【GNN+加密流量】TFE-GNN: A Temporal Fusion Encoder Using GNN for Fine-grained Encrypted Trafic Classificat
文章目录
- 论文名称
-
- 摘要
- 存在的问题
- 论文贡献
-
- 1. 预定义
- 2. Byte-level Trafc Graph Construction(字节级流量图构造)
- 3. Dual Embedding(双重嵌入)
- 4. Trafc Graph Encoder with Cross-gated Feature Fusion(具有交叉门控特征融合的流量图编码器)
- 5. 下游任务
- 6. 模型总结
- 7. 实验
- 总结
-
- 论文内容
- 数据集
论文名称
中文题目:TFE-GNN:一种用于细粒度加密流量分类的图神经网络时间融合编码器
发表会议:WWW '23: The ACM Web Conference 2023
发表年份:2023-4-30
作者:Haozhen Zhang
latex引用:
@inproceedings{zhang2023tfe,
title={TFE-GNN: A Temporal Fusion Encoder Using Graph Neural Networks for Fine-grained Encrypted Traffic Classification},
author={Zhang, Haozhen and Yu, Le and Xiao, Xi and Li, Qing and Mercaldo, Francesco and Luo, Xiapu and Liu, Qixu},
booktitle={Proceedings of the ACM Web Conference 2023},
pages={2066--2075},
year={2023}
}
摘要
加密流量分类正受到研究人员和工业公司的广泛关注。然而,现有的方法只提取低级别特征,由于不可靠的统计属性而无法处理短流,或者平等地对待标头和有效负载,无法挖掘字节之间的潜在相关性。因此,本文提出了一种基于逐点互信息(PMI)的字节级流量图构建方法,以及一种基于图神经网络(TFE-GNN)进行特征提取的时序融合编码器模型。特别地,我们设计了双嵌入层、基于gnn的流量图编码器和交叉门控特征融合机制,该机制可以先分别嵌入头部和有效载荷字节,然后将它们融合在一起,以获得更强的特征表示。在两个真实数据集上的实验结果表明,TFE-GNN在细粒度加密流量分类任务中优于多种最先进的方法。
存在的问题
- 依赖于流量统计特征的加密流量检测方法需要手工制作特征工程,且在某些情况下可能由于不可靠/不稳定的低层统计信息而失败。较短流相比于较长流而言具有较高的偏差。因为短流的统计特征几乎没有。
- 目前大多数基于gnn的方法[1,11,21,25,29]根据数据包之间的相关性构造图,这实际上是统计特征的另一种使用形式,也存在上述问题。
- 对于那些使用数据包字节作为特征的gnn模型,也有两个主要缺点:(1)混合使用报头和有效负载。现有的方法只是简单地平等对待包的报头和有效载荷,而忽略它们之间的意义差异。(2)未充分利用原始字节。虽然利用了数据包字节,但大多数方法将数据包视为节点,只是将数据包的原始字节作为节点特征,没有充分利用数据包
论文贡献
- 首次提出了一种基于逐点互信息(PMI)的字节级流量图构建方法,通过将数据包字节序列转换为图来构建字节级流量图,从不同的角度支持流量分类。
- 提出了TFE-GNN,它分别处理数据包头和有效载荷,并将每个字节级流量图编码为每个数据包的总体表示向量。因此,TFE-GNN使用包级表示向量而不是低级别表示向量。
- 为了评估所提出的TFE-GNN的性能,我们将其与几种现有方法在自收集的WWT数据集和公共ISCX数据集上进行了比较[5,15]。结果表明,对于用户行为分类,TFE-GNN在有效性上优于这些方法。
论文解决上述问题的方法:
- 使用包字节而不是统计特征来进行特征工程
论文的任务:
分类加密流量,图级别的分类+RNN
1. 预定义
- 图结构
- G = { V , E , X } G = \{V, E, X\} G={V,E,X} : 其中 G G G 表示该图, V V V表示图中的节点, E E E表示图中的边, X X X表示节点的特征矩阵。
- A A A : G G G 的邻接矩阵, a i , j a_{i,j} ai,j 表示第 i 个和第 j个节点的连接情况。
- N ( v ) N(v) N(v):表示节点 v v v 的邻域节点
- d l d_l dl: 表示第 l l l 层的embedding嵌入维数
- T S = [ P t 1 , P t 2 , . . . , P t n ] , t 1 < = t 2 < = . . . < = t n TS = [P_{t_1},P_{t_2},...,P_{t_n}], t_1<=t_2<=...<=t_n TS=[Pt1,Pt2,...,Ptn],t1<=t2<=...<=tn,其中 P t i P_{t_i} Pti代表带有时间戳的单个数据包, n n n为流量段的序列长度, t 1 , t n t_1,t_n t1,tn分别是流量段的开始时间和结束时间。
- 加密流量分类
- M M M:训练样本数量
- N N N:流量类别数量
- b s i j = [ b 1 i j , b 2 i j , . . . , b m i j ] bs_i^j = [b_1^{ij},b_2^{ij},...,b_m^{ij}] bsij=[b1ij,b2ij,...,bmij]: m m m是字节序列长度, b k i j b_k^{ij} bkij为第i个流量样本的第j个字节序列的第k个字节的值
- s i = [ b s 1 i , b s 2 i , . . . , b s n i ] s_i = [bs_1^i,bs_2^i,...,bs_n^i] si=[bs1i,bs2i,...,bsni]: n n n为序列长度, b s j i bs_j^i bsji为第i个流量样本的第j个字节序列。这里的 s i s_i si可以看成是上面的 T S TS TS
举例:
某个 s i s_i si为[[0x01,0x02, 0x03… 0x10],[0x21,0x32, 0x73… 0x68],…,[0x55,0x65,…,0x79]], s i s_i si包含多个数据包,每个数据包用它们的字节序列来表示,其中 b s 1 i bs_1^i bs1i就是[0x01,0x02, 0x03… 0x10], b 1 i 1 b_1^{i1} b1i1就是0x01
2. Byte-level Trafc Graph Construction(字节级流量图构造)
- 节点:某一个字节,注意相同的字节值共享同一个节点,因此节点个数不会超过256,这样能够保持图在一定的规模下,不会太大。
- 字节之间的相关性表示:采用点互信息(PMI)来建模两个字节之间的相似性,字节i和字节j的相似性用 P M I ( i , j ) PMI(i,j) PMI(i,j)表示。
- 边:根据PMI值来构造边,PMI值为正:表示字节之间的语义相关性高;而PMI值为零或负值:表示字节之间的语义相关性很小或没有。因此,我们只在PMI值为正的两个字节之间创建一条边。
- 节点特征:每个节点的初始特征为字节的值,维度为1,范围为[0,255]
- 图构建:由于 P M I ( i , j ) = = P M I ( j , i ) PMI(i,j) == PMI(j,i) PMI(i,j)==PMI(j,i),因此该图是个无向图。
3. Dual Embedding(双重嵌入)
双重嵌入的必要性:字节值通常用作进一步向量嵌入的初始特征。具有不同值的两个字节对应两个不同的嵌入向量。然而,字节的含义不仅随字节值本身而变化,还随它所在的字节序列的部分而变化。换句话说,在数据包的报头和有效载荷中,具有相同值的两个字节的表示含义可能完全不同。原因是有效载荷携带数据包的传输内容,而报头是描述其内容的数据包的第一部分。如果我们使头和负载中具有相同值的两个字节对应于相同的嵌入向量,则由于含义混淆,模型很难收敛到这些嵌入参数的最优值。
根据上面提到的基本原理,分别处理数据包的报头和有效载荷,并分别为这两个部分构建字节级流量图(即,字节级流量报头图和字节级流量有效载荷图)。采用两个不共享参数的嵌入层的双嵌入,分别将初始字节值特征嵌入到两种图的高维嵌入向量中。
因此有两个嵌入矩阵:
- E h e a d e r ∈ R K × d 0 E_{header} \in R^{K \times d_0} Eheader∈RK×d0:其中K为节点个数, d 0 d_0 d0为嵌入维度
- E p a y l o a d ∈ R K × d 0 E_{payload} \in R^{K \times d_0} Epayload∈RK×d0
4. Trafc Graph Encoder with Cross-gated Feature Fusion(具有交叉门控特征融合的流量图编码器)
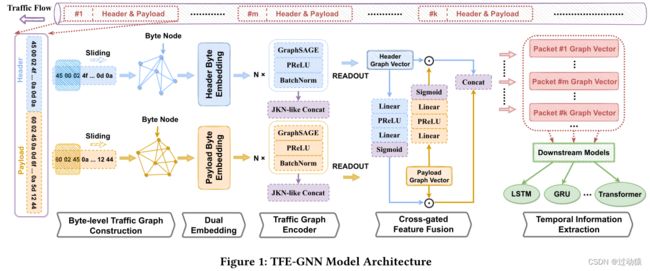
模型:4层GraphSAGE
关键点:
- 分别处理header和payload,使用不共享的参数
- 连接4层GraphSAGE的输出,作为最终的节点嵌入 h v f i n a l h_v^{final} hvfinal,具体如下: h v f i n a l = c o n c a t ( h v ( 1 ) , h v ( 2 ) , h v ( 3 ) , h v ( 4 ) ) h_v^{final} = concat(h_v^{(1)},h_v^{(2)},h_v^{(3)},h_v^{(4)}) hvfinal=concat(hv(1),hv(2),hv(3),hv(4))
- readout层使用了mean pooling,分别得到header和payload的图嵌入 g h g_h gh和 g p g_p gp,具体如下: g = h 1 f i n a l ⊕ . . . ⊕ h V f i n a l ∣ V ∣ g = \frac{h_1^{final}\oplus...\oplus h_V^{final}}{|V|} g=∣V∣h1final⊕...⊕hVfinal,其中 V V V为图节点个数
-
交叉门控特征融合
由于分别从流量header图和流量payload图中提取特征,并获得了两个图的最终表示 g h g_h gh和 g p g_p gp,当前目标是在 g h g_h gh和 g p g_p gp之间创建一个合理的关系,以获得数据包字节的总体表示。具体方法:使用了两个线性层+两个激活层来将获取门控矢量 s h s_h sh和 s p s_p sp,由于激活层使用的是sigmoid,因此 s h s_h sh和 s p s_p sp的元素大小范围在[0,1]
s h = s i g m o i d ( w h 2 T P R e L U ( w h 1 T g h + b h 1 ) + b h 2 ) s_h = sigmoid(w_{h_2}^TPReLU(w_{h_1}^Tg_h+b_{h_1})+b_{h_2}) sh=sigmoid(wh2TPReLU(wh1Tgh+bh1)+bh2)
s p = s i g m o i d ( w p 2 T P R e L U ( w p 1 T g p + b p 1 ) + b p 2 ) s_p = sigmoid(w_{p_2}^TPReLU(w_{p_1}^Tg_p+b_{p_1})+b_{p_2}) sp=sigmoid(wp2TPReLU(wp1Tgp+bp1)+bp2)
z = c o n c a t ( s h ⊙ g p , s p ⊙ g h ) z = concat(s_h \odot g_p, s_p \odot g_h) z=concat(sh⊙gp,sp⊙gh)
5. 下游任务
由于我们已经将流量段中每个数据包的原始字节编码为表示向量z,因此可以将段级分类任务视为时间序列预测任务。使用的模型包括LSTM和transformer。
6. 模型总结
- 输入:pcap流量包
- 流量包预处理:将流量分段,每段用 s i = [ b s 1 i , b s 2 i , . . . , b s n i ] s_i = [bs_1^i,bs_2^i,...,bs_n^i] si=[bs1i,bs2i,...,bsni]表示。
- 建图:一个数据包建一个图,例如对 b s 1 i bs_1^i bs1i分别建两个图(分别是header图( G h G_h Gh)和payload图( G p G_p Gp)),该数据包中的每个字节是一个节点(相同的字节共用一个节点),边要根据字节与字节之间的PMI值构建,PMI>0则建边,否则不建边。这样一来,一个数据包段就包含了多个图,举例来说, s i s_i si 包含2n个图(n个header图,n个payload图)。
- 对每一个字节产生的两个图而言,分别进行嵌入,生成两个嵌入矩阵: E h e a d e r ∈ R K × d 0 E_{header} \in R^{K \times d_0} Eheader∈RK×d0、 E p a y l o a d ∈ R K × d 0 E_{payload} \in R^{K \times d_0} Epayload∈RK×d0
- 将这两个嵌入矩阵分别放入两个不共享参数的4层堆叠GraphSAGE模型,产生结果,结果为每个层的输出concat后的结果。
输入: E h e a d e r E_{header} Eheader:[batch_size, num_nodes, nodes_embedding_input]、 E p a y l o a d E_{payload} Epayload:[batch_size, num_nodes, nodes_embedding_input]
输出: h h e a d e r f i n a l h_{header}^{final} hheaderfinal:[batch_size, num_nodes, nodes_embedding_output*4]、 h p a y l o a d f i n a l h_{payload}^{final} hpayloadfinal:[batch_size, num_nodes, nodes_embedding_output*4]
- 对输出进行mean pooling,获得图表示。
输入: h h e a d e r f i n a l h_{header}^{final} hheaderfinal:[batch_size, num_nodes, nodes_embedding_output*4]、 h p a y l o a d f i n a l h_{payload}^{final} hpayloadfinal:[batch_size, num_nodes, nodes_embedding_output*4]
输出: g h g_h gh:[batch_size, nodes_embedding_output*4]、 g p g_p gp:[batch_size, nodes_embedding_output*4]
- 交叉门控特征融合
输入: g h g_h gh:[batch_size, nodes_embedding_output*4]、 g p g_p gp:[batch_size, nodes_embedding_output*4]
输出: z z z:[batch_size, nodes_embedding_output*4]
- 下游任务(其实就是一个nlp序列预测问题了, s i s_i si类似于一篇文章的一个段落)
输入: s i = [ [ z 向量 1 1 , z 向量 2 1 , . . . , z 向量 m 1 ] , [ z 向量 1 2 , z 向量 2 2 , . . . , z 向量 m 2 ] , . . . , [ z 向量 1 n , z 向量 2 n , . . . , z 向量 m n ] ] s_i = [[z向量1^1,z向量2^1,...,z向量m^1],[z向量1^2,z向量2^2,...,z向量m^2],...,[z向量1^n,z向量2^n,...,z向量m^n]] si=[[z向量11,z向量21,...,z向量m1],[z向量12,z向量22,...,z向量m2],...,[z向量1n,z向量2n,...,z向量mn]]
输出: l a b e l i = [ l a b e l 1 , l a b e l 2 , . . . , l a b e l n ] label_i = [label1,label2,...,labeln] labeli=[label1,label2,...,labeln]
总的来说,就是先进行了一个图级别的gnn,对每个字节都生成了向量z(类似于nlp中词向量),然后再接上一个rnn将原始问题变为序列预测问题。
反过来想,我们可以将流量分类问题直接看成文本分类问题,以下是对应关系:
- pcap包 — 一篇文章
- 数据包段 — 一篇文章中的一个段落
- 数据包 — 一篇文章中的一个段落中的一个句子
- 数据包中的每个字节 — 句子中的词语
前面的图神经网络所做的工作就是获取一个恰当的词向量表示。
7. 实验
针对以下问题开展实验:
- RQ1:每个组件的有用性如何(章节4.3)?
- RQ2:哪个GNN架构性能最好(第4.4节)?
- RQ3:TFE-GNN模型的复杂性如何(第4.5节)?
- RQ4:超参数的变化会在多大程度上影响TFE-GNN的有效性(第4.6节)?
- 实验设置
-
数据集:
- ISCX VPNnonVPN:包含加密流量(VPN)和非加密流量(non-VPN),6个用户行为类别
- ISCX Tor-nonTor:包含加密流量(Tor)和非加密流量(non-Tor),8个用户行为类别,由于该数据集中缺少流的概念,因此划分为60秒不重叠的块来作为一个流进行训练。
- WWT(自行收集的数据集):WhatsApp:12个用户行为类别;微信:9个用户行为类别;Telegram:6个用户行为类别。此外,还记录了每个用户行为样本的开始和结束时间戳,用于流量分割。
通过分层抽样,训练集:测试集 = 9:1
-
预处理:
- 对于每个数据集,我们定义并过滤掉两种“异常”样本:
(1)空流或段:所有数据包都没有有效载荷的流量流或段。空的流或段不包含任何负载,因此我们不能构造相应的图。事实上,这些样本通常用于建立客户机和服务器之间的连接,几乎没有有助于分类的判别信息。
(2)过长的流或段:长度(即报文数)大于10000的流量或段。过长流或段中包含的报文数量过多,可能由于网络环境暂时不良或其他潜在原因导致其中出现大量的坏报文或重传报文。在大多数情况下,这样的样本引入了太多的噪声,因此我们也将过长的流或段视为异常样本并将其删除。
(3)此外,对于数据集的每个剩余样本,我们删除了其中的坏包和重传包。- 去掉Ethernet报头
- 为了消除对源自这些IP地址和端口号的敏感信息的干扰,源、目的IP地址和端口号都被删除了
-
实现细节和基线:
参数:
- 每个数据包段所包含的最多数据包数 <= 50
- 最大负载字节长度和最大报头字节长度分别设置为150和40。
- PMI窗口大小设为5
- epoch:1520
- 学习率:1e-2,逐步衰减到1e-4
- 优化器:Adam
- batch_size:512
- warmup:0.1
- dropout:0.2
评估:
- 总体精度(AC)、精度(PR)、召回率(RC)、macro F1-score (F1)
baseline:
- 基于传统特征工程的方法:AppScanner[31]、CUMUL[23]、K-FP (K-Fingerprinting)[8]、FlowPrint[32]、GRAIN[43]、FAAR[19]、ETC-PS[40]
- 基于深度学习的方法:FS-Net[18]、EDC[16]、FFB[44]、MVML[4]、DF[30]、ET-BERT[17]
- 基于图神经网络的方法:GraphDApp[29]、ECD-GNN[11]
-
对比实验


-
消融实验(RQ1)
- H:header
- P:payload
- dual:双层编码
- JKN:GraphSAGE的四层concat操作
- CGFF:交叉门通特征融合
- A&N:激活函数和批归一化

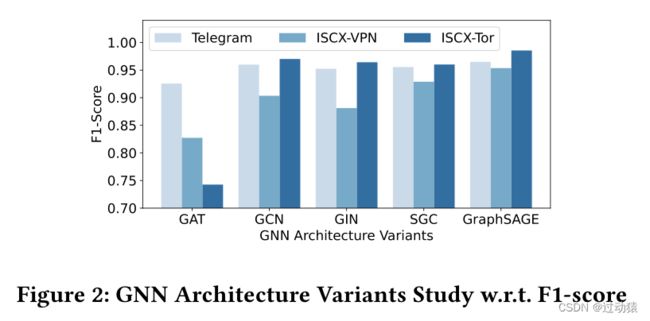
- GNN架构变体研究(RQ2)
- 模型复杂度分析(RQ3)

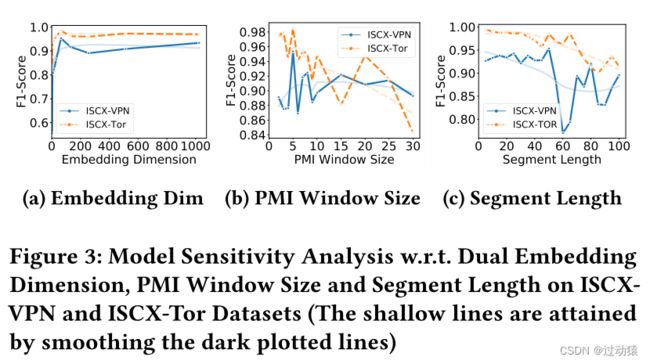
- 模型敏感性分析(RQ4)
其实就是一些超参数的选择问题,寻找最优的超参数。
总结
论文内容
-
学到的方法
理论上的方法:
- 除了统计特征外,可以尝试从字节特征入手
-
论文优缺点
优点:
- 放弃了从统计特征入手来分析,而是从字节特征入手,避免了短流所造成的统计特征难以采集的缺陷
- 该方法不仅能够处理加密流量,同时也可以处理未加密流量
缺点:
- 双层嵌入那里没有具体写明初始是如何将字节值嵌入到高维的,使得复现起来有些困难。
- 有限图构造方法。该模型的图拓扑在训练前确定,这可能导致非最优性能。此外,TFE-GNN不能处理每个包的原始字节中隐含的字节噪声。
- 字节序列中隐含的未使用的时间信息。在构造逐层流量图时,没有引入字节序列的显式时间特征。(没懂什么意思)
-
创新想法
- 构图时,相同的字节值共用一个节点,但并没有根据字节值出现的频率进行分配权重,我认为,对于出现的字节值较多节点,要添加更多的权重,使得其成为该图中比较重要的节点。具体可以参考:https://blog.csdn.net/Dajian1040556534/article/details/130113702这篇文章。
数据集
- ISCX VPNnonVPN:包含加密流量(VPN)和非加密流量(non-VPN),6个用户行为类别
- ISCX Tor-nonTor:包含加密流量(Tor)和非加密流量(non-Tor),8个用户行为类别,由于该数据集中缺少流的概念,因此划分为60秒不重叠的块来作为一个流进行训练。
- WWT(自行收集的数据集):WhatsApp:12个用户行为类别;微信:9个用户行为类别;Telegram:6个用户行为类别。