C++类属(泛型)——模板详解
第八章——类属(泛型)——模板
1.概述
在程序设计中经常会用到这样的一些程序实体:这些程序实体的实现和所完成的基本功能相同,不同的地方仅在于它们所涉及的数据类型不同。对于这些函数或类,如果能分别只用一个函数和一个类来描述它们,将会大大简化程序设计的工作,并能实现代码复用。
在程序设计中,一个程序实体能对多种类型的数据进行操作或描述的特性成为类属性(generics)。能具有类属性的程序实体通常有类属函数和类属类。类属函数是指一个函数能对不同类型的数据(参数)完成相同的操作。类属类是指一个类的成员类型可变,从而可以用它描述不同种类的对象。具有类属性的程序实体可实现一种特殊的多态——参数化多态。基于具有类属性的程序实体进行程序设计的技术称为类属程序设计(或泛型程序设计,generic programming),它为软件复用提供了另一条途径。
在C++中,通常采用模板类来实现类属函数和类属类。
2.模板
模板(template)是一段程序代码,它带有参数类型,在程序中可以通过给这些参数提供一些类型来得到针对不同类型的具体代码。
(1).函数模板
在动态类语言中,由于定义函数时不指定参数的类型,每个函数都能接受多种类型的数据,因此,所有的函数都是类属函数。
而在静态类型语言中,由于函数参数的类型必须要在程序中明确指定,因此,所有函数都是非类属的。
C++是一种静态类型语言,要实现类属函数必须采用其他手段。C++提供了多种实现类属函数的途径,其中包括:宏定义、指针类型参数以及函数模板。由于宏定义虽然能够实现类属函数的效果,但它毕竟不是函数,而是在编译之前的文字替换,因此,这里不把宏定义作为类属函数来考虑。
下面介绍C++中用指针参数和函数模板实现的类属函数。
<1>.用指针参数实现类属函数
【例】用指针参数实现类属的排序函数
分析:一个排序函数要能对任意的数组进行排序,它一般需要知道数组的首地址、数组元素的个数、每个数组元素的尺寸(占内存的字节数)以及如何比较两个数组元素的大小。因此设计如下函数框架:
先定义一个void*类型的形参base,使得它能够接受任意数组的首地址;
然后定义两个unsigned int类型的形参count和element_size,分别用于获得数组元素的个数和每个数组元素的尺寸;最后定义一个函数指针类型的形参cmp,它从调用者处获得一个函数(称为回调函数,callback information),该函数用于比较两个数组元素的大小。框架如下图所示:
void sort(
void *base,//需排序的数据首地址
unsigned int count,//数据个数
unsigned int element_size,//数据尺寸
bool (*less_than)(const void *,const void *)//比较两个数组元素大小的函数指针,由调用者提供
)
不论何种排序算法,一般都需要对数组进行以下操作:
1.取第i个元素(i可以从0到count-1),可以由下面的公式计算第i个元素的首地址
(char *)base+i*element_size
2.比较第i个和第j个元素的大小(i和j可以从0到count-1).可以先计算出第i个和第j个元素的首地址,然后调用cmp指向的函数来比较这两个地址上的元素的大小(第i个元素是否小于第j个元素)。
(*less than)((char*)base+i*element_size,(char*)base+j*element_size)
3.交换第i个和第j个元素。可以先计算出第i个和第j个元素的首地址,然后逐个字节交换这两个地址上的元素。
char* p1 = (char*)base + i * element_size,
* p2 = (char*)base + j * element_size;
for (int k = 0; k < element_size; k++)
{
char temp = p1[k];
p1[k] = p2[k];
p2[k] = temp;
}
下面的程序片段是利用上面定义的排序函数分别对int,double以及A类型的数组进行排序:
bool int_less_than(const void* p1, const void* p2)
{
if (*(int*)p1 < *(int*)p2)
return true;
else
return false;
}
bool double_less_than(const void* p1, const void* p2)
{
if (*(double*)p1 < *(double*)p2)
return true;
else
return false;
}
bool A_less_than(const void* p1, const void* p2)
{
if (*(A*)p1 < *(A*)p2)//类A需要重载操作符“<”
return true;
else
return false;
}
int a[100];
sort(a, 100, sizeof(int), int_compare));//对int类型进行排序
用指针实现类属函数的不足之处在于:除了数组首地址和数组元素个数外,需要定义额外的参数(元素的尺寸和比较函数),并且需要进行大量的指针运算,这不仅使得实现比较麻烦,而且使得程序易读性差和容易出错。
另外,用指针类型实现类属函数也不便于编译程序进行类型检查。
<2>.用函数模板实现类属函数
函数模板(function template)是指带有类型参数的函数定义,其格式如下:
template <class T1,class T2,...>
<返回值类型> <函数名>(<参数表>)
{
...
}
其中,T1和T2等是函数模板的类型参数,使用函数模板定义函数时需要提供相应的具体类型。<返回值类型>、<参数表>中的参数类型以及函数体中局部变量的类型可以是T1、T2等。
【例】用模板类实现类属的排序函数:
#include调试结果如下:
0 1 2 4 5
5.1 5.3 5.6 5.7 5.9
2 3 5 7 8
(2).函数模板的实例化
实际上,函数模板定义了一系列重载的函数。要使用函数模板所定义的函数(称为模板函数),首先必须要对函数模板进行实例化(生成具体的函数,instantiation)。函数模板的实例化通常是隐式的,即编译程序会根据调用时实参的类型自动地将函数模板实例化为具体的函数,这个确定函数模板实例的过程叫做模板实参推演。例如对于上例的排序函数,编译程序会根据调用时的参数类型分别把它实例化成下面的三个具体函数:
void sort(int elements[], unsigned int count){...}
void sort(double elements[], unsigned int count){...}
void sort(A elements[], unsigned int count){...}
有时,编译程序无法根据调用时的实参类型来确定所调用的模板函数,这是需要在程序中显式地实例化函数模板,即在调用模板函数时需要显式地向函数模板提供具体的类型参数。
例如:
template<class T>
T max(T a, T b)
{
return a > b ? : b;
}
int x,y;
double m,n;
max(x,y);//调用模板函数:int max(int a,int b)
max(m,n);//调用模板函数: double max(double a, double b)
max(x,m);//调用什么?
对于上面的函数调用max(x,m),可以采用下面的方式之一来处理:
1).对x或m进行显示类型转换:
max((double)x,m); //或max(x,(int m));
2).显示实例化:
max<double>(x,m); //或max(x,m);
除了类型参数,模板也可以有非类型参数
#include在上面的程序中,函数模板f除了带有类型的参数T外,还带有一个int类型的参数size,并且在调用模板函数f时对函数模板进行了显示实例化;f
有时,为了弥补函数模板所缺乏的一些灵活性,需要把函数模板与函数重载结合起来使用。例如,对于前面的函数模板max和调用max(x,m)时的实例化问题,也可以通过再另外定义一个max的重载函数来解决:
double max(int a, double b)
{
return a>b?a:b;
}
(3).类模板
如果一个类的成员类型可变,则该类称为类属类。在C++中,类属类一般用类模板来实现,**类
template <class T1,class T2,...>
class <类名>
{ <类成员声明>
};
其中,T1、T2等为类模板的类型参数,可以用它们来定义类成员的类型。对于在类的外部定义的成员函数,则应该采用下面的形式:
template<class T1,class T2,...>
<返回值类型> <类名> <T1,T2,...>::<成员函数名> (<参数表>){...}
【例】定义一个可以表示各种类型元素的类属栈类
#include调试结果如下:
1
3.14
2
与函数模板类似,类模板实际定义了若干个类,在使用这些类之前,编译程序将会对类模板进行实例化。值得注意的是:类模板的实例化需要在程序中显式地指出。例如在上例中,采用了下面的显示实例化:
Stack<int>st1;//实例化一个元素类型为int的栈类
Stack<double>st2;//实例化一个元素类型为double的栈类
Stack<A>st3;//实例化一个元素类型为A的栈类
除了类型参数外,类模板也可以包括非类型参数。
【例】定义一个能表示不同大小的栈模板。
只需对上例稍加改变即可。
#include值得注意的是:类模板中的静态成员仅属于实例化后的类(模板类),不同类模板实例之间不共享类模板中的静态成员。
例如:
template<class T>
class A
{
static int x;
T y;
};
template <class T>int A<T>::x = 0;
A<int>a1, a2;//a1和a2共享一个x
A<double>b1, b2;//b1和b2共享另一个x
3.模板的复用
模板是一种基于源代码的复用机制。一个模板代表了一组函数或类,在使用模板时首先要实例化。函数模板的实例化可以是隐式的,也可以是显示的;而类的模板的实例化则是显式进行的。
一个模板可以有很多实例,但是,是否实例化该模板的某个实例要根据使用情况来决定。
在C++中,由于源文件(模板)是分别编译的,如果在一个源文件中定义和实现了一个模板,但在该源文件中未使用到该模板的某个实例,则在相应的目标文件中,编译程序不会生成该模板相应实例的代码。
例如,在下面的代码中,在源文件中file1中要使用在源文件file2中定义和实现的一个模板的某个实例,而在源文件file2中未使用这个实例,则源文件file1无法使用这个实例。
//file1.cpp
#include"file2.h"
int main()
{
S<float>s1;//实例化“S”并创建该类的一个对象s1
s1.f();//调用void S::f()
S<int>s2;//实例化“S”并创建该类的一个对象s2
s2.f();//ERROR,连接程序将指出:“void S::f()”不存在
sub();
return 0;
}
//file2.h
template <class T>
class S
{
T a;
public:
void f();
}
extern void sub();
//file2.cpp
#include"file2.h"
template <class T>
void S<T>::f()
{
......
}
void sub
{
S<float>x;//实例化“S并创建该类的一个对象x”
x.f();//实例化“void S::f()”并调用之
}
在上面的程序中,由于类模板S中f的实现在源文件file2.cpp中,而该源文件中只用到它的一个实例“S::f()”,因此,在file2.cpp的编译结果中只有这个实例,这样源文件file1.cpp中需要使用的实例“S::f()”就不存在,从而导致连接时刻的错误。
解决上述问题的通常做法是把模板的定义和实现都放在某个头文件中,在需要使用模板的源文件中包含该头文件即可。例如:
//file.h
template <class T>//类模板S的定义
class S
{
T a;
public:
void f();
}
template <class T>//类模板S中的f实现
void S<T>::f()
{
......
}
//file1.cpp
#include"file.h"
#include"file2.h"
int main()
{
S<float> s1;//实例化“S”并创建该类的一个对象s1
s1.f();//实例化“void S::f()”并调用之
sub();
return 0;
}
//file2.h
extern void sub();
//file2.h
#include"file.h"
void sub()
{
S<float>x;//实例化“S”并创建该类的一个对象x
x.f();//实例化“void S::f()”并调用之
}
一般来说,要正常使用模板就必须要见到该模板的完整源代码。不过上面的源代码复用存在下面一个问题:如果两个源文件中都有对同一个模板的相同实例的使用,这样,在两个源文件的编译结果中都有相应实例的实现代码,如何消除重复的实例呢?一般可有两种解决方案:
1).由程序开发环境决定。编译程序在编译某个含有模板定义的源文件时,将在开发环境中记下该源文件使用到的所有模板实例,当编译程序编译另一个源文件时,如果发现这个源文件中使用的某个模板实例已经存在了,则不再生成这个模板实例。
2).由连接程序来解决。连接程序在对目标文件进行连接时,把多余的实例舍弃。至于舍弃哪一个实例,则由具体的实现来解释。
4.C++标准模板库
(1).概述
除了从C标准保留下来的一些功能外,C++标准库还提供了很多新的功能,这些功能大都以函数模板和类模板的形式提供,它们构成了C++的标准模板库(standard template library,简称STL)。另外,STL除了是一个标准库外,它还隐含着一种程序设计模式。
STL主要包含了一些容器模板、算法模板以及迭代器模板。
容器用于存储数据,是由同类型的元素所构成的长度可变的序列,如向量、集合、栈以及队列等,它们通过类模板来实现。
算法用于对容器中的元素进行一些常用的操作,如排序、查找等,它们通过函数模板来实现。
迭代器用于访问容器中的元素,它们由具有抽象指针功能的类模板来实现。
为了提高算法与容器之间的相互独立性,在STL中算法的参数不是容器,而是容器中的某个迭代器,在算法中通过迭代器来访问和遍历容器中的元素。迭代器起到了容器和算法之间的桥梁作用,它使得一个算法可以作用于多种容器,从而保证了算法的通用性。
下面通过一个例子来体会一下容器、迭代器和算法以及这三者之间的关系。
【例】利用STL,从键盘输入一系列正整数,计算其中的最大元素、所有元素的和以及对元素进行排序。
#include(2).容器
容器(container)是由长度可变的同类型元素所构成的序列。容器由类模板来实现,模板的参数是容器的元素类型。
下面是一些常用容器:
1. vector<元素类型>
用于需要快速定位(访问)任意位置上的元素以及主要在元素序列的尾部增加/删除元素的场合。在头文件vector中定义,用动态数组实现。
2. list<元素类型>
用于经常在元素序列中任意位置上插入/删除元素的场合。在头文件list中定义,用双向链表实现。
3. deque<元素类型>
用于主要在元素序列的两端增加/删除元素以及需要快速定位(访问)任意位置上的元素的场合。在头文件deque中定义,用分段的连续空间结构实现。
4. stack<元素类型>
用于仅在元素序列的尾部增加/删除元素的场合。在头文件stack中定义,一般基于deque来实现。
5. queue<元素类型>
用于仅在元素序列的尾部增加、头部删除元素的场合。在头文件queue中定义,一般基于deque来实现。
6. priority_queue<元素类型>
它与queue的操作类似,不同之处在于,每次增加元素之后,它将对元素位置进行调整,使得头部的元素总是最大。也就是说,每次删除的总是最大(优先级最高)的元素。在头文件queue中定义,一般基于vector和heap结构来实现。
7. map<关键字类型,值类型>和multimap<关键字类型,值类型>
容器中每个元素由<关键字,值>构成(属于一种pair结构类型,该结构有两个成员:first和second,关键字对应first成员,值对应second成员),元素是根据关键字排序的,用于需要根据关键字来访问元素的场合。对于map,不同元素的关键字不能相同;对于multimap,不同元素的关键字可以相同。它们在头文件map中定义,常常用某种二叉树来实现。
8. set<元素类型>和multiset<元素类型>
它们分别是map和multimap的特例,在set和multiset中,每个元素只有关键字而没有值,或者说,关键字与值合一了。在头文件set中定义。
9. basic_string<字符类型>
与vector类似,不同之处在于其元素为字符类型,并提供了一系列与字符串相关的操作。string和wstring分别是它的两个实例,即basic_string和basic_string
(3).迭代器
迭代器(iterator)实现了抽象的指针(智能指针)功能,它们指向容器中的元素,用于对容器中的元素进行访问和遍历。在STL中,迭代器是作为类模板来实现的,可分为以下几种:
-
输出迭代器(output iterator):只能用于修改它们所指向的容器元素。能通过它进行元素间接访问操作(*),但该操作只能出现在赋值操作的左边(*<输出迭代器>=…)。另外,还可对它进行++操作。
-
输入迭代器(input iterator):只能用于修改它所指向的容器元素。能通过它进行元素的间接访问操作(*),但该操作只能出现在赋值操作的右边(…=*<输入迭代器>)。另外,还可对它进行++操作。
-
前向迭代器(forward iterator):具有输出迭代器和输入迭代器的所有功能。
-
双向迭代器(bidirectional iterator):具有前向迭代器的所有功能。另外,还可以对它进行“–”操作,以及实现双向遍历容器元素的功能。
-
随机访问迭代器(random-access iterator):具有双向迭代器的所有功能,另外,还可以对它进行随机访问元素操作([]),以及对它进行+,-,+=,-=,<,>,<=,>=操作。
上面的几种迭代器之间存在如下图所示的相容关系,其中,箭头的含义是:在需要箭头左边迭代器的地方可以用箭头右边的迭代器去替代。
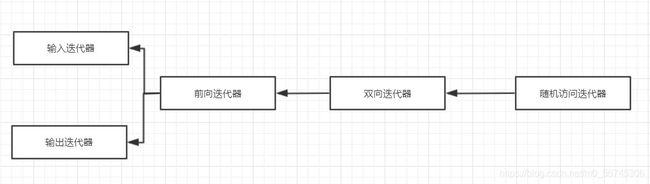
大多数容器类都有相应的迭代器,但对于不同的容器,与它们关联的迭代器会有所不同。对于vector、deque以及basic_string容器类,它们的迭代器是随机访问迭代器。而对于map/multimap以及set/multiset,它们的迭代器则是双向迭代器。需要注意的是,queue、stack、和priority_queue不支持迭代器!
(4).算法
除了容器类模板本身提供的操作外,在STL中还提供了一系列通用算法(algorithm)来操作容器中的元素。在STL中,算法是用函数模板实现的。为了提高算法的通用性以及算法与容器之间的相互独立性,算法的参数不是容器,而是容器的迭代器,在算法中通过迭代器来遍历和访问容器中的元素。
使用算法对容器中的元素进行操作时,一般需要指出要操作的范围(元素)。一个范围由两个迭代器来表示,其中,第一个迭代器指向范围中的第一个元素,第二个迭代器指向范围中最后一个元素的下一个位置。有的算法在一个范围里操作,有的算法需要在两个或两个以上范围里进行操作。当操作需要两个或两个以上范围时,如果没有专门指出,这些范围可以在同一个容器中,也可以在不同的容器中。当两个范围的大小相同时,对第二个范围只要提供一个迭代器(首元素)就可以了。
另外,有些算法还要求使用者提供一个称作“谓词”的函数或对象作为自定义的操作条件,其参数为元素类型,返回值为bool。还有一些算法需要使用者提供一个称作“操作”的函数或函数对象用于参与算法的操作,其参数和返回值类型由相应的算法决定。
STL中的算法有很多,可以分为下面几类:
- 调序算法:实现按某个要求来改变容器中元素次序的操作。
- 编辑算法:实现对容器元素的复制、替换、删除、赋值等操作。
- 查找算法:实现在容器中查找元素或子元素序列等操作。
- 算术算法:实现对容器内的元素进行求和、内积和、差等操作。
- 集合算法:实现集合的基本运算。该类算法要求容器内的元素已排序。
- 堆算法:实现基于堆结构的容器元素操作。具有堆结构的容器的主要特点是第一个元素最大。
- 元素遍历算法for_each:依次访问一个范围内的每个元素,并对每个元素调用某个指定的操作函数对其进行操作。
在STL中,算术算法在头文件numeric中定义,其他算法在头文件algorithm中定义。
【例】算法的操作范围、自定义操作条件和所需的额外操作的使用实例。
解:下面通过一些具体的算法来理解算法的操作范围、自定义操作条件和所需的额外操作的含义。
#include调试结果为:
(push_back) v: 0 1 2 3 4 5 6 7 8 9
(random_shuffle) v: 8 1 9 2 0 5 7 3 4 6
(sort(小->大)) v: 0 1 2 3 4 5 6 7 8 9
(sort(大->小)) v: 9 8 7 6 5 4 3 2 1 0
(replace elements greater than 4 with -1) v: -1 -1 -1 -1 -1 4 3 2 1 0
(sum of all elements in v): 35
(push_back) v1: 0 1 2 3
(push_back) v2: 3 4 5 6 7
(merge v1 and v2) v: 0 1 2 3 3 4 5 6 7 0
(set union of v1 and v2) v: 0 1 2 3 4 5 6 7
(sum of the innner product of elements in v1 and v2): 32