Pandas进阶修炼120题-第二期(Pandas数据处理,21-50题)
文章目录
- 往期回顾:
-
- 第一期:Pandas基础(1-20题)
- 第二期:Pandas数据处理(21-50题)
- 第三期:Pandas金融数据处理(51-80题)
- Pandas进阶修炼120题
-
- 第二期 Pandas数据处理
-
- 21.读取本地EXCEL数据
- 22.查看df数据前5行
- 23.将salary列数据转换为最大值与最小值的平均值
-
- 方法一:正则表达式(分别使用apply(),applymap(),map()来实现)
- 方法二:apply + 自定义函数
- 24.将数据根据学历进行分组并计算平均薪资
- 25.将createTime列时间转换为月-日
-
- 方法一:数据由时间戳格式转为时间日期格式,再修改格式
- 方法二:常规方法(挨个修改)
- 方法三:分别使用apply,applymap,map使用lambda 函数批量修改
- 26.查看索引、数据类型和内存信息
- 27.查看数值型列的汇总统计
- 28.新增一列根据salary将数据分为三组
-
- 方法一:pd.cut() 自定义箱子
- 方法二:pd.qcut() 自动划分为数量大致相等的箱子
- 29.按照salary列对数据降序排列
- 30.取出第33行数据
-
- 方法一:df.loc[n]
- 方法二:df.iloc[n]
- 方法三:df.iloc[n-1,:]
- 方法四:df[n-1:n]
- 方法五:df.iloc[n:n+1],df.loc[n:n+1]
- 31.计算salary列的中位数
- 32.绘制薪资水平频率分布直方图
-
- 方法一:直接使用自带的plot绘制
- 方法二:使用matplotlib.pyplot绘制
- 方法三:方法二的拓展,添加数据标签
- 33.绘制薪资水平密度曲线
-
- 方法一:直接使用plot绘制
- 方法二:使用seaborn画图
- 34.删除最后一列categories
-
- 方法一:指定labels,axis
- 方法二:方法一(labels,axis = 1)的替代方法,columns = labels
- 35.将df的第一列与第二列合并为新的一列
- 36.将education列与salary列合并为新的一列
- 37.计算salary最大值与最小值之差
-
- 方法一:直接计算
- 方法二:分别使用apply,applymap,map,并使用lambda函数来实现
- 38.将第一行与最后一行拼接
-
- 1.分步执行
- 2.直接一句话执行
- 39.将第8行数据添加至末尾
- 40.查看每列的数据类型
- 41.将createTime列设置为索引
- 42.生成一个和df长度相同的随机数DataFrame
- 43.将上一题生成的DataFrame与df合并
- 44.生成新的一列new为salary列减去之前生成随机数列
- 45.检查数据中是否含有任何缺失值
-
- 方法一:判断行,列,行&列空值的方法
- 方法二:标准答案使用.values的原因就是为了避免连续使用any()
- 46.将salary列类型转换为浮点数
- 47.计算salary大于10000的次数
- 48.查看每种学历出现的次数
- 49.查看education列共有几种学历
- 50.提取salary与new列的和大于60000的最后3行
-
- 方法一:布尔索引 + tail()
- 方法二:标准答案解析
自己再写一遍的pandas习题,相比于标准答案添加了自己的理解与注释,也可直接下载链接上的习题
链接:https://pan.baidu.com/s/1arrqcBFZKqJngzRzUB2QfA?pwd=29eb
提取码:29eb
–来自百度网盘超级会员V3的分享
往期回顾:
-
第一期:Pandas基础(1-20题)
-
第二期:Pandas数据处理(21-50题)
-
第三期:Pandas金融数据处理(51-80题)
Pandas进阶修炼120题
第二期 Pandas数据处理
21.读取本地EXCEL数据
import pandas as pd
df = pd.read_excel('pandas120_21_50.xlsx')
22.查看df数据前5行
df.head()
| createTime | education | salary | |
|---|---|---|---|
| 0 | 2020-03-16 11:30:18 | 本科 | 20k-35k |
| 1 | 2020-03-16 10:58:48 | 本科 | 20k-40k |
| 2 | 2020-03-16 10:46:39 | 不限 | 20k-35k |
| 3 | 2020-03-16 10:45:44 | 本科 | 13k-20k |
| 4 | 2020-03-16 10:20:41 | 本科 | 10k-20k |
23.将salary列数据转换为最大值与最小值的平均值
方法一:正则表达式(分别使用apply(),applymap(),map()来实现)
总结
· apply:应用在DataFrame的行或列中,也可以应用到单独一个Series的每个元素中
· map:应用在单独一个Series的每个元素中
· applymap:应用在DataFrame的每个元素中
import re
def func_re(x):
"""
x:待解析的字符串
方法:通过正则表达式解析最小值与最大值,然后输出平均值
return:返回中间值
"""
pattern = r'(\d+)k-(\d+)'
matches = re.findall(r'(\d+)k-(\d+)k',x)[0]
average_num = int(((int(matches[0]) + int(matches[1])) / 2) * 1000)
return average_num
# 使用apply()进行数据转换
t_df = df[:].copy()
t_df['salary'] = t_df['salary'].apply(func_re)
t_df
| createTime | education | salary | |
|---|---|---|---|
| 0 | 2020-03-16 11:30:18 | 本科 | 27500 |
| 1 | 2020-03-16 10:58:48 | 本科 | 30000 |
| 2 | 2020-03-16 10:46:39 | 不限 | 27500 |
| 3 | 2020-03-16 10:45:44 | 本科 | 16500 |
| 4 | 2020-03-16 10:20:41 | 本科 | 15000 |
| ... | ... | ... | ... |
| 130 | 2020-03-16 11:36:07 | 本科 | 14000 |
| 131 | 2020-03-16 09:54:47 | 硕士 | 37500 |
| 132 | 2020-03-16 10:48:32 | 本科 | 30000 |
| 133 | 2020-03-16 10:46:31 | 本科 | 19000 |
| 134 | 2020-03-16 11:19:38 | 本科 | 30000 |
135 rows × 3 columns
# 使用map()进行数据转换
t_df = df[:].copy()
t_df['salary'] = t_df['salary'].map(func_re)
t_df
| createTime | education | salary | |
|---|---|---|---|
| 0 | 2020-03-16 11:30:18 | 本科 | 27500 |
| 1 | 2020-03-16 10:58:48 | 本科 | 30000 |
| 2 | 2020-03-16 10:46:39 | 不限 | 27500 |
| 3 | 2020-03-16 10:45:44 | 本科 | 16500 |
| 4 | 2020-03-16 10:20:41 | 本科 | 15000 |
| ... | ... | ... | ... |
| 130 | 2020-03-16 11:36:07 | 本科 | 14000 |
| 131 | 2020-03-16 09:54:47 | 硕士 | 37500 |
| 132 | 2020-03-16 10:48:32 | 本科 | 30000 |
| 133 | 2020-03-16 10:46:31 | 本科 | 19000 |
| 134 | 2020-03-16 11:19:38 | 本科 | 30000 |
135 rows × 3 columns
# 使用apply()进行数据转换
t_df = df[:].copy()
t_df['salary'] = t_df[['salary']].applymap(func_re) # 注意series是没有applymap的,需要对花式索引后的结果(DataFrame类型)使用
t_df
| createTime | education | salary | |
|---|---|---|---|
| 0 | 2020-03-16 11:30:18 | 本科 | 27500 |
| 1 | 2020-03-16 10:58:48 | 本科 | 30000 |
| 2 | 2020-03-16 10:46:39 | 不限 | 27500 |
| 3 | 2020-03-16 10:45:44 | 本科 | 16500 |
| 4 | 2020-03-16 10:20:41 | 本科 | 15000 |
| ... | ... | ... | ... |
| 130 | 2020-03-16 11:36:07 | 本科 | 14000 |
| 131 | 2020-03-16 09:54:47 | 硕士 | 37500 |
| 132 | 2020-03-16 10:48:32 | 本科 | 30000 |
| 133 | 2020-03-16 10:46:31 | 本科 | 19000 |
| 134 | 2020-03-16 11:19:38 | 本科 | 30000 |
135 rows × 3 columns
方法二:apply + 自定义函数
和方法一不同的是使用已有的函数来对字符串提取分离
t_df = df[:].copy()
def func(df):
lst = df['salary'].split('-')
smin = int(lst[0].strip('k'))
smax = int(lst[1].strip('k'))
df['salary'] = int((smin + smax) / 2 * 1000)
return df
t_df = t_df.apply(func, axis=1)
t_df
| createTime | education | salary | |
|---|---|---|---|
| 0 | 2020-03-16 11:30:18 | 本科 | 27500 |
| 1 | 2020-03-16 10:58:48 | 本科 | 30000 |
| 2 | 2020-03-16 10:46:39 | 不限 | 27500 |
| 3 | 2020-03-16 10:45:44 | 本科 | 16500 |
| 4 | 2020-03-16 10:20:41 | 本科 | 15000 |
| ... | ... | ... | ... |
| 130 | 2020-03-16 11:36:07 | 本科 | 14000 |
| 131 | 2020-03-16 09:54:47 | 硕士 | 37500 |
| 132 | 2020-03-16 10:48:32 | 本科 | 30000 |
| 133 | 2020-03-16 10:46:31 | 本科 | 19000 |
| 134 | 2020-03-16 11:19:38 | 本科 | 30000 |
135 rows × 3 columns
# strip()函数用于去除字符串两侧的空格,也可以去除别的字符比如strip(k)
def func(df):
# 先将字符串以'-'分割
lst = df['salary'].split('-') # 这个地方有点奇怪,函数外直接这么写是错的,会报错AttributeError: 'Series' object has no attribute 'split'
# 分割后的字符串去除掉‘k’,再转为整形,即为最小值与最大值
smin = int(lst[0].strip('k'))
smax = int(lst[1].strip('k'))
df['salary'] = int((smin + smax) / 2 * 1000)
return df
df = df.apply(func,axis = 1) #注意函数中如果是直接对df某一列操作的,需要说明axis = 1
df
| createTime | education | salary | |
|---|---|---|---|
| 0 | 2020-03-16 11:30:18 | 本科 | 27500 |
| 1 | 2020-03-16 10:58:48 | 本科 | 30000 |
| 2 | 2020-03-16 10:46:39 | 不限 | 27500 |
| 3 | 2020-03-16 10:45:44 | 本科 | 16500 |
| 4 | 2020-03-16 10:20:41 | 本科 | 15000 |
| ... | ... | ... | ... |
| 130 | 2020-03-16 11:36:07 | 本科 | 14000 |
| 131 | 2020-03-16 09:54:47 | 硕士 | 37500 |
| 132 | 2020-03-16 10:48:32 | 本科 | 30000 |
| 133 | 2020-03-16 10:46:31 | 本科 | 19000 |
| 134 | 2020-03-16 11:19:38 | 本科 | 30000 |
135 rows × 3 columns
24.将数据根据学历进行分组并计算平均薪资
# 方法一:
df.groupby(by = ['education'])[['salary']].mean()
| salary | |
|---|---|
| education | |
| 不限 | 19600.000000 |
| 大专 | 10000.000000 |
| 本科 | 19361.344538 |
| 硕士 | 20642.857143 |
# 方法二:标准答案,可以看出groupby后直接.mean()只会对salary奏效
df.groupby(by = ['education']).mean()
C:\Users\Cheng\AppData\Local\Temp\ipykernel_9028\3549734645.py:2: FutureWarning: The default value of numeric_only in DataFrameGroupBy.mean is deprecated. In a future version, numeric_only will default to False. Either specify numeric_only or select only columns which should be valid for the function.
df.groupby(by = ['education']).mean()
| salary | |
|---|---|
| education | |
| 不限 | 19600.000000 |
| 大专 | 10000.000000 |
| 本科 | 19361.344538 |
| 硕士 | 20642.857143 |
25.将createTime列时间转换为月-日
to_pydatetime()函数:用于将时间序列数据转换为Python的datetime对象
strftime()函数:用于将日期时间格式化为字符串。它接受一个日期时间对象和一个格式化字符串作为参数,并返回一个格式化后的字符串。
思路:先将字符串转换为datetime对象,在确定格式后重新已字符串的形式存储
此外,标准答案中的ix要被版本淘汰了,尽量使用其他的做替换
方法一:数据由时间戳格式转为时间日期格式,再修改格式
要将createTime列转换为月-日格式,可以使用strftime()函数修改格式,但它需要接受日期时间对象。
可以使用pandas中的dt访问器,它提供了对Series值的datetime属性的访问。
t_df = df[:].copy()
# t_df['createTime'] = t_df['createTime'].to_datetime() # 直接写这句会报错,AttributeError: 'Series' object has no attribute 'to_datetime'
t_df['createTime'] = pd.to_datetime(t_df['createTime'])
t_df['createTime'] = t_df['createTime'].dt.strftime("%m-%d") # .strftime("%m-%d")
t_df
| createTime | education | salary | |
|---|---|---|---|
| 0 | 03-16 | 本科 | 27500 |
| 1 | 03-16 | 本科 | 30000 |
| 2 | 03-16 | 不限 | 27500 |
| 3 | 03-16 | 本科 | 16500 |
| 4 | 03-16 | 本科 | 15000 |
| ... | ... | ... | ... |
| 130 | 03-16 | 本科 | 14000 |
| 131 | 03-16 | 硕士 | 37500 |
| 132 | 03-16 | 本科 | 30000 |
| 133 | 03-16 | 本科 | 19000 |
| 134 | 03-16 | 本科 | 30000 |
135 rows × 3 columns
方法二:常规方法(挨个修改)
要将createTime列转换为月-日格式,可以使用strftime()函数修改格式,但它需要接受日期时间对象。
可以使用iloc访问并修改每个时间戳的格式,使用to_pydatetime()来转换格式。
t_df = df[:].copy()
length = len(t_df)
for i in range(length):
t_df.iloc[i,0] = t_df.iloc[i,0].to_pydatetime().strftime("%m-%d")
t_df
| createTime | education | salary | |
|---|---|---|---|
| 0 | 03-16 | 本科 | 27500 |
| 1 | 03-16 | 本科 | 30000 |
| 2 | 03-16 | 不限 | 27500 |
| 3 | 03-16 | 本科 | 16500 |
| 4 | 03-16 | 本科 | 15000 |
| ... | ... | ... | ... |
| 130 | 03-16 | 本科 | 14000 |
| 131 | 03-16 | 硕士 | 37500 |
| 132 | 03-16 | 本科 | 30000 |
| 133 | 03-16 | 本科 | 19000 |
| 134 | 03-16 | 本科 | 30000 |
135 rows × 3 columns
方法三:分别使用apply,applymap,map使用lambda 函数批量修改
方法二的lambda函数版本
t_df = df[:].copy()
t_df['createTime'] = t_df['createTime'].apply(lambda x:x.to_pydatetime().strftime("%m-%d"))
t_df
| createTime | education | salary | |
|---|---|---|---|
| 0 | 03-16 | 本科 | 27500 |
| 1 | 03-16 | 本科 | 30000 |
| 2 | 03-16 | 不限 | 27500 |
| 3 | 03-16 | 本科 | 16500 |
| 4 | 03-16 | 本科 | 15000 |
| ... | ... | ... | ... |
| 130 | 03-16 | 本科 | 14000 |
| 131 | 03-16 | 硕士 | 37500 |
| 132 | 03-16 | 本科 | 30000 |
| 133 | 03-16 | 本科 | 19000 |
| 134 | 03-16 | 本科 | 30000 |
135 rows × 3 columns
t_df = df[:].copy()
t_df['createTime'] = t_df[['createTime']].applymap(lambda x:x.to_pydatetime().strftime("%m-%d"))
t_df
| createTime | education | salary | |
|---|---|---|---|
| 0 | 03-16 | 本科 | 27500 |
| 1 | 03-16 | 本科 | 30000 |
| 2 | 03-16 | 不限 | 27500 |
| 3 | 03-16 | 本科 | 16500 |
| 4 | 03-16 | 本科 | 15000 |
| ... | ... | ... | ... |
| 130 | 03-16 | 本科 | 14000 |
| 131 | 03-16 | 硕士 | 37500 |
| 132 | 03-16 | 本科 | 30000 |
| 133 | 03-16 | 本科 | 19000 |
| 134 | 03-16 | 本科 | 30000 |
135 rows × 3 columns
df['createTime'] = df['createTime'].map(lambda x:x.to_pydatetime().strftime("%m-%d"))
df
| createTime | education | salary | |
|---|---|---|---|
| 0 | 03-16 | 本科 | 27500 |
| 1 | 03-16 | 本科 | 30000 |
| 2 | 03-16 | 不限 | 27500 |
| 3 | 03-16 | 本科 | 16500 |
| 4 | 03-16 | 本科 | 15000 |
| ... | ... | ... | ... |
| 130 | 03-16 | 本科 | 14000 |
| 131 | 03-16 | 硕士 | 37500 |
| 132 | 03-16 | 本科 | 30000 |
| 133 | 03-16 | 本科 | 19000 |
| 134 | 03-16 | 本科 | 30000 |
135 rows × 3 columns
26.查看索引、数据类型和内存信息
df.info()
RangeIndex: 135 entries, 0 to 134
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 createTime 135 non-null object
1 education 135 non-null object
2 salary 135 non-null int64
dtypes: int64(1), object(2)
memory usage: 3.3+ KB
27.查看数值型列的汇总统计
df.describe()
| salary | |
|---|---|
| count | 135.000000 |
| mean | 19159.259259 |
| std | 8661.686922 |
| min | 3500.000000 |
| 25% | 14000.000000 |
| 50% | 17500.000000 |
| 75% | 25000.000000 |
| max | 45000.000000 |
28.新增一列根据salary将数据分为三组
方法一:pd.cut() 自定义箱子
t_df = df[:].copy()
bins = [0,5000,15000,float('inf')]
labels = ['low','middle','high']
t_df['salary-category'] = pd.cut(t_df['salary'],bins = bins,labels = labels)
t_df
| createTime | education | salary | salary-category | |
|---|---|---|---|---|
| 0 | 03-16 | 本科 | 27500 | high |
| 1 | 03-16 | 本科 | 30000 | high |
| 2 | 03-16 | 不限 | 27500 | high |
| 3 | 03-16 | 本科 | 16500 | high |
| 4 | 03-16 | 本科 | 15000 | middle |
| ... | ... | ... | ... | ... |
| 130 | 03-16 | 本科 | 14000 | middle |
| 131 | 03-16 | 硕士 | 37500 | high |
| 132 | 03-16 | 本科 | 30000 | high |
| 133 | 03-16 | 本科 | 19000 | high |
| 134 | 03-16 | 本科 | 30000 | high |
135 rows × 4 columns
t_df.groupby(by = ['salary-category'])['salary'].count()
salary-category
low 9
middle 47
high 79
Name: salary, dtype: int64
方法二:pd.qcut() 自动划分为数量大致相等的箱子
labels = ['low','middle','high']
df['salary-category'] = pd.qcut(df['salary'],q = 3,labels = labels)
df
| createTime | education | salary | salary-category | |
|---|---|---|---|---|
| 0 | 03-16 | 本科 | 27500 | high |
| 1 | 03-16 | 本科 | 30000 | high |
| 2 | 03-16 | 不限 | 27500 | high |
| 3 | 03-16 | 本科 | 16500 | middle |
| 4 | 03-16 | 本科 | 15000 | low |
| ... | ... | ... | ... | ... |
| 130 | 03-16 | 本科 | 14000 | low |
| 131 | 03-16 | 硕士 | 37500 | high |
| 132 | 03-16 | 本科 | 30000 | high |
| 133 | 03-16 | 本科 | 19000 | middle |
| 134 | 03-16 | 本科 | 30000 | high |
135 rows × 4 columns
df.groupby(by = ['salary-category'])['salary'].count()
salary-category
low 56
middle 41
high 38
Name: salary, dtype: int64
29.按照salary列对数据降序排列
df.sort_values(by = ['salary'],ascending = False,inplace = True,ignore_index = True)
df
| createTime | education | salary | salary-category | |
|---|---|---|---|---|
| 0 | 03-16 | 本科 | 45000 | high |
| 1 | 03-16 | 本科 | 40000 | high |
| 2 | 03-16 | 本科 | 37500 | high |
| 3 | 03-16 | 本科 | 37500 | high |
| 4 | 03-16 | 硕士 | 37500 | high |
| ... | ... | ... | ... | ... |
| 130 | 03-16 | 本科 | 4500 | low |
| 131 | 03-16 | 本科 | 4000 | low |
| 132 | 03-16 | 本科 | 4000 | low |
| 133 | 03-16 | 不限 | 3500 | low |
| 134 | 03-16 | 本科 | 3500 | low |
135 rows × 4 columns
30.取出第33行数据
方法一:df.loc[n]
df.loc[32]
createTime 03-16
education 本科
salary 25000
salary-category high
Name: 32, dtype: object
方法二:df.iloc[n]
df.iloc[32]
createTime 03-16
education 本科
salary 25000
salary-category high
Name: 32, dtype: object
方法三:df.iloc[n-1,:]
df.iloc[32,:]
createTime 03-16
education 本科
salary 25000
salary-category high
Name: 32, dtype: object
方法四:df[n-1:n]
df[32:33]
| createTime | education | salary | salary-category | |
|---|---|---|---|---|
| 32 | 03-16 | 本科 | 25000 | high |
方法五:df.iloc[n:n+1],df.loc[n:n+1]
需要注意的是,’ iloc ‘和’ loc '也可以接受一个范围,例如 df .iloc[N:N+1] or df.loc[N:N+1] ,这些也会返回一个DataFrame。
df.loc[32:33]
| createTime | education | salary | salary-category | |
|---|---|---|---|---|
| 32 | 03-16 | 本科 | 25000 | high |
| 33 | 03-16 | 本科 | 25000 | high |
31.计算salary列的中位数
df['salary'].median()
17500.0
np.median(df['salary'])
17500.0
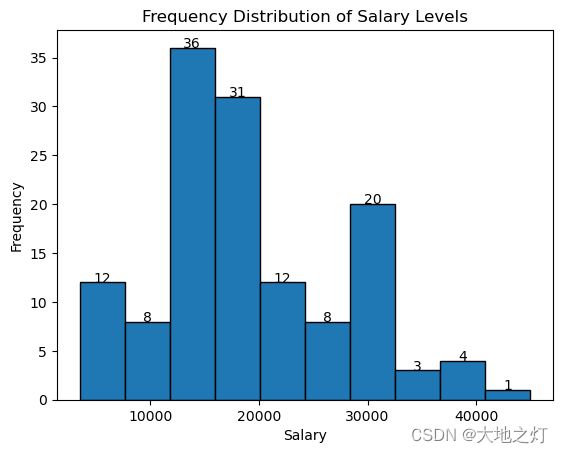
32.绘制薪资水平频率分布直方图
方法一:直接使用自带的plot绘制
df['salary'].plot(kind = 'hist',edgecolor = 'black')

方法二:使用matplotlib.pyplot绘制
import matplotlib.pyplot as plt
plt.hist(df['salary'],bins = 10,edgecolor = 'black') # bins默认为10
plt.title('Frequency Distribution of Salary Levels')
plt.xlabel('Salary')
plt.ylabel('Frequency')
plt.show()

方法三:方法二的拓展,添加数据标签
n,bins,patches = plt.hist(df[‘salary’], bins=10, edgecolor=‘black’)创建直方图并返回三个对象:n(直方图bins的值),bins (bins的边缘)和patches(用于创建直方图的单个patch)。
for循环遍历直方图中的每个patch。对于每个补丁,plt.text()用于添加文本标签。plt.text()的前两个参数指定文本的位置(在本例中是补丁上边缘的中心),第三个参数是要添加的文本(在本例中是bin的值,格式为整数)。ha = 'center’指定文本水平居中。
其余的代码与前面相同。
import matplotlib.pyplot as plt
n, bins, patches = plt.hist(df['salary'],bins = 10,edgecolor = 'black')
"""
print(n) # [12. 8. 36. 31. 12. 8. 20. 3. 4. 1.]
print(bins) # [ 3500. 7650. 11800. 15950. 20100. 24250. 28400. 32550. 36700. 40850. 45000.]
print(patches) #
"""
# Add labels to each bin
for i in range(len(patches)):
plt.text(
patches[i].get_x()+patches[i].get_width()/2.,
patches[i].get_height(),
f'{n[i]:.0f}',
ha = 'center'
)
plt.title('Frequency Distribution of Salary Levels')
plt.xlabel('Salary')
plt.ylabel('Frequency')
plt.show()
33.绘制薪资水平密度曲线
直方图和密度曲线的关系:
直方图和密度曲线(也称为水平曲线或核密度估计)都是可用于分析数据集分布的图形表示。它们提供了类似的信息,但它们的呈现方式略有不同。
直方图:直方图是数据集分布的图形表示。它是对一个连续变量的概率分布的估计。要构造一个直方图,第一步是对范围内的值进行“分组”——也就是说,将整个范围内的值分成一系列的区间——然后计算每个区间内有多少个值。箱子通常被指定为一个变量的连续的、不重叠的间隔。绘制的值表示每个bin内的观测值计数。
密度曲线(平坦度曲线):密度曲线是直方图的平滑版本,用于可视化分布的“形状”。它是直方图的一种变体,使用核平滑来绘制值,通过平滑噪声来实现更平滑的分布。密度图的峰值有助于显示值在区间内的集中位置。y轴表示密度:曲线在给定x值处的高度表示该值出现的概率密度。
两者之间的关系是,它们都提供了数据分布的可视化解释。直方图只提供每个箱中值的原始计数,而密度曲线提供了更平滑的分布估计。密度图曲线下的面积(或直方图中条形图的总面积)之和为1。
在许多情况下,密度图可能受箱宽选择的影响较小,并且通常可以更好地理解分布的形状,使其成为许多数据分析师的首选,而不是直方图。然而,直方图对于非技术人员来说可能更直观,因为它们提供了不同类别中数据计数的直观表示。
方法一:直接使用plot绘制
df.salary.plot(kind = 'kde',xlim = (0,80000))

方法二:使用seaborn画图
import seaborn as sns
import matplotlib.pyplot as plt
sns.kdeplot(df['salary'],color = 'darkblue')
plt.title('Density Plot of Salary Levels')
plt.xlabel('Salary')
plt.ylabel('Density')
plt.show()

34.删除最后一列categories
注意:默认情况下,drop不会修改DataFrame;它返回一个删除指定行或列的新DataFrame。
如果你想就地修改DataFrame,你可以传递inplace=True给drop。
方法一:指定labels,axis
t_df = df[:].copy()
t_df.drop(labels = ['salary-category'],axis = 1,inplace = True)
t_df.head()
| createTime | education | salary | |
|---|---|---|---|
| 0 | 03-16 | 本科 | 45000 |
| 1 | 03-16 | 本科 | 40000 |
| 2 | 03-16 | 本科 | 37500 |
| 3 | 03-16 | 本科 | 37500 |
| 4 | 03-16 | 硕士 | 37500 |
方法二:方法一(labels,axis = 1)的替代方法,columns = labels
df.drop(columns = ['salary-category'],inplace = True)
df.head()
| createTime | education | salary | |
|---|---|---|---|
| 0 | 03-16 | 本科 | 45000 |
| 1 | 03-16 | 本科 | 40000 |
| 2 | 03-16 | 本科 | 37500 |
| 3 | 03-16 | 本科 | 37500 |
| 4 | 03-16 | 硕士 | 37500 |
35.将df的第一列与第二列合并为新的一列
df['new_Column'] = df['createTime'] + df['education']
df.head()
| createTime | education | salary | new_Column | |
|---|---|---|---|---|
| 0 | 03-16 | 本科 | 45000 | 03-16本科 |
| 1 | 03-16 | 本科 | 40000 | 03-16本科 |
| 2 | 03-16 | 本科 | 37500 | 03-16本科 |
| 3 | 03-16 | 本科 | 37500 | 03-16本科 |
| 4 | 03-16 | 硕士 | 37500 | 03-16硕士 |
36.将education列与salary列合并为新的一列
df['new_Column2'] = df['education'] + df['salary'].map(str)
df.head()
| createTime | education | salary | new_Column | new_Column2 | |
|---|---|---|---|---|---|
| 0 | 03-16 | 本科 | 45000 | 03-16本科 | 本科45000 |
| 1 | 03-16 | 本科 | 40000 | 03-16本科 | 本科40000 |
| 2 | 03-16 | 本科 | 37500 | 03-16本科 | 本科37500 |
| 3 | 03-16 | 本科 | 37500 | 03-16本科 | 本科37500 |
| 4 | 03-16 | 硕士 | 37500 | 03-16硕士 | 硕士37500 |
37.计算salary最大值与最小值之差
方法一:直接计算
df['salary'].max() - df['salary'].min()
41500
方法二:分别使用apply,applymap,map,并使用lambda函数来实现
pandas中的map、apply和applymap函数分别用于将函数应用于series、series/dateframe或dataframe的元素。但是,计算列的最大值和最小值之间的差值是对整个序列的操作,而不是对单个元素的操作,因此通常不会使用这些函数来完成。
话虽如此,如果你真的想使用map, apply和applymap与lambda函数来解决这个问题,你可以做下面的事情:
1:使用apply:
apply用于沿dateframe的axis应用函数。
在此代码中,lambda函数计算“salary”列的最大值和最小值之间的差值。
你可以这样使用它:
df[['salary']].apply(lambda x:x.max()-x.min())
salary 41500
dtype: int64
2:使用map:
map用于series中每个元素的函数。
在这段代码中,lambda函数从每个工资中减去最低工资,然后使用max()找到这些值中的最大值,即最高工资和最低工资之间的差值。
df['salary'].map(lambda x:x-df['salary'].min()).max()
41500
3:使用applymap:
applymap用于dataframe中每个元素的函数。所以需要选择‘salary’列作为dataframe而非series。
这段代码与前面的代码类似,但是df[[‘salary’]]用于选择’salary’列作为dataframe,并且使用applymap代替map。
df[['salary']].applymap(lambda x:x-df['salary'].min()).max()
salary 41500
dtype: int64
38.将第一行与最后一行拼接
1.分步执行
# 获取第一行
first_row = df.iloc[[0]]
# 获取最后一行
last_row = df.iloc[[-1]]
# 拼接
frames = [first_row,last_row]
df_concat = pd.concat(frames,ignore_index = True)
# 重置索引
df_concat.reset_index(drop = True,inplace = True)
df_concat
| createTime | education | salary | new_Column | new_Column2 | |
|---|---|---|---|---|---|
| 0 | 03-16 | 本科 | 45000 | 03-16本科 | 本科45000 |
| 1 | 03-16 | 本科 | 3500 | 03-16本科 | 本科3500 |
2.直接一句话执行
df_concat = pd.concat([df[:1],df[-2:-1]],ignore_index = True).reset_index(drop = True)
df_concat
| createTime | education | salary | new_Column | new_Column2 | |
|---|---|---|---|---|---|
| 0 | 03-16 | 本科 | 45000 | 03-16本科 | 本科45000 |
| 1 | 03-16 | 不限 | 3500 | 03-16不限 | 不限3500 |
39.将第8行数据添加至末尾
df.append(df.iloc[[7]])
C:\Users\Cheng\AppData\Local\Temp\ipykernel_9028\3138359087.py:1: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df.append(df.iloc[[7]])
| createTime | education | salary | new_Column | new_Column2 | |
|---|---|---|---|---|---|
| 0 | 03-16 | 本科 | 45000 | 03-16本科 | 本科45000 |
| 1 | 03-16 | 本科 | 40000 | 03-16本科 | 本科40000 |
| 2 | 03-16 | 本科 | 37500 | 03-16本科 | 本科37500 |
| 3 | 03-16 | 本科 | 37500 | 03-16本科 | 本科37500 |
| 4 | 03-16 | 硕士 | 37500 | 03-16硕士 | 硕士37500 |
| ... | ... | ... | ... | ... | ... |
| 131 | 03-16 | 本科 | 4000 | 03-16本科 | 本科4000 |
| 132 | 03-16 | 本科 | 4000 | 03-16本科 | 本科4000 |
| 133 | 03-16 | 不限 | 3500 | 03-16不限 | 不限3500 |
| 134 | 03-16 | 本科 | 3500 | 03-16本科 | 本科3500 |
| 7 | 03-16 | 本科 | 35000 | 03-16本科 | 本科35000 |
136 rows × 5 columns
40.查看每列的数据类型
df.dtypes
createTime object
education object
salary int64
new_Column object
new_Column2 object
dtype: object
41.将createTime列设置为索引
df.set_index('createTime')
df
| createTime | education | salary | new_Column | new_Column2 | |
|---|---|---|---|---|---|
| 0 | 03-16 | 本科 | 45000 | 03-16本科 | 本科45000 |
| 1 | 03-16 | 本科 | 40000 | 03-16本科 | 本科40000 |
| 2 | 03-16 | 本科 | 37500 | 03-16本科 | 本科37500 |
| 3 | 03-16 | 本科 | 37500 | 03-16本科 | 本科37500 |
| 4 | 03-16 | 硕士 | 37500 | 03-16硕士 | 硕士37500 |
| ... | ... | ... | ... | ... | ... |
| 130 | 03-16 | 本科 | 4500 | 03-16本科 | 本科4500 |
| 131 | 03-16 | 本科 | 4000 | 03-16本科 | 本科4000 |
| 132 | 03-16 | 本科 | 4000 | 03-16本科 | 本科4000 |
| 133 | 03-16 | 不限 | 3500 | 03-16不限 | 不限3500 |
| 134 | 03-16 | 本科 | 3500 | 03-16本科 | 本科3500 |
135 rows × 5 columns
42.生成一个和df长度相同的随机数DataFrame
df_1 = pd.DataFrame(pd.Series(np.random.randint(1,10,135)))
df_1
| 0 | |
|---|---|
| 0 | 3 |
| 1 | 8 |
| 2 | 2 |
| 3 | 2 |
| 4 | 7 |
| ... | ... |
| 130 | 6 |
| 131 | 5 |
| 132 | 5 |
| 133 | 1 |
| 134 | 4 |
135 rows × 1 columns
43.将上一题生成的DataFrame与df合并
df = pd.concat([df,df_1],ignore_index = True,axis = 1)
df.columns = ['createTime','education','salary','new_Column','new_Column2','randint']
df
| createTime | education | salary | new_Column | new_Column2 | randint | |
|---|---|---|---|---|---|---|
| 0 | 03-16 | 本科 | 45000 | 03-16本科 | 本科45000 | 3 |
| 1 | 03-16 | 本科 | 40000 | 03-16本科 | 本科40000 | 8 |
| 2 | 03-16 | 本科 | 37500 | 03-16本科 | 本科37500 | 2 |
| 3 | 03-16 | 本科 | 37500 | 03-16本科 | 本科37500 | 2 |
| 4 | 03-16 | 硕士 | 37500 | 03-16硕士 | 硕士37500 | 7 |
| ... | ... | ... | ... | ... | ... | ... |
| 130 | 03-16 | 本科 | 4500 | 03-16本科 | 本科4500 | 6 |
| 131 | 03-16 | 本科 | 4000 | 03-16本科 | 本科4000 | 5 |
| 132 | 03-16 | 本科 | 4000 | 03-16本科 | 本科4000 | 5 |
| 133 | 03-16 | 不限 | 3500 | 03-16不限 | 不限3500 | 1 |
| 134 | 03-16 | 本科 | 3500 | 03-16本科 | 本科3500 | 4 |
135 rows × 6 columns
44.生成新的一列new为salary列减去之前生成随机数列
df['new'] = df['salary'] - df['randint']
df
| createTime | education | salary | new_Column | new_Column2 | randint | new | |
|---|---|---|---|---|---|---|---|
| 0 | 03-16 | 本科 | 45000 | 03-16本科 | 本科45000 | 3 | 44997 |
| 1 | 03-16 | 本科 | 40000 | 03-16本科 | 本科40000 | 8 | 39992 |
| 2 | 03-16 | 本科 | 37500 | 03-16本科 | 本科37500 | 2 | 37498 |
| 3 | 03-16 | 本科 | 37500 | 03-16本科 | 本科37500 | 2 | 37498 |
| 4 | 03-16 | 硕士 | 37500 | 03-16硕士 | 硕士37500 | 7 | 37493 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 130 | 03-16 | 本科 | 4500 | 03-16本科 | 本科4500 | 6 | 4494 |
| 131 | 03-16 | 本科 | 4000 | 03-16本科 | 本科4000 | 5 | 3995 |
| 132 | 03-16 | 本科 | 4000 | 03-16本科 | 本科4000 | 5 | 3995 |
| 133 | 03-16 | 不限 | 3500 | 03-16不限 | 不限3500 | 1 | 3499 |
| 134 | 03-16 | 本科 | 3500 | 03-16本科 | 本科3500 | 4 | 3496 |
135 rows × 7 columns
45.检查数据中是否含有任何缺失值
在Python中,DataFrame通常与pandas库相关联。要检查DataFrame中的空缺或缺失值,可以使用pandas提供的’ isnull() ‘或’ isna() '函数。
在上面的例子中,’ isnull() ‘函数返回与原始形状相同的DataFrame,但包含指示每个元素是否缺失的布尔值。然后,’ any() '函数检查每列或每行中是否有任何值为True, ’ any().any() '检查整个DataFrame中是否有任何True值。
方法一:判断行,列,行&列空值的方法
# 判断行是否有空值
column_vacancies = df.isnull().any()
# 判断列是否有空值
row_vacancies = df.isnull().any(axis = 1)
# 判断整个DataFrame中是否有空值
is_vacant = df.isnull().any().any()
# 打印结果
print(column_vacancies)
print("-------------------------------")
print(row_vacancies)
print("-------------------------------")
print(is_vacant)
createTime False
education False
salary False
new_Column False
new_Column2 False
randint False
new False
dtype: bool
-------------------------------
0 False
1 False
2 False
3 False
4 False
...
130 False
131 False
132 False
133 False
134 False
Length: 135, dtype: bool
-------------------------------
False
方法二:标准答案使用.values的原因就是为了避免连续使用any()
df.isnull().values.any()
False
46.将salary列类型转换为浮点数
df['salary'] = df['salary'].astype('float')
df.dtypes
createTime object
education object
salary float64
new_Column object
new_Column2 object
randint int32
new int64
dtype: object
47.计算salary大于10000的次数
len(df[df['salary']>10000])
119
48.查看每种学历出现的次数
df['education'].value_counts()
本科 119
硕士 7
不限 5
大专 4
Name: education, dtype: int64
49.查看education列共有几种学历
df['education'].nunique()
4
50.提取salary与new列的和大于60000的最后3行
方法一:布尔索引 + tail()
filtered_df = df[df['salary'] + df['new'] > 60000]
filtered_df.tail(3)
| createTime | education | salary | new_Column | new_Column2 | randint | new | |
|---|---|---|---|---|---|---|---|
| 6 | 03-16 | 本科 | 35000.0 | 03-16本科 | 本科35000 | 9 | 34991 |
| 7 | 03-16 | 本科 | 35000.0 | 03-16本科 | 本科35000 | 6 | 34994 |
| 8 | 03-16 | 本科 | 32500.0 | 03-16本科 | 本科32500 | 1 | 32499 |
方法二:标准答案解析
df1 = df[['salary','new']] # 通过花式索引选择salary和new列为新的DataFrame df1
rowsums = df1.apply(np.sum,axis = 1) # rowsums是df1中包含每一行的和的值的Series。np.sum沿着axis=1去计算每一行的值
# 基于rowsums大于60000的条件对df进行筛选
# 其中,np.where(rownums > 60000)[0]当条件为True的时候返回索引序列
# [-3:] 从索引序列中选择后三个索引
# 最后df.iloc用于根据索引从是原始DataFrame中选择对应的行,":",用于选择所有的列
res = df.iloc[np.where(rowsums > 60000)[0][-3:], :]
res
| createTime | education | salary | new_Column | new_Column2 | randint | new | |
|---|---|---|---|---|---|---|---|
| 6 | 03-16 | 本科 | 35000.0 | 03-16本科 | 本科35000 | 9 | 34991 |
| 7 | 03-16 | 本科 | 35000.0 | 03-16本科 | 本科35000 | 6 | 34994 |
| 8 | 03-16 | 本科 | 32500.0 | 03-16本科 | 本科32500 | 1 | 32499 |