【网络原理】 (1) (应用层 传输层 UDP协议 TCP协议 TCP协议段格式 TCP内部工作机制 确认应答 超时重传 连接管理)
文章目录
- 应用层
- 传输层
-
- UDP协议
- TCP协议
-
- TCP协议段格式
- TCP内部工作机制
-
- 确认应答
- 超时重传
网络原理部分我们主要学习TCP/IP协议栈这里的关键协议(TCP 和 IP),按照四层分别介绍.(物理层,我们不涉及).
应用层
我们需要学会自定义一个应用层协议.
自定义协议的原因?
当前的软件(应用程序)要解决的业务场景是错综复杂的,业务复杂,使用程序来解决这个复杂的业务,程序也就复杂了.因此很难有一个通用的协议满足所有的业务需求.
怎样去进行自定义协议?
- 结合需求,分析清楚,请求响应(客户端/服务器之间)要传递哪些信息.
- 明确传递的信息以什么样的格式来组织.约定好具体格式内容后,客户端就能够按照这个格式构造数据并发送,服务器按照这个格式解析处理.约定的协议的内容(传递的信息)是和业务相关性特别大的.但是协议的数据组织的格式(传递格式),和业务相关性没那么大.因此针对上述这个组织数据的格式,业界一些大佬发明了一些比较通用的的数据格式.
(1)XML:标签化的数据组织方式,使用标签来表示键值对,以及树形结构.

(2) json:最初是出自于 js这个语言.格式比XML简单明了一些.

上述xml和json都是按照文本的方式来组织的.优点,可读性好,用户不需要借助其他工具,肉眼就能看懂数据的含义.缺点,效率不高,尤其是占用较多的网络带宽.xml中要额外传很多标签,json中要传很多的key.对应服务器来说,网络带宽是很贵的硬件资源.于是就有了下面的方式.
(3)protobuf(谷歌)它是一种二进制的表示数据的方式,针对对上述数据信息,通过二进制的方式进行压缩表示.特定:肉眼观察不了(二进制,直接用记事本打开是乱码)但是占用空间小了,传输的带宽也就降低了.
传输层
传输层虽然是操作系统内核已经实现好了,但是我们需要调用系统的socket api完成网络编程的。socket就是属于传输层的部分。
端口号
端口号起到效果就是区分一个主机上具体的应用程序的。因此我们要求在同一个主机上,一个端口号不能被多个进程绑定。
端口号是传输层协议的概念,TCP和UDP协议报头中都会包含 源端口和目的端口。TCP和UDP都是使用2个字节,16个bit位来表示的.即一个端口号的取值范围:0-65535.但是我们自己写程序绑定的端口,得从1024起,因为0-1023这个范围的端口称为"知名端口号/具体端口号",这些端口号是属于已经分配给一些知名的广泛使用的应用程序了.

UDP协议
基本特点:无连接,不可靠,面向数据报,全双工.
UDP协议报文结构:
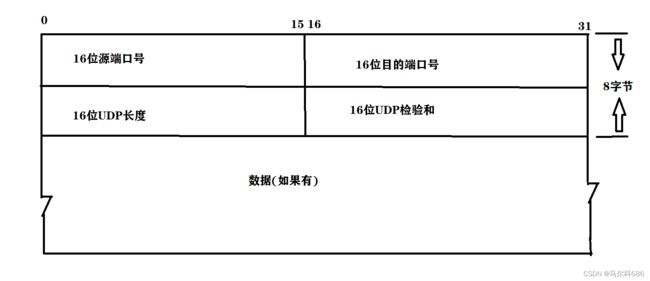

UDP就会把载荷数据(就是通过UDPsocket,也就是send方法拿来的数据,基础上再在前面拼装上几个字节的报头).
UDP报头里就包含了一些特定的属性,也就携带了一些重要的信息.不同的协议,功能不同,报头中带有的属性信息就不同,对于UDP来说报头一共就是8个字节,分为四个部分(每个部分2个字节).
一次网络通信,设计到五元组:源IP ,源端口,目的IP ,目的端口 ,协议类型.
UDP报文长度也是2个字节表示的,2个字节的表示范围:0->65535,换算单位64KB.一共UDP数据报最大只能传输64KB的数据.
如果应用层数据报超过64KB了怎么办?
- 在应用层通过代码的方式针对应用层数据报进行手动分包,拆成多个包通过多个UDP数据报进行传输.(本来send一次,现在需要send多次了)
- 不用UDP,缓存TCP(TCP没有这样的限制)
校验和:是验证传输的数据是否是正确的.
在网络传输过程中,可能会受到一些干扰,在这些干扰下就可能出现"比特翻转"的情况(1变0,0变1)一旦数据变了,对于数据的含义可能就是致命的,程序中经常使用1表示某个功能开始,0表示某个功能关闭,本来网络数据报是想开启功能,结果因为翻转,导致变成了关闭.因此引入了校验和来进行鉴别.
校验和:针对数据内容进行一系列的数学运算,得到一个比较短的结果(如2字节),如果数据内容一定,得到的校验和的结果就一定,数据变了,校验和也就变了.

针对网络传输的数据来说,生成校验和的算法有很多,比如:
- CRC:循环冗余校验,把数据的每个字节循环网上累加.如果累加移除了,高位就不要了.好算,但是校验效果不是特别理想.万一数据同时变了两个bit位(前一个字节少1,后一个字节多1),就会出现内容变了,CRC没变的情况.
- MD5:本质是用一系列公式来进行更复杂的数学运算.MD5算法特点:(1)定长:无论原始数据多长,得到的MD5都是固定长度.(4字节版本和8字节版本)(2)冲突概率小,原始数据哪怕只变动一个地方,算出来的MD5值都会差别很大.(让MD5结果更分散了)(3)不可逆,通过原始数据计算MD5很容易,通过MD5还原成原始数据很难,理论上是不可实现的.
- SHA1
TCP协议
TCP协议相比于UDP复杂不少,它是有连接,可靠传输,面向字节流,全双工.
TCP协议段格式
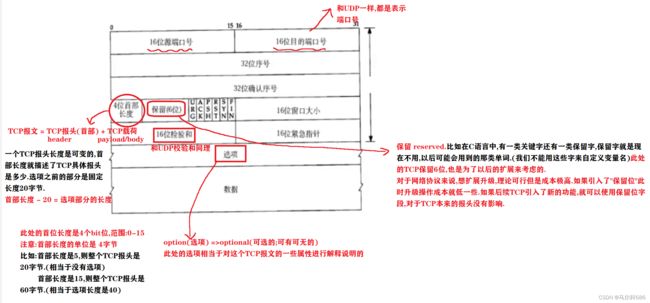
TCP内部工作机制
深度理解掌握TCP提供10个核心的机制:
确认应答
TCP可靠传输,可靠并不是说发送方100%能把消息发送给接收方(毕竟网线断了是不可能发过去的).确认应答就是实现可靠传输的最核心机制.TCP进行可靠性传输,最主要就是靠的这个确认应答机制.A给B发了个消息,B收到之后就会返回一个应答报文(ACK),此时A收到应答之后,就知道了刚才发的数据已经顺利到达B了.
考虑更复杂的情况.网络中数据后发先至,两个主机之间,路线存在多条,数据报1和数据报2走的都是不同的路线…数据报1和数据报2转发路径上的路由器/交换机不一样,有的转发速率快,有的慢,此时两个数据报到达的顺序就更存在变数了.
结论:网络先发后至的这个现象是客观存在的,无法避免.因此应答报文的到达顺序也是可能发生变动的.此时就考虑如何规避这种顺序错乱带来的歧义.
如果解决上述后发先至的问题?
给传输的数据和应答报文都进行编号就可以了.当我们引入序号之后,就不怕顺序乱了.即使顺序上乱了,也可以通过序号来区分当前应答报文是针对哪个数据进行的.任何一条数据(包括应答报文)都是有序号的,确认序号则是只有应答报文有.(普通报文确认序号字段里的值无意义).这一条报文是否是应答报文,取决于ACK标志位.如果ACK这个标志位为1则是应答报文,为0就不是应答报文.

实际上TCP的序号并不是按照"一条两条"这样的方式来编号的.TCP是面向字节流的.TCP的序号也是按照字节来编号的.

TCP的字节的序号是依次累加的,这个依次累加的过程对于后一条数据来说,起始字节的序号就是上一个数据的最后一个字节的序号.每个TCP数据报报头填写的序号只需要写TCP数据的头一个字节的序号即可.TCP知道了头一个字节的序号,再根据TCP报文长度,就很容易知道每个字节的序号.
确认序号的取值是收到的数据的最后一个字节的序号+1.
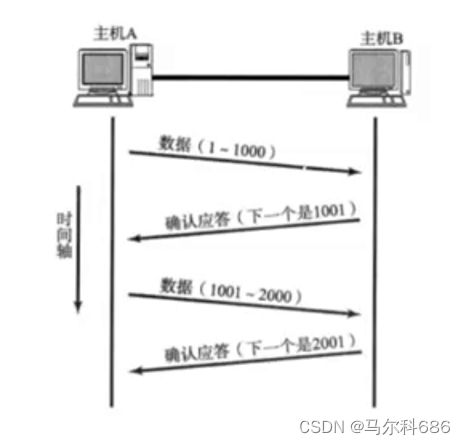
小结:TCP可靠传输能力,最主要是通过确认应答机制来保证的.通过应答报文,就可以让发送方清楚的知道传输是否成功.进一步的引入了序号和确认序号,针对多组数据进行详细的区分.
超时重传
超时重传:超过一定时间,还没响应,就重新传输.
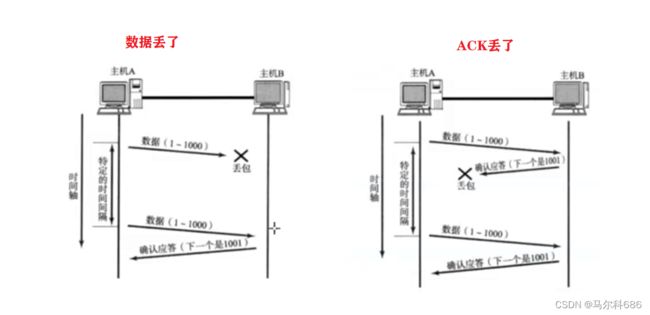
我们在讨论确认应答的时候,只是讨论了顺利传输的情况.如果丢包了,我们还得再来考虑.
丢包涉及到两种情况:
- 发的数据丢了;
- 返回的ack丢了.
发送方看到的结果就是没有收到ack,区分不了是哪种情况,所以上面的两种情况会一视同仁,都认为是丢包了.此时TCP没有躺平,还是要尽力挽救一下的.(丢包是一个概率性时间,通常情况下丢包的概率是比较小的,因此如果重新发一下这个数据报,其实还是有很大的概率成功传输的).
TCP就引入了重传机制,在丢包的时候,就重新再发一次同样的数据.但是我们还是要区分到底是丢包了,还是ack走的满,在路上呢?此时TCP直接引入了一个时间阈值.发送方发了一个数据之后,就会等待ACK,此时开始计时.如果在时间阈值之内也没有收到ACK,那么就不管ACK是在路上,还是彻底丢了,都视为丢包了.
TCP对于这种重复数据的传输是有特殊处理,去重.TCP存在一个"接收缓冲区"这样的存储空间(接收方操作系统内核里的一段内存).每个TCP的socket对象,都有一个接收缓冲区(也有一个发送缓冲区).主机B收到主机A的数据,是B的网卡读到数据了,然后把这个数据放到B的对应socket的接收缓冲区中,后续应用程序使用getInputStream进一步的使用read,就是从接收缓冲区来读数据.(根据数据的序号,TCP很容易识别当前接收缓冲区里的这两条数据是否重复.如果重复就把后来的这份数据丢弃.保证应用程序调用read读取到的数据一定是不重复的).
小结:由于去重和重新排序机制的存在,发送方只要发现ACK没有按时到达,就会重传数据.即使重复了,即使数据乱了,都没事,接收方都能很好的处理.(去重和排序都依赖TCP报头的序号).
站在数学角度看多次重传丢包的情况:假设一次传输丢包概率是10%,传输成功的概率是90%,如果第一次传输丢包了,第二次重传也丢包了,概率是10%*10% = 1%,三次都丢了的概率是0.1%,连续重传都丢包,此时的概率原则上讲,是非常低的.如果这个情况真的出现了,只能说明此时丢包的概率远远不止10%,即当前网络出现重大故障.因此当重传到一定次数的时候,就不会再继续重传了,此时会认为是网络出现故障.接下来TCP会尝试重置连接(相当于断开重连),如果重置还是失败,就彻底断开连接了.
小结:可靠传输是TCP最核心的部分,TCP的可靠传输就是通过确认应答 + 超时重传 来体现的,其中确认应答描述的是传输顺利的情况,超时重传描述的是传输出现问题的情况.这两者相互配合,共同支撑整体的TCP可靠性.