1000Wqps生产级IM,怎么架构?
前言
在40岁老架构师 尼恩的读者社区(50+)中,很多小伙伴拿高薪,完成架构的升级,进入架构师赛道,打开薪酬天花板。
然后,在架构师的面试过程中,常常会遇到IM架构的问题:
如果要你从0到1做IM架构, 需要从哪些方面展开
你是怎么做项目的IM架构的?
1亿级以上qps的高并发IM,改如何架构?
前几天,40岁老架构师尼恩,站在腾讯企业IM的巨人肩膀,给大家提供一份比较全面的参考答案。具体的文章链接为
腾讯太狠:10亿QPS的IM,如何实现?
今天,40岁老架构师尼恩,站在B站1000Wqps生产级IM服务框架的巨人肩膀,再给大家提供一份比较全面的参考答案。就是本文。
通过这些企业级、工业级、生产级案例,大家可以在面试的时候,对比进行介绍,综合介绍。
从而给面试官展示自己雄厚的技术实力、开阔的技术视野,从而在面试的时候,可以充分展示一下大家雄厚的 “技术肌肉”,让你的面试官爱到 “不能自已、口水直流”。
这里,尼恩也一并把这个题目以及参考答案,收入咱们的 《尼恩Java面试宝典》V92版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
注:《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到公号【技术自由圈】取
文章目录
-
- 前言
- B站1000Wqps生产级IM服务框架
- 3590万QPS超高吞吐压测
-
- 服务端配置
- 压测参数
- 资源使用
- 压测结果
- goim搭建
-
- 基于 docker 安装zookeeper、redis、kafka
- 设置 env 环境变量
- 启动 discovery
- 启动 comet
- 启动 logic
- 解决exec: “gcc“: executable file not found in %PATH%问题
-
- 一、什么是 MinGW-w64 ?
- 二、为什么使用 MinGW-w64 ?
- 三、MinGW-w64 适合做什么?
- 四、下载和安装 MinGW-w64
- 五、安装失败
-
- 1. 问题背景
- 2. 报错原因
- 3. 解决方案
- 启动 job
- 启动 goim 的 example
- 源码解读
-
- 核心依赖库
- GOIM网元架构
-
- comet
- logic
- kafka
- router
- job
- 如何进行高并发伸缩
- 几个重要的结构体
-
- Bucket 结构体
- Room 结构
- Channel 结构
- 消息结构
-
- 1. 任务队列消息
- 2. GOIM消息协议
- 消息流转
-
- 生成消息
- 消息的投递
- 第一棒:Logic服务的消息消峰
-
- logic
- http 服务
- rpc 服务
- MQ 消费处理
-
- 用户消息
- 房间消息
- 广播消息
- 第二棒:传输消息
-
- job 组件
- job 发送消息(普通消息,房间消息,广播)
- goroutine 和 channel 实现高并发架构
- 队列缓存+批量写入高并发架构
- Job 处理房间消息小结:
- 第三棒:由Comet将消息发送给客户端
-
- Comet(彗星)的主要功能
- Comet 处理的main方法
- Comet 如何管理用户端的长连接
- Comet 如何进行channel管理
- 锁分段的架构
- goroutine 和 channel 实现高并发
- 高性能池化架构
- Redis 与 Session 结构
- 服务发现
- GOIM 的高并发架构
- GOIM 的总结
- 参考文档
- 说在最后:有问题可以找老架构尼恩取经
- 推荐相关阅读
B站1000Wqps生产级IM服务框架
goim是bilibili公司技术总监毛剑创作,使用go语言开发,用于B站生产线上的IM服务框架(聊天室),
官网:https://goim.io/
下面是官方的3590万QPS超高吞吐压测
3590万QPS超高吞吐压测
服务端配置
| CPU | 内存 | 操作系统 | 数量 |
|---|---|---|---|
| Intel® Xeon® CPU E5-2630 v2 @ 2.60GHz | DDR3 32GB | Debian GNU/Linux 8 | 1 |
压测参数
- 不同UID同房间在线人数: 1,000,000
- 持续推送时长: 15分钟
- 持续推送数量: 40条/秒
- 推送内容: {“test”:1}
- 推送类型: 单房间推送
- 到达计算方式: 1秒统计一次,共30次
资源使用
- 每台服务端CPU使用: 2000%~2300%(刚好满负载)
- 每台服务端内存使用: 14GB左右
- GC耗时: 504毫秒左右
- 流量使用: Incoming(450MBit/s), Outgoing(4.39GBit/s)
压测结果
- 推送到达: 3590万/秒左右;
其框架原理图如下:下面是官方的架构图
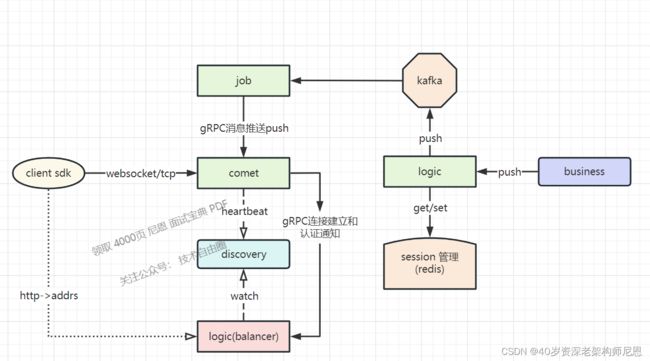
接下来,尼恩首先给大家介绍 goim的实操,再介绍 底层架构、核心源码、高性能架构设计。
goim搭建
基于 docker 安装zookeeper、redis、kafka
zookeeper
使用尼恩地表最强环境中现成服务
redis:
使用尼恩地表最强环境中现成服务
kafka:
version: '3.5'
services:
kafka:
image: 'bitnami/kafka:2.8.0'
ports:
- '9092:9092'
- '9999:9999'
environment:
- KAFKA_BROKER_ID=1
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092
# 客户端访问地址,更换成自己的主机IP (如果要外网访问就是服务器IP)
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.56.121:9092
- KAFKA_CFG_ZOOKEEPER_CONNECT=192.168.56.121:2181
# 允许使用PLAINTEXT协议(镜像中默认为关闭,需要手动开启)
- ALLOW_PLAINTEXT_LISTENER=yes
# 关闭自动创建 topic 功能
- KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=false
# 全局消息过期时间 6 小时(测试时可以设置短一点)
- KAFKA_CFG_LOG_RETENTION_HOURS=6
# 开启JMX监控
- JMX_PORT=9999
#volumes:
#- ./kafka:/bitnami/kafka
# Web 管理界面 (用KnowStreaming可以不用下面的)
kafka_manager:
image: 'hlebalbau/kafka-manager:latest'
ports:
- "9000:9000"
environment:
ZK_HOSTS: "192.168.56.121:2181"
APPLICATION_SECRET: letmein
depends_on:
- kafka
# docker network create base-env-network
networks:
base-env-network:
external:
name: "base-env-network"
设置 env 环境变量
export REGION=sh
export ZONE=sh001
export DEPLOY_ENV=dev
REGION=sh;ZONE=sh001;DEPLOY_ENV=dev
[root@centos1 discovery]# vi /etc/profile
[root@centos1 discovery]# source /etc/profile
启动 discovery
两步:
- 拉取 discovery
- 启动 discovery
拉取discovery
cd /usr/local
git clone https://github.com/bilibili/discovery.git
启动discovery
cd /usr/local/discovery/cmd/discovery
go run main.go -conf discovery.toml

具体实操效果,请参见尼恩配套视频
启动 comet
cd goim/cmd/comet
go run main.go -conf comet-example.toml
-conf D:\virtual\centos-8.2\go\src\goim\cmd\comet\comet-example.toml
REGION=sh;ZONE=sh001;DEPLOY_ENV=dev
启动效果
启动 logic
- go命令启动logic
- idea 启动logic
- 解决gcc 没有找到的问题
cd goim/cmd/logic
go run main.go -conf logic-example.toml
REGION=sh;ZONE=sh001;DEPLOY_ENV=dev
-conf D:\virtual\centos-8.2\go\src\goim\cmd\logic\logic-example.toml
解决exec: “gcc“: executable file not found in %PATH%问题
原因:系统没有安装gcc编译器
解决方法:安装 MinGW-w64
什么是gcc? GCC(GNU Compiler Collection)是由 GNU 开发的编程语言编译器。 GCC最初代表“GNU C Compiler”,当时只支持C语言。 后来又扩展能够支持更多编程语言,包括 C++、Fortran 和 Java 等。 因此,GCC也被重新定义为“GNU Compiler Collection”,成为历史上最优秀的编译器, 其执行效率与一般的编译器相比平均效率要高 20%~30%。
一、什么是 MinGW-w64 ?
什么是 MinGW-w64 ?
MinGW 的全称是:Minimalist GNU on Windows 。
一句话来概括:MinGW 就是 GCC 的 Windows 版本 。
MinGW 是将经典的开源 C语言 编译器 GCC 移植到了 Windows 平台下,并且包含了 Win32API ,因此可以将源代码编译为可在 Windows 中运行的可执行程序。
而且还可以使用一些 Windows 不具备的,Linux平台下的开发工具。
MinGW-w64 与 MinGW 的区别在于 MinGW 只能编译生成32位可执行程序,而 MinGW-w64 则可以编译生成 64位 或 32位 可执行程序。
正因为如此,MinGW 现已被 MinGW-w64 所取代,且 MinGW 也早已停止了更新,内置的 GCC 停滞在了 4.8.1 版本,而 MinGW-w64 内置的 GCC 则更新到了 6.2.0 版本。
二、为什么使用 MinGW-w64 ?
- MinGW-w64 是开源软件,可以免费使用。
- MinGW-w64 由一个活跃的开源社区在持续维护,因此不会过时。
- MinGW-w64 支持最新的 C语言 标准。
- MinGW-w64 使用 Windows 的C语言运行库,因此编译出的程序不需要第三方 DLL ,可以直接在 Windows 下运行。
- 那些著名的开源 IDE 实际只是将 MinGW-w64 封装了起来,使它拥有友好的图形化界面,简化了操作,但内部核心仍然是 MinGW-w64。
MinGW-w64 是稳定可靠的、持续更新的 C/C++ 编译器,使用它可以免去很多麻烦,不用担心跟不上时代,也不用担心编译器本身有bug,可以放心的去编写程序。
三、MinGW-w64 适合做什么?
对于熟悉 MinGW-w64 的高手而言,它可以编译任何 C语言 程序。
但对于一般人来说,MinGW-w64 太过简陋,连图形用户界面都没有。这让习惯使用鼠标的人,感到很痛苦。虽然也可以通过一些配置,让 MinGW-w64 拥有图形用户界面,但那个过程非常麻烦。
除此之外,编译复杂的程序时,还需要你会编写 Makefile ,否则只能一个文件一个文件的编译,可想而知会多么辛苦。
但对于初学 C语言 的人来说,MinGW-w64 是正合适的编译器,至少黑色的命令提示符界面很有编程的气氛,感觉很酷。
在刚开始学 C语言 时,所有代码通常都写在一个文件中,只要输入几个简单的命令,就能用 MinGW-w64 编译成可执行文件。
虽然 VS2015 等编译器,只要点击下鼠标就可以完成编译,但它会自动生成一大堆工程文件,让初学者摸不着头脑。
而 MinGW-w64 则只会生成一个可执行文件。
如果对 MinGW-w64 和 VS2015 等编译器进行一下形容,那么 MinGW-w64 是手动的,而 VS2015 等编译器则是自动的。
因此 MinGW-w64 的编译过程更加直观容易理解,也比较适合C语言学习。
总而言之,对于一般人来说,MinGW-w64 适合学习 C语言 时使用,真正工作还是用 VS2015 更好。
当然如果您是在 Linux 下工作,那么Code::Blocks可能是一个选择,不过最大的可能是您必须习惯使用 GCC 来编译程序。
四、下载和安装 MinGW-w64
1.到官网下载MinGW,下载地址:
MinGW-w64 - for 32 and 64 bit Windows download | SourceForge.net
也可以使用尼恩的网盘版本 exe文件
2.下载完成后安装,
Architecture选项中如果是32位系统就选择i686.
如果是64位系统就选择x86_64.
下一步安装路径可以自己选择。
如果出现报错cc1.exe: sorry, unimplemented: 64-bit mode not compiled in就说明你安装的是32位的,需要重新安装64位的才可以。
3.安装完成后将自己的安装路径下的mingw64\bin目录添加到环境变量PATH,
例如默认的安装目录是C:\Program Files\mingw-w64\x86_64-8.1.0-posix-seh-rt_v6-rev0\mingw64\bin
C:\Program Files\mingw-w64\x86_64-8.1.0-posix-seh-rt_v6-rev0
d:\Program Files\mingw-w64\x86_64-8.1.0-win32-seh-rt_v6-rev0
4.cmd执行gcc -v 看看是否安装成功,如果成功重启你的编辑器重新运行就不报错了
五、安装失败
1. 问题背景
安装MinGW的原因是要搭建一个C++的环境阅读JVM的HotSpot源码,笔者后面转用虚拟机的CentOS系统安装,能成功搭好C++环境。此文仅为帮助有需要安装MinGW的小伙伴。
今天使用exe在线安装器安装MinGW-w64时弹出下面报错的提示框
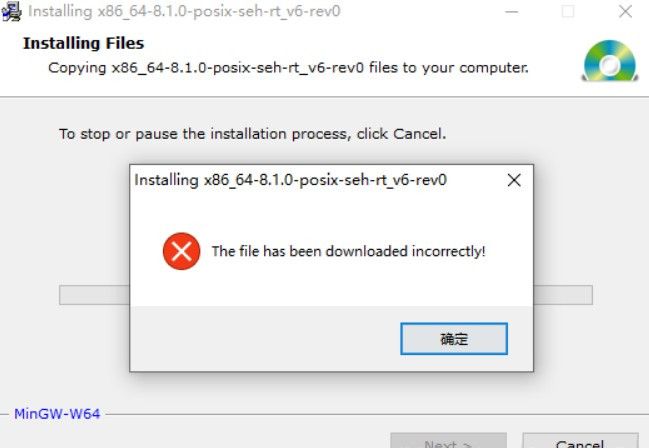
2. 报错原因
因为文件资源是托管在sourceforge上面的,因此在线安装器需要从该网站上下载文件。99%都是网络不好导致下载失败,有能力者可以科学上网解决。没办法科学上网的同学可以使用下面的解决方案,很简单。
3. 解决方案
前往MinGW-w64的sourceforge页面,直接下载完整的包即可,如下图所示:
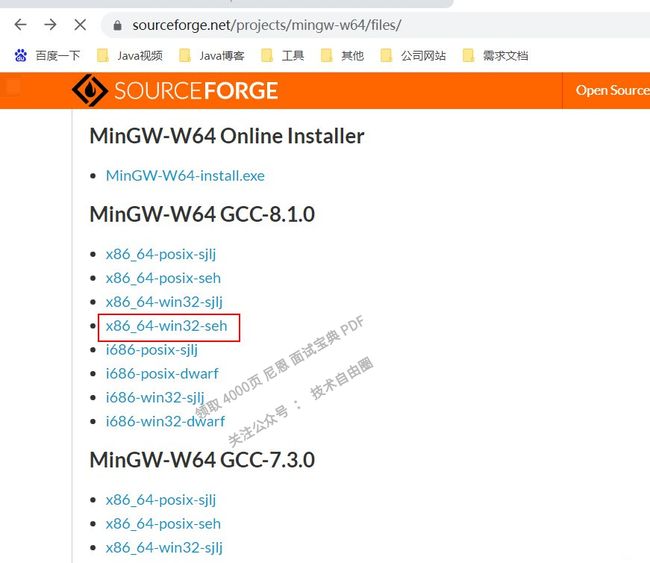
版本这里根据各自的电脑选择,我的电脑是64位,所以选择x86_64;
电脑是windows系统,所以选择 win32;seh是先进的异常处理模式技术,支持64位操作系统。
其他硬件情况可以参考MinGW-w64安装教程——著名C/C++编译器GCC的Windows版本。
下载完成后,配置环境变量:
首先看我解压出来后存放目录:
点击进入bin目录,等下配置的环境变量路径就是下图的这个路径:
配置环境变量
以上文件不好找,直接在尼恩的视频配套网盘资源文件夹里边获取。
启动 job
cd goim/cmd/logic
go run main.go -conf job-example.toml
REGION=sh;ZONE=sh001;DEPLOY_ENV=dev
go run main.go -conf D:\virtual\centos-8.2\go\src\goim\cmd\job\job-example.toml
启动 goim 的 example
vim goim/example/javascript/client.js
修改:
var ws = new WebSocket('ws://127.0.0.1:3102/sub');
也可以在idea里边直接修改:
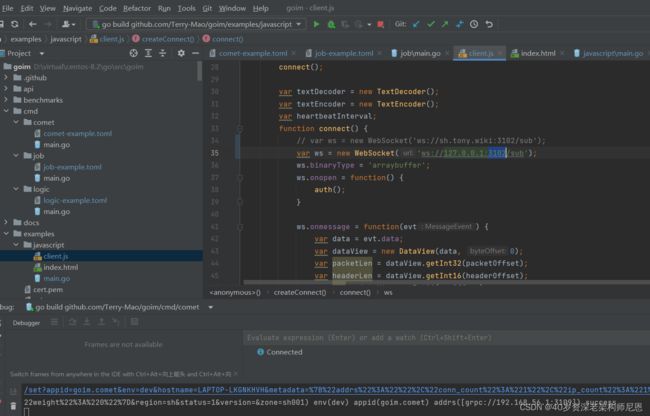
执行
cd goim/example/javascript
go run main.go
go run main.go -conf D:\virtual\centos-8.2\go\src\goim\examples\javascript
浏览器打开
http://127.0.0.1:1999
然后发送数据
curl -d 'mid message' 'http://192.168.56.1:3111/goim/push/mids?operation=1000&mids=123'
-d/–data HTTP POST方式传送数据
源码解读
本文的重点,主要梳理了GOIM的架构,消息流转和消息处理。
本文没有提到Comet的具体逻辑,套接字编程和RingBuffer等,但是Comet的复杂度远高于其他两个网元,因此强烈建议阅读Comet源码,应该会对Go网络编程有更多认识。
GOIM 是Go实现的消息推送的分布式服务,易于扩容伸缩,使用了bilibili/discovery来支持服务发现。
相较于我之前用Socket.IO做的信令服务,优点在于更优雅的扩容,将连接层和逻辑层分离,职责更清晰。
当然缺点也有(没有和具体实现解耦,如MQ的选型,导致不够灵活;客户端非全双工通信,TCP利用率偏低,这点并不全是缺点,好处是:消息流转清晰,职责非常明确),这部分可以自己做定制(最后的参考文献2中讲很多)。
核心依赖库
//配置文件操作
github.com/BurntSushi/toml v0.3.1
//kafka相关
github.com/Shopify/sarama v1.19.0 // indirect
//discovery依赖
github.com/bilibili/discovery v1.0.1
//kafka相关
github.com/bsm/sarama-cluster v2.1.15+incompatible
github.com/davecgh/go-spew v1.1.1 // indirect
github.com/eapache/go-resiliency v1.1.0 // indirect
github.com/eapache/go-xerial-snappy v0.0.0-20180814174437-776d5712da21 // indirect
github.com/eapache/queue v1.1.0 // indirect
//http请求处理库
github.com/gin-gonic/gin v1.3.0
//grpc数据序列化库
github.com/gogo/protobuf v1.1.1
github.com/golang/glog v0.0.0-20160126235308-23def4e6c14b
github.com/golang/protobuf v1.2.0
github.com/golang/snappy v0.0.0-20180518054509-2e65f85255db // indirect
//redis操作
github.com/gomodule/redigo v2.0.0+incompatible
github.com/google/uuid v1.0.0
github.com/issue9/assert v1.0.0
github.com/pierrec/lz4 v2.0.5+incompatible // indirect
github.com/pkg/errors v0.8.0
github.com/rcrowley/go-metrics v0.0.0-20181016184325-3113b8401b8a // indirect
github.com/smartystreets/assertions v0.0.0-20180927180507-b2de0cb4f26d // indirect
github.com/smartystreets/goconvey v0.0.0-20180222194500-ef6db91d284a
github.com/stretchr/testify v1.3.0
github.com/thinkboy/log4go v0.0.0-20160303045050-f91a411e4a18
github.com/ugorji/go/codec v0.0.0-20190204201341-e444a5086c43
github.com/zhenjl/cityhash v0.0.0-20131128155616-cdd6a94144ab
golang.org/x/net v0.0.0-20181011144130-49bb7cea24b1
//远程服务调用相关rpc库
google.golang.org/grpc v1.16.0
//kafka相关库
gopkg.in/Shopify/sarama.v1 v1.19.0
gopkg.in/yaml.v2 v2.2.2 // indirect
核心的依赖库:
- grpc
- redis
- kafka
GOIM网元架构
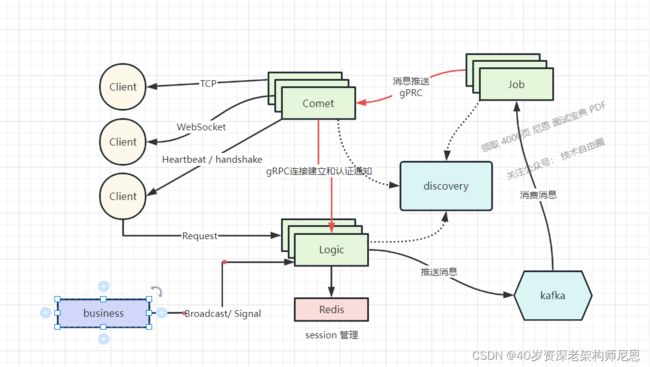
总的来说,整个应用的架构如下
下面是官方的架构图
- Comet负责建立和维持客户端的长连接;
- Job负责消息的分发;
- Logic提供三种纬度的消息(全局,ROOM,用户)投递,还包括业务逻辑,Session管理。
来一个细致点的架构图
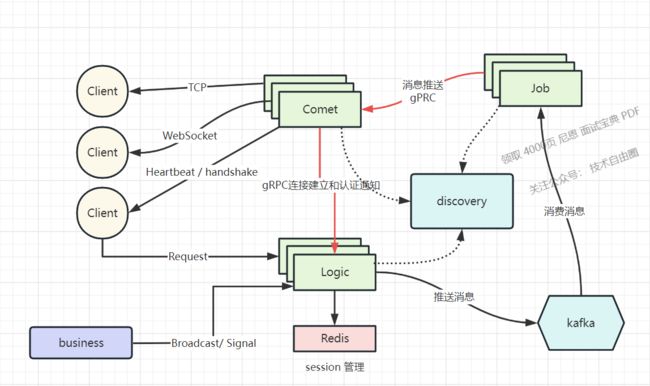
在整个架构中,系统被分成 Comet, Logic, Job, Router 四大模块,主要的功能为:
- Comet 程序是连接层,暴露给公网,
- 内网所有的业务处理推给 Logic 模块,通过 RPC 通信。
- 各个模块通过 RPC 同步通信+ MQ异步通讯结合 交互,
从消息的发送和接收的流程视角来说,四大模块之间的关系为:
- logic启动http服务器, 接受http请求,用于将数据推送到kafka以及获取在线用户信息,websocket身份校验
- comet组件起动webdocket/tcp服务, 管理连接, 并负责将数据推送至指定连接
- job组件订阅指定kafka指定频道的消息信息, 开启管道监听(将获得的数据推送到comet当中某个链接上)从discovery当中找到comet组件
- discovery负责监控以上组件的活动状态
comet
comet 属于接入层,非常容易扩展,直接开启多个comet节点,修改配置文件中的base节点下的server.id修改成不同值(注意一定要保证不同的comet进程值唯一),前端接入可以使用LVS 或者 DNS来转发
logic
logic 属于无状态的逻辑层,可以随意增加节点,使用nginx upstream来扩展http接口,内部rpc部分,可以使用LVS四层转发
kafka
kafka 可以使用多broker,或者多partition来扩展队列
router
router 属于有状态节点,logic可以使用一致性hash配置节点,增加多个router节点
目前还不支持动态扩容,所以,提前预估好在线和压力情况
job
job 根据kafka的partition来扩展多job工作方式,具体可以参考下kafka的partition负载
如何进行高并发伸缩
comet 属于接入层,非常容易扩展,直接开启多个 comet 节点,前端接入可以使用 LVS 或者 DNS来转发。
logic 属于无状态的逻辑层,可以随意增加节点,使用 nginx upstream 来扩展 http 接口,内部 rpc 部分,可以使用 LVS 四层转发。
job 用于解耦 comet 和 logic。
系统使用 kafka 作为消息队列,可以通过 kafka 使用多个 broker 或者多个 partition 来扩展队列。
使用 redis 作为元数据、节点心跳信息等维护
几个重要的结构体
Bucket管理者Rooms和Channel,都是以map数据结构保存,
room是以rid(roomId)为key,room实体指针为value,Channel是subkey为key,channel实体指针为value。
一个channel维护着一个长链接用户,对应着唯一的room,而同一个room拥有多条channel
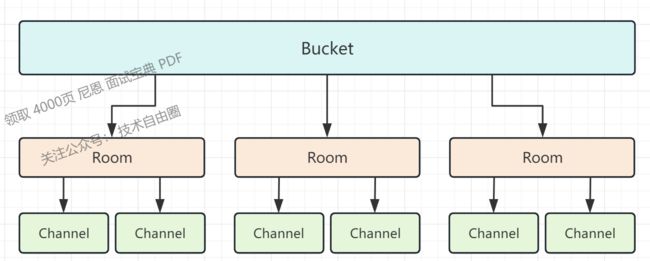
Bucket:
每个 Comet 程序拥有若干个 Bucket,
一个Bucket 可以理解为 Session Map,
一个Bucket 保存着当前 Comet 服务于哪些 Room 和 Channel.
一个Channel长连接具体分布在哪个 Bucket 上呢?根据 SubKey 一致性 Hash 来选择。
Room:
Room房间,可以理解为群组或是一个 Group.
这个房间内维护 N 个 Channel, 即长连接用户。
在该 Room 内广播消息,会发送给房间内的所有 Channel.
Channel:
维护一个长连接用户,只能对应一个 Room.
推送的消息可以在 Room 内广播,也可以推送到指定的 Channel.
Proto:
消息结构体,存放版本号,操作类型,消息序号和消息体。
Bucket 结构体
定义很明了,维护当前消息通道和房间的信息,
一个 Comet Server 默认开启 1024 Bucket, 这样做的好处是减少锁 ( Bucket.cLock ) 争用,在大并发业务上尤其明显。
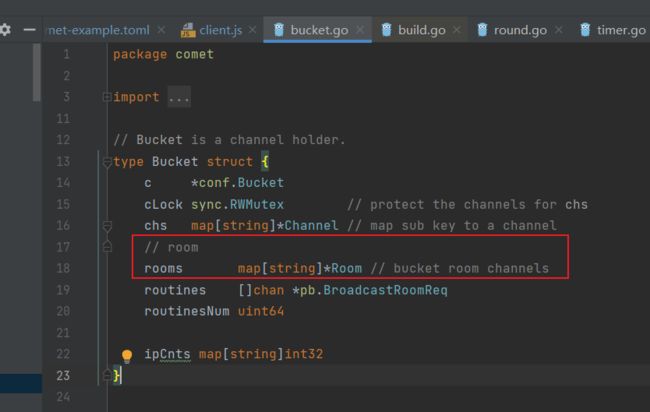
Bucket方法也很简单,加减 Channel 和 Room.
// Put put a channel according with sub key.
func (b *Bucket) Put(rid string, ch *Channel) (err error) {
var (
room *Room
ok bool
)
b.cLock.Lock()
// close old channel
if dch := b.chs[ch.Key]; dch != nil {
dch.Close()
}
b.chs[ch.Key] = ch
if rid != "" {
if room, ok = b.rooms[rid]; !ok {
room = NewRoom(rid)
b.rooms[rid] = room
}
ch.Room = room
}
b.ipCnts[ch.IP]++
b.cLock.Unlock()
if room != nil {
err = room.Put(ch)
}
return
}
// Del delete the channel by sub key.
func (b *Bucket) Del(dch *Channel) {
...
}
// Channel get a channel by sub key.
func (b *Bucket) Channel(key string) (ch *Channel) {
b.cLock.RLock()
ch = b.chs[key]
b.cLock.RUnlock()
return
}
Room 结构
Room 结构体稍显复杂一些,
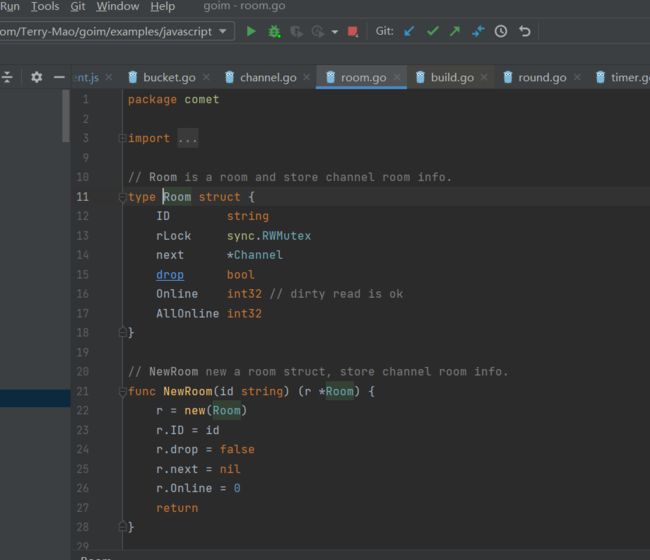
Room 不但要维护所属的消息通道 Channel, 还要消息广播的合并写,即 Batch Write,
Room 如果不合并写,每来一个小的消息都通过长连接写出去,系统 Syscall 调用的开销会非常大,Pprof 的时候会看到网络 Syscall 是大头。
Logic Server 通过 RPC 调用,将广播的消息发给 Room.Push, 数据会被暂存在proto这个结构体 里,每个 Room 在初始化时会开启一个 groutine 用来处理暂存的消息,达到 Batch Num 数量或是延迟一定时间后,将消息批量 Push 到 Channel 消息通道。
Channel 结构
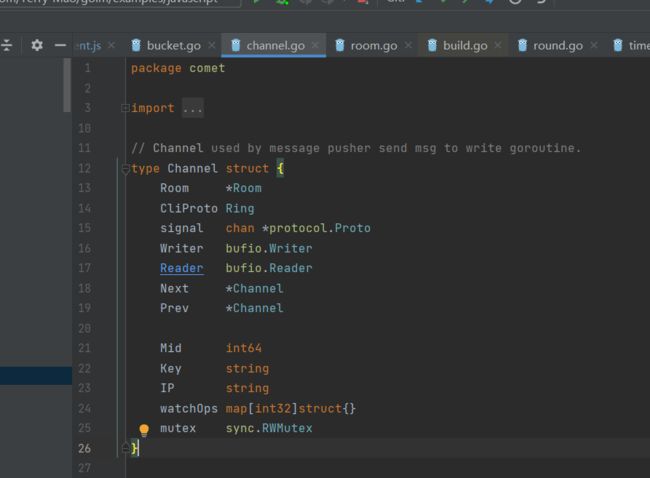
Channel是一个通道。
Channe的Writer/Reader 就是对网络 Conn 的封装,
cliProto 是一个 Ring Buffer,保存 Room 广播或是直接发送过来的消息体。
消息结构
1. 任务队列消息
不管是个人消息,还是房间消息和广播消息,都是用的如下结构;
type PushMsg struct {
Type PushMsg_Type // 消息类型,个人,房间广播,广播
Operation int32 // 指令 goim/api/comet/grpc/operation.go
Speed int32 // 广播时用 TODO:
Server string // Comet的Hostname, 个人消息时指定
Room string // 房间号
Keys []string // bucket key
Msg []byte // 消息体
}
其中Op和Type可以帮助Job单元可以针对消息上做差异化的处理。
2. GOIM消息协议
区别于任务队列消息,这个条消息是客户端实际收到的消息
type Proto struct {
Ver int32 // 版本号
Op int32 // 消息类型,如Ping,Pong, Text
Seq int32 // 序列号 TODO:
Body []byte // 消息体 等于 PushMsg.Msg
}
其中只有Op和Body是从Logic单元传递过来的,其他字段很大一部分用于消息路由,定位Comet/ Bucket/ Room/ Channel,
消息流转
生成消息
Logic提供了HTTP接口以支持消息发送能力,业务消息(除鉴权/心跳等基础数据包外)生成都是由Logic完成第一手处理,
主要有三个纬度:用户,房间,全应用广播:
用户消息的demo
curl -d 'mid message' http://api.goim.io:3111/goim/push/mids?operation=1000&mids=123
房间消息的demo
curl -d 'broadcast message' http://api.goim.io:3111/goim/push/all?operation=1000
全应用广播消息的demo
curl -d 'broadcast message' http://api.goim.io:3111/goim/push/all?operation=1000
消息的投递
从架构图中可以知道,消息的投递分为三棒:
第一棒: 消息是通过HTTP调用Logic服务,然后用MQ来存储削峰;
第二棒:Job成员都从给队列中消费消息,投递给一个或者多个Comet,
第三棒:由Comet将消息发送给客户端。
第一棒:Logic服务的消息消峰
logic
logic 处理 http请求(启用 http 服务,rpc 服务,供其他组件进行调用)
logic 模块是comet 模块调用的,接受 comet 模块的命令,然后进行处理,再发送的消息的kafka队列上,同时链接 router 模块,记录用户的 uid server room 等信息。同时获得router模块的信息。
cmd/logic/main.go
func main() {
flag.Parse()
if err := conf.Init(); err != nil {
panic(err)
}
log.Infof("goim-logic [version: %s env: %+v] start", ver, conf.Conf.Env)
// grpc register naming
dis := naming.New(conf.Conf.Discovery)
resolver.Register(dis)
// logic
srv := logic.New(conf.Conf)
//启动http监听服务, 监听来自客户端的http请求
httpSrv := http.New(conf.Conf.HTTPServer, srv)
//启动grpc服务, 监听来自其他组件的rpc调用
rpcSrv := grpc.New(conf.Conf.RPCServer, srv)
...
}
http 服务
internal/logic/http/server.go
func New(c *conf.HTTPServer, l *logic.Logic) *Server {
engine := gin.New()
engine.Use(loggerHandler, recoverHandler)
go func() {
if err := engine.Run(c.Addr); err != nil {
panic(err)
}
}()
s := &Server{
engine: engine,
logic: l,
}
//初始化路由(测试例子当中的请求uri就是这边设置映射的)
s.initRouter()
return s
}
...
//初始化http路由
func (s *Server) initRouter() {
group := s.engine.Group("/goim")
group.POST("/push/keys", s.pushKeys)
group.POST("/push/mids", s.pushMids)
group.POST("/push/room", s.pushRoom)
group.POST("/push/all", s.pushAll)
group.GET("/online/top", s.onlineTop)
group.GET("/online/room", s.onlineRoom)
group.GET("/online/total", s.onlineTotal)
group.GET("/nodes/weighted", s.nodesWeighted)
group.GET("/nodes/instances", s.nodesInstances)
}
rpc 服务
internal/logic/grpc/server.go
func New(c *conf.RPCServer, l *logic.Logic) *grpc.Server {
keepParams := grpc.KeepaliveParams(keepalive.ServerParameters{
MaxConnectionIdle: time.Duration(c.IdleTimeout),
MaxConnectionAgeGrace: time.Duration(c.ForceCloseWait),
Time: time.Duration(c.KeepAliveInterval),
Timeout: time.Duration(c.KeepAliveTimeout),
MaxConnectionAge: time.Duration(c.MaxLifeTime),
})
//创建rpc服务
srv := grpc.NewServer(keepParams)
//注册rpc服务(做一些路由映射..)
pb.RegisterLogicServer(srv, &server{l})
lis, err := net.Listen(c.Network, c.Addr)
if err != nil {
panic(err)
}
go func() {
if err := srv.Serve(lis); err != nil {
panic(err)
}
}()
return srv
}
MQ 消费处理
在Logic服务中会通过处理,将消息处理成**#消息格式#任务队列消息**的格式,然后投递到MQ中。
其中三种纬度的消息处理稍有不同:
用户消息
// goim/internal/logic/push.go
// mid => []PushMsg{op, server, keys, msg}
func (l *Logic) PushMids(c context.Context, op int32, mids []int64, msg []byte) (err error) {
// 根据用户ID获取所有的 key:server 对应关系;在redis中是一个hash
keyServers, _, err := l.dao.KeysByMids(c, mids)
// ...
keys := make(map[string][]string)
for key, server := range keyServers {
// ...
keys[server] = append(keys[server], key)
}
for server, keys := range keys {
// 通过DAO组装PushMsg投递给MQ
if err = l.dao.PushMsg(c, op, server, keys, msg); err != nil {
return
}
}
return
}
房间消息
没什么特别的处理
// goim/internal/logic/push.go
func (l *Logic) PushRoom(c context.Context, op int32, typ, room string, msg []byte) (err error) {
return l.dao.BroadcastRoomMsg(c, op, model.EncodeRoomKey(typ, room), msg)
}
// // goim/internal/logic/dao
func (d *Dao) BroadcastRoomMsg(c context.Context, op int32, room string, msg []byte) (err error) {
pushMsg := &pb.PushMsg{
Type: pb.PushMsg_ROOM,
Operation: op,
Room: room,
Msg: msg,
}
b, err := proto.Marshal(pushMsg)
// ...
if err := d.nsqProducer.Publish(d.c.Nsq.Topic, b); err != nil {
log.Errorf("PushMsg.send(push pushMsg:%v) error(%v)", pushMsg, err)
}
return
}
广播消息
没什么特别的处理
// goim/internal/logic/push.go
func (l *Logic) PushAll(c context.Context, op, speed int32, msg []byte) (err error) {
return l.dao.BroadcastMsg(c, op, speed, msg)
}
// goim/internal/logic/dao
func (d *Dao) BroadcastMsg(c context.Context, op, speed int32, msg []byte) (err error) {
pushMsg := &pb.PushMsg{
Type: pb.PushMsg_BROADCAST,
Operation: op,
Speed: speed, // 这里需要去到Job才知道speed的具体功效
Msg: msg,
}
b, err := proto.Marshal(pushMsg)
if err != nil {
return
}
if err := d.nsqProducer.Publish(d.c.Nsq.Topic, b); err != nil {
log.Errorf("PushMsg.send(push pushMsg:%v) error(%v)", pushMsg, err)
}
return
}
小结:
- 针对用户单发时,会获取到具体的sever和keys组装到PushMsg
- 房间消息,没有server和keys, 但是多一个room是通过typ和roomID组装而成的 “live://1000”
- 广播消息,除了消息体之外,另外有一个speed字段
第二棒:传输消息
由Logic处理好的消息会放在MQ中,然后到了 第二棒:Job成员都从给队列中消费消息,投递给一个或者多个Comet
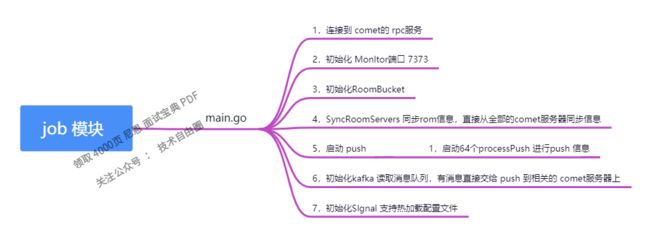
第二棒的Job任务怎么和Comet单元或者网元通讯呢? 通过gRPC调用Comet单元。
第二棒的Job任务 通过gRPC调用Comet单元 的方式,push 到相关的comet服务器上。用户就接受到了消息。
相比其他两个网元,Job就简单多了。
job 组件
job组件创建kafka订阅服务,对comet组件进行监听
func main() {
flag.Parse()
if err := conf.Init(); err != nil {
panic(err)
}
log.Infof("goim-job [version: %s env: %+v] start", ver, conf.Conf.Env)
// grpc register naming
dis := naming.New(conf.Conf.Discovery)
resolver.Register(dis)
// job
j := job.New(conf.Conf)
go j.Consume()
...
}
internal/job/job.go 具体实现
func New(c *conf.Config) *Job {
j := &Job{
c: c,
consumer: newKafkaSub(c.Kafka),
rooms: make(map[string]*Room),
}
j.watchComet(c.Discovery)
return j
}
job 发送消息(普通消息,房间消息,广播)
从MQ中消费到消息后会调用c.job.push(ctx, pushMsg)。
// job 发送消息(普通消息,房间消息,广播)
func (j *Job) push(ctx context.Context, pushMsg *pb.PushMsg) (err error) {
switch pushMsg.Type {
case pb.PushMsg_PUSH:
err = j.pushKeys(pushMsg.Operation, pushMsg.Server, pushMsg.Keys, pushMsg.Msg)
case pb.PushMsg_ROOM:
// 获取一个job中的Room缓存,用于房间内“定时,定量”发送消息,减少请求次数
// 这里调用的Push并不会立即发送,而是放在Room.proto这个channel中
// 实际放松是由Room.pushproc来定时
err = j.getRoom(pushMsg.Room).Push(pushMsg.Operation, pushMsg.Msg)
case pb.PushMsg_BROADCAST:
err = j.broadcast(pushMsg.Operation, pushMsg.Msg, pushMsg.Speed)
default:
err = fmt.Errorf("no match push type: %s", pushMsg.Type)
}
return
}
// 根据serverID发送给特定的Comet服务,避免广播
// cometServers 是由discovery服务发现维护的comet列表。
func (j *Job) pushKeys(operation int32, serverID string, subKeys []string, body []byte) (err error) {
buf := bytes.NewWriterSize(len(body) + 64)
p := &comet.Proto{
Ver: 1,
Op: operation,
Body: body,
}
p.WriteTo(buf)
p.Body = buf.Buffer()
p.Op = comet.OpRaw
var args = comet.PushMsgReq{
Keys: subKeys,
ProtoOp: operation,
Proto: p,
}
if c, ok := j.cometServers[serverID]; ok {
if err = c.Push(&args); err != nil {
log.Errorf("c.Push(%v) serverID:%s error(%v)", args, serverID, err)
}
log.Infof("pushKey:%s comets:%d", serverID, len(j.cometServers))
}
return
}
// 处理成一个BroadcastReq,并广播给所有的Comet
func (j *Job) broadcast(operation int32, body []byte, speed int32) (err error) {
// ... 与pushKeys一致,生成一个p
comets := j.cometServers
// 如 speed = 64, len(comets) = 2, speed = 32
speed /= int32(len(comets))
var args = comet.BroadcastReq{
ProtoOp: operation,
Proto: p,
Speed: speed, // 是被传递给Comet处理,继续跟踪
}
for serverID, c := range comets {
if err = c.Broadcast(&args); err != nil {
log.Errorf("c.Broadcast(%v) serverID:%s error(%v)", args, serverID, err)
}
}
log.Infof("broadcast comets:%d", len(comets))
return
}
房间消息处理:
getRoom(roomID) -> room.Push() -> p -> room.proto
|
|---> NewRoom(batch, duration)
|
|---> go room.pushproc() -> p <- room.proto
// goim/internal/job/room.go
type Room struct {
c *conf.Room // 关于房间的配置
job *Job // 绑定job,为了追溯Room所属的Job
id string // 房间ID
proto chan *comet.Proto // 有缓冲channel
}
// pushproc merge proto and push msgs in batch.
// 默认batch = 20, sigTime = 1s
func (r *Room) pushproc(batch int, sigTime time.Duration) {
var (
n int
last time.Time
p *comet.Proto
buf = bytes.NewWriterSize(int(comet.MaxBodySize)) // 4096B = 4KB
)
// 设置了一个定时器,在一定时间后往room.proto放送一个roomReadyProto信号。
td := time.AfterFunc(sigTime, func() {
select {
case r.proto <- roomReadyProto:
default:
}
})
defer td.Stop()
for {
if p = <-r.proto; p == nil {
// 如果创建了room,但是读到空包
break // exit
} else if p != roomReadyProto {
// 读取room.proto 如果是正常的数据包,则合并到buf中去,如果满了怎么办?
p.WriteTo(buf)
// 如果是第一个数据包,则重置定时器,并继续读取后续数据包
if n++; n == 1 {
last = time.Now()
td.Reset(sigTime)
continue
} else if n < batch {
// 后续的数据包,不会重置定时器,但是如果时间仍在第一个数据包的 sigTime 时间间隔内
// 简单说,定时器还没到时间
if sigTime > time.Since(last) {
continue
}
}
// 累计的数据包数量已经超过了batch, 执行发送动作
} else {
// 定时器到读到了roomReadyProto
// 如果buf已经被重置了,则跳出循环执行清理动作;否则执行发送消息
if n == 0 {
break
}
}
// 发送房间内的消息
_ = r.job.broadcastRoomRawBytes(r.id, buf.Buffer())
buf = bytes.NewWriterSize(buf.Size())
n = 0
// 如果配置了房间最大闲置时间,则重新设定定时器
// 也就是说,如果房间被创建后,处理完了该房间的消息,并不是直接跳出循环清理房间
// 而是,会阻塞等待下一次的消息再来,如果在 “1m / r.c.Idle” 时间内没有来,则会跳出循环清理掉该房间
// 如果在 “1m / r.c.Idle” 内有消息,则会重新设定定时器为sigTime,并为proto计数
if r.c.Idle != 0 {
td.Reset(time.Duration(r.c.Idle)) // 默认15分钟
} else {
td.Reset(time.Minute)
}
}
// 清理动作
r.job.delRoom(r.id)
}
goroutine 和 channel 实现高并发架构
… 由于限字数,此处具体内容,请参见 《尼恩Java面试宝典》V92 PDF版本
队列缓存+批量写入高并发架构
… 由于限字数,此处具体内容,请参见 《尼恩Java面试宝典》V92 PDF版本
Job 处理房间消息小结:
… 由于限字数,此处具体内容,请参见 《尼恩Java面试宝典》V92 PDF版本
第三棒:由Comet将消息发送给客户端
Comet(彗星)的主要功能
… 由于限字数,此处具体内容,请参见 《尼恩Java面试宝典》V92 PDF版本
Comet 处理的main方法
… 由于限字数,此处具体内容,请参见 《尼恩Java面试宝典》V92 PDF版本
Comet 如何管理用户端的长连接
… 由于限字数,此处具体内容,请参见 《尼恩Java面试宝典》V92 PDF版本
Comet 如何进行channel管理
… 由于限字数,此处具体内容,请参见 《尼恩Java面试宝典》V92 PDF版本
锁分段的架构
… 由于限字数,此处具体内容,请参见 《尼恩Java面试宝典》V92 PDF版本
goroutine 和 channel 实现高并发
… 由于限字数,此处具体内容,请参见 《尼恩Java面试宝典》V92 PDF版本
高性能池化架构
… 由于限字数,此处具体内容,请参见 《尼恩Java面试宝典》V92 PDF版本
Redis 与 Session 结构
… 由于限字数,此处具体内容,请参见 《尼恩Java面试宝典》V92 PDF版本
服务发现
… 由于限字数,此处具体内容,请参见 《尼恩Java面试宝典》V92 PDF版本
GOIM 的高并发架构
… 由于限字数,此处具体内容,请参见 《尼恩Java面试宝典》V92 PDF版本
GOIM 的总结
… 公号限字数,此处具体内容,请参见 《尼恩Java面试宝典》V92 PDF版本
参考文档
官网:https://goim.io/
- https://github.com/Terry-Mao/goim
- https://juejin.im/post/5cd12fa16fb9a0320b40ec32
说在最后:有问题可以找老架构尼恩取经
架构之路,充满了坎坷
转架构很难,按照8020原则,80%的人,在这里是转不过去的。
这是一场竞争, 哪怕走在前面半步就比较容易获取胜利,叫做强者愈来愈强。
架构和高级开发不一样 ,
架构的问题是open的,开发式的,没有标准答案的
在做架构过程中,如果遇到复杂的场景,确实不知道怎么做架构方案,
或者在转型过程中,确实找不到有底的方案,怎么办? 可以来找40岁老架构尼恩求助.
上次一个小伙伴,他们要进行 电商网站的黄金链路架构, 开始找不到思路,但是经过尼恩 10分钟语音指导,一下就豁然开朗。
关于IM架构,后面尼恩会出一个系列的视频,帮助大家彻底掌握,从而开启自己的 架构师之路。
推荐相关阅读
《痛失网易30K之一:为啥用阻塞队列,list不行吗?》
《痛失网易30K之二:看你牛逼轰轰,请写一个阻塞队列》
《滴滴太狠:分布式ID,如何达到1000Wqps?》
《10亿级用户,如何做 熔断降级架构?微信和hystrix的架构对比》
《虾皮一面:手写一个Strategy模式(策略模式)》
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓