DynamicDet: A Unified Dynamic Architecture for Object Detection 一个目标检测器的通用动态架构
目录
检测代码:
本文分享 CVPR 2023 论文『DynamicDet: A Unified Dynamic Architecture for Object Detection』,北京大学王选计算机研究所王勇涛团队所提出的一个目标检测器的通用动态架构。
具体信息如下:
- 论文:https://arxiv.org/abs/2304.05552
- 代码:https://github.com/VDIGPKU/DynamicDet
TL; DR
本文旨在设计一个动态目标检测器架构,通过为不同难易程度的图像自动化选择推理路径,以在目标检测任务上取得优秀的推理速度与精度权衡。具体而言,作者针对目标检测器的特点提出了一个通用动态架构,并设计了自适应路由器来自动为每个待检测图像选择最佳早退路线。同时,作者为所提出的通用动态架构设计了相应的无超参数训练策略和可变时延推理策略,以实现上述动态架构的有效训练与推理部署。如上图,作者在MS COCO目标检测数据集上进行了实验,结果显示所提方案显著超过了众多基准模型,取得了现阶段领先的精度与推理速度的权衡结果。
一、研究背景
人脑启发了深度学习和计算机视觉的众多领域,动态神经网络 (Dynamic Neural Network) 就是一个典型的例子。如上图所示,人类可以快速识别出左侧“简单”图像上的所有目标,但需要更多的时间识别出右侧“困难”图像上的目标。换句话说,人类大脑对不同图像的处理速度是不同的,而这一速度往往取决于理解图像的难易程度。
人脑的这种特性激发了对动态神经网络的研究,研究者们通过为不同难度的图像自适应地选择推理路线,在图像分类、人脸检测等任务上取得了极其优秀的精度与推理速度的权衡。
然而,由于缺乏适用于目标检测器的动态推理架构和早退 (early exiting) 策略,设计一个强大的动态目标检测器是颇具挑战的。
在本文中,作者提出了一个通用动态框架来实现目标检测器的动态推理,即DynamicDet。首先,针对目标检测器的特点提出了一个通用动态架构,并设计了**自适应路由器 (Adaptive Router) 来自动为每个待检测图像选择最佳早退路线。其次,作者为所提出的通用动态架构设计了相应的无超参数训练策略 (Hyperparameter-free Optimization Strategy) 和可变时延推理策略 (Variable-speed Inference Strategy) **。
二、研究方法
通用动态架构
目标检测器通常由主干网络Backbone、脖颈网络Neck、检测器头Head三部分组成,主干网络 (如ResNet50、Vision Transformer等等) 用于提取基础视觉特征,脖颈网络 (如FPN、BiFPN等等) 用于融合多尺度特征信息,检测器头则通过特定设计来预测目标的种类和位置。如上图,本文所提的目标检测器的通用动态架构也是基于此架构,但区别之处在于其拥有两个级联主干网络及对应的脖颈网络和检测器头,并且在两个主干网络之间插入了动态路由器 (Router) 。
以推理为例,首先,待检测图像将经过第一个主干网络提取第一级多尺度特征,并将该多尺度特征送入动态路由器评判该图像难易程度:
(1) 若判别为“简单”图像,则第一级多尺度特征将送入第一组脖颈网络和检测器头,输出检测结果;
(2) 若判别为“困难”图像,则待检测图像及其第一级多尺度特征将被送入第二个主干网络,提取获得第二级多尺度特征,并将第二级多尺度特征送入第二组的脖颈网络和检测器头,输出检测结果。值得注意的是,本文第二个主干网络处理图像及前一级多尺度特征的方案直接借鉴了组合主干网络 (CBNetV2) 的方案。
通过上述过程,“简单”图像仅由一个主干网络提取基础特征 (快速但粗糙) ,而“困难”图像则由两个级联的主干网络提取基础特征 (缓慢但精细) 。显然,该结构可以有效取得精度与推理速度的权衡。同时,得益于该架构的一般性,任意现有的目标检测器都可以快速延展并直接利用该方案。
自适应路由器
为更好地评判图像的难易程度,作者提出了自适应路由器 (Adaptive Router) ,并基于输入的多尺度特征信息来作出难易评判。
假设第一个主干网络输出的多尺度特征为,为降低动态路由器的计算复杂度,作者首先对其进行信息压缩,获得压缩后的特征:
其中为全局池化操作、为通道维度拼接操作。
之后,作者通过两个线性映射层将特征映射到难易评分:
其中,、分别表示ReLU和Sigmoid激活函数,是线性层的可学习参数。在本文中,第一个线性层将特征数压缩至,第二个则压缩至1 (即) 。
无超参数训练策略
作者为上述提出的通用动态架构设计了一套无超参数的训练策略。
(1) 首先,基于训练集数据联合训练级联的两组目标检测器,训练目标为
其中,、分别表示输入图像和真实标签,表示第组目标检测器的可学习参数,表示第组目标检测器训练损失 (即边界框回归损失和分类损失等) 。在该过程中,级联的两组目标检测器均通过训练拥有了检测目标的能力,因此在后续训练中其参数将被冻结。
(2) 之后,基于训练集数据训练自适应路由器。作者首先展示了一种朴素的做法,假设训练目标为
则自适应路由器所输出的将始终趋向于最大值 (即1) ,以通过尽可能多得选择“困难”图像的路线以取得最低损失,然而这显然不符合动态检测器的预期。
再进一步,一种常规的做法是在训练目标中增加额外的硬件惩罚项,如
但是,这将使得应用到不同检测器或不同硬件情景时需要反复试错以微调超参数,这会导致巨大的资源消耗。
为此,作者提出利用两组检测器的损失差来作为信号评判图像难易,并以此来训练自适应路由器。
如上图,作者发现“简单”图像在两组检测器上的损失差较小,而“困难”图像则较大。这是符合直觉的:由于“简单”图像信息含量少,第一组检测器已可以完成检测任务;而由于“困难”图像信息含量多,第一组检测器可能无法很好地完成检测任务,但精度更高的第二组检测器可以精确检测。
基于上述发现,作者引入了一个自适应偏移来奖励第一组检测器、惩罚第二组检测器:
其中即为所述的自适应偏移,它为两组检测器在训练集数据上损失差的中位数。在实际应用时,该自适应偏移可以离线统计获得,也可以在训练过程中基于训练数据动态更新。
可变时延推理策略
作者为上述提出的通用动态架构设计了一套可变时延推理策略。
在推理时,自适应路由器将输出待检测图像的难易评分,作者发现可以通过为同一个动态检测器设置不同的难易阈值直接获取一系列的精度与推理速度的权衡,从而满足不同的时延需求。同时,为直接获取特定推理时延的难易阈值,作者提出了一个简单但有效的方案。
(1) 统计所有验证集数据的难易评分,为;
(2) 基于特定时延需求 (假设为) ,利用下式获得难易比例:
其中、分别为第一组和第二组检测器的推理时延;
(3) 获取在验证集上的难易阈值:
其中,用以求得给定集合的第分位数。值得注意的是,考虑到验证集和测试集的数据是符合独立同分布的,则可以直接应用到测试集。
三、实验结果
本文在MS COCO目标检测数据集上进行了实验。如下表所示,作者以YOLOv7系列模型为基准,在此基础上将YOLOv7、YOLOv7-X、YOLOv7-W6拓展为动态目标检测器,取得了超过基准模型的一系列精度与推理速度的权衡结果。例如,Dy-YOLOv7-W6 / 90 (10%的图像被划分为“简单”,90%被划分为“困难”) 在48 FPS下取得了56.7% AP,在相似精度下较YOLOv7-D6提速17%;Dy-YOLOv7-W6 / 100 在46 FPS下取得了56.8% AP,在相似精度下较YOLOv7-E6E提速39%。
值得注意的是,与常规的模型放缩方案不同,本文所提的动态目标检测器方案仅需一个模型,就能直接取得一系列精度与推理速度的权衡结果。
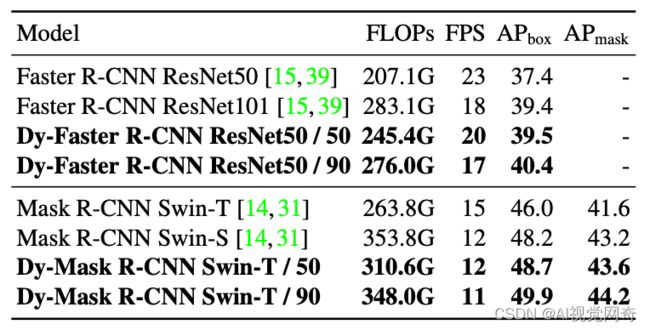
作者在二阶段检测器上也进行了实验,基准模型为Faster R-CNN ResNet和Mask R-CNN Swin Transformer。如下表,以Dy-Mask R-CNN Swin-T / 50 为例, 其在12 FPS下取得了48.7% AP (bbox),与Mask R-CNN Swin-S速度相同但精度提升0.5%。
为展示动态目标检测器评分的有效性,作者在下图中对不同图片的难易评分进行了可视化展示。从图中可以看到,”简单“图像通常包含更少的目标,有着常规的摄像视角和整洁的背景;而”困难“图像通常包含更多且更小的目标,并有着更复杂的场景 (如遮挡等) 。

四、结语
本文提出了一个针对目标检测器的通用动态架构,并提出了一整套的训练与推理流程,可以基于现有模型快速获得动态目标检测器。作者以多个典型的目标检测器为基准进行了充分的实验,结果显示所提方案在仅利用一个动态目标检测器模型的情况下,可以取得一系列优秀的精度与推理速度的权衡结果,显著超过基准模型。
检测代码:
import argparse
import time
import logging
from pathlib import Path
import cv2
import torch
import torch.nn as nn
import torch.backends.cudnn as cudnn
from numpy import random
from models.yolo import Model
from utils.datasets import LoadStreams, LoadImages
from utils.general import check_img_size, check_imshow, non_max_suppression, \
scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path
from utils.plots import plot_one_box
from utils.torch_utils import select_device, time_synchronized, intersect_dicts
logger = logging.getLogger(__name__)
def detect(save_img=False):
source, cfg, weight, view_img, save_txt, nc, imgsz = opt.source, opt.cfg, opt.weight, \
opt.view_img, opt.save_txt, opt.num_classes, opt.img_size
save_img = not opt.nosave and not source.endswith('.txt') # save inference images
webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(
('rtsp://', 'rtmp://', 'http://', 'https://'))
# Directories
save_dir = Path(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok)) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Initialize
set_logging()
device = select_device(opt.device)
half = device.type != 'cpu' # half precision only supported on CUDA
# Load model
model = Model(cfg, ch=3, nc=nc) # create
state_dict = torch.load(weight, map_location='cpu')['model']
state_dict = intersect_dicts(state_dict, model.state_dict()) # intersect
model.load_state_dict(state_dict, strict=False) # load
model.to(device)
logger.info('Transferred %g/%g items from %s' % (len(state_dict), len(model.state_dict()), weight)) # report
for p in model.parameters():
p.requires_grad = False
model.float().fuse().eval()
# Compatibility updates
for m in model.modules():
if type(m) in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU]:
m.inplace = True # pytorch 1.7.0 compatibility
elif type(m) is nn.Upsample:
m.recompute_scale_factor = None # torch 1.11.0 compatibility
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check img_size
if hasattr(model, 'dy_thres'):
model.dy_thres = opt.dy_thres
logger.info('Set dynamic threshold to %f' % opt.dy_thres)
if half:
model.half() # to FP16
# Set Dataloader
vid_path, vid_writer = None, None
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride)
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride)
# Get names and colors
names = model.module.names if hasattr(model, 'module') else model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
old_img_w = old_img_h = imgsz
old_img_b = 1
t0 = time.time()
for path, img, im0s, vid_cap in dataset:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Warmup
if device.type != 'cpu' and (old_img_b != img.shape[0] or old_img_h != img.shape[2] or old_img_w != img.shape[3]):
old_img_b = img.shape[0]
old_img_h = img.shape[2]
old_img_w = img.shape[3]
for i in range(3):
model(img, augment=opt.augment)[0]
# Inference
t1 = time_synchronized()
with torch.no_grad(): # Calculating gradients would cause a GPU memory leak
pred = model(img, augment=opt.augment)[0]
t2 = time_synchronized()
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t3 = time_synchronized()
# Process detections
for i, det in enumerate(pred): # detections per image
if webcam: # batch_size >= 1
p, s, im0, frame = path[i], '%g: ' % i, im0s[i].copy(), dataset.count
else:
p, s, im0, frame = path, '', im0s, getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # img.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or view_img: # Add bbox to image
label = f'{names[int(cls)]} {conf:.2f}'
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=1)
# Print time (inference + NMS)
print(f'{s}Done. ({(1E3 * (t2 - t1)):.1f}ms) Inference, ({(1E3 * (t3 - t2)):.1f}ms) NMS')
# Stream results
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
print(f" The image with the result is saved in: {save_path}")
else: # 'video' or 'stream'
if vid_path != save_path: # new video
vid_path = save_path
if isinstance(vid_writer, cv2.VideoWriter):
vid_writer.release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path += '.mp4'
vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer.write(im0)
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
#print(f"Results saved to {save_dir}{s}")
print(f'Done. ({time.time() - t0:.3f}s)')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--cfg', type=str, default='cfg/dy-yolov7-step1.yaml', help='model.yaml path')
parser.add_argument('--weight', type=str, default='dy-yolov7.pt', help='model.pt path(s)')
parser.add_argument('--num-classes', type=int, default=80, help='number of classes')
# parser.add_argument('--source', type=str, default='demo/demo.mp4', help='source') # file/folder, 0 for webcam
parser.add_argument('--source', type=str, default=r'D:\data\mp4\jupter_240\high_res_20230509-172731_1683624451037_1_237.mp4', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view_img', action='store_true',default=True,help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--dy-thres', type=float, default=0.5, help='dynamic thres')
opt = parser.parse_args()
print(opt)
with torch.no_grad():
detect()