【使用深度学习的城市声音分类】使用从提取音频特征(频谱图)中提取的深度学习进行声音分类研究(Matlab代码实现)
欢迎来到本博客❤️❤️
博主优势:博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
本文目录如下:
目录
1 概述
2 运行结果
3 参考文献
4 Matlab代码实现

1 概述
使用深度学习进行城市声音分类是一种常见的研究方向。下面是一个基本的步骤,通过从音频特征(频谱图)中提取特征,应用深度学习进行声音分类:
1. 数据收集和准备:收集包含城市环境下不同声音的音频数据集。可以通过麦克风或其他录音设备在不同城市环境中进行采集,确保数据集中包含各种声音类别,如车辆噪音、人声、自然声等。将音频数据进行预处理,如剪辑、采样率调整、去噪等。
2. 音频特征提取:使用音频处理技术从音频数据中提取有代表性的特征。常用的方法是将音频数据转化为频谱图,如使用短时傅里叶变换(STFT)生成音频的时频谱图。其他特征提取方法还包括Mel频谱系数(MFCC),音频能量等。这些特征将作为深度学习模型的输入。
3. 构建深度学习模型:选择适合音频分类的深度学习模型,例如卷积神经网络(CNN)、长短时记忆网络(LSTM)或变换器网络(Transformer)。通过建立模型架构,将频谱图等音频特征输入模型,并输出对应的声音类别概率分布。
4. 数据集划分和训练:将数据集划分为训练集和测试集。使用预处理的音频特征作为输入,利用训练集对深度学习模型进行训练。通过反向传播和优化算法,调整模型参数以提高分类准确率。使用验证集进行模型的调参和选择最佳模型。
5. 模型评估和改进:使用测试集对训练好的深度学习模型进行评估。计算准确率、召回率、F1分数等指标,评估模型的性能。如果模型性能不理想,可以尝试调整超参数、修改模型架构或增加更多的训练数据。
6. 模型应用和部署:使用训练好的深度学习模型进行城市声音的实时或离线分类。将音频数据转化为频谱图或其他特征,并将其输入到训练好的模型中,得到对应的声音类别。
通过上述步骤,你可以使用从音频特征中提取的深度学习模型进行城市声音分类的研究。这种方法在城市环境监测、噪音控制等领域具有潜在的应用价值。
该数据集包含来自 8732 个类的 4 个城市声音摘录 (<=10s),它们是:
- 空调
- 汽车喇叭
- 儿童玩耍
- 狗吠
- 钻探
- 发动机怠速
- 枪声
- 手提钻
- 警笛
- 街头音乐
随附的元数据包含每个声音摘录的唯一 ID 及其给定的类名。
此数据集的示例包含在随附的 git 存储库中,可以从 https://urbansounddataset.weebly.com/urbansound8k.html 下载完整的数据集。
音频示例文件数据概述
这些声音摘录是.wav格式的数字音频文件。
声波通过以称为采样率的离散间隔采样来数字化(CD质量音频通常为44.1kHz,这意味着每秒采集44,100次样本)。
每个样本是特定时间间隔的波的振幅,其中位深度决定了样本的详细程度,也称为信号的动态范围(通常为 16 位,这意味着样本的范围可以是 65,536 个振幅值)。
深度学习工作流程
访问数据 -> 预处理 -> 提取信号特征(频谱图) -> 训练神经网络 -> 部署(可选)。
2 运行结果
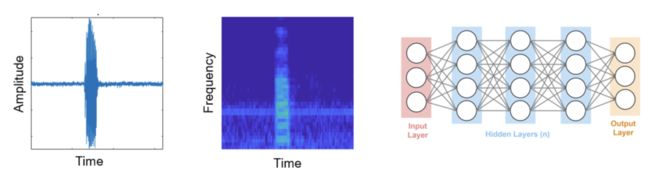
预处理音频数据并提取频谱图特征。
将音频信号转换为频谱图,采样时间为fs,并将频谱图保存为原始音频文件目录。
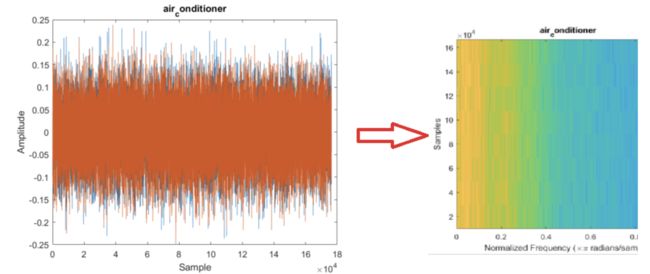
从已提取的频谱图数据中,我们将创建用于训练和分类的简单神经网络。图像存储在频谱图文件夹中。每个类的数据在子文件夹中分开,由文件夹名称标记。
拆分数据,使 80% 的图像用于训练,10% 用于验证,其余用于测试。在我有限的时间内,我只使用了整个数据集的 25% 进行训练。
训练准确率为:92%,如下图所示:

测试的准确率为:91%,混淆矩阵如下: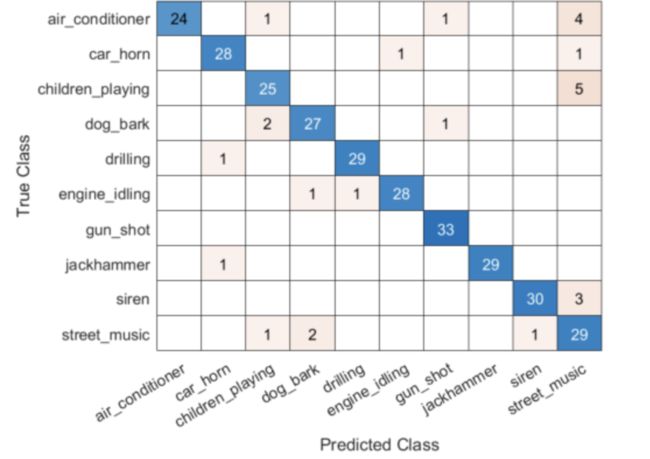
3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]陈蕴博,李海军.卷积神经网络在城市声音分类中的应用研究[J].德州学院学报,2022,38(04):25-28.
[2]陈波,俞轶颖.基于深度神经网络的城市声音分类模型研究[J].浙江工业大学学报,2019,47(02):199-203.
[3]孙陈影,沈希忠.LSTM和GRU在城市声音分类中的应用[J].应用技术学报,2020,20(02):158-164.