Shell脚本-定时任务学习笔记
文章目录
-
-
- Shell介绍
- 第一个shell脚本程序:
- Shell脚本的执行
- shell脚本在执行时,向脚本传递参数
- 定时任务,定时执行shell脚本
- 获取系统时间并且序列化成想要的格式
- 变量:
-
- 定义变量:
- **使用变量:**
- 变量类型
-
-
- 1) 局部变量
- 2) 环境变量
- 3) shell变量
-
- Shell中的替换
-
- **转义符:**
- **命令替换:**
- **变量替换**:
- Shell运算符
-
- **算数运算符:**
- **关系运算符:**
- **布尔运算符:**
- **字符串运算符:**
- **文件测试运算符:**
- Shell中的字符串
-
- 单引号和双引号
- 拼接字符串:
- 获取字符串长度:
- 提取子字符串/截取:
- 处理路经的字符串:
- Shell的数组:
-
- **定义数组:**
- **读取数组:**
- **获取数组的信息/长度/下标:**
- printf函数:
- Shell中条件语句
-
- if 语句
- **case …… esac语句**
- Shell 的循环语句
-
- **for 循环**
- **while循环**
- **until 循环**
- Shell函数
- shell的文件包含:
-
- 示例重要:
-
- 1.循环在一个文件夹里面创建10个文件
- 2.sqoop 把mysql数据导入hive
Shell介绍
Shell是一种脚本语言,那么,就必须有解释器来执行这些脚本,常见的脚本解释器有:
**bash:**是Linux标准默认的shell。bash由Brian Fox和Chet Ramey共同完成,是BourneAgain Shell的缩写,内部命令一共有40个。
sh: 由Steve Bourne开发,是Bourne Shell的缩写,sh 是Unix 标准默认的shell。
另外还有:ash、 csh、 ksh等。
常见的编程语言分为两类:一个是编译型语言,如:c/c++/java等,它们远行前全部一起要经过编译器的编译。另一个解释型语言,执行时,需要使用解释器一行一行地转换为代码,如:awk, perl, python与shell等。
Shell 经过了POSIX的标准化,所以它是可以在不同的linux系统上进行移植。
关于注释的问题: 在shell中使用#进行注释,注意,sh里面没有多行注释,只能每一行加一个#号;
第一个shell脚本程序:
touch 文件名 创建一个文件
vi 文件名 会自动创建一个文件
#!/bin/bash # 上面中的 #! 是一种约定标记, 它可以告诉系统这个脚本需要什么样的解释器来执行; echo "Hello, world!"
报错:-bash: ./helloShell: 权限不够
[root@hadoop2 shellTest]# chmod 777 helloShell
Shell脚本的执行
1,输入脚本的绝对路径或相对路径
/root/helloWorld.sh
./helloWorld.sh
2,bash或sh +脚本
bash /root/helloWorld.sh
sh helloWorld.sh
注:当脚本没有x权限时,root和文件所有者通过该方式可以正常执行。
3,在脚本的路径前再加". " 或source
source /root/helloWorld.sh
. ./helloWorld.sh
区别:第一种和第二种会新开一个bash,不同bash中的变量无法共享。但是使用. ./脚本.sh 这种方式是在同一个shell里面执行的。
shell脚本在执行时,向脚本传递参数
运行脚本的时候命令后面跟上参数,参数之间用空格隔开
在编写脚本的时候可以使用$1获取第一个参数$2获取第二个参数…
https://www.cnblogs.com/guosj/p/4904799.html
定时任务,定时执行shell脚本
https://www.cnblogs.com/zhuyeshen/p/12073618.html https://www.cnblogs.com/ccppjy/p/11167704.html
需要先安装crontab
查看crontab安装了没有,服务启动没,有没有设置了开机启动
[root@hadoop2 shellTest]# yum list installed | grep crontab
crontabs.noarch 1.11-6.20121102git.el7 @anaconda
[root@hadoop2 shellTest]# systemctl status crond
没有的话安装
yum install vixie-cron
yum install crontabs
安装完启动crond服务,设置开机启动
systemctl list-unit-files | grep crond 查看服务是否开启
查看各个开机级别的crond服务运行情况
[root@CentOS ~]# chkconfig –list crond
crond 0:关闭 1:关闭 2:启用 3:启用 4:启用 5:启用 6:关闭
可以看到2、3、4、5级别开机会自动启动crond服务
取消开机自动启动crond服务:
[root@CentOS ~]# chkconfig crond off
新增调度任务可用两种方法:
1)、在命令行输入: crontab -e 然后添加相应的任务,wq存盘退出。
2)、直接编辑/etc/crontab 文件,即vi /etc/crontab,添加相应的任务。
crontab -e配置是针对某个用户的,而编辑/etc/crontab是针对系统的任务
查看调度任务
crontab -l //列出当前的所有调度任务
crontab -l -u jp //列出用户jp的所有调度任务
删除任务调度工作
crontab -r //删除所有任务调度工作
把定义定时任务的文件里面的任务给删了该定时任务就没有了
直接编辑 vim /etc/crontab ,默认的文件形式如下:
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
*/1 * * * * root /root/hello.sh >> /root/sh.txt
~
前四行是有关设置cron任务运行的环境变量。
SHELL变量的值指定系统使用的SHELL环境(该样例为bash shell),
PATH变量定义了执行命令的路径。Cron的输出以电子邮件的形式发给MAILTO变量定义的用户名。
如果MAILTO变量定义为空字符串(MAILTO=""),电子邮件不会被发送。执行命令或脚本时HOME变量可用来设置基目录。
时间表达式
文件/etc/crontab中每行任务的描述格式如下: cron表达式,具体可以看cron表达式的笔记(kafka/flume)
minute hour day month dayofweek command (*/1 * * * *)
minute - 从0到59的整数
hour - 从0到23的整数
day - 从1到31的整数 (必须是指定月份的有效日期)
month - 从1到12的整数 (或如Jan或Feb简写的月份)
dayofweek - 从0到7的整数,0或7用来描述周日 (或用Sun或Mon简写来表示)
command - 需要执行的命令(可用as ls /proc >> /tmp/proc或 执行自定义脚本的命令)
星号表示任意,例如day的地方是*表示每天执行
任务写法介绍
*/1 * * * * root /root/hello.sh >> /root/sh.txt
root表示以root用户身份来运行
run-parts表示后面跟着的是一个文件夹,要执行的是该文件夹下的所有脚本
对于以上各语句,星号()表示所有可用的值。例如在指代month时表示每月执行(需要符合其他限制条件)该命令。
整数间的连字号(-)表示整数列,例如1-4意思是整数1,2,3,4
指定数值由逗号分开。如:3,4,6,8表示这四个指定整数。
符号“/”指定步进设置。“/”表示步进值。如0-59/2定义每两分钟执行一次。步进值也可用星号表示。如*/3用来运行每三个月份运行指定任务。
以“#”开头的为注释行,不会被执行。
*/1 * * * * root /root/hello.sh >> /root/sh.txt
执行的是每隔一分钟执行一次hello.sh脚本 上边脚本输出的内容 大家也知道 >> 符号 指定文件获取内容的存放位置,结果写入/root/sh.txt
每五分钟执行 */5 * * * *
每小时执行 0 * * * *
每天执行 0 0 * * *
每周执行 0 0 * * 0
每月执行 0 0 1 * *
每年执行 0 0 1 1 *
0 2 * * * root ``/usr/local/wfjb_web_back/backDB``.sh ``#每天凌晨两点执行backDB.sh该文件
Cron表达式从左往右,从秒开始;而Crontab则是从分钟开始的。
Cron表达式是一个字符串,字符串以5或6个空格隔开,分为6或7个域,每一个域代表一个含义,Cron有如下两种语法
(1) Seconds Minutes Hours DayofMonth Month DayofWeek Year
(2)Seconds Minutes Hours DayofMonth Month DayofWeek
获取系统时间并且序列化成想要的格式
time=$(date “+%Y%m%d-%H%M%S”)
或者
time=$(date “+%Y-%m-%d %H:%M:%S”)
…等各种自己想要的格式
echo “${time}”
上面两行简单的代码就是shell获取当前时间并按照自己想要的格式输出。
需要注意几点
date后面有一个空格,否则无法识别命令,shell对空格还是很严格的。
Y显示4位年份,如:2018;y显示2位年份,如:18。m表示月份;M表示分钟。d表示天,而D则表示当前日期,如:1/18/18(也就是2018.1.18)。H表示小时,而h显示月份(有点懵逼)。s显示当前秒钟,单位为毫秒;S显示当前秒钟,单位为秒。
https://blog.csdn.net/qq_35531549/article/details/88748752
查看和修改Linux的时间的命令
\1. 查看时间和日期
命令 : “date”
2.设置时间和日期,使用-s参数
例如:将系统日期设定成2019年12月4日的命令
命令 : “date -s 12/04/2019”
将系统时间设定成下午15点14分55秒的命令
命令 : “date -s 15:14:55”
\3. 将当前时间和日期写入BIOS,避免重启后失效
命令 : “hwclock -w” (记忆方法,hardware clock write. 硬件时间写入)
4.扩展
date
不加参数可以直接看到当前日期时间
cal
不加参数可以直接看到本月月历
变量:
定义变量:
country="China"
Number=100
注意: 1,变量名和等号之间不能有空格;
2,首个字符必须为字母(a-z,A-Z)。
3, 中间不能有空格,可以使用下划线(_)。
4, 不能使用标点符号。
5, 不能使用bash里的关键字(可用help命令查看保留关键字)。
使用变量:
只需要在一个定义过的变量前面加上美元符号 $ 就可以了, 另外,对于变量的{} 是可以选择的, 它的目的为帮助解释器识别变量的边界.
country="China"
echo $country
echo ${country}
echo "I love my ${country}abcd!"
#这个需要有{}的;
重定义变量: 直接把变量重新像开始定义的那样子赋值就可以了:
country="China"
country="ribenguizi"
只读变量: 用 readonly 命令 可以把变量字义为只读变量。
readonly country="China"
#或
country="China"
readonly country
删除变量: 使用unset命令可以删除变量,但是不能删除只读的变量。用法:
unset variable_name
将一个命令的执行结果赋给变量
A=`ls -la` 反引号,运行里面的命令,并把结果返回给变量A
A=$(ls -la) 等价于反引号
eg: aa=$((4+5))
bb=`expr 4 + 5s `
变量类型
运行shell时,会同时存在三种变量:
1) 局部变量
局部变量在脚本或命令中定义,仅在当前shell实例中有效,其他shell启动的程序不能访问局部变量。
2) 环境变量
所有的程序,包括shell启动的程序,都能访问环境变量,有些程序需要环境变量来保证其正常运行。必要的时候shell脚本也可以定义环境变量。
3) shell变量
shell变量是由shell程序设置的特殊变量。shell变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了shell的正常运行
特殊变量:

$* 和 $@ 的区别为: $* 和 $@ 都表示传递给函数或脚本的所有参数,不被双引号(" “)包含时,都以”$1" “ 2 " … " 2" … " 2"…"n” 的形式输出所有参数。但是当它们被双引号(" “)包含时,”$*" 会将所有的参数作为一个整体,以"$1 $2 … n " 的 形 式 输 出 所 有 参 数 ; " n"的形式输出所有参数;" n"的形式输出所有参数;"@" 会将各个参数分开,以"$1" “ 2 " … " 2" … " 2"…"n” 的形式输出所有参数。
$? 可以获取上一个命令的退出状态。所谓退出状态,就是上一个命令执行后的返回结果。退出状态是一个数字,一般情况下,大部分命令执行成功会返回 0,失败返回 1。
Shell中的替换
转义符:
在echo中可以用于的转义符有:
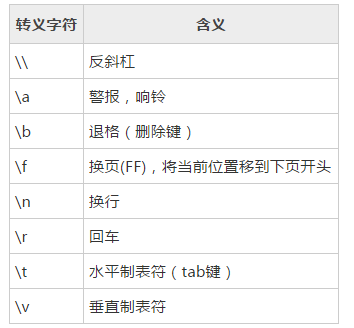
使用 echo 命令的 –E 选项禁止转义,默认也是不转义的; 使用 –n 选项可以禁止插入换行符;
使用 echo 命令的 –e 选项可以对转义字符进行替换。
另外,注意,经过我的实验,得到:
echo "\\" #得到 \
echo -e "\\" #得到 \
echo "\\\\" #得到 \\
echo -e "\\" #得到 \
命令替换:
它的意思就是说我们把一个命令的输出赋值给一个变量,方法为把命令用反引号(在Esc下方)引起来. 比如:
directory=`pwd`
echo $directory
变量替换:
可以根据变量的状态(是否为空、是否定义等)来改变它的值.
[
Shell运算符
算数运算符:
原生bash不支持简单的数学运算,但是可以通过其他命令来实现,例如 awk 和 expr. 下面使用expr进行; expr是一款表达式计算工具,使用它可以完成表达式的求值操作;
[
比如:
a=10
b=20
expr $a + $b
expr $a - $b
expr $a \* $b
expr $a / $b
expr $a % $b
a=$b
注意:
-
在expr中的乖号为:*
-
在 expr中的 表达式与运算符之间要有空格,否则错误;
-
在[ $a == $b ]与[ $a != $b ]中,要需要在方括号与变量以及变量与运算符之间也需要有括号, 否则为错误的。(亲测过)
关系运算符:
只支持数字,不支持字符串,除非字符串的值是数字。常见的有:

注意:也别忘记了空格;
布尔运算符:
[
字符串运算符:
[
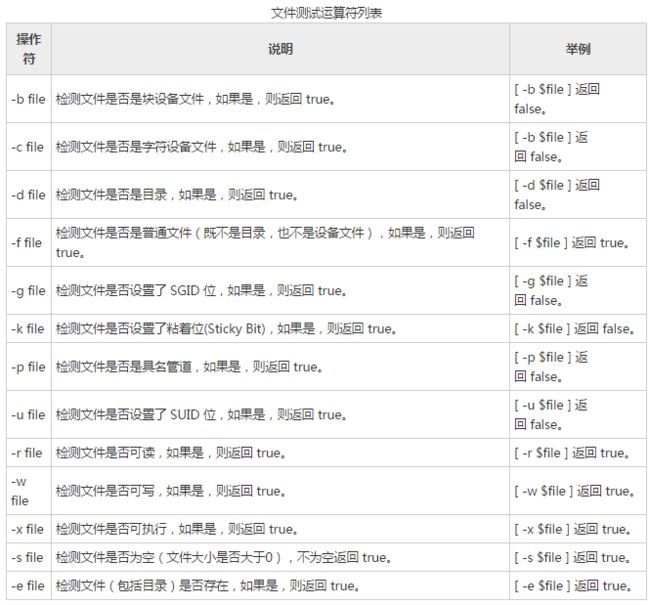
文件测试运算符:
检测 Unix 文件的各种属性。
Shell中的字符串
单引号和双引号
单引号的限制:
- 单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;
- 单引号字串中不能出现单引号(对单引号使用转义符后也不行)。
双引号的优点:
- 双引号里可以有变量
- 双引号里可以出现转义字符
拼接字符串:
country="China"
echo "hello, $country"
#也可以
echo "hello, "$country" "
获取字符串长度:
string="abcd"
echo ${#string} #输出 4
提取子字符串/截取:
字符串下标从0开始
string="alibaba is a great company"
echo ${string:1:4} #输出liba
查找子字符串:
string="alibaba is a great company"
echo `expr index "$string" is` #输出:8,这个语句的意思是:找出单词is在这名话中的位置
处理路经的字符串:
例如:当一个路径为 /home/xiaoming/1.txt时,如何怎么它的路径(不带文件) 和如何得到它的文件名??
得到文件名使用 bashname命令:
# 参数:
# -a,表示处理多个路径;
# -s, 用于去掉指定的文件的后缀名;
basename /home/yin/1.txt -> 1.txt
basename -a /home/yin/1.txt /home/zhai/2.sh -> 1.txt 2.sh
basename -s .txt /home/yin/1.txt -> 1
basename /home/yin/1.txt .txt -> 1
得到路径名(不带文件名)使用 dirname命令:
参数:没有啥参数;
//例子:
dirname /usr/bin/ -> /usr
dirname dir1/str dir2/str -> dir1 dir2
dirname stdio.h -> .
Shell的数组:
bash支持一维数组, 不支持多维数组, 它的下标从0开始编号. 用下标[n] 获取数组元素;
定义数组:
在shell中用括号表示数组,元素用空格分开。 如:
array_name=(value0 value1 value2 value3)
也可以单独定义数组的各个分量,可以不使用连续的下标,而且下标的范围没有限制。如:
array_name[0]=value0
array_name[1]=value1
array_name[2]=value2
读取数组:
读取某个下标的元素一般格式为:
${array_name[index]}
读取数组的全部元素,用@或*
${array_name[*]}
${array_name[@]}
获取数组的信息/长度/下标:
取得数组元素的个数:
length=${#array_name[@]}
#或
length=${#array_name[*]}
获取数组的下标:
length=${!array_name[@]} #或 length=${!array_name[*]}
取得数组单个元素的长度:
lengthn=${#array_name[n]}
printf函数:
它与c语言中的printf相似,不过也有不同,下面列出它的不同的地方:
- printf 命令不用加括号
- format-string 可以没有引号,但最好加上,单引号双引号均可。
- 参数多于格式控制符(%)时,format-string 可以重用,可以将所有参数都转换。
- arguments 使用空格分隔,不用逗号。
下面为例子:
# format-string为双引号 $ printf "%d %s\n" 1 "abc" 1 abc # 单引号与双引号效果一样 $ printf '%d %s\n' 1 "abc" 1 abc # 没有引号也可以输出 $ printf %s abcdef abcdef # 格式只指定了一个参数,但多出的参数仍然会按照该格式输出,format-string 被重用 $ printf %s abc def abcdef $ printf "%s\n" abc def abc def $ printf "%s %s %s\n" a b c d e f g h i j a b c d e f g h i j # 如果没有 arguments,那么 %s 用NULL代替,%d 用 0 代替 $ printf "%s and %d \n" and 0 # 如果以 %d 的格式来显示字符串,那么会有警告,提示无效的数字,此时默认置为 0 $ printf "The first program always prints'%s,%d\n'" Hello Shell -bash: printf: Shell: invalid number The first program always prints 'Hello,0' $
Shell中条件语句
if 语句
包括:1. if [ 表达式 ] then 语句 fi
-
if [ 表达式 ] then 语句 else 语句 fi
-
if [ 表达式] then 语句 elif[ 表达式 ] then 语句 elif[ 表达式 ] then 语句 …… fi
例子:
a=10
b=20
if [ $a == $b ]
then
echo "a is equal to b"
else
echo "a is not equal to b"
fi
另外:if … else 语句也可以写成一行,以命令的方式来运行,像这样:
if test $[2*3] -eq $[1+5]; then echo 'The two numbers are equal!'; fi;
其中,test 命令用于检查某个条件是否成立,与方括号([ ])类似。
case …… esac语句
case … esac 与其他语言中的 switch … case 语句类似,是一种多分枝选择结构。case语句格式如下:
case 值 in
模式1)
command1
command2
command3
;;
模式2)
command1
command2
command3
;;
*)
command1
command2
command3
;;
esac
其中, 1. 取值后面必须为关键字 in,每一模式必须以右括号结束。取值可以为变量或常数。匹配发现取值符合某一模式后,其间所有命令开始执行直至 ;;。;; 与其他语言中的 break 类似,意思是跳到整个 case 语句的最后。2. 如果无一匹配模式,使用星号 * 捕获该值,再执行后面的命令。
Shell 的循环语句
for 循环
一般格式为:
for 变量 in 列表
do
command1
command2
...
commandN
done
注意:列表是一组值(数字、字符串等)组成的序列,每个值通过空格分隔。每循环一次,就将列表中的下一个值赋给变量。 例如:
顺序输出当前列表的数字:
for loop in 1 2 3 4 5
do
echo "The value is: $loop"
done
显示主目录下以 .bash 开头的文件:
#!/bin/bash
for FILE in $HOME/.bash*
do
echo $FILE
done
while循环
一般格式为:
while command do Statement(s) to be executed if command is true done例如:
COUNTER=0 while [ $COUNTER -lt 5 ] do COUNTER='expr $COUNTER+1' echo $COUNTER done
until 循环
until 循环执行一系列命令直至条件为 true 时停止。until 循环与 while 循环在处理方式上刚好相反。 常用格式为:
until command
do
Statement(s) to be executed until command is true
done
command 一般为条件表达式,如果返回值为 false,则继续执行循环体内的语句,否则跳出循环。
类似地, 在循环中使用 break 与continue 跳出循环。 另外,break 命令后面还可以跟一个整数,表示跳出第几层循环。
Shell函数
Shell函数必须先定义后使用,定义如下,
function_name () { list of commands [ return value ] }也可以加上function关键字:
function function_name () { list of commands [ return value ] }注意:
调用函数只需要给出函数名,不需要加括号。
函数返回值,可以显式增加return语句;如果不加,会将最后一条命令运行结果作为返回值。
Shell 函数返回值只能是整数,一般用来表示函数执行成功与否,0表示成功,其他值表示失败。
函数的参数可以通过 $n 得到.如:
funWithParam(){ echo "The value of the first parameter is $1 !" echo "The value of the second parameter is $2 !" echo "The value of the tenth parameter is ${10} !" echo "The value of the eleventh parameter is ${11} !" echo "The amount of the parameters is $# !" # 参数个数 echo "The string of the parameters is $* !" # 传递给函数的所有参数 } funWithParam 1 2 3 4 5 6 7 8 9 34 73
像删除变量一样,删除函数也可以使用 unset 命令,不过要加上 .f 选项,如下所示:
unset .f function_name
shell的文件包含:
Shell 也可以包含外部脚本,将外部脚本的内容合并到当前脚本。使用:
. filename #或 source filename
两种方式的效果相同,简单起见,一般使用点号(.),但是注意点号(.)和文件名中间有一空格。
被包含脚本不需要有执行权限。
示例重要:
1.循环在一个文件夹里面创建10个文件
#!/bin/sh
cd ~
mkdir shell_tut
cd shell_tut
for ((i=0; i<10; i++));
do
touch test_$i.txt
done
示例解释
•第1行:指定脚本解释器,这里是用/bin/sh做解释器的
•第2行:切换到当前用户的home目录
•第3行:创建一个目录shell_tut
•第4行:切换到shell_tut目录
•第5行:循环条件,一共循环10次
•第6行:创建一个test_1…10.txt文件
•第7行:循环体结束
cd, mkdir, touch都是系统自带的程序,一般在/bin或者/usr/bin目录下。for, do, done是sh脚本语言的关键字。
2.sqoop 把mysql数据导入hive
#!/bin/bash
sqoop import --connect jdbc:mysql://192.168.4.22:3306/dsp --username root --password CJmy@567 --table dsp_account --hcatalog-database ods --hcatalog-table dsp_account_orc -m 1
echo "完成!!!"
https://www.cnblogs.com/zhangchao162/p/9614145.html
https://www.cnblogs.com/yinheyi/p/6648242.html
脚本大全,里面有100个左右的shell脚本https://blog.csdn.net/hongrisl/article/details/88062228 不知道咋写看看
学习参考:https://blog.csdn.net/qq_36119192/article/details/82964713
https://www.jb51.net/article/161028.htm
shell的执行顺序:https://www.cnblogs.com/guge-94/p/10482921.html