大数据课程D4——hadoop的MapReduce
文章作者邮箱:[email protected] 地址:广东惠州
▲ 本章节目的
⚪ 了解MapReduce的作用和特点;
⚪ 掌握MapReduce的组件;
⚪ 掌握MapReduce的Shuffle;
⚪ 掌握MapReduce的小文件问题;
⚪ 掌握MapReduce的压缩机制;
⚪ 掌握MapReduce的推测执行机制;
⚪ 掌握MapReduce的数据倾斜问题;
一、简介
1. 概述
1. MapReduce是Hadoop提供的一套进行分布式计算机制。
2. MapReduce是Doug Cutting根据Google的论文
3. MapReduce会将整个计算过程拆分为2个阶段:Map阶段和Reduce阶段。在Map阶段,用户需要考虑对数据进行规整和映射;在Reduce阶段,用户需要考虑对数据进行最后的规约。
2. 特点
1. 优点
a. 易于编程:MapReduce提供了相对简单的编程模型。这就保证MapReduce相对易于学习。用户在使用的时候,只需要实现一些接口或者去继承一些类,覆盖需要实现的逻辑,即可实现分布式计算。
b. 具有良好的可扩展性:如果当前集群的性能不够,那么MapReduce能够轻易的通过增加节点数量的方式来提高集群性能。
c. 高容错性:当某一个节点产生故障的时候,MapReduce会自动的将这个节点上的计算任务进行转移而整个过程不需要用户手动参与。
d. 适合于大量数据的计算,尤其是PB级别以上的数据,因此MapReduce更适合于离线计算。
2. 缺点
a. 不适合于实时处理:MapReduce要求处理的数据是静态的,实时的特点在于数据池是动态的。
b. 不擅长流式计算:MapReduce的运行效率相对较低,在处理流式计算的时候,效率更低。
c. 不擅长DAG(有向图)运算:如果希望把上一个MapReduce的运行结果作为下一个MapReduce的输入数据,那么需要手动使用工作流进行调度,而MapReduce本身并没有这种调度功能。
3. 入门案例
1. 案例:统计文件中每一个字符出现的次数(文件:characters.txt)。

2. Hadoop对Windows系统的兼容性不强,所以在Windows中运行Hadoop程序的时候需要添加一些其他的配置 - 配置之后,需要双击winutils.exe,如果出现一个黑色窗口一闪而过,那么没有任何问题;如果双击winutils.exe之后报错,那么将jar目录下的msvcr120.dll文件放到C:\\Windows\\System32目录下,然后再次双击winutils.exe工具,查看是否报错。
3. 配置环境变量:
a. 新建HADOOP_HOME。
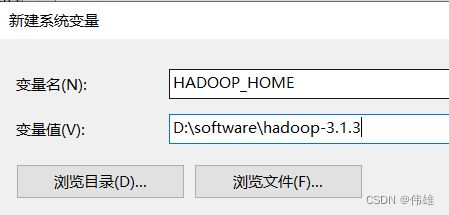
b. 修改Path。

c. 新建HADOOP_USER_NAME。

4. 如果运行程序的时候,出现了null/bin/winutils.exe错误,那么解决方案:
a. 先检查环境变量是否配置正确。
b. 如果环境变量配置正确,但是运行程序依然报错,那么可以在Driver类中添加代码:System.setProperty("hadoop.home.dir", "Hadoop的解压路径")。
5. 如果运行程序的时候,出现了NativeIO$Windows,那么说明Hadoop和Windows系统兼容性不够强,在运行程序的时候,检查出错,解决方案如下:
a. 先检查环境变量是否配置正确。
b. 如果环境变量配置正确,那么可以将Hadoop解压目录的bin目录下的hadoop.dll文件拷贝到C:\\Windows\\System32目录下,再次运行程序查看结果是否正确。
c. 如果上述两种方案依然不能解决问题,那么需要在当前工程下建好对应的包,然后将jar目录下的NativaIO.java拷贝到这个包下。
6. 练习:
a. 统计一个文件中单词出现的次数(文件:words.txt)。
b. IP去重(文件:ip.txt)。
二、组件
1. Writable - 序列化
1. 在MapReduce中,要求被处理的数据能够被序列化。MapReduce提供了单独的序列化机制 - MapReduce底层的序列化机制是基于AVRO实现的。为了方便操作,在AVRO的基础上,MapReduce提供了更简单的序列化形式 - 只需要让被序列化的对象对应的类实现Writable接口,覆盖其中的write和readFields方法。
2. MapReduce针对常见类型提供了基本的序列化类。
| Java类 |
MapReduce的序列化类型 |
| Byte |
ByteWritable |
| Short |
ShortWritable |
| Int |
IntWritable |
| Long |
LongWritable |
| Float |
FloatWritable |
| Double |
DoubleWritable |
| Boolean |
BooleanWritable |
| String |
Text |
| Array |
ArrayWritable |
| Map |
MapWritable |
3. 在MapReduce中,要求被序列化的对象对应的类中必须提供无参构造。
4. 在MapReduce中,要求被序列化的对象的属性值不能为null。
5. 案例:统计一个人花费的上行流量和下行流量(文件:flow.txt)。
2. Partitioner - 分区
1. 在MapReduce中,分区用于将数据按照指定的条件来进行分隔,本质上就是对数据进行分类。
2. 在MapReduce中,如果不指定,那么默认使用的是HashPartitioner。
3. 实际过程中,如果需要指定自己的分类条件,那么需要自定义分区。
4. 案例:分地区统计每一个人花费的总流量(文件:flow.txt)。
5. 在MapReduce中,需要对分区进行编号,编号从0开始依次网上递增。
6. 在MapReduce中,如果不指定,那么默认只有1个ReduceTask,每一个ReduceTask会对应一个结果文件。也因此,如果设置了Partitioner,那么需要给定对应数量的ReduceTask - 分区数决定了ReduceTask的数量。
3. WritableComparable - 排序
1. 在MapReduce中,会自动的对放在键的位置上的元素进行排序,因此要求放在键的位置上的元素对应的类必须实现Comparable。考虑到MapReduce要求被传输的数据能够被序列化,因此放在键的位置上的元素对应的类要考虑实现 - WritableComparable。
2. 案例:对结果文件中的数据按照下行流量来进行排序(目录:serial_flow)。
3. 在MapReduce中,如果需要对多字段进行排序,那么称之为二次排序。
4. 案例:先按照月份进行升序排序;如果是同一个月中,按照利润进行降序排序(文件:profit.txt)。
4. Combiner - 合并
1. 可以在Driver类中通过job.setCombinerClass(XXXReducer.class);来设置Combiner类。
2. Combiner实际上是在不改变计算结果前提的下来减少Reducer的输入数据量。

3. 在实际过程中,如果添加Combiner,那么可以有效的提高MapReduce的执行效率,缩短MapReduce的执行时间。但是需要注意的是,并不是所有的场景都适合于使用Combiner。可以传递运算的场景,建议使用Combiner,例如求和、求积、最值、去重等;但是不能传递的运算,不能使用Combiner,例如求平均值。
5. InputFormat - 输入格式
1. InputFormat发生在MapTask之前。数据由InputFormat来负责进行切分和读取,然后将读取到的数据交给MapTask处理,所以InputFormat读取出来的数据是什么类型,MapTask接收的数据就是什么类型。
2. 作用:
a. 用于对文件进行切片处理
b. 提供输入流用于读取数据
3. 在MapReduce中,如果不指定,那么默认使用是TextInputFormat,而TextInputFormat继承了FileInputFormat。默认情况下,FileInputFormat负责对文件进行切片处理;TextInputFormat负责提供输入流来读取数据。
4. FileInputFormat在对文件进行切片过程中的注意问题:
a. 切片最小是1个字节大小,最大是Long.MAX_VALUE。
b. 如果是一个空文件,则整个文件作为一个切片来进行处理。
c. 在MapReduce中,文件存在可切与不可切的问题。大多数情况下,默认文件是可切的;但是如果是压缩文件,则不一定可切。
d. 如果文件不可切,无论文件多大,都作为一个切片来进行处理。
e. 在MapReduce中,如果不指定,Split和Block等大。
f. 如果需要调小Split,那么需要调小maxSize;如果需要调大Split,那么需要调大minSize。

g. 在切片过程中,需要注意阈值SPLIT_SLOP=1.1。
5. TextInputFormat在读取数据过程中需要注意的问题:
a. TextInputFormat在对文件进行处理之前,会先判断文件是否可切:先获取文件的压缩编码,然后判断压缩编码是否为空。如果压缩编码为空,则说明该文件不是压缩文件,那么默认可切;如果压缩编码不为空,则说明该文件是一个压缩文件,会判断这是否是一个可切的压缩文件。
b. 在MapReduce中,默认只有BZip2(.bz2)压缩文件可切。
c. 从第二个MapTask开始,会从当前切片的第二行开始处理,处理到下一个切片的第一行;第一个MapTask要多处理一行数据;最后一个MapTask要少处理一行数据。这样做的目的是为了保证数据的完整性。

6. 自定义输入格式:定义一个类继承InputFormat,但是考虑到切片过程相对复杂,所以可以考虑定义一个类继承FileInputFormat,而在FileInputFormat中已经覆盖了切片过程,只需要考虑如何实现读取过程即可(文件:score.txt)。
7. 多源输入:在MapReduce中,允许同时指定多个文件作为输入源,而且这多个文件可以放在不同的路径下。这多个文件的数据格式可以不同,可以为每一个文件单独指定输入格式。
6. OutputFormat - 输出格式
1. OutputFormat发生在ReduceTask之后,接收ReduceTask产生的数据,然后将结果按照指定格式来写出。
2. 作用:
a. 校验输出路径,例如检查输出路径不存在。
b. 提供输出流用于将数据写出。
3. 在MapReduce中,如果不指定,默认使用的是TextOutputFormat。 TextOutputFroamt继承了FileOutputFormat。其中,FileOutputFormat负责对输出路径进行校验,TextOutputFormat则是对数据进行写出。
4. 在MapReduce中,也支持自定义输出格式以及多源数据,但是注意,实际开发中自定义输出格式以及多源输出用的非常少。
三、Shuffle
1. Map端的Shuffle
1. 当MapTask调用map方法处理数据之后,会将处理结果进行写出,写出到MapTask自带的缓冲区中。每一个MapTask都会自带一个缓冲区,本质上是一个环形的字节数组,维系在内存中,默认大小是100M。
2. 数据在缓冲区中会进行分区、排序,如果指定了combiner,那么还会进行合并。这次排序是将完全杂乱没有规律的数据整理成有序的数据,所以使用的是快速排序。
3. 当缓冲区使用达到指定阈值(默认是0.8,即缓冲区使用达到80%)的时候,会进行spill(溢写),产生一个溢写文件。因为数据在缓冲区已经分区且排序,所以产生的单个溢写文件中的数据是分好区且排好序的。
4. 溢写之后,MapTask产生的数据会继续写到缓冲区中,如果再次达到条件,会再次进行溢写。每一个溢写都会产生一个新的溢写文件。多个溢写文件之间的数据是局部有序但整体无序的。
5. 当所有数据都处理完成之后,那么MapTask会将所有的溢写文件进行合并(merge),合并成一个大的结果文件final out。在merge的时候,如果有数据依然在缓冲区中,那么会将缓冲区中的数据直接merge到final out中。
6. 在merge过程中,数据会再次进行分区且排序,因此final out中的数据是分好区且排好序的。如果溢写文件个数达到3个及以上,并且指定了Combiner,那么在merge过程中还会进行combine。这次排序是将局部有序的数据整理成整体有序的状态,所以采用的是归并排序。
7. 注意问题:
a. 缓冲区设置为环形的目的减少重复寻址的次数。
b. 设置阈值的目的是为了降低阻塞的几率。
c. 溢写过程不一定会产生。
d. 原始数据的大小并不能决定溢写次数。
e. 溢写文件的大小受序列化因素的影响。

2. Reduce端的Shuffle
1. 当ReduceTask达到启动阈值(默认是0.05,即当有5%的MapTask结束)的时候,就会启动来抓取数据。
2. ReduceTask启动之后,会在当前服务器上来启动多个(默认是5个)fetch线程来抓取数据。
3. fetch线程启动之后,会通过HTTP请求中的get请求来获取数据,在发送请求的时候会携带分区号作为参数。
4. fetch线程会将抓取来的数据临时存储到本地磁盘上,形成一个个的小文件。
5. 当所有的fetch抓取完数据之后,ReduceTask会将这些小文件进行merge,合并成一个大文件。在merge过程中,会对数据再次进行排序。这次排序是将局部有序的数据整理成整体有序的状态,所以采用的是归并排序。
6. merge完成之后,ReduceTask会将相同的键对应的值分到一组去,形成一个(伪)迭代器(本质上是一个基于迭代模式实现的流),这个过程称之为分组(group)。
7. 分组之后,每一个键调用一次reduce方法。

3. MapReduce执行流程

4. Shuffle优化
1. 适当的增大缓冲区。实际过程中,可以缓冲区设置为250M~400M之间。
2. 增加Combiner,但是不是所有场景都适合于使用Combiner。
3. 可以考虑对结果进行压缩传输。如果网络条件比较差,那么可以考虑将final out文件压缩之后再传递给ReduceTask,但是ReduceTask手到数据之后需要进行解压,所以这种方案是在网络传输和压缩解压之间的一种取舍。
4. 适当的考虑fetch线程的数量。
四、扩展
1. 小文件问题
1. 在大数据环境下,希望所处理的文件都是大文件,但是在生产环境中,依然不可避免的会产生很多小文件。
2. 小文件的危害:
a. 存储:每一个小文件在HDFS上都会对应一条元数据。如果有大量的小文件,那么在HDFS中就会产生大量的元数据。元数据过多,就会占用大量的内存,还会导致查询效率变低。
b. 计算:每一个小文件都会对应一个切片,每一个切片会对应一个MapTask(线程)。如果有大量的小文件,就会产生大量的切片,就会导致产生大量的MapTask。如果MapTask过多,那么就会致使服务器的线程的承载压力变大,致使服务器产生卡顿甚至崩溃。
3. 到目前为止,市面上针对小文件的处理手段无非两种:合并和打包。
4. Hadoop针对小文件提供了原生的打包手段:Hadoop Archive,将指定小文件打成一个har包。
2. 压缩机制
1. MapReduce支持对数据进行压缩:可以对MapTask产生的中间结果(final out)进行压缩,也支持对ReduceTask的输出结果进行压缩。
2. 在MapReduce中,默认支持的压缩格式有:Default,BZip2,GZip,Lz4,Spappy,ZStandard,其中比较常用的是BZip2。
3. 推测执行机制
1. 推测执行机制本质上是MapReduce针对慢任务的一种优化。慢任务指的是其他任务都正常执行完,但是其中几个任务依然没有结束,那么这几个任务就称之为慢任务。
2. 一旦出现了慢任务,那么MapReduce会将这个任务拷贝一份放到其他节点上,两个节点同时执行相同的任务,谁先执行完,那么它的结果就作为最终结果;另外一个没有执行完的任务就会被kill掉。
3. 慢任务出现的场景:
a. 任务分配不均匀。
b. 节点性能不一致。
c. 数据倾斜。
3. 在实际生产过程中,因为数据倾斜导致慢任务出现的机率更高,此时推测执行机制并没有效果反而会占用更多的集群资源,所以此时一般会考虑关闭推测执行机制。
4. 推测执行机制配置(放在mapred-site.xml文件中):
4. 数据倾斜
1. 数据倾斜指的是任务之间处理的数据量不均等。例如统计视频网站上各个视频的播放量,那么此时处理热门视频的任务索要处理的数据量就会比其他的任务要多,此时就产生了数据倾斜。
2. Map端的数据倾斜的产生条件:多源输入、文件不可切、文件大小不均等。一般认为Map端的倾斜无法解决。
3. 实际开发中,有90%的数据倾斜发生在了Reduce端,直接原因就是因为是对数据进行分类,本质原因是因为数据本身就有倾斜的特性,可以考虑使用二阶段聚合的方式来处理Reduce端的数据倾斜。
5. join
1. 如果在处理数据的时候,需要同时处理多个文件,且文件相互关联,此时可以考虑将主要处理的文件放在输入路径中,将其他关联文件缓存中,需要的时候再从缓存中将文件取出来处理。
2. 案例:统计每一天卖了多少钱。