Python内置函数系统学习(3)——数据转换与计算 (详细语法参考+参数说明+具体示例) 详解min()函数在列表、元组、字典的综合应用 | lambda 很牛哦!你怎么看!?
两岸猿声啼不住,轻舟已过万重山!

作者主页: 追光者♂
个人简介:
[1] 计算机专业硕士研究生
[2] 2022年度博客之星人工智能领域TOP4
[3] 阿里云社区特邀专家博主
[4] CSDN-人工智能领域优质创作者
[5] 预期2023年10月份 · 准CSDN博客专家
- 无限进步,一起追光!!!
感谢大家 点赞 收藏⭐ 留言!!!
之前记录过的关于Python内置函数的Blog(包括但不限于):
- Python内置函数系统学习(2)——数据转换与计算 (详细语法参考+参数说明+应用场景示例), max()在列表、元组、字典中的综合应用 | 编程实现当前内存使用情况的监控
- Python内置函数系统学习(1)——数据转换与计算 (详细语法参考+参数说明+应用场景示例) 对象—>>字符串、字符—>>ASACII码 综合应用
写在前面:尽管博主科研很忙,无法参加蓝桥杯考试,但还是希望能够感受一下其中氛围哦!本次分享的案例均是具有比较强的应用意义,就如:求最小值,这本是很简单的问题,但是它在列表、元组、字典中的综合应用,你看过没?!这对于要参加蓝桥杯的小伙伴儿应该会有所帮助!祝大家取得好成绩!此外,这也是后续理解Python内置函数&人工智能&机器学习的基础,建议大家跟随练习!也祝各位学习顺利!
目录
- 一、求最小值
-
- 1.1 语法参考 & 参数说明
- 1.2 示例
-
- 1.2.1 在字符、数值、标点及汉字中取最小值
- 1.2.2 获取多个数值中的最小值
- 1.2.3 在列表中使用min
-
- 1.2.3.1 进一步练习(1):求 带有限制条件的“最小值”
- 1.2.3.2 进一步练习(2):向列表中添加指定个数的随机数
- 1.2.4 在元组中使用min
-
- 1.2.4.1 中文字符元组
- 1.2.4.2 英文名字元组
- 1.2.4.3 中文+数字——成绩 元组
- 1.2.4.4 lambda ?
- 1.2.4.5 元组——北、上、广、深GDP值
- 1.2.4.6 补充:快速理解
- 1.2.5 在字典中使用min
-
- 1.2.5.1 人名+qq号码
- 1.2.5.2 通过映射函数创建字典
- 1.2.5.3 模拟人员技能工资数据
- 1.3 应用场景
-
- 1.3.1 场景一:获取最新上映的电影名称(字典&字典,字典-->>列表)
- 1.3.2 场景二:获取汽车碰撞测试中分数最低的那项
- 1.3.3 场景三:获取二手房指定户型且总价最低的信息
一、求最小值
1.1 语法参考 & 参数说明
语法参考:
min()函数用于执行与max()函数相反的操作,用于获取指定的多个参数中的最小值 或 可迭代对象元素中的最小值。其语法格式如下:
min(iterable, *[, default=obj, key=func])min(arg1, arg2, *args, *[, key=func])min(tuplename)
参数说明:
- [1] iterable:可迭代对象,如字符串、列表、元组、字典等;
- [2] default:命名参数,用来指定最小值不存在时返回的默认值;
- [3] key:命名参数,其为一个函数,用来指定获取最小值的方法;
- [4] arg:指定数值;
- [5] tuplename:表示元组的名称。
返回值:返回给定参数的最小值。
补充说明: min()函数在参数使用上与max()函数基本一致,只是在执行上是与max()函数相反的操作。
1.2 示例
1.2.1 在字符、数值、标点及汉字中取最小值
Min函数是
根据元素编码的码值大小来取得最小值的。我们通常使用的字符的编码值可以通过其对应ASCII码表或相应编码表获得。Min函数对数字、字符等常见用法如下:
# 昵 称:XieXu & CSDN@追光者♂
# 时 间: 2023/4/6/0006 18:40
# 在字符、数值、标点及汉字中取最小值
str1 = '0123456789' # 数字-字符串
str2 = 'abcdABCD' # 字母-字符串
str3 = '你好' # 汉字-字符串
str4 = '!~@#¥%……&*' # 符号-字符串
print('数字-字符串最小值为:', min(str1))
print('字母-字符串最小值为:', min(str2))
print('汉字-字符串最小值为:', min(str3))
print('符号-字符串最小值为:', min(str4))
在PyCharm中执行后,输出结果为:

1.2.2 获取多个数值中的最小值
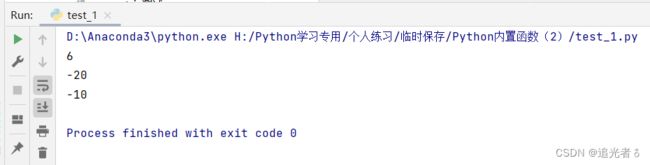
# 获取多个数值中的最小值
print(min(6, 8, 10, 6, 100))
print(min(-20, 100 / 3, 7, 100))
print(min(0.2, -10, 10, 100))
结果也是“显而易见”滴:
1.2.3 在列表中使用min
在列表中有多种方法可以求最小值,
min()是最方便、简单的方法。使用min函数获取列表最小值时,函数内部将对列表中的元素进行循环比较,然后返回列表元素最小的值,当存在多个相同的最小值时,返回的是最先出现的那个最小值。min()函数在列表中的常见用法如下:
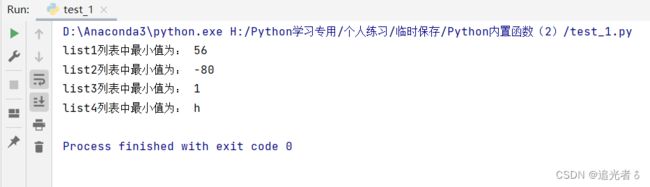
# 在列表中使用min
list1 = [98, 79, 88, 100, 56, 100] # 元素为数值的列表
list2 = [-80, -20, -10] # 元素为负数的列表
list3 = ['1', '2', '5', '8'] # 元素为字符串数字的列表
list4 = ['你', '好', 'p', 'y', 't', 'h', 'o', 'n'] # 元素为汉字与英文字母的列表
print('list1列表中最小值为:', min(list1))
print('list2列表中最小值为:', min(list2))
print('list3列表中最小值为:', min(list3))
print('list4列表中最小值为:', min(list4))
我们可以得到如下结果:
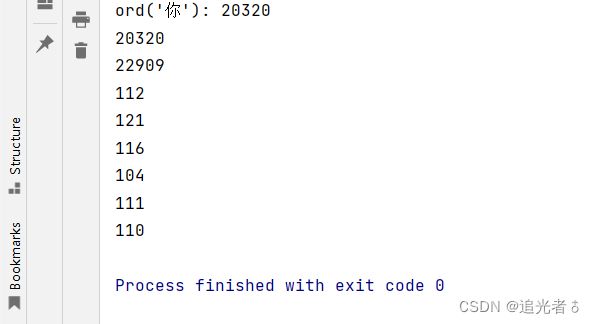
此处,可以再简单练习一下:
print("ord('你'):",ord('你'))
for i in list4: # 列表的迭代
# print(ord(list4[i])) # TypeError: list indices must be integers or slices, not str
# print(i)
print(ord(i)) # 这样即可哈
注:
-
关于
ord(),可参阅:请看 目录2.1 -
关于chr(),可参阅:请看 目录2.3.2
1.2.3.1 进一步练习(1):求 带有限制条件的“最小值”
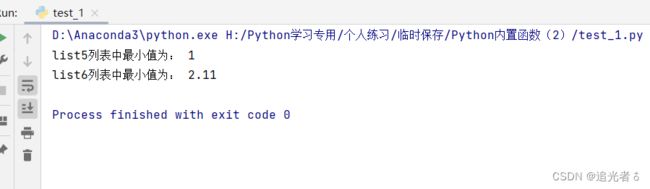
list5 = [1, -3, 5, -7, 8] # 包含正、负数的列表
list6 = [3, 3.15, 2.11, 6] # 包含小数的列表
# 指定键为求绝对值函数,参数会进行求绝对值后再取较小者
print('list5列表中最小值为:', min(list5, key=abs))
# 获取小数中的绝对值
print('list6列表中最小值为:', min(list6))
结果如下:(在注释中已经解释的很仔细啦!)
1.2.3.2 进一步练习(2):向列表中添加指定个数的随机数
import random # 导入随机数模块
seq = [] # 空列表
i = 0
while i < 10: # 循环10次
# 每循环一次向列表中添加一个随机数
seq.append(random.randint(1, 100))
i += 1
getMin = min(seq) # 获取最小值
print('原列表值:', seq)
print('列表最小值:', getMin)

1.2.4 在元组中使用min
1.2.4.1 中文字符元组
在元组中获取元素的最小值和列表相似,常见用法如下:
# 在元组中使用min
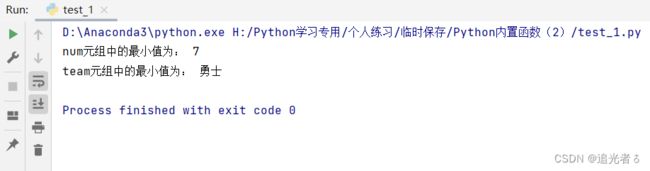
num = (7, 14, 21, 28, 35, 42, 49, 56, 63) # 创建一个数值元组
team = ('马刺', '火箭', '勇士', '湖人') # 创建字符元组
print('num元组中的最小值为:', min(num))
print('team元组中的最小值为:', min(team))
对此,进一步练习:
team = ('马刺', '火箭', '勇士', '湖人') # 创建字符元组
# print('team元组中的最小值为:', min(team)) # team元组中的最小值为: 勇士
# print(ord('勇士')) # TypeError: ord() expected a character, but string of length 2 found
print(ord('勇士'[0])) # 21191
print(ord('勇')) # 21191
print("*" * 20)
for i in team:
# print(ord(i)) # TypeError: ord() expected a character, but string of length 2 found
# print(i) # 测试
# print(i[0]) # 测试
print(ord(i[0]))
这样,就能更好的理解上面的练习了~

1.2.4.2 英文名字元组
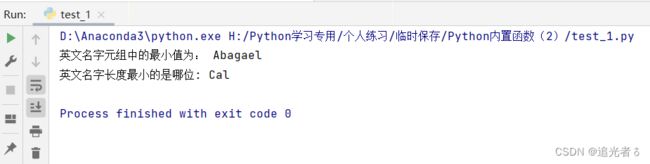
name = ('Jack', 'MacKenzie', 'Cal', 'Rainbo', 'Ralph', 'Abagael') # 英文名字元组
print('英文名字元组中的最小值为:', min(name))
print('英文名字长度最小的是哪位:', min(name, key=lambda i: len(i)))
1.2.4.3 中文+数字——成绩 元组
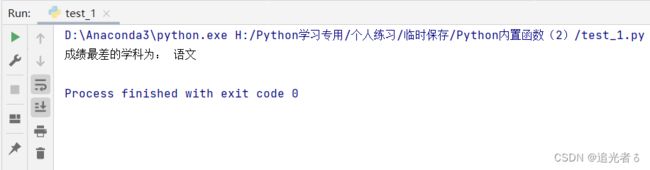
fraction = ('数学 98', '英语 99', '语文 93') # 学生成绩
print('成绩最差的学科为:', min(fraction, key=lambda i: i[3:])[:3])
为了进一步理解,继续针对上面的“成绩”元组——练习:
fraction = ('数学 98', '英语 99', '语文 93') # 学生成绩
print('成绩最差的学科为:', min(fraction, key=lambda i: i[3:])[:3])
# 进一步练习
print(len(fraction)) # 3
print(len(fraction[0])) # 5
print(len(fraction[1])) # 5
print(len(fraction[2])) # 5
print(fraction[0]) # 数学 98
print((fraction[0])[:3]) # 数学。。。这说明输出的是 学科
# 也就是说,通过min函数得到分数最低的项,然后输出该项的前2个字符
# [:3]指的是 输出前2个,不包括第3个。。。
print((fraction[3:])[:3]) # ()
print((fraction[3:])) # ()
结合注释,会更容易理解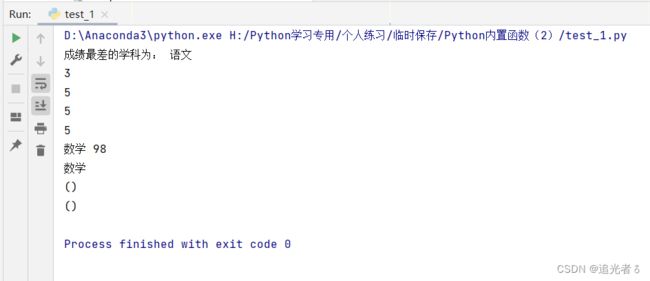
1.2.4.4 lambda ?
对于该关键字,lambda,真的是 言有尽,意无穷。
近期发布的几篇Blog中,都含有lambda。它的应用场景真的是很多!
主要是 lambda 参数 表达式。
此处暂时不做详细说明,根据我近期分享的这些例子,会更好理解。
1.2.4.5 元组——北、上、广、深GDP值
# 北、上、广、深GDP值
gdp = (('北京', '30320亿'), ('上海', '32679亿'), ('广州', '23000亿'), ('深圳', '24620亿'))
print('GDP值最低的是元组中下标为', gdp.index(min(gdp, key=lambda i: i[1][0:6])), '的那组数据')
print('GDP值最低的城市为:', min(gdp, key=lambda i: i[1][0:6])[0])
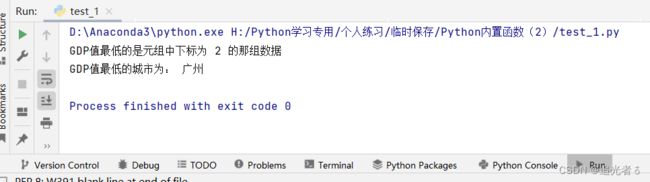
进一步理解,练习:
gdp = (('北京', '30320亿'), ('上海', '32679亿'), ('广州', '23000亿'), ('深圳', '24620亿'))
print(gdp[1][:]) # ('上海', '32679亿')
print(gdp[1][0:]) # ('上海', '32679亿')
print(gdp[1][0:6]) # ('上海', '32679亿')
print(gdp[:][:]) # (('北京', '30320亿'), ('上海', '32679亿'), ('广州', '23000亿'), ('深圳', '24620亿'))
print((gdp[1][0:6])[0]) # 上海...这说明 这样可以输出 城市
# for i in gdp:
# print((gdp[i][0:6])[0]) # TypeError: tuple indices must be integers or slices, not tuple
# print((gdp[i.index()][0:6])[0]) # 上海
# print(i) # 即输出 ('北京', '30320亿') ...('深圳', '24620亿')
# print(gdp[0]) # ('北京', '30320亿')
# print(len(gdp[0])) # 2
# print(len(gdp[1])) # 2
# print(gdp[0][0:3]) # ('北京', '30320亿')
# print(gdp[0][0:2]) # ('北京', '30320亿')
# print(gdp[0][1:3]) # ('30320亿',)
# print(gdp[0][1:2]) # ('30320亿',)
# print(gdp[0][2:4]) # ()
# print(gdp[0][2:]) # ()
# print(gdp[0][1:]) # ('30320亿',)
# print(gdp[0][0:]) # ('北京', '30320亿')
# 这说明,'30320亿'的index,即下标为1
# gdp[0]访问的是 ('北京', '30320亿'),这整个
# gdp[0][0:] 表示访问 '北京','30320亿' 这俩都输出,因为二者的index 分别为0和1,而[0:]表示它俩都输出~
# 而key=lambda i: i[1][0:6])[0])中的i已经指的是每一个元素了,也就是说明
# 这里的i[1]中的1,指的是城市后面的那个元素,即数字~
# [0:6]访问的就是数字~
此处,可根据我上面写的注释来理解。可打开部分注释来查看。
这是部分注释打开时的输出:(同上述代码)
1.2.4.6 补充:快速理解
在Python中,我们可以使用min()函数来查找元组中的最小值。min()函数接受一个可迭代对象(如元组)作为参数,并返回其中的最小值。
这是一个简单的示例:
numbers = (5, 10, 2, 8, 3)
min_num = min(numbers)
print(min_num) # 输出:2
在上面的代码中,我们有一个包含一些数字的元组numbers。通过调用min()函数,并将numbers作为参数传入,我们得到元组中的最小值。在本例中,输出结果为2。
如果你想在元组中的特定范围内查找最小值,则可以使用切片操作:
numbers = (5, 10, 2, 8, 3)
min_num = min(numbers[1:4]) # 在索引1到3的范围内查找最小值
print(min_num) # 输出:2
这样,我们将只在索引1到3之间的子元组中查找最小值。在本例中,输出结果仍然为2。
1.2.5 在字典中使用min
1.2.5.1 人名+qq号码
通过
min函数获取字典中的最小值时,用法与max函数相同,只是执行max函数的相反操作。常见用法如下:
# 昵 称:XieXu & CSDN@追光者♂
# 时 间: 2023/4/6/0006 21:33
# 在字典中使用min
# qq号数据
qq = {'小明qq': 875897, '小红qq': 5343215, '小李qq': 77582, '小华qq': 873541843}
print('qq号码最短的是:', min(qq.values(), key=lambda i: i))
print('最短的qq号码是:', min(qq.items(), key=lambda i: i[1])[0][:2], '的')
输出结果为:

显然,最短的QQ号,在数值上,也是最小的,因此可以用min()函数来求。
此处,为了进一步理解,我们继续练习:
qq = {'小明qq': 875897, '小红qq': 5343215, '小李qq': 77582, '小华qq': 873541843}
# print(qq) # {'小明qq': 875897, '小红qq': 5343215, '小李qq': 77582, '小华qq': 873541843}
# print(qq.keys()) # dict_keys(['小明qq', '小红qq', '小李qq', '小华qq'])
# print(qq.values()) # dict_values([875897, 5343215, 77582, 873541843])
# print(qq.items()) # dict_items([('小明qq', 875897), ('小红qq', 5343215), ('小李qq', 77582), ('小华qq', 873541843)])
# print(qq.items(0)) # TypeError: dict.items() takes no arguments (1 given)
for i in qq:
print(i, qq[i]) # 迭代:获取 字典的键 和 值
print("*" * 20)
print(qq['小李qq']) # 77582
# print(qq['小李qq'][0][:2]) # TypeError: 'int' object is not subscriptable
# print((qq['小李qq'])[0][:2]) # TypeError: 'int' object is not subscriptable
print(('小李qq',qq['小李qq'])[0][:2]) # 小李
结合注释以及输出,可以对上述加以理解。

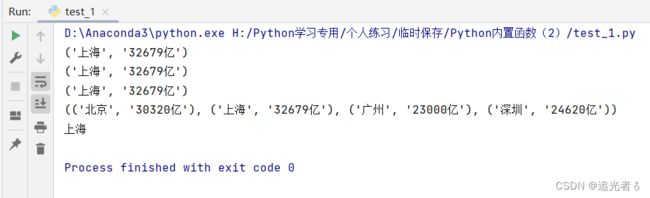
1.2.5.2 通过映射函数创建字典
city = ['北京', '天津', '上海', '长春'] # 城市列表
temperature = ['29', '30', '23', '22'] # 温度列表
dict1 = dict(zip(city, temperature)) # 通过映射函数创建字典
print('温度最低的那组数据为:', min(dict1.items(), key=lambda i: i[1]))
print('温度最低的城市为:', min(dict1.items(), key=lambda i: i[1])[0])
结果:(由上面 人名+qq号码的例子,此处不难理解~)
1.2.5.3 模拟人员技能工资数据
# 模拟人员技能工资数据
dict2 = {'布兰特': {'月薪': 3800, '技能等级': '3级'},
'查尔斯': {'月薪': 2600, '技能等级': '2级'},
'爱德华': {'月薪': 6300, '技能等级': '6级'}}
print('技能等级最低的那位员工是:', list(dict2.keys())[list(dict2.values()).
index(min(dict2.values(), key=lambda i: i['技能等级']))])
print('月薪最低的那个人的技能等级为:', min(dict2.values(), key=lambda i: i['月薪'])['技能等级'])
print('月薪最低值为:', min(dict2.values(), key=lambda i: i['月薪'])['月薪'])
# 将月薪最低人员的工资调整为3500
min(dict2.values(), key=lambda i: i['月薪'])['月薪'] = 3500
print('调整后的人员技能工资数据为:\n', dict2)
输出结果:(此处可细细体会 字典&字典 )

1.3 应用场景
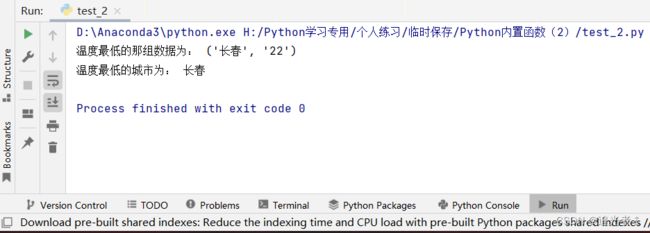
1.3.1 场景一:获取最新上映的电影名称(字典&字典,字典–>>列表)
在获取最新上映的电影名称时,可以通过电影上映的天数来判断该影片是否为新上映的电影,
上映的天数越少说明该影片为刚上应的影片。代码如下:
# 昵 称:XieXu & CSDN@追光者♂
# 时 间: 2023/4/7/0007 9:50
# 场景一:获取最新上映的电影名称
# 电影信息
dict_film = {'阿拉丁': {'上映天数': 7, '当前票房': '723万', '排片场次': 92533},
'哥斯拉2': {'上映天数': 1, '当前票房': '354万', '排片场次': 6347},
'一条狗的使命': {'上映天数': 14, '当前票房': '198万', '排片场次': 47520}}
print('最近刚上映的那条电影数据为:', min(dict_film.values(), key=lambda i: i.get('上映天数')))
# 获取最新上映的那条电影数据
small_value = min(dict_film.values(), key=lambda i: i.get('上映天数'))
# 将所有电影数据转换为列表,再获取最新上映电影数据在列表中的下标
value_index = list(dict_film.values()).index(small_value)
print('最近刚上映的电影名称为:', list(dict_film.keys())[value_index])
输出结果为:
1.3.2 场景二:获取汽车碰撞测试中分数最低的那项
全球各大品牌的汽车多不胜数,购买者除了喜欢关注车子的外形以及配置以外,最为关系的就是汽车的安全等级,这里通过汽车碰撞测试的数据,查看一下哪项测试的分数最低。代码如下:
# 昵 称:XieXu & CSDN@追光者♂
# 时 间: 2023/4/7/0007 9:56
# 场景二:获取汽车碰撞测试中分数最低的那项
import pandas # 导入pandas模块
# 汽车五星碰撞数据
dict_car = {'日系': {'丰田 RAV4': {'正面碰撞': '16.330分', '正面40%碰撞': '15.810分', '侧面碰撞': '18.000分', '鞭打试验': '7.240分'}},
'韩系': {'现代 途胜': {'正面碰撞': '16.310分', '正面40%碰撞': '15.630分', '侧面碰撞': '18.000分', '鞭打试验': '3.500分'}},
'德系': {'大众 途观L': {'正面碰撞': '14.290分', '正面40%碰撞': '16.100分', '侧面碰撞': '18.000分', '鞭打试验': '3.220分'}}}
values_list = [] # 保存碰撞数据的列表
fraction_list = [] # 保存碰撞测试四项每一项的总分
for values in dict_car.values(): # 遍历第一层车型与碰撞数据
for value in values.values(): # 遍历第二层各车型碰撞数据
values_list.append(value) # 将碰撞数据添加至列表
data = pandas.DataFrame(values_list) # 碰撞数据转换为DataFrame
# 将数据中所有的“分”字去掉,并将分数转换为float类型
for d in data.columns:
data[d] = data[d].map(lambda i: i.replace('分', '')).astype(float)
# 将每个测试项的分数总和添加至列表中
fraction_list.append(str(data[d].sum()))
# 获取最小总分数在列表中的索引值
value_index = fraction_list.index(min(fraction_list))
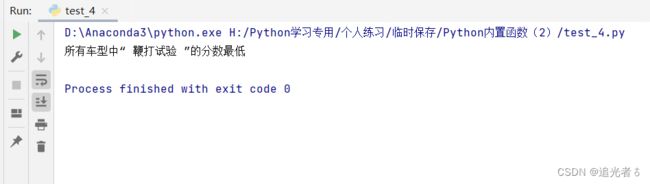
print('所有车型中“', data.columns[value_index], '”的分数最低')
来看结果:(结合注释是比较好理解的~)
1.3.3 场景三:获取二手房指定户型且总价最低的信息
在购买二手房时,不仅需要考虑到资金是否充足,还需要参考户型是否符合自家人员的居住条件,如果以户型为优先选择二手房的条件时,并且不在乎面积大小的情况下,多数用户都会优先查看房价较低的房源信息。这里以畅销户型“2室1厅1卫”为条件获取房价最低的房源信息。代码如下:
# 昵 称:XieXu & CSDN@追光者♂
# 时 间: 2023/4/7/0007 10:00
# 场景三:获取二手房指定户型且总价最低的信息
# 二手房数据
dict_house = {'中天北湾新城': {'总价': 89.0, '户型': '2室1厅1卫', '建筑面积': 89.0, '单价': 10000.0},
'桦林苑': {'总价': 99.8, '户型': '3室2厅2卫', '建筑面积': 143.0, '单价': 6979.0},
'嘉柏湾': {'总价': 32.0, '户型': '1室1厅1卫', '建筑面积': 43.3, '单价': 7390.0},
'中环12区': {'总价': 51.5, '户型': '2室1厅1卫', '建筑面积': 57.0, '单价': 9035.0},
'昊源高格蓝湾': {'总价': 210.0, '户型': '3室2厅2卫', '建筑面积': 160.8, '单价': 13060.0}}
# 获取二手房数据中满足户型为“2室1厅1卫”的信息
data = list(filter(lambda i: i['户型'] == '2室1厅1卫', dict_house.values()))
# 获取满足户型“2室1厅1卫”中总价最低的那条信息
min_data = min(data, key=lambda i: i['总价'])
# 获取总价最低信息的下标位置
value_index = list(dict_house.values()).index(min_data)
# 获取“2室1厅1卫”总价最低的小区名称
name = list(dict_house.keys())[value_index]
print('满足“2室1厅1卫”且总价最低的二手房信息为:\n', name, ':', min_data)
在PyCharm中执行以后,我们可以得到如下结果:

近期分享的题目,都是具有比较强的应用意义。建议大家在练习时,看到题目先考虑一下自己的思路,看能不能有较好的解决方案。然后再看我给出的示例code,可以亲自去执行一下哦!
热门专栏推荐:
- Python&AI专栏:【Python从入门到人工智能】
- 前端专栏:【前端之梦~代码之美(H5+CSS3+JS.】
- 文献精读&项目专栏:【小小的项目 (实战+案例)】
- C语言/C++专栏:【C语言、C++ 百宝书】(实例+解析)
- Java系列(Java基础/进阶/Spring系列/Java软件设计模式等)
- 问题解决专栏:【工具、技巧、解决办法】
- 加入Community 一起追光:追光者♂社区
持续创作优质好文ing哦…✍✍✍
记得一键三连哦!!!
求关注!求点赞!求个收藏啦!
