Dubbo服务调用过程
目录
简单的想想大致流程
调用具体的信息
落地的调用流程
需要一个协议
常见的三种协议形式
Dubbo 协议
需要约定序列化器
序列化协议
粗略的调用流程图
详细的调用流程
调用流程-客户端源码分析
模板方法
路由和负载均衡得到 Invoker
调用的三种方式
调用流程-服务端端源码分析
总结
注意:本文参考 帅地问我:Dubbo服务调用过程
简单的想想大致流程
在分析Dubbo 的服务调用过程前我们先来思考一下如果让我们自己实现的话一次调用过程需要经历哪些步骤?
首先我们已经知晓了远程服务的地址,然后我们要做的就是把我们要调用的方法具体信息告知远程服务,让远程服务解析这些信息。
然后根据这些信息找到对应的实现类,然后进行调用,调用完了之后再原路返回,然后客户端解析响应再返回即可。
调用具体的信息
那客户端告知服务端的具体信息应该包含哪些呢?
首先客户端肯定要告知要调用是服务端的哪个接口,当然还需要方法名、方法的参数类型、方法的参数值,还有可能存在多个版本的情况,所以还得带上版本号。
由这么几个参数,那么服务端就可以清晰的得知客户端要调用的是哪个方法,可以进行精确调用!
然后组装响应返回即可,我这里贴一个实际调用请求对象列子。
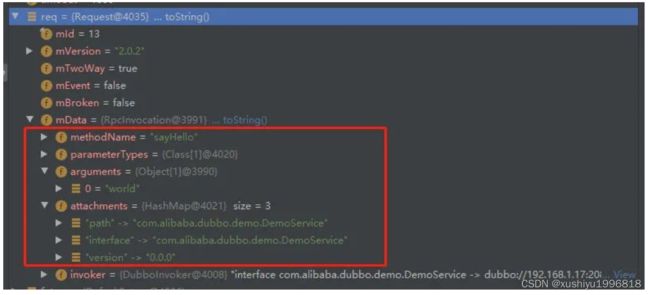
data 就是我所说的那些数据,其他是框架的,包括协议版本、调用方式等等这个下面再分析。
到此其实大致的意思大家都清楚了,就是普通的远程调用,告知请求的参数,然后服务端解析参数找到对应的实现调用,再返回。
落地的调用流程
上面的是想象的调用流程,真实的落地调用流程没有这么简单。
首先远程调用需要定义协议,也就是互相约定我们要讲什么样的语言,要保证双方都能听得懂。
比如我会英语和中文,你也会英语、中文,我们之间要做约定,选定一个语言比如都用中文来谈话,有人说不对啊,你中文夹着的英文我也能听得懂啊。
那是因为你的大脑很智能,它能智能地识别到交流的语言,而计算机可不是,你想想你的代码写 print 1,它还能打出 2 不成?
也就是计算机是死板的,我们的程序告诉它该怎么做,它就会生硬的怎么做。
需要一个协议
所以首先需要双方定义一个协议,这样计算机才能解析出正确的信息。
常见的三种协议形式
应用层一般有三种类型的协议形式,分别是:固定长度形式、特殊字符隔断形式、header+body 形式。
固定长度形式:指的是协议的长度是固定的,比如100个字节为一个协议单元,那么读取100个字节之后就开始解析。
优点就是效率较高,无脑读一定长度就解析。
缺点就是死板,每次长度只能固定,不能超过限制的长度,并且短了还得填充,在 RPC 场景中不太合适,谁晓得参数啥的要多长,定长了浪费,定短了不够。
特殊字符隔断形式:其实就是定义一个特殊结束符,根据特殊的结束符来判断一个协议单元的结束,比如用换行符等等。
这个协议的优点是长度自由,反正根据特殊字符来截断,缺点就是需要一直读,直到读到一个完整的协议单元之后才能开始解析,然后假如传输的数据里面混入了这个特殊字符就出错了。
header+body 形式:也就是头部是固定长度的,然后头部里面会填写 body 的长度, body 是不固定长度的,这样伸缩性就比较好了,可以先解析头部,然后根据头部得到 body 的 len 然后解析 body。
dubbo 协议就是属于 header+body 形式,而且也有特殊的字符 0xdabb ,这是用来解决 TCP 网络粘包问题的。
Dubbo 协议
Dubbo 支持的协议很多,我们就简单的分析下 Dubbo 协议。

协议分为协议头和协议体,可以看到 16 字节的头部主要携带了魔法数,也就是之前说的 0xdabb,然后一些请求的设置,消息体的长度等等。
16 字节之后就是协议体了,包括协议版本、接口名字、接口版本、方法名字等等。
其实协议很重要,因为从中可以得知很多信息,而且只有懂了协议的内容,才能看得懂编码器和解码器在干嘛,我再截取一张官网对协议的解释图。

需要约定序列化器
网络是以字节流的形式传输的,相对于我们的对象来说,我们对象是多维的,而字节流是一维的,我们需要把我们的对象压缩成一维的字节流传输到对端。
然后对端再反序列化这些字节流变成对象。
序列化协议
其实从上图的协议中可以得知 Dubbo 支持很多种序列化,我不具体分析每一种协议,就大致分析序列化的种类,万变不离其宗。
序列化大致分为两大类,一种是字符型,一种是二进制流。
字符型的代表就是 XML、JSON,字符型的优点就是调试方便,它是对人友好的,我们一看就能知道那个字段对应的哪个参数。
缺点就是传输的效率低,有很多冗余的东西,比如 JSON 的括号,对于网络传输来说传输的时间变长,占用的带宽变大。
还有一大类就是二进制流型,这种类型是对机器友好的,它的数据更加的紧凑,所以占用的字节数更小,传输更快。
缺点就是调试很难,肉眼是无法识别的,必须借用特殊的工具转换。
更深层次的就不深入了,序列化还是有很多门道的,以后有机会再谈。
Dubbo 默认用的是 hessian2 序列化协议。
所以实际落地还需要先约定好协议,然后再选择好序列化方式构造完请求之后发送。
粗略的调用流程图
我们来看一下官网的图。

简述一下就是客户端发起调用,实际调用的是代理类,代理类最终调用的是 Client (默认Netty),需要构造好协议头,然后将 Java 的对象序列化生成协议体,然后网络调用传输。
服务端的 NettyServer接到这个请求之后,分发给业务线程池,由业务线程调用具体的实现方法。
但是这还不够,因为 Dubbo 是一个生产级别的 RPC 框架,它需要更加的安全、稳重。
详细的调用流程

前面已经分析过了客户端也是要序列化构造请求的,为了让图更加突出重点,所以就省略了这一步,当然还有响应回来的步骤,暂时就理解为原路返回,下文会再做分析。
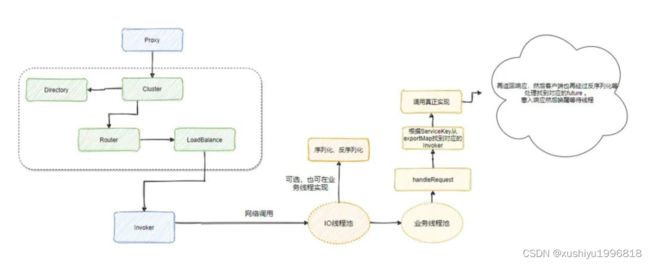
可以看到生产级别就得稳,因此服务端往往会有多个,多个服务端的服务就会有多个 Invoker,最终需要通过路由过滤,然后再通过负载均衡机制来选出一个 Invoker 进行调用。
当然 Cluster 还有容错机制,包括重试等等。
请求会先到达 Netty 的 I/O 线程池进行读写和可选的序列化和反序列化,可以通过 decode.in.io控制,然后通过业务线程池处理反序列化之后的对象,找到对应 Invoker 进行调用。
调用流程-客户端源码分析
客户端调用一下代码。
String hello = demoService.sayHello("world");
调用具体的接口会调用生成的代理类,而代理类会生成一个 RpcInvocation 对象调用 MockClusterInvoker#invoke方法。
此时生成的 RpcInvocation 如下图所示,包含方法名、参数类和参数值。
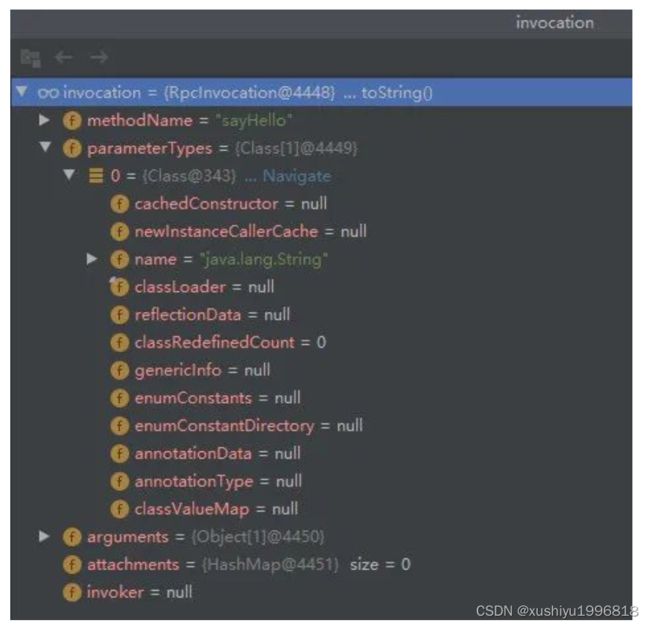
然后我们再来看一下 MockClusterInvoker#invoke 代码。
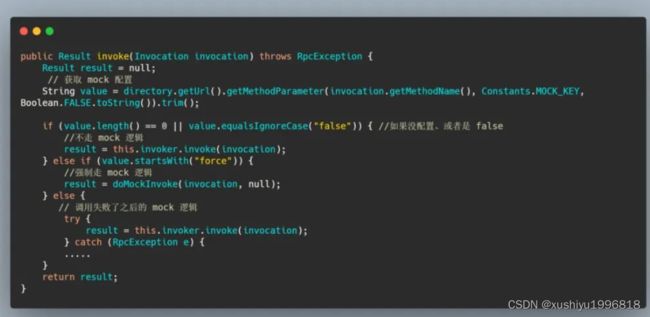
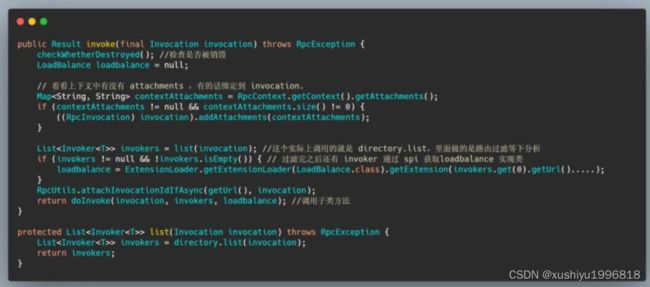
可以看到就是判断配置里面有没有配置 mock, mock 的话就不展开分析了,我们来看看 this.invoker.invoke 的实现,实际上会调用 AbstractClusterInvoker#invoker 。
模板方法
这其实就是很常见的设计模式之一,模板方法。如果你经常看源码的话你知道这个设计模式真的是太常见的。
模板方法其实就是在抽象类中定好代码的执行骨架,然后将具体的实现延迟到子类中,由子类来自定义个性化实现,也就是说可以在不改变整体执行步骤的情况下修改步骤里面的实现,减少了重复的代码,也利于扩展,符合开闭原则。
在代码中就是那个 doInvoke由子类来实现,上面的一些步骤都是每个子类都要走的,所以抽到抽象类中。
路由和负载均衡得到 Invoker
我们再来看那个 list(invocation),其实就是通过方法名找 Invoker,然后服务的路由过滤一波,也有再造一个 MockInvoker 的。
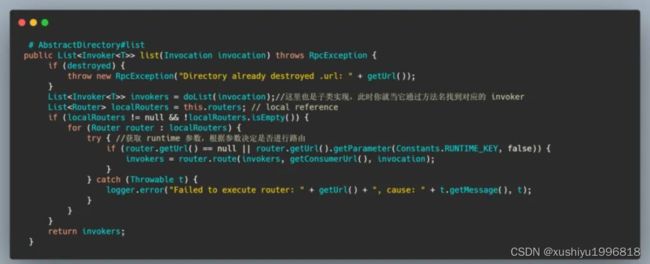
然后带着这些 Invoker 再进行一波 loadbalance 的挑选,得到一个 Invoker,我们默认使用的是 FailoverClusterInvoker,也就是失败自动切换的容错方式,其实关于路由、集群、负载均衡是独立的模块,如果展开讲的话还是有很多内容的,所以需要另起一篇讲,这篇文章就把它们先作为黑盒使用。
稍微总结一下就是 FailoverClusterInvoker 拿到 Directory 返回的 Invoker 列表,并且经过路由之后,它会让 LoadBalance 从 Invoker 列表中选择一个 Invoker。
最后FailoverClusterInvoker会将参数传给选择出的那个 Invoker 实例的 invoke 方法,进行真正的远程调用,我们来简单的看下 FailoverClusterInvoker#doInvoke,为了突出重点我删除了很多方法。
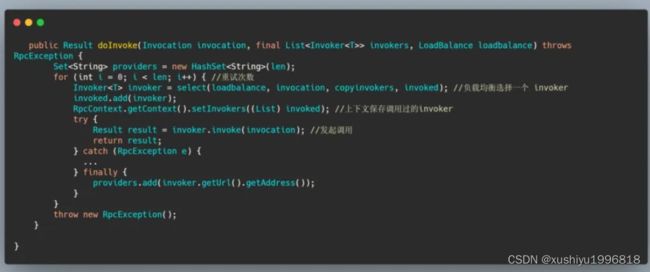
发起调用的这个 invoke 又是调用抽象类中的 invoke 然后再调用子类的 doInvoker,抽象类中的方法很简单我就不展示了,影响不大,直接看子类 DubboInvoker 的 doInvoke 方法。

调用的三种方式
从上面的代码可以看到调用一共分为三种,分别是 oneway、异步、同步。
oneway还是很常见的,就是当你不关心你的请求是否发送成功的情况下,就用 oneway 的方式发送,这种方式消耗最小,啥都不用记,啥都不用管。
异步调用,其实 Dubbo 天然就是异步的,可以看到 client 发送请求之后会得到一个 ResponseFuture,然后把 future 包装一下塞到上下文中,这样用户就可以从上下文中拿到这个 future,然后用户可以做了一波操作之后再调用 future.get 等待结果。
同步调用,这是我们最常用的,也就是 Dubbo 框架帮助我们异步转同步了,从代码可以看到在 Dubbo 源码中就调用了 future.get,所以给用户的感觉就是我调用了这个接口的方法之后就阻塞住了,必须要等待结果到了之后才能返回,所以就是同步的。
可以看到 Dubbo 本质上就是异步的,为什么有同步就是因为框架帮我们转了一下,而同步和异步的区别其实就是future.get 在用户代码被调用还是在框架代码被调用。
再回到源码中来,currentClient.request 源码如下就是组装 request 然后构造一个 future 然后调用 NettyClient 发送请求。

我们再来看一下 DefaultFuture 的内部,你有没有想过一个问题,因为是异步,那么这个 future 保存了之后,等响应回来了如何找到对应的 future 呢?
这里就揭秘了!就是利用一个唯一 ID。

可以看到 Request 会生成一个全局唯一 ID,然后 future 内部会将自己和 ID 存储到一个 ConcurrentHashMap。这个 ID 发送到服务端之后,服务端也会把这个 ID 返回来,这样通过这个 ID 再去ConcurrentHashMap 里面就可以找到对应的 future ,这样整个连接就正确且完整了!
我们再来看看最终接受到响应的代码,应该就很清晰了。
先看下一个响应的 message 的样子:
Response [id=14, version=null, status=20, event=false, error=null, result=RpcResult [result=Hello world, response from provider: 192.168.1.17:20881, exception=null]]
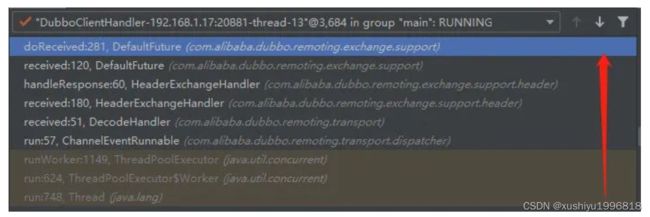
看到这个 ID 了吧,最终会调用 DefaultFuture#received的方法。
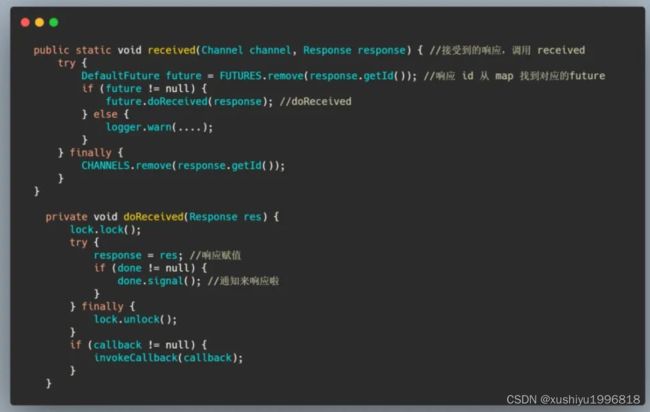
为了能让大家更加的清晰,我再画个图:

到这里差不多客户端调用主流程已经很清晰了,其实还有很多细节,之后的文章再讲述,不然一下太乱太杂了。
发起请求的调用链如下图所示:
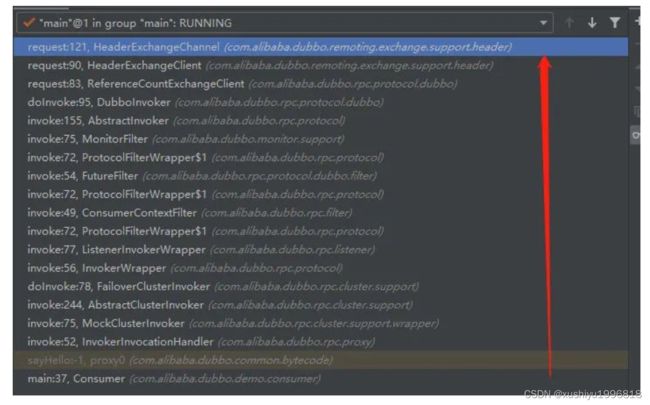
处理请求响应的调用链如下图所示:
调用流程-服务端端源码分析
服务端接收到请求之后就会解析请求得到消息,这消息又有五种派发策略:

默认走的是 all,也就是所有消息都派发到业务线程池中,我们来看下 AllChannelHandler 的实现。

就是将消息封装成一个 ChannelEventRunnable 扔到业务线程池中执行,ChannelEventRunnable 里面会根据 ChannelState 调用对于的处理方法,这里是 ChannelState.RECEIVED,所以调用 handler.received,最终会调用 HeaderExchangeHandler#handleRequest,我们就来看下这个代码。
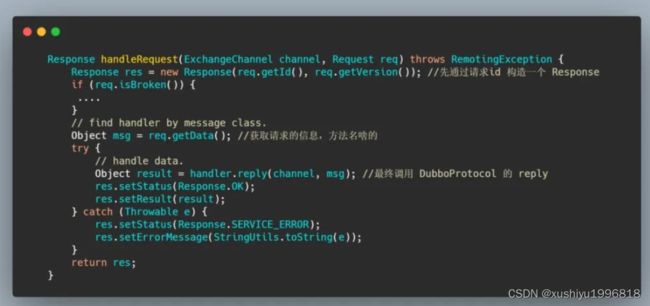
这波关键点看到了吧,构造的响应先塞入请求的 ID,我们再来看看这个 reply 干了啥。

最后的调用我们已经清楚了,实际上会调用一个 Javassist 生成的代理类,里面包含了真正的实现类,之前已经分析过了这里就不再深入了,我们再来看看getInvoker 这个方法,看看怎么根据请求的信息找到对应的 invoker 的。

关键就是那个 serviceKey, 还记得之前服务暴露将invoker 封装成 exporter 之后再构建了一个 serviceKey将其和 exporter 存入了 exporterMap 中吧,这 map 这个时候就起作用了!
这个 Key 就长这样:

找到 invoker 最终调用实现类具体的方法再返回响应整个流程就完结了,我再补充一下之前的图。
总结
今天的调用过程我再总结一遍应该差不多了。
首先客户端调用接口的某个方法,实际调用的是代理类,代理类会通过 cluster 从 directory 中获取一堆 invokers(如果有一堆的话),然后进行 router 的过滤(其中看配置也会添加 mockInvoker 用于服务降级),然后再通过 SPI 得到 loadBalance 进行一波负载均衡。
这里要强调一下默认的 cluster 是 FailoverCluster ,会进行容错重试处理,这个日后再详细分析。
现在我们已经得到要调用的远程服务对应的 invoker 了,此时根据具体的协议构造请求头,然后将参数根据具体的序列化协议序列化之后构造塞入请求体中,再通过 NettyClient 发起远程调用。
服务端 NettyServer 收到请求之后,根据协议得到信息并且反序列化成对象,再按照派发策略派发消息,默认是 All,扔给业务线程池。
业务线程会根据消息类型判断然后得到 serviceKey 从之前服务暴露生成的 exporterMap 中得到对应的 Invoker ,然后调用真实的实现类。
最终将结果返回,因为请求和响应都有一个统一的 ID, 客户端根据响应的 ID 找到存储起来的 Future, 然后塞入响应再唤醒等待 future 的线程,完成一次远程调用全过程。
而且还小谈了下模板方法这个设计模式,当然其实隐藏了很多设计模式在其中,比如责任链、装饰器等等,没有特意挑开来说,源码中太常见了,基本上无处不在。