【深度学习】从现代C++中的开始:卷积
一、说明
在上一个故事中,我们介绍了机器学习的一些最相关的编码方面,例如 functional 规划、矢量化和线性代数规划。
本文,让我们通过使用 2D 卷积实现实际编码深度学习模型来开始我们的道路。让我们开始吧。
二、关于本系列
我们将学习如何仅使用普通和现代C++对必须知道的深度学习算法进行编码,例如卷积、反向传播、激活函数、优化器、深度神经网络等。
 这个故事是:在C++中编码 2D 卷积
这个故事是:在C++中编码 2D 卷积
查看其他故事:
0 — 现代C++深度学习编程基础
2 — 使用 Lambda 的成本函数
3 — 实现梯度下降
4 — 激活函数
...更多内容即将推出。
三、卷 积
卷积是信号处理领域的老朋友。最初,它的定义如下:
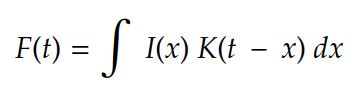
在机器学习术语中:
- 我(...通常称为输入
- K(...作为内核,以及
- F(...)作为给定 K 的 I(x) 的特征映射。
考虑一个多维离散域,我们可以将积分转换为以下求和:
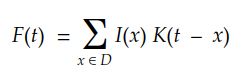
最后,对于2D数字图像,我们可以将其重写为:
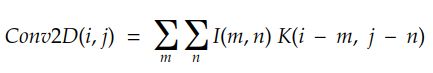
理解卷积的一种更简单的方法是下图:
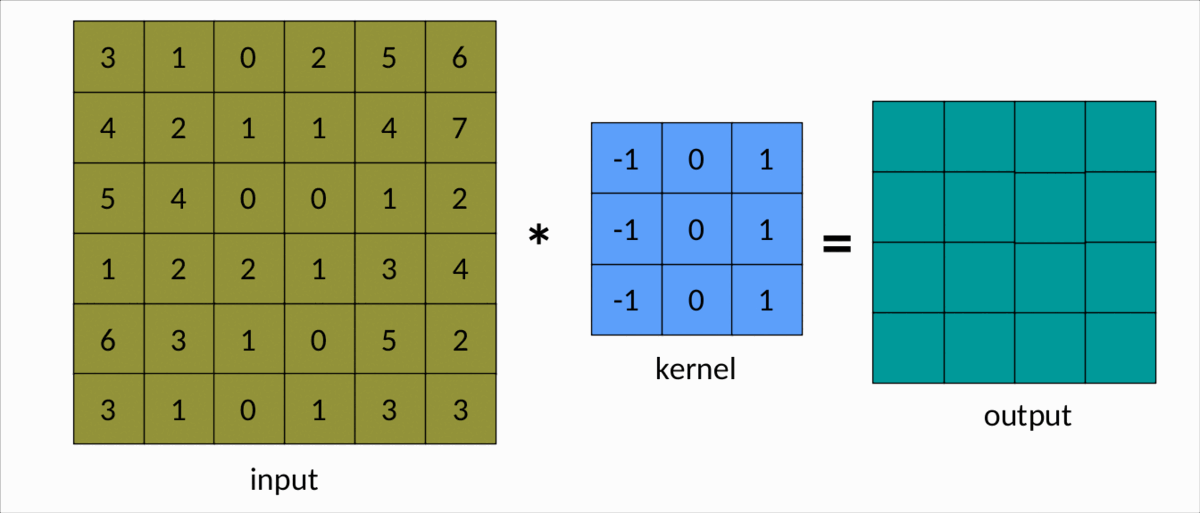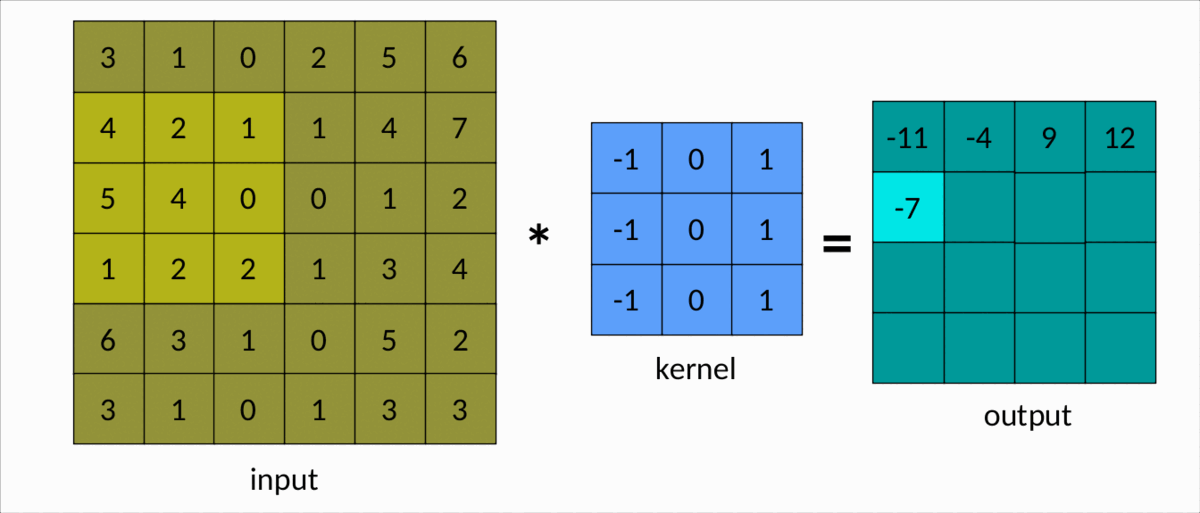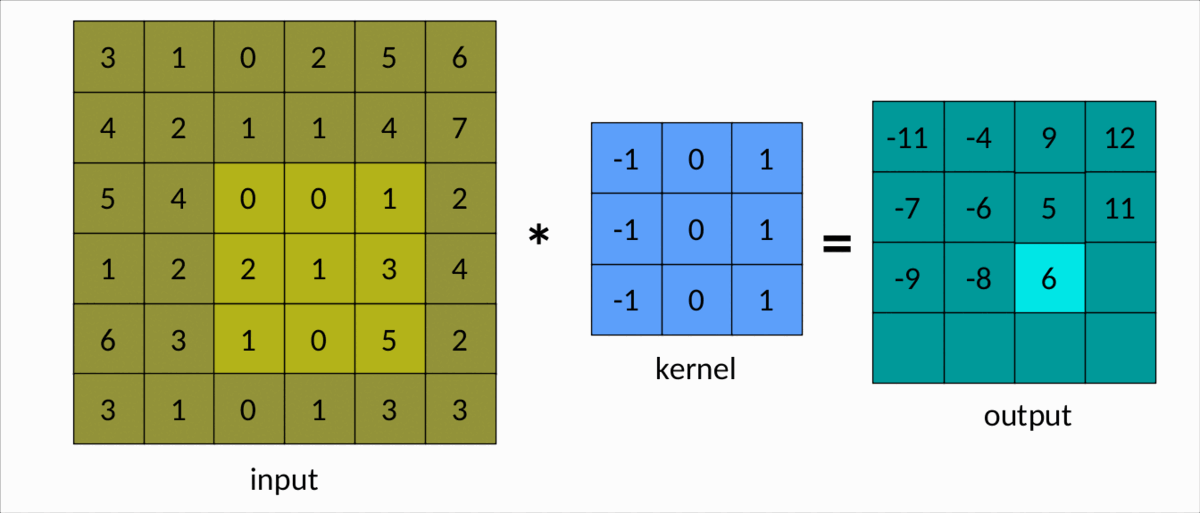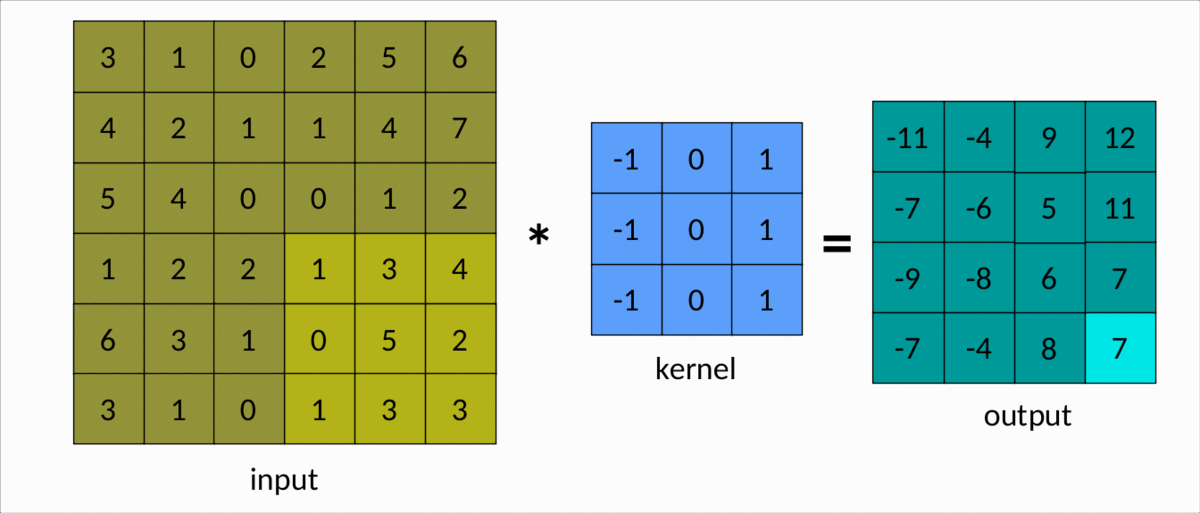 有效卷积 — 作者图片
有效卷积 — 作者图片
我们可以很容易地看到内核在输入矩阵上滑动,生成另一个矩阵作为输出。这是卷积的简单情况,称为有效卷积。在这种情况下,矩阵的维度由下式给出:Output
dim(Output) = (m-k+1, n-k+1)
这里:
m分别是输入矩阵中的行数和列数,以及nk是平方核的大小。
现在,让我们对第一个 2D 卷积进行编码。
四、使用循环对 2D 卷积进行编码
实现卷积的最直观方法是使用循环:
auto Convolution2D = [](const Matrix &input, const Matrix &kernel)
{
const int kernel_rows = kernel.rows();
const int kernel_cols = kernel.cols();
const int rows = (input.rows() - kernel_rows) + 1;
const int cols = (input.cols() - kernel_cols) + 1;
Matrix result = Matrix::Zero(rows, cols);
for (int i = 0; i < rows; ++i)
{
for (int j = 0; j < cols; ++j)
{
double sum = input.block(i, j, kernel_rows, kernel_cols).cwiseProduct(kernel).sum();
result(i, j) = sum;
}
}
return result;
};这里没有秘密。我们将内核滑过列和行,为每个步骤应用内积。现在,我们可以像以下那样简单地使用它:
#include
#include
using Matrix = Eigen::MatrixXd;
auto Convolution2D = ...;
int main(int, char **)
{
Matrix kernel(3, 3);
kernel <<
-1, 0, 1,
-1, 0, 1,
-1, 0, 1;
std::cout << "Kernel:\n" << kernel << "\n\n";
Matrix input(6, 6);
input << 3, 1, 0, 2, 5, 6,
4, 2, 1, 1, 4, 7,
5, 4, 0, 0, 1, 2,
1, 2, 2, 1, 3, 4,
6, 3, 1, 0, 5, 2,
3, 1, 0, 1, 3, 3;
std::cout << "Input:\n" << input << "\n\n";
auto output = Convolution2D(input, kernel);
std::cout << "Convolution:\n" << output << "\n";
return 0;
} 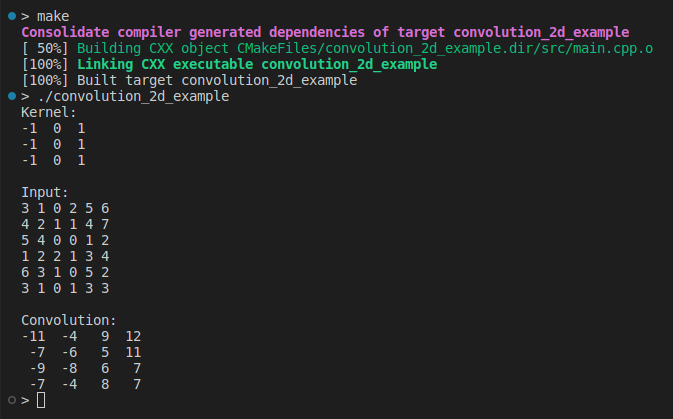
这是我们第一次实现卷积 2D,设计为易于理解。有一段时间,我们不关心性能或输入验证。让我们继续前进以获得更多见解。
在接下来的故事中,我们将学习如何使用快速傅立叶变换和托普利兹矩阵来实现卷积。
五、填充
在前面的示例中,我们注意到输出矩阵始终小于输入矩阵。有时,这种减少是好的,有时是坏的。我们可以通过在输入矩阵周围添加填充来避免这种减少:

填充为 1 的输入图像
卷积中填充的结果如下所示:
填充卷积 — 作者图片
实现填充卷积的一种简单(和蛮力)方法如下:
auto Convolution2D = [](const Matrix &input, const Matrix &kernel, int padding)
{
int kernel_rows = kernel.rows();
int kernel_cols = kernel.cols();
int rows = input.rows() - kernel_rows + 2*padding + 1;
int cols = input.cols() - kernel_cols + 2*padding + 1;
Matrix padded = Matrix::Zero(input.rows() + 2*padding, input.cols() + 2*padding);
padded.block(padding, padding, input.rows(), input.cols()) = input;
Matrix result = Matrix::Zero(rows, cols);
for(int i = 0; i < rows; ++i)
{
for(int j = 0; j < cols; ++j)
{
double sum = padded.block(i, j, kernel_rows, kernel_cols).cwiseProduct(kernel).sum();
result(i, j) = sum;
}
}
return result;
};此代码很简单,但在内存使用方面非常昂贵。请注意,我们正在制作输入矩阵的完整副本以创建填充版本:
Matrix padded = Matrix::Zero(input.rows() + 2*padding, input.cols() + 2*padding);
padded.block(padding, padding, input.rows(), input.cols()) = input;更好的解决方案可以使用指针来控制切片和内核边界:
auto Convolution2D_v2 = [](const Matrix &input, const Matrix &kernel, int padding)
{
const int input_rows = input.rows();
const int input_cols = input.cols();
const int kernel_rows = kernel.rows();
const int kernel_cols = kernel.cols();
if (input_rows < kernel_rows) throw std::invalid_argument("The input has less rows than the kernel");
if (input_cols < kernel_cols) throw std::invalid_argument("The input has less columns than the kernel");
const int rows = input_rows - kernel_rows + 2*padding + 1;
const int cols = input_cols - kernel_cols + 2*padding + 1;
Matrix result = Matrix::Zero(rows, cols);
auto fit_dims = [&padding](int pos, int k, int length)
{
int input = pos - padding;
int kernel = 0;
int size = k;
if (input < 0)
{
kernel = -input;
size += input;
input = 0;
}
if (input + size > length)
{
size = length - input;
}
return std::make_tuple(input, kernel, size);
};
for(int i = 0; i < rows; ++i)
{
const auto [input_i, kernel_i, size_i] = fit_dims(i, kernel_rows, input_rows);
for(int j = 0; size_i > 0 && j < cols; ++j)
{
const auto [input_j, kernel_j, size_j] = fit_dims(j, kernel_cols, input_cols);
if (size_j > 0)
{
auto input_tile = input.block(input_i, input_j, size_i, size_j);
auto input_kernel = kernel.block(kernel_i, kernel_j, size_i, size_j);
result(i, j) = input_tile.cwiseProduct(input_kernel).sum();
}
}
}
return result;
}; 这个新代码要好得多,因为这里我们没有分配一个临时内存来保存填充的输入。但是,它仍然可以改进。调用和内存成本也很高。input.block(…)kernel.block(…)
调用的一种解决方案是使用 CwiseNullaryOp 替换它们。
block(…)
我们可以通过以下方式运行填充卷积:
#include
#include
using Matrix = Eigen::MatrixXd;
auto Convolution2D = ...; // or Convolution2D_v2
int main(int, char **)
{
Matrix kernel(3, 3);
kernel <<
-1, 0, 1,
-1, 0, 1,
-1, 0, 1;
std::cout << "Kernel:\n" << kernel << "\n\n";
Matrix input(6, 6);
input <<
3, 1, 0, 2, 5, 6,
4, 2, 1, 1, 4, 7,
5, 4, 0, 0, 1, 2,
1, 2, 2, 1, 3, 4,
6, 3, 1, 0, 5, 2,
3, 1, 0, 1, 3, 3;
std::cout << "Input:\n" << input << "\n\n";
const int padding = 1;
auto output = Convolution2D(input, kernel, padding);
std::cout << "Convolution:\n" << output << "\n";
return 0;
} 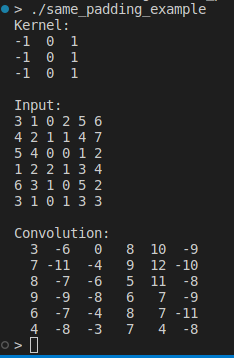
请注意,现在,输入和输出矩阵具有相同的维度。因此,它被称为填充。默认填充模式,即无填充,通常称为填充。我们的代码允许 ,或任何非负填充。samevalidsamevalid
六、内核
在深度学习模型中,核通常是奇次矩阵,如、等。有些内核非常有名,比如 Sobel 的过滤器:3x35x511x11
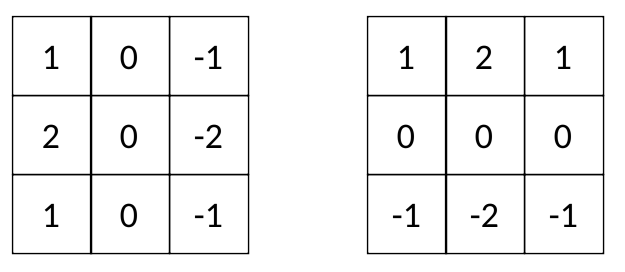 索贝尔过滤器 Gx 和 Gy
索贝尔过滤器 Gx 和 Gy
更容易看到每个 Sobel 滤镜对图像的影响:
使用 Sobel 过滤器的代码在这里。
Gy 突出显示水平边缘,Gx 突出显示垂直边缘。因此,Sobel 内核 Gx 和 Gy 通常被称为“边缘检测器”。
边缘是图像的原始特征,例如纹理、亮度、颜色等。现代计算机视觉的关键点是使用算法直接从数据中自动查找内核,例如Sobel过滤器。或者,使用更好的术语,通过迭代训练过程拟合内核。
事实证明,训练过程教会计算机程序实现如何执行复杂的任务,例如识别和检测物体、理解自然语言等......内核的训练将在下一个故事中介绍。
七、结论和下一步
在这个故事中,我们编写了第一个2D卷积,并使用Sobel滤波器作为将此卷积应用于图像的说明性案例。卷积在深度学习中起着核心作用。它们被大量用于当今每个现实世界的机器学习模型中。我们将重新审视卷积,以学习如何改进我们的实现,并涵盖一些功能,如步幅。