使用贝叶斯算法完成文档分类问题
贝叶斯原理
贝叶斯原理(Bayes' theorem)是一种用于计算条件概率的数学公式。它是以18世纪英国数学家托马斯·贝叶斯(Thomas Bayes)的名字命名的。贝叶斯原理表达了在已知某个事件发生的情况下,另一个事件发生的概率。具体而言,它可以用来计算某个假设的后验概率,即在已知一些先验概率的情况下,根据新的证据来更新这些概率。贝叶斯原理的数学表达式为:
P(A|B) = P(B|A) * P(A) / P(B)
其中,P(A|B)表示在B发生的条件下A发生的概率,也称为后验概率;P(B|A)表示在A发生的条件下B发生的概率,也称为似然度;P(A)和P(B)分别表示A和B的先验概率,即在考虑任何证据之前,A和B分别发生的概率。上面的解释比较难以理解,下面通过一个实际的例子来看看。
高斯朴素贝叶斯:特征变量是连续变量,符合高斯分布,比如说人的身高,物体的长度。
多项式朴素贝叶斯:特征变量是离散变量,符合多项分布,在文档分类中特征变量体现在一个单词出现的次数,或者是单词的TF-IDF值等。
伯努利朴素贝叶斯:特征变量是布尔变量,符合0/1分布,在文档分类中特征是单词是否出现。
上面介绍了朴素贝叶斯原理,那么如何使用朴素贝叶斯进行文档分类任务呢?下面是使用多项式朴素贝叶斯进行文本分类的demo例子。
# 中文文本分类
import os
import jieba
import warnings
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
warnings.filterwarnings('ignore')
def cut_words(file_path):
"""
对文本进行切词
:param file_path: txt文本路径
:return: 用空格分词的字符串
"""
text_with_spaces = ''
text=open(file_path, 'r', encoding='gb18030').read()
textcut = jieba.cut(text)
for word in textcut:
text_with_spaces += word + ' '
return text_with_spaces
def loadfile(file_dir, label):
"""
将路径下的所有文件加载
:param file_dir: 保存txt文件目录
:param label: 文档标签
:return: 分词后的文档列表和标签
"""
file_list = os.listdir(file_dir)
words_list = []
labels_list = []
for file in file_list:
file_path = file_dir + '/' + file
words_list.append(cut_words(file_path))
labels_list.append(label)
return words_list, labels_list
# 训练数据
train_words_list1, train_labels1 = loadfile('text classification/train/女性', '女性')
train_words_list2, train_labels2 = loadfile('text classification/train/体育', '体育')
train_words_list3, train_labels3 = loadfile('text classification/train/文学', '文学')
train_words_list4, train_labels4 = loadfile('text classification/train/校园', '校园')
train_words_list = train_words_list1 + train_words_list2 + train_words_list3 + train_words_list4
train_labels = train_labels1 + train_labels2 + train_labels3 + train_labels4
# 测试数据
test_words_list1, test_labels1 = loadfile('text classification/test/女性', '女性')
test_words_list2, test_labels2 = loadfile('text classification/test/体育', '体育')
test_words_list3, test_labels3 = loadfile('text classification/test/文学', '文学')
test_words_list4, test_labels4 = loadfile('text classification/test/校园', '校园')
test_words_list = test_words_list1 + test_words_list2 + test_words_list3 + test_words_list4
test_labels = test_labels1 + test_labels2 + test_labels3 + test_labels4
stop_words = open('text classification/stop/stopword.txt', 'r', encoding='utf-8').read()
stop_words = stop_words.encode('utf-8').decode('utf-8-sig') # 列表头部\ufeff处理
stop_words = stop_words.split('\n') # 根据分隔符分隔
# 计算单词权重
tf = TfidfVectorizer(stop_words=stop_words, max_df=0.5)
train_features = tf.fit_transform(train_words_list)
# 上面fit过了,这里transform
test_features = tf.transform(test_words_list)
# 多项式贝叶斯分类器
from sklearn.naive_bayes import MultinomialNB
clf = MultinomialNB(alpha=0.001).fit(train_features, train_labels)
predicted_labels=clf.predict(test_features)
# 计算准确率
print('准确率为:', metrics.accuracy_score(test_labels, predicted_labels))上面的例子中用到了TfidVectorizer来提取特征向量,TfidfVectorizer是Scikit-learn中的一个文本特征提取函数,用于将文本转换为数值特征向量。它的作用是将原始的文本数据集转换为TF-IDF特征向量集。TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于衡量一个词语在文档中的重要性的指标。词频TF计算了一个单词在文档中出现的次数,它认为一个单词的重要性和它在文档中出现的次数呈正比。逆向文档频率IDF,是指一个单词在文档中的区分度。它认为一个单词出现在的文档数越少,就越能通过这个单词把该文档和其他文档区分开。IDF越大就代表该单词的区分度越大。所以TF-IDF实际上是词频TF和逆向文档频率IDF的乘积。这样我们倾向于找到TF和IDF取值都高的单词作为区分,即这个单词在一个文档中出现的次数多,同时又很少出现在其他文档中。这样的单词适合用于分类。TF-IDF的具体计算公式如下:
TF-IDF = TF(t,d) * IDF(t)。 其中,t表示词语,d表示文档,TF(t,d)表示词语t在文档d中出现的频率,IDF(t)表示逆文档频率,可以通过以下公式计算:
IDF(t) = log(N / df(t))。 其中,N表示文档总数,df(t)表示包含词语t的文档数。
TfidfVectorizer函数的主要参数如下:
- stop_words:停用词列表,可以是'english'表示使用Scikit-learn自带的英文停用词列表,也可以是一个自定义停用词列表;
- tokenizer:用于分词的函数,如果不指定,则默认使用Scikit-learn的内置分词器;
- ngram_range:用于控制特征中词语的个数,可以是单个词语(unigram),两个词语(bigram),三个词语(trigram)等;
- max_features:用于控制特征向量的最大维度;
- norm:用于归一化特征向量的方式,可以是'l1'或'l2';
- use_idf:是否使用IDF权重;
- smooth_idf:是否对IDF权重加1平滑处理;
- sublinear_tf:是否使用对数函数对TF进行缩放。
下面是使用TfidfVectorizer将一段文本转换成特征向量的例子。
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(stop_words='english')
documents = [
"This is the first document.",
"This is the second document.",
"And this is the third one.",
]
X = vectorizer.fit_transform(documents)
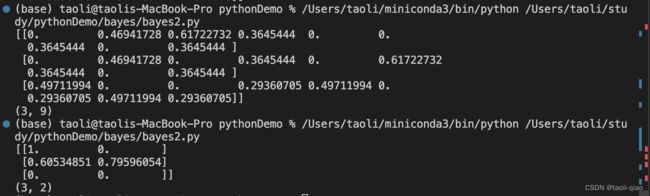
print(X.toarray())
print(X.shape)下面是打印的特征向量结果,使用了X.toarray()方法将稀疏矩阵转换为密集矩阵。,第一个结果是没有传入stop_words的结果,生成的特征向量是一个3行9列的数据,第二个结果是加入stop_words的结果,第二次是一个3行2列的数据。每一行代表一个文档,每一列代表一个特征。可以看到,这些特征是根据词频和逆文档频率计算得到的。