单链表的头插法与尾插法详解
创建单链表
关于数据结构的入门,就是从顺序表和单链表开始。
我们不讲顺序表,直接从单链表开始我们的数据结构和算法的学习之路。
单链表就是一种特殊的结构体组合而成的数据结构,关于单链表的创建方法有很多种,但都大同小异。

正如这幅图中所表示的那样,单链表就是由可能不连续的数据所组合而成的数据结构。 其中每个数据分为两部分,一部分是数据存储的位置,称为数据域,另外指针所存储的地方,称为指针域。
typedef struct Node {
int data; // 存储链表数据
struct Node *next; // 存储结点的地址
}LNode,*Linklist;
在进入创建链表之前,我们先写好主函数的用来输出的输出函数。
void Illustrate(Linklist head) {
Linklist tem = head; // 将头指针的地址赋给临时的指针
while (tem->next != NULL) { // 指向最后一个结点的指针域时会停止
tem = tem->next; // 结点不断向后移动
printf("%d\n", tem->data);
}
}
int main() {
Linklist head = NULL; // 链表的头指针
head = Creat_list(head); // 创建链表
Illustrate(head); // 输出每个结点的数据域
system("pause");
return 0;
}
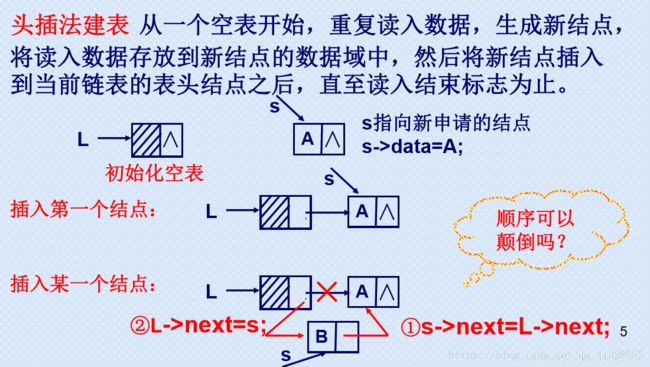
头插法创建单链表
头插法代码:
Linklist Creat_list(Linklist head) {
head = (Linklist)malloc(sizeof(Lnode)); // 为头指针开辟内存空间
Lnode *node = NULL; // 定义新结点
int count = 0; // 创建结点的个数
head->next = NULL;
node = head->next; // 将最后一个结点的指针域永远保持为NULL
printf("Input the node number: ");
scanf("%d", &count);
for (int i = 0; i < count; i++) {
node = (Linklist)malloc(sizeof(Lnode)); // 为新结点开辟内存空间
node->data = i; // 为新结点的数据域赋值
node->next = head->next; // 将头指针所指向的下一个结点的地址,赋给新创建结点的next
head->next = node; // 将新创建的结点的地址赋给头指针的下一个结点
}
return head;
}
头插法创建链表的根本在于深刻理解最后两条语句
node->next = head->next; // 将头指针所指向的下一个结点的地址,赋给新创建结点的next
head->next = node; // 将新创建的结点的地址赋给头指针的下一个结点
创建第一个结点
执行第一次循环时,第一次从堆中开辟一块内存空间给node,此时需要做的是将第一个结点与 head 连接起来。而我们前面已经说过,单链表的最后一个结点指向的是 NULL。
因此插入第一个结点时,我们需要将头指针指向的 next 赋给新创建的结点的 next , 这样第一个插入的结点的 next 指向的就是 NULL。 接着,我们将数据域,也就是 node 的地址赋给 head->next, 这时 head->next 指向的就是新创建的 node的地址。而 node 指向的就是 NULL。
接着我们创建第二个结点
因为使用的头插法,因此新开辟的内存空间需要插入 头指针所指向的下一个地址,也就是新开辟的 node 需要插入 上一个 node 和 head 之间。 第一个结点创建之后,head->next 的地址是 第一个 node 的地址。 而我们申请到新的一块存储区域后,需要将 node->next 指向 上一个结点的首地址, 而新node 的地址则赋给 head->next。 因此也就是 node->next = head->next 。
这样便将第一个结点的地址赋给了新创建地址的 next 所指向的地址。后两个结点就连接起来。
接下来再将头结点的 next 所指向的地址赋为 新创建 node 的地址。 head->next = node ,这样就将头结点与新创建的结点连接了起来。 此时最后一个结点,也就是第一次创建的结点的数据域为0,指针域为 NULL。
创建更多的结点也就不难理解。
执行一次:

会发现,头插法创建链表时候,就相当于后来居上。 后面的结点不断往前插,而最后创建的结点在第一个结点处, 第一个创建的结点变成了尾结点。
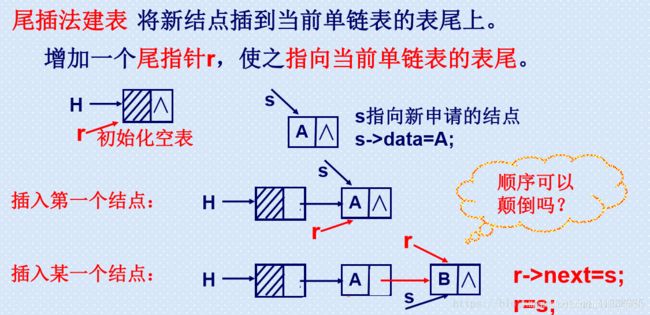
尾插法创建单链表
尾插法代码:
Linklist Creat_list(Linklist head) {
head = (Linklist)malloc(sizeof(Lnode)); // 为头指针开辟内存空间
Linklist node = NULL; // 定义结点
Linklist end = NULL; // 定义尾结点
head->next = NULL; // 初始化头结点指向的下一个地址为 NULL
end = head; // 未创建其余结点之前,只有一个头结点
int count = 0 ; // 结点个数
printf("Input node number: ");
scanf("%d", &count);
for (int i = 0; i < count; i++) {
node = (Linklist)malloc(sizeof(Lnode)); // 为新结点开辟新内存
node->data = i; // 新结点的数据域赋值
end->next = node;
end = node;
}
end->next = NULL;
}
尾插法深刻理解:
end->next = node;
end = node;
尾插法创建第一个结点
刚开始为头结点开辟内存空间,因为此时除过头结点没有新的结点的建立,接着将头结点的指针域 head->next 的地址赋为 NULL。因此此时,整个链表只有一个头结点有效,因此 head此时既是头结点,又是尾结点。因此将头结点的地址赋给尾结点 end 因此:end = head。 此时end 就是 head, head 就是 end。 end->next 也自然指向的是 NULL。
尾插法创建第二个结点
创建完第一个结点之后,我们入手创建第二个结点。 第一个结点,end 和 head 共用一块内存空间。现在从堆中心开辟出一块内存给 node,将 node 的数据域赋值后,此时 end 中存储的地址是 head 的地址。此时,end->next 代表的是头结点的指针域,因此 end->next = node 代表的就是将上一个,也就是新开辟的 node 的地址赋给 head 的下一个结点地址。
此时,end->next 的地址是新创建的 node 的地址,而此时 end 的地址还是 head 的地址。 因此 end = node ,这条作用就是将新建的结点 node 的地址赋给尾结点 end。 此时 end 的地址不再是头结点,而是新建的结点 node。
一句话,相当于不断开创新的结点,然后不断将新的结点的地址当做尾结点。尾结点不断后移,而新创的结点时按照创建的先后顺序而连接的。先来新到。
尾插法创建单链表,结点创建完毕
最后,当结点创建完毕,最后不会有新的结点来替换 end ,因此最后需要加上一条 end->next = NULL。将尾指针的指向为 NULL。
创建更多结点也自然容易理解了一些。
执行一次:
总结
由上面的例子以及比较,我们可以看见:
1、头插法相对简便,但插入的数据与插入的顺序相反;
2、尾插法操作相对复杂,但插入的数据与插入顺序相同。
两种创建的方法各有千秋,根据实际情况选择不同的方法。
关于链表的相关其他操作,请浏览相关文档。
原文地址:https://blog.csdn.net/qq_41028985/article/details/82859199