SSM学习半个月后的笔记整理,希望对你有帮助
在Typora上写完搬上来的。格式可能有点怪,见谅。
目录
一.Spring
1.IOC容器----Inversion of Control Containers and the Dependency Injection pattern
2.AOP------Aspect Oriented Programming
二.SpringMVC-----和秋名山跑道一样绕
1.SpringMVC流程
2.SpringMVC的操作
3.SpringMVC使用的设计模式
4.SpringMVC的优缺点
三.Mybatis------持久层的框架
前言:我遇到的Mybatis
进入Mybatis
1.什么是Mybatis
2.Mybatis的工作流程
3.Mybatis的使用
4.一级缓存和二级缓存
四.SSM框架小结
ssm框架由Spring,SpringMVC,Mybatis三大框架组成。
一.Spring
Spring 是ssm框架项目的粘合剂。整个项目中的装配bean的大工厂,在配置文件中可以是使用特点的参数(别名)去调用实体类的构造方法来实例化对象。Spring 框架的两大灵魂:IOC和AOP;
1.IOC容器----Inversion of Control Containers and the Dependency Injection pattern
IOC容器是Spring的核心,同时也是典型的工厂模式。最基本的技术就是“反射(Reflection)”编程。由Spring来负责控制对象的生命周期和对象间的关系。
IOC容器的两种叫法,是基于不同方面理解得出的名称
-
控制反转
java基础中,创建一个对象都是通过new Object();进行创建所需要的对象。代码之间被紧紧的联系在一起。代码的复用性降低,维护的成本也变大起来。这种在代码编译时候就已经创建好了对象。(当A对象需要B对象时候,需要在代码中new B();)引入IOC后,代码之间解耦。在代码运行到需要一个新的对象时候。就实例化对象。(主动创建B对象去注入A对象中)。
这种B对象实例化的改变:手写代码new B();到 IOC容器 主动创建B对象注入A对象。对象实例化的过程就交给了IOC容器完成。实例化对象的这种控制权就交到IOC容器手中。就被称为 控制反转
-
依赖注入
依赖注入和控制反转是同一个概念的东西。在控制反转的解释中,A对象依赖B对象,所以IOC主动创建B对象注入A对象中,
也被称作 依赖注入
缺点:只有第一条看得懂,因为刚接触的时候。对于这种编程方式还是挺难受的。代码量减少太多了

2.AOP------Aspect Oriented Programming
在以往的编程中,都是使用面对对象编程(OOP)。慢慢的衍生了一种新的编程思想(AOP)。
AOP的设计模式在GOF书中提到(看不懂)

希望以后有时间可以阅读这本书--《Design Patterns: Elements of Reusable Object-Oriented Software》
初学ssm框架两个星期,对于AOP理解如下:
一种可以在指定的代码运行前或许运行后 再执行指定的代码的技术。比如在方法运行前执行某个操作,也被称为:对某个方法增强
切点:@Pointcut("execution(* com.aijava.springcode.service...(..))")
execution的详解
通知的注解方式如下

网上有一篇文章结尾对于aop写的很好引用如下
Spring中的AOP代理可以使JDK动态代理,也可以是CGLIB代理,前者基于接口,后者基于子类。
Spring中的AOP代理还是离不开Spring的IOC容器,代理的生成,管理及其依赖关系都是由IOC容器负责,Spring默认使用JDK动态代理,在需要代理类而不是代理接口的时候,Spring会自动切换为使用CGLIB代理,不过现在的项目都是面向接口编程,所以JDK动态代理相对来说用的还是多一些。
为什么觉得好:因为想到面试的时候被问到aop可以这样子回答,而动态代理使用这两种方式实现。然后可以对将动态代理将给面试官。显得开放性思维。
AOP应用:日志的打印,事务的控制,对控制层入参时候对参数的校验。对于我,目前就使用了前三个AOP的应用。
重点!!!(初学者,所以觉得很新颖)
网上看到一个很让人惊讶的应用,既然是面对切面代理,那不可以对于某一个bug进行替换。将有问题的方法换成正确的方法进行执行。
百度得到的AOP应用场景如图

缺点:百度的时候看到如图
总结:AOP基于OOP编程,是一种思想。如何使用,如何正确使用???
二.SpringMVC-----和秋名山跑道一样绕

的图片已经介绍了SpringMVC和优点。
但是面试造火箭,SpringMVC具体是怎么实现的也是要会的。
每次搜SpringMVC的流程,看的头发蒙。有一次看到一个pdf写的很好,我就复制粘贴放这里了
1.SpringMVC流程
SpringMVC流程图
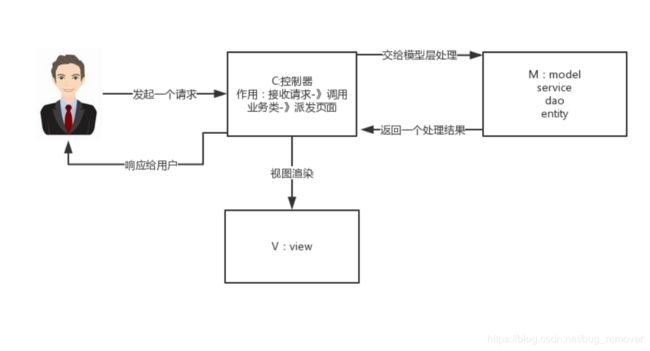
下图才是SpringMVC内部实现的原理

是不是看到这张图直接自闭了(初学者)哈哈哈哈哈 需要多看几十遍图片。先在脑海里面有个大概思路。
其实很好理解 又不是很好理解。因为东西不难看懂,但是组合起来显得很复杂。
首先知道前端控制器(DispatcherServlet)本身并没有干什么事,只是接收一下请求和转发请求给其他程序处理,接收处理的结果。
url从用户鼠标点击页面后发送到这个前端控制器(DispathcherServlet),然后就转发url咯!请求各种各样当然需要解析,很自然的就到了处理映射器(HandlerMapping)。
这个处理映射器(HandlerMapping)的功能就是:负责url、参数、content-type、method等匹配。 然后返回一个叫做HandlerExecutionChain(执行链)给前端控制器(DispatcherServlet)。
这时候前端控制器(DispatcherServlet)就接收处理映射器(HandlerMapping)的返回结果,然后转发给HandlerAdatper(处理器适配器)。请求HandlerAdatper(处理器适配器)去执行Handler(处理器)。
HandlerAdatper(处理器适配器)就获取得到前端控制器转发来的 handler Object(处理器对象),根据Handler规则执行不同的Handler(处理器)
所以这里HandlerAdatper(处理器适配器)执行完后就会返回ModleAndView(模型和视图)给前端控制器(DispatcherServlet)
前端控制器(DispatcherServlet)接收到ModleAndView(模型和视图)后将其转发给视图解析器(ViewResolver)(发送请求进行视图解析)视图解析器(ViewResolver)将前端控制器(DispatcherServlet)发来的ModleAndView(模型和视图)对象进行解析,将逻辑视图匹配对应的物理视图。并且将封装成一个View对象(视图对象)。将View对象(视图对象)返回给前端控制器(DispatcherServlet)。
前端控制器(DispatcherServlet)调用View中的render()方法对物理视图进行渲染。(即将模型数据填充至视图中),然后响应给用户。这时候才得到我们前端页面看到的东西----响应体
至此,SpringMVC的流程才结束。在我们编码的过程中,只需要开发处理适配器(HandlerAdatper),Handler(处理器,后端控制器),视图(就是前端页面)。
再补充一下SpringMVC的三大组件
-
处理器映射器(HandlerMapping)
-
处理器适配器(HandlerAdatper)
-
视图解析器(ViewResolver)
2.SpringMVC的操作
上面介绍了SpringMVC的流程,下面就讲讲SpringMVC的一些操作。
常用的注解 @Controller、@RestController、 @RequestMapping、@PathVariable、@RequestParam 以及 @RequestBody
| @Controller | @controller注解通常用于类上 |
|---|---|
| @RestController | @RestController = @Controller + @ResponseBody |
| @RequestMapping | 比较常用的有三个属性:value、method 和 produces。 |
| @PathVariable | 主要用来获取 URL 参数 |
| @RequestParam | 也是获取请求参数的 |
| @RequestBody | 注解实现接收http请求的json数据,将json转换为java对象。 |
| @ResponseBody | 注解实现将conreoller方法返回对象转化为json对象响应给客户。 |
@PathVariable和@RequestParam的区别

SpringMVC实现重定向和转发的操作:
(1)转发:在返回值前面加"forward:",譬如"forward:/hello.jsp"
(2)重定向:在返回值前面加"redirect:",譬如"redirect:百度一下,你就知道"
3.SpringMVC使用的设计模式
(1)工厂模式:BeanFactory就是简单工厂模式的体现,用来创建对象的实例;
(2)单例模式:Bean默认为单例模式。
(3)代理模式:Spring的AOP功能用到了JDK的动态代理和CGLIB字节码生成技术;
(4)模板方法:用来解决代码重复的问题。比如. RestTemplate, JmsTemplate, JpaTemplate。
(5)观察者模式:定义对象键一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它 的对象都会得到通知被制动更新,如Spring中listener的实现--ApplicationListener。
4.SpringMVC的优缺点
优缺点:比较多,我就直接拿别人整理好的。借鉴,不是剽窃。(哈哈哈哈哈)

SpringMVC就到这里结束了,下面进入Mybatis的篇章
三.Mybatis------持久层的框架
前言:我遇到的Mybatis
简单性是MyBatis数据映射器相对于对象关系映射工具的最大优势。----翻译官方中的一句话
越简单,意味着框架封装的东西越多。所以让我们踏进Mybatis的大门吧!
进入Mybatis
我们之前都是使用dao层,JDBC的连接数据库或者数据库连接池,例如Druid(德鲁伊)连接池,C3p0连接池。JDBC的连接十分繁琐,Druid(德鲁伊)其实也是一个比较强大的连接池,因为它是阿里出品,淘宝和支付宝专用数据库连接池。C3p0是一个开放源代码的JDBC连接池。在1.0版本的时候我们都是JDBC连接数据库,加上事务控制就要苦死苦活了。后面有了数据库连接池,确实爽。(感谢我学生年代的最后一个老师-陈)。后面’陈‘又教了Mybatis框架。从JDBC到数据库连接池再到Mybatis,一步一步攀登!
1.什么是Mybatis
Mybatis是一个持久层的框架技术,同时也被叫做半自动的ORM(Object Relational Mapping)的框架技术。
Hibernate 属于全自动 ORM 映射工具,使用 Hibernate 查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。而 Mybatis 在查询关联对象或关联集合对象时,需要手动编写 sql 来完成,所以,称之为半自动 ORM 映射工具。
MyBatis:机械工具,使用方便,拿来就用,但工作还是要自己来作,不过工具是活的,怎么使由我决定。(小巧、方便、高效、简单、直接、半自动)
Hibernate:智能机器人,但研发它(学习、熟练度)的成本很高,工作都可以摆脱他了,但仅限于它能做的事。(强大、方便、高效、复杂、绕弯子、全自动)
2.Mybatis的工作流程
Mybatis流程图
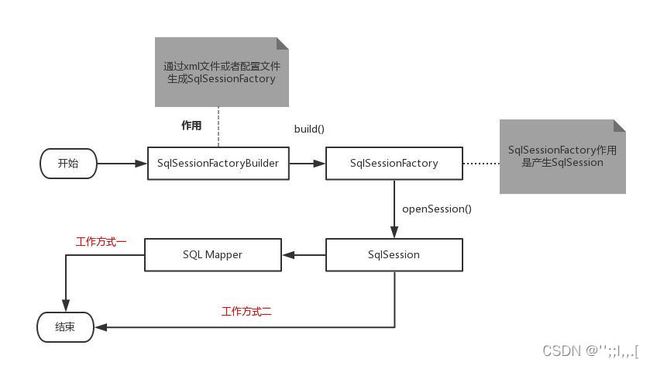
SqlSessionFactoryBuilder是利用XML或者Java编码获得资源来构建SqlSessionFactory。通过它可以构建过个SqlSessionFactory。它的作用就是一个构建器,一旦我们构建了SqlSessionFactory,它的作用也就消失了.生命周期就是方法的开始到方法的结束。
SqlSessionFactoryBuilder的作用就是创建SqlSessionFactory
SqlSessionFactory是线程安全的,它一旦被创建,应该在应用执行期间都存在。在应用运行期间不要重复创建多次,建议使用单例模式。
一般在配置文件会提前配置好DataSource,然后在SqlSessionFactory中使用。
SqlSessionFactory用于创建SqlSession,一般是从Connection或者DataSource中创建。
SqlSession里面就包含了增删改查的方法
SqlSession提供select/insert/update/delete方法,在旧版本中使用使用SqlSession接口的这些方法,但是新版的Mybatis中就会建议使用Mapper接口的方法。
Mybatis的流程比较简单,目前认知还在浅水区。流程过程就是通过FactoryBuilder构建Factory--Factory构建SqlSession--然后使用SqlSession。
3.Mybatis的使用
3.1 ${}和#{}
在JDBC的时候我们就学过Preparedstament的用法,就是为了防止sql语句的注入。增加安全性,提高代码的可读性、可维护性,效率更高。同样的,在Mybatis的使用中#{}来防止sql语句的注入和实现预编译。达到增加安全性,提高代码的可读性、可维护性,效率更高。所以${}就是直接与sql语句拼接,然后在执行数据库语句。
预编译: 校验sql语句的语法!先把sql模板给数据库,数据库先进行校验,再进行编译。执行时只是把参数传递过去而已! 若二次执行时,就不用再次校验语法,也不用再次编译!直接执行!
3.2 一对多和多对一
一对多
如果你要查询一个用户有多少个地址,这就形成了一对多。那么接受这个新的返回值就需要一个新的实体类,或者在原有的实体类上新增地址集合属性。之后使用
多对一
你看的所有书都属于一个作者,这就形成多对多。与一对多同理,加属性或者建新的实体类。然后通过
补充,一般只用到前面两个,当然还有多对多。实际也和前面两个,衍生出来的。看教程,有点晦涩
3.3分页设置
MyBatis使用RowBounds实现的分页是逻辑分页,也就是先把数据记录全部查询出来,然在再根据 offset 和 limit 截断记录返回。
在DefaultResultSetHandler中,逻辑分页会将所有的结果都查询到,然后根据RowBounds中提供的offset和limit值来获取最后的结果/
分页其实很简单,就是已经将返回值封装好了,然后看需要的是那一页的值就 return 。
4.一级缓存和二级缓存
4.1缓存
缓存能干吗?什么时候用缓存?---------对于缓存的解释我也难以说清,但是是个程序员都知道缓存这个概念。对于编程来说,所谓的缓存就是将程序或者系统经常用到的对象(数据)存在内存中。这样子就可以快速使用,不必每一次都去获取程序或者对象。这样子可以加快效率,减少资源开销。适用缓存的数据:大部分时候都要用到,如果数据改变,又不易造成影响的数据。不适用缓存的地方就是对数据的正确性要求高,会造成较大影响的数据。
那么Mybatis的一级缓存和二级缓存又是什么?
4.2一级缓存
Mybatis是默认开启一级缓存的。存储了我们查询的数据。因为开发中百分之七十的sql都是查询。Mybatis将查询到的结果存在Map中,当下次查询的时候,就直接取出数据返回结果。但是SqlSession的增删改和关闭被调用的时候。就会将一级缓存的数据清空。那么问题来了,SqlSession每次执行完后都会自动关闭,一级缓存就被清空。那怎么确保第二次查询同样的sql语句是从一级缓存里面获取?那就需要Spring的事务配置了。这样子对于同一个Service层使用的是同一个SqlSession。这样子就可以确保两次执行都是同一个SqlSession。
4.3二级缓存
一级缓存的出现,可以很好解释原因。那么二级缓存的出现,就是趋于数据库的操作多起来。就可能存在多个SqlSession执行同一条sql语句需要执行数据库多次。那么二级缓存就产生了--化多为一!
二级缓存是默认不开启的,而且和SqlSession没有关系。所以多个SqlSession可以使用同一个Mapper的二级缓存。但是执行增删改操作也会清空二级缓存。二级缓存是基于namespace(命名空间)和mapper(映射文件)的作用域起作用的。下面图片开启二级缓存的方法(cache标签也有很多属性)

小细节:需要给对应的pojo对象添加序列化,因为二级缓存的介质多种多样。不一定在缓存里。
4.4小结
虽然还有一个自定义缓存,但是感觉离我太过于遥远。希望有机会用到。Mybatis的缓存执行流程有一张图画的很好。下面就copy B站狂神的一张图片。用了别人的图,就得广告一下。这是B站搜“BV1NE411Q7Nx”的29集

四.SSM框架小结
笔记没有那么详细,但是百度了很多东西整理出来的,就算是取其精华吧。第一次写五千字的笔记。也将是我的第一篇博客。挺好的!
——— 那些头发茂盛的人。