【C++ 基础】第10章:泛型算法与Lambda表达式
泛型算法与Lambda表达式
- 1 泛型算法
-
- 1.1 泛型算法:可以支持多种类型的算法
-
- 1.1.1 这里重点讨论 C++ 标准库中定义的算法
-
- 1.1.1.1
- 1.1.2 为什么要引入泛型算法而不采用方法的形式
-
- 1.1.2.1 内建数据类型不支持方法
- 1.1.2.2 泛型算法计算逻辑存在相似性,可避免重复定义
- 1.1.3 泛型算法如何实现支持多种类型:使用迭代器作为算法与数据的桥梁
- 1.2 泛型算法通常来说都不复杂,但优化足够好
- 1.3 一些泛型算法与方法同名,实现功能类似,此时建议调用方法而非算法
-
- 1.3.1 std::find V.S. std::map::find
- 1.4 泛型算法的分类
-
- 1.4.1 读算法:给定迭代区间,读取其中的元素并进行计算
-
- 1.4.1.1 accumulate
- 1.4.1.2 find :给定一个迭代区间,从迭代区间开头依次搜索与我们希望查找的元素相同的值
- 1.4.1.3 count
- 1.4.2 写算法:向一个迭代区间中写入元素
-
- 1.4.2.1 单纯写操作: fill / fill_n
- 1.4.2.2 读 + 写操作: transform / copy
- 1.4.2.3 注意:写算法一定要保证目标区间足够大
- 1.4.3 排序算法:改变输入序列中元素的顺序
-
- 1.4.3.1 sort / unique
- 1.5 泛型算法使用迭代器实现元素访问
- 1.6 迭代器的分类
-
- 1.6.1 输入迭代器:可读,可递增(++)——典型应用为 find 算法
- 1.6.2 输出迭代器:可写,可递增——典型应用为 copy 算法
- 1.6.3 前向迭代器:可读写,可递增——典型应用为 replace 算法
- 1.6.4 双向迭代器:可读写,可递增递减——典型应用为 reverse 算法
- 1.6.5 随机访问迭代器:可读写,可增减一个整数——典型应用为 sort 算法
- 1.7 一些算法会根据迭代器类别(不是类型)的不同引入相应的优化:如 distance 算法
- 1.8 一些特殊的迭代器
-
- 1.8.1 插入迭代器
-
- 1.8.1.1 back_insert_iterator
- 1.8.1.2 front_insert_iterator
- 1.8.1.3 insert_iterator(iterater)
- 1.8.2 流迭代器
-
- 1.8.2.1 istream_iterator
- 1.8.2.2 ostream_iterator
- 1.8.3 反向迭代器
- 1.8.4 移动迭代器: move_iterator
- 1.9 迭代器与哨兵( Sentinel )
- 1.10 并发算法( C++17 / C++20 )
-
- 1.10.1 std::execution::seq(顺序执行)
- 1.10.2 std::execution::par(并发执行)
- 1.10.3 std::execution::par_unseq(并发非顺序执行)
- 1.10.4 std::execution::unseq(非顺序执行,一条指令可以处理多个数据(SIMD))
- 2 bind 与 lambda 表达式
-
- 2.1 很多算法允许通过可调用对象自定义计算逻辑的细节
-
- 2.1.1 transform
- 2.1.2 copy_if
- 2.1.3 sort
- 2.2 什么叫可调用对象?
- 2.3 如何定义可调用对象
-
- 2.3.1 函数指针:概念直观,但定义位置受限
- 2.3.2 类:功能强大,但书写麻烦
- 2.3.3 bind :基于已有的逻辑灵活适配,但描述复杂逻辑时语法可能会比较复杂难懂
- 2.3.4 lambda 表达式:小巧灵活,功能强大
- 3 bind
-
- 3.1 早期的 bind 雏形: std::bind1st / std::bind2nd
- 3.2 std::bind ( C++11 引入):用于修改可调用对象的调用方式
-
- 3.2.1 调用 std::bind 时,传入的参数会被复制,这可能会产生一些调用风险
- 3.2.2 可以使用 std::ref 或 std::cref 避免复制的行为
- 3.3 std::bind_front ( C++20 引入): std::bind 的简化形式
- 4 lambda 表达式
-
- 4.1 lambda 表达式( https://leanpub.com/cpplambda )
- 4.2 lambda 表达式会被编译器翻译成类进行处理
- 4.3 lambda 表达式的基本组成部分
-
- 4.3.1 参数与函数体
- 4.3.2 返回类型
- 4.3.3 捕获:针对函数体中使用的局部自动对象进行捕获
-
- 4.3.3.1 值捕获
- 4.3.3.2 引用捕获
- 4.3.3.3 混合捕获
- 4.3.3.4 捕获的补充
- 4.3.3.5 this 捕获
- 4.3.3.6 初始化捕获( C++14 )
- 4.3.3.7 *this 捕获( C++17 )
- 4.3.4 说明符
-
- 4.3.4.1 mutable
- 4.3.4.2 constexpr (C++17)
- 4.3.4.3 consteval (C++20)
- 4.3.5 模板形参( C++20 )
- 4.4 lambda 表达式的深入应用
-
- 4.4.1 捕获时计算( C++14 )
- 4.4.2 即调用函数表达式( Immediately-Invoked Function Expression, IIFE )
- 4.4.3 使用 auto 避免复制( C++14 )
- 4.4.4 Lifting ( C++14 )
- 4.4.5 递归调用( C++14 )
- 5 泛型算法的改进——ranges
-
- 5.1 可以使用容器而非迭代器作为输入
- 5.2 从类型上区分迭代器与哨兵
- 5.3 引入映射概念,简化代码编写
- 5.4 引入 view ,灵活组织程序逻辑
1 泛型算法
1.1 泛型算法:可以支持多种类型的算法
下图7行:调用了泛型算法sort用于排序
6行:定义了一个vector,里面包含100个元素
7行:调用std::begin和std::end来获取两个迭代器,这两个迭代器分别指向vector的对象x开头和结尾元素下一位。我么把这两迭代器传给sort,就能实现对x的排序。
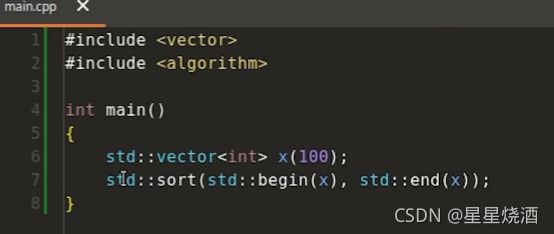
那么泛型体现在哪?
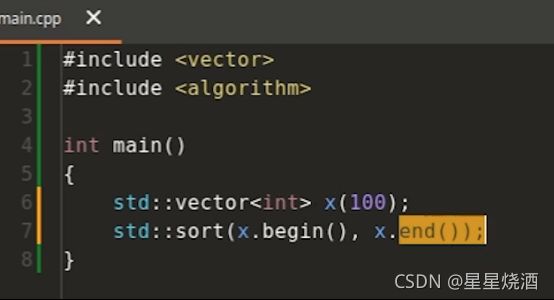
我们将上图代码修改一下:代码可以运行
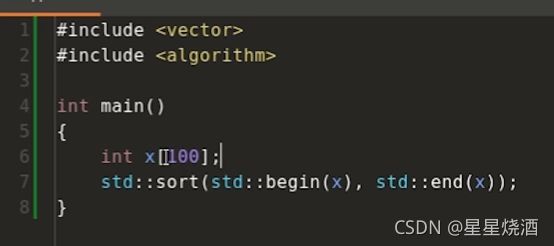
上图构造了包含100个元素的数组x,接下来对其进行排序。
修改之前和修改之后,传入sort的参数的类型不一样。修改之前传入的是vector所对应的迭代器,修改之后,传入的是int*型指针。
即std::sort在一定程度上支持各种类型的参数传入。
1.1.1 这里重点讨论 C++ 标准库中定义的算法
1.1.1.1
泛型算法是可以支持多种类型的算法,这里主要讨论C++标准库中定义的算法,包括
- algorithm
- numeric
- ranges
1.1.2 为什么要引入泛型算法而不采用方法的形式
这里出现了一个问题,那就是为什么要引入泛型算法而不采用方法的形式(这里的方法指的是类的成员函数
)
下图的sort是定义在名字空间中的函数,它不是定义在某个类里面的额,它不是一个方法。
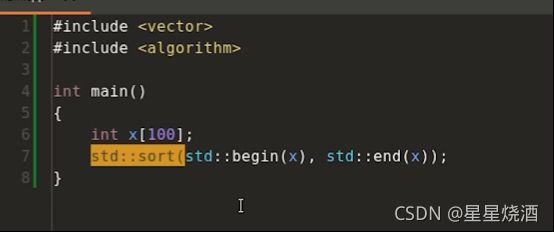
下图8行的sort是方法:
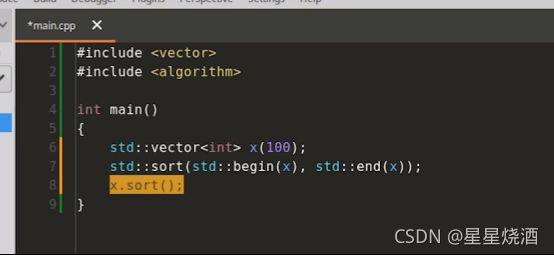
1.1.2.1 内建数据类型不支持方法
下图6行的x是内建数组类型(内建类型:基本类型,int,char,double,基本类型的数组类型,基本类型的指针类型,基本类型的引用类型)
下图程序不合法:
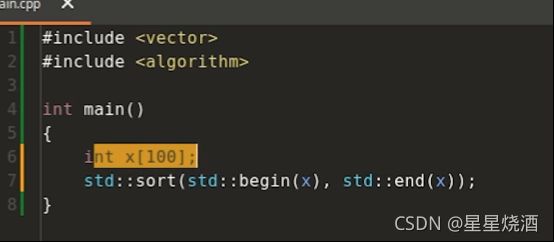
1.1.2.2 泛型算法计算逻辑存在相似性,可避免重复定义
泛型算法通常会实现成模板,因为模板有个好处:可以接收不同类型模板参数,如上图的sort就是典型的模板。
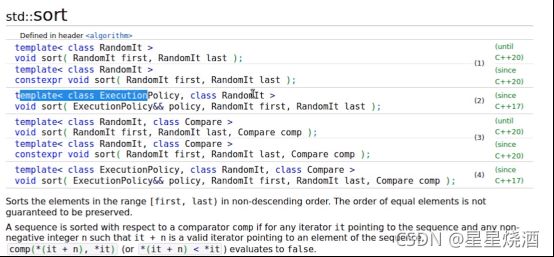
sort有4种定义方式,每一种定义方式都是声明成模板。声明成模板的好处:如果以不同类型实例化模板函数,编译器会自动生成不同实例。我们只需要去写一个具体sort逻辑即可,这个sort逻辑可能实现了快速排序,这个逻辑写好之后,如果我们传入的是不同的参数类型(如下图7行)(如vector的迭代器、数组的指针等),只要传入的这个东西支持解引用,解引用完后能比较大小等等这些操作,编译器就能自动为我们实例化出sort针对于我们目前传入类型所对应函数版本,这种实例化后的版本会使得代码能直接使用。
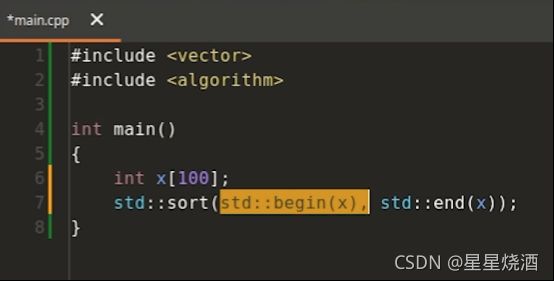
这样我们就实现了,只需定义一套函数逻辑,编译器针对不同的参数类型产生不同的实例化。这样就能够避免逻辑的重复定义。
这也是我们为什么要引入泛型算法,虽然传入的参数类型不一样,但是函数内部的计算逻辑存在相似性,故我们只写一套算法逻辑即可。
1.1.3 泛型算法如何实现支持多种类型:使用迭代器作为算法与数据的桥梁
如下图7行:泛型算法sort传入的是两个迭代器(迭代器本质是要模拟指针,或者说是泛化指针),使用迭代器作为算法与数据的桥梁。通过迭代器获取一段区间,然后在这段区间上进行相关操作。
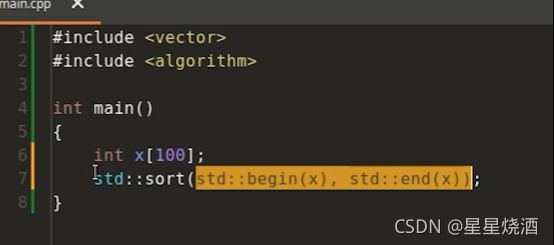
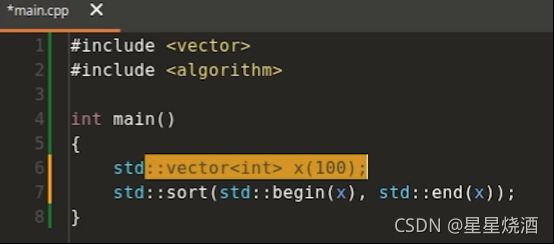
也可以:(这里的x是vector,是c++提供的标准类模板,不是内建数据类型,故可以定义方法(7行))
我们可以通过下图程序获取x指向开头元素的迭代器和指向结尾元素的下一个的迭代器,这样的写法和上述代码行为一样:
1.2 泛型算法通常来说都不复杂,但优化足够好
如在容器中查找元素的算法、把元素加起来的算法等等。
泛型算法通常来说都不复杂,但拥有足够好的优化,主要体现在:速度足够快,对于异常输入的处理足够鲁棒。
1.3 一些泛型算法与方法同名,实现功能类似,此时建议调用方法而非算法
1.3.1 std::find V.S. std::map::find
std::map::find方法:给定一个键,在容器map中寻找这个键是否存在,如果存在,就把这个键所对应的迭代器返回。
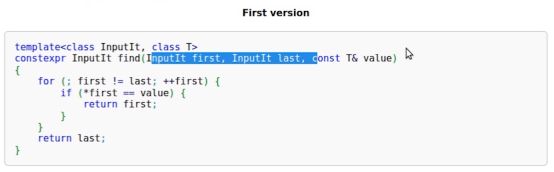
std::find:泛型算法,这个泛型算法可以接收任意类型的迭代器(只要)这个迭代器是输入迭代器即可。std::find也是在容器中寻找某一元素是否满足传入的参数value(如下图)
建议使用std::map::find。
像vector容器没有通过find方法,这是因为在vector中调用find方法很耗性能,且泛型算法中本身就提供了std::find算法。一般容器里面提供find方法,那么一定是容器中定义的find方法比泛型算法的find算法性能更好。
1.4 泛型算法的分类
泛型算法通常针对容器操作的,严格上是针对容器中的迭代区间操作。
1.4.1 读算法:给定迭代区间,读取其中的元素并进行计算
1.4.1.1 accumulate

(1):InputIt first:输入迭代器;InputIt last:输出迭代器;由这两个迭代器标明一个区间。
然后T init:初值(做累加的话得有初值,在初值基础上累加),最后accumulate返回一个T,这个T就是做完累加后的结果。

如上图,把first的值拿出来(*first)和init相加,再把相加之后的值保存到init。
++first:把first指向的位置挪到下一位(迭代器指向的位置挪到下一位)
(2):第2组声明比第(1)组多了BinaryOperation,accumulate是累加,我们可以使用加法做累加,乘法做累计,对于字符串我们甚至可以把它拼接起来,这也是累计。不同的累计方法,在一些情况下我们可能会去修改缺省的累计方法,这时使用BinaryOperation,通过引入一个函数指针,或者引入lamda表达式或者blind来修改accumulate内部的行为。
BinaryOperation:二元操作符。传入两个值,把init作为第一个值,*first作为第二个值,然后使用op进行操作,op可以定义成任何行为,如乘法,除法等

1.4.1.2 find :给定一个迭代区间,从迭代区间开头依次搜索与我们希望查找的元素相同的值
如下图,find返回的是InputIt,即返回一个迭代器,这个迭代器表明了是否在区间中找到了我们想要的那个值,表明了找到的这个值在区间中的位置,如果能找到的话,那么这个inputit一定是位于inputit first和inputit last之间的位置,如果没有找到希望的元素,那么inputit会等于inputit last。

1.4.1.3 count
从头到尾遍历迭代区间,如果这个迭代区间里面有我们希望找到的信息,那么就把需要返回的值+1,即计数
1.4.2 写算法:向一个迭代区间中写入元素
1.4.2.1 单纯写操作: fill / fill_n
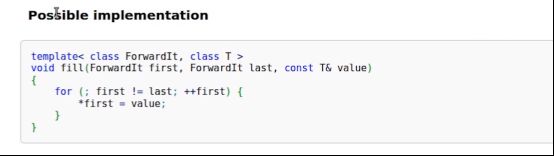
- fill
也是通过迭代器给定一个区间,这个区间标明开头位置和结束位置。把区间里的每个元素都赋值成value

- fill_n
fill_n如何确定写入的区间?首先给定区间开头元素OutputIt first,同时给定Size count:往区间里面写入多少个元素。即只要给定了开头元素后,无论是给定结尾元素还是给定需要多少个元素,我都能够确定区间范围,然后在这个区间范围进行写操作。

fill_n的实现也是通过循环,循环了count次

1.4.2.2 读 + 写操作: transform / copy
- transform
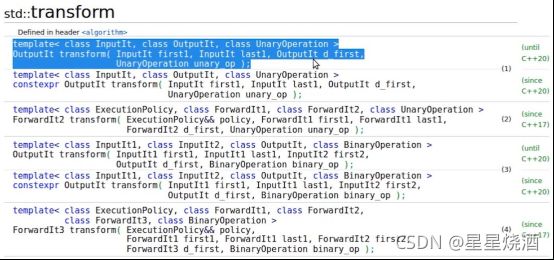
(1)InputIt first1,InputIt last1这个区间是用来读的;OutputIt d_first表示了写入区间的开头位置;UnaryOperation unary_op表示一元操作符,
通过while(first1 != last1)遍历整个读的区间(first1,last1).
*first1++:先对first1解引用,解引用之后获取到的值扔到unary_op里面进行计算(相当于对输入的数值进行变换),把变换后的值写到d_first里面,同时会把first1迭代器向下移动一位,d_first往后挪一位。

transform会遍历输入区间的每一个元素,对元素使用unary op进行变换并将变换后的结果写入到输出区间d_first中。
transform
transform的实现通常涉及到两个区间:读区间和写区间,读区间是给定了开头位置和结尾位置,是能确定读取范围,而写的区间只给了开头位置,因为写区间不需要给结尾位置,写区间到底多长,我们通过读区间就能确定出来。
- copy
遍历输入区间的每一个元素,将输入区间的元素拷贝到输出区间中
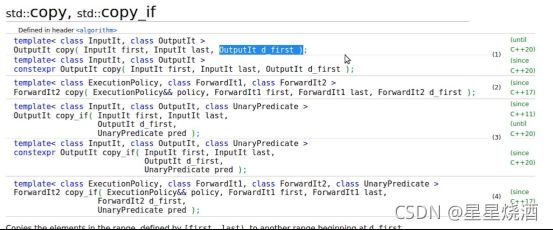
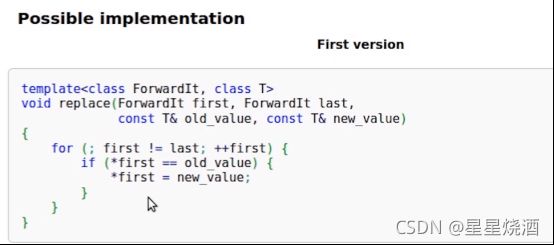
1.4.2.3 注意:写算法一定要保证目标区间足够大
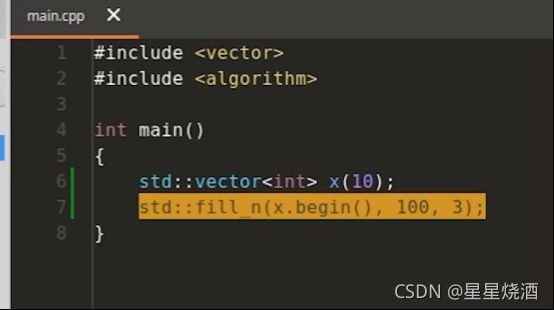
上图代码危险,运行结果未定义,因为vector包含10个元素,7行:要写入100个元素,那么会造成内存访问越界。
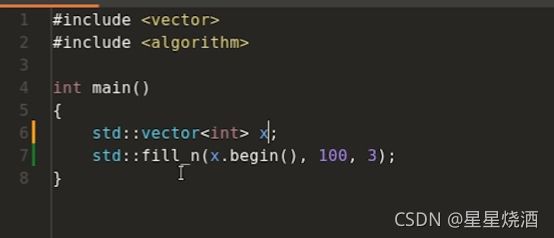
即,fill_n、transform和copy都不会给定输出区间或者填充区间的结尾,所以一定要确保目标区间足够大,否则会产生未定义的行为。
当然,我们也可以如下图这样定义vector(6行),然后动态扩展vector。
1.4.3 排序算法:改变输入序列中元素的顺序
1.4.3.1 sort / unique
- sort
使用sort的前提容器中的元素要支持<号比较。
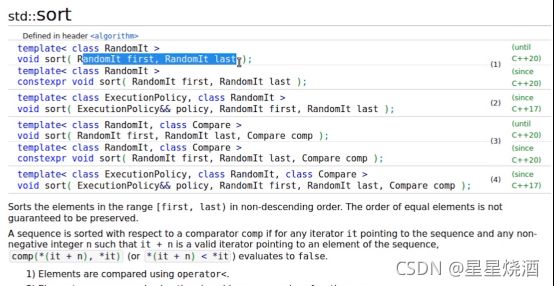
如上图(1),sort算法也是需要给定迭代器,通过first和last构造迭代区间,然后会对区间里面的元素进行排序。缺省情况下会对区间里面的元素从小到大排序。
(3):Compare comp是一个二元函数,这个函数接受两个元素,经过计算返回一个bool值,表示第一个元素和第二个元素的大小关系。通过引入Compare可以改变sort的缺省行为,缺省情况(1)只能从小到大排序,使用Compare可以实现从大到小排序,或者更复杂的排序方法(通过实例化Compare引入更复杂方法)。
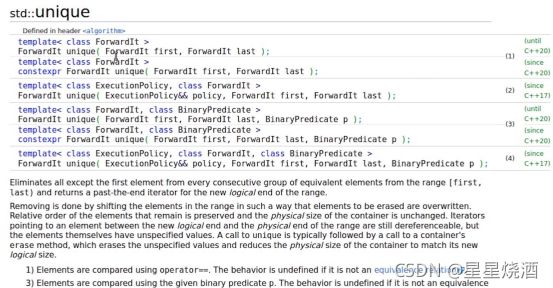
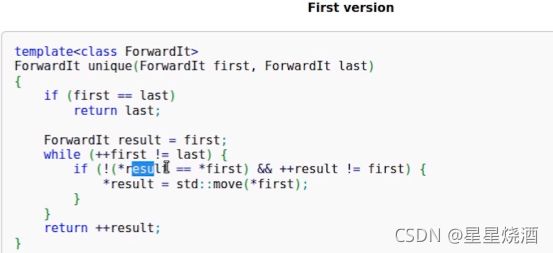
- unique
unique也是读取一个区间,但需要保证区间里面所有元素都是有序的,判断有序的元素里面是否出现若干连续相同的元素,只保留若干连续相同的元素中的一个。

对1,2,2,3,4做了unique之后,输出为:

如上图,unique返回一个迭代器,这个迭代器指向最后一个4,即我们做完unique后,所有元素的下一个位置。


1.5 泛型算法使用迭代器实现元素访问
1.6 迭代器的分类
1.6.1 输入迭代器:可读,可递增(++)——典型应用为 find 算法
1.6.2 输出迭代器:可写,可递增——典型应用为 copy 算法
1.6.3 前向迭代器:可读写,可递增——典型应用为 replace 算法
接收的是ForwardIt前向迭代器

1.6.4 双向迭代器:可读写,可递增递减——典型应用为 reverse 算法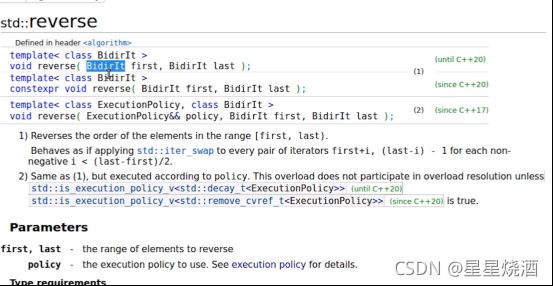
1.6.5 随机访问迭代器:可读写,可增减一个整数——典型应用为 sort 算法
为什么要引入迭代器?迭代器是用于模拟数组指针。
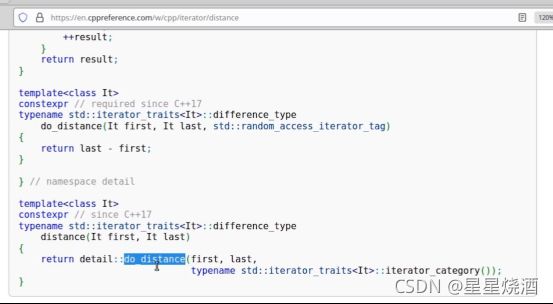
1.7 一些算法会根据迭代器类别(不是类型)的不同引入相应的优化:如 distance 算法
distance接收两个迭代器InputIt first和InputIt last,计算这两个迭代器之间元素的距离。
distance算法在函数声明时接收的是输入迭代器InputIt,换句话说只要是输入迭代器,那么就可以使用distance算法。
1.8 一些特殊的迭代器
之前讨论过,泛型算法会使用迭代器作为一个桥梁来访问一个区间,无论是对区间读还是写,都要定位出所要读或写的区间,通常我们会使用迭代器来描述这样的区间。如有一个vector容器,我可以用vector的begin或end来获取表示了整个vector容器里面所有元素的区间,然后让泛型算法进行处理。
除了上述的基于容器构造的迭代器,我们还有一些特殊的迭代器:插入迭代器、流迭代器、反向迭代器、移动迭代器。
1.8.1 插入迭代器
1.8.1.1 back_insert_iterator
back_insert_iterator是一个类模板:
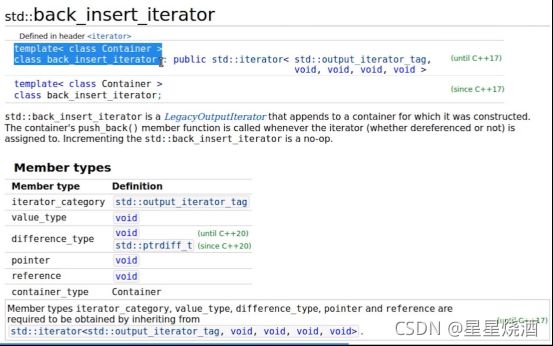

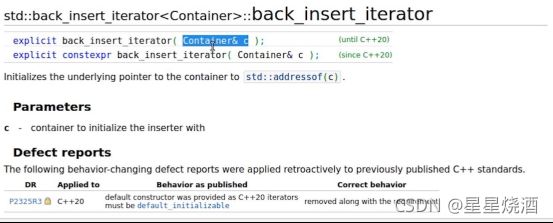
back_insert_iterator还提供构造函数,如上图,接收一个Container(Container代表一个容器),保存在它的对象的内部,接下来对容器进行这些操作:operator=,operator*,operator++,operator++(int)。其中operator*,operator++,operator++(int)这3中操作都是no-op(无操作,不会对对象内部产生任何影响),唯一影响的是operator=(会往关联的容器(构造back_insert_iterator时传入的参数(容器))的结尾中插入对象(调用容器的push_back接口插入元素的,不是调用insert))。
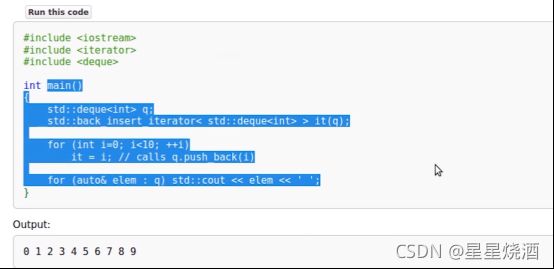
如上图定义了back_insert_iterator,it(q)这个迭代器它底层关联了容器q,接下来调用it = i,本质上就是调用q.push_back(i),依次插入元素。
故back_insert_iterator要能work,底层就要支持push_back接口。
为什么要引入back_insert_iterator?
如之前的fill_n(写操作),写操作的目标区间要足够大,如下图程序:使用fill_n希望往x里面插入10个元素,每个元素的值是3:程序出错


这是因为8行的x里面底层所包含的缓存区不能够写入10个元素,那么在进行写操作时会造成缓存区溢出,即非法写入,这个行为是未定义的。为什么fill_n会这样?
我们来看看fill_n是如何实现的:我们要对first进行递增,解引用,把value值写到解引用后所指向的位置,如果递增之后first指向的是一块非法的内存,那么解引用后往里写东西,这个行为就是未定义的。

而back_insert_iterator提供了operator=,operator*,operator++,operator++(int)接口。那么我们可以使用back_insert_iterator的对象来作为上图的first。如果使用back_insert_iterator作为上图fill_n的第一个参数,那么会往back_insert_iterator所对应的底层的容器中不断调用push_back进行插入,如将上图程序改为:
8行:定义了一个插入迭代器,这个插入迭代器的底层就是vector,程序不报错。
使用了back_insert_iterator插入迭代器作为fill_n的第一个参数,接下来在fill_n内部循环了10次,相当于调用了10次x的push_back,就等于把元素插入进去了。


上图8行比较长,back_insert_iterator可以简写为back_inserter:
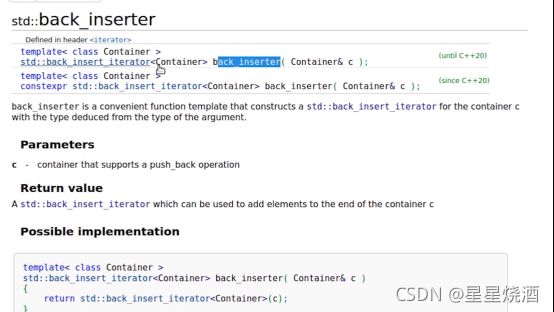
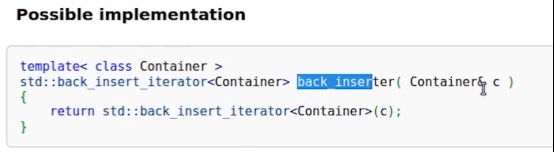
即调用back_inserter,传入一个容器Container,就能返回back_insert_iterator。
即:
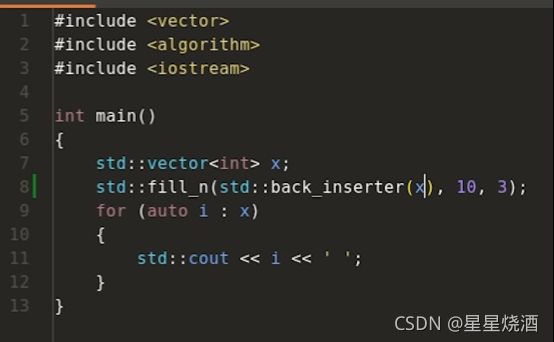

故引入插入迭代器,本质上是算法的写操作一定要保证目标容器有足够大的空间,但是在一些情况下可能没办法保证目标容器有足够大的空间,这时可以考虑使用插入迭代器,在使用了插入迭代器之后,似乎是对迭代器解引用之后来赋值,但是它会在底层转换成相应的push_back这样的语句,或者其他插入元素的语句,这样就能够确保即使容器刚开始没有那么大的空间,但是也能够去调用相应的写算法来完成一系列相关的操作。
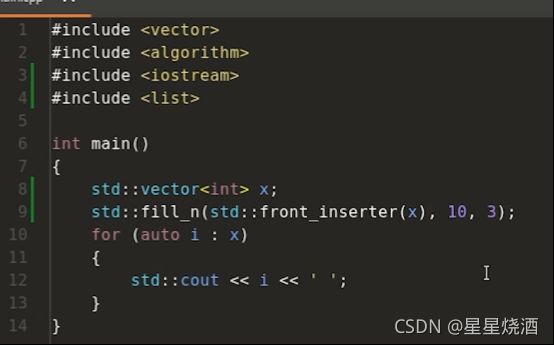
1.8.1.2 front_insert_iterator
front_insert_iterator通过调用pusk_front来向容器的开头插入元素。
9行:front_insert_iterator也可简化成front_inserter。使用front_inserter来构造了一个插入迭代器,每次调用fill_n时,本质上就是调用pusk_front
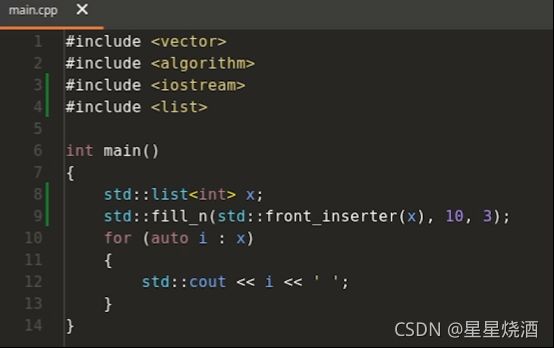

但是把8行的list换成vector,报错:(vector本身不支持pusk_front)
1.8.1.3 insert_iterator(iterater)
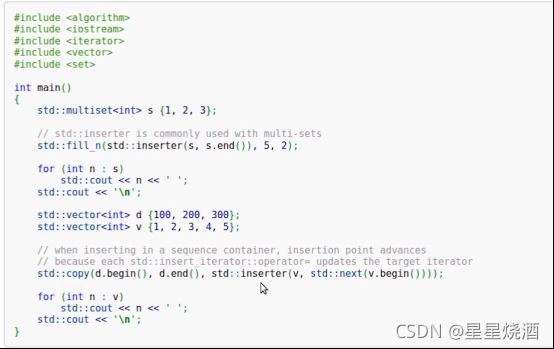
更加一般化的插入迭代器。insert_iterator在构造时提供容器、容器的迭代器。在每次写=号时(赋值时),会调用容器的insert,而容器在调用insert,一般要提供迭代器的位置,这个位置就代表要插入的位置,相应的就会使用在构造insert_iterator时传入的Container::iterator来作为insert的位置。

1.8.2 流迭代器
1.8.2.1 istream_iterator
istream_iterator也是一个类模板,第一个参数T是需要我们显式给定的,后3个参数CharT、Traitds、Distance都是缺省的。

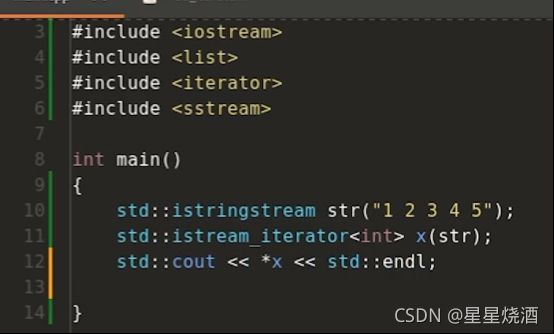
下图10行:isstringstream是输入的字符串流,可以使用它来进行字符输入
12:迭代器x可以用*来解引用

下图14行:迭代器可以++


输入流迭代器干了啥?
输入迭代器不断对输入流进行解析,解析出传入的参数:

istream_iterator的具体操作:

- constructor
构造函数有如下4种:(如上图程序使用了下图的(3):使用输入流的对象作为输入,来构造出istream_iterator对象)

除此之外,我们通常也使用(2)这样的缺省的方式构造istream_iterator。如下图12行,构造了一个缺省的输入流迭代器
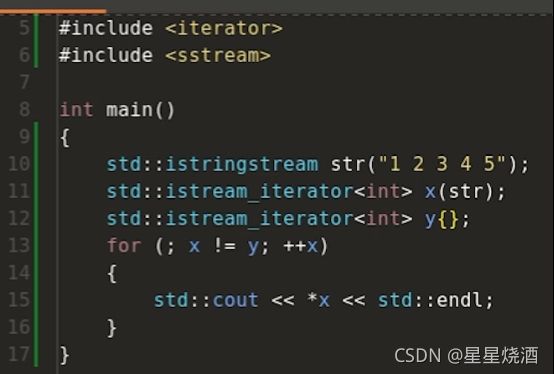

上图,11行构造了一个输入流迭代器,10行相当于使用str从输入流中获取相应的int元素。12行构造了一个输入流迭代器,这个迭代器是使用缺省方式构造的。通常,迭代器是成对使用的,用来表示一段区间的开头和结尾位置,比如vector,我可以用vector的begin和end来获取开头结尾位置,但是对于流迭代器,会有一个比较尴尬的事情,使用上图11行可以用来表示一段区间,区间里包含了一些int值,可以使用它来表示区间的开头位置,但对于流迭代器而言,我们通常使用一个空的流迭代器(缺省方式构造出来的流迭代器)来表示区间结尾位置。接下来不断地对迭代器进行递增,最终会走到区间结尾位置。每次递增,会把10行str的底层buffer刷新,当底层的输入流全部被耗尽之后,那么x就会自动把它的状态转化为一个特殊状态,这个特殊状态和y的状态进行比较,两者状态一致则为真。通过这样的方法,11行12行就构造出一个概念上的区间,其中x对应区间开头,y对应区间结尾。接下来13~16行对上述区间进行遍历并打印。
实际上输入流迭代器是一个输入迭代器,它可以递增、解引用。既然是一个输入迭代器,那么相应来讲,那么就可以吧输入流迭代器应用在一些输入迭代器的算法上,如accumulate,如下图:
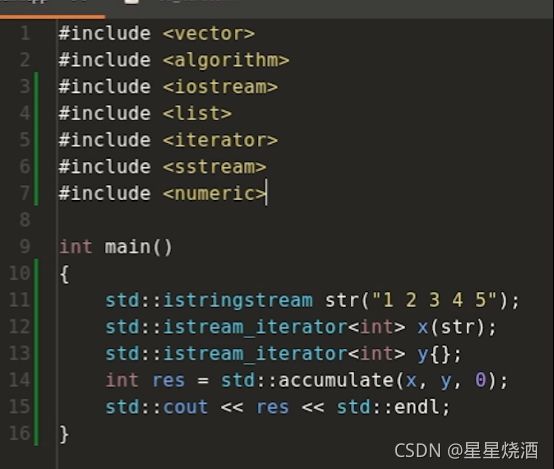

上图12即:使用输入流迭代器来标识一个区间,这个区间里的元素是整数int,accumulate算法即把这些整数值加起来。
注意上图程序的13行不能写成如下这样:(下图这个不是类对象的定义,而是函数声明)

1.8.2.2 ostream_iterator
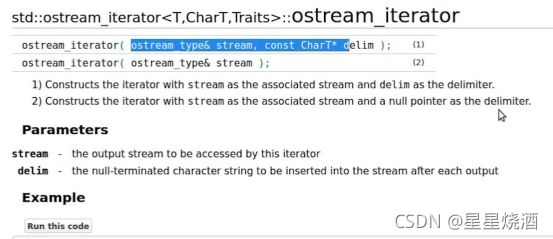
如上,输出流迭代器在构造时也是有两种构造方法:
(1):传入一个输出流,同时传入一个delim:间隔符
(2):只传入一个输出流
如下图蓝色即间隔符:
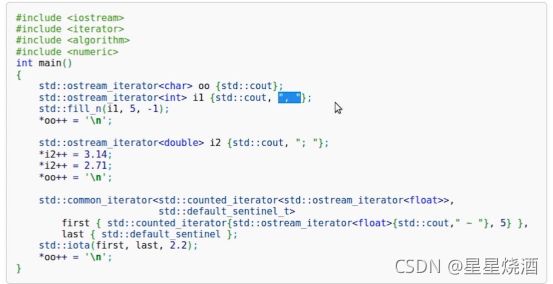
上图,fill_n:往目标容器里面插入n个元素(上图插入5个元素,每个元素为-1)

输出流迭代器本质上是把写操作映射成向输出流进行输出这样的操作。
1.8.3 反向迭代器
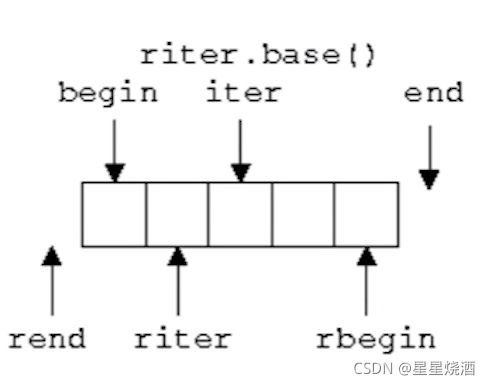
对于一些容器,我们可以使用rbegin和rend获取反向迭代器,反向迭代器基本上是从后到前遍历容器的元素。
如:
12行:输出流迭代器
把x中的所有元素都输出到标准输出中


12行换成rbegin和rend:


注意:riter.base:如下图,反向迭代器riter在第二格,而调用riter.base()则riter.base()指向riter的下一位
1.8.4 移动迭代器: move_iterator
移动迭代器:move_iterator,本质上在每次读取时候会调用std::move,对于支持移动赋值构造的对象来说会将原有的对象的内容清空。
int main()
{
std::vector<std::string> v{"this", "_", "is", "_", "an", "_", "example"};
auto print_v = [&](auto const rem) {
std::cout << rem;
for (const auto& s : v)
std::cout << std::quoted(s) << ' ';
std::cout << '\n';
};
print_v("Old contents of the vector: ");
std::string concat = std::accumulate(std::make_move_iterator(v.begin()),
std::make_move_iterator(v.end()),
std::string());
print_v("New contents of the vector: ");
std::cout << "Concatenated as string: " << quoted(concat) << '\n';
}
// 输出为Old contents of the vector: "this" "_" "is" "_" "an" "_" "example"
// New contents of the vector: "" "" "" "" "" "" ""//使用了std::move,v里面的元素被移动给concat了,v里面被清空了
// Concatenated as string: "this_is_an_example"
上面代码的vector包含若干string,后面调用make_move_iterator,用来构造move_iterator迭代器,然后调用accumulate,string数据accumulate即相当于把string数据串联起来。上图代码会把vector中包含的元素打印出来。
1.9 迭代器与哨兵( Sentinel )
对于一个容器来讲,通常我们需要使用一个迭代器来表示一段区间,如begin返回容器开头,end返回容器结尾的下一位,即通过begin和end表示了一段区间。但是我们表示区间的方法还有很多,比如之前在istream_iterator中的x和y,本质上x对应一个迭代器,y对应一个迭代器,但是y和end不一样,end是确确实实指向了一块内存,begin一次次进行递增,当走到最后一块内存时,则begin和end相等,此时区间访问结束。但是istream_iterator的y并不指向一块具体的内存,x不断递增至和y等价的状态。我们并不需要两个迭代器描述两块内存,某个迭代器递增之后能走到另外一块内存。我们只需要两块迭代器描述两个对象(如x和y),其中一个对象不断变化,直至和另一个对象判等时相等即区间访问结束。
基于这样的要求,故引入哨兵(用来表示区间结尾的迭代器,如上述的y)。
主要用于range,如下图蓝色,使用哨兵概念时,蓝色这俩可以是不同类型:

1.10 并发算法( C++17 / C++20 )
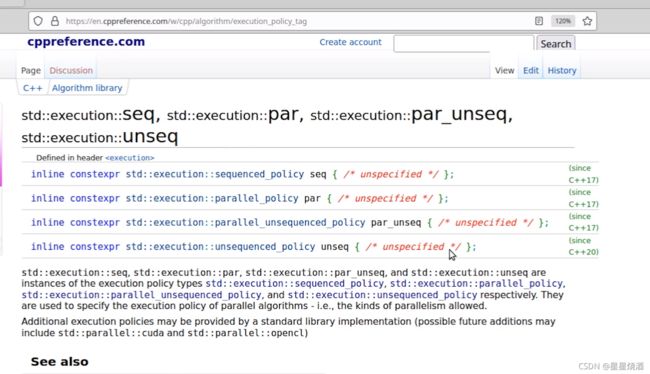
4种执行方式。
1.10.1 std::execution::seq(顺序执行)
1.10.2 std::execution::par(并发执行)
par:会使用多个线程执行
1.10.3 std::execution::par_unseq(并发非顺序执行)
1.10.4 std::execution::unseq(非顺序执行,一条指令可以处理多个数据(SIMD))
unseq:一个线程执行时,一条指令可以处理多个数据(SIMD)。
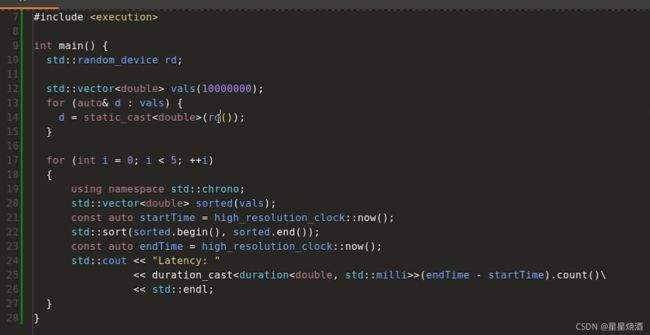
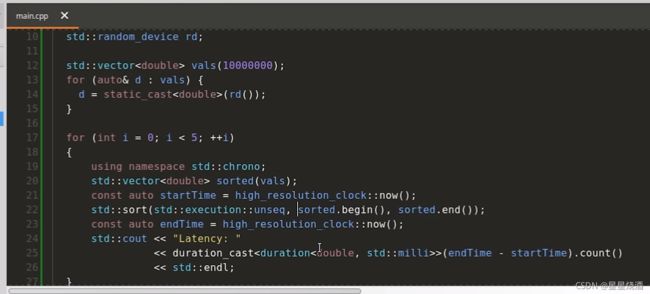
多线程更快,如下图为单线程代码:
10行:产生随机数
12~15行:构造了一个包含10000000个double类型的数组,数组中的元素随机排布
20行:把vals复制到sorted里面
22行:调用sort来对sorted进行排序
21、23行:c++标准库函数,用来获取当前时间,这俩时间相减即可知22行sort执行了多长时间。
25行:使用duration_cast把sort执行时间打印出来
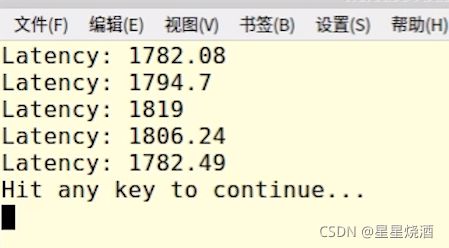
接下来使用unseq:(一次性处理多个元素)(22行)
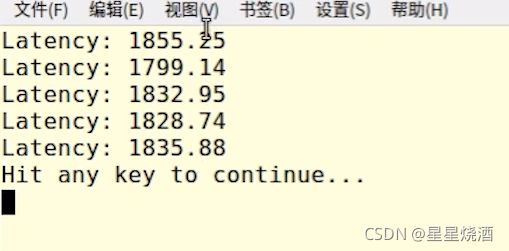
时间并没有减少多少。
接下来使用par:(多线程)
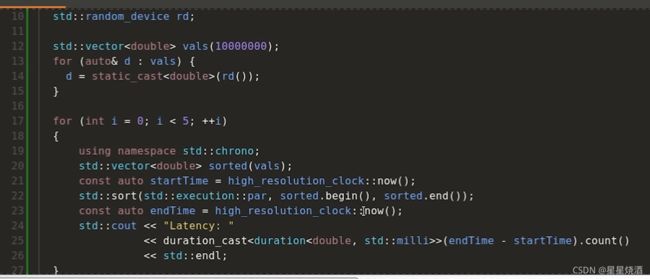

速度提升。
2 bind 与 lambda 表达式
之前讨论算法,更多的是讨论算法的接口以及它所实现的通用的逻辑。很多算法允许通过可调用对象自定义计算逻辑的细节。
2.1 很多算法允许通过可调用对象自定义计算逻辑的细节
2.1.1 transform
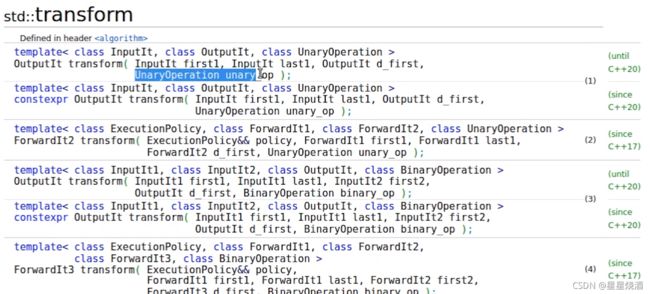
上图蓝色是一个可调用对象。从读区间获取每个元素,每个元素都调用UnaryOperation的对象unaryop,获取相应的结果,并把这个结果写到目标区间*d first++里面去。即我们可以定义不同的UnaryOperation来实现不同的功能,如下图:
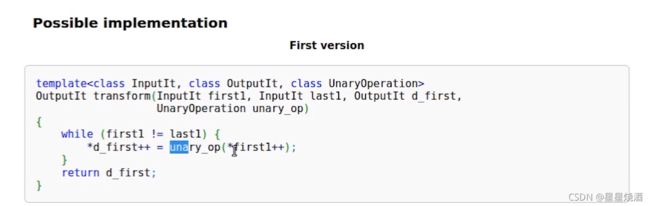
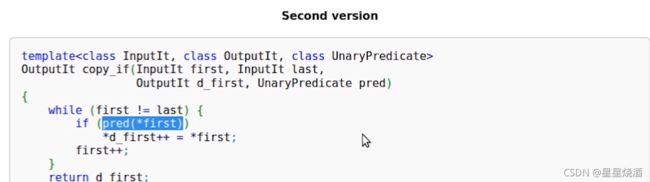
2.1.2 copy_if
copy_if也有一个UnaryPredicate(Unary即只接收一个元素,Predicate即位置,判断是真是假)
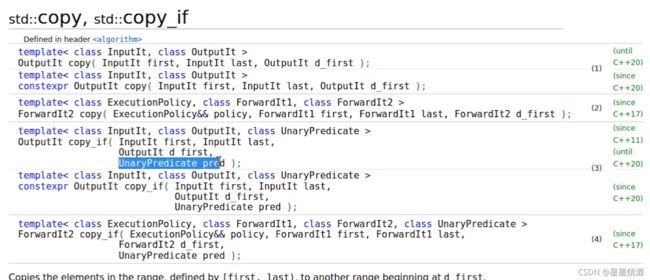
copy的实现:从输入区间读取每个元素,写入输出区间
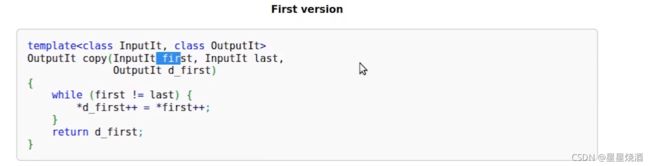
copy_if实现:有一个位置UnaryPredicate(输入元素pred,在if(pred(*first))返回一个bool值来表示这个元素是真是假,如果if语句返回的是真,才进行写入操作。),即通过UnaryPredicate来自定义一个算法逻辑,只选择输入区间的一部分内存放入输出区间。
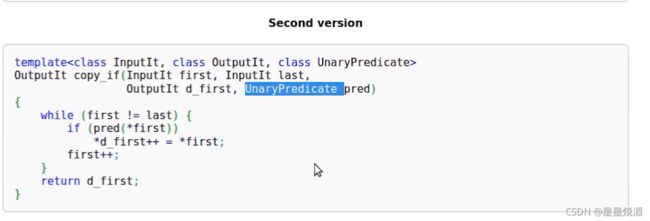
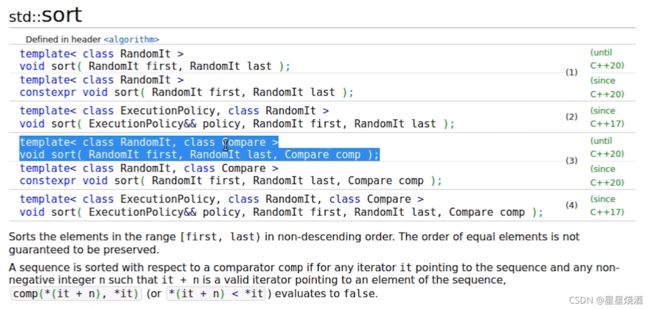
2.1.3 sort
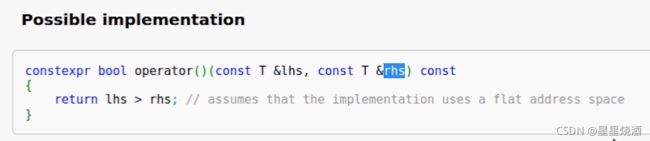
缺省情况下,sort是使用<号将元素由小到大排序。但是我们也可以使用下图蓝色Compare来自定义排序方式(如使用>进行比较,排序)。
2.2 什么叫可调用对象?
如上图,copy_if的实现例子,蓝色的pred(*first)是指,把输入元素first传到pred()里面进行处理,处理完后返回结果,这种语法形式很像函数调用,因此把pred称为可调用对象。实际上函数或函数指针就是一种典型的可调用对象。
如下:
13行:定义了一个输入容器x
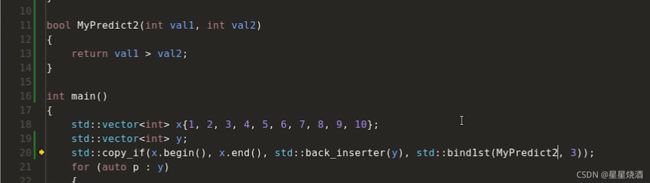
15行:调用copy_if,传入的区间是x.begin()和x.end(),即传入区间包含x的每个元素;输出的迭代器是back_inserter(往14行的y里面push_back);copy_if最后一个参数是位置:MyPredict,即给定任何数据,返回真假(6~9行:传入的元素大于3才会返回真),只有返回真,才会将x中的元素写入y中。


即如上代码,我们定义了一个函数指针MyPredict,使用这个函数定义了可调用对象。
2.3 如何定义可调用对象
如上图程序
2.3.1 函数指针:概念直观,但定义位置受限
bool MyPredict(int val){
return val > 3;
}
int main() {
std::vector<int> x{1,2,3,4,5,6,7,8,9,10};
std::vector<int> y;
std::copy_if(x.begin(),x.end(),std::back_inserter(y), MyPredict);
for(auto & val : y){
std::cout << val << " "; // 输出为 4 5 6 7 8 9 10
}
return 0;
}
但定义位置受限。即我们不能在函数内部定义函数,比如说将MyPredict定义到main函数里面,报错:

2.3.2 类:功能强大,但书写麻烦
可以通过操作符重载的方式,为类引入一些可调用对象的方式。
2.3.3 bind :基于已有的逻辑灵活适配,但描述复杂逻辑时语法可能会比较复杂难懂
2.3.4 lambda 表达式:小巧灵活,功能强大
3 bind
bind是通过绑定的方式修改可调用对象的调用方式。
3.1 早期的 bind 雏形: std::bind1st / std::bind2nd
具有了 bind 的基本思想,但功能有限。

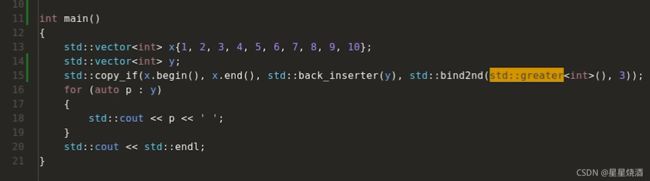
其中,greater是一个函数模板:接收两个参数lhs和rhs,然后判断lhs是否大于rhs。而上图程序15行,bind2nd中,把第二个参数固定成3,那么这个bind2nd变成了新的可调用对象,只接收一个参数,这个参数只要大于3,则返回真值。
使用std::bind1st:

使用std::bind1st即对greater函数的第一个参数lhs进行绑定,即此时bind1st传入的参数,只要满足小于3,才会返回真值。
但使用场景有限:下图代码错
3.2 std::bind ( C++11 引入):用于修改可调用对象的调用方式
使用bind,需要加入名字空间:

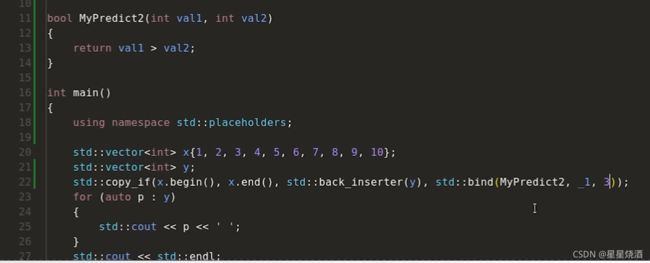
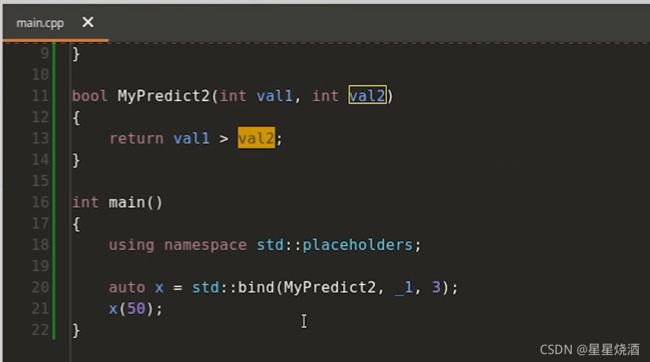
std::bind(MyPredict,_1,3)是可调用对象,我们重点讨论下std::bind(MyPredict,_1,3)的行为:
20行:bind绑定的是MyPredict2。这里的_1代表21行中x(50)中的第一个参数,_1定义在std::placeholders名字空间里面。
21行:x(50)调用MyPredict2,50会作为MyPredict2第一个参数。结合20行,即把50和3传入MyPredict2(11行)
13行:判断50是否大于3,从而返回真假值。

或写成:(把名字空间和_1写一起)

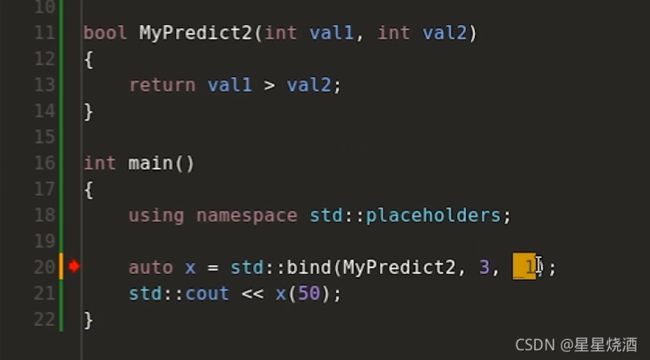
要注意,_1不是代表传入MyPredict2的第一个参数(11行的val1),而是指调用21行的x时,x输入的第1个参数。
再如:下图3作为MyPredict2的第一个参数(11行的val1),50还是对应_1,作为MyPredict2的第二个参数(11行的val2)
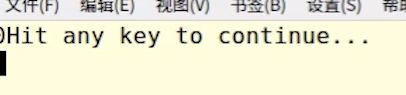
我们还可以:
20行:_2:传入bind的第2个参数。


即,20行,bind绑定MyPredict2,_2绑定为val1,3绑定为val2,接下来21行调用x时传入两个参数,hello对应的是_1,50对应的是_2。
再如:

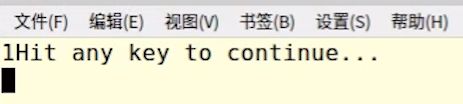
再如:

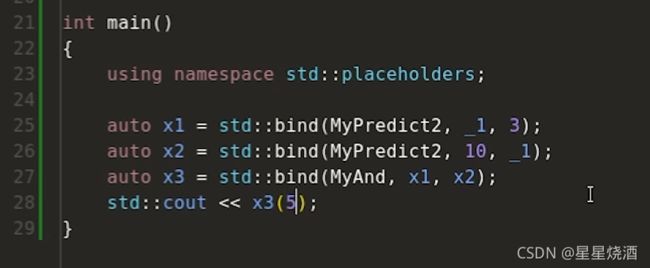

上图,28行:5传入到bind里面(27行),然后会先对x1和x2进行计算,使用5来替换25、26行的_1,由13行,5>3返回真;由18行,10>5,返回真。接下来对27行的MyAnd进行计算,由16行,val1和val2都是真,则返回TRUE,即返回1。x3的行为是输入一个参数,判断这个参数是否位于3和10之间。故28行输入5,返回TRUE。
由上知,bind可以组合。
再如:
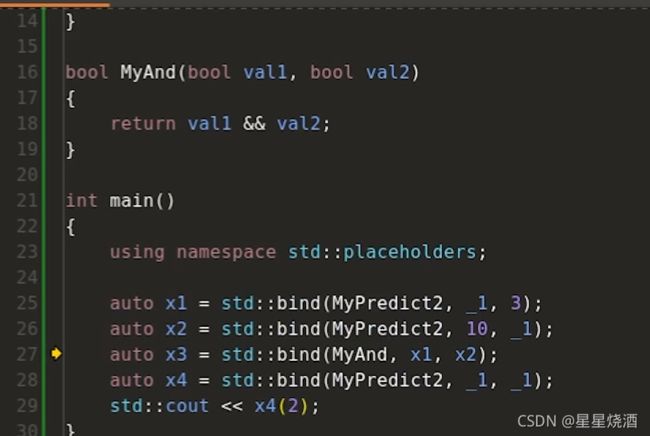
无论29行输入啥,都会返回0。因为13行两个参数相等。
3.2.1 调用 std::bind 时,传入的参数会被复制,这可能会产生一些调用风险
- 传入的参数会被复制
如下图25行:构造了x1,x1里面要包含可调用对象MyPredict2的信息,其次还要包含3这样的信息,3是怎么样保存在x1里?3是被复制进去的。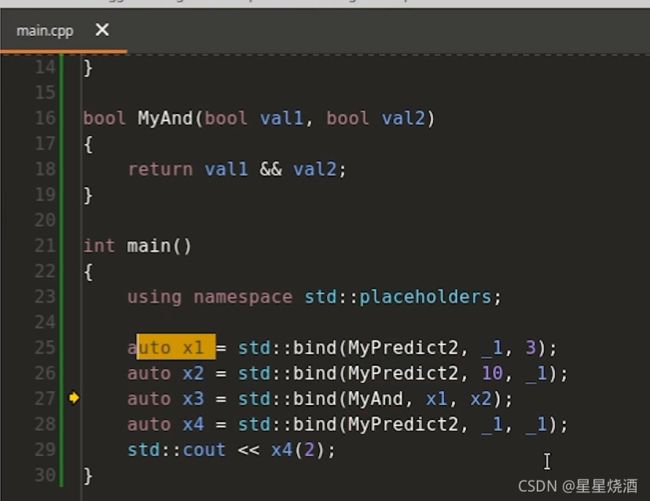
此时会有风险。如下代码:
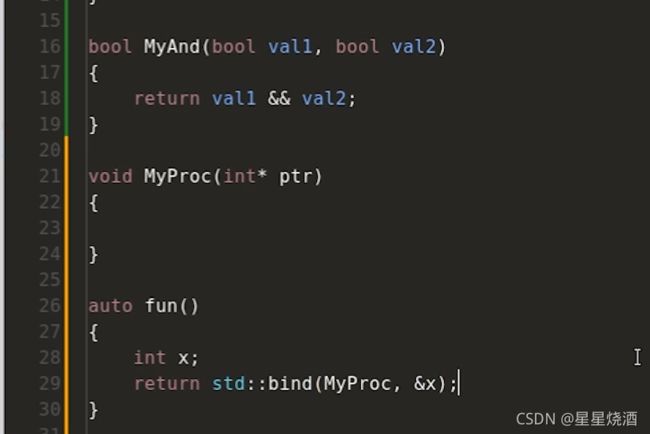


26行:b是对Proc的绑定
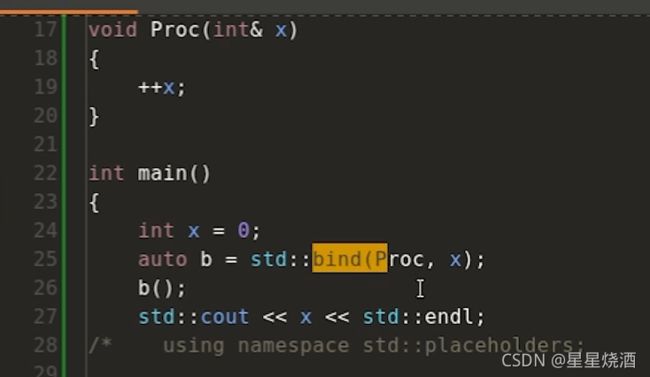
在构造bind时,x会被拷贝给b这个对象里面包含的数据成员,接下来26行b()调用Proc时,是要拿b里面那个拷贝过来的x传入17行Proc的形参内,然后进行++x,但是24行的那个x还是为0,并没有++0=1。

那么对于这种情况,想要修改x,该如何处理?我们可以可以使用 std::ref 或 std::cref 避免复制的行为。
3.2.2 可以使用 std::ref 或 std::cref 避免复制的行为
-
std::ref


25行的std::ref(x)会构成一个对象,这个对象会被拷贝复制给b内部,但是std::ref(x)对象内部会包含一个引用,引用这个x,因此接下来调用Proc时,还是会使用这个引用,还是会修改x的值。这也就是bind传引用的方式。 -
std::cref(传常量引用时避免拷贝)

但bind也有自己的局限性,它的可读性不是很强,在书写复杂逻辑时候可能会出现bind套bind的情况,在C++20中引入了std::bind_front来简化bind的书写。
3.3 std::bind_front ( C++20 引入): std::bind 的简化形式
4 lambda 表达式
4.1 lambda 表达式( https://leanpub.com/cpplambda )
- lambda 表达式为了更灵活地实现可调用对象而引入

- C++11 引入 lambda 表达式
- C++14 支持初始化捕获、泛型 lambda
- C++17 引入 constexpr lambda , *this 捕获
- C++20 引入 concepts ,模板 lambda
4.2 lambda 表达式会被编译器翻译成类进行处理
lambda 表达式功能强大是因为它会被翻译成类。但是类书写起来麻烦。
4.3 lambda 表达式的基本组成部分

4.3.1 参数与函数体
lambda表达式的目标是构造一个可调用对象,要想调用可调用对象,需要有输入输出,故要提供参数、函数体。

如下图,之前使用bind_front来实现某个数和3进行比较,返回是真是假。
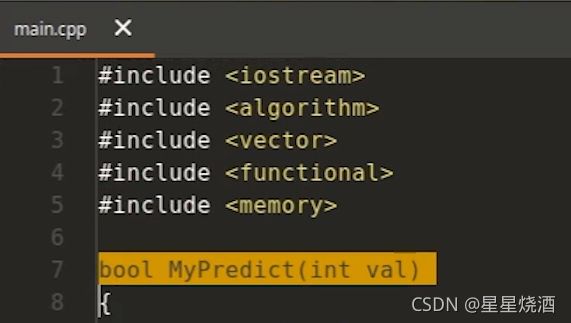

如果用lambda表达式:
9行:lambda表达式构造出来的对象x
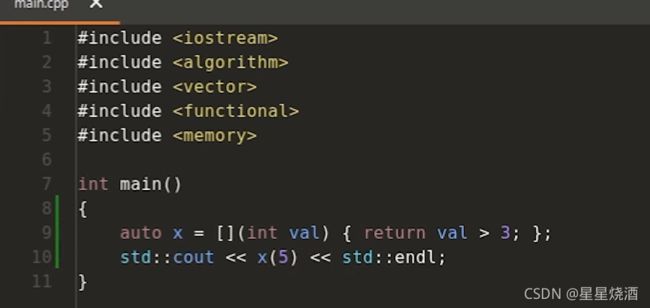
或
即5>3,返回true。
其中上上图9行:(int val)是lambda表达式的参数;{return val > 3;};是函数体;
再如,实现输入一个数,大于3小于10时为真的功能:
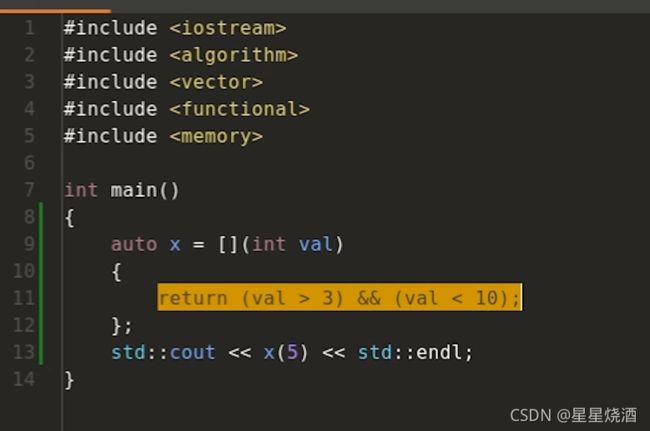
lambda表达式实际上是类:
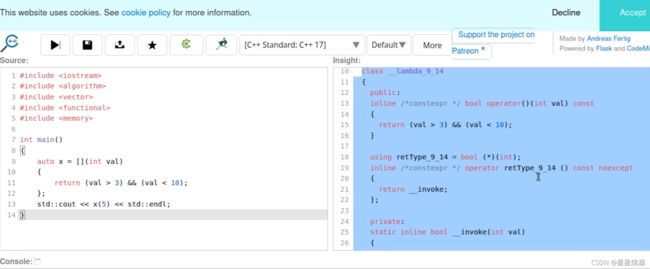
4.3.2 返回类型
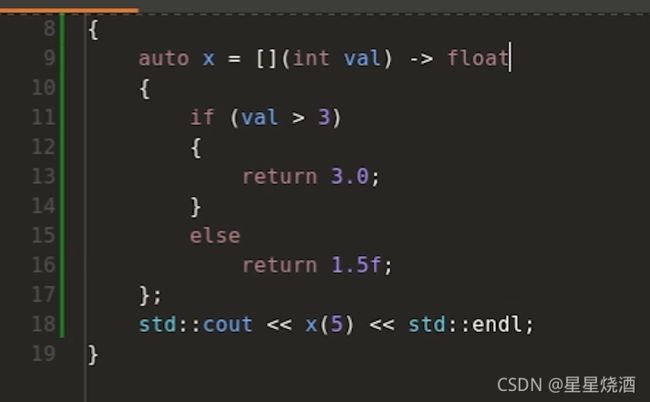
如下图,lambda表达式的返回类型是bool:

我们可以显式写出lambda表达式的返回类型:(下图9行)
再如:
int main() {
// 返回类型bool
auto x = [](int val)->bool {return val > 3;};
return 0;
}
4.3.3 捕获:针对函数体中使用的局部自动对象进行捕获
如下图:令val和y比较
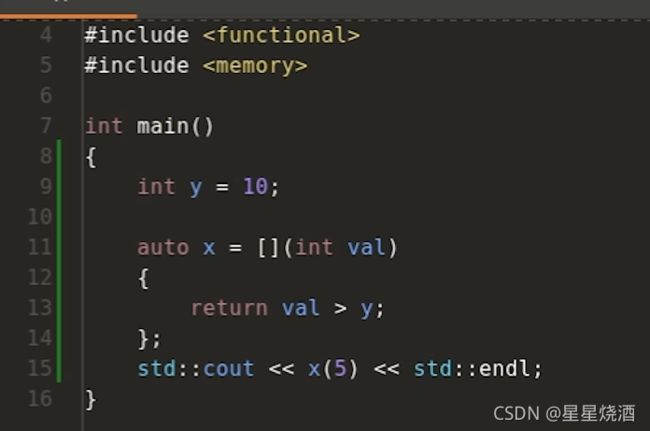
上图程序不合法,因为lambda表达式内部不知道y是什么,不会跳到lambda表达式外面查看y是啥。
我们应该在11行的[]中加入y,这个[]就是用来捕获的:

返回0(5<10)。可以编译。
捕获即,会把上图9行的y值复制到lambda表达式内部的y中,即捕获了y。
但是上图9行的y是局部自动对象(会自动进行销毁),如果我们把这个局部自动对象改为下图:

此时程序不合法。因为9行的y不再是局部自动对象了,它是一个局部静态对象,我们不能捕获局部静态对象。
如果不使用捕获,那么程序合法:
即只有局部自动对象,我们不能在lambda表达式函数体内直接使用,要想使用,需要进行捕获。而静态对象或全局对象,我们不需要进行捕获。
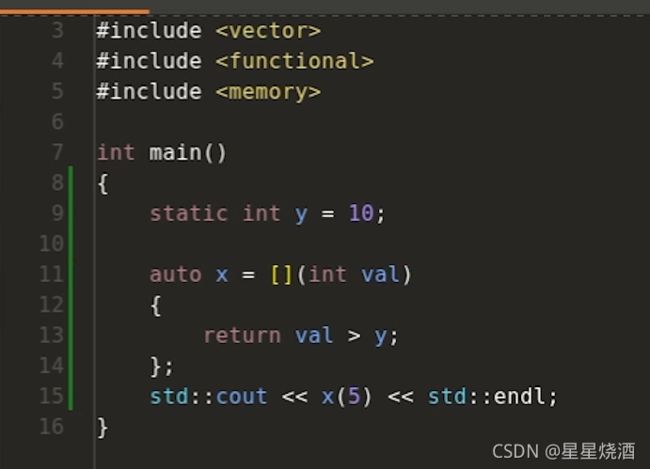
4.3.3.1 值捕获
下图11行:捕获了一个y

打印出10即说明我们在lambda表达式内部对y进行修改,这个信息不会传递到lambda表达式外部。
这是因为11~15行的y使用了值捕获(使用[]),即y被复制到lambda表达式内部。
4.3.3.2 引用捕获
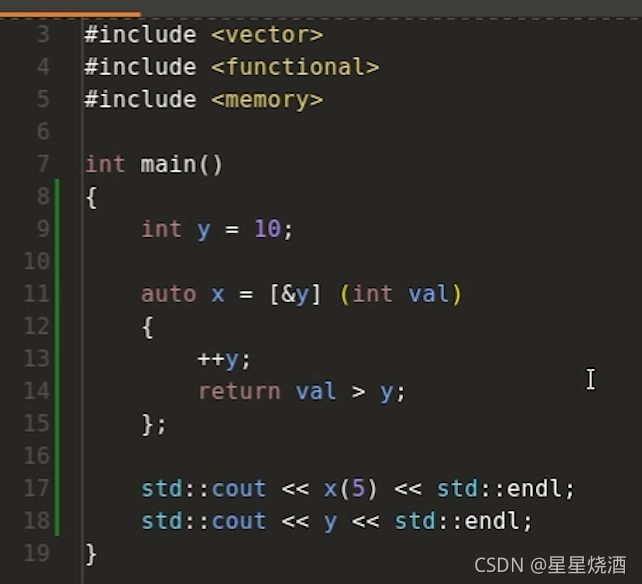

y的值增加了,因为11行使用了引用捕获,此时lambda表达式里面的y会和9行的y绑定。
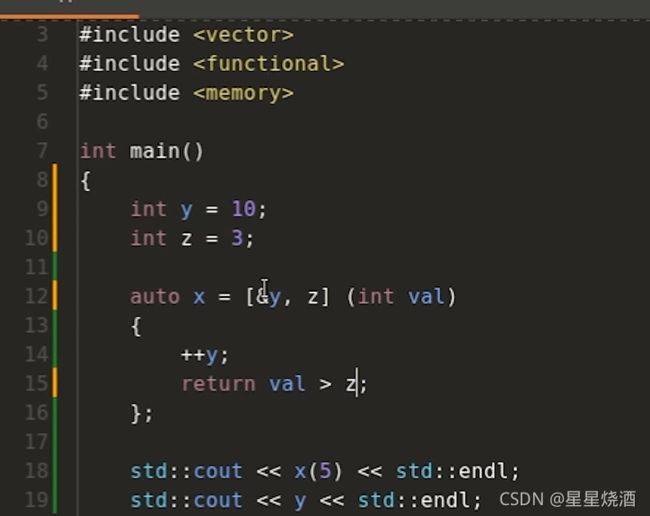
4.3.3.3 混合捕获
[]是捕获列表,里面可以包含多种捕获。
12行:对y进行引用捕获,对z进行值捕获。故++y会影响9行y值。
4.3.3.4 捕获的补充
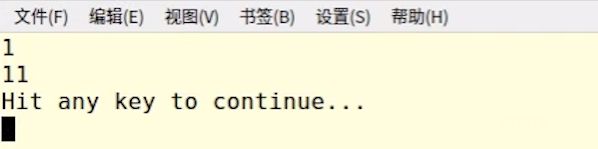
对所有使用的对象进行值捕获:如14行的z会被自动捕获为3。
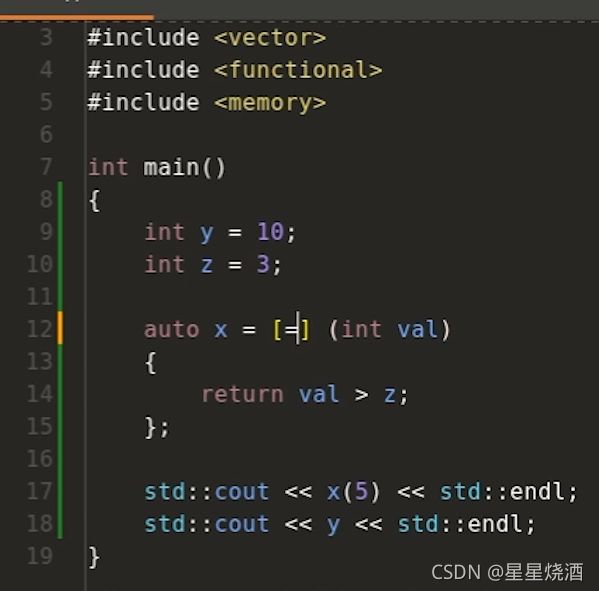
再如:
如果14行使用了某些局部自动对象(如z),这些对象没有显式出现在12行捕获列表里面,那么我们可以使用引用的方式进行捕获:即对所有使用的对象进行引用捕获。
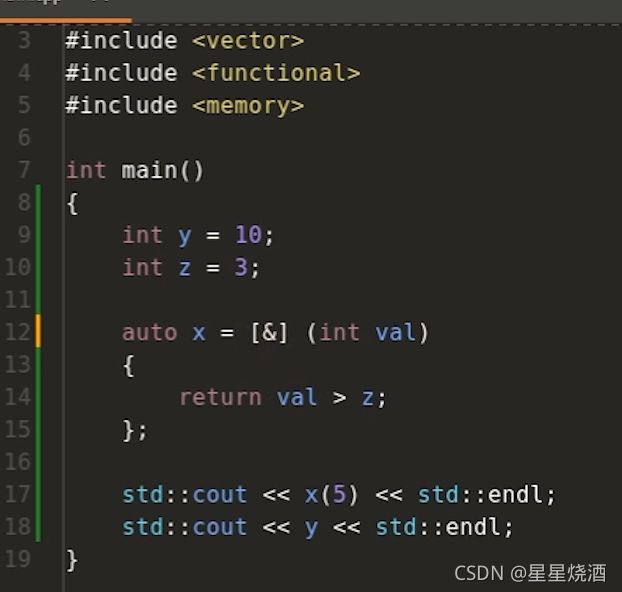

再如:
lambda表达式内用到的局部自动对象通常是采用引用捕获的方式,但是z是例外,需要采用值捕获。
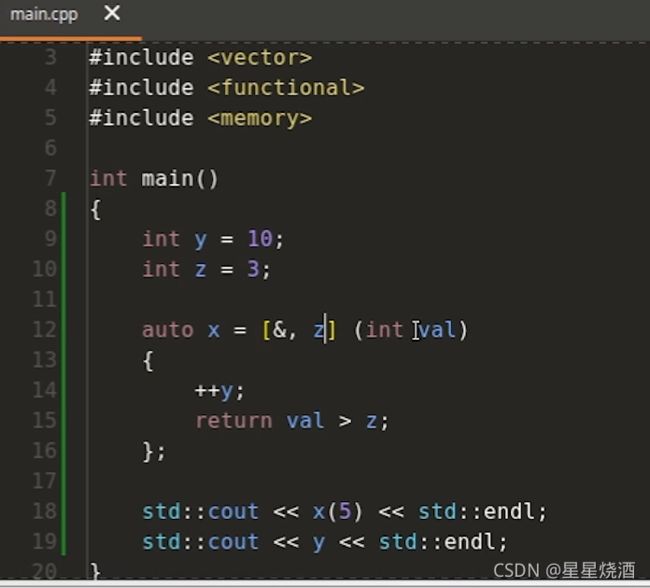

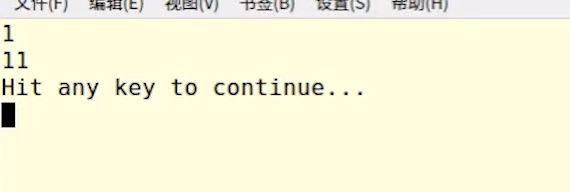
再如:
下图代码指,lambda表达式内使用使用的局部自动对象通常是采用值捕获的方式。但是对于y我们采用的是引用捕获的方式。

4.3.3.5 this 捕获
7行:定义一个结构体Str
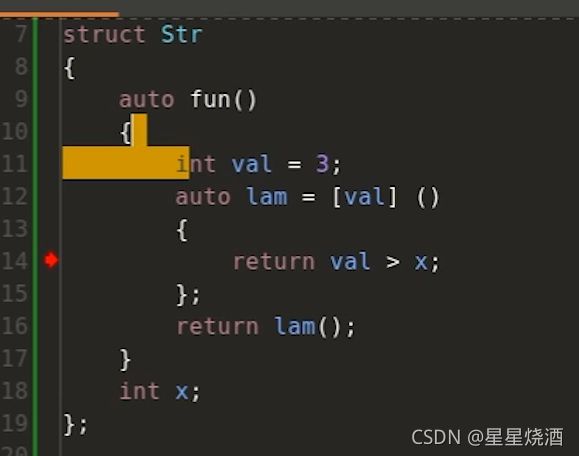
但上图18行的x不是局部自动对象,不是静态对象也不是全局对象,故我们不能使用上述的值捕获来捕获x(val是局部自动对象,可以使用值捕获来捕获val)。我们应该使用this来捕获这个x。
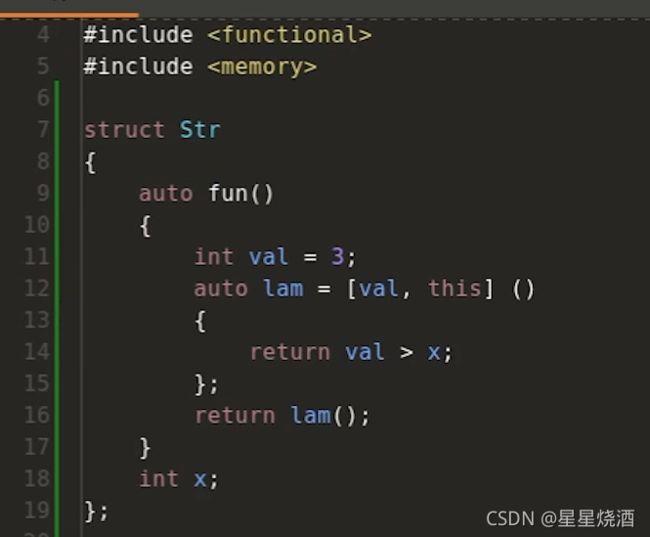

关键字this表示如果我构造了结构体Str的对象,在里面调用fun函数,this实际上是一个指针,指向Str的对象。如下图,23行我们构造了Str的对象s,24行调用fun函数,那么此时12行的this对应得是对象s的地址,故我们可以在Str内部使用18行的x。
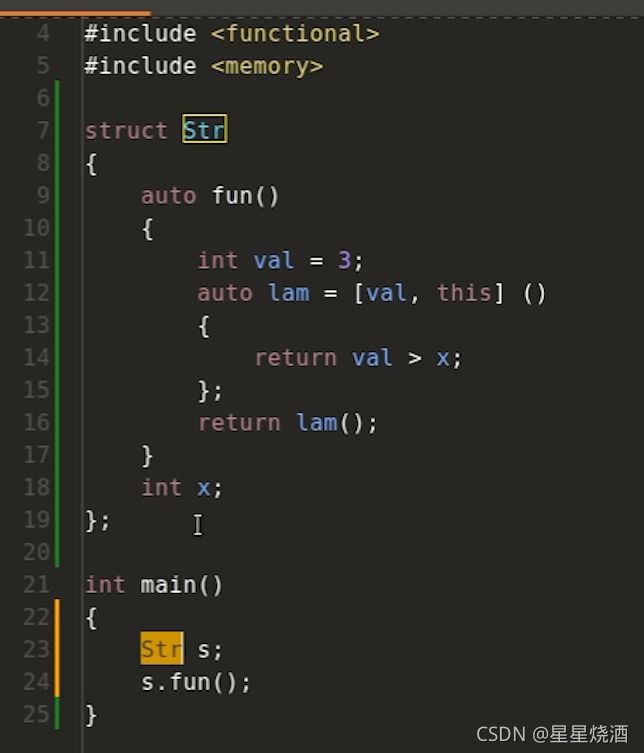
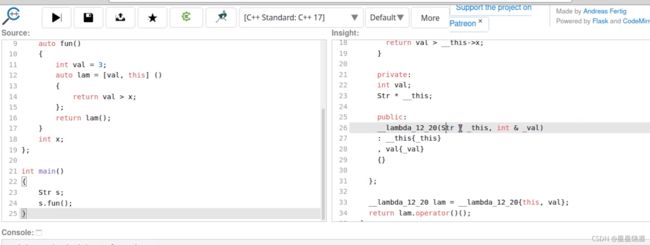
4.3.3.6 初始化捕获( C++14 )
c++14之前:


c++14之后:
24行:y = x是初始化捕获(构造一个自动对象y,然后把x的值赋给y,接下来这个y可以在lambda表达式内部进行使用)


这种捕获的好处:
- 我们可以使用这样的方式来引入一些更复杂的捕获逻辑,如:(25行相当于构造lambda表达式时会把a里面的值移动到y,接下来a里面空了,但我们在lambda表达式内就可以使用y)
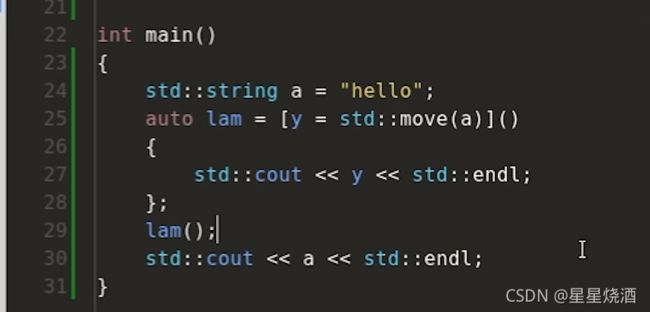
- 提升系统性能
如下图程序:


使用c++14的初始化捕获,上图代码可以修改为:

这个代码和之前代码有个优势,26行的y是在构造lambda表达式时被执行了一次,接下来把z值保存下来,在每一次判断时,都是判断val和z。
如果不使用初始化捕获,那么每一次调用lambda表达式,都会计算x+y的值。对比之下,使用初始化捕获可以提升系统性能。
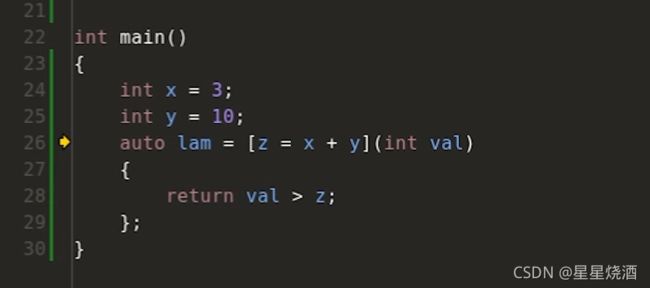
再如下图:
26行左边x指我们要构造一个对象x,这个对象x将用于lambda表达式里面,而这个对象x会使用26行右边的x进行初始化。

(x和y没有使用)
4.3.3.7 *this 捕获( C++17 )
下图的Str中我们使用this捕获实际上有个问题:

this捕获实际上有些危险,如:
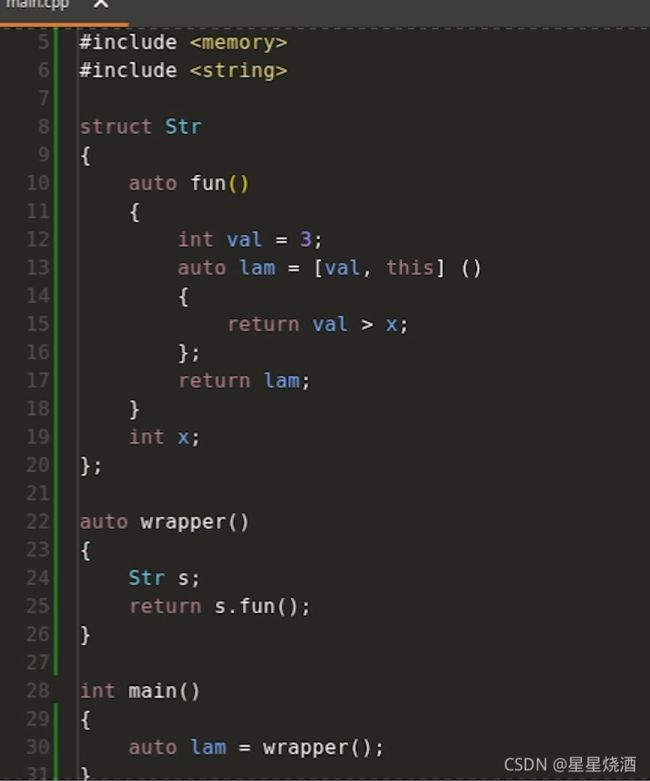
上图代码有风险,30行的wrapper返回的是lambda表达式,这个lambda表达式捕获了一个局部自动对象val(12行),这个局部自动对象会用值的方式拷贝在lambda表达式内部,除此之外,lambda表达式还捕获了一个this,this是Str对象的指针,指向了24行的对象s,但s是局部自动对象,在调用完wrapper函数后,这个s会被销毁。换句说,我们在30行获得的lam,它里面包含了一个悬挂的指针,指向一个已经被销毁的对象。而接下来如果再去调用lambda时(31行),行为会是未定义的:
故在c++17引入*this:this是一个指针,*this是指针解引用。
this这个指针指向Str的对象,*this则是Str的对象(不再是指向),他会把Str里面所有内容复制到lambda表达式内部,此时执行下图31行则会比较安全,因为我们不在乎24行的s是否被销毁。
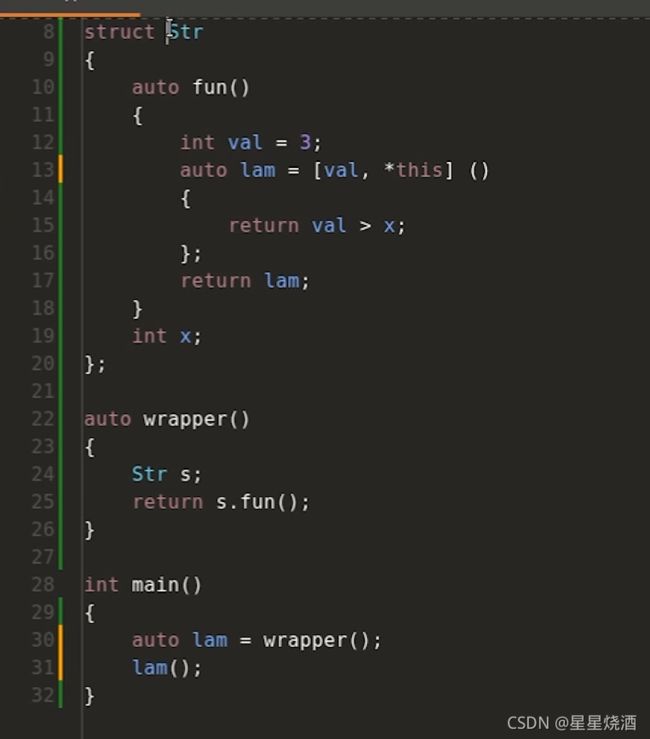
但*this相当于复制了Str对象s的内容,会消耗更多性能。
4.3.4 说明符
4.3.4.1 mutable
mutable:移除按值进行复制捕获的参数的不可修改性
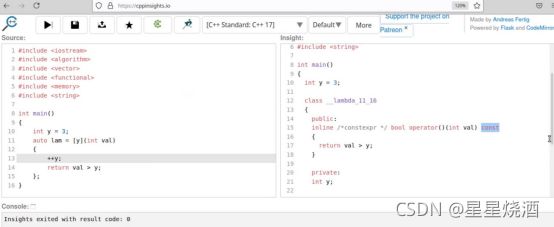

4.3.4.2 constexpr (C++17)
constexpr:建议编译器在编译期进行执行

4.3.4.3 consteval (C++20)
consteval:强制编译器在编译期进行执行
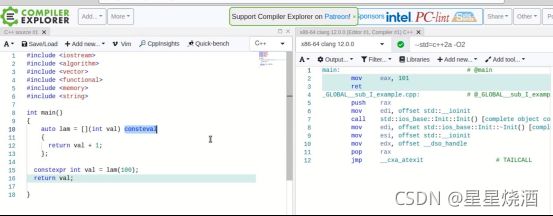
4.3.5 模板形参( C++20 )
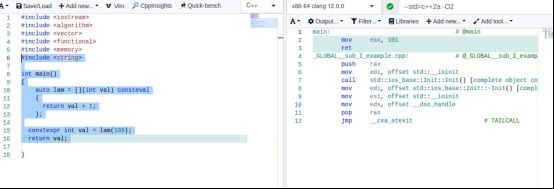

4.4 lambda 表达式的深入应用
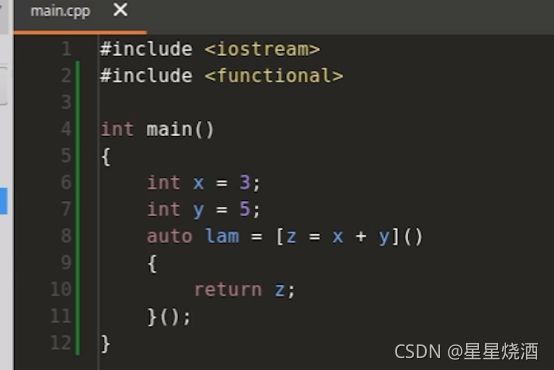
4.4.1 捕获时计算( C++14 )
如下图:捕获x+y(10行)
这样在12行每一次调用lam时,都会执行x+y。比较耗费时间。

可改成:(8行:在捕获之初就把x+y计算出来了;12行每次调用lam时,会直接从lambda表达式所对应构造出来的类的对象里面读取z的值就OK了,不需要重复计算x+y)

4.4.2 即调用函数表达式( Immediately-Invoked Function Expression, IIFE )
如上图8~11行构造一个lambda表达式,我们通常是构造了之后再去执行,即把构造和执行分成两步。
但是即调用lambda表达式会将上图代码转化为:
即,先构造lambda表达式(8~11行),然后马上执行这个lambda表达式来获取相应结果。
这样有啥好处?
下图13行val是一个常量,常量即要在初始化时就给定其值,这个值不能改变。但是初始化的方式如果很复杂,我们之前可以通过定义一个函数(fun函数)来初始化这个常量val:

但是这样初始化常量val比较复杂,我们可以把fun函数改成一个lambda表达式(8~11行),这就是即调用的lambda表达式,我们把初始化val的逻辑发到lambda表达式内部,即通过一个简单的lambda表达式就初始化val了。
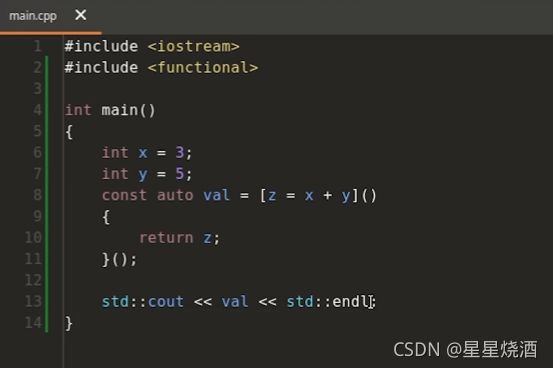
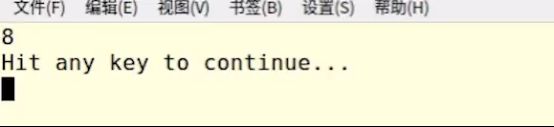
4.4.3 使用 auto 避免复制( C++14 )
之前在写lambda表达式时是显式地给出参数类型,如:下图lambda表达式地参数式x,类型是int。
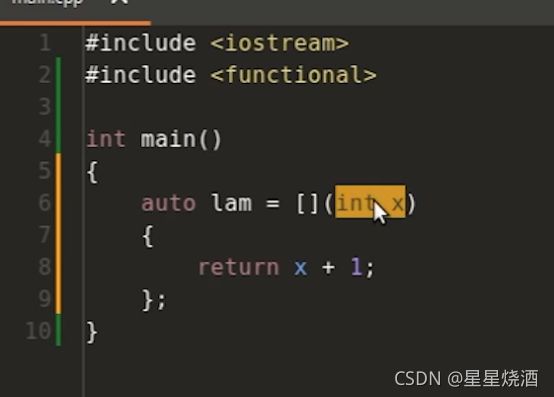
我们可以把参数类型换成auto:
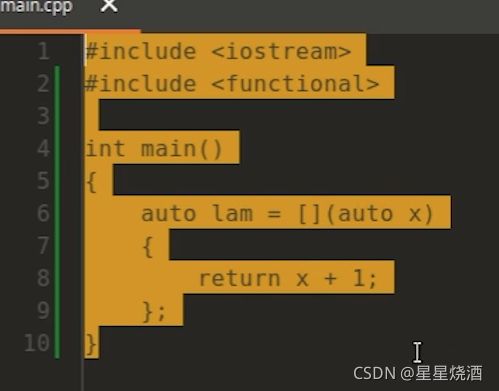
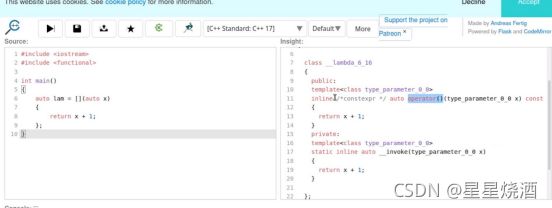
这个auto可以是int,double也可以是float等等。那么这和使用auto避免复制有什么关系?
如下图:
7行:定义了一个map,里面包含一个元素,键是2,值是3;
8~11行:定义一个lambda表达式,访问map;
13行:调用lambda表达式
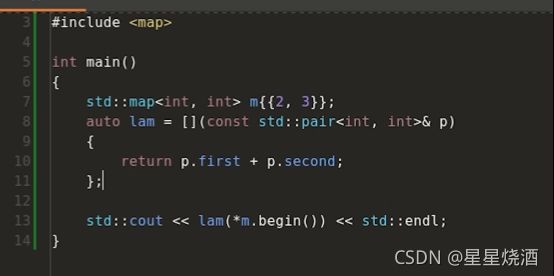
map里面保存的元素,可以认为是std::pair,分别表示键和值;通过*m.begin相当于访问了map的第一个元素({2, 3})。但这样还是可能会复制。
我们应写成:
int main() {
std::map<int,int> m {{2,3}};
auto lam = [](const auto & p){ // 注意这里如果写const std::pair还是会复制,因为map的返回值类型为std::pair,这无疑中加重了我们的负担量
return p.first + p.second;
};
lam(*m.begin());
}
4.4.4 Lifting ( C++14 )
Lifting(C++14):利用Lambda表达式是由类进行实现以及auto会被实现为模版来实现近似多态的行为。
17行:使用bind绑定fun函数
18行:调用b


fun1和fun2只是参数类型不同,功能相同。因此可以都写成fun(即使用了c++的函数重载),但是bind在使用时无法区分这个fun函数是fun1还是fun2,故引入lifting。
17行的左边auto对应的是lambda表达式的类型;auto x中的auto对应的是输入参数x的类型。
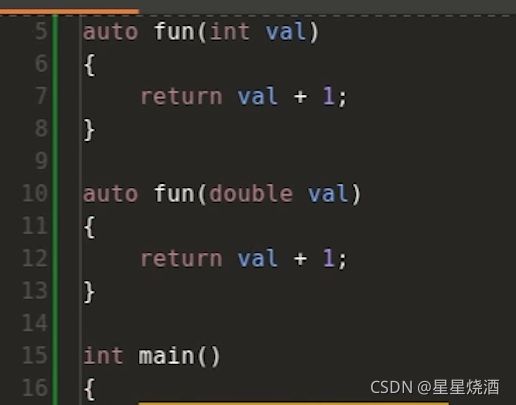
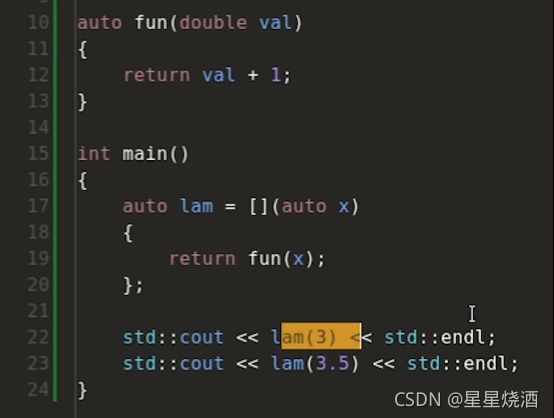

17~20行实现了一个函数模板,把模板参数x传入之后,在调用fun函数时,会根据传入的参数的具体类型来选择两个fun函数的其中一个来进行调用。
auto fun(int val){
return val + 1;
}
auto fun(double val){
return val + 1;
}
int main() {
auto lam = [](auto x){
return fun(x);
};
std::cout << lam(3) <<std::endl;
std::cout << lam(3.0) <<std::endl;
}
4.4.5 递归调用( C++14 )
递归调用:
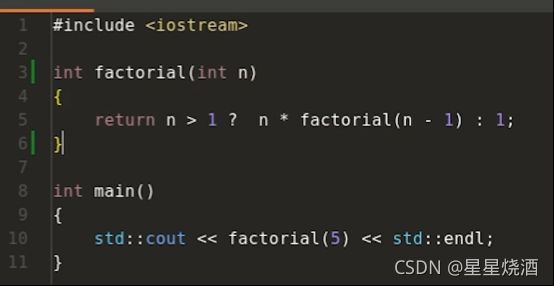

把上述表达式转换成lambda表达式(使用lambda表达式来实现递归):
int main() {
auto factorial = [](int n){
//lambda表达式里面再定义一个lambda表达式:接收一个int n,一个impl(一个参数)
auto f_impl = [](int n ,const auto & impl)->int // 注意,写递归时候一定要显式给出返回类型(->int:f_impl会返回int型整数)
{
return n>1 ? n * impl(n-1,impl) : 1;
};
return f_impl(n,f_impl);
};
}

编译器并不需要知道factorial、f_impl的类型,故使用auto不会出现无法确定factorial、f_impl的返回类型这种trick。
5 泛型算法的改进——ranges
5.1 可以使用容器而非迭代器作为输入
通过 std::ranges::dangling 避免返回无效的迭代器