Google B4 论文阅读一
目录
一、B4网络介绍
1. 全局控制层(global)
2. 局部网络控制层(site controllers)
3. 物理设备层(switch hardware)
二、B4网络的效果
三、B4网络的改进和展望
说在前面,博客上有很多人已经写了关于B4的文章,所以我也在怀疑要不要再次重复写一遍。昨天听了华为的HDC.Cloud开发者大会学校分会场,回答了问题奖励了一本《鲲鹏处理器架构与编程》,会上华为的技术专家在讲华为自研的轻量级容器引擎iSula时就说:“Docker已经流行很多年了,并且功能也非常强大了,但是华为为什么还要自研,是否是重复造轮子呢?” 我本来想这应该也是华为布局的一部分吧,避免遭到更多的制裁而无法继续相应业务,但是华为技术专家的回答是“需求驱动”,因为iSula不仅能够启动更快,更节省内存空间,还能适应IOT、边缘计算等多场景。我也想说的是,我的方向不是计算机网络的,这个很多也借鉴了网上的内容,毕竟论文内容讲的就是那些,就像iSula也完全兼容Dockefile的语法,我写也是为了让自己了解的更多一些,才疏学浅,共同学习,争取每周分享一到两篇内容,欢迎批评指正,谢谢。
论文名:B4: Experience with a Globally-Deployed Software Defifined WAN
一、B4网络介绍
Google的数据中心之间传输的数据可以分为三大类:
1、用户数据远程数据中心备份,如邮件、文档、音视频文件等;
2、跨数据中心的分布式存储访问,例如计算资源和存储资源分布在不同的数据中心;
3、大规模的跨数据中心的数据同步。
这三大类从前往后数据量依次变大,对延时的敏感度依次降低,优先级依次变低。这些都是B4网络改造中涉及到的流量工程(TE,Traffic Engineering)部分所要考虑的因素。最为关键的是B4之前的WAN的链路带宽利用率只有30%-40%,而为了保证高可靠性,对每个字节数据都是平等对待,没有面对流量激增较好的负载均衡措施,依靠的是付出昂贵的代价来增加2-3倍带宽和高端的路由设备。同时数据链路上的转发失败信息全部被屏蔽,使得应用程序无法得到消息,也没有相关中央设备对路由线路重新规划,而只是依靠竞争策略来不断抢占数据通路。
因此Google就提出了基于SDN和OpenFlow的B4网络,来相应地解决弹性带宽需求、到达适中的站点数量、有能力处理终端应用和网络问题,并且不至于太高的成本。还有就是可以让新的协议在网络设备中快速迭代、简化测试环境、有中央TE服务器来规划容量和路由策略、网络中心简化管理。
下面来介绍B4的架构,如图1. B4架构[1]。
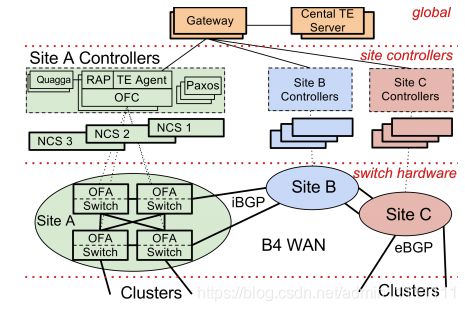
图1. B4架构[1]
谷歌对于B4网络系统的设计可分类三个层次:全局控制层(global),局部网络控制层(site controllers)和物理设备层(switch hardware)。
1. 全局控制层(global)
全局的TE Server通过SDN Gateway从各个数据中心(Site A、Site B、Site C)的控制器收集并掌握个站点的链路信息。TE Server获取各站点链路信息后,根据SDN Gateway上报的拓扑和链路情况以及bandwidth情况,计算出最优路径(即每个流映射到对应的tunnel)和需要分配对应的带宽,把这些信息通过SDN Gateway下发到站点的Controller,再由OFC(OpenFlow Controller)下发到OpenFlow交换机(OFA Switch)的TE转发表(ACL)中进行转发,这些ACL转发表项优先级高于LPM路由表。如下图2.,选择器(selector)就选择了ACL Table中的Multiple table index =0,entries=2这个表项。
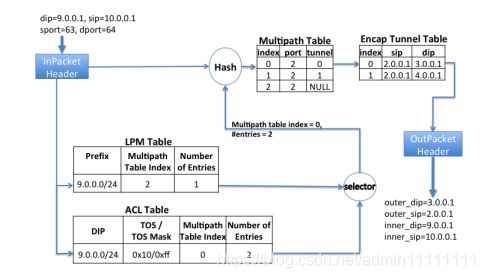
图2. 在交换机上最短路径转发[1]
2. 局部网络控制层(site controllers)
每个数据中心(stie)有一组controller用来控制该数据中心WAN网的交换机,一个controller可以控制多台交换机,而一个交换机也可以连接到多个controller,因此需要Paxos算法来进行master选举,作为处于工作状态的主用controller。在Controller中,RAP(Routing Application Proxy)作为SDN应用与Quagga(三层路由协议栈,支持多路由协议)通信。Controller收到交换机送上来的路由协议报文和链路状态变化通知时,把自己管理的信息通过RAP传递给Quagga协议栈,Quagga计算出路由方案后在controller中保留一份,放在RIB中,同时下发到交换机中,如下图3.。
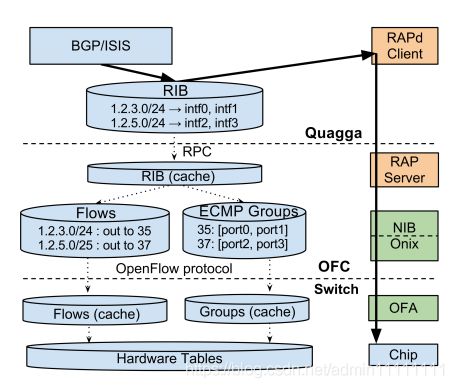
图3. 集成路由和OpenFlow控制[1]
站点controller中的TE Agent作用是与全局Gateway通信,每个OpenFlow交换机的链路状态信息都会通过TE Agent发送到全局Gateway中,全局Gateway汇总后,发送给TE Server进行路径和带宽信息计算。
3. 物理设备层(switch hardware)
B4网络中,数据中心内部的路由器运行eBGP路由协议,与他数据中心WAN里面的设备之间运行iBGP路由协议。
B4网络中的物理交换机运行OpenFlow协议。OpenFlow协议用来描述OFC和OpenFlow交换机之间交互信息的接口标准。参考图3. 集成路由和OpenFlow控制。图4. 交换机实体及其物理拓扑[1],谷歌强大的一点可能就是它研究东西只要能做到最好那怕自己重新设计一个交换机,下图应该是谷歌设计的采用经典CLOS架构的Saturn交换机。
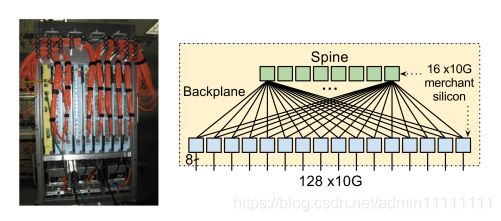
图4. 交换机实体及其物理拓扑[1]
二、B4网络的效果
谷歌针对TE算法中最大可用路径数和分流量化大小进行了实验。如下图5. TE全局吞吐量的提升比例[1],(a)中设置的分流量化大小是1/64时,最大路径在增长到4条之后TE全局吞吐量便无明显增长,谷歌实际的网络中就采用4条路径作为TE算法参数。在(b)中最大路径数设置为4时,分流的量化越大效果越好。添加更多路径和使用更细粒度的流量分割都为TE提供了更多的灵活性,但它会消耗额外的硬件资源,实际应用是1/4的分流量化大小。
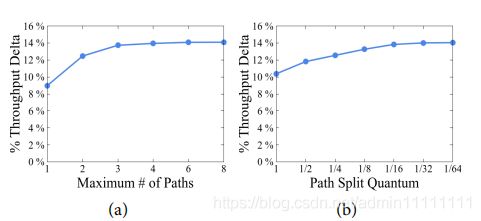
图5. TE全局吞吐量提升比例[1]
在使用集中式TE后,B4的网络链路利用率(如图6.(a)所示)在一天的变化都是接近100%的,比传统的WAN的30%-40%有了大幅度的提高。
图6.(b)中红线表示高优先级与低优先级的数据包的比例,蓝色部分带“*”线段表示高优先级的丢包率,绿色“+”表示低优先级的丢包率。可以看出高优先级的丢包率在全天24小时内几乎都为0,这样就可以满足对延迟较高的应用的要求。
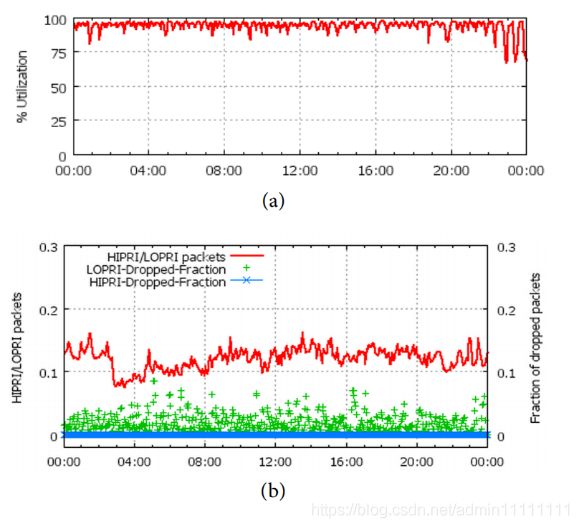
图6. 站点边缘利用率和丢包率
如图7. 链路的利用率[1],可以看出B4的整体负载平衡方案还是非常不错的。对于至少75%的站点到站点的边缘链路,各链路利用率的最大值:最小值为1.05(即最佳值为5%),最大值:最小值为2.0。但问题就在这,B4网络在没有故障的时候,边缘网络中链路的最大利用率与最小利用率比例为1.05,但在发生故障的时候上升为2.0,说明负载均衡方案可以进一步提升,论文也提到这个也是正在进行研究的主题。
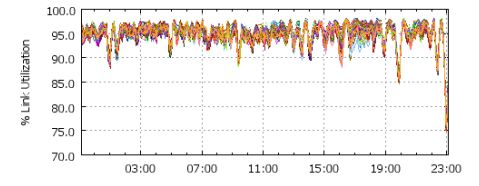
图7. 链路的利用率[1]
三、B4网络的改进和展望
本篇文章发表较早,所以在后续谷歌2018年发表的“B4 and after: ...”一文中有了更多的改进,但是了解B4网络还是先从它的发展起源开始了解更好。不过B4网络的改进和展望会提到2018年发表的文章谈及的一些需要改进的点。
- 从控制平面到数据平面的协议数据包桥接的瓶颈和硬件编程的开销;
- B4网络的架构不能推广到所有SDNs或者所有WANs;
- 在发生故障时采取更加有效的负载均衡策略。在B4网络没有故障时,边缘网络链路的最大利用率与最小利用率比例为1.05,而当发生故障时,比例上升为2。说明负载均衡策略还有优化空间。
References:
[1]Jain S , Kumar A , Mandal S , et al. B4: Experience with a Globally-Deployed Software Defined WAN[C]// Proceedings of the ACM SIGCOMM 2013 conference on SIGCOMM. ACM, 2013:3-14.
[2]谷歌B4广域网论文笔记_jianghuiyou的专栏-CSDN博客