openGauss数据库-SQL引擎之查询解析
文章目录
-
- 一、SQL引擎
- 二、查询解析
-
- 1、词法分析
- 2、语法分析
- 3、语义分析
一、SQL引擎
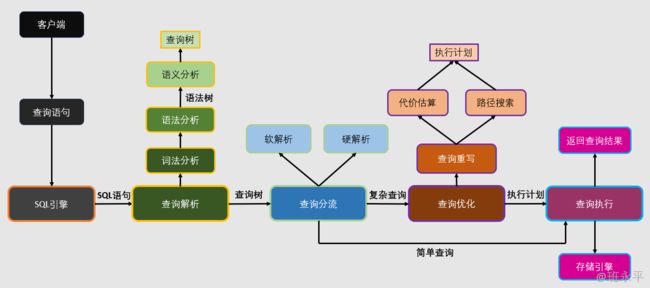
SQL引擎作为 openGauss 数据库的核心模块之一,起到了承上启下的作用,上接客户端应用程序的SQL语句,并返回查询结果, 下接执行器,指挥执行器运行执行计划。SQL 引擎包括查询解析、查询分流、查询优化、查询执行
-
SQL 引擎中查询解析作为第一个接触到 SQL 语句的模块,主要负责将 SQL语句转换为查询树,即逻辑执行计划,以便于后续进行查询优化与执行。
-
SQL 引擎中查询分流负责将简单查询与复杂查询分流,是提高数据库性能的第一步基本操作。
-
SQL 引擎中查询优化负责对查询计划进行优化,其优化器产生的执行计划的优劣直接决定了数据库的性能。
-
SQL 引擎中查询执行负责严格执行优化器给予的计划,听从优化器的指挥,从存储空间中读取数据并进行加工处理最终返回给客户端。
openGauss 中 SQL引擎总流程图如下:
二、查询解析
SQL语句 openGauss 的编译过程符合编译器实现的常规过程,需要进行词法分析、语法分析和语义分析,最终生成查询树。
查询解析流程图如下:

1、词法分析
从查询语句中识别出系统支持的关键字、标识符、运算符、终结符等,确定每个词固有的词性。
openGauss 采用 flex 工具来完成词法分析的主要工作。对于用户输入的每个 SQL 语句,它首先交由 flex 工具进行词法分析。flex 工具通过对已经定义好的词法文件进行编译,生成词法分析的代码。
openGauss中的词法文件是 scan.l,它根据SQL语言标准对SQL语言中的关键字、标识符、操作符、常量、终结符等进行了定义和识别。代码如下:
/* 定义 SQL 运算操作符 */
op_chars [\~\!\@\#\^\&\|\`\?\+\-\*\/\%\<\>\=]
operator {op_chars}+
/* 定义 openGauss 支持的数值类型 */
integer {digit}+
decimal (({digit}*\.{digit}+)|({digit}+\.{digit}*))
decimalfail {digit}+\.\.
real ({integer}|{decimal})[Ee][-+]?{digit}+
realfail1 ({integer}|{decimal})[Ee]
realfail2 ({integer}|{decimal})[Ee][-+]
词法分析将一个SQL划分成多个不同的 token,每个 token 都有自己的词性,如关键词、标识符、操作符、常量,并通过 kwlookup.cpp 二分查找优先处理关键词,代码如下:
/*
* 使用普通的 strcmp() 比较进行二分搜索。
*/
low = keywords;
high = keywords + (num_keywords - 1);
while (low <= high) { /* 二分搜索 */
const ScanKeyword* middle = NULL;
int difference;
middle = low + (high - low) / 2; /* 取关键词中值 */
difference => strcmp(middle-name, word);
if (difference == 0) { /* 找到则返回 middle */
return middle;
} else if (difference < 0) {
low = middle + 1;
} else {
high = middle - 1;
}
}
return NULL; /* 未找到则返回空值,说明该文本中不含关键词 */
词法分析得到的 token 将被传入语法分析进行下一步解析。
2、语法分析
在完成词法分析后,需要进行语法分析,语法分析根据词法分析获得的词(token)来匹配语法规则,最终生成一个抽象语法树,每个词作为语法树的叶子节点出现。根据SQL的标准定义语法规则,使用词法分析中产生的词去匹配语法规则,如果一个 SQL 语句能够匹配一个语法规则,则生成对应的抽象语法树。
在 openGauss 中采用了 bison 工具来完成语法分析的主要工作,并定义了 bison 工具能够识别的语法文件 gram.y,在 Makefile 中通过 bison 工具对 gram.y 进行编译,最终生成 gram.cpp 文件。
在 openGauss 中,为了保存语法分析的结果,根据 SQL 语言的不用性质定义了一系列记录状态的结构体,通常以 Stmt 为后缀,如 Insert 语句对应的 Statement 结构体如下:
typedef struct InsertStmt {
NodeTag type;
RangeVar *relation; /* 记录要插入的关系 */
List *cols; /* 可选,目标列的名称 */
Node *selectStmt; /* 源 SELECT/VALUES 或 NULL */
List *returningList; /* 要返回的表达式列表 */
WithClause *withClause; /* WITH 子句 */
UpsertClause *upsertClause; /* DUPLICATE KEY UPDATE 子句,作用:当insert已经存在的记录时,就执行update*/
HintState *hintState;
bool isRewritten; /* 记录这个 Stmt 是由重写者还是最终用户创建的 */
} InsertStmt;
在完成词法分析和语法分析后,raw_parser函数会将所有的语法分析树封装为一个 List 结构,raw_parse_tree_list(即语法树链表),List 中的每个 ListCell 包含一个语法树,并返回给exec_simple_query函数,进入语义分析开始下一步解析。
3、语义分析
在完成词法分析和语法分析后,需要进行语义分析,处理语法分析生成的抽象语法树,以检查 SQL 命令是否符合语义规定,能否正确执行。负责语义分析的是位于 analyze.cpp 下的 parse_analyze 函数。parse_analyze 会根据词法分析和语法分析得到的语法树,生成一个 ParseState 结构体用于记录语义分析的状态。ParseState 顾名思义-解析状态,保存了语义分析的状态信息,ParseState 结构体定义如下:
struct ParseState {
struct ParseState* parentParseState; /* 指向外层查询 */
const char* p_sourcetext; /* 原始SQL命令 */
List* p_rtable; /* 范围表 */
List* p_joinexprs; /* 连接表达式 */
List* p_joinlist; /* 连接项 */
List* p_relnamespace; /* 表名集合 */
List* p_varnamespace; /* 属性名集合 */
bool p_lateral_active;
List* p_ctenamespace; /* 公共表达式名集合 */
List* p_future_ctes; /* 不在p_ctenamespace中的公共表达式 */
CommonTableExpr* p_parent_cte;
List* p_windowdefs; /* WINDOW子句的原始定义 */
int p_next_resno; /* 下一个分配给目标属性的资源号 */
List* p_locking_clause; /* 原始的FOR UPDATE/FOR SHARE信息 */
Node* p_value_substitute;
bool p_hasAggs; /* 是否有聚集函数 */
bool p_hasWindowFuncs; /* 是否有窗口函数 */
bool p_hasSubLinks; /* 是否有子链接 */
bool p_hasModifyingCTE;
bool p_is_insert; /* 是否为INSERT语句 */
bool p_locked_from_parent;
bool p_resolve_unknowns;
bool p_hasSynonyms;
Relation p_target_relation; /* 目标表 */
RangeTblEntry* p_target_rangetblentry; /* 目标表在RangeTable对应的项 */
......
};
然后调用 transformStmt 函数,transformStmt 函数根据 NodeTag 的值,将语法树转化为不同的 Stmt 结构体,并调用对应的语义分析函数进行处理,例如通过 transformWhereClause 函数处理 where 子句,并将 ParseState 中的 p_joinlist 链表指针以及处理 where 子句得到的表达式树包装成 FromExpr 结构体,存入 **Query 结构体(查询树)**的 jointree。transformStmt 函数代码如下:
/* 递归地将解析树转换为查询树 */
Query* transformStmt(ParseState* pstate, Node* parseTree, bool isFirstNode, bool isCreateView)
{
Query* result = NULL;
/* 根据不同的命令类型进行相应的处理,最后生成查询树 */
switch (nodeTag(parseTree)) {
/* 可优化语句 */
/* 插入语句 */
case T_InsertStmt:
result = transformInsertStmt(pstate, (InsertStmt*)parseTree);
break;
/* 删除语句 */
case T_DeleteStmt:
result = transformDeleteStmt(pstate, (DeleteStmt*)parseTree);
break;
/* 更新语句 */
case T_UpdateStmt:
result = transformUpdateStmt(pstate, (UpdateStmt*)parseTree);
break;
/* 合并语句 */
case T_MergeStmt:
result = transformMergeStmt(pstate, (MergeStmt*)parseTree);
break;
/* 选择语句 */
case T_SelectStmt: {
SelectStmt* n = (SelectStmt*)parseTree;
if (n->valuesLists)
result = transformValuesClause(pstate, n);
else if (n->op == SETOP_NONE)
result = transformSelectStmt(pstate, n, isFirstNode, isCreateView);
else
result = transformSetOperationStmt(pstate, n);
} break;
/* 特别情况 */
/* 游标 */
case T_DeclareCursorStmt:
result = transformDeclareCursorStmt(pstate, (DeclareCursorStmt*)parseTree);
break;
/* 查询分析语句 */
case T_ExplainStmt:
result = transformExplainStmt(pstate, (ExplainStmt*)parseTree);
break;
/* 宏定义 若为分布式架构 */
#ifdef PGXC
case T_ExecDirectStmt:
result = transformExecDirectStmt(pstate, (ExecDirectStmt*)parseTree);
break;
#endif
/* 建表语句 */
case T_CreateTableAsStmt:
result = transformCreateTableAsStmt(pstate, (CreateTableAsStmt*)parseTree);
break;
default:
/* 其他不需要转换的语句;只需返回原始解析树,包含有 Query 节点 */
result = makeNode(Query);
result->commandType = CMD_UTILITY;
result->utilityStmt = (Node*)parseTree;
break;
}
/* 标记为原始查询 */
result->querySource = QSRC_ORIGINAL;
result->canSetTag = true;
/* 标记同义词对象是否在 rtables 中 */
result->hasSynonyms = pstate->p_hasSynonyms;
/* 返回查询树 */
return result;
}
transformWhereClause 函数代码如下:
Node* transformWhereClause(ParseState* pstate, Node* clause, const char* constructName)
{
Node* qual = NULL;
if (clause == NULL) {
return NULL;
}
/* 将分析树 SelectStmt 下 whereClause 字段表示的 WHERE 子句转换为一颗表达式树 */
qual = transformExpr(pstate, clause);
/* 将返回结果强转为 bool 类型 */
qual = coerce_to_boolean(pstate, qual, constructName);
return qual;
}
FromExpr 结构体定义如下:
typedef struct FromExpr{
NodeTag type;
List* fromlist; /* 子连接链表 */
Node* quals; /* 表达式树 */
} FromExpr;
transformStmt函数完成语义分析后会返回查询树。一个完整的SQL语句中的每个子句的语义分析结果保存在Query 结构体的对应字段中,**Query 结构体(查询树)**定义如下:
typedef struct Query {
NodeTag type; /* NodeTag,记录Stmt类型 */
CmdType commandType; /* 命令类型 */
QuerySource querySource; /* 查询来源 */
uint64 queryId; /* 查询树的标识符 */
bool canSetTag; /* 原始查询,为false;查询重写或者查询规划新增,为true */
Node* utilityStmt; /* 定义游标或者不可优化的查询语句 */
int resultRelation; /* 结果关系 */
bool hasAggs; /* 目标属性或HAVING子句中是否有聚集函数 */
bool hasWindowFuncs; /* 目标属性中是否有窗口函数 */
bool hasSubLinks; /* 是否有子查询 */
bool hasDistinctOn; /* 是否有DISTINCT子句 */
bool hasRecursive; /* 公共表达式是否允许递归 */
bool hasModifyingCTE; /* WITH子句是否包含INSERT/UPDATE/DELETE */
bool hasForUpdate; /* 是否有FOR UPDATE或FOR SHARE子句 */
bool hasRowSecurity; /* 重写是否应用行级访问控制 */
bool hasSynonyms; /* 范围表是否有同义词 */
List* cteList; /* WITH子句,用于公共表达式 */
List* rtable; /* 范围表 */
FromExpr* jointree; /* 连接树,描述FROM和WHERE子句出现的连接 */
List* targetList; /* 目标属性 */
List* starStart; /* 对应于ParseState结构体的p_star_start */
List* starEnd; /* 对应于ParseState结构体的p_star_end */
List* starOnly; /* 对应于ParseState结构体的p_star_only */
List* returningList; /* RETURNING子句 */
List* groupClause; /* GROUP子句 */
List* groupingSets; /* 分组集 */
Node* havingQual; /* HAVING子句 */
List* windowClause; /* WINDOW子句 */
List* distinctClause; /* DISTINCT子句 */
List* sortClause; /* ORDER子句 */
Node* limitOffset; /* OFFSET子句 */
Node* limitCount; /* LIMIT子句 */
List* rowMarks; /* 行标记链表 */
Node* setOperations; /* 集合操作 */
......
} Query;
经过语义分析的处理后,最后生成查询解析树即 Query 结构体,通过语义分析的检查,抽象语法树就转换成一个逻辑执行计划。至此 SQL 引擎的查询解析过程完成,SQL引擎开始执行查询优化。