Spark SQL快速入门
1. 了解Spark SQL
1.1 什么是Spark SQL
Spark SQL是spark的一个模块,用于处理海量的结构化数据。
1.2 Spark SQL有什么特点?优点是什么?
特点:
- Spark SQL支持读取和写入多种格式的数据源,包括Parquet、JSON、CSV、JDBC等。
- Spark SQL支持标准的SQL语言,包括SELECT、JOIN、GROUP BY等,还支持用户自定义函数(UDF)和窗口函数(Window Function)等高级功能。
- Spark SQL支持将SQL查询结果转换为DataFrame或RDD,使得可以在Spark的其他API中继续处理数据。
- Spark SQL可以和Spark的其他组件(如Spark Streaming、MLlib等)无缝集成,从而实现实时数据处理和机器学习等应用。
优点:
- Spark SQL提供了一个统一的编程接口,将SQL查询和DataFrame API结合在一起,使得开发人员可以更方便地处理结构化数据。
- Spark SQL采用了Spark的分布式计算框架,可以在大规模集群上运行,处理大量的数据。
- Spark SQL支持延迟计算和数据缓存等优化技术,可以提高计算性能。
- Spark SQL提供了丰富的数据源支持,可以方便地读取和写入各种数据格式的数据。
- Spark SQL支持多种语言的API,包括Scala、Java、Python和R等,使得开发人员可以使用自己熟悉的语言进行开发。
2. Spark SQL概述
2.1 Spark SQL和Hive的区别与联系
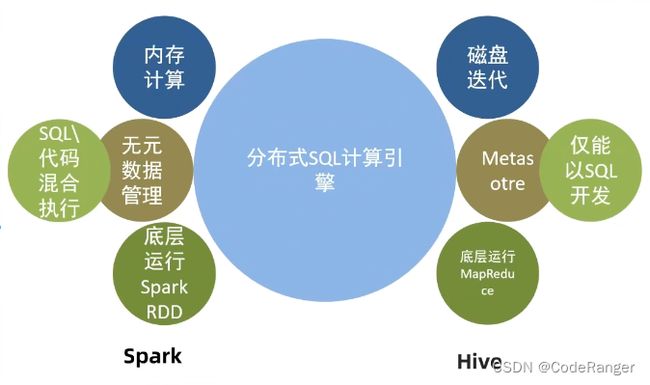
相似之处:
- Spark SQL和Hive都是基于Hadoop生态圈的大数据处理工具,都可以处理PB级别的数据。
- Spark SQL和Hive都支持SQL语言,可以使用SQL查询语言来操作数据。
- Spark SQL和Hive都支持数据存储在HDFS中。
不同之处:
- Spark SQL是基于Spark的内存计算框架,而Hive是基于MapReduce的离线计算框架。因此,在某些情况下,Spark处理数据比Hive更快。
- Spark SQL支持广泛的数据源类型,包括Hive、JSON、Parquet、JDBC等,而Hive只支持Hive数据源类型。
- Spark SQL支持实时计算、流处理、机器学习等高级功能,而Hive只支持批处理。
- Spark SQL可以通过Spark Streaming和Structured Streaming实现实时计算和流处理,而Hive需要使用额外的工具来实现流处理。
2.2 Spark SQL的数据抽象

2.3 DataFrame概述
DataFrame是一种分布式的数据集合,它以表格形式(只能以表格的形式)表示,并且具有带有命名列的概念,类似于传统数据库或电子表格应用程序中的表格。DataFrame可以看作是一个关系型数据库中的一张表,或者是Python或R中的一个数据框架,但是不同的是,DataFrame是在分布式环境下运行的,可以处理大量的数据。
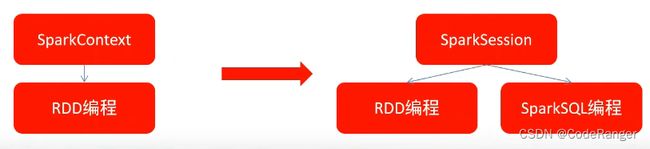
2.4 SparkSession对象
在RDD阶段,程序的执行入口为SparkContext。在spark2.0之后,推出了SparkSession对象,作为spark编码的统一入口对象。
3. DataFrame 详解
3.1 DataFrame 的组成
前面说过DataFrame是一个二维表结构,那么它的结构一定有三部分组成:行、列和表结构描述。
在结构层面:
- StructType对象描述整个DataFrame的表结构
- StructFiled对象描述一个列的信息
在数据层面:
- Row对象记录一行数据
- Column对象记录一列数据并包含列的信息
也就是说,Column是包含单个StructFiled对象的,所有的Column组成全部的StructType对象。
3.2 代码构建
下面用一个例子解释各个api的作用及相关参数的含义
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
import re
if __name__ == '__main__':
# 构建入口对象
spark = SparkSession.builder. \
appName("test"). \
master("local[*]"). \
getOrCreate()
sc = spark.sparkContext
# 基于RDD转换成DataFrame
rdd = sc.textFile("一个数据文件,格式形如:'username, age'"). \
map(lambda x: x.split(",")). \
map(lambda x: (x[0], int(x[1]))) # 将str类型的年龄变为int类型
# 构建DataFrame对象
# 参数1 被转换的RDD
# 参数2 指定列名,通过list的形式指定,按照顺序依次提供字符串名称即可
df = spark.createDataFrame(rdd, schema=['name', 'age'])
# 打印表结构
df.printSchema()
# 打印df中的数据
# 参数1表示展示出多少条数据,默认不传的话是20
# 参数2表示是否对列进行截断,如果列的数据长度超过20个字符串长度,后续的内容不显示以...代皙#如果False表示不阶产全部显示,默认是True
df.show(20, False)
上面的代码是基于RDD转换成DataFrame的构建方法,下面我们用基于StructType的方法构建。
schema = StructType().add("name", StringType(), nullable=True). \
add("age", IntegerType(), nullable=False)3.3 读取外部数据
通过Spark SQL的统一api进行数据读取,并构建DataFrame

format是指支持读取的数据格式,schema就是配置StructType的信息,指定数据的类型和名称
3.4 DataFrame的编程风格
DataFrame的编程风格支持两种:DSL和SQL语法风格。
DSL风格指的是使用Spark SQL提供的DataFrame API进行编程,可以支持更加复杂的数据处理操作。DSL风格的代码通常比SQL语法风格的代码更加直观和易于调试,因为DSL代码中可以使用编程语言的各种特性和工具来处理数据,比如函数、变量、循环等。
代码:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("example").getOrCreate()
# 读取csv数据文件
df = spark.read.format("csv")\
.option("header", True)\
.option("inferSchema", True)\
.load("data.csv")
# 进行数据处理
result = df.filter(df["age"] > 25)\
.groupBy("gender")\
.agg({"salary": "avg"})\
.orderBy("gender")
# 输出结果
result.show()使用SQL语法风格的编程方式,可以直接使用SQL语句对DataFrame进行查询和数据处理。SQL语法风格的代码通常比DSL风格的代码更加简洁和易于理解,因为SQL语句可以直接表达数据处理的逻辑。
代码:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("example").getOrCreate()
# 读取csv数据文件
df = spark.read.format("csv")\
.option("header", True)\
.option("inferSchema", True)\
.load("data.csv")
# 创建临时视图
df.createOrReplaceTempView("people")
# 使用SQL语句进行查询
result = spark.sql("""
SELECT gender, AVG(salary) as avg_salary
FROM people
WHERE age > 25
GROUP BY gender
ORDER BY gender
""")
# 输出结果
result.show()