1.6python网络爬虫--读取和处理纯文本格式(CSV,PDF,docx)
目录:
- 前言:
- 一,文档编码
- 二,纯文本
-
- 1.对一般简单的纯文本的介绍:
- 2.文本编码介绍和使用
-
- (1)编码类型简介
- (2)使用编码
- 三,CSV
- 四,PDF
- 五, 微软Word和.docx
- 六,拓展:
前言:
互联网并不是:那些符合新式 Web 2.0 潮流,并且经过多媒体内容(这些内容在网络数据采集时几乎要被忽略的)点缀 的 HTML 网站构成的集合。这忽略了互联网最基本的特征:作为不同类型文件的传输媒介。 虽然互联网在 20 世纪 60 年代末期就已经以不同的形式出现,但是 HTML 直到 1992 年才 问世。在此之前,互联网基本上就是收发邮件和传输文件;今天看到的网页的概念那时还没有。总之,互联网并不是一个 HTML 页面的集合,它是一个信息集合,而 HTML 只是展示信息的一个框架。如果我们的爬虫不能读取其他类型的文件,包括纯文本、 PDF、图像、视频、邮件等,我们将会失去很大一部分数据。 本文将重点介绍文档处理的相关内容:包括把文件下载到文件夹里;读取文档并提取数 据;文档的不同编码类型,让程序可以读取非英文的 HTML 页面。
一,文档编码
文档编码是一种告诉程序——无论是计算机操作系统还是用来处理的其他程序(或代码程序)——读取文档的规则。文档编码的方式通常可以根据文件的扩展名进行判断,虽然文件扩展名并不是由编码 确定的,也不是一一对应的关系,而是由开发者确定的。一般地,通过文件拓展名可以用相关程序来打开,如果打开程序的执行方式对应文档编码的话,最终便可成功读取文档。但是,如果文件拓展名更改为不属于该文件类型的拓展名,例如,.txt改为.png格式,可以用另外的程序打开,但会导致实际类型与相关程序执行不对应,导致文档读取失败。这种情况很少见,如果 要正确地读取一个文档,必须要知道它的扩展名。
从最底层的角度看,所有文档都是由 0 和 1 编码而成的。而在高层(贴近用户的层级), 编码算法会定义“每个字符多少位”或“每个像素的颜色值用多少位”(图像文件里)之类的事情,在那里你会遇到一些数据压缩算法或体积缩减算法,比如 PNG 图像编码格式 (一种无损压缩的位图图形格式)。
虽然第一次处理这些非 HTML 格式的文件(纯文本)时会觉得没把握,但是只要安装了合适(简便)的库, Python 就可以帮你处理任意类型的文档。而纯文本文件、视频文件和图像文件的唯一区别, 就是它们的 0 和 1 面向用户的转换方式不同。
二,纯文本
1.对一般简单的纯文本的介绍:
虽然把文件存储为在线的纯文本格式并不常见,但是一些简易网站,或者拥有大量纯文本文件的“旧式学术”网站经常会这么做。例如,互联网工程任务组(例如 https://www.ietf.org/rfc/)网站就存储了 IETF 发表过的所有文档,包含 HTML、PDF 和纯文本格式。
IETF的存储纯文本网站网页:
对于大多数简单的纯文本文件,大多数浏览器都可以很好地显示纯文本文件,采集也会很简单,没有多大问题,可以用下面的方法读取:
from urllib.request import urlopen
html=urlopen("https://www.ietf.org/rfc/bcp-index.txt")
print(html.read())
输出效果:

通常,当用 urlopen 获取了网页之后,我们会把它转变成 BeautifulSoup 对象,方便后面 对 HTML 进行分析。在这段代码中,我们直接读取页面内容。因为这个页面不是 HTML(而是纯文本),所以 BeautifulSoup 库就没用了。一旦纯文本文件被读成字符串,只能用普通 Python 字符串 的方法分析它了。这么做有个缺点,就是不能对字符串使用 HTML 标签,去定位 那些真正需要的文字,避开那些不需要的文字。这样从纯文本文件中抽取某 些信息,还是有些难度的。
2.文本编码介绍和使用
如果你想正确地读取一个文件,知道它的扩展名就可以了。但这条规则不能应用到最基本的文档格式:.txt 文件。 大多数时候用前面的方法读取纯文本文件都没问题。但是,互联网上的文本文件
(数据)会比较复杂。下面介绍一些英文和非英文编码的基础知识,包括 ASCII、Unicode 和 ISO 编码,以及对应的处理方法。
(1)编码类型简介
20 世纪 90 年代初,一个叫 Unicode 联盟(The Unicode Consortium)的非营利组织尝 试将地球上所有用于书写的符号进行统一编码。其目标包括拉丁字母、斯拉夫字母 (кириллица)、中国象形文字(象形)、数学和逻辑符号( , ≥),甚至表情和 “杂项”(miscellaneous)符号,如生化危机标记( )和和平符号( )等。
编码的结果就是 UTF-8,全称是“Universal Character Set - Transformation Format 8 bit”,即“统一字符集 - 转换格式 8 位”。一个常见的误解是 UTF-8 把所有字符都存储成 8 位。其实“8 位”只是显示一个字符需要的最小位数,而不是最大位数。(如果 UTF-8 的 每个字符都是 8 位,那一共也只能存储 28 个,即 256 个字符。这对中文字符和其他符号来 说显然不够。)
真实情况是,UTF-8 的每个字符开头有一个标记表示“这个字符只用一个字节”或“那个 字符需要用两个字节”,一个字符最多可以是四个字节。由于这四个字节里还包含一部分 设置信息,用来决定多少字节用做字符编码,所以全部的 32 位(32 位 =4 字节 ×8 位 / 字 节)并不会都用,其实最多使用 21 位,也就是总共 2 097 152 种可能里面可以有 1 114 112 个字符。
虽然对很多程序来说,Unicode 都是上帝的礼物(godsend),但是有些习惯很难改变, ASCII 依然是许多英文用户的不二选择。
ASCII 是 20 世纪 60 年代开始使用的文字编码标准,每个字符 7 位,一共 27 ,即 128 个字 符。这对于拉丁字母(包括大小写)、标点符号和英文键盘上的所有符号,都是够用的。
在 20 世纪 60 年代,存储的文件用 7 位编码和用 8 位编码之间的差异是巨大的,因为内存 非常昂贵。当时,计算机科学家们为了是需要增加一位来获得一个漂亮的二进制数(用 8 位),还是让文件用更少的位数(用 7 位)费尽心机。最终,7 位编码胜利了。但是,在新式的计算方式中,每个 7 位码的前面都补充(pad)了一个“0”1 ,留给我们两个最坏的结果 是,文件大了 14%(编码由 7 位变成 8 位,体积增加了 14%),并且由于只有 128 个字符, 缺乏灵活性。
在 UTF-8 设计过程中,设计师决定利用 ASCII 文档里的“填充位”,让所有以“0”开头的 字节表示这个字符只用 1 个字节,从而把 ASCII 和 UTF-8 编码完美地结合在一起。因此, 下面的字符在 ASCII 和 UTF-8 两种编码方式中都是有效的:
01000001 - A
01000010 - B
01000011 - C
而下面的字符只在 UTF-8 编码里有效,如果文档用 ASCII 编码,那么就会被看成是“无法 打印”:
11000011 10000000 - À
11000011 10011111 - ß
11000011 10100111 - ç
除了 UTF-8,还有其他 UTF 标准,像 UTF-16、UTF-24、UTF-32,不过很少用这些编码标 准对文件进行编码,只在一些特定介绍范围的环境里使用。
显然,Unicode 标准也有问题,就是任何一种非英文语言文档的体积都比 ASCII 编码的体 积大。虽然你的语言可能只需要用大约 100 个字符,像英文的 ASCII 编码,8 位就够了, 但是因为是用 UTF-8 编码,所以你还是得用至少 16 位表示每个字符。这会让非英文的纯 文本文档体积差不多达到英文文档的两倍,对那些不用拉丁字符集的语言来说都是如此。
ISO 标准解决这个问题的办法是为每种语言创建一种编码。和 Unicode 不同,它使用了与 ASCII 相同的编码,但是在每个字符的开头用 0 作“填充位”,这样就可以让语言在需要 的时候创建特殊字符。这种做法对欧洲那些依赖拉丁文字母的语言(编码还是按照 0-127 一一对应)非常合适,只不过需要增加一些特殊字符。这使得 ISO-8859-1(为拉丁文字母 设计的)标准里有了分数符号(如 ½)和版权标记符号(©)。
还有一些 ISO 字符集,像 ISO-8859-9(土耳其语)、ISO-8859-2(德语等语言)、ISO-8859- 15(法语等语言)也是用类似的规律做出来的。
虽然这些年 ISO 编码标准的使用率一直在下降,但是目前仍有约 9% 的网站使用 ISO 编 码 2 ,所以有必要做基本的了解,并在采集网站之前需要检查是否使用了这种编码方法。
(2)使用编码
在前面的代码中,我们用默认设置的 urlopen 读取了网上的 .txt 文档。这么做对英文文档没有 任何问题。但如果你遇到的是俄语、阿拉伯语文档,或者文档里有一个像“résumé” 这样的单词,就可能出问题。 看看下面的代码:
from urllib.request import urlopen
html= urlopen( "http://www.pythonscraping.com/pages/warandpeace/chapter1-ru.txt")
print(html.read())
这段代码会把《战争与和平》原著(托尔斯泰用俄语和法语写的)的第 1 章打印到屏幕 上。打印结果一开头是这样:

放在大多数浏览器上也是乱码的:
就算让懂俄语的人来看,这些乱码也难以辨认。这个问题是因为 Python 默认把文本读成 ASCII 编码格式,而浏览器把文本读成 ISO-8859-1 编码格式。其实都不对,应该用 UTF-8 编码格式。
我们可以把字符串显示转换成 UTF-8 格式,这样就可以正确显示斯拉夫文字了:
from urllib.request import urlopen
html = urlopen( "http://www.pythonscraping.com/pages/warandpeace/chapter1-ru.txt")
print(str(html.read(), 'utf-8'))
输出效果:

你可能打算以后用网络爬虫的时候全部采用 UTF-8 编码读取内容,毕竟 UTF-8 也可以完美地处理 ASCII 编码。但是,要记住还有 9% 的网站使用 ISO 编码格式。所以在处理纯文 本文档时,想用一种编码搞定所有的文档依旧不可能。有一些库可以检查文档的编码,或 是对文档编码进行估计(用一些逻辑判断“раÑÑказє不是单词),不过效果并 不是很好。
处理 HTML 页面的时候,网站其实会在 部分显示页面使用的编码格式。大多数网站,尤其是英文网站,都会带这样的标签:
<meta charset='utf-8'>
中文网站的标签多数是这样的(也有不少utf-8的):
<meta charset="GB2312">
如果你要做很多网络数据采集工作,尤其是面对国际网站时,建议你先看看 meta 标签的内 容,用网站推荐的编码方式读取页面内容。
三,CSV
进行网页采集的时候,你可能会遇到 CSV 文件,也可能希望将数据保存为 CSV 格式。Python 有一个超赞的标准库(https://docs.python.org/3.4/library/csv.html)可以读写 CSV 文件。虽然这个库可以处理各种 CSV 文件,但是这里我重点介绍标准 CSV 格式。如 果你在处理 CSV 时有特殊需求,请查看文档。
Python 的 csv 库主要是面向本地文件,就是说你的 CSV 文件得存储在你的电脑上。而进 行网络数据采集的时候,很多文件都是在线的。不过有一些方法可以解决这个问题:
• 手动把 CSV 文件下载到本机,然后用 Python 定位文件位置;
• 写 Python 程序下载文件,读取之后再把源文件删除;
• 从网上直接把文件读成一个字符串,然后转换成一个 StringIO 对象,使它具有文件的 属性。
虽然前两个方法也可以用,但是既然可以轻易地把 CSV 文件保存在内存里,就不要 再下载到本地占硬盘空间了。直接把文件读成字符串,然后封装成 StringIO 对象,让 Python 把它当作文件来处理,就不需要先保存成文件了。下面的程序就是从网上获取一个 CSV 文件(这里用的是 http://pythonscraping.com/files/MontyPythonAlbums.csv 里的 Monty Python 乐团的专辑列表),然后把每一行都打印到运行窗口里:
from urllib.request import urlopen
from io import StringIO
import csv
page=urlopen("http://pythonscraping.com/files/MontyPythonAlbums.csv").read().decode('ascii', 'ignore')#将网页文件获取后转换成字符串,并设置编码以及错误警告处理;
dataFile=StringIO(page)#创建StringIO对象,使得可以当成文件处理,可不用保存先;
csvdatas=csv.reader(dataFile)
for row in csvdatas:
print(row)
显示结果很长,开始部分是这样:
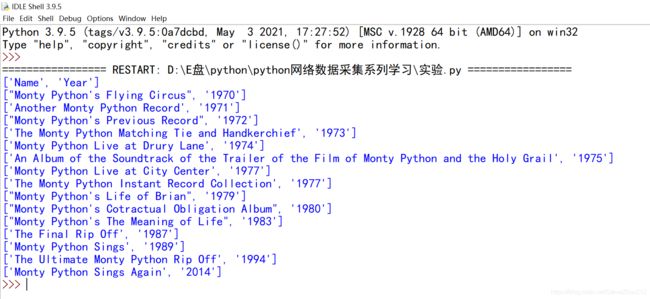
从代码中你会发现 csv.reader 返回的 csvReader 对象是可迭代的(类似行结构的数据),而且由 Python 的列表对象构成。因此,csvReader 对象可以用下面的方式接入:
from urllib.request import urlopen
from io import StringIO
import csv
page=urlopen("http://pythonscraping.com/files/MontyPythonAlbums.csv").read().decode('ascii', 'ignore')#将网页文件获取后转换成字符串,并设置编码以及错误警告处理;
dataFile=StringIO(page)#创建StringIO对象,使得可以当成文件处理,可不用保存先;
csvdatas=csv.reader(dataFile)
for row in csvdatas:#csvdatas是可迭代的,由列表对象构成;
print("The album \""+row[0]+"\" was released in "+str(row[1]))
输出结果是:

注意看第一行的内容,The album “Name” was released in Year,其中的name, year标题行也被当做主要信息打印出来了。虽然写示例代码的时候, 这行内容是否显示都无所谓,但是工作中肯定不希望将这行信息保留在数据里。有些程序员可能会简单地跳过 csvReader 对象的第一行,或者写一个简单的条件把第一行处理掉。 不过,还有一个函数可以很好地处理这个问题,那就是 csv.DictReader:
csv.DictReader 会返回把 CSV 文件每一行转换成 Python 的字典对象返回,而不是列表对 象,并把字段列表保存在变量 dictReader.fieldnames 里,字段(标题行)列表同时作为字典对象的键:
from urllib.request import urlopen
from io import StringIO
import csv
page=urlopen("http://pythonscraping.com/files/MontyPythonAlbums.csv").read().decode('ascii', 'ignore')#将网页文件获取后转换成字符串,并设置编码以及错误警告处理;
dataFile=StringIO(page)#创建StringIO对象,使得可以当成文件处理,可不用保存先;
csvdatas=csv.DictReader(dataFile)
print(csvdatas.fieldnames)
for row in csvdatas:#csvdatas是可迭代的,由除字段名(标题行)的每行对象构成;
print(row)
输出效果:
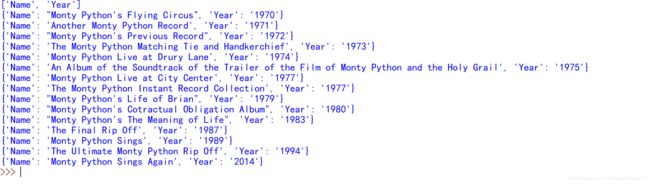
虽然用 DictReaders 创建、处理和打印 CSV 信息,比 csvReaders 要多写一点儿代码,但是 考虑到它的便利性和实用性,多写那点儿代码还是值得的。
一种方式如下:
from urllib.request import urlopen
from io import StringIO
import csv
page=urlopen("http://pythonscraping.com/files/MontyPythonAlbums.csv").read().decode('ascii', 'ignore')#将网页文件获取后转换成字符串,并设置编码以及错误警告处理;
dataFile=StringIO(page)#创建StringIO对象,使得可以当成文件处理,可不用保存先;
csvdatas=csv.DictReader(dataFile)
for row in csvdatas:#csvdatas是可迭代的,由除字段名(标题行)的每行对象构成;
print("".join(["The album ",row['Name']," was released in ",row['Year'],"."]))
输出效果:

四,PDF
一些特定的媒体文件只能在特定的系统环境下运行,或者这类文件需要额外的工具进行转换才能被使用,这造成使用的局限性和不必要的麻烦。某种意义上说,Adobe 在 1993 年发明 PDF 格式(Portable Document Format,便携式文档格式)是一种技术革命。 PDF 可以让用户在不同的系统上用同样的方式查看图片和文本文档,无论这些文件是在哪 种系统上制作的。
虽然把 PDF 显示在网页上已经有点儿过时了(采用HTML ,为什 么还要用这种静态、加载速度超慢的格式呢?),但是 PDF 仍然无处不在,尤其是在处理 商务报表和表单的时候。
不过目前很多 PDF 解析库都是用 Python 2.x 版本建立的,还没有迁移到 Python 3.x 版本。 但是,因为 PDF 比较简单,而且是开源的文档格式,所以有一些给力的 Python 库可以读 取 PDF 文件,而且支持 Python 3.x 版本。
PDFMiner3K 就是一个非常好用的库(是 PDFMiner 的 Python 3.x 移植版)。它非常灵活, 可以通过命令行使用,也可以整合到代码中。它还可以处理不同的语言编码,而且对网络 文件的处理也非常方便。
在命令行中输入pip指令,即可安装:
pip install PDFMiner3K
下面的例子可以把任意 PDF 读成字符串,然后用 StringIO 转换成文件对象:
from urllib.request import urlopen
from pdfminer.pdfinterp import PDFResourceManager, process_pdf
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from io import StringIO
from io import open
def readPDF(page):
rsrcmgr = PDFResourceManager()# 创建PDF资源管理器 来管理共享资源。
retstr = StringIO()#变成StringIO对象,可以以文件处理
laparams = LAParams()#创建一个PDF参数分析器
device = TextConverter(rsrcmgr, retstr, laparams=laparams)
process_pdf(rsrcmgr, device, page)
device.close()
contents = retstr.getvalue()
retstr.close()
return contents
page=urlopen("http://pythonscraping.com/pages/warandpeace/chapter1.pdf")
contents=readPDF(page)
print(contents)
page.close()
输出效果:

readPDF 函数最大的好处是,如果你的 PDF 文件在电脑里,你就可以直接把 urlopen 返回 的对象 pdfFile 替换成普通的 open() 文件对象,即把urlopen语句改为以下语句,即可对本地PDF打印阅读:
pdfFile = open("../pages/warandpeace/chapter1.pdf", 'rb')
输出结果可能不是很完美,尤其是当 PDF 里有图片、各种各样的文本格式,或者带有表格 和数据图的时候。但是,对大多数只包含纯文本内容的 PDF 而言,其输出结果与纯文本格 式基本没什么区别。
五, 微软Word和.docx
Word 的特异功 能就是把那些应该写成简单的 TXT 或 PDF 格式的文件,变成了既大又慢且难以打开的怪 兽,它们经常在系统切换和版本切换中出现格式不兼容,而且因为某些原因在文件内容已 经定稿后仍处于可编辑的状态。Word 文件从未打算让人频繁传递。不过它们在一些网站 上很流行,包括重要的文档、信息,甚至图表和多媒体;总之,那些内容都应该用 HTML代替。
大约在 2008 年以前,微软 Office 产品中 Word 用 .doc 文件格式。这种二进制格式很难读 取,而且能够读取 word 格式的软件很少。为了跟上时代,让自己的软件能够符合主流软 件的标准,微软决定使用 Open Office 的类 XML 格式标准,此后新版 Word 文件才与其他 文字处理软件兼容,这个格式就是 .docx。
不过,Python 对这种 Google Docs、Open Office 和 Microsoft Office 都在使用的 .docx 格 式 的 支 持 还 不 够 好。 虽 然 有 一 个 python-docx 库(http://python-docx.readthedocs.org/en/ latest/),但是只支持创建新文档和读取一些基本的文件数据,如文件大小和文件标题,不 支持正文读取。如果想读取 Microsoft Office 文件的正文内容,我们需要自己动手找方法。
第一步是从文件读取 XML:
from zipfile import ZipFile
from urllib.request import urlopen
from io import BytesIO
wordFile = urlopen("http://pythonscraping.com/pages/AWordDocument.docx").read()
wordFile = BytesIO(wordFile)
document = ZipFile(wordFile)
xml_content = document.read('word/document.xml')
print(xml_content.decode('utf-8'))
输出效果:

这段代码把一个远程 Word 文档读成一个二进制文件对象(BytesIO 与本章之前用的 StringIO 类似),再用 Python 的标准库 zipfile 解压(所有的 .docx 文件为了节省空间都 进行过压缩),然后读取这个解压文件,就变成 XML 了。
这个 Word 文档在 http://pythonscraping.com/pages/AWordDocument.docx,内容如图 6-2 所示。
上面这段 Python 程序读取这个简单的 Word 文档后,输出的结果是那样的。
确实包含了大量信息,但是被隐藏在 XML 里面。好在文档的所有正文内容都包含在 标签里面,标题内容也是如此,这样就容易处理了。
from zipfile import ZipFile
from urllib.request import urlopen
from io import BytesIO
from bs4 import BeautifulSoup
wordFile = urlopen("http://pythonscraping.com/pages/AWordDocument.docx").read()
wordFile = BytesIO(wordFile)
document = ZipFile(wordFile)
xml_content = document.read('word/document.xml')
wordObj = BeautifulSoup(xml_content.decode('utf-8'))
textStrings = wordObj.findAll("w:t")
for textElem in textStrings:
print(textElem.text)
这段代码的结果并不完美,但是已经差不多了,一行打印一个 标签,可以看到 Word 是如何对文字进行断行处理的:

你会看到这里“docx”是单独一行,这是因为在原始的 XML 里,它是由 标签包围的。这是 Word 用红色波浪线高亮显示“docx”的方式, 提示这个词可能有拼写错误。
文档的标题是由样式定义标签 处理的。虽然不能非常简单地定 位标题(或其他带样式的文本),但是用 BeautifulSoup 的导航功能还是可以帮助我们解决 问题的:
from zipfile import ZipFile
from urllib.request import urlopen
from io import BytesIO
from bs4 import BeautifulSoup
wordFile = urlopen("http://pythonscraping.com/pages/AWordDocument.docx").read()
wordFile = BytesIO(wordFile)
document = ZipFile(wordFile)
xml_content = document.read('word/document.xml')
wordObj = BeautifulSoup(xml_content.decode('utf-8'))
textStrings = wordObj.findAll("w:t")
for textElem in textStrings:
closeTag = ""
try:
style = textElem.parent.previousSibling.find("w:pstyle")
if style is not None and style["w:val"] == "Title":
print(""
)
closeTag = ""
except AttributeError:
# 不打印标签
pass
print(textElem.text)
print(closeTag)
输出效果:

这段代码很容易进行扩展,打印不同文本样式的标签,或者把它们标记成其他形式。
六,拓展:
python 的StringIO
最后,文中如有不足,敬请批评指正!!!