MySQL备份迁移之mydumper
简介
mydumper 是一款开源的 MySQL 逻辑备份工具,主要由 C 语言编写。与 MySQL 自带的 mysqldump 类似,但是 mydumper 更快更高效。
mydumper 的一些优点特性:
- 轻量级C语言开发
- 支持多线程备份数据,备份后按表生成多个备份文件
- 支持事务性和非事务性表一致性备份
- 支持将导出的文件压缩,节约空间
- 支持多线程恢复
- 支持已守护进程模式工作,定时快照和连续二进制日志
- 支持按指定大小将备份文件切割
- 数据与建表语句分离
下载安装
安装方式非常多,以下介绍几种常见的方式。
- Ubuntu 中自带了 myloader
sudo apt-get install mydumper
- 使用 deb 包安装,以 Ubuntu 为例
apt-get install libatomic1
wget https://github.com/mydumper/mydumper/releases/download/v0.11.5/mydumper_0.11.5-1. ( l s b r e l e a s e − c s ) a m d 64. d e b d p k g − i m y d u m p e r 0 . 11.5 − 1. (lsb_release -cs)_amd64.deb dpkg -i mydumper_0.11.5-1. (lsbrelease−cs)amd64.debdpkg−imydumper0.11.5−1.(lsb_release -cs)_amd64.deb
- 编译安装
- docker 安装
根据实际平台情况,可选择不同的安装方式,官方也提供了一些常见的安装文档,https://github.com/mydumper/mydumper
参数说明
mydumper 参数说明
-B, --database 要备份的数据库,不指定则备份所有库,一般建议备份的时候一个库一条命令
-T, --tables-list 需要备份的表,名字用逗号隔开
-o, --outputdir 备份文件输出的目录
-s, --statement-size 生成的insert语句的字节数,默认1000000
-r, --rows 将表按行分块时,指定的块行数,指定这个选项会关闭 --chunk-filesize
-F, --chunk-filesize 将表按大小分块时,指定的块大小,单位是 MB
-c, --compress 压缩输出文件
-e, --build-empty-files 如果表数据是空,还是产生一个空文件(默认无数据则只有表结构文件)
-x, --regex 是同正则表达式匹配 'db.table'
-i, --ignore-engines 忽略的存储引擎,用都厚分割
-m, --no-schemas 不备份表结构
-d, --no-data 不备份表数据
-G, --triggers 备份触发器
-E, --events 备份事件
-R, --routines 备份存储过程和函数
-W, --no-views 不备份视图
--where 只导出符合条件的数据
-k, --no-locks 不使用临时共享只读锁,使用这个选项会造成数据不一致
--less-locking 减少对InnoDB表的锁施加时间(这种模式的机制下文详解)
-l, --long-query-guard 设定阻塞备份的长查询超时时间,单位是秒,默认是60秒(超时后默认mydumper将会退出)
--kill-long-queries 杀掉长查询 (不退出)
-b, --binlogs 导出binlog
-D, --daemon 启用守护进程模式,守护进程模式以某个间隔不间断对数据库进行备份
-I, --snapshot-interval dump快照间隔时间,默认60s,需要在daemon模式下
-L, --logfile 使用的日志文件名(mydumper所产生的日志), 默认使用标准输出
--tz-utc 跨时区时使用的选项。允许备份timestamp,这样会导致不同时区的备份还原出问题,默认关闭。
--skip-tz-utc 同上,默认值。
--use-savepoints 使用savepoints来减少采集metadata所造成的锁时间,需要 SUPER 权限
--success-on-1146 Not increment error count and Warning instead of Critical in case of table doesn't exist
-h, --host 连接的主机名
-u, --user 备份所使用的用户
-p, --password 密码
-P, --port 端口
-S, --socket 使用socket通信时的socket文件
-t, --threads 开启的备份线程数,默认是4
-C, --compress-protocol 压缩与mysql通信的数据
-V, --version 显示版本号
-v, --verbose 输出信息模式, 0 = silent, 1 = errors, 2 = warnings, 3 = info, 默认为 2
myloader 参数说明
-d, --directory 备份文件的文件夹
-q, --queries-per-transaction 每次事务执行的查询数量,默认是1000
-o, --overwrite-tables 如果要恢复的表存在,则先drop掉该表,使用该参数,需要备份时候要备份表结构
-B, --database 还原到的数据库(目标库)
-s, --source-db 被还原的数据库(源数据库),-s db1 -B db2,表示源库中的db1数据库,导入到db2数据库中。
-e, --enable-binlog 启用还原数据的二进制日志
-h, --host 主机
-u, --user 还原的用户
-p, --password 密码
-P, --port 端口
-S, --socket socket文件
-t, --threads 还原所使用的线程数,默认是4
-C, --compress-protocol 压缩协议
-V, --version 显示版本
-v, --verbose 输出模式, 0 = silent, 1 = errors, 2 = warnings, 3 = info, 默认为2
常用案例
mydumper 导出示例
# 个人实际中最常用的备份语句
mydumper -B test -o /home/mydumper/data/test -e -G -R -E -D -u root -p 123456 -h 192.168.0.191 -P 3306 -v 3 --long-query-guard 288000 --skip-tz-utc --no-locks --logfile /home/mydumper/log/test
# 备份全部数据库
mydumper -u root -p 123456 -o /home/mydumper/data/all/
# 备份全部数据库,排除系统库,
mydumper -u root -p 123456 --regex '^(?!(mysql|sys|performance_schema|information_schema))' -o /home/mydumper/data/all/
# 备份全部数据库,包含触发器、事件、存储过程及函数
mydumper -u root -p 123456 -G -R -E -o /home/mydumper/data/all/
# 备份指定库
mydumper -u root -p 123456 -G -R -E -B db1 -o /home/mydumper/data/db1
# 备份指定表
mydumper -u root -p 123456 -B db1 -T tb1,tb2 -o /home/mydumper/data/db1
# 只备份表结构
mydumper -u root -p 123456 -B db1 -d -o /home/mydumper/data/db1
# 只备份表数据
mydumper -u root -p 123456 -B db1 -m -o /home/mydumper/data/db1
myloader 导入案例
# 个人实际中最常用的导入语句
myloader -h 192.168.0.192 -P 33306 -u root -p 123456 -t 1 -v 3 -d /home/mydumper/data/test/0/ -B test
# 从备份中恢复指定库
myloader -u root -p 123456 -s db1 -o -d /home/mydumper/data/all/0/
# 导入时开启 binlog
myloader -u root -p 123456 -e -o -d /home/mydumper/data/db1/0/
# 将源库的 db1 导入到备库的 db1_bak 库中
myloader -u root -p 123456 -B db1_bak -s db1 -o -d /home/mydumper/data/db1/0/
# 导入特定的某几张表
## 先将 metadata 文件和需要单独导入的表的结构文件和数据文件导入到单独的文件夹中。此处默认库已建好,否则还需要复制建库相关语句。
cp /home/mydumper/data/db1/0/metadata /backup/db1/0/
cp /home/mydumper/data/db1/0/d1.t1-schema.sql /backup/db1/0/
cp /home/mydumper/data/db1/0/d1.t1.sql /backup/db1/0/
## 从新文件夹中导入数据
myloader -u root -p 123456 -B db1 -d /backup/db1/0/
## 以上就可以单独导入 db1.t1 表
关于 -e 参数,需要稍微注意下。默认情况下,myloader 是不开启 binlog 的,这样可以提高导入速度。如果导入实例有从库,且需要导入的结果同步到从库上,则需要使用 -e 打开 binlog 记录。
导出之后的目录如下,以数据库 d1 ,其中有表 t1 为例:
-d1
-0
metadata 记录备份时间点的Binlog信息,日志文件名和写入位置
d1-schema-create.sql 建库语句
d1-schema-post.sql 存储过程,函数,事件创建语句
d1.t1-schema.sql 表结构文件
d1.t1.sql 表数据文件,若使用了分块参数,大表的数据文件会出现多个,以数字分开。
-1
以上为比较常见的导出后的目录结构,根据实际情况不同,可能还有会含有触发器的文件,含有视图的文件等。
常见问题与实践经验
-
Error switching to database whilst restoring table
使用 myloader 导入时会出现这类报错,可以尝试的解决方法如下:调大 wait_timeout 参数;调大 max_packet_size 参数;使用一个线程导入, -t 1。
-
(myloader:35671): CRITICAL **: Error restoring test.email_logger from file test.email_logger.sql: Cannot create a JSON value from a string with CHARACTER SET ‘binary’.
MySQL 的一个 Bug,可以尝试手动修改对应的备份文件,将
/!40101 SET NAMES binary/;
修改为:
/!40101 SET NAMES utf8mb4/;
-
(myloader:34726): CRITICAL **: Error restoring test.(null) from file test-schema-post.sql: Access denied; you need (at least one of) the SUPER privilege(s) for this operation
在导入 AWS RDS 时部分存储过程创建失败,有比较严格的权限限制,需要导入用户有 SUPER 权限,但是 AWS RDS 用户无法授予 SUPER 权限。针对这部分存储过程,可以考虑手动在备份库上创建。
-
大表导出优化
使用
-r或-F参数,对导出的数据文件进行分片。 -
备份机器配置尽可能高
备份前先预估大小,避免机器磁盘不足。尽可能选用配置较高的机器,加快备份速度。
-
非必要数据不备份
备份前对于不用备份的数据可以提前进行一次删除,也可在导出数据时添加正则参数等过滤部分表
-
备份尽量不跨网络
备份数据时尽量在内网中进行,若需要将数据迁移到外网,可以备份完之后,将备份文件拷贝到外网服务器上,尽量减少导出时网络不稳定的干扰。导入时同理。
-
加快导入速度的一些方法
选择合适的线程数,根据实际情况和机器配置,选择合适的线程参数,并非线程数越多越快。
导入时关闭 MySQL 的 binlog 写入,待导入完成后再开启。
在内网或较稳定的环境中进行导入。
原理与架构
mydumper 工作流程
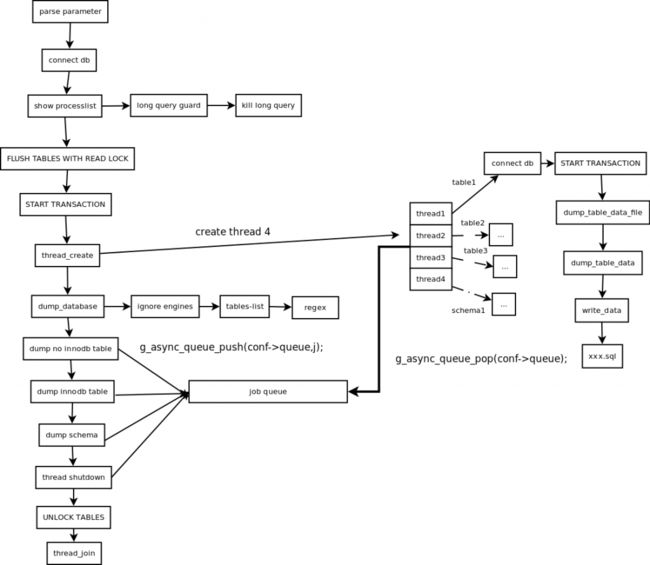
主要步骤概括
- 主线程 FLUSH TABLES WITH READ LOCK,施加全局只读锁,阻止DML语句写入,保证数据的一致性。
- 读取当前时间点的二进制日志文件名和日志写入的位置并记录在metadata文件中。
- N个dump线程 START TRANSACTION WITH CONSISTENT SNAPSHOT,开启读一致的事务。
- dump non-InnoDB tables, 首先导出非事务引擎的表。
- 主线程 UNLOCK TABLES 非事务引擎备份完后,释放全局只读锁。
- dump InnoDB tables,基于事务导出InnoDB表。
- 事务结束。
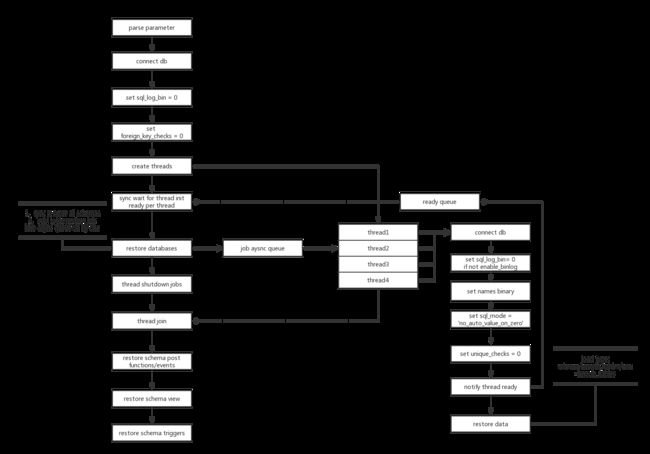
myloader 工作原理
更多技术文章,请关注我的个人博客 www.immaxfang.com 和小公众号 Max的学习札记。