hive的安装配置及使用
hive需要MySQL和hadoop的支持
文章目录
- hive需要MySQL和hadoop的支持
-
- 安装完毕MySQL之后下载并解压hive
- 添加系统环境变量
- 配置hive
- 修改 vim hive-env.sh
- 修改hive-site.xml(1、简化配置(推荐))
- 修改hive-site.xml(2、在简化的基础上添加了部分配置)
- 下载一个mysql的连接包,然后移动到`hive/lib/`中(编写java连接mysql的那个jar包)
- hive第一次启动需要进入hive下初始化(hive/bin)
- 由于我的初始化过,所以这次初始化失败了,(初始化只能在第一次使用前,并且只需要执行一次)
- 启动mysql,hadoop集群,然后直接输入hive,就可以启动hive了
- 实验3
-
- 数据集:
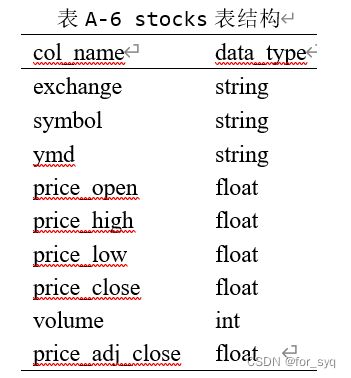
- (1)创建一个内部表stocks,字段分隔符为英文逗号,表结构如表A-6所示。
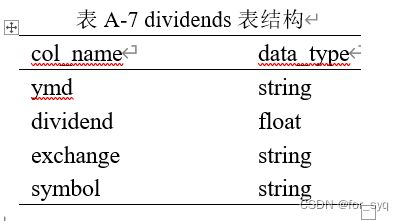
- (2)创建一个外部分区表dividends(分区字段为exchange和symbol),字段分隔符为英文逗号,表结构如表A-7所示。
- (3)从stocks.csv文件向stocks表中导入数据。
- (4) 创建一个未分区的外部表dividends_unpartitioned,并从dividends.csv向其中导入数据,表结构如表A-8所示。
- (5)通过对dividends_unpartitioned的查询语句,利用Hive自动分区特性向分区表dividends各个分区中插入对应数据。
- (6)查询IBM公司(symbol=IBM)从2000年起所有支付股息的交易日(dividends表中有对应记录)的收盘价(price_close)。
- (7)查询苹果公司(symbol=AAPL)2008年10月每个交易日的涨跌情况,涨显示rise,跌显示fall,不变显示unchange。
- (8)查询stocks表中收盘价(price_close)比开盘价(price_open)高得最多的那条记录的交易所(exchange)、股票代码(symbol)、日期(ymd)、收盘价、开盘价及二者差价。
- (9)从stocks表中查询苹果公司(symbol=AAPL)年平均调整后收盘价(price_adj_close) 大于50美元的年份及年平均调整后收盘价。
- (10)查询每年年平均调整后收盘价(price_adj_close)前三名的公司的股票代码及年平均调整后收盘价。
MySQL的安装请参考: llinux系统下面安装mysql 5.7.27 (1分钟可安装完毕)
安装完毕mysql了可以将mysql设置为开机自启,不然每次启动hive前都得启动mysql,(先启动mysql,然后hadoop,最后才是hive)
mysql开机自启:
systemctl enable mysqld
安装完毕MySQL之后下载并解压hive
tar -zxvf apache-hive-2.3.6-bin.tar.gz
mv apache-hive-2.3.6-bin hive
cd hive/conf
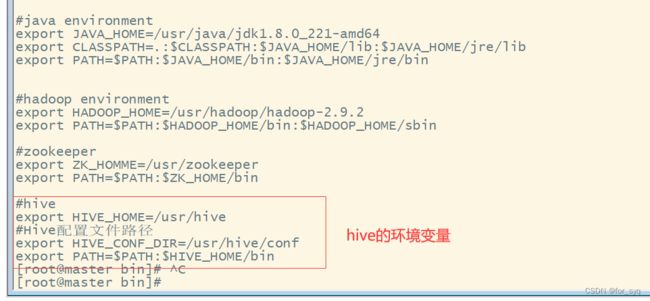
添加系统环境变量
#hive
export HIVE_HOME=/usr/hive
#Hive配置文件路径
export HIVE_CONF_DIR=/usr/hive/conf
export PATH=$PATH:$HIVE_HOME/bin
配置hive
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
cp hive-log4j2.properties.template hive-log4j2.properties
cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
修改 vim hive-env.sh
#Java路径
export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64
#Hadoop安装路径
export HADOOP_HOME=/usr/hadoop/hadoop-2.9.2
#Hive安装路径
export HIVE_HOME=/usr/hive
#Hive配置文件路径
export HIVE_CONF_DIR=/usr/hive/conf
# hive存放外部jar包的位置
export HIVE_AUX_JARS_PATH=/usr/hive/bin
修改hive-site.xml(1、简化配置(推荐))
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
//所连接的MySQL数据库实例 hive这个数据库将会在初始化hive的时候创建,当然也可以改为其他名称
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
//连接的MySQL数据库驱动
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
//连接的MySQL数据库用户名
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
//连接的MySQL数据库密码
<value>root</value>
</property>
</configuration>
修改hive-site.xml(2、在简化的基础上添加了部分配置)
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- Exception in thread "main" java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI -->
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<!-- Relative path in absolute URI: ${system:user.name%7D -->
<!-- 去掉system: -->
/usr/hive/tmp/${user.name} </value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/usr/hive/tmp/${hive.session.id}_resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/usr/hive/warehouse</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/usr/hive/logs/${user.name}</value>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<!-- Relative path in absolute URI: ${system:user.name%7D -->
<!-- 去掉system: -->
/usr/hive/logs/${user.name} /operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>
<!-- 配置 MySQL 数据库连接信息 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value><!-- 指定mysql用户名 -->
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value><!-- 指定mysql密码 -->
</property>
</configuration>
下载一个mysql的连接包,然后移动到hive/lib/中(编写java连接mysql的那个jar包)

hive第一次启动需要进入hive下初始化(hive/bin)
schematool -dbType mysql derby -initSchema
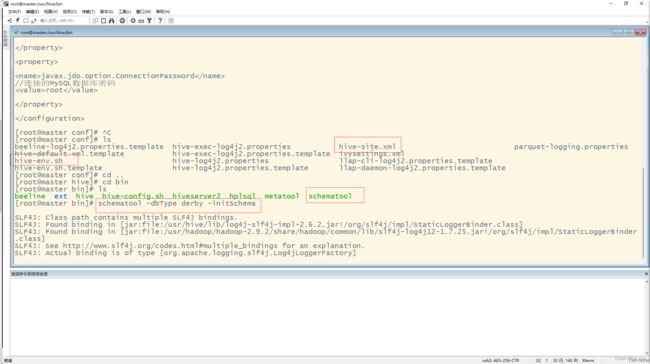
由于我的初始化过,所以这次初始化失败了,(初始化只能在第一次使用前,并且只需要执行一次)
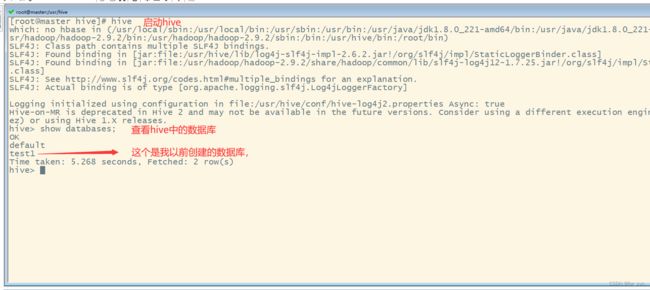
启动mysql,hadoop集群,然后直接输入hive,就可以启动hive了
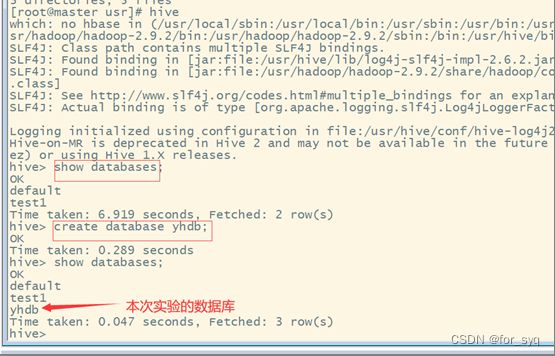
实验3
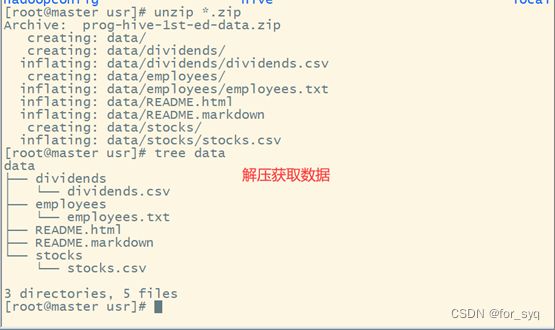
数据集:
数据获取地址:https://www.cocobolo.top/FileServer/prog-hive-1st-ed-data.zip
解压后可以得到本实验所需的stocks.csv和dividends.csv两个文件。
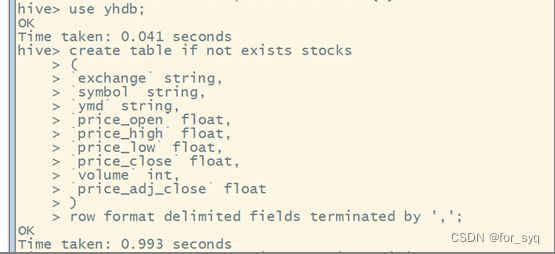
(1)创建一个内部表stocks,字段分隔符为英文逗号,表结构如表A-6所示。
创建表的语句如下:
create table if not exists stocks
(
`exchange` string,
`symbol` string,
`ymd` string,
`price_open` float,
`price_high` float,
`price_low` float,
`price_close` float,
`volume` int,
`price_adj_close` float
)
row format delimited fields terminated by ',';
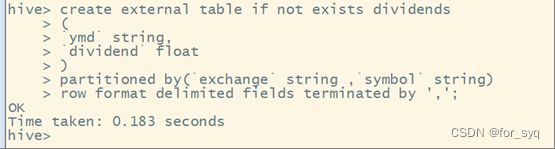
(2)创建一个外部分区表dividends(分区字段为exchange和symbol),字段分隔符为英文逗号,表结构如表A-7所示。
create external table if not exists dividends
(
`ymd` string,
`dividend` float
)
partitioned by(`exchange` string ,`symbol` string)
row format delimited fields terminated by ',';
(3)从stocks.csv文件向stocks表中导入数据。
操作语句如下:
load data local inpath '/usr/data/stocks/stocks.csv' overwrite into table stocks;

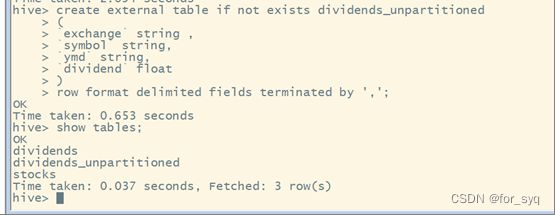
(4) 创建一个未分区的外部表dividends_unpartitioned,并从dividends.csv向其中导入数据,表结构如表A-8所示。
create external table if not exists dividends_unpartitioned
(
`exchange` string ,
`symbol` string,
`ymd` string,
`dividend` float
)
row format delimited fields terminated by ',';
导入数据
load data local inpath '/usr/data/dividends/dividends.csv' overwrite into table dividends_unpartitioned;

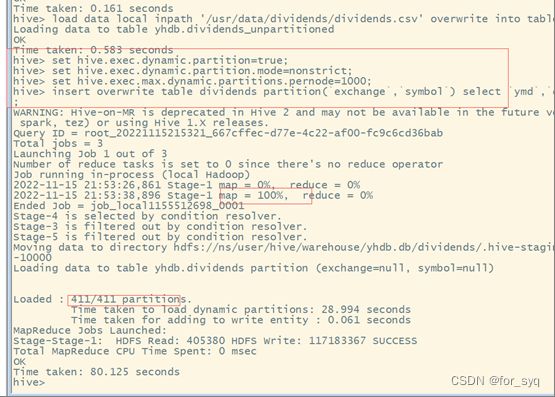
(5)通过对dividends_unpartitioned的查询语句,利用Hive自动分区特性向分区表dividends各个分区中插入对应数据。
操作语句如下:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=1000;
insert overwrite table dividends partition(`exchange`,`symbol`) select `ymd`,`dividend`,`exchange`,`symbol` from dividends_unpartitioned;
(6)查询IBM公司(symbol=IBM)从2000年起所有支付股息的交易日(dividends表中有对应记录)的收盘价(price_close)。
select s.ymd,s.symbol,s.price_close
from stocks s
LEFT SEMI JOIN
dividends d
ON s.ymd=d.ymd and s.symbol=d.symbol
where s.symbol='IBM' and year(ymd)>=2000;
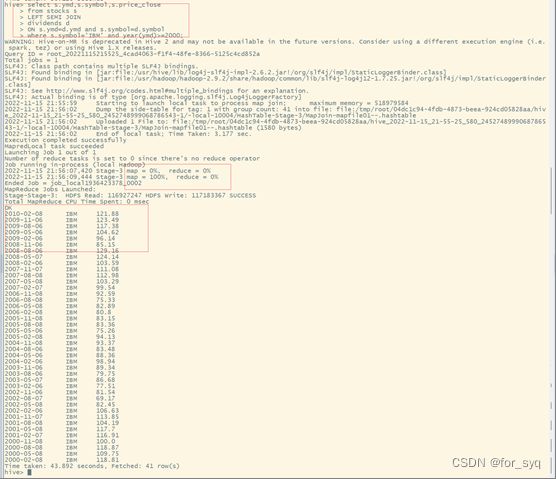
(7)查询苹果公司(symbol=AAPL)2008年10月每个交易日的涨跌情况,涨显示rise,跌显示fall,不变显示unchange。
select ymd,
case
when price_close-price_open>0 then 'rise'
when price_close-price_open<0 then 'fall'
else 'unchanged'
end as situation
from stocks
where symbol='AAPL' and substring(ymd,0,7)='2008-10';
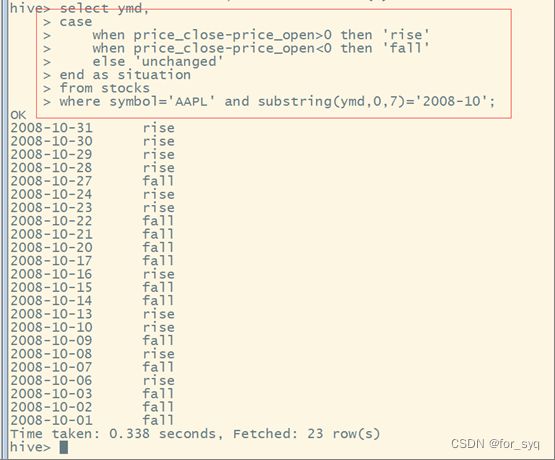
(8)查询stocks表中收盘价(price_close)比开盘价(price_open)高得最多的那条记录的交易所(exchange)、股票代码(symbol)、日期(ymd)、收盘价、开盘价及二者差价。
select `exchange`,symbol,ymd,price_close-price_open as `diff`
from
(
select *
from stocks
order by price_close-price_open desc
limit 1
)t;
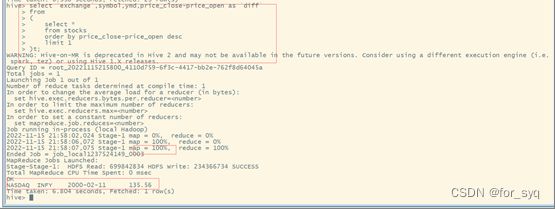
(9)从stocks表中查询苹果公司(symbol=AAPL)年平均调整后收盘价(price_adj_close) 大于50美元的年份及年平均调整后收盘价。
select
year(ymd) as `year`,
avg(price_adj_close) as avg_price from stocks
where `exchange`='NASDAQ' and symbol='AAPL'
group by year(ymd)
having avg_price > 50;
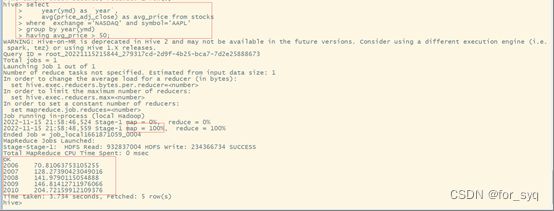
(10)查询每年年平均调整后收盘价(price_adj_close)前三名的公司的股票代码及年平均调整后收盘价。
select t2.`year`,symbol,t2.avg_price
from
(
select
*,row_number() over(partition by t1.`year` order by t1.avg_price desc) as `rank`
from
(
select
year(ymd) as `year`,
symbol,
avg(price_adj_close) as avg_price
from stocks
group by year(ymd),symbol
)t1
)t2
where t2.`rank`<=3;
