基于pyqt和卷积网络CNN的中文汉字识别
直接上效果演示图:
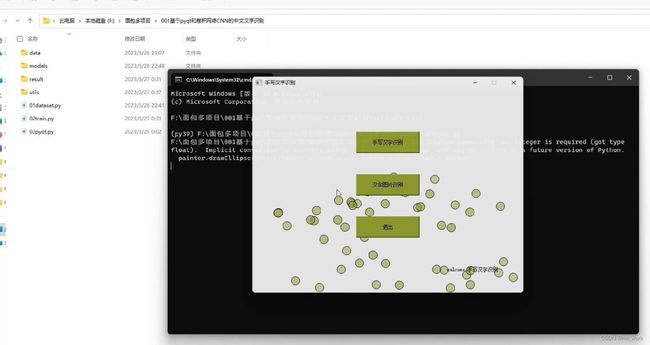

通过点击按钮可以实现在画板上写汉字识别和加载图片识别两个功能。
视频演示和demo仓库地址在b站视频001期:
到此一游7758258的个人空间-到此一游7758258个人主页-哔哩哔哩视频
所有代码展示:
十分的简洁,主要是01,02,03.py文件
运行01dataset.py可以将data文件下的图片数据集保存成txt格式记录。
运行02train.py可以读取txt记录的图片数据进行训练,训练的模型保存在本地,其中提供了10多种的模型可以任意的切换。包括:efficientnet、Alexnet、DenseNet、DLA、GoogleNet、Mobilenet、ResNet、ResNext、ShuffleNet、Swin_transformer、VGG等。
训练结束后保存评价指标图在result文件下:

最后运行03pyqt.py可以展示一个可视化的交互界面,通过点击按钮来识别,这里弹出的界面上提供了第一个按钮为在画板上控制鼠标写出汉字识别。
第二个按钮为加载汉字图片进行识别。
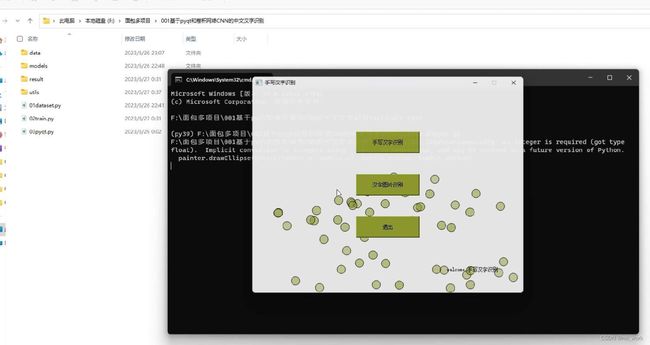
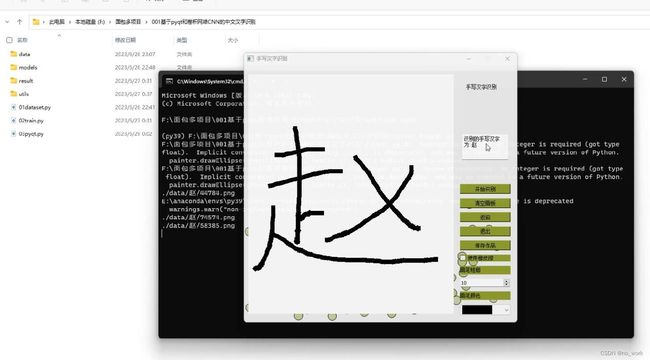
先是第一个按钮点击后,左侧为鼠标手写汉字界面,右侧为预测结果和控制按钮。
第二个按钮和第一个按钮界面展示一样,只不过手写变成了加载本地图片来识别。

科普下卷积神经网络相关知识:
CNN是卷积神经网络(Convolutional Neural Network)的缩写。它是一种前馈神经网络,特别适用于处理具有网格状结构的数据,例如图像、视频和声音等。CNN由多个卷积层、池化层和全连接层组成。
CNN的核心思想是通过卷积操作和池化操作来提取输入数据中的特征。卷积层使用卷积核对输入数据进行滑动窗口操作,以捕捉不同位置的局部特征。通过堆叠多个卷积层,网络可以学习到更加复杂的特征表示。池化层则用于降低数据维度,并保留最显著的特征。全连接层将特征映射到具体的输出类别上。
CNN在计算机视觉领域取得了巨大成功,广泛应用于图像分类、目标检测、人脸识别等任务。其优势在于能够自动学习具有平移不变性的特征,并且对于大规模数据集训练时具有较好的性能。
ALexNet是一种深度卷积神经网络(CNN),由Alex Krizhevsky等人于2012年提出。它是第一个在ImageNet Large-Scale Visual Recognition Challenge(ILSVRC)上取得显著优势的深度学习模型。
ALexNet采用了多层卷积层和全连接层的结构。相比于传统的浅层网络,ALexNet引入了更深的网络结构,包含5个卷积层和3个全连接层。同时,它还使用了非线性激活函数(ReLU)来增强模型的表达能力,并且引入了局部响应归一化(Local Response Normalization)层来提高泛化性能。
ALexNet的设计突破了之前的限制,通过大规模数据集的训练,成功地提升了图像分类任务的准确性。它在2012年的ILSVRC比赛中取得了远超其他模型的成绩,标志着深度学习方法在计算机视觉领域的崛起。
ALexNet的成功对深度学习的发展产生了重要影响,激发了更多研究者对深度神经网络的研究兴趣,并为后续的网络架构设计提供了启示。
GoogleNet,也称为Inception,是由Google团队在2014年提出的深度卷积神经网络(CNN)。它是为了参加ImageNet Large-Scale Visual Recognition Challenge(ILSVRC)而设计的。
GoogleNet采用了一种称为"Inception模块"的特殊结构,它允许网络在不同尺度上进行并行处理,以捕捉不同层次的特征。这种并行处理有助于减少参数量,并且在一定程度上缓解了过拟合问题。
与传统的网络相比,GoogleNet具有更深的结构,但通过合理的设计和使用1x1的卷积核进行降维操作,成功地减少了计算复杂度和参数数量。它在2014年的ILSVRC比赛中取得了显著的成果,并且提出的架构思想影响了后续深度学习模型的发展。
VGG是一种深度卷积神经网络(CNN),由牛津大学的研究团队在2014年提出。它被命名为VGG,以纪念论文作者之一Visual Geometry Group(视觉几何群)。
VGG网络的主要特点是其深度和简单性。相比于之前的模型,VGG采用了更多的卷积层和池化层,达到了16或19个卷积层的深度。同时,VGG中的卷积层都使用了较小的3x3卷积核,并且连续堆叠多次,以增加网络的非线性表达能力。
VGG网络的结构非常规整,逻辑清晰。它由多个卷积块组成,每个卷积块由连续的卷积层和一个池化层构成。最后的全连接层负责将提取到的特征映射到具体的输出类别上。
尽管VGG网络相对较深,但它在各种视觉任务上表现出色。VGG的设计思想启发了后续更深层次的神经网络架构,为深度学习的发展做出了重要贡献。
RESNET是一种深度残差网络(Residual Network),由微软研究院的研究团队在2015年提出。它是为了解决深度神经网络中的退化问题(degradation problem)而设计的。
在传统的深度神经网络中,随着网络层数的增加,模型的准确性通常会饱和或下降。这是因为较深层次的网络更难优化,容易出现梯度消失或梯度爆炸等问题。为了解决这个问题,RESNET引入了残差学习的思想。
RESNET通过跳过连接(skip connection)来构建残差块。跳过连接使得信息可以直接在网络中传递,绕过某些层,从而避免了信息丢失和退化。具体而言,每个残差块的输入通过一个恒等映射(identity mapping)与输出相加,然后再进入激活函数进行非线性变换。这种设计使得网络学习到残差的差异,从而更有效地优化模型。
RESNET的结构可以很容易地扩展到更深的层数,甚至达到数百层的深度。利用残差连接的设计,RESNET在ILSVRC比赛等各种视觉任务中取得了非常出色的结果,并且成为深度学习中非常重要的网络架构之一。
MobileNet是一种轻量级的深度卷积神经网络(CNN),由Google的研究团队于2017年提出。它的设计旨在实现在嵌入式设备和移动设备等资源受限的环境下进行高效的图像识别和分类。
MobileNet通过使用深度可分离卷积(depthwise separable convolution)来减少模型的计算量和参数数量。深度可分离卷积将标准卷积操作拆分为两个步骤:深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)。深度卷积对每个输入通道单独执行卷积操作,而逐点卷积用于组合输出通道。这种方式可以大幅减少计算量,同时保持较好的模型准确性。
MobileNet还引入了宽度乘法器(width multiplier)和分辨率乘法器(resolution multiplier)的概念。宽度乘法器用于控制每一层的特征通道数,以进一步减少模型的计算负载。分辨率乘法器则用于调整输入图像的分辨率,从而在模型运行时降低计算需求。
MobileNet在保持相对较小模型大小和低计算成本的同时,仍能保持较高的识别准确率。这使得它在移动设备、嵌入式设备和实时应用等场景中受到广泛应用,例如图像分类、目标检测和人脸识别等任务。
ShuffleNet是一种轻量级的深度神经网络架构,由微软研究院的研究团队于2018年提出。它的设计目标是在计算资源受限的设备上实现高效的图像分类和目标检测。
ShuffleNet通过引入逐通道组卷积(channel shuffling)和分组卷积(group convolution)等操作来减少模型的计算复杂度和参数量。逐通道组卷积将输入特征图的通道重新排列,以增加不同通道之间的交互性。分组卷积将输入特征图分为多个组,并对每个组进行卷积操作,以减少计算量。
ShuffleNet的核心结构是Shuffle Unit,它包含了逐通道组卷积、分组卷积和特征重组(feature shuffle)等操作。Shuffle Unit的设计使得网络在同时保持较低计算负担的前提下,能够学习到更丰富的特征表示。
ShuffleNet具有较小的模型大小和低计算需求,适合在移动设备、嵌入式设备和实时应用等场景中部署。它在保持相对较高的准确率的同时,有效地优化了计算资源的利用。ShuffleNet已经在图像分类、目标检测和人脸识别等领域取得了显著的成果,并为轻量级深度学习模型的发展提供了重要思路。
EfficientNet是一种高效的深度卷积神经网络(CNN)架构,由Google Brain团队在2019年提出。它通过联合优化模型深度、宽度和分辨率来实现更好的性能和计算效率。
EfficientNet的设计思想是基于两个观察结果:首先,较大的模型往往具有更好的性能,但训练和推理成本也更高;其次,网络的深度、宽度和分辨率之间存在着相互依赖的关系。基于这些观察结果,EfficientNet使用了一个称为Compound Scaling的方法,同时增加了模型的深度、宽度和分辨率,以在资源受限的环境下取得更好的性能。
EfficientNet的核心结构是EfficientNet-B0到EfficientNet-B7,它们是由不同层数和通道数的组合构成的。通过使用复合缩放方法,每个EfficientNet模型都可以根据任务和计算资源进行调整,并在准确性和计算效率之间找到一个平衡点。
EfficientNet在许多计算机视觉任务上表现出色,包括图像分类、目标检测和语义分割等。它已经成为当今领先的深度学习模型之一,为在资源受限的设备上实现高效而准确的推理提供了重要的解决方案。
Swin Transformer是一种新兴的视觉感知模型,由香港中文大学的研究团队在2021年提出。它结合了Transformer架构和局部窗口注意力机制,通过分解嵌入式图像处理的长距离依赖性问题。
传统的Transformer模型在处理图像时会面临计算和内存开销的挑战,因为图像具有高分辨率和大量的位置信息。为了解决这个问题,Swin Transformer引入了一个细粒度的分割策略和基于窗口的局部注意力机制。
Swin Transformer首先将输入图像分成小的非重叠路径块(patch),然后在这些路径块上应用Transformer的自注意力机制。接下来,通过使用窗口化的局部注意力机制,模型能够同时处理局部和全局的信息。这种设计不仅降低了计算和内存开销,还有效地捕捉到了图像中不同尺度的特征。
Swin Transformer在多个计算机视觉任务上取得了令人印象深刻的结果,包括图像分类、目标检测和语义分割等。它兼具高效性和表现力,在减少计算复杂度的同时,保持了较好的准确性和泛化性能。Swin Transformer为图像处理领域带来了新的思路和突破,并吸引了广泛的关注和研究。