统计与分析竞赛2021年【本科组】-B题:用户消费行为价值分析
目录
摘 要
1 任务背景与重述
1.1 任务背景
1.2 任务重述
2 任务分析
3 数据假设
4 任务求解
4.1 任务一:数据预处理
4.1.1 数据清洗
4.1.2 数据集成
4.1.3 数据变换
4.2 任务二:对用户城市分布情况与分布情况可视化分析
4.2.1 城市分布情况可视化分析
4.2.2 登录情况可视化分析
4.3 任务三:建立随机森林分类模型进行预测
4.3.1 符号说明
4.3.2 模型准备
4.3.3 预测模型的选择
4.3.4 随机森林分类模型
4.3.5 特征重要性分析
4.3.6 预测实验
4.3.7 模型评价
4.4 任务四:用户消费行为价值分析与建议
4.4.1 用户行为分析
4.4.2 用户行为转化分析
4.4.3 用户价值分析——RFM
4.4.4 给企业的建议
参考文献
代码实现
数据预处理部分代码展示
摘 要
随着线上教育平台的兴起,如何判别高价值用户并优化成本已然成为平台的重要工
作。本文依据题目所给数据研究某儿童线上教育平台的用户消费行为,将用户关键信息
进行可视化,建立数据预测模型,并最终为企业提出合理建议。
针对任务一,本文首先对数据进行清洗,处理掉重复值、缺失值、无效值与异常值,
例如针对用户信息表删除重复用户 id 数据 19265 条,删除城市信息缺失数据 24089 条,
删除城市信息异常数据 399 条。随后,为了方便数据查找与集中处理,将后续任务需用
到的数据进行集成处理。最后,为了将数据转变为更适合数据挖掘的形式,对数据采用
零 - 均值规范化( z-score 标准化),便于后续数据模型的建立。
针对任务二,需要从用户城市分布与用户登录情况进行数据可视化分析。分析用户
城市分布是为了得到该 APP 的用户核心分布区,故从城市位置分布与用户数量分布两
方面入手。首先将预处理好后的城市信息导入地图,发现用户城市分布较为广泛,城市
密度东密西疏,对城市位置进行聚类分析,得出城市集中分布的五大区域,随后对用户
数量分布进行分析,发现该 APP 用户大部分集中在成渝、华北 - 北京、珠三角以及长三
角,综合得出该四大区域为用户核心分布区。对于用户登录情况,本文从用户活跃度与
用户流失两方面进行分析,利用玫瑰图、面积图等得出该 APP 存在活跃用户数偏低,
营销转化不足等问题。
针对任务三,需要以用户是否会购买下单为目标建立数据模型。购买预测问题本质
上是二分类问题,因此本文将下单用户标记为 1 ,未下单标记为 0 。从中随机选取 75%
的数据作为训练集,并对剩余数据进行预测与结果比对。在预测模型的选择上,本文分
别比较了随机森林分类、逻辑回归与决策树分类三种模型的预测结果,从中选取了准确
率最高的随机森林分类作为最终模型,计算特征权重,进行预测实验。最后根据混淆矩
阵表明,该模型训练良好,且准确率达到 98.3% 。
针对任务四,需要从用户消费行为与用户价值两个方面进行分析,并对企业给出建
议。本文首先将用户消费行为分为访问、关注领券和开课购买三个部分,并分别统计出
行为量。随后将这三个行为放到空间、年龄和设备这个三个维度下,分析其中的关系,
得出四大核心区用户挖掘度不够,产品对 9.2969 设备用户购买决策影响甚微等结论。接
着本文将用户行为转化绘制成漏斗图,进一步探究行为间转化关系。针对用户价值,本
文采用调整后的 RFM 模型对用户进行价值分类,得到重要价值用户仅占到用户总体的
4.55% ,最后结合用户不同的价值类型,从 4P 角度为该企业提出了针对性建议。
本文借助了高德地图与 MPai 数据科学平台进行数据分析与建模,提高了结果正确
性与模型准确性。
关键词:购买预测;随机森林分类;消费者行为; RFM 模型
1 任务背景与重述
1.1 任务背景
大数据时代之下,各个领域的公司都在拓展互联网业务,为公司产品引入新鲜活跃
的用户,激发用户对产品的购买欲望,提升公司品牌的影响力。对儿童教育行业而言,
传统教育模式一定程度上已经无法满足当下市场需求,线上教育的影响越来越显著。用
户下载相应的儿童教育软件,进行注册,领取体验课,下单购买课程进行学习,完成课
后测试并订正,这便是一个完整的线上教育流程。这种方式一定程度上缓解了教育资源
不平衡的现状,然而线上教育的弊端也十分明显,对企业而言,课程质量能否吸引家长
孩子,如何判别高质量用户,如何优化营销,制定特色产品运营方案等,都是十分值得
思考的问题。因此,利用数据分析方法,结合消费者行为学,通过对用户学习情况、产
品使用情况、登录情况以及城市分布情况等,为企业进行用户分析,判断用户价值,并
对其制定针对性营销策略,提升用户粘性,减少用户流失率,为企业带来利润,便是线
上儿童教育企业需要着手扬长避短的地方。
1.2 任务重述
需要对给定数据进行预处理以提高数据质量,并对其进行基于用户各城市分布情
况、登录情况的可视化分析。同时根据数据构建模型,判断用户最终是否会下单购买。
随后需要通过用户消费行为价值分析,给企业提出合理的建议。
2 任务分析
任务一要求获取数据并进行预处理,提高数据质量。需要在观察数据集字段构成之
后进行数据清洗、数据集成与数据规范化等操作。
任务二要求对用户的各城市分布情况、登录情况进行分析,并分别将结果进行多
种形式的可视化展现。这需要对用户城市分布与用户数量分布分别分析,由此得到该
APP 的用户核心分布区;其次,还需要根据登录情况,分析用户活跃度与用户流失情
况。
任务三要求构建模型判断用户最终是否会下单购买或下单购买的概率。需要首先
划分训练集与测试集,分析并选择合适的特征,利用训练集建立合适的模型以预测测试
集,并与测试集原始数据进行对比,得到模型效果的评估。
任务四要求通过用户消费行为价值分析,给企业提出合理的建议。需要分别对用户
行为与用户价值进行分析,并结合之前的分析结论,为企业提出合理的建议,实现小本
促销,提升企业高价值用户占比。
全过程如图1所示: 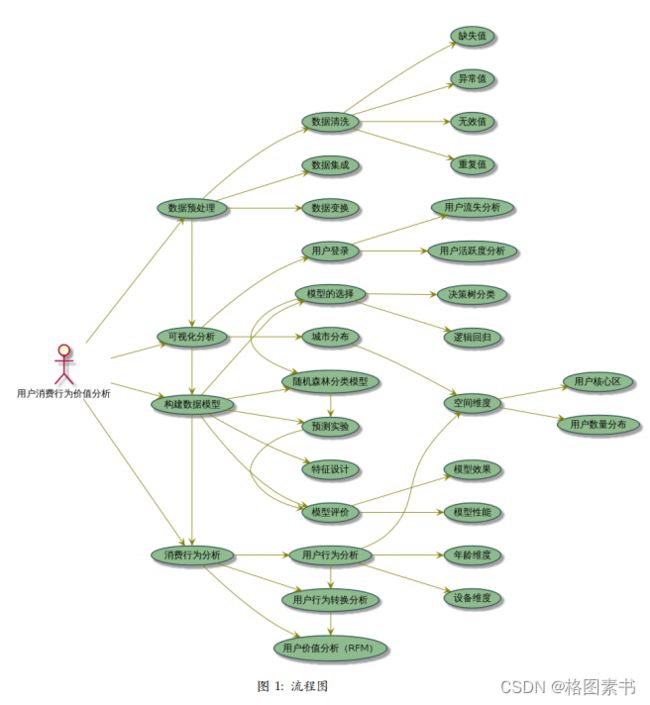
3 数据假设
1) 所给数据真实可靠;
2) 每个用户 ID 是唯一的,且每个用户仅一个对应 ID ;
3) 随着样本容量无限增加,解释变量的样本方差趋于一个有限的常数;
4) 解释变量 X 是确定性变量,不是随机变量,而且在重复抽样中取固定值;
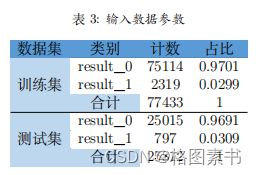 解释模型或进一步调整模型结构。
解释模型或进一步调整模型结构。
5) 随机干扰项尽可能服从零均值,同方差,零协方差的正态分布,满足无序列相
关性;
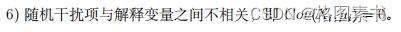
4 任务求解
4.1 任务一:数据预处理
对附件四个表中数据进行观察,初步得到如下结果:
• 用户信息表共有 8 个字段: user_id 、 first_order_time 、 first_order_price 、 age_month 、
city_num 、 platform_num 、 model_num 、 app_num ,分别表示为用户 id 、体验
课下单时间、体验课价格、年龄、城市、设备、手机型号和 APP 激活。样本量为
135968 ,其中体验课下单时间的数据类型为长日期,城市数据类型为文本, APP
激活为逻辑数据整型表达,设备与手机型号是,其余均为整型数据。
• 用户登录情况表共有 16 个字段: user_id 、 login_day 、 login_diff_time 、 distance_day 、
login_time 、 launch_time 、 chinese_subscribe_num 、 math_subscribe_num 、 add_-
friend 、 add_group 、 camp_num 、 learn_num 、 finish_num 、 study_num 、 coupon 、
course_or-der_num ,分别表示为用户 id 、登录天数、登录间隔、最后登录距期末
天数、登录时长、再次访问落地页数,隔天、关注公众号 1 、关注公众号 2 、添加
销售好友、进群、开课数、学习课节数、完成课节数、课程重复学习、领券数量
和有年课未完成订单。样本量为 135617 ,所有字段均为整形数据。
• 用户登录情况表共有 26 个字段: user_id 、 main_home 、 main_home2 、 main
Page 、 schoolReportPage 、 main_mime 、 lightCourseTab 、 main_learnPark 、 part
nerGameBarriersPage 、 evaulationCenter 、 coupon_visit 、 click_buy 、 progress_bar 、
ppt 、 task 、 video_play 、 video-_Read 、 Next_nize 、 Answer_task 、 Chapter_module 、
course_tab 、 slide_subscribe 、 baby_info 、 c-lick_notUnlocked 、 share 、 click_dialog ,
分别表示为用户 id 、首页访问数、首页访问数、课程计划访问数、课程访问数共
计 26 个字段,分别表示用户 id 、首页访问数、首页访问数、课程计划访问数、课
程访问数、我的访问数、轻课访问数、学习乐园访问数、小屋首页访问数、测评中
心访问数、是否领券访问数、购买按钮点击访问数、拖动进度条访问数、 ppt 下一
步访问数、任务结束页访问数、视频跟读访问数、界面继续访问数、识字访问数、
答案解析访问数、点击模块访问数、今日课程访问数、上课页访问数、宝宝访问
数、课程未购买弹窗访问数、点击分享访问数和首页广告弹窗点击访问数。样本
量为 135617 ,与用户登录情况表一相同,均为整形数据。
• 用户下单表共有 2 个字段: user_id 和 result ,分别表示为用户 id 和是否购买。样
本量为 4639,所有字段均为整形数据。
4.1.1 数据清洗
数据清洗主要处理的是数据中的重复值、缺失值和异常值。对数据集进行处理,结
果如下:
1. 用户信息表:通过观察信息表中的数据,首先,发现重复的用户 id 数据,其它
字段信息完全不相同,这与实际情况矛盾,因此需删除表中 所有 重复数据,总计
19265 条,保留 116703 条唯一值。其次,除用户信息表的城市字段有缺失值以
外,其余字段无缺失值。由于城市字段较为特殊,不对缺失值进行插补,而是仅
研究有数据部分进行筛选,故删除了 24089 个缺失值与 399 个异常值,最终得到
92215 条数据。此外,就字段而言, APP 激活所有数据均一样,为无效字段,因
此删除该字段。
2. 用户登录表:同 1 中对用户 id 重复值的处理,删除数据总计 19201 条,保留
116416 条唯一值,无缺失值。其次,用户登录天数必须非负,故剔除登录天数和
最后登录距期末天数两字段中小于 0 的数值异常数据,总计 3589 条。另外,在
正常情况下,学习课节数必须 ≥ 完成课节数,故删除逻辑,总计 8365 条。还需
考虑学习课节数为 0 ,而完成课节数不为 0 的情况,故删除逻辑异常数据,总计
1167 条,最终得到 103295 条数据。而该表中的添加销售好友和进群两个字段所
有数据均一致,故仅保留添加销售好友一个字段而删除进群字段。
3. 用户访问表:同 1 中对用户 id 重复值的处理,删除数据总计 19201 条,保留
116416 条唯一值,用户 id 顺序与用户登录表一致,无缺失值;其次,通过数据观
察可以发现,有少部分用户无任何访问记录,却在用户下单表里有购买记录,因
此我们判定此类用户为刷单用户,需要剔除,总计 229 条,最终得到 116187 条
数据。对于购买按钮点击访问数字段而言, 116187 条字段中仅有 2 条数据值为 1 ,
其余均为 0 ,因此为无效字段,做删除处理。
4. 用户下单表:同 1 中对用户 id 重复值的处理,删除数据总计 26 条,保留 4613
条唯一值。
4.1.2 数据集成
为便于查找数据和集中处理数据,对用户信息表、用户登录情况表、用户访问统计
表以及用户下单表进行集成。经过数据清洗后,用户信息表、用户登录情况表和用户访
问统计表已无重复冗余字段,且后两者样本数量都达到一致,但用户下单表仅有下单
用户的用户 id ,因此,仅需将用户信息表、用户登录情况表和用户访问统计表进行简
单合并,并对应用户下单表,用户下单表中不存在的数据存为 0 。最终集成结果为:在
用户信息 - 下单表中,数据共记 92215 条,下单用户 3140 个;在用户登录 - 访问 - 下单表
中,数据共记 103247 条,下单用户 3117 个;在用户信息 - 登录 - 访问 - 下单表中,数据共
计 81194 条,下单用户 2413 个。
 综上,针对用户活跃度,可以得到以下结论:
综上,针对用户活跃度,可以得到以下结论:
 其中,针对异常值,推测该款软件于期末 46 周前进行过一次大批量的推广活动后,
其中,针对异常值,推测该款软件于期末 46 周前进行过一次大批量的推广活动后,
 综上,针对用户活跃度,可以得到以下结论:
综上,针对用户活跃度,可以得到以下结论:
 如体验课下单时间(first_order_time)、体验课价格( first_order_price )、购买
如体验课下单时间(first_order_time)、体验课价格( first_order_price )、购买
 如表2所示,逻辑回归算法的表现最差,原因是逻辑回归这样的线性分类模型不适
如表2所示,逻辑回归算法的表现最差,原因是逻辑回归这样的线性分类模型不适
 2. 边缘函数是正确分类结果大于最大错误分类结果的表征方式,即边缘函数越大,
2. 边缘函数是正确分类结果大于最大错误分类结果的表征方式,即边缘函数越大,
4.1.3 数据变换
数据变换处理可将原始数据转换成为适合数据挖掘的形式。不同评价指标往往具
有不同的量纲,数值见的差别可能很大,不进行处理可能会影响到数据分析的结果。为
了消除指标之间的量纲和取值范围差异的影响,需要进行标准化处理,将数据按照比例
进行缩放,使之落入一个特定的区域,便于进行综合分析。
对于本数据集中用户登录情况表和用户访问统计表,由于需要采用零 - 均值规范化
( z-score 标准化),即标准差标准化进行处理,经过处理的数据的均值为 0 ,标准差为 1 ,
其转化公式为: 
4.2 任务二:对用户城市分布情况与分布情况可视化分析
4.2.1 城市分布情况可视化分析
分析用户城市分布,最终目的是得到该 APP 的用户核心分布区,而核心分布区不
仅与用户城市分布有关,还和用户数量分布有关,因此应从这两个方面入手进行分析。
将用户信息表中的数据导入地图,得用户城市分布图,并对近十万名用户所在的
361 座城市进行 K-means 聚类分析,得到用户城市分布五大区域,再对经纬度进行筛
选,求得五大区域城市占比如图2所示: 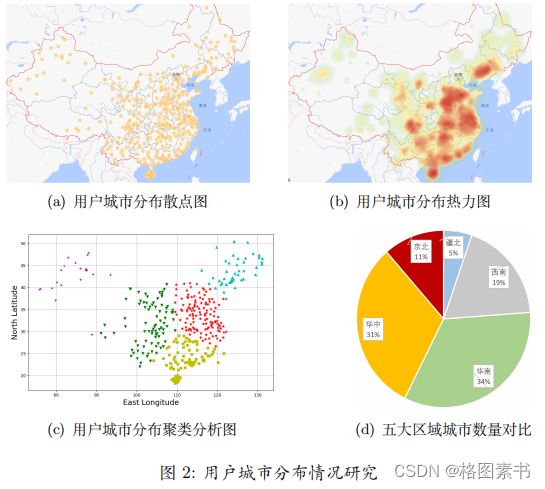
可以得出:
1. 该 APP 用户地区分布较为广泛,涵盖了我国大部分省市。
2. 用户所在城市分布东密西疏,这与我国人口分布类似;通过聚类分析,可以看出
用户城市分布大致在五个区域:疆北、西南、华南、华中以及京北。其中华南华中地区
城市数量占比已过半,高达 65 % 。这表明该地区极大可能是用户核心区。
接下来对用户数量分布进行分析,将每座城市的用户数量连同经纬度一起倒入地
图,得到用户数量分布图(圆圈越大表明该地用户数量越多),另外,为了更直观感受
不同城市用户数量差异,对用户人数大于 850 的城市进行对比,如图 3 所示: 同时,产 
品购买者数量分布也是一大关键信息,因此我们将用户下单表中的信息事先预处理,分
别统计 288 座城市中下单用户数量,同样录入到地图中(柱体颜色越深表示下单用户
数量越多),并计算出各重点区域下单用户比例,如图 4 所示:由此可得:
1. 该 APP 用户大部分集中在成渝、华北 - 北京、珠三角以及长三角这四大区,而相
对较偏远的西北部地区则用户分布较少,例如西藏、新疆、内蒙古、云南等。当前重点
地区用户分布情况与我国目前互联网经济发展情况大体一致,这表明线上教育平台依 
托于互联网的发展。
2. 在四大区用户数量超过 850 的城市中,成渝区占比 32% ,华北 - 北京占 24% ,珠三
角占 16% ,长三角占 5% 总计 77% ;但是成渝区下单用户仅占该地区总用户数的 5.99% ,
华北 - 北京占 10.89% ,珠三角占 24.10% ,长三角占 18.18% ,由此可见,东部沿海地区
可能仍有很大潜在市场。
3. 重庆市的用户人数已经达到全部总用户人数的 10.62% ,远远高于其他城市,推
测该 APP 总部位于重庆市随后营销由重庆向外推广,因此中西部省会城市用户数量不
低,然而重庆市下单用户占比却是垫底,这也表明,在对外营销过程中可能存在某些问
题导致本地用户流失。
综合上述分析,我们将用户分布划分为四大核心区域:成渝、华北 - 北京、珠三角
以及长三角,现将四大区域的用户数量下钻到市级用户画像,如图5所示: 
由市级用户画像可以得出:
1. 各区域都存在两个或三个重点城市(华北 - 北京四个),如重庆,深圳,保定,上
海,杭州等地。
2. 正是由于这些重点城市的存在使得四大核心区域用户占比大幅提升,如成都,重
庆用户数占成渝区的 91.15% ,上海,杭州以及苏州占长三角的 65.45% 等。
因此,在后续分析中可以对以上城市着重分析。
4.2.2 登录情况可视化分析
分析用户登录情况,最终目的是得到该 APP 的用户粘性,而分析用户粘性需要从
用户活跃度与用户流失两个方面去考虑,因此选用已预处理过的用户登录情况表进行
分析,选取字段为:登录天数、登录间隔、最后登录距期末天数、登录时长以及隔天再
次访问落地页数。
首先进行用户活跃度分析。导入登录天数数据,得到用户登录天数分布图,其中横
轴表示登录天数,纵轴表示用户数量,如6所示: 
由此可以看出:根据用户登录天数分布,可以初步了解到用户登录天数集中在 7 天
内,占比 94.55% ,其中峰值在 5 天,用户登录达 3 至 6 天的数量居多,占比 60.26% 。
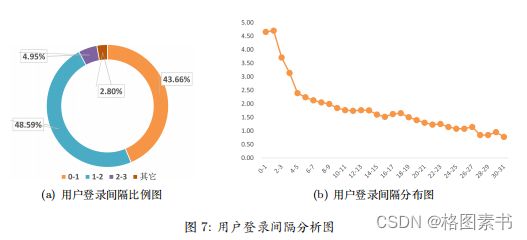
随后再导入登录间隔数据,通过观察,发现登录间隔区间是 [0 , 135] , 而当登录间隔
处于 [0 , 3] 区间时,用户比例已经超过 97 % ,因此我们仅对登录间隔区间在 [0 , 31] 的数
据进行绘图,此时用户占比已经超过 99 . 21 % ,同时,为了图像更美观,对用户数量做
取对数处理,得到用户登录间隔分布图,其中横轴表示登录间隔区间,纵轴表示用户数
量关于 e 的对数,如 7 所示:
接着再导入登录时长数据,通过观察,发现登录时长区间是 [0 , 1339] ,并对表前的
数据进行分析判断该数据单位为小时 ( h ) ,故登录时长区间是 [0 , 55 . 8] 天;同样地,当
天数超过 10 ,用户比例已经 ≤ 3 . 56 %, 故仅对前十天数据进行绘图,得到用户登录时长
分布图,其中,横轴表示天数,0 . 5 表示半天,纵轴左侧表示用户数量,右侧表示用户
比例,如 8 所示:
综上,针对用户活跃度,可以得到以下结论:
1. 从登录时长情况来看,结合图 6 和图 8 ,用户对该款 APP 倾向于短期使用,登
录时间越长,用户数量越少。假设存在较长周期的课程的情况下,该款 APP 的用户留
存不足,推测购买长期课程的人数少。
2. 从登录间隔来看,用户登录间隔较短,但结合登录时长,当登录时长超过半天
后,用户数量递减,因此用户登录情况属于间歇性短期登录,而非长期的规律性使用。
3. 从用户登录活跃整体情况的来看,由于用户的短期活跃程度明显高于长期活跃
程度,推测用户大多数仅使用试用课程,而且购买正式长期课程。
接下来进行用户流失分析。导入隔天再次访问落地页数数据,落地页访问数据是反
映产品营销转化能力的指标,它指的是用户通过搜索或者点击链接进入网站仅浏览了
第一个页面就离开的访问次数,该指标越高,表明营销越能吸引潜在用户。通过观察,
发现当隔天落地页访问数 ≤ 7 时,用户比例已经突破 99 . 97 % ,故仅对 [0 , 7] 进行作图,
得到用户隔天再次访问落地页数玫瑰图,如图 9 所示:
由此可以看出:隔天再次访问落地页数在 3 次内时占比已达到 99.00% ,当值为 0
时占比最大为 63.01% 。说明该款软件产品的落地页信息对于用户吸引力不足,导致近
6 成用户并不会再次访问该页面以了解更多信息。
接下来导入最后登录距离期末天数数据,以期末作为重要时间节点,依据距离期末
天数统计用户数量,以此来分析用户流失情况。按照行业标准,依据用户流情况失将用
户划分为三类:活跃用户(最后登录距离期末 < 60 天)、潜水用户( 60 天 ≤ 最后登录
距离期末 ≤ 90 天)以及流失用户(最后登录距离期末 ≥ 90 天)。以周为单位,做出用
其中,针对异常值,推测该款软件于期末 46 周前进行过一次大批量的推广活动后,
由于正式用户转换率不足,导致该期用户的流失堆积在 46 周左右,但该异常值不影响
后续用户流失基本分析,故不做额外处理。所得用户流失分类如表 1 所示:
综上,针对用户活跃度,可以得到以下结论:
1. 该款 APP 产品落地页的营销转化不足,落地页作为内容营销较为直接、有效率
的一个渠道之一,在该产品中的访问量不足;同时结合用户登录情况,可以了解到真正
被吸引的用户数量较少,产品的落地页设置效果不佳。
2. 活跃用户数不足,仅占 36.87% ,潜水用户和流失用户占比较大,为总用户数的
63.13% 。说明该款产品的持续激活用户能力、留存忠诚用户能力不够充足。
4.3 任务三:建立随机森林分类模型进行预测
4.3.1 符号说明

4.3.2 模型准备
购买预测问题本质上是个二分类问题,因此我们将下单用户标记为 1 ,未下单用户
标记为 0 。将数据洗牌后选取 75% 的数据作为训练集并构建特征训练集模型。最终训
练好模型后,使用模型对剩余 25% 的数据进行预测,将预测输出的结果与原本数据进
行比对。
基于上文的数据探索并结合实际 APP 使用情况,我们利用现有字段数据类型构建
五大基础特征指标,即登录信息统计指标、用户指标、课程指标、基本信息渠道指标以
及消费指标(如图 11 所示)。特征的具体设计说明如下:
1. 登录基础特征指标主要描述用户与 APP 的触点、使用活跃程度、用户流失情况
等相关信息,例如登录天数( login_day )、登录间隔( login_diff_time )、最后登
录距期末天数( distance_day )、登录时长( login_time )等。
2. 用户指标主要用于表示用户自身情况、社交互动情况以及用户与 APP 其他渠道
的关注关系。如用户 ID ( user_id )是用户的基本主键,添加销售好友( add_friend )、
进群( add_group )等表示用户与 APP 其他渠道的关联性、点击分享访问数( share )
表示用户针对 APP 进行的社群互动行为等。
3. 课程指标描述了用户在 APP 中的核心功能板块——在线课程的各方面情况,例
如课程计划访问数( mainPage )、课程访问数( schoolReportPage )等从宏观角度
统计用户的课程安排; ppt 下一步访问数( ppt )、视频跟读访问数( video_play )、
界面继续访问数( video_Read )等描述用户的上课互动行为。
4. 基本信息渠道指标主要指 APP 中各种与在线课程内容非直接相关的基础信息
及营销信息渠道的互动情况。例如首页访问数( main_home )、测评中心访问数
( evaulationCenter )、小屋首页访问数( partnerGameBarriersPage )等。
5. 消费指标主要描述的是用户在 APP 使用过程中的任何付费意向、付费结果等。例
如体验课下单时间(first_order_time)、体验课价格( first_order_price )、购买
按钮点击访问数( click_buy )等。
4.3.3 预测模型的选择
可用于购买行为预测的方法有许多,具体包括时间序列分析、面板数据模型、基于
机器学习的模型和随机模型。随着数据可获得性的提高,越来越多研究基于机器学习的
预测模型来预测用户的未来购买行为。这些基于机器学习的预测方法主要包括逻辑回
归、支持向量机、人工神经网络、梯度提升决策树等。
随机森林( Random Forest )是指利用多棵决策树对样本进行样本并训练和预测的
一种算法。随机森林算法是一个包含多个决策树的算法,其输出的类别是由单独的方法
树输出类别的众树来决定的。
它的优点在于对于大部分的数据,它的分类效果比较好;它能处理高维特征,不容
易产生过度拟合,模型训练速度比较快,特别是对于大数据而言;在决定类别时,它可
以评估变数的重要性;它对数据集的适应能力强,既能处理离散型数据,也能处理连续
型数据,数据集无需特意规范化。
本文进行了用户未来是否购买预测问题的研究,因此分别使用机器学习中常用的
分类问题来评估预测模型的性能。
为了使模型具有一定的可解释性,还分析了预测性能较优的若干个模型的特征重
要性结果。经过特征分析、数据清洗整理得到原始数据集,然后度量各个特征变量的重
要性,选择重要性较高的特征生成新的数据集,在原始数据集和新数据集基础上分别
训练了用于预测用户是否购买的随机森林分类模型、逻辑回归模型和决策树回归模型,
实验对比的结果表明,在随机森林预测模型综合性能更好。也验证了随机森林的优点。
预测用户未来是否购买是一个典型的二分类问题,因此我们使用二分类问题中常
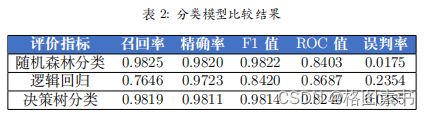
用的评估指标,包括召回率、精确率、 F1 值、 ROC 值以及误判率来评估模型性能。在
测试集上的评估结果如表 2 所示。
如表2所示,逻辑回归算法的表现最差,原因是逻辑回归这样的线性分类模型不适
用于本研究中的非线性问题,它无法处理复杂的非线性分类问题。决策树分类可以找到
非线性分割,更加接近人的思维方式,可以产生可视化的分类规则,产生的模型具有可
解释性(可以抽取规则)。树模型拟合出来的函数其实是分区间的阶梯函数,但对比于
随机森林分类,决策树的泛化能力弱。随机森林分类算法在以决策树为基学习器的基础
上,进一步在决策树的训练过程中引入了随机特征选择,减小方差,而且方差的减小补
偿了偏差的增大,在构建决策树的时候,随机森林的每棵决策树都最大可能的进行生长
而不进行剪枝,在对预测输出进行结合时,随机森林通常对回归任务使用简单平均法。
随机森林在数据集上表现良好,能够处理很高维的数据,不用特征选择且在训练完后能
给出特征的重要性,基于本身特性一一训练时采用并行化方法,与其他算法相比其训练
速度快很多。总体而言,随机森林是一个在精确率、稳定性以及训练速度上都有良好表
现的模型。
通过表格数据可以轻易发现,随机森林分类的所有评价指标均为最优,这说明使用
该方法对于预测用户购买行为具有很好的预测性能。
4.3.4 随机森林分类模型
同一批数据,用同样的算法只能产生一棵树,而 Bagging 策略可以产生不同的数
据集。 Bagging 策略来源于 bootstrap aggregation :从样本集(假设样本集 N 个数据
点)中重采样选出 N b 个样本(有放回的采样,样本数据点个数仍然不变为 N ),在所
有样本上,对这 n 个样本建立分类器,重复以上两步 m 次,获得 m 个分类器,最后
根据这 m 个分类器的投票结果,决定数据属于哪一类。
2. 边缘函数是正确分类结果大于最大错误分类结果的表征方式,即边缘函数越大,
分类结果可信度就越高,就所有训练集分别应用决策树可形成随机森林。具体步
骤如下 :
采用 Bagging 算法在原始数据中进行 N 次随机抽样,将其数据整理为训练样本
集合。
依次针对训练样本建立决策树,在树的节点处随机选取 d 个参数,应用 Gini 系
数选取最优参数进行决策树分支,其中, Gini 系数可表示为: 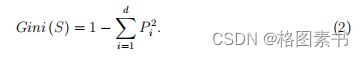

4.3.5 特征重要性分析
经过数据预处理,得到 37 维的特征构建,并使用随机森林算法对训练集样本进行
建模。当模型建立完毕后,输出所有特征的重要性。并利用该模型对测试集进行预测,
并与原本结果进行比较。输入数据参数如表 3 所示。
特征重要性分析可以用来评估构建的特征的预测能力或对预测模型的重要性。通
过特征重要性分析,可以很直接地观测到所构建的特征的预测能力,从而在一定程度上
解释模型或进一步调整模型结构。
用户最终是否会下单购买随机森林分类模型特征重要性前 10 名如表 4 所示。
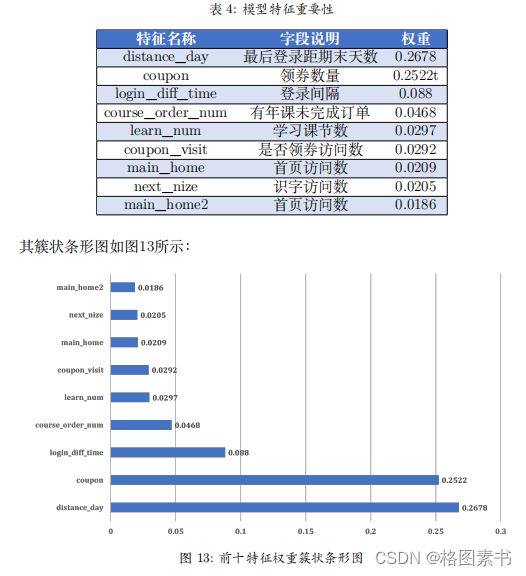 从随机森林算法做出的特征重要性排序可以发现:
从随机森林算法做出的特征重要性排序可以发现:
1. 排名前十的特征总权重和为 0.7899 ,其中登录基础特征指标含 2 个,分别是最后
登录距期末天数和登录间隔;消费指标有 3 个,分别为领券数量、有年课未完成
订单、是否领券访问数;与课程直接相关的课程指标有 2 个,分别是学习课节数
和识字访问数;基本信息渠道指标有 2 个,为首页访问数 1 和首页访问数 2 ;用
户指标有 1 个为关注公众号 1 。权重排名前十的特征中登录基础特征指标比重合
计 0.3558 ,消费指标比重合计 0.3282 ,说明用户登录情况活跃度和消费优惠折扣
对用户选择倾向影响比较大。
2. 在权重排名前十的特征中,课程指标中的学习课节数和识字访问数权重分别为
0.0297 和 0.0176 ,总计 0.0502 ,与登录基础特征指标和消费指标相比较少,说明
可能课程的体验互动情况对于用户的购买决策影响作用相对较弱。又可见关注公
众号 1 这个特征描述用户对用户购买决策的影响占比排名前十,由此推测该产品
中的在线语文课程相关内容对于用户来说的感知价值更高( Zeithaml et al, 1988 ),
进而正向影响用户的付费意愿( Wang et al,2020 )。
3. 在权重排名前十的特征中的基本信息渠道指标中,首页访问数 1 和首页访问数 2
的权重分别为 0.0209 和 0.0186 。由此说明该 APP 的营销渠道中较为突出有效的
集中于首页信息,而类似落地页、弹窗广告等的营销效果可能不足。
最后,选取特征重要性排名前 29 的特征,即原始数据值中重要性大于 0.005 的特
征,组成新数据集用于后面的实验。
4.3.6 预测实验
再次对通过特征重要性排名选出的前 29 特征使用随机森林分类模型,取经过数据
洗牌后新数据集的 75% 作为训练集进行训练,得到各特征权重,从高到低如表 5 所示。


4.3.7 模型评价
对于随机森林分类模型,预测效果可以从训练过程中的模型性能和最终的模型效
果两方面进行评估。
因为训练集是经过采样且正负样本是相对均衡的,所以对于训练过程中模型的效
果评估,我们主要使用召回率、精确率、 F1 值、 ROC 值以及误判率这四个指标对模型
进行观察。本次实验会对训练集进行拆分,将训练集中 75% 的数据用与模型拟合即真
正意义上的训练集。然后将剩下 25% 的数据用做验证集,以便于观察模型在训练过程
中的真实表现,防止模型出现过拟合。
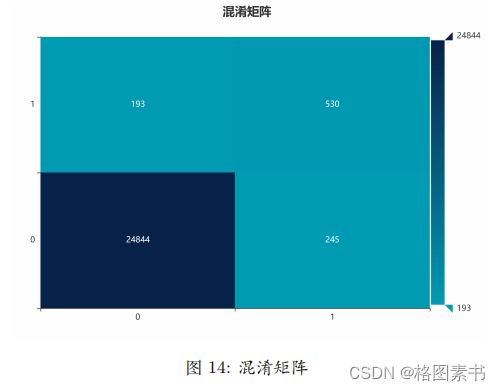
依照样本类型对样本进行预测时,通过比较真实类别和预测类别可以得到混淆矩
阵如图 14 所示:通过混淆矩阵可以看出,训练过程中的模型性能好。
 数据洗牌后,将 75% 的是否购买数据作为测试集,使用模型剩余 25% 的数据进行
数据洗牌后,将 75% 的是否购买数据作为测试集,使用模型剩余 25% 的数据进行
预测,将输出的结果与原数据进行比对。得到测试数据评估结果表 7 如下:
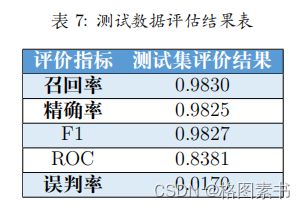 通过对比新测试集预测数据及原是否购买数据可以发现,该模型的精确率达到
通过对比新测试集预测数据及原是否购买数据可以发现,该模型的精确率达到
98.3% ,模型效果好。
4.4 任务四:用户消费行为价值分析与建议
对于任务四,需要分别从用户行为分析与用户价值分析入手,并结合前述任务中的
分析,为企业提出建议。
4.4.1 用户行为分析
一般情况下,用户进行线上教育消费往往有以下行为:点击浏览、关注、收藏、领
券以及支付。因此,通过分析附件中所给的数据,首先将非课程相关访问量视为用户消
费第一行为,其中包含的数据是:首页访问数 1 、首页访问数 2 、我的访问数、轻课访
问数、学习乐园访问数、小屋首页访问数、测评中心访问数、是否领券访问数、宝宝访
问数、课程未购买弹窗访问数、点击分享访问数以及首页广告弹窗点击访问,共 12 个
字段,将其命名为 访问 ;接着将数据关注公众号 1 、关注公众号 2 、添加销售好友、进
群以及领券数量作为用户第二消费行为,共 5 个字段,将其命名为 关注领券 ;最后将
开课数数据作为用户第三消费行为,将其命名为 开课购买 ,如表 8 所示:
 明确用户消费行为后,需从不同维度对这些行为进行分析,通过观察数据,合理选
明确用户消费行为后,需从不同维度对这些行为进行分析,通过观察数据,合理选
取空间维度、年龄维度以及设备维度对这三种行为进行分析。
首先对空间维度进行分析,将用户城市分布信息导入地图,对三种行为分别作出空
间维度 - 消费行为图,其中颜色越深表示行为量越多;其次,对四大核心区的市级单位
进行对比分析,横轴表示点击量(单位:万 w )与城市名,如图 15 所示:
由此可得:
1. 从访问到关注领券到开课这个行为链条来看,重庆市和其他城市相比都高出了
一定数量级,但是最终重庆市用户的购买量却不及其他城市,推测重庆市的营销运营效
率不高,对该区域用户洞察不够准确,导致无法从该区域的消费者中挖掘到价值。
2. 四大核心用户区中成渝地区的辐射效应并不明显,其核心城市周围的用户数量
分布较少。而其他核心城市,例如北京、广州、上海、深圳等从人口来看应该具有很大
市场潜力,但是这些区域的用户挖掘深度明显不足。
下面对年龄维度进行分析,由于年龄在 0 至 12 岁的用户数量已经超过 99 . 01 % ,因
此仅对该年龄段的用户进行分析;同时,为了分析图呈现更美观,对三大行为量做取对
 数处理,绘制出年龄维度-消费行为图,如图 16 所示:
数处理,绘制出年龄维度-消费行为图,如图 16 所示:
由此可得:
1. 针对 12 岁年龄范围内的用户进一步进行分析,可以发现学前衔接阶段,即 4 至
6 岁的用户行为数量最大,基本符合低幼阶段市场情况。
2. 在 12 岁年龄范围内,关注领券和开课行为关联较为密切,推测用户倾向于使用
试听课程进行初步体验。
最后对设备维度进行分析,通过数据观察,发现所有的用户所使用的的手机设备仅
两种: 9.2969 设备与 13.557 设备。同样地,为了分析图呈现更美观,对三大行为量做
取对数处理,绘制出设备维度 - 消费行为图,如图 17 所示:
由此可得:
1. 通过数据统计分析,可以发现 9.2969 设备用户基数占据大多数,而 13.557 设备
用户仅在访问阶段行为存在。而在 9.2969 设备的用户行为来看,几乎所有行为集中在
访问阶段,而推进到关注领券并开课的用户数量极少。说明各渠道综合来看,对使用
13.557 设备用户的营销手段不理想,对 9.2969 设备用户的影响作用也十分有限。

4.4.2 用户行为转化分析
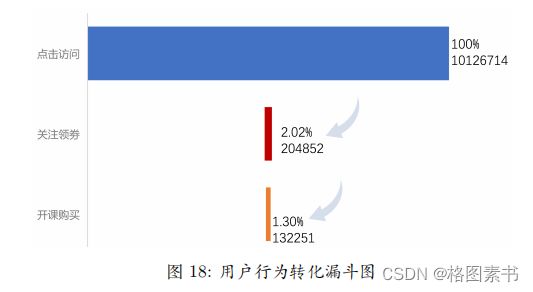
统计行为量,做出用户行为转化漏斗图,并计算出转化率,如图 18 所示:
由此可得:
1. 由图可以直观地看出从访问阶段到关注领券的转换率极低,仅为 2.02% ,而从关
注领券到开课购买的转化率为 64.56% ,说明在用户的决策链中,前期对产品了解阶段
的信息并没有十分显著的影响,而用户在开课时,受到价格因素的印象较大,基本都会
选择领券体验。
2. 结合前述中的登陆情况(用户登录时长短、流失严重),用户基本停留在领券开
课体验阶段,并未真正付费为企业带来价值。下面一部分从用户价值的角度来进一步进
行分析。
4.4.3 用户价值分析——RFM
从客户关系管理的角度引入 RFM 模型来对用户价值进行分析。原 RFM 模型更多
地是从电商消费视角,即最近一次消费( Recency )、消费频率( Frequency )和消费金额
( Monetary )来对用户进行分类。由于该企业所处行业为在线教育,为了反映用户的潜
在价值,将用户最后一次登录学习的时间距期末天数作为 R 维度,作为客户的留存和
 流失情况的衡量;将学习课节数作为 F 维度作为用户参与互动情况的衡量以及将体验
流失情况的衡量;将学习课节数作为 F 维度作为用户参与互动情况的衡量以及将体验
课价格作为 M 维度作为用户消费情况的衡量。针对这三个维度,均采用平均值作为基
准来判别 R 值、 F 值和 M 值的高低,对该款 APP 的用户价值按照下表标准进行分析:

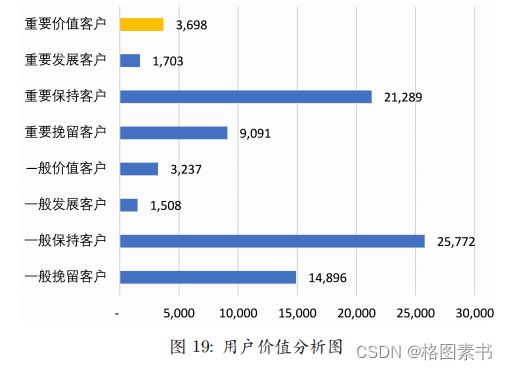
代入数据,得到用户价值分析图,如图 19 所示:
结合图表可见看出 : 该款 APP 的用户价值保持型和挽留型客户为主要类型,占比
高达 87.50% ;而重要价值用户占到用户总体仅 4.55% ,与前述分析中用户行为的表现
基本一致,平台整体用户价值分布情况并不乐观,大多数用户并没有真正为企业创造价
值。
针对该款 APP 目前主要的几种不同价值类型的用户,可以采取以下具有针对性的
营销策略:
对于重要价值用户,持续维护用户关系,提升用户的用户体验,进而增强其对平台
的依赖性,来达到深度挖掘其价值的目的。
对于重要保持用户,可以定期进行针对性的多渠道推送,提醒其学习进度,并传递
新课程优势的信息点,做到留存优化。
对于重要挽留用户,可以采用跨平台推送等形式,提醒用户登录;对所购课程不满
意的用户,可以通过客服等及时反馈现有问题,并推荐其他优质内容来吸引用户复购。
 对于该平台大量的一般保持用户,推测为相关免费课程体验使用后就不再继续登
对于该平台大量的一般保持用户,推测为相关免费课程体验使用后就不再继续登
录,企业可以通过推送新一轮有竞争力价格的体验课,进一步转换用户。
对于一般挽留用户,企业的重心可以放在新媒体、社群口碑等方式,扩大课程曝光
度,来提升用户对该 APP 的印象。
4.4.4 给企业的建议
结合上述消费者行为价值分析,以及前述任务中建立的用户下单模型,现从 4P 角
度,即产品( Product )、价格( Price )、渠道( Place )和促销( Promotion ),为该企业
提供一些建议:
1. 产品:明确早教产品定位,综合提升课程有用性和用户体验。
由于该款在线教育产品的用户年龄以 3 至 12 岁为主,均为 K12 教育中的学前教
育或小学阶段教育。结合政策在 2021 年 3 月 31 日教育部印发的《关于大力推进幼儿
园与小学科学衔接的指导意见》的要求,建议企业针对低龄阶段的在线教育应注重课程
内容的质量与吸引力。因此建议企业明确早教产品的定位,以学科启蒙结合娱乐导向的
教育,注重产品 UI 设计以适应儿童审美,来达到吸引用户的目的。
另外建议企业注意课程互动性和课程质量的提升,来完善用户体验。在购买决策模
型中课程对于用户购买的影响因素权重偏小,结合实际情况,由于课程参与者为儿童,
而购买决策的执行者为家长,他们之间的信息不对称一定程度上也会影响用户购买的
行为。建议企业一方面提高课程的趣味程度,来吸引儿童用户,同时要完善家长的用户
体验,以完善整个购买决策的推进。
2. 价格:体验课程采用渗透定价策略,同时结合产品生命周期。
通过上述消费者行为价值分析,可以得知绝大多数用户对价格较为敏感,对产品的
感知价格较低。因此可以通过体验课程的渗透定价来进一步刺激市场需求。又由于课程
边际成本几乎可以忽略,因此采用渗透定价能够更好地吸引大量顾客,来提高该款产品
的市场占有率。
但同时由于整体用户的价格敏感程度高,在退出正式产品时,应考虑到产品的生命
周期,建议企业针对周期较长的课程采取分期付款的方式进行标价,同时要保持一定的
产品更新频率,以防止用户搭便车后的流失。
3. 渠道:把握多渠道宣传,扩大下沉市场渗透。
由上述的登录分析和用户城市分析可知,该款软件产品的基础用户群分布在成渝、
华北 - 北京、珠三角以及长三角四大核心区域,同时相较其他行业,集中度较低。结合
购买模型的因素权重可知,该 APP 的其他平台的宣传影响并不大,付费用户的转化情
况不佳。因此建议采取多渠道的宣传,进一步扩大市场营销力。
另建议企业把握下沉市场低幼教育课程质量参差不齐、课程面不够丰富齐全的痛
点,以一线城市为起点,向低线城市扩散,来撬动更大的用户群体。
4. 促销:注重产品组合和体验营销,利用社群营销建立口碑。
低幼阶段儿童没有提分等压力教育产品的设计重点是激发孩子的兴趣。在快乐的
体验过程中传输一定知识。因此建议企业注重产品组合的广度,设计多种类型的课程来
打包销售,同时增加游戏化设计和提升用户交互。
此外通过社群营销来建立用户口碑。由于当前低幼阶段儿童家长以 80/90 后为主,
教育理念升级,除关注小高及以后阶段的升学情况外,更加关注从小培养孩子的各方面
兴趣和综合能力,因此建议企业把握这部分家长的消费习惯,而微信社群、新媒体等,
作为 80 、 90 后的主要信息渠道对该款产品的口碑建立有很重要的作用。
参考文献

代码实现
数据预处理部分代码展示
在进行数据清洗时,需要首先查看缺失值,利用 python 编码如下:
import pandas as pd
data1 = pd.read_csv(’../../user_info.csv’)
data2 = pd.read_csv(’../../login_day.csv’)
data3 = pd.read_csv(’../../ visit_info .csv’)
data4 = pd.read_csv(’../../ result .csv’)
print(data1. isnull () .any())
print(data2. isnull () .any())
print(data3. isnull () .any())
print(data4. isnull () .any())
# display result
# user_id False
# first_order_time False
# first_order_price False
# age_month False
# city_num True
# platform_num False
# model_num False
# app_num False
# dtype: bool
# user_id False
# login_day False
# login_diff_time False
# distance_day False
# login_time False
# launch_time False
# chinese_subscribe_num False
# math_subscribe_num False
# add_friend False
# add_group False
# camp_num False
# learn_num False
# finish_num False
# study_num False
# coupon False
# course_order_num False
# dtype: bool
# user_id False
# main_home False
# main_home2 False
# mainpage False
# schoolreportpage False
# main_mime False
# lightcoursetab False
# main_learnpark False
# partnergamebarrierspage False
# evaulationcenter False
# coupon_visit False
# click_buy False
# progress_bar False
# ppt False
# task False
# video_play False
# video_read False
# next_nize False
# answer_task False
# chapter_module False
# course_tab False
# slide_subscribe False
# baby_info False
# click_notunlocked False
# share False
# click_dialog False
# dtype: bool
# user_id False
# result False
# dtype: bool 利用 python 删除重复值代码如下:
# -*-coding:utf-8-*-
import pandas as pd
data1 = pd.read_csv(’../user_info.csv’)
print(data1[’user_id’ ]. count())
wp1 = data1.drop_duplicates(subset=’user_id’,keep=False)
print(wp1[’user_id’].count())
wp1.to_csv(’../user_infoPretreatment.csv’)
data2 = pd.read_csv(’../login_day.csv’)
print(data2[’user_id’ ]. count())
wp2 = data2.drop_duplicates(subset=’user_id’,keep=False)
print(wp2[’user_id’].count())
wp2.to_csv(’../login_dayPretreatment.csv’)
data3 = pd.read_csv(’../visit_info.csv’)
print(data3[’user_id’ ]. count())
wp3 = data3.drop_duplicates(subset=’user_id’,keep=False)
print(wp3[’user_id’].count())
wp3.to_csv(’../visit_infoPretreatment.csv’)
data4 = pd.read_csv(’../result.csv’)
print(data4[’user_id’ ]. count())
wp4 = data4.drop_duplicates(subset=[’user_id’],keep=False)
print(wp4[’user_id’].count())
wp4.to_csv(’../resultPretreatment.csv’)
# display result
# 135968
# 116703
# 135617
# 116416
# 135617
# 116416
# 4639
# 4613 利用 python 合并数据如下:
# -*-coding:utf-8-*-
import pandas as pd
data1 = pd.read_csv(’../user_info_tobemerged.csv’)
data2 = pd.read_csv(’../login_day_tobemerged.csv’)
data3 = pd.read_csv(’../visit_info_tobemerged.csv’)
data4 = pd.read_csv(’../result_tobemerged.csv’)
result23 = pd.merge(data2, data3, on=[’user_id’])
result23 .to_csv(’../merge23.csv’, encoding=’gbk’)
result234 = pd.merge(result23, data4, on=[’user_id’], how=’left’)
result234 = result234. fillna (0)
result234.to_csv(’../merge234.csv’, encoding=’gbk’)
result1234 = pd.merge(data1, result234, on=[’user_id’], how=’right’)
result1234.to_csv(’../merge1234.csv’, encoding=’gbk’) 对城市经纬度做 K-means 聚类分析代码如下:
import pandas as pd
import numpy as np
from sklearn. cluster import KMeans
import matplotlib.pyplot as plt
# ------ 1.导入数据 ------
df = pd.read_csv(’china.csv’) # 此处注意换成自己的数据集路径
#print(df.head()) # 展示前5行数据
# ------ 2.提取经纬度数据 ------
x = df
x_np = np.array(x) # 将x转化为numpy数组
# ------ 3.构造K-Means聚类器 ------
n_clusters = 5 # 类簇的数量
estimator = KMeans(n_clusters) # 构建聚类器
# ------ 4.训练K-Means聚类器 ------
estimator. fit (x)
# ------ 5.数据可视化 ------
markers = [’*’, ’v’, ’+’, ’^’, ’s’ , ’x’, ’o’ ] # 标记样式列表
colors = [’r’ , ’g’ , ’m’, ’c’ , ’y’, ’b’, ’orange’] # 标记颜色列表
labels = estimator.labels_ # 获取聚类标签
plt . figure ( figsize =(9, 6))
plt .xlabel(’East Longitude’, fontsize =18)
plt .ylabel(’North Latitude’, fontsize =18)
for i in range(n_clusters): # 遍历所有城市,绘制散点图
members = labels == i # members是一个布尔型数组
plt . scatter(
x_np[members, 1], # 城市经度数组
x_np[members, 0], # 城市纬度数组
marker = markers[i], # 标记样式
c = colors[ i ] # 标记颜色
) # 绘制散点图
plt .grid()
plt .show()