整洁架构之道--三种经典的编程范式
本文是《Clean Architecture》--整洁架构之道中关于编程范式相关章节的笔记,首发于公众号「Go 招聘」
前言
之前整理了整洁架构之道这本书前两章节的读书笔记:《clean architecture》第一部分笔记。今天再来分享一下书中第二部分关于编程范式的内容。
第二部分的主题内容
第二部分主要是关于编程范式的讲述,分别从结构化编程、面向对象编程、函数式编程来说明介绍编程范式。
Chap3. PARADIGM OVERVIEW 编程范式总览
STRUCTURED PROGRAMMING 结构化编程
OBJECT-ORIENTED PROGRAMMING 面向对象编程
FUNCTIONAL PROGRAMMING 函数式编程
FOOD FOR THOUGHT 仅供思考
CONCLUSION 本章小结
Chap4. STRUCTURED PROGRAMMING 结构化编程
PROOF 可推导性
A HARMFUL PROCLAMATION goto 是有害的
FUNCTIONAL DECOMPOSITION 功能性降解拆分
NO FORMAL PROOFS 形式化证明没有发生
SCIENCE TO THE RESCUE 科学来救场
TESTS 测试
CONCLUSION 本章小结
Chap5. OBJECT-ORIENTED PROGRAMMING 面向对象编程
THE POWER OF POLYMORPHISM 多态的强大性
DEPENDENCY INVERSION 依赖反转
ENCAPSULATION? 封装
INHERITANCE? 继承
POLYMORPHISM? 多态
CONCLUSION 本章小结
Chap6. FUNCTIONAL PROGRAMMING 函数式编程
SQUARES OF INTEGERS 整数平方
IMMUTABILITY AND ARCHITECTURE 不可变性与软件架构
SEGREGATION OF MUTABILITY 可变性的隔离
EVENT SOURCING 事件溯源
CONCLUSION 本章小结
Chap3. 编程范式总览
三个编程范式
三个编程范式,它们分别是结构化编程(structured programming)、 面向对象编程(object-oriented programming)以及函数式编程(functional programming)。
结构化编程是第一个普遍被采用的编程范式,由 Edsger Wybe Dijkstra 于 1968 年最先提出。结构化编程范式归结为:结构化编程对程序控制权的直接转移进行了限制和规范。
面向对象编程式的提出比结构化编程还早了两年,是在 1966 年由 Ole Johan Dahl 和 Kriste Nygaard 在论文中总结归纳出来的。面向对象编程范式归结为:面向对象编程对程序控制权的间接转移进行了限制和规范。
函数式编程概念是基于与阿兰·图灵同时代的数学家 Alonzo Church 在 1936 年发明的入演算的直接衍生物。函数式编程语言中应该是没有赋值语句的。大部分函数式编程语言只允许在非常严格的限制条件下,才可以更改某个变量的值。函数式编程范式归结为:函数式编程对程序中的赋值进行了限制和规范。
思考和小结
每个编程范式的目的都是设置限制。这些范式主要是为了告诉我们不能做什么,而不是可以做什么。这三个编程范式分别限制了 goto 语句、函数指针和赋值语句的使用。
这三个编程范式可能是仅有的三个了,三个编程范式都是在 1958 年到 1968 年这 10 年间被提出来的,后续再也没有新的编程范式出现过。
这些编程范式的历史知识与软件架构有关系吗?当然有,而且关系相当密切。譬如说多态是我们跨越架构边界的手段,函数式编程是我们规范和限制数据存放位置与访问权限的手段,结构化编程则是各模块的算法实现基础。 这和软件架构的三大关注重点不谋而合:功能性、组件独立性以及数据管理。
Chap4. 结构化编程
可推导性
Dijkstra 认为程序员可以像数学家一样对自己的程序进行推理证明。换句话说,程序员可以用代码将一些已证明可用的结构串联起来。
Dijkstra 在研究过程中发现了一个问题。goto 语句的某些用法会导致某个模块 无法被递归拆分成更小的、可证明的单元,这会导致无法采用分解法来将大型问题进一步拆分成更小的、可证明的部分。
不过两年前Bohm 和 Jocopini 刚刚证明了人们可以用顺序结构、分支结构、循环结构这三种结构构造出任何程序。这个发现非常重要:因为它证明了我们构建可推导模块所需要的控制结构集与构建所有程序所需的控制结构集的最小集是等同的。这样—来,结构化编程就诞生了。
goto 是有害的
随着编程语言的演进,goto 语句的重要性越来越小,最终甚至消失了。如今大部分的现代编程语言中都已经没有了 goto 语句。哦,对了,LISP 里从来就没有过!
功能分解
既然结构化编程范式可将模块递归降解拆分为可推导的单元,这样一来,我们就可以将一个大型问题拆分为一系列高级函数的组合,而这些高级函数各自又可以继续被拆分为一系列低级函数。
测试
Dijkstra 曾经说过“测试只能展示 Bug 的存在,并不能证明不存在 Bug”, 换句话说,一段程序可以由一个测试来证明其错误性,但是却不能被证明是正确的。
小结
结构化编程范式中最有价值的地方就是,它赋予了我们创造可证伪程序单元的能力。这就是为什么现代编程语言一般不支持无限制的 goto 语句。更重要的是,这也是为什么在架构设计领域,功能性分解仍然是最佳实践之一。
Chap5. 面向对象编程
什么是面向对象?一种常见的回答是“数据与函数的组合” 。另一种是面向对象编程是一种对真实世界进行建模 的方式。回答此问题的同时另外还会搬出这三个词语:封装(encapsulation)、继承(inheritance)、多态(polymorphism)。其隐含意思就是说面向对象编程是这三项的有机组合,或者任何一种支持面向对象的编程语言必须支持这三个特性。
封装
通过釆用封装特性,我们可以把一组相关联的数据和函数圈起来,使圈外面的代码只能看见部分函数,数据则完全不可见。这里举了一个c语言版本封装的例子。使用 point.h 的程序是没有 Point 结构体成员的访问权限的。它们只能调用 makePoint() 函数和 distance() 函数,但对它们来说,Point 这个数据结构体的内部细节,以及函数的具体实现方式都是不可见的。
point.h
struct Point;
struct Point* makePoint(double x, double y);
double distance (struct Point *p1, struct Point *p2);point.c
#include "point.h"
#include
#include
struct Point {
double x,y;
};
struct Point* makepoint(double x, double y) {
struct Point* p = malloc(sizeof(struct Point));
p->x = x;
p->y = y;
return p;
}
double distance(struct Point* p1, struct Point* p2) {
double dx = p1->x - p2->x;
double dy = p1->y - p2->y;
return sqrt(dx*dx+dy*dy);
} C++通过在编程语言层面引入 public、private、protected 这些关键词,部分维护了封装性。但所有这些都是为了解决编译器自身的技术实现问题而引入的 hack——编译器由于技术实现原因必须在头文件中看到成员变量的定义。
而 Java 和 C# 则彻底抛弃了头文件与实现文件分离的编程方式,这其实进一步削弱了封装性。因为在这些语言中,我们是无法区分一个类的声明和定义的。
所以我们很难说强封装是面向对象编程的必要条件。而事实上,有很多面向对象编程语言|对封装性并没有强制性的要求。
继承
继承的主要作用是让我们可以在某个作用域内对外部定义的某一组变量与函数进行覆盖。
namedPoint.h
struct NamedPoint;
struct NamedPoint* makeNamedPoint(double x, double y, char* name);
void setName(struct NamedPoint* np, char* name);
char* getName(struct NamedPoint* np);namedPoint.c
#include "namedPoint.h"
#include
struct NamedPoint {
double x,y;
char* name;
};
struct NamedPoint* makeNamedPoint(double x, double y, char* name) {
struct NamedPoint* p = malloc(sizeof(struct NamedPoint));
p->x = x;
p->y = y;
p->name = name;
return p;
}
void setName(struct NamedPoint* np, char* name) {
np->name = name;
}
char* getName(struct NamedPoint* np) {
return np->name;
} main.c
#include "point.h"
#include "namedPoint.h"
#include
int main(int ac, char** av) {
struct NamedPoint* origin = makeNamedPoint(0.0, 0.0, "origin");
struct NamedPoint* upperRight = makeNamedPoint (1.0, 1.0, "upperRight");
printf("distance=%f\n",
distance(
(struct Point*) origin,
(struct Point*) upperRight));
} 可以看出NamedPoint 之所以可以被伪装成 Point 来使用,是因为 NamedPoint 是 Point 结构体的一个超集,同两者共同成员的顺序也是一样的。这种编程方式虽然看上去有些投机取巧,但是在面向对象理论被提出之前,这已经很常见了。其实,C++内部就是这样实现单继承的。在 main.c 中,程序员必须强制将 NamedPoint 的参数类型转换为 Point,而在真正的面向对象编程语言中,这种类型的向上转换通常应该是隐性的。因此,我们可以说,早在面向对象编程语言被发明之前,对继承性的支持就已经存在很久了。
综上所述,我们可以认为,虽然面向对象编程在继承性方面并没有开创出新,但是的确在数据结构的伪装性上提供了相当程度的便利性。分析得出 面向对象编程在封装性上得 0 分,在继承性上勉强可以得 0.5 分(满分为 1)。
多态
在面向编程对象语言被发明之前,我们所使用的编程语言能支持多态吗? 答案是肯定的。那是怎么做的呢?函数指针。调用的方法会指向函数指针指向的函数。UNIX 操作系统强制要求每个 IO 设备都要提供 open、close、read、write 和 seek 这 5 个标准函数。所以IO设备需要支持这些接口函数。为什么 UNIX 操作系统会将 IO 设备设计成插件形式呢?因为自 20 世纪 50 年代末期以来,我们学到了一个重要经验:程序应该与设备无关。 这个经验从何而来呢?因为一度所有程序都是设备相关的,但是后来我们发现自己其实真正需要的是在不同的设备上实现同样的功能。归根结底,多态其实不过就是函数指针的一种应用。自从 20 世纪 40 年代末期冯·诺依曼架构诞生那天起,程序员们就一直在使用函数指针模拟多态了。也就是说,面向对象编程在多态方面没有提出任何新概念。
依赖反转
想象一下在安全和便利的多态支持出现之前,软件是什么样子的。下面有一个典型的调用树的例子如图5.1,main 函数调用了一些高层函数,这些高层函数又调用了一些中层函数,这些中层函数又继续调用了一些底层函数。在这里,系统行为决定了控制流,而控制流则决定了源代码依赖关系。
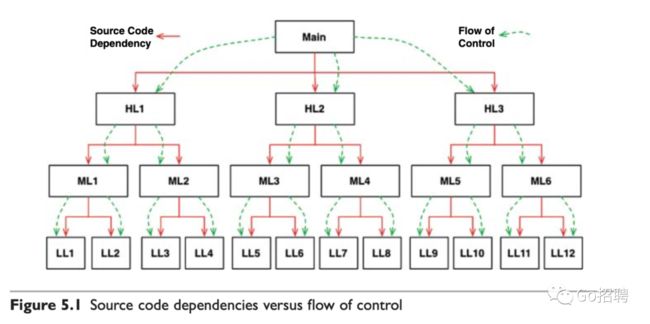
一旦我们使用了多态,情况就不一样了。如图5.2。模块 HL1 调用了 ML1 模块中的 F() 函数,这里的调用是通过源代码级别的接口来实现的。
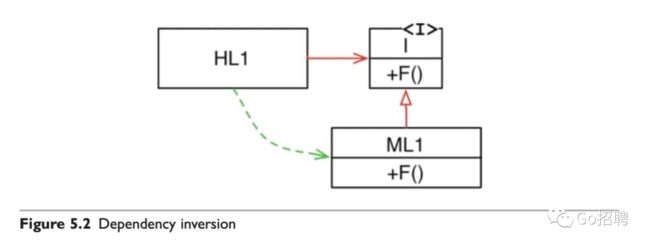
现在,我们可以再回头来看图 5.1 中的调用树,就会发现其中的众多源代码依赖关系都可以通过引入接口的方式来进行反转。通过这种方法,软件架构师可以完全控制采用了面向对象这种编程方式的系统中所有的源代码依赖关系,而不再受到系统控制流的限制。不管哪个模块调用或者被调用,软件架构师都可以随意更改源代码依赖关系。
图5.3 依赖反转可以使数据库模块和用户界面模块都依赖于业务逻辑模块。我们让用户界面和数据库都成为业务逻辑的插件。也就是说,业务逻辑模块的源代码不需要引入用户界面和数据库这两个模块。

这样一来,业务逻辑、用户界面以及数据库就可以被编译成三个独立的组件或者部署单元(例如 jar 文件、DLL 文件、Gem 文件等)了,这些组件或者部署单元的依赖关系与源代码的依赖关系是一致的,业务逻辑组件也不会依赖于用户界面和数据库这两个组件。
业务逻辑组件就可以独立于用户界面和数据库来进行部署了,我们对用户界面或者数据库的修改将不会对业务逻辑产生任何影响,这些组件都可以被分别独立地部署。
如果系统中的所有组件都可以独立部署,那它们就可以由不同的团队并行开发,这就是所谓的独立开发能力。
小结
面向对象编程到底是什么?业界在这个问题上存在着很多不同的说法和意见。然而对一个软件架构师来说,其含义应该是非常明确的:面向对象编程就是以对象为手段来对源代码中的依赖关系进行控制的能力, 这种能力让软件架构师可以构建出某种插件式架构,让高层策略性组件与底层实现性组件相分离,底层组件可以编译成插件,实现独立于高层组件的开发和部署。
Chap6.函数式编程
函数式编程所依赖的原理,在很多方面其实是早于编程本身出现的。因为函数式编程这种范式强烈依赖于 Alonzo Church 在 20 世纪 30 年代发明的 λ 演算。
函数式编程语言中的变量(Variable)是不可变(Vary)的。
不可变性与软件架构
为什么不可变性是软件架构设计需要考虑的重点呢?为什么软件架构帅要操心变量的可变性呢?答案显而易见:所有的竞争问题、死锁问题、并发更新问题都是由可变变量导致的。 如果变量永远不会被更改,那就不可能产生竞争或者并发更新问题。如果锁状态是不可变的,那就永远不会产生死锁问题。
作为一个软件架构师,当然应该要对并发问题保持高度关注。我们需要确保自己设计的系统在多线程、多处理器环境中能稳定工作。
可变性的隔离
一种常见方式是将应用程序,或者是应用程序的内部服务进行切分,划分为可变的和不可变的两种组件。不可变组件用纯函数的方式来执行任务,期间不更改任何状态。这些不可变的组件将通过与一个或多个非函数式组件通信的方式来修改变量状态(参见图 6.1)。
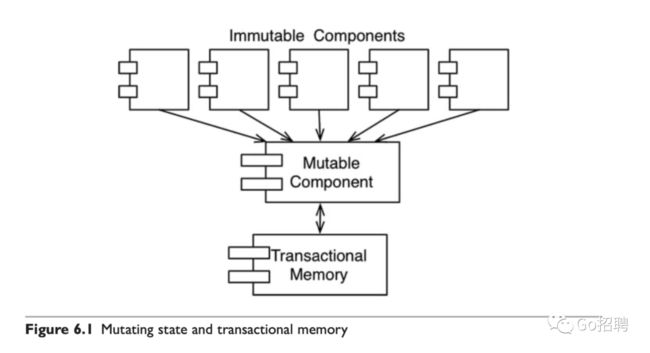
由于状态的修改会导致一系列并发问题的产生,所以我们通常会采用某种事务型内存来保护可变变量,避免同步更新和竞争状态的发生。事务型内存基本上与数据库保护磁盘数据的方式 1 类似,通常釆用的是事务或者重试机制。
这里的要点是:一个架构设计良好的应用程序应该将状态修改的部分和不需要修改状态的部分隔离成单独的组件,然后用合适的机制来保护可变量。
软件架构师应该着力于将大部分处理逻辑都归于不可变组件中,可变状态组件的逻辑应该越少越好。
事件溯源
这里举了个简单的例子,假设某个银行应用程序需要维护客户账户余额信息,当它放行存取款事务时,就要同时负责修改余额记录。
如果我们不保存具体账户余额,仅仅保存事务日志,那么当有人想查询账户余额时。我们就将全部交易记录取出,并且每次都得从最开始到当下进行累计。当然,这样的设计就不需要维护任何可变变量了。
事件溯源,在这种体系下,我们只存储事务记录,不存储具体状态。当需要具体状态时,我们只要从头开始计算所有的事务即可。
这种数据存储模式中不存在删除和更新的情况,我们的应用程序不是 CRUD,而是 CR。因为更新和删除这两种操作都不存在了,自然也就不存在并发问题。如果我们有足够大的存储量和处理能力,应用程序就可以用完全不可变的、纯函数式的方式来编程。
小结
结构化编程是多对程序控制权的直接转移的限制。
面向对象编程是对程序控制权的间接转移的限制。
函数式编程是对程序中赋值操作的限制。
每个范式都约束了某种编写代码的方式,没有一个编程范式是在增加新能力。
我们必须面对这种不友好的现实:软件构建并不是一个迅速前进的技术。今天构建软件的规则和 1946 年阿兰·图灵写下电子计算机的第一行代码时是一样的。尽管工具变化了,硬件变化了,但是软件编程的核心没有变。
总而言之,软件,或者说计算机程序无一例外是由顺序结构、分支结构、循环结构和间接转移这几种行为组合而成的,无可增加,也缺一不可。
总结
名言警句:
三个编程范式,它们分别是结构化编程(structured programming)、 面向对象编程(object-oriented programming)以及函数式编程(functional programming)。
结构化编程范式:对程序控制权的直接转移进行了限制和规范。
面向对象编程范式:对程序控制权的间接转移进行了限制和规范。
函数式编程范式:对程序中的赋值进行了限制和规范。
面向对象编程在封装性上得 0 分,在继承性上勉强可以得 0.5 分(满分为 1)。
多态是我们跨越架构边界的手段,函数式编程是我们规范和限制数据存放位置与访问权限的手段,结构化编程则是各模块的算法实现基础。
如果系统中的所有组件都可以独立部署,那它们就可以由不同的团队并行开发,这就是所谓的独立开发能力。
面向对象编程就是以对象为手段来对源代码中的依赖关系进行控制的能力。
所有的竞争问题、死锁问题、并发更新问题都是由可变变量导致的。
一个架构设计良好的应用程序应该将状态修改的部分和不需要修改状态的部分隔离成单独的组件,然后用合适的机制来保护可变量。
每个范式都约束了某种编写代码的方式,没有一个编程范式是在增加新能力。
软件,或者说计算机程序无一例外是由顺序结构、分支结构、循环结构和间接转移这几种行为组合而成的,无可增加,也缺一不可。
关于整洁架构之道的第二部分关于三种编程范式的记录今天就介绍到这里了。第三部分从设计原则(SOLID)开始,敬请期待。如果有不同见解欢迎留言讨论。
欢迎关注Go招聘公众号,获取Go专题、大厂内推、面经、简历、股文等相关资料。