【Linux】深入理解缓冲区
目录
什么是缓冲区
为什么要有缓冲区
缓冲区刷新策略
缓冲区在哪里
手动设计一个用户层缓冲区
什么是缓冲区
缓冲区本质上一块内存区域,用来保存临时数据。缓冲区在各种计算任务中都广泛应用,包括输入/输出操作、网络通信、图像处理、音频处理等。
这块内存区域是由谁提供的呢,缓冲区在哪里呢?可以继续向下看.
这里先告诉答案,是C标准库提供的.
为什么要有缓冲区
缓冲区用于解决数据传输速度不匹配或不稳定的问题,并提高数据处理的效率。
当从硬盘读取大量数据时,将数据直接传输到内存中可能会导致读写速度不匹配(内存速度快,而硬盘读取速度慢,这是相对来说的),从而导致性能瓶颈。为了缓解这个问题,可以引入一个缓冲区,先将一部分数据读取到缓冲区中,然后再从缓冲区逐步读取数据到内存中,以平衡数据传输速度。
这里有个很合适的例子来解释:
例如你和你的朋友在两个不同的大学,相差大概500公里,有一天你想送一些书给你的朋友,此时你可以选择骑自行车,亲自骑行去送这些书,礼轻情意重嘛,加上中途休息,然后由于速度慢,花了大概一周的时间才到,送了之后然后又骑回自己的学校,又花了一周的时间,一共过了两周完整的工作才完成,耗时太长。
假设此时你学聪明了,既然那么慢,那么直接坐高铁去送,可来回一共都500多了,这都比这些书的价值多了,即成本太高了.
可以把以上这些书看做资源,这种模式叫做写透模式.
此时你想到,可以寄快递来送这些书啊,价格便宜,而且两三天就到了,这多实惠,于是你把这些书交给了顺丰 快递,过了两三天,你的朋友在手机上给你说,说我收到这些书了,然后这样就成功的把资源交到了对方的手中。这个顺丰快递在这里扮演的角色便是缓冲区.
顺丰 拿到你的快递也不是立马就送,而是等待数量足够多时,再一次性开始运输,这相当于是一种缓冲区的刷新策略.
缓冲区刷新策略
刷新策略主要有以下3种:
1.立即刷新
2.行刷新(行缓冲),遇到\n刷新
3.满刷新(全缓冲),指的是将输入或输出的数据完全存储在缓冲区中,然后再进行传输或处理。
当然也会有一些特殊情况:
1.用户强制刷新(fflush)
2.进程退出
遇到以上两种情况时,必须马上从刷新缓冲区的数据,而不要按照之前的刷新策略继续等待.
所以缓冲策略 = 一般情况 + 特殊情况.
一般而言,行缓冲的设备文件 --- 显示器
全缓冲的设备文件 --- 磁盘文件
但所有的设备,永远倾向于全缓冲 --> 缓冲区满了再刷新 --> 需要更少次数的IO操作 -->更少次数的外设访问(相当于提高了整机效率).
有同学可能有疑问,比如10行数据,每一行有100个字节,虽然10行最后再一起刷新,只进行了一次的外设访问,但是数据量很多啊,1000个字节,而按行刷新虽然刷新了10次,但每次数据量少啊,那为什么外设访问次数越少越好呢?
这是因为和外部设备IO的时候,数据量的大小不是主要矛盾,你和外设预备IO的过程是最耗费时间的.
比如你和别人借钱,往往沟通的过程要耗费很长时间,而转账的过程只需要几秒,这同样的道理.
那我们直接改成全缓冲不就行了吗?这样效率不就高了吗,还要什么行缓冲.
其实这些策略,都是根据实际情况做的妥协:
例如行缓冲就是针对于显示器,是给用户看的,一方面要照顾效率,另一方面也要照顾用户体验.
而平常我们打开的一些文本文件便是全缓冲,等到用户全部写完再一次性进行保存.
有了这些缓冲区和策略,便可以提高数据处理的效率.
缓冲区在哪里
为了解决这个问题,我们可以先写以下代码:
int main()
{
//C语言提供的接口
printf("hello,printf\n");
fprintf(stdout,"hello,fprintf\n");
const char* s = "hello,fputs\n";
fputs(s,stdout);
//系统接口
const char* ss = "hello,write\n";
write(1,ss,strlen(s));
//注意这里有一个创建子进程
fork();
}我们这里把创建子进程fork函数放在了最后,这有什么用呢?放在最后子进程什么都没有执行就结束了,有什么意义呢?
我们先把代码运行一下:

可以看到,这些都是正常输出的,没有任何问题.
但我们此时创建一个log.txt文件,然后把输出结果重定向到它里面,然后cat看卡里面的内容:

很奇怪的现象:我们发现除了系统接口的只输出了一次,C语言提供的函数都输出了两次 .
这是什么原因呢?
根据我们上面所讲的缓冲区的刷新策略:
我们直接运行程序是向显示器中打印,采用的是行刷新策略,而我们重定向到文件中,向文件中打印,便成了全缓冲策略.
1.如果是向显示器中打印,那么采用的是行刷新策略,那么最后执行fork的时候,所有的数据都已经刷新完成了,此时再执行fork就没有意义了.
2.如果对程序进行了重定向,即此时要向文件中打印,此时刷新策略便隐式的变成了全缓冲,
\n换行符便没有了意义.
fork的时候,一定是函数已经执行完了,但是数据还没有刷新! 这些数据在当前进程对应的C标准库中的缓冲区里. 这些数据是父进程的.
代码执行完了,并不代表数据已经刷新了,fork之后子进程和父进程执行return 0的时候,即要把数据刷新的时候,要发生写时拷贝,这样就有了两份数据,然后分别输出到文件中。
所以就出现了C语言标准库输出的函数打印了两次,而系统接口打印了一次。
因为系统接口是直接写入到了文件中,而不用经过缓冲区。
此时,更加让我们确信了一个事实:缓冲区一定不是操作系统提供的!而是由C语言标准库提供的!因为如果是操作系统提供的,那么这个系统接口也应该输出两次,而不是只有一次。
那么它在哪里呢?
我们再加一条代码:
fflush(stdout);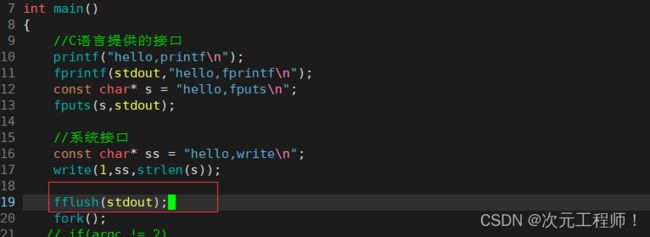
我们再次运行,然后将其输出到log.txt文件中: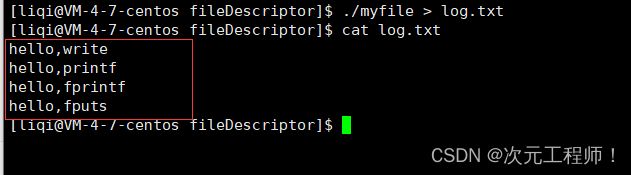
我们发现此时都只输出了一条语句,而不是两条语句了.
经过上面的讲解,我相信大家也能明白了,fflush已经强制将缓冲区的内容刷新了出来,此时缓冲区已经是空的了,然后再执行fork,父子进程缓冲区都是空的,所以也没有数据刷新了,这样才各自只打印了一条语句。
那么注意的是,我们fflush是C语言提供的,参数我们只提供了一个stdout,那么它是如何找到缓冲区的呢?
在C语言中,打开文件对应函数是fopen.它的函数原型如下:
![]()
它的函数返回值是FILE*,即一个struct file,里面不仅封装了fd,而且包含了该文件fd对应的语言层的缓冲区结构_IO_FILE。
_IO_FILE的内部结构大致如下:
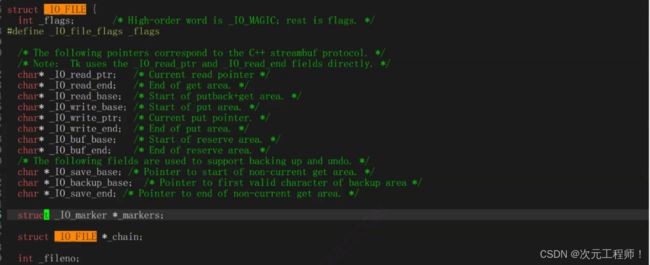
所以C语言缓冲区存在FILE结构体里.
这里需要说明一下的是,内核中也有缓冲区,只不过是内核缓冲区,和用户级缓冲区(例如C语言提供的缓冲区)两个各自独立,互不影响.

手动设计一个用户层缓冲区
我们知道缓冲区被封装在一个file结构体中,而且里面还有文件描述符fd等,所以首先我们要创建一个结构体来封装这些数据.
#define NUM 1024
struct MyFILE_{
int fd;//文件描述符
char buffer[NUM];//缓冲区
int end;//当前缓冲区的结尾
};
typedef struct MyFILE_ MyFILE;
同样的,为了使用,还有四个接口来使用,分别为fopen_,fputs_,fflush_,fclose_这四个接口。
先来说fopen_,这个主要有两个参数,第一个参数是打开的文件路径pathname,第二个是打开模式mode(r,r+,w,w+,a,a+),最后返回MyFILE结构体.
这六种模式不全部一一写,只写一种w模式,够我们使用即可。
方法思路是:首先调用系统open()接口,然后传入参数,打开模式为O_WRONLY,O_TRUNC,O_CREAT,然后接受返回的fd
如果fd大于等于0,说明打开成,然后此时再为FILE结构体开空间并初始化,并将FILE中的fd等于刚才open所得到的fd
MyFILE* fopen_(const char* pathname,const char* mode)
{
assert(pathname);
assert(mode);
MyFILE* fp = NULL;
if(strcmp(mode,"r") == 0)
{
}
else if(strcmp(mode,"r+") == 0)
{
}
else if(strcmp(mode,"w") == 0)
{
int fd = open(pathname,O_WRONLY | O_TRUNC | O_CREAT,0666);
if(fd >= 0)
{
fp = (MyFILE*)malloc(sizeof(MyFILE));
memset(fp,0,sizeof(MyFILE));
fp->fd = fd;
}
}
else if(strcmp(mode,"w+") == 0)
{
}
else if(strcmp(mode,"a") == 0)
{
}
else if(strcmp(mode,"a+") == 0)
{
}
return fp;
}
接下来是fputs_,主要作用是向指定文件描述符fd中(本质上还是向缓冲区中写入)写入内容。所以第一个参数是要写入的内容,第二个参数是MyFILE结构体.
主要思路是先将传入的内容拷贝到MyFILE中的buffer缓冲区中,然后再更新end的长度。
此时我们再判断fd是0,1,2还是其他文件,这里我们只实现了fd=1的情况
当fd=1时,先判断缓冲区中最后一个字符是否是'\0',如果是,则write写入到1中,即刷新缓冲区的内容,并将end置为0.
若不是,则无需任何操作.
void fputs_(const char* message, MyFILE* fp)
{
assert(message);
assert(fp);
strcpy(fp->buffer+fp->end,message);
fp->end += strlen(message);
//for debug
//printf("%s\n",fp->buffer);
//暂时没有刷新,刷新策略是是来执行的呢? 用户通过执行C标准库中的代码逻辑,来完成刷新动作
//效率提高体现在哪里呢?因为C提供了缓冲区,那么我们就通过策略,减少了IO次数的执行次数,不是数据量!
if(fp->fd == 0)
{
//标准输入
}
else if(fp->fd == 1)
{
//标准输出
if(fp->buffer[fp->end-1] == '\n')
{
//fprintf(stderr,"fflush: %s",fp->buffer);
write(fp->fd,fp->buffer,fp->end);
fp->end = 0;
}
}
else if(fp->fd == 0)
{
//标准错误
}
else
{
//其他文件
}
}
接下来是fflush_,这个函数主要作用是强制刷新缓冲区中的内容.
主要思路是:先判断缓冲区内容是否为空,若不为空,则write写入到编号为fd文件中,然后调用syncfs函数将数据写入磁盘,最后将end置为0.
void fflush_(MyFILE* fp)
{
assert(fp);
if(fp->end != 0)
{
//暂且认为刷新了 -- 其实是把数据写到了内核
write(fp->fd,fp->buffer,fp->end);
syncfs(fp->fd);//将数据写入到磁盘
fp->end = 0;
}
}
最后一个是fclose_,这个函数作用是关闭文件,并刷新缓冲区内容.
这个比较简单,直接复用刚才的fflush_刷新缓冲区和调用close函数关闭文件即可
void fclose_(MyFILE* fp)
{
assert(fp);
fflush_(fp);
close(fp->fd);
free(fp);
}
关于缓冲区的内容到这里就讲解完了,如果有疑问或者错误的地方,欢迎评论区或私信 提出或指正哦