数据分析利器Python——Pandas(一、数据结构)
文章目录
-
- 一、数据结构
-
- 1、Series
-
- 1.1、基础
- 1.2、索引操作
-
- 索引基础
- 切片索引
- 不连续索引
- 2、DataFrame
-
- 2.1、基础
- 2.2、索引
-
- 混合索引
- inplace参数
- 复杂操作
- 3、Index
-
- 3.1、常见类型
pandas的基础是numpy,他是一个强大的分析结构化数据的工具集。
一、数据结构
1、Series
1.1、基础
Series是类似一维数组的对象,由数据和索引组成,索引在左,数据在右,且索引是自动创建的
构建Series
- 通过数组/列表
- 通过dict
预览数据:obj.head()【默认显示前五行】,obj.tail(num)显示后num行数据
获取数据和索引:obj.index obj.values
import numpy as np
import pandas as pd
pd.Series(range(10,20))

如图所示,左侧为索引【默认自动生成从0开始的索引】,右侧为数据【默认没有名字】
a = {"a":1,"b":3,"c":5}
pd.Series(a) # 通过字典创建
'''
输出内容
a 1
b 3
c 5
dtype: int64
'''
1.2、索引操作
索引基础
可以在创建时使用index关键字修改索引,为数据添加名字
pd.Series(range(3),index=['a','b','d'],name="rand_num")
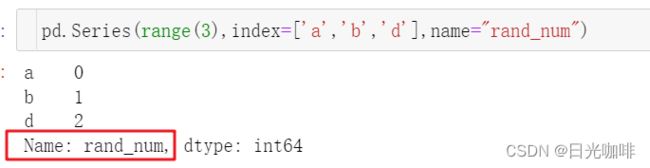
我们也可以给索引起名字:obj.index.name=“index_name”
通过索引名(字符串)获取数据,ser_obj[‘idx_name’], 或 ser_obj.loc[‘idx_name’]
通过索引位置【整型】获取数据:ser_obj.iloc[index]
ser_obj[num]方括号内既可以放整型索引,也可以放字符串类型的列名
ser_obj.loc[num]方括号内放字符串类型的列名
ser_obj.iloc[num]方括号内放整型索引
通过in判断数据是否存在,Series也可看作定长、有序的字典
Pandas会根据数据类型自动处理缺失数据
- object->None
- float->NaN
切片索引
ser_obj[2:4]原理同列表索引,不包含终止索引
ser_obj[‘label1’:‘label3’],需要注意,按照索引名切片时,包含终止索引
不连续索引
ser_obj[ [‘label1’,‘label3’,‘label5’] ]
ser_obj[ [pos1,pos3,pos5] ]
2、DataFrame
多维数组 / 表格型数据,类似Excel。它也有索引——行索引和列索引。
2.1、基础
(1)构建
- 通过ndarray
- 通过dict
# 使用jupyter notebook
# 通过ndarray构建DataFrame
array = np.random.rand(15).reshape((3,5))
a = pd.DataFrame(array)
a
# 通过dict构建DataFrame
dict_data = {
'A':1.,
'B':pd.Timestamp('20220429'),
'C':pd.Series(1,index=list(range(4)),dtype='float32'),
'D':np.array([3]*4,dtype='int32'),
'E':['Math','Python','C','English'],
'F':'China'
}
df_obj = pd.DataFrame(dict_data)
df_obj

可以看到,在通过dict创建DataFrame时,我们每列最大的长度是4,对于长度小于4的列表,生成DataFrame时,系统自动广播成为满足最大长度的列表。
(2)我们可以通过列索引获取列数据(每一列都是Series类型,可以通过Series的索引方法进行索引)
(3)增加列数据:df_obj[new_label] = data
(4)删除列:
- df_obj.drop(columns=[])【注意返回值是操作后的结果但是并不改变源数据】
- del df_obj[col_index]
# 获取DataFrame的列名
df_obj.columns
# 获取DataFrame的索引名(行名)
df_obj.index
# 以数组形式返回除去行索引列索引外的所有数据
df_obj.values
# 预览数据
df_obj.head(num) # 查看前num行数据
# 获取数据和索引
df_obj.E # E为列名,若列名中存在空格则会失效,所以建议使用下面的索引方式
df_obj['E'] # 索引结果为Series类型
2.2、索引
关于列索引、行索引和不连续索引方法同Series,但注意,此时的loc和iloc不可省略。
混合索引
先行后列、先列后行
inplace参数
我们之前说过,Series删除操作并不改变原数据,若想要改变源数据,第一个方法是可以用原数据接收,另一个方法则是可以在删除的函数中加入参数inplace并将其设置为True,此时则没有返回值,是在原始数据上进行操作。【inplace默认为False,有返回值,对原始数据无影响】
# 法一
df_obj=df_obj.drop('E',axis=1) # 指定删除E列并修改源数据
# 法二
df_obj.drop('E',axis=1,inplace=True) # 不需要返回值,若加返回值则其为空,因为inplace=True时,没有返回值
复杂操作
(1)找到包含某标签的值——布尔值遮罩
df[‘E’].str.contains(‘Python’),返回的是包含True和False的列表
filter_condition=df['E'].str.contains('Python')
df[filter_condition] # 筛选出符合条件的值
(2)找到在某个范围的值
df[df['rank']<=10] # 返回rank属性<10的某些行
3、Index
Series和DataFrame中的index都是Index对象,Index对象是不可变的,它保证了数据的安全
3.1、常见类型
Index
Int64Index
MultiIndex,层级索引
DatetimeIndex,时间戳类型
重置索引:reset_index(drop=False),将索引值重新赋值为从0开始的索引,原来的索引变为数据中的一列,列名为index。函数中的drop参数默认为False,若令drop=True,则表示删除原索引列