4、数据库操作语句:聚合函数
目录
1、定义
2、常用的聚合函数
1)Avg/sum:只适用于数值类型的字段(或变量)。
2)Max/min:适用于数值类型、字符串类型、日期时间类型的字段(或变量)
3)Count:
①作用:I、计算指定字段在查询结果中出现的个数。II、在计算指定字段出现的个数时,不计算null值。
②如果计算表中有多少条记录,如何实现:
③如果需要统计表中的记录个条数,以上三种方式那个效率更高?
3、group by的使用
1)需求:查询各个部门的平均工资,最高工资。
2)使用多个列分组
3)需求:查询各个department_id,job_id的平均工资
4)在group by中使用with rollup,会在不使用with rollup的查询结果上多出一行数据,该数据是group by所有数据的平均数值,作用类似于avg函数。
4、Having的使用(作用:用来过滤数据)
1)如果过滤条件中使用了聚合函数,则必须使用having来替换where。否则,报错。并且having必须声明在group by的后面
2)在开发中使用HAVING 的前提是mql中使用了GROUP BY。
3)Where和having对比
5、SQL底层执行原理
1)Select 语句的完整结构
①SQL92语法
②SQL99语法
③Sql语句的执行过程
1、定义
定义:作用于一组数据,并对一组数据返回一个值

2、常用的聚合函数
1)Avg/sum:只适用于数值类型的字段(或变量)。
Select avg(salary),sum(salary),avg(salary)*107 from employees;
公式:avg=sum/count 在计算过程中自动将null值过滤掉。
select avg(commission_pct),sum(commission_pct)/count(commission_pct) from employees;
2)Max/min:适用于数值类型、字符串类型、日期时间类型的字段(或变量)
Select max(salary),min(salary) from employees;
Select max(last_name),min(last_name) from employees;
3)Count:
①作用:I、计算指定字段在查询结果中出现的个数。II、在计算指定字段出现的个数时,不计算null值。
Select count(employee_id),count(salary) from employees;
Select count(1),count(2) from employees;//将每条记录看成1(或者2),结果为记录的条数。
②如果计算表中有多少条记录,如何实现:
方式一:count(*)
方式二:count(1)
方式三:count(字段)
③如果需要统计表中的记录个条数,以上三种方式那个效率更高?
I、如果使用的是myisam存储引擎,则三者效率相同O(1)
II、如果使用的是innodb存储引擎,则三者效率:count(*)=count(1)>count(字段)
III、方差、标准差、中位数
3、group by的使用

1)需求:查询各个部门的平均工资,最高工资。
Select dapartment_id,avg(salary),sum(salary) from employees group by department_id;//按照部门id分组,计算出各个部门的平均工资以及各个部门的工资总和。
2)使用多个列分组
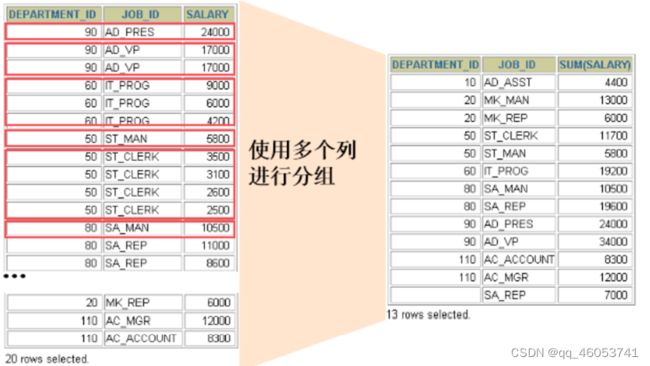
3)需求:查询各个department_id,job_id的平均工资
Select department_id,job_id,avg(salary) from employees group by department_id,job_id;
错误案例:Select department_id,job_id,avg(salary) from employees group by department_id;
结论1:select中出现的非组函数的字符段必须声明在group by中。反之,group by中声明的字段可以不出现在select中
结论2:group by声明在from后面、where后面,order by前面、limit前面
4)在group by中使用with rollup,会在不使用with rollup的查询结果上多出一行数据,该数据是group by所有数据的平均数值,作用类似于avg函数。
Select department_id,avg(salary) from employees group by department_id with rollup;
结论3:当使用with rollup时,不能同时使用order by子句进行结果排序,即with rollup和order by是互斥。
4、Having的使用(作用:用来过滤数据)
1)如果过滤条件中使用了聚合函数,则必须使用having来替换where。否则,报错。并且having必须声明在group by的后面

练习:查询各个部门中最高工资比10000高的部门信息
Select department_id,max(salary) from employee group by department_id having max(salary)>10000;
2)在开发中使用HAVING 的前提是mql中使用了GROUP BY。
练习:查询部门id为10,20,30,40这个部门中最高工资比10000高的部门信息
方式一:Select department_id,max(salary)from employees where department_id in (10,20,30,40) group by department_id having max(salary)>10000;
方式二:select department_id,max(salary) from employees group by department_id having max(salary)>10000 and department_id in(120,20,30,40);
推荐方式一,原因:执行效率高
结论:当过滤条件中有聚合函数时,则此过滤条件必须声明在having中
当过滤条件中没有聚合函数时,则此过滤条件声明在where中或having中都可以。但是,建议声明在where中
3)Where和having对比
①从适用范围上讲,having的适用范围更广
②如果过滤条件中没有聚合函数:这种情况下,where的执行效率高于having
5、SQL底层执行原理
1)Select 语句的完整结构
①SQL92语法
Select ……….(存在聚合函数)
From ……..,…..,
Where 多表连接条件 and 不包含聚合函数的过滤条件
Group by …….
Having 包含聚合函数的过滤条件
Order by…,….(asc/desc)
Limit …,…
②SQL99语法
Select ……….(存在聚合函数)
From …(left/right)join….on 多表连接条件 (left/right)join … on 多表连接条件
Where不包含聚合函数的过滤条件
Group by …….
Having 包含聚合函数的过滤条件
Order by…,….(asc/desc)
Limit …,…
③Sql语句的执行过程
From—>on—>(left/right join)—>where—>group by—>having—>select—>distinct—>order by—>limit