阿里云大数据开发三面面经,已过,面试题已配答案
一面:阿里云大数据开发一面面经,已过,面试题已配答案_蓦然_的博客-CSDN博客
二面:阿里云大数据开发二面面经,已过,面试题已配答案_蓦然_的博客-CSDN博客
1、SQL题
自由发挥
2、实习经历
根据自己的来就行,一面面试题也有说
3、Hadoop和Spark的相同点和不同点
相同点:
- Hadoop和Spark都是并行计算,两者都是用MR模型进行计算。
- 都提供了灾难恢复
-
- Hadoop将每次处理后的数据写入磁盘中,对应对系统错误具有天生优势。
- Spark的数据对象存储在弹性分布式数据集(RDD)中。这些数据对象既可放在内存,也可以放在磁盘,所以RDD也提供完整的灾难恢复功能。
不同点:
- Hadoop将中间结果存放在HDFS中,每次MR都需要刷写-调用,而Spark中间结果存放优先存放在内存中,内存不够再存放在磁盘中,不放入HDFS,避免了大量的IO和刷写读取操作;
- Hadoop底层使用MapReduce计算架构,只有map和reduce两种操作,表达能力比较欠缺,而且在MR过程中会重复的读写HDFS,造成大量的磁盘io读写操作,所以适合高时延环境下批处理计算的应用;Spark是基于内存的分布式计算架构,提供更加丰富的数据集操作类型,主要分成转化操作和行动操作,包括map、reduce、filter、flatmap、groupbykey、reducebykey、union和join等,数据分析更加快速,所以适合低时延环境下计算的应用;
- Spark与Hadoop最大的区别在于迭代式计算模型。基于MapReduce框架的Hadoop主要分为map和reduce两个阶段,所以在一个job里面能做的处理很有限,对于复杂的计算,需要使用多次MR;Spark计算模型是基于内存的迭代式计算模型,根据用户编写的RDD算子和程序,在调度时根据宽窄依赖可以生成多个Stage,根据action算子生成多个Job。所以Spark相较于MapReduce,计算模型更加灵活,可以提供更强大的功能。
- 由于Spark基于内存进行计算,在面对大量数据且没有进行调优的情况下,可能会出现比如OOM内存溢出等情况,导致spark程序可能无法运行起来,而MapReduce虽然运行缓慢,但是至少可以慢慢运行完。
- Hadoop适合处理静态数据,对于迭代式流式数据的处理能力差;Spark通过在内存中缓存处理的数据,提高了处理流式数据和迭代式数据的性能。
4、Spark RDD和DataSet的关系
RDD
RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象。代码中是一个抽象类,它代表一个不可变、可分区、里面的元素可并行计算的集合。
DataFrame
DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。
DataSet
1)是Dataframe API的一个扩展,是Spark最新的数据抽象。它提供了RDD的优势(强类型,使用强大的lambda函数的能力)以及Spark SQL优化执行引擎的优点。
2)用户友好的API风格,既具有类型安全检查也具有Dataframe的查询优化特性。
3)Dataset支持编解码器,当需要访问非堆上的数据时可以避免反序列化整个对象,提高了效率。
4)样例类被用来在Dataset中定义数据的结构信息,样例类中每个属性的名称直接映射到DataSet中的字段名称。
5) Dataframe是Dataset的特列,DataFrame=Dataset[Row] ,所以可以通过as方法将Dataframe转换为Dataset。Row是一个类型,跟Car、Person这些的类型一样,所有的表结构信息我都用Row来表示。
6)DataSet是强类型的。比如可以有Dataset[Car],Dataset[Person]。
7)DataFrame只是知道字段,但是不知道字段的类型,所以在执行这些操作的时候是没办法在编译的时候检查是否类型失败的,比如你可以对一个String进行减法操作,在执行的时候才报错,而DataSet不仅仅知道字段,而且知道字段类型,所以有更严格的错误检查。就跟JSON对象和类对象之间的类比。
5、Spark宽窄依赖
窄依赖是指父RDD的每个分区只被子RDD的一个分区所使用,子RDD分区通常对应常数个父RDD分区(O(1),与数据规模无关)
相应的,宽依赖是指父RDD的每个分区都可能被多个子RDD分区所使用,子RDD分区通常对应所有的父RDD分区(O(n),与数据规模有关)

6、Spark如何解决数据倾斜
Spark面试题——数据倾斜调优(版本一)_笔经面经_牛客网
Spark面试题——数据倾斜调优(版本二)_笔经面经_牛客网
7、Kafka如何保证高吞吐量
- 顺序读写
- 零拷贝
- 文件分段
- 批量发送
- 数据压缩
详细解释可以见牛客上分享的大数据面试题V3.0
8、Kafka如何保证消息顺序性
- 设置Key值,指定分区
- max.in.flight.requests.per.connection设置为1
- 设置重试次数大于100次
详细解释可以见牛客上分享的大数据面试题V3.0
9、Flink双流join
批处理有两种方式处理两个表的Join,一种是基于排序的Sort-Merge Join,另一种是转化为Hash Table 加载到内存里做Hash Join。
在双流Join的场景中,Join的对象是两个流,数据是不断进入的,所以我们Join的结果也是需要持续更新的。基本思路是将一个无线的数据流,尽可能拆分成有限数据集去做Join。
1)Regular Join
这种 Join 方式需要去保留两个流的状态,持续性地保留并且不会去做清除。两边的数据对于对方的流都是所有可见的,所以数据就需要持续性的存在 State 里面,那么 State 又不能存的过大,因此这个场景的只适合有界数据流。
2)Interval Join
加入了一个时间窗口的限定,要求在两个流做 Join 的时候,其中一个流必须落在另一个流的时间戳的一定时间范围内,并且它们的 Join key 相同才能够完成 Join。加入了时间窗口的限定,就使得我们可以对超出时间范围的数据做一个清理,这样的话就不需要去保留全量的 State。
Interval Join 是同时支持 processing time 和 even time去定义时间的。如果使用的是 processing time,Flink 内部会使用系统时间去划分窗口,并且去做相关的 state 清理。如果使用 even time 就会利用 Watermark 的机制去划分窗口,并且做 State 清理。
3)Window join
将两个流中有相同 key 和处在相同 window 里的元素去做 Join。它的执行的逻辑比较像 Inner Join,必须同时满足 Join key 相同,而且在同一个 Window 里元素才能够在最终结果中输出。
详细解释可以见牛客上分享的大数据面试题V3.0
10、Flink反压机制
反压(back pressure)就是流式系统中关于处理能力的动态反馈机制,并且是从下游到上游的反馈。下图示出数据流在Flink TaskManager之间流动的逻辑。
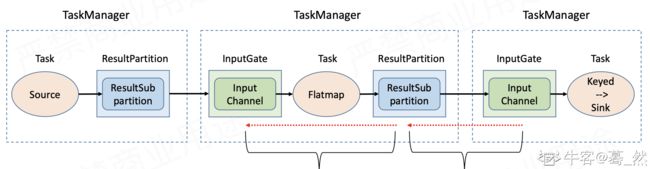
一旦因为下游处理能力不足而出现反压,反压信号的传播应该分为两个阶段:一是从下游TaskManager的输入端(InputGate)传播到直接上游TaskManager的输出端(ResultPartition);二是在TaskManager内部从输出端传播到输入端。
先介绍旧版本中的流控和反压机制。
Flink 1.5之前:基于TCP的流控和反压
在1.5版本之前,Flink并没有特别地去实现自己的流控机制,而是在传输层直接依靠TCP协议自身具备的滑动窗口机制。
Flink 1.5之后:基于Credit的流控和反压
基于TCP的流控和反压方案有两大缺点:
- 只要TaskManager执行的一个Task触发反压,该TaskManager与上游TaskManager的Socket就不能再传输数据,从而影响到所有其他正常的Task,以及Checkpoint Barrier的流动,可能造成作业雪崩;
- 反压的传播链路太长,且需要耗尽所有网络缓存之后才能有效触发,延迟比较大。
Flink 1.5+版本为了解决这两个问题,引入了基于Credit的流控和反压机制。它本质上是将TCP的流控机制从传输层提升到了应用层——即ResultPartition和InputGate的层级,从而避免在传输层造成阻塞。
太多了。。。。。详细解释可以见牛客上分享的大数据面试题V3.0
11、分布式一致性协议
二面的时候分享了