常见结构—索引
一、索引的分类
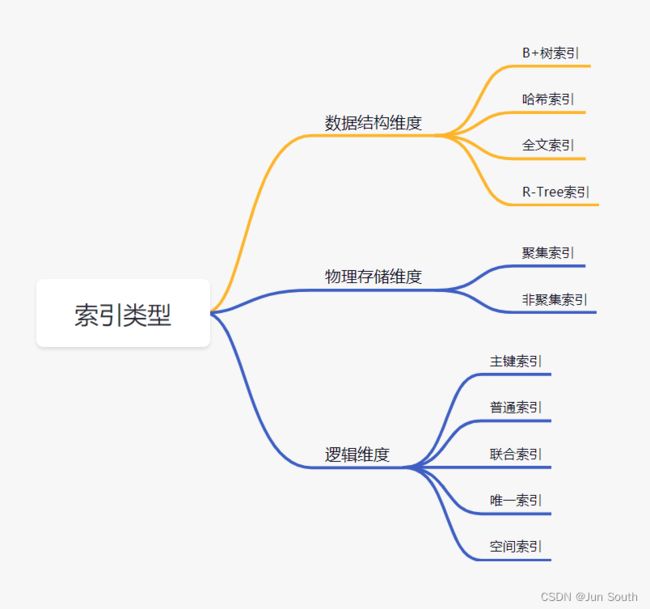
1、数据结构维度
1.B+树索引:所有数据存储在叶子节点,复杂度为O(logn),适合范围查询。
2.哈希索引: 适合等值查询,检索效率高,一次到位。
3.全文索引:MyISAM和InnoDB中都支持使用全文索引,一般在文本类型char,text,varchar类型上创建。
4.R-Tree索引: 用来对GIS数据类型创建SPATIAL索引。
2、物理存储维度
1.聚集索引:聚集索引就是以主键创建的索引,在叶子节点存储的是表中的数据。(Innodb存储引擎)。
2.非聚集索引:非聚集索引就是以非主键创建的索引,在叶子节点存储的是主键和索引列。(Innodb存储引擎)。
3、逻辑维度
1.主键索引:一种特殊的唯一索引,不允许有空值。
2.普通索引:MySQL中基本索引类型,允许空值和重复值。
3.联合索引:多个字段创建的索引,使用时遵循最左前缀原则。
4.唯一索引:索引列中的值必须是唯一的,但是允许为空值。
5.空间索引:MySQL5.7之后支持空间索引,在空间索引这方面遵循OpenGIS几何数据模型规则。
二、索引间的区别
1、聚簇索引 与 非聚簇索引
聚簇索引是数据存储方式,表示索引结构和数据一起存放的索引,非聚集索引是索引结构和数据分开存放的索引。
聚簇索引叶子节点存储了一整行记录,而非聚簇索引叶子节点存储的是主键信息,一般非聚簇索引还需要回表查询。
一个表中只能拥有一个聚集索引(因为一般聚簇索引就是主键索引),而非聚集索引一个表则可以存在多个。
在MyISM存储引擎中,主键索引、普通索引都是非聚簇索引,因为数据和索引是分开的,叶子节点都使用一个地址指向数据。
2、Hash 索引
2.1Hash 索引和 B+树
1.B+树可以进行范围查询,Hash 索引不能。
2.B+树支持联合索引的最左侧原则,Hash 索引不支持。
3.B+树支持 order by 排序,Hash 索引不支持。
4.Hash 索引在等值查询上比 B+树效率更高。(但是索引列的重复值很多的话,Hash冲突,效率降低)。
5.B+树使用 like 进行模糊查询的时候,like 后面(比如%开头)的话可以起到优化的作用,Hash 索引根本无法进行模糊查询。
2.2哈希索引限制
哈希索引只包含哈希值和行指针,不存储字段值,所以不能使用"覆盖索引"的优化方式,去避免读取数据表。
哈希索引数据并不是按照索引值顺序存储的,索引也就无法用于排序
哈希索引页不支持部分索引列匹配查找,因为哈希索引始终是使用索引列的全部内容计算哈希值的。
哈希索引只支持等值比较查询,包括=,in(),<=>,不支持任何范围查询。列入where price>100 访问哈希索引的数据非常快,除非有很多哈希冲突(不同的索引列值却有相同的哈希值)
如果哈希冲突很多的话,一些索引维护操作的代价也会很高。
有大量重复键值情况下,哈希索引的效率也是极低的,存在所谓的哈希碰撞问题
3、全文索引
5.6版本之后InnoDB存储引擎开始支持全文索引,仅支持英文,通过空格作为分词的分隔符,对于中文来说是不合适的
5.7版本之后通过使用ngram插件开始支持中文。
MySQL允许在char、varchar、text类型上建立全文索引
mysql的全文索引主要用于全文字段的检索场景,支持char、varchar、text几个字段加全文索引,仅支持InNoDB与MyISAM引擎。
使用倒排索引(inverted index)的方式,将字段中的内容进行分词,
存储分词与自身所在位置的映射,从而加快查询效率。
内置了ngram解析器来支持中文、日文、韩文等语言的文本,全文索引支持通过建表语句来创建或者建表后新增。
ngram简介
ngram一种基于统计语言模型的算法,是通过一个大小为n的滑动窗口,将一段文本分成多个由n个连续单元组成的term。
三、注意事项
1、索引失效
1、like,前模糊查询不能使用索引。(在建立索引时用reverse(columnName)处理)。
2、数据区分度不大的字段不宜使用索引。
3、组合索引最左前缀不满足。
4、MySQL规定: 函数计算索引失效。
失效: select id from user where id + 1 = 10000;
有效: select id from user where id = 9999;
5、隐式类型转换
select * from user where id = 1;如果id是字符类型的,1是数字类型的,索引失效(当于加CAST( id AS signed int)函数)。
6、隐式字符编码转换
两个表的字符集不一样,一个是utf8mb4,一个是utf8,相当于加了CONVERT(id USING utf8mb4)函数,索引失效。
7、当用 or 时,查询条件中只有or关键字,且or前后的两个条件中的列都有索引时,查询中才使用索引。
8、不要在 SQL 中用双引号。
9、使用 <> 、not in 、not exist、!= 会使索引失效。
10、不要用null直接与运算符比较,应用 is null 或 is not null 进行比较,或用 isnull 函数。
2、执行计划 Explain
MySQL5.6 支持 select语句
MySQL8.0 支持 select、delete、inster、replace、update语句
2.1、Explain 重要字段
id:
查询的序列号
id相同时,执行顺序由上至下。
id不同,子查询时id会递增,id值越大优先级越高,则越先被执行。
id相同和不同都存在时,id相同的可以理解为一组,从上往下顺序执行。所有组中,id值越大,优先级越高越先执行。
select_type:
查询的类型,常见值有如下,
simple:表示查询类型,查询中不包括子查询或者union。
primary:查询中若包含任何复杂的子部分,最外层查询则被标记为primary
derived:在from列表中包含的子查询被标记为derived(衍生),MySQL会递归执行这些子查询,把结果放在临时表里。
subquery:在select或where列表中包含了子查询。
table:
显示这一行的数据是关于哪张表的。
partitions:
表示涉及到的分区。
type:
访问类型排序,包括ALL(全表扫描)、index(索引扫描)、range(索引范围扫描)、ref(非唯一索引扫描)、eq_ref(唯一索引扫描)等;
system > const > eq_ref > ref > ref_or_null > index_merge > range > index > ALL
system:const连接类型的特例,当查询的表只有一行时使用
const:通过索引一次就找到了,如对主键或唯一索引的查询,这是效率最高的链接方式
eq_ref:唯一索引或主键查询,对应每个索引建,表中只有一条记录与之匹配 【A表扫描每一行B表只有一行匹配满足】
ref:非唯一索引查找,返回匹配某个单独值的所有行。
ref_or_null:类似于ref类型的查询,但是附加了对NULL值列的查询
index_merge:该链接类型表示使用了索引合并优化方法
range:索引范围扫描,常见于between、>、< 这样的查询条件
index:FULL index Scan全索引扫描,同ALL的区别是,遍历的是索引树
ALL:FULL TABLE Scan全表扫描 ,这是效率最差的链接方式
possible——keys:
可能用到的索引,但不一定实际使用上。
key:
查询中实际使用的索引,如果为null,则没有使用索引。
ref:
指出那些列或常量被用于索引查找
rows:
检查的行数。
filtered:
表示通过条件过滤后的结果集占总结果集的百分比;
extra:
分析执行计划
Distinct: 优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作
Not exists: 使用not exists来优化查询
Using filesort: 使用文件来进行排序,通常会出现在order by 或 group by 查询中
Using index: 使用了覆盖索引进行查询**【意思是查询所需要的信息用索引来获取,不需要对表进行访问】**
Using temporary: MySQL需要使用临时表来处理,常见于排序、子查询、和分组查询
Using where: 需要在MySQL服务器层使用WHERE条件来过滤数据
select tables optimized away: 直接通过索引来获取数据,不用访问表
2.2、Explain 用法
mysql> explain select * from test where id=1;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | test | NULL | ALL | NULL | NULL | NULL | NULL | 7 | 14.29 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
# 给id字段添加索引
mysql> create index id_index on test(id);
Query OK, 0 rows affected (0.08 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain select * from test where id=1;
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | test | NULL | ref | id_index | id_index | 5 | const | 4 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)3、一些案例
1.大表(千万级)添加索引
添加索引时会加锁
1.先创建一张跟原表A数据结构相同的新表B。
2.在新表B添加需要加上的新索引。
3.把原表A数据导到新表B。
4.rename新表B为原表的表名A,原表A换别的表名。
2.删除大量数据
1.删除索引
2.删除数据
3.添加索引
3.慢查询优化基本步骤
1、注意设置SQL_NO_CACHE。
2、where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高。
3、explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询)。
4、order by limit 形式的sql语句让排序的表优先查。
5、了解业务方使用场景。
6、加索引时参照建索引的几大原则。
7、观察结果,不符合预期继续从1分析。
4、到排序索引
分词系统将文档自动切分成单词序列,文档转为单词序列构成的数据流,对每单词赋予唯一编号,都有对应的含有该单词的倒排列表。到排序索引需要的空间较大,节点较多。

分词:
