day82 Flink 安装 Source 算子
文章目录
- 一、Flink
-
- 1、Flink 和 Spark 区别
- 二、Flink
-
- 1、Source
-
- 1 本地集合、本地文件、套接字
- 2 自定义数据源(连接数据库)
- 2、一些算子
-
- 1 map
- 2 keyby
- 3 reduce
- 4 agg
- 5 window
- 6 sideout
- 有的没的
I know, i know
地球另一端有你陪我
一、Flink
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
可以对标 Spark,一个擅于流处理,一个擅于批处理
1、Flink 和 Spark 区别
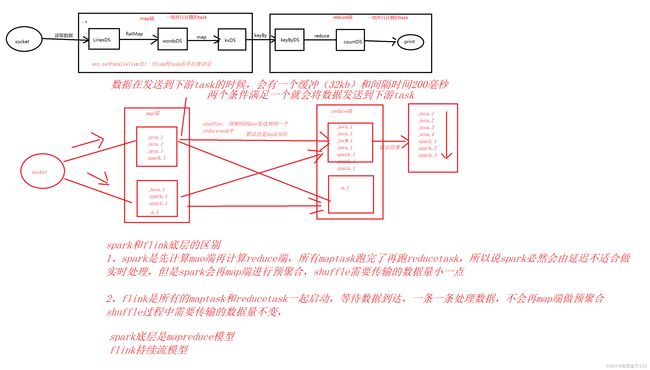
应用上:
Flink 多用于处理流数据;Spark 多用于处理批数据
底层上:
Flink 底层是持续流模型,有类似的 Map 端(上游)和 Reduce 端(下游),
每次运行会同时启动上、下游的任务,保证数据的实时处理,数据一条一条处理,不会在 map 端做预聚合,shuffle 过程的数据传输量不变;
Spark 底层是 MapReduce 模型,会先进行 Map 端的计算,再开启 Reduce 计算,
因此 Spark 在处理实时数据时必然会产生延迟,只能实现微批处理。
二、Flink
1、Source
读取数据的途径
1 本地集合、本地文件、套接字
package source
import org.apache.flink.streaming.api.scala._
object Demo1Source {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment
= StreamExecutionEnvironment.getExecutionEnvironment
/**
* 处理本地集合,有界流
*/
val listDS: DataStream[Int]
= env.fromCollection(List(1, 2, 3, 4, 5))
// listDS.print()
/**
* 处理本地文件,有界流
*/
val studentsDS: DataStream[String]
= env.readTextFile("Flink/data/students.txt")
// 统计班级人数
// 不同于spark,每一次加算都会显示结果
studentsDS
.map(_.split(",")(4))
.map((_, 1))
.keyBy(_._1)
.reduce((x, y) => (x._1, x._2 + y._2))
.print()
env.execute()
/**
* 处理套接字,无界限流
*/
val socketDS: DataStream[String]
= env.socketTextStream("master",8888)
socketDS.print()
env.execute()
}
}
2 自定义数据源(连接数据库)
Flink 支持自定义数据源,需要继承相关类 SourceFunction
其下又包含
package source
import java.sql.{Connection, DriverManager, ResultSet}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.source.{RichSourceFunction, SourceFunction}
import org.apache.flink.streaming.api.scala._
object Demo3ReadMysql {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment
= StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(2)
val sqlDS: DataStream[(String, String)]
= env.addSource(new MysqlSource)
sqlDS.print()
env.execute()
}
}
/**
*
* SourceFunction: 单并行度的source< run方法只执行一次
* RichSourceFunction: 多了open和close方法
* ParallelSourceFunction: 并行的source,每个并行度中run方法都会执行一次
* RichParallelSourceFunction: 多了open和close方法
*
*/
class MysqlSource extends RichSourceFunction[(String, String)] {
/**
* open方法在run 方法之前执行,一般用于初始化
*/
var conn: Connection = _
override def open(parameters: Configuration): Unit = {
println("创建jdbc链接")
// 1、加载驱动
// import java.sql.Connection
Class.forName("com.mysql.jdbc.Driver")
// 2、创建链接
conn = DriverManager.getConnection(
"jdbc:mysql://master:3306/tour", "root", "123456")
}
override def close(): Unit = {
conn.close()
}
override def run(
ctx: SourceFunction.SourceContext[(String, String)]): Unit = {
// 3、查询数据
val ps = conn.prepareStatement(
"select city_id,city_name from admin_code")
// 4、执行查询
val rs: ResultSet = ps.executeQuery()
// 5、解析数据
while(rs.next()){
val cityId: String = rs.getString("city_id")
val cityName: String = rs.getString("city_name")
// 发送到下游
ctx.collect((cityId,cityName))
}
}
override def cancel(): Unit = {
}
}
2、一些算子
和 scala 使用起来是手感是相似的,一点点区别是,算子除了可以传入函数之外,
还可以传入一个继承特定主类的自定义类对象。
实际上,传入函数的底层就是引用这些自定义类对象。Flink 底层是由 Java 编写的,
在后期的更新中引入了这种传入函数的使用方式
1 map
package transformation
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.streaming.api.scala._
object Demo1Map {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment
= StreamExecutionEnvironment.getExecutionEnvironment
val studentsDS: DataStream[String]
= env.readTextFile("Flink/data/students.txt")
/**
* map算子 --- 面向函数编程
*/
// scala
val scalaDS: DataStream[String] = studentsDS.map(line => {
//flink 就算最后没有sink 前面的代码也会执行
println("====map====")
val clazz = line.split(",")(4)
clazz
})
scalaDS.print()
// java 实现MapFunction 接口,实现map方法 -- 面向接口编程
val javaDS: DataStream[String]
= studentsDS.map(new MapFunction[String,String] {
override def map(t: String): String = {
t.split(",")(4)
}
})
javaDS.print()
env.execute()
}
}
2 keyby
Flink 中没有 reducebykey 这样一步到位的算子,而是需要两个算子来完成分组聚合
此为第一个,能够将 key 相同是元素进行分组
package transformation
import org.apache.flink.api.java.functions.KeySelector
import org.apache.flink.streaming.api.scala._
object Demo4KeyBy {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment
= StreamExecutionEnvironment.getExecutionEnvironment
val linesDS: DataStream[String]
= env.socketTextStream("master", 8888)
val wordDS = linesDS.map((_, 1))
/**
* keyBy: 将相同的key 发送到同一个task中,
* key之后可以进行聚合计算,针对每一个key
*/
// scala
val scalaDS = wordDS.keyBy(_._1)
// java
val javaDS = wordDS.keyBy(new KeySelector[(String, Int),String] {
override def getKey(in: (String, Int)): String = {
in._1
}
})
javaDS.print()
env.execute()
}
}
3 reduce
分组后,可以使用 reduce 算子对数据进行聚合
Flink 无法像 Spark 中能够对数据进行预聚合,每处理一条数据都会输出一次结果
package transformation
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.streaming.api.scala._
object Demo5Reduce {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment
= StreamExecutionEnvironment.getExecutionEnvironment
val linesDS = env.socketTextStream("master", 8888)
val wordDS = linesDS
.map((_, 1))
.keyBy(_._1)
/**
*
* reduce 对同一个key的数据进行聚合计算
* flink 中的聚合没有预计算,每一条数据都会输出一个结果
*/
// scala
val scalaDS: DataStream[(String, Int)]
// 也无法想 Spark 中那样简写 _+_
= wordDS.reduce((x, y) => (x._1, x._2 + y._2))
// java
val javaDS = wordDS.reduce(new ReduceFunction[(String, Int)] {
override def reduce(
t: (String, Int), t1: (String, Int)): (String, Int) = {
(t._1, t._2 + t1._2)
}
})
javaDS.print()
env.execute()
}
}
4 agg
package transformation
import org.apache.flink.streaming.api.scala._
object Demo6Agg {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment
= StreamExecutionEnvironment.getExecutionEnvironment
val studentsDS = env.readTextFile("Flink/data/students.txt")
/**
* 聚合函数
* sum
* max
* min
* maxBy
* minBy
*/
/**
* 统计班级人数
*/
val sumNum = studentsDS
.map(line => {
(line.split(",")(4), 1)
})
.keyBy(_._1)
.sum(1)
// sumNum.print()
/**
* 获取每个班级最大的年龄
* max 和 maxBy 之间的区别在于 max 返回流中的最大值,
* 但 maxBy 返回具有最大值的完整键, min 和 minBy 同理。
* 即,max 出来的只有部分数据有效,maxby是一整条有效数据
*/
val stuDS = studentsDS
.map(line => {
val split = line.split(",")
Student(
split(0), split(1), split(2).toInt, split(3), split(4))
})
val maxAge = stuDS
.keyBy(_.clazz)
.maxBy("age")
maxAge.print()
env.execute()
}
}
case class Student(
id: String, name: String, age: Int, gender: String, clazz: String)
5 window
窗口函数,当窗口中有数据就会输出,没有则不会输出
分为滑动窗口(窗口间有交集)和滚动窗口(窗口间无交集)
package transformation
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object Demo7Window {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment
= StreamExecutionEnvironment.getExecutionEnvironment
val linesDS = env.socketTextStream("master", 8888)
val wordDS = linesDS
.map((_, 1))
.keyBy(_._1)
/**
* 每一个5秒统计单词的数量,统计该5秒内的
* 滚动窗口(两个窗口没有交接)
*/
val windowDS = wordDS
.timeWindow(Time.seconds(5))
/**
* 每一个5秒统计单的数量,统计最近15的数据
* 滑动窗口,有交叉
*/
wordDS
.timeWindow(Time.seconds(15),Time.seconds(5))
//在窗口内进行聚合计算
val reduceDS: DataStream[(String, Int)] = windowDS
.reduce((x, y) => (x._1, x._2 + y._2))
reduceDS.print()
env.execute()
}
}
6 sideout
旁路输出,会将数据源中的数据按照需要进行分流,
因为一次可以分出多个流,可以避免数据的重复读取
package transformation
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object Demo9SideOutPut {
// 旁路输出
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment
= StreamExecutionEnvironment.getExecutionEnvironment
val studentsDS = env.readTextFile("Flink/data/students.txt")
// spark
val maleDS: DataStream[String]
= studentsDS.filter(_.split(",")(3) == "男")
val femaleDS: DataStream[String]
= studentsDS.filter(_.split(",")(3) == "女")
// 用 SideOutPut 需要预设标签,用于分类
val male: OutputTag[String] = OutputTag[String]("男")
val female: OutputTag[String] = OutputTag[String]("女")
val processDS: DataStream[String]
= studentsDS.process(new ProcessFunction[String, String] {
override def processElement(i: String // 数据
, context: ProcessFunction[String, String]#Context
// 承接上下文
, collector: Collector[String]): Unit = {
val gender = i.split(",")(3)
if ("男".equals(gender)) {
context.output(male, i)
} else {
context.output(female, i)
}
}
})
processDS
//通过标记获取流
val maleData: DataStream[String]
= processDS.getSideOutput(male)
val femaleData: DataStream[String]
= processDS.getSideOutput(female)
femaleData.print()
env.execute()
}
}
有的没的
1、Flink 中,使用到 map 等转换算子时,需要用到隐式转换,否则会报错
而同过书写代码自动添加的类是不包含隐式转换的,因此需要额外手动添加
推荐直接写 _ ,将所有的类全部 import
import org.apache.flink.streaming.api.scala._
2、Flink 的报错提示不会显示在第一个 Exception 上,而是会在下面,需要翻
3、默认 Flink 会使用本地的全部资源(核),运行结果前面的数字
即为处理该条数据的核编号
4、C:\Windows\System32\drivers\etc\hosts
设置本地 ip 地址绑定位置
5、Mysql 中没有 insert overwrite table() values() 这样的语法