SpringCloud知识点整理
1.Zuul
基本功能
网关作为整个微服务的入口,主要的作用包括动态路由、监控、限流、降级、鉴权等功能。
降级:也就是当后面微服务超时不响应的时候,可以在网关层进行报错等处理。
监控: 如记录访问日志,方便统一查询。
限流:针对每个微服务,有多种限流方式(具体待研究),使用精心设计的值保证后续微服务不被压垮,同时也不过多浪费机器性能。
鉴权:如IP白名单、黑名单等,用于筛选用户是否有访问权限,如果是内部人员才能访问的可以使用过滤器指定IP地址范围,都拦截就可以了。
zuul原理图
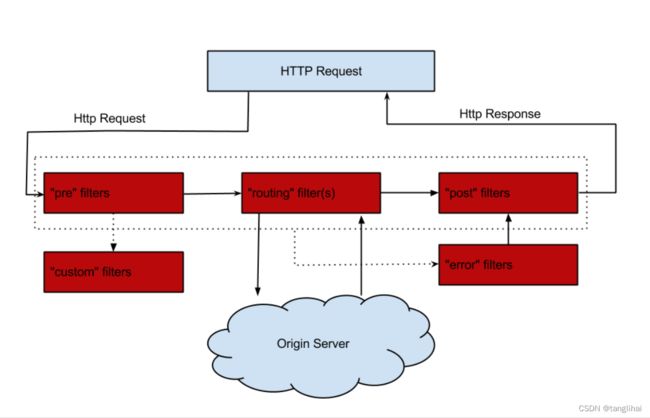
zuul主要就是由过滤器构成,分为pre filters、routing filters、post filters,pre filters在转发请求前调用,post filters在转发请求后调用,routing filters转发请求时调用(可在调用前后进行过滤处理)。如果任意一个阶段报错了,那么会进入error过滤器进行处理。zuul实现了自己的默认error过滤器,使用下面配置可以禁用zuul的默认error处理。
zuul.SendErrorFilter.error.disable=true
示例
路由配置:下面配置表示uri为/myusers/开头的请求,都访问serviceId为users的微服务。
更多配置内容可查看Spring Cloud Netflix
zuul:
routes:
users:
path: /myusers/**
serviceId: users熔断降级:熔断需要实现FallbackProvider接口。
class MyFallbackProvider implements FallbackProvider {
//这里可指定具体路由的熔断降级处理,如填写users,则该类是users相关路径的降级处理
@Override
public String getRoute() {
return "*";
}
@Override
public ClientHttpResponse fallbackResponse(String route, Throwable throwable) {
return new ClientHttpResponse() {
@Override
public HttpStatus getStatusCode() throws IOException {
return HttpStatus.OK;
}
@Override
public int getRawStatusCode() throws IOException {
return 200;
}
@Override
public String getStatusText() throws IOException {
return "OK";
}
@Override
public void close() {
}
@Override
public InputStream getBody() throws IOException {
return new ByteArrayInputStream("fallback".getBytes());
}
@Override
public HttpHeaders getHeaders() {
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
return headers;
}
};
}
}过滤器:过滤器都是通过实现ZuulFilter类完成,记得要加@Component注解才能纳入IOC容器管理。
public class QueryParamPreFilter extends ZuulFilter {
//过滤器的排序,值越小的越先调用
@Override
public int filterOrder() {
return PRE_DECORATION_FILTER_ORDER - 1; // run before PreDecoration
}
//指定过滤器的类型,包括PRE_TYPE、ROUTE_TYPE、POST_TYPE、ERROR_TYPE(error处理)
@Override
public String filterType() {
return FilterConstants.PRE_TYPE;
}
//指定什么情况下需要调用该过滤器,true表示需要调用
@Override
public boolean shouldFilter() {
RequestContext ctx = RequestContext.getCurrentContext();
return !ctx.containsKey(FORWARD_TO_KEY) // a filter has already forwarded
&& !ctx.containsKey(SERVICE_ID_KEY); // a filter has already determined serviceId
}
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
HttpServletRequest request = ctx.getRequest();
if (request.getParameter("sample") != null) {
// put the serviceId in `RequestContext`
ctx.put(SERVICE_ID_KEY, request.getParameter("foo"));
}
return null;
}
}过滤器的调用源码:可以看出preRoute或postRoute阶段报错,那么调用error过滤器之后还会调用postRoute过滤器;而postRoute阶段报错,只会调用error过滤器。
public void service(javax.servlet.ServletRequest servletRequest, javax.servlet.ServletResponse servletResponse) throws ServletException, IOException {
try {
init((HttpServletRequest) servletRequest, (HttpServletResponse) servletResponse);
// Marks this request as having passed through the "Zuul engine", as opposed to servlets
// explicitly bound in web.xml, for which requests will not have the same data attached
RequestContext context = RequestContext.getCurrentContext();
context.setZuulEngineRan();
try {
preRoute();
} catch (ZuulException e) {
error(e);
postRoute();
return;
}
try {
route();
} catch (ZuulException e) {
error(e);
postRoute();
return;
}
try {
postRoute();
} catch (ZuulException e) {
error(e);
return;
}
} catch (Throwable e) {
error(new ZuulException(e, 500, "UNHANDLED_EXCEPTION_" + e.getClass().getName()));
} finally {
RequestContext.getCurrentContext().unset();
}
}
限流:zuul限流放在pre过滤器当中进行处理,使用RateLimiter等工具类进行处理,感兴趣的可自行查阅相关资料学习。
2.springcloud-bus
作用:消息总线的作用是当刷新配置中心配置时,能够通过不重启客户微服务,便能够刷新配置。
原理:修改完配置中心配置后,通过一个刷新配置文件的url让其中一个微服务进行配置文件刷新,同时该微服务会将刷新操作发送到配置完成的消息队列(支持RabbitMQ和kafka)当中,同样名字的微服务会监听同一个topic消息队列,其他微服务通过消费这条消息来实现配置文件的刷新。所以这里是一个微服务的监听机制。
可参考:SpringCloud07_消息总线(Bus)_微凉归期的博客-CSDN博客_springcloud消息总线
3.springcloud-config
微服务既然每个微服务是无状态的,那么同样类型的服务具有同样的配置,为了方便统一管理,于是配置中心被抽取了出来。配置中心分为server端和client端,server端即是config,启动时从git中拉取配置文件信息复制一份到本地,client端(其他的基础微服务)从server拉取配置信息时,如果git不可用,那么会访问server端本地存储的配置文件信息。
如果配置中心和本地配置了相同的配置文件,那么优先级是远程优先,其次本地。
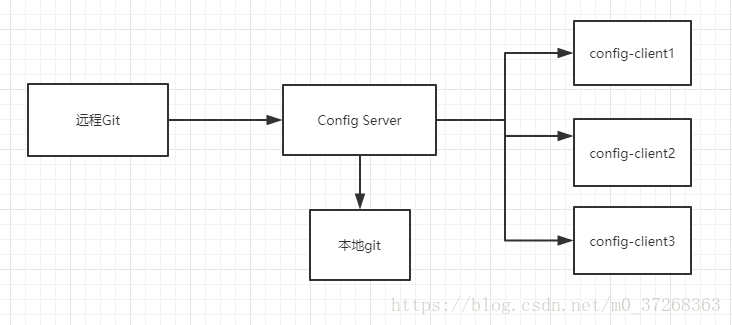
图来源于:SpringCloud Config配置中心原理以及环境切换_向大海走去的博客-CSDN博客_springcloud配置中心原理
4.Eureka
Eureka分成两个部分,eureka-client和eureka-server,client指的是消费者和生产者(通常就是我们的业务微服务),server指的是注册中心。
服务注册:client向server注册,server存储 client的信息,包括IP地址、端口等。
获取注册列表信息: client从server获取到服务提供者列表信息,存储到client当中,每30秒刷新一次该信息。feign调用的时候使用ribbon进行负载均衡。
服务续约:client每隔30秒钟发送一次心跳到server续约,如果90秒server都没有收到client的续约,那么会在注册表中将该实例删除。该值可配置。
服务续约任务的调用间隔时间,默认为30秒
eureka.instance.lease-renewal-interval-in-seconds=30
服务失效的时间,默认为90秒。
eureka.instance.lease-expiration-duration-in-seconds=90
服务下线: client程序关闭的时候会调用一个shutdown方法通知server删除该实例。
自我保护机制:为了防止因网络波动导致服务误删除,eureka提供了自我保护机制。当15分钟内心跳成功比例低于百分之85,那么会进入自我保护机制,自我保护机制情况下不会对注册信息进行删除(因为网络波动情况下删除注册信息,如果网络恢复了,client又没有重启,server中就永远找不到该实例了),同时会接受新的服务进行注册,不过不会同步到集群中的其他server当中。当client心跳恢复时,server会退出自我保护机制。
参考:
Eureka工作原理_代码忘烦恼的博客-CSDN博客_eureka原理
Spring Cloud Eureka 自我保护机制_Monster_起飞的博客-CSDN博客
5.Hystrix
服务熔断包含服务隔离、服务降级、服务熔断三个功能。
服务隔离:是指我们的调用服务使用的Tomcat线程池进行线程管理,如果调用其他微服务的时候继续使用Tomcat的线程,如果其他微服务阻塞势必会导致当前调用服务不可用,所以需要使用新的线程池负责调用其他微服务。每一个微服务使用一个线程池,即便某个微服务发生故障,也只会影响到相关负责的线程池发生阻塞,而不会影响到当前调用微服务以及其他没有发生故障的微服务。
服务降级:如果被调用微服务发生故障抛异常,那么会进入到fallback逻辑里面进行服务降级处理(类似异常处理)。
服务熔断:默认20次请求中,有百分之50的请求失败或超时,那么会打开熔断,之后所有的请求都直接降级。5秒后变成半开状态,每5秒发送一个请求测试下游微服务是否恢复故障,其他的请求依然走降级处理,如果恢复故障了则关闭熔断。
6.Feign
远程调用工具,通过生成代理类的方式对其他微服务或指定的http地址进行调用,使用起来简单便捷,内置了ribbon,通过ribbon进行负载均衡选择合适的微服务,然后feign调用。
Feign原理 (图解)_xjk201的博客-CSDN博客_feign调用原理
7.ribbon
包含七种负载均衡策略。
轮询(RoundRobinRule):依次选择服务提供者进行访问,默认就是该策略。
随机(RandomRule):随机选择一个服务提供者进行访问。
可用性优先(AvailabilityFilteringRule):先过滤掉断路的微服务以及并发数量高的微服务,在剩下的微服务中进行轮询。
响应时间(WeightedResponseTimeRule):根据微服务的响应时间进行排序,响应越快选中几率越高。刚启动时使用轮询,收集到足够信息之后就切换成响应时间模式。
重试(RetryRule):先按照轮询获取服务,如果失败则重试。
最优可用(BestAvailableRule):先过滤掉断路的微服务,然后选择并发量最小的微服务进行访问。
区域内可用(ZoneAvoidanceRule):剔除区域内不可用的server,然后再过滤并发连接过多的server。
也可以自定义负载均衡策略,具体做法可以去查找更多资料。
Ribbon七种负载均衡策略详解_凉拌海蜇丝的博客-CSDN博客_ribbon负载均衡策略有哪几种