C生万物 | 指针入门到进阶全方位覆盖教程

文章篇幅较长,可前往电脑端进行学习
之前很多粉丝私信我说C语言指针怎么这么难,看了很多视频都学不懂,于是我写了一篇有关指针从入门到进阶的教学,帮助那些对指针很困扰的同学有一个好的学习途径,下面是本文的参考配套视频,出自b站【鹏哥C语言】,鹏哥讲得很好,大家快去看看
C语言程序设计从入门到进阶

文章目录
- ———————————————【指针初阶 · 入门篇】 ———————————————
- 一、指针是什么?
-
- 1、指针、地址、内存
- 2、指针与变量
- 3、解答:为何指针均为4个字节❓
- 二、指针的进一步理解
-
- 1、指针和指针类型
- 2、指针的解引用
- ⭐指针存在的意义1:访问字节的范围
- ⭐指针存在的意义2:类型决定步长
- 小练习:初始化数组
- 三、野指针
-
- 1、野指针成因
-
- ① 指针未初始化
- ② 指针越界访问
- ③ 指针指向的空间释放
- 2、如何规避野指针
- 四、指针运算
-
- 1、指针与整数的运算
- 2、指针的关系运算
- 3、指针与指针的运算
- 五、指针和数组
- 六、二级指针
-
- 1、变量、指针、二级指针
- 2、有关二级指针的运算
- ———————————————【指针进阶 · 提升篇】 ———————————————
- 一、字符指针
-
- 1、指针存放单字符
- 2、指针存放字符串
- 3、一道剑指offer的面试题
- 二、指针常量与常量指针
-
- 【引入】
- 【常量指针】
-
- 1、介绍与分析
- 2、小结与记忆口诀
- 【指针常量】
-
- 1、介绍与分析
- 2、小结与记忆口诀
- 一份凉皮所引发的故事
- 三、指针数组与数组指针
-
- 【指针数组】
-
- 1、概念明细
- 2、数组地址偏移量与指针偏移量
- 3、指针变量与数组名的置换【✔】
- 4、实例讲解
-
- ① 指针数组存放地址
- ② 指针数组存放数组
- 【数组指针】
-
- 1、数组指针的定义
- 2、&数组名VS数组名
- 3、数组指针的使用【⭐】
- 【数组传参与指针传参】
-
- 1、 一维数组传参
- 2、 二维数组传参
- 3、 一级指针传参
- 4、 二级指针传参
- 四、指针函数与函数指针
-
- 【指针函数】
-
- 1、定义
- 2、示例
- 【函数指针】
-
- 1、概念理清
- 2、如何调用函数指针?
- 3、两道“有趣”的代码题O(∩_∩)O
-
- < 第一题 >
- < 第二题 >
- 4、函数指针数组
-
- 概念明细
- 具体引用:转移表✔
- 5、指向函数指针数组的指针
- 五、回调函数
-
- 1、回调函数的概念
- 2、为什么要使用回调函数?
- 3、回调函数使用场景
-
- 场景一:模拟计算器的加减乘除
- 场景二:模拟qsort函数【⭐】
-
- 1、qsort函数解读
- 2、用用qsort
- 3、使用冒泡排序模拟qsort
- 4、原理分析
- 场景三:模拟任务下载进度
- 场景四:模拟文件下载模块
- ———————————————【指针进阶 · 炼狱篇】 ———————————————
- 一、再谈指针大小
- 二、难题攻坚战
-
- 第一题【指针运算】
- 第二题【指针偏移】
- 第三题【指针访问字节数】
- 第四题【指针数组】
- 第五题【数组指针 + 函数指针】
- 三、指针和数组笔试题解析✒
-
- 1、简易一维数组
- 2、不带 '\0' 的字符数组
- 3、带 '\0' 的字符数组
- 4、字符指针【⭐】
- 5、二维数组
- 四、指针相关历年笔试真题汇总【更新中...】✍
-
- 笔试题1
- 笔试题2
- 笔试题3
- 笔试题4
- 笔试题5
- 笔试题6
- 笔试题7
- 笔试题8【⭐】
-
- 视频解说
- —————————————————【总结篇】 —————————————————
- ✍总结与提炼
- 推荐书籍阅读
———————————————【指针初阶 · 入门篇】 ———————————————
一、指针是什么?
1、指针、地址、内存
相信很多同学在学习了指针之后还不清楚指针是什么?
- 对于指针来说,它在内存中其实是中一个最小单元的编号,也就是地址。通俗一些说其实就相当于我们在酒店开了一间房,这个房间的编号就叫做地址,你也可以把它叫做一个指针,那么这间房间就只是这个酒店里面的一个编号而已
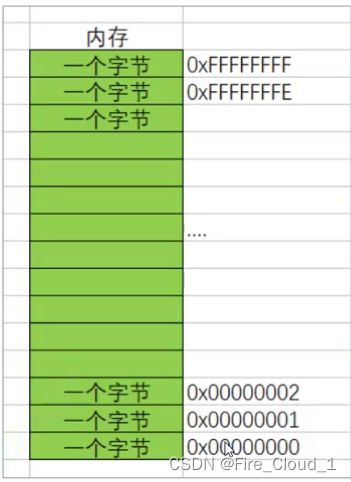
- 其实这么看来就可以说指针、内存、地址这三者其实是等价的
- 上面说到的是在内存中指针的说法,但是在我们学习C语言时,口头上所称的指针,通常指的是
指针变量,是用来存放内存地址的变量
【总结一下】:指针就是地址,口语中说的指针通常指的是指针变量
2、指针与变量
- 上面说到了指针变量,那我们就接着这个来做一个展开:当我们去定义出一个变量的时候,其实可以可以使用
[&]取地址操作符去取出这个变量在内存中的地址,然后存放到一个变量中,那此时这个变量就叫做【指针变量】 - 一起到VS中通过代码来看看
int a = 10;
int* pa = &a;
printf("%p\n", &a);
printf("%p\n", pa);
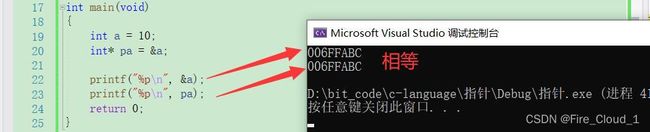
- 可以看到,通过将变量a的地址取出来给到变量pa,然后以
%p内存地址的形式去打印【pa】和【&a】的值就可以看到两个值是相等的,就可以说明pa里面确实存放了a的地址 - 在操作符章节的时候我有讲到过如何去看待
int* pa = &a,对于这个*来说值得就是pa这个变量是一个指针变量。它的前面的int表示的就是这个指针变量存放的是一个整型的地址,那它就是一个【整型指针变量】 - 这样看可能会比较抽象,我们可以通过调用【内存】的方式来观察一下
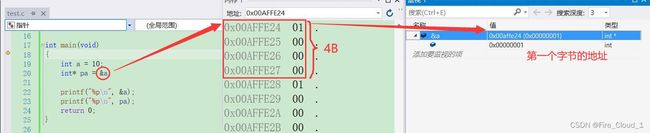
- 此时就可以发现变量a在内存中是占4个字节的,而
[&a]则是取出了首字节的地址,这么看相信你一定是非常得清晰了
- 不仅如此,除了整型变量的地址可以被存起来,字符型的地址也可以被存放起来,如下
char ch = 'c';
char* pc = &ch;
printf("%p\n", &ch);
printf("%p\n", pc);

- 那既然这个pc是一个变量的话,操作系统也会在内存中为其分配地址,我们可以去打印这个【指针变量】的地址看看

- 同样,我们可以通过调用【内存】的方式去观察一下,便可以看出char类型的变量在内存中确实只占一个字节
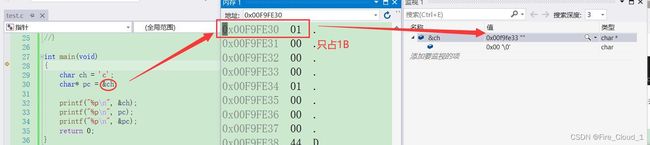
【总结一下】:指针变量,用来存放地址的变量。(存放在指针中的值都被当成地址处理)
3、解答:为何指针均为4个字节❓
上面我们讲到了一个指针可以存放一个变量的地址,明白了整型和字符型的变量在内存中所占的大小,那指针在内存中占多少空间呢?
- 这里我定义了三个不同类型的变量以及不同类型的指针变量去接收它们的地址,接着使用
sizeof()去计算了它们各自的地址
int main(void)
{
char ch = 'c';
int a = 10;
float f = 3.14f;
char* pc = &ch;
int* pa = &a;
float* pf = &f;
printf("%d\n", sizeof(pc));
printf("%d\n", sizeof(pa));
printf("%d\n", sizeof(pf));
return 0;
}
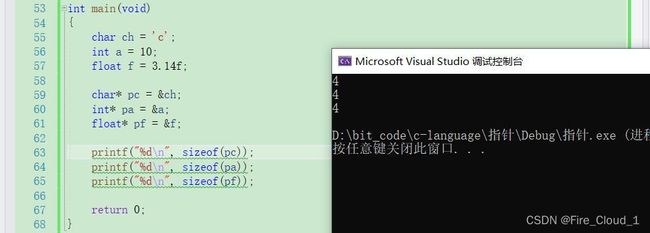
- 从运行结果可以看出每个指针变量的大小均为4个字节,这是为什么呢?这还要从机器中的【地址线】讲起
- 经过仔细的计算和权衡我们发现一个字节给一个对应的地址是比较合适的。对于32位的机器,假设有32根地址线,那么假设每根地址线在寻址的时候产生高电平(高电压)和低电平(低电压)就是(1或者0)

- 就是0101这样的存储方式,然后根据二进制的逢二进一去罗列出这32根地址线可以存储下多少地址,这里告诉你,一共是有232个地址可以存储
- 每个地址标识一个字节,那我们就可以计算出(232Byte = 4GB) 4G的空间进行编址
这里我们就明白:
- 在32位的机器上,地址是32个0或者1组成二进制序列,那地址就得用4个字节的空间来存储(1B = 8b),所以
一个指针变量的大小就应该是4个字节 - 那如果在64位机器上,如果有64个地址线,那
一个指针变量的大小是8个字节,才能存放一个地址
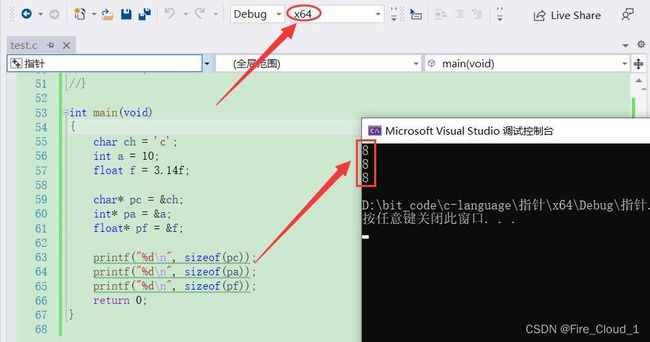
- 可以看到,若是我们将编译器放在64位系统上运行,最后的显示结果就为【8】,就可以验证我们上面的说法
【总结一下】:
- 指针变量是用来存放地址的,地址是唯一标识一个内存单元的
- 指针的大小在32位平台是4个字节,在64位平台是8个字节
二、指针的进一步理解
对指针有了初步的一个认识之后,接下去我们来进一步的认识指针有什么用?它存在的意义究竟是什么?
1、指针和指针类型
- 我们都知道,变量有不同的类型,整型,浮点型等。那指针有没有类型呢?
——> 准确的说:有的 - 在上一小节我介绍了指针可以存放其对应数据类型变量的地址,那对于指针本身来说这个类型究竟意味着什么呢?可以看到下面有各种各样不同类型的指针
char *pc = NULL;
int *pi = NULL;
short *ps = NULL;
long *pl = NULL;
float *pf = NULL;
double *pd = NULL;
这里可以看到,指针的定义方式是: [type + *]
- 那有同学一定会想,既然指针里面存放的都是变量的地址,而且每个指针的大小都是4个字节。那为何不把指针定义为一个统一的标准呢?就像【宏定义】一样定义出这个指针,完全不需要去考虑它需要存放什么变量类型的地址
- 例如就把指针统一地定义为【ptr】就会非常方便
这一点现在还说不清楚,当你看完指针存在的意义时就会明白这一切了
2、指针的解引用
然后先来说说有关指针解引用的问题
- 一样看到下面这段代码,指针pc里面存放的是ch的地址,指针pa里面存放的是a的地址,在上面我只讲到了指针和变量之间地址的关系,但是没有说到
地址和值的关系 - 那对于一个值来说它是存放在这块地址上的,既然我的这个指针存放了变量的地址,那可不可以访问到这块地址中存放着的内容呢❓
char ch = 'c';
int a = 10;
char* pc = &ch;
int* pa = &a;
- 此时就可以使用到
[*]解引用这个操作符了,便可以取到这块地址中所存放的内容,可以看到与其存放的变量中的值都是一样的
printf("ch = %c\n", ch);
printf("*pc = %c\n", *pc);
printf("a = %d\n", a);
printf("*pa = %d\n", *pa);

- 我们知道赋值运算符,若是一个变量的值你不想要了,那就可以修改这个变量的值,那既然指针可以访问到这个变量的值,可以不可以修改呢❓
- 也是一样,可以通过
[*]解引用的方式就可以做到
*pc = 'd';
*pa = 20;
- 通过运行结果就可以看到里面的值确实做了修改
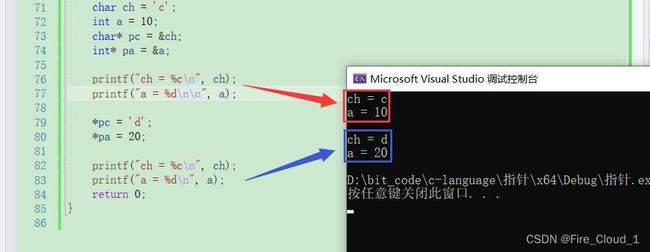
上面只是带你进一步了解了指针的更多作用,下面我们要真正地深入指针的挖掘,理解指针存在的意义了
⭐指针存在的意义1:访问字节的范围
好,我们来看如何去展示不同类型的指针究竟有什么它们各自存在的意义
- 首先我定义了一个变量a为它放入了一个值,要注意这个值它不是一个地址,而是一个十六进制的值,将其转换为二进制就可以发现刚好为32位,那一个整型变量可存放的数据大小也为4个字节32位
- 然后将这个变量的地址存放到一个指针中去,那这个指针存放的便是一个整型数据的大小,此时它就是一个【整型指针】。然后我通过解引用获取到了这块地址中所存放的内容,现在要去做一个修改
int a = 0x11223344;
int* pa = &a;
*pa = 0;
- 此时我们就可以通过内存块的变化来看看究竟
解引用修改值后内存中是如何变化的
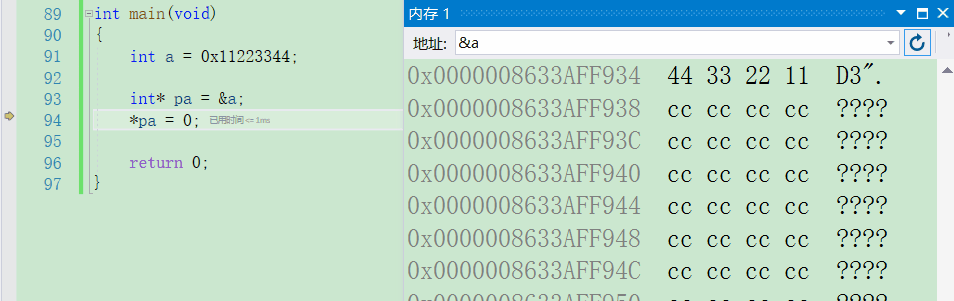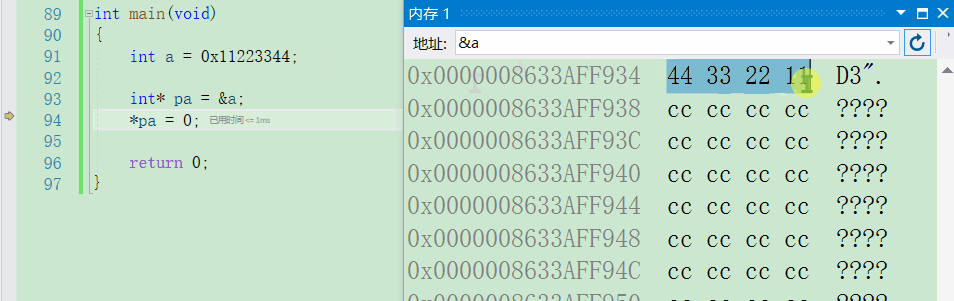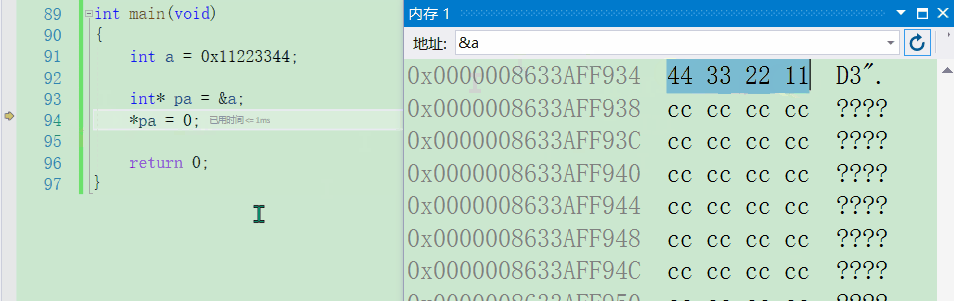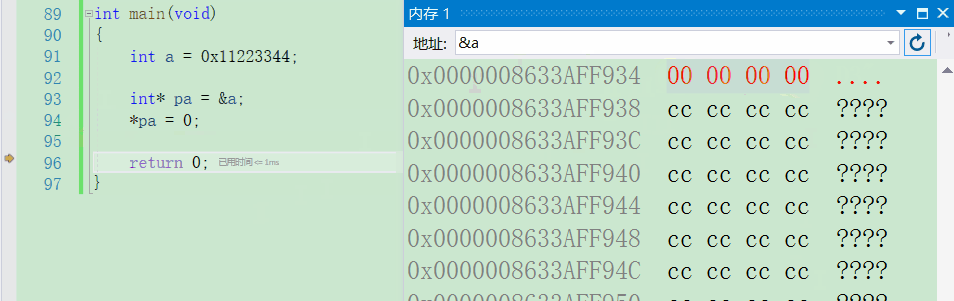
相信通过上面这幅图一定是非常清晰了
- 但是我为了要验证不同的指针类型究竟有什么不同的意义,所以我便将这个整型变量的地址存放到一个字符型的指针中去,然后再去修改这个整型变量的值,看看会发生什么变化
int a = 0x11223344;
char* pc = &a;
*pc = 0;

- 可以看到,只改变了一个字节,也就是8个比特位的长度,我这里一行显示的4个字节,在内存中是一行显示一个字节的
【总结一下】:指针类型 决定了指针在进行解引用操作的时候能访问几个字节【权限有多大】
-
char*的指针,解引用访问1个字节 -
int*的指针,解引用访问4个字节 -
double*的指针,解引用访问8个字节
⭐指针存在的意义2:类型决定步长
除此之外,不同类型指针存放的意义就是它们移动的步长不一样
- 通过下面的代码可以看到,两个不同类型的指针都接受了整型变量的地址,我们知道指针是可以进行偏移的,那使这两个指针都向后偏移1会发生怎样的变化呢?
int a = 10;
int* pa = &a;
char* pc = &a;
printf("pa = %p\n", pa);
printf("pa + 1= %p\n\n", pa + 1);
printf("pc = %p\n", pc);
printf("pc + 1= %p\n", pc + 1);
- 很明显可以看出,对于整型指针来说,
+1会向后偏移4个字节;而对于字符型指针来说+1会向后偏移1个字节。这其实就可以看出不同指针其实还是有着它们的不同意义

【总结一下】:指针类型 决定了指针的步长(向前 / 向后走一步都多大距离)
-
char*的指针 + 1【跳过一个字符型,也就是向后走1个字节】 -
short*的指针 + 1【跳过一个短整型,也就是向后走2个字节】 -
int*的指针 + 1【跳过一个整型,也就是向后走4个字节】 -
double*的指针 + 1【跳过一个浮点型,也就是向后走8个字节】
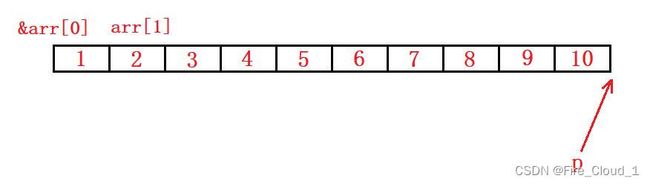
小练习:初始化数组
通过了解了上面有关不同指针类型的概念之后,相信你对指针一定能够有了一个自己的理解,接下去我们来做一个习题练练手
- 现在我初始化了一个数组,大小为10,首先对其所有元素初始化为0。拿一个指针变量去接收一下这个数组的首元素的地址,这样来看就可以通过这个指针访问到这个数组了
int arr[10] = { 0 };
int* p = arr;
int sz = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < sz; ++i)
{
*p = i + 1;
p++;
}
- 通过一个循环去遍历这个数组的大小,然后使用
*解引用便可以访问到当前循环遍历的那个元素,就可以利用循环变量做一个初始化了,然后p++每次让指针向后偏移一个元素,便可以初始化完所有的数组元素了
相信我这么说你还有点懵,没关系,可以通过画图来分析一下
- 首先看到指针p指向数组的首元素地址,此时使用
*p便可以访问到这块地址上的元素,即可以做修改,此时【i = 0】,i + 1便是1,所以这块地址中的内容会被初始化为1,接着p++,接着p++跳过4个字节的大小,因为它是一个整型指针,便来到arr[1]这块空间的地址

- 同理,来到数组第二个元素的地址后,依旧可以通过
*p访问到这块地址中的内容做一个修改,然后指针p会向后移动4个字节的大小,刚好跳过一个数组元素,因为这是一个整型数组,数组中的每一个元素都是整型的
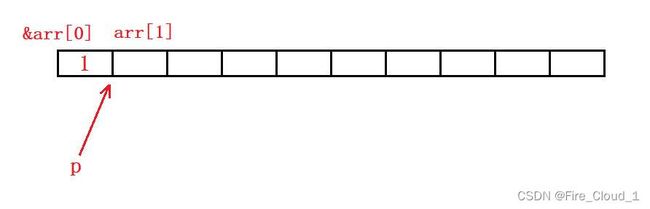
- 最后,当【i】遍历完了整个数组的大小之后也通过这个指针初始化完了数组的所有元素,此时指针也移动到了数组最后一个元素地址
- 来看一下运行结果

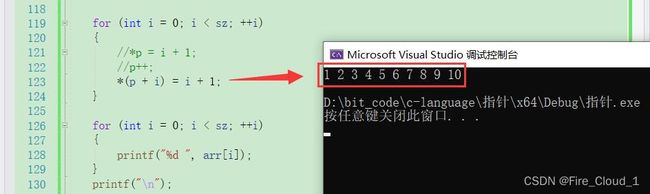
- 当然,为了简洁方便,我们也可以将初始化元素和指针的后移动同时进行,也就是下面这种写法
for (int i = 0; i < sz; ++i)
{
*(p + i) = i + 1;
}
p + i访问到了让当前数组位置所在地址,然后通过*解引用便访问到了这块地址所在内容,然后一样的【i + 1】便可以进行一个修改,将其放在循环里就可以使得每次i的值在变化的同时带动指针的偏移,最后也是可以完成数组的初始化
三、野指针
概念: 野指针就是指针指向的位置是不可知的(随机的、不正确的、没有明确限制的)
1、野指针成因
对于野指针相信大家在使用指针的时候都会遇到,可能也有同学听说过它是一个很危险的东西,而且在写代码的时候一不小心就使一个指针变成了野指针,接下去我将出现野指针的情况做一个罗列
① 指针未初始化
- 首先第一种就是这个指针未初始化的情况,也就是你定义了整型指针,但是呢并没有在系统中为其分配一块空间,此时这个指针p就指向了内存中一块随机的地址,此时这个指针就叫做【野指针】
- 然后在这个时候又使用
*p访问到了这块地址中的内容,并对其做一个修改,那么此时就会出现问题
int main(void)
{
int* p;
*p = 20;
return 0;
}
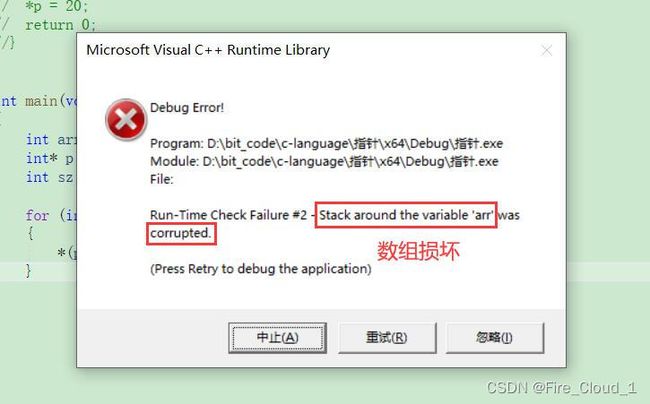
② 指针越界访问
- 第二种情况就是指针越界访问,用我们刚才那个关于初始化数组的小练习,此时我在遍历这个数组的时候在边界多访问了一次,那此时就会造成一个越界访问
- 若是指针p访问arr数组内的地址是没有问题的,因为这些地址是操作系统已经分配给我们的,但若是多访问一个位置的话其实这块地址就是一个随机的地址,那这个指针也就成了【野指针】
int main(void)
{
int arr[10] = { 0 };
int* p = arr;
int sz = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i <= sz; ++i)
{
*(p + i) = i + 1;
}
}
- 可以看到编译器报出了错误❌
③ 指针指向的空间释放
- 其实这可以联系我们的生活实际,比如说我在酒店里开了一间房,房间的房号叫302,此时就想要叫我的好兄弟明天也一起来住(doge),于是就告诉了他在XX酒店XX房间号。但是呢我只付了一个晚上的钱,到了第二天早上便只好退房了。
- 但是到了第二天张三却真的拿了他的行李箱过来住了,可以呢酒店前天说这间房已经退了不可以住了,不过张三执意要住,可是这间房呢已经退换回去了,还给酒店了,张三没有了使用权,此时他的这个行为就可以被称为是非法访问
- 还有另外一种空间释放指的是在堆区动态申请内容后释放,要使用到
free(),这一块就不在这里讲了,后面介绍到动态内存规划的章节再做细讲,如果想了解的可以看看我的这篇【链表】文章 ——> 带你从浅入深真正搞懂链表
2、如何规避野指针
知道了会产生野指针的情况,那我们就要针对这些情况去做一些风险规避
1. 指针初始化
- 这一块很简单,只要是定义了一个指针,那就千万别忘了对它进行一个初始化,无论是让其保存一个地址或者是置为空都可以
- 其实可以把野指针看作是一条野狗,若是让这个指针保存一个地址也就是有个主人管住它了,那也就不会产生危险;将其置为空其实就使用链子把它拴起来了,也不会有问题
int a = 10;
int* pa = &a;
char* pc = NULL;
2. 小心指针越界
- 这一块的话自己小心和注意一点就行
3. 指针指向空间释放,及时置NULL
- 这个我在前面说起过,对于从堆区中动态申请的一块空间现在要将其释放了,也就是还给操作系统,但是呢你初始化后的指针还是指向堆区中的这块地址,只是它被释放了而已,此时就要让这个指针指向空(也就是NULL),这样就可以防止随意操作一块随机地址的风险了
4. 避免返回局部变量的地址
- 这一点我们上面也看到过了,若是返回一个在函数中创建的局部变量,此时外界虽然是接受到了这个变量的地址,但是这个变量的作用域只是在这个函数内部,除了作用域就销毁了,若是外界有一个指针接受了这个随机的地址,然后再去操作它就非常危险了
- 这一点可以看C++引用章节的传引用返回部分 ,有细说到为何不能返回局部变量
5. 指针使用之前检查有效性
- 如果你还是担心自己的程序会出现野指针的问题,那么就要在操作一个指针的时候检查一下这个指针是否合法,也就是像下面这样在操作这个指针pa的时候判断一个它是否为空
int a = 10;
int* pa = &a;
if (pa != NULL)
{
printf("%d\n", *pa);
}
- 可以看到,若是不对其进行一个判断,然后这个指针又是一个空指针的话,就会造成一个很大的问题

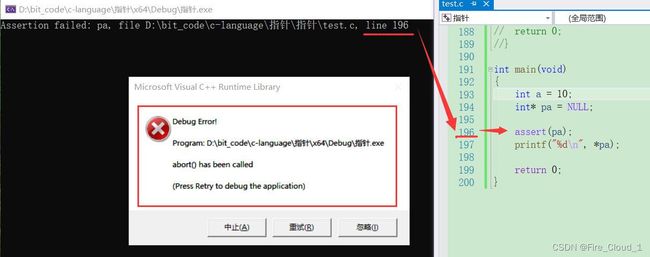
- 当然,如果你觉得这样写条件判断比较麻烦的话也是有其他简便的办法的,就是使用
assert()进行一个断言。这种方式的话就比较粗暴一些了,直接给你弹出一个警告框
int main(void)
{
int a = 10;
int* pa = NULL;
assert(pa);
printf("%d\n", *pa);
return 0;
}
- 也就是像下面这样,还会告诉具体哪行出现了错误,当然也就是你写断言的那样
四、指针运算
在了解了许多有关指针的基本知识和指针的使用技巧后,我们就要使用指针去做一些运算的工作,一起来看看
1、指针与整数的运算
- 首先通过下面这段程序来看看指针和整数之间的运算
- 首先是定义了一个float类型的数组,然后定义了一个
float类型的指针。不过在一开始定义出来的时候没有进行一个初始化。我们循环内部对其进行了一个初始化,首先让其指向这个数组的首元素地址,再通过for循环去遍历这个数组 - 主要来看的就是就是循环的内部这个指针是如何变化的,
*vp++这个表达式有两个操作符,一个是[*]解引用操作符,一个则是[++]递增操作符,如果你对操作符优先级了解的话可以知道【++】是比【*】的优先级来得高的,所以它会先进行一个运算,可是呢可以看出这是一个后置++,所以这个表达式所操作的还是vp当前所指向的这块地址。那么解引用取到的就是当前这块地址所存放的内容,可以看到右边是将其修改为0
#define N_VALUES 5
int main(void)
{
float values[N_VALUES];
float* vp;
//指针+-整数;指针的关系运算
for (vp = &values[0]; vp < &values[N_VALUES];)
{
*vp++ = 0;
}
}
- 程序的思路和我们上面那个小练习初始化数组是一样的,这是这里的运算表达式稍微复杂一些而已

- 到最后初始化完成后也就是指向这一块地址

- 接着通过打印这个数组来看看是否初始化完了这个数组中的所有元素
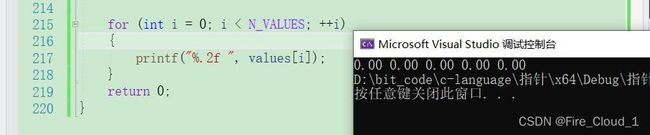
2、指针的关系运算
- 好,我们继续来看指针的关系运算。与上一段类似,所以一些初始化的代码就不给出了
#define N_VALUES 5
for (vp = &values[N_VALUES]; vp > &values[0];)
{
*--vp = 0;
}
- 可以看到,在这个for循环中,指针vp首先是指向数组的最后一个元素的后一个位置,那有同学问到这不是指针访问越界了吗?【野指针】!!!!
- 不要激动其实这不算是越界访问,而只能说是【越界指向】,这个指针就是指向了一下这块地址,但是呢并没有对这块地址进行任何的操作,那也就不会有危险。
- 其实对于野指针来说最大的危险就是一个指针指向了一块没有被操作系统分配过的、随机的地址,而且还去访问、修改这块地址中的内容
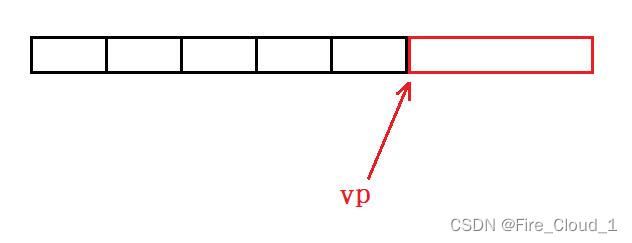
举个生活中的小案例:若是某一天你在银行前面溜达、经过一下,但是呢银行的保安说你是来抢银行的,那这个时候你一定不乐意了。那此时就可以将自己想作是那个指针,然后银行就是那个随机的地址,你就是看了看这块随机的地址,但是并没有去动它,是不会存在危害滴!
好,题外话,我们回归代码
- 来解释一下
*--vp是什么意思,前置- -代表的就是让这个指针先前移一个位置,也就是让它从越界的那个位置回到存放最后一个元素所在的位置,此时也会不会造成越界访问了,然后再使用*解引用操作符访问到这个地址的内容,同样进行一个初始化 - 此时数组就被初始化好了

可是呢,还是有同学会觉得这样去写代码不是很直观,毕竟前置- -的这个代码阅读性并不是很高,因此就将数组的初始化修改成了下面这样
for (vp = &values[N_VALUES - 1]; vp >= &values[0]; vp--)
{
*vp = 0;
}
- 这么看起来的话其实就非常直观了,大家应该是都可以很轻松地看懂,指针从数组的最后一个位置开始遍历,直到遍历到第一个元素的地址为止,指针的偏移也放到了for循环中,而不是放在循环体的表达式里
- 但是呢这样的判断会使得指针vp最后偏移到了
数组的最前端,也会产生一个越界的情况

实际在绝大部分的编译器上是可以顺利完成任务的,然而我们还是应该避免这样写,因为标准并不保证它可行
【标准规定】:
- 允许指向数组元素的指针与指向数组最后一个元素后面的那个内存位置的指针比较,但是不允许与指向第一个元素之前的那个内存位置的指针进行比较。
- OK,我知道你已经晕了,来解释一下,其实很好理解,就是对我们上面讲过的有关指针运算的两道题目做一个总结罢了。一句话来说就是【
指针可以越界指向数组最后一个元素后面的那个位置,但是不可以指向第一个元素前面的那个位置】,不要问我为什么,因为人家标准就是这么规定的,你就不要越界访问那个位置就可以了
3、指针与指针的运算
接下去我们来说说有关指针和指针之间的运算,题目的情景我们之前在讲函数递归的时候有说起过
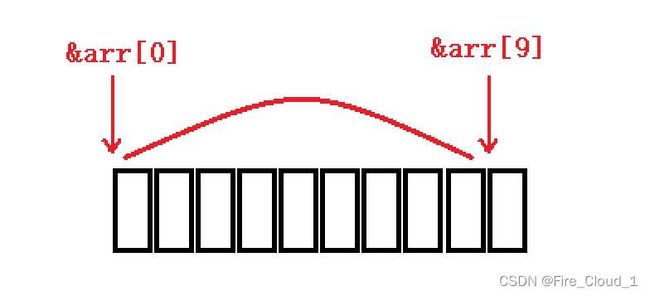
- 首先我们来做个引入,请你算算下面这段代码最后输出的结果为多少
int main(void)
{
int arr[10] = { 0 };
printf("%d\n", &arr[9] - &arr[0]);
return 0;
}
- 答案是9,你算对了吗❓开始我们有讲到过【地址】其实就是【指针】,那么对于两个地址之间的差值其实就是两个指针之间的距离,简单点说那也就是
&arr[9]自&arr[0]偏移了9个位置,所以它们之间的元素个数就是【9】
- 不过两个指针的相减,需要它们指向同一块连续内存空间,像下面这种情况就是不对的,因为int类型的变量和char类型的变量在内存中不是连续存放的,它们在内存中的距离是不确定的,是随机的
int a = 10;
char ch = 'c';
printf("%d\n", &a - &ch);
好,接下去来看看指针与指针之间的运算
- 这里是要去求解一个字符串的长度,我们可以使用自带的库函数
strlen()、自定义函数变量累加、递归,在本文中,我还要再介绍一种方法,也就是使用【指针】 - 思路很简单,函数形参接受了一个数组的首元素地址,在内部拿一个字符型指针接受一下,然后通过这个字符型指针去遍历这个字符串,我们知道对于一个字符串来说以
\0作为结束的标志,因此只需要每次解引用判断是否遍历到\0即可 - 最后当遍历到字符串结尾的时候将末尾的指针与形参接受的首元素地址,也就是指向首元素地址的指针,进行一个相减,就可以获取到这个字符串的长度了
int my_strlen(char* str)
{
char* pc = str;
while (*pc != '\0')
{
pc++;
}
return pc - str;
}
五、指针和数组
关于指针聊了这么久,接下去我们看看指针和数组之间有什么联系,如果想了解数组相关知识的,可以看看这篇文章——> 窥探数组设计的种种陷阱
我们看一个栗子
- 在数组章节就有讲起过,数组名就是首元素地址,验证一下将它们的地址都打印出来可以发现是相同的
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,0 };
printf("%p\n", arr);
printf("%p\n", &arr[0]);
return 0;
}

- 因此我们就可以将数组名作为数组的首元素地址给到一个指针,通过这个指针就可以去遍历这个数组,因为
arr[i]和*(p + i)都可以访问到数组中下标为i这个元素,因此&arr[i]和p + i所访问的地址也是一样的
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int* p = arr; //指针存放数组首元素的地址
int sz = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < sz; i++)
{
printf("&arr[%d] = %p <====> p+%d = %p\n", i, &arr[i], i, p + i);
}
return 0;
}
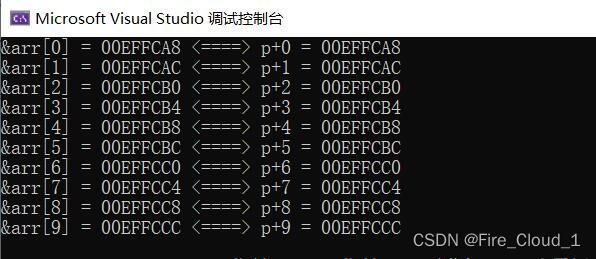
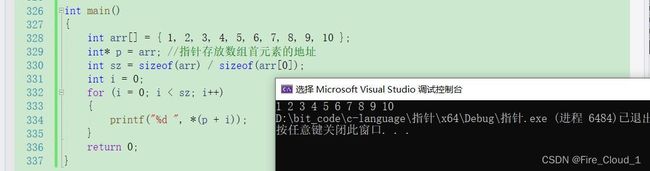
- 既然
&arr[i]和p + i所访问的地址也是一样的,那我们就可以通过*(p + i)去访问这个数组中的所有元素
✒【总结一下】
- 数组和指针不是一个东西,数组能够存放一组数,是一个连续的空间,它的大小取决于
数组元素的类型和个数;而指针则是用来存放地址,它的大小取决于你当前编译器所运行的环境,是32位 / 64位 - 数组和指针的联系在于:数组名是首元素地址,把数组名给到一个指针变量之后,可以通过这个指针变量来访问这个数组中的所有元素
六、二级指针
好,看完了上面的这些内部,你对指针的一些基础算是入门了,接下去我们来做一些提升,学习一下二级指针
1、变量、指针、二级指针
- 通过上面的学习可以知道,对于一个指针变量来说,可以接受一个变量的地址,那么这个指针其实就叫做【一级指针】,那我们知道对于一级指针来说也是有地址的,我也带你看过了,那现在我想做的一件事就是
把一个一级指针的地址存放到一个变量里 - 下面这个
pp就是一个二级指针,它存放有一级指针p的地址
int a = 10;
int* p = &a;
int** pp = &p;
- 现在我通过下面这张图为你做一个讲解。首先变量a的值为10,地址为
0x00befd90,然后一级指着变量p存放了变量a的地址,所以可以说它指向a。对于变量p来说,它也有自己的地址,为0x00befd84,二级指针变量pp里则是存放了这个地址,所以可以说它指向p

- 然后来解释一下有关指针变量前面的一些星号:对于变量p,它前面的
*表示它是一个指针变量,【int】则表示它保存的一个int类型变量的地址,就说它指向一个整型变量 - 对于变量pp,它前面的
*表示它是一个指针变量,【int *】则表示它保存的一个int*类型变量的地址,就说它指向一个指针变量
万不可以把二级指针理解为就是前面两个星号这么简单,要将指针和地址之间的关系联系起来
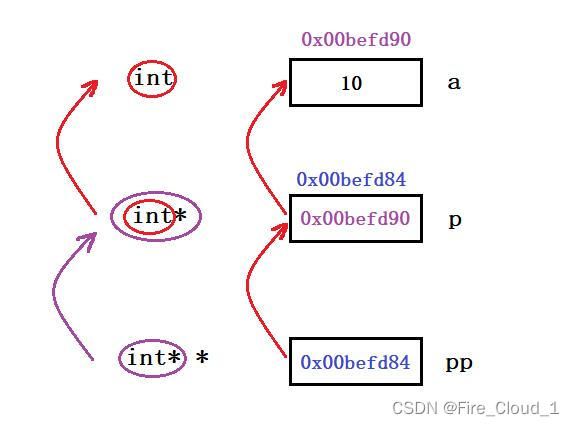
肯定还有同学没有理解,我通过一个生活小案例来说明一下
- 其实【指针与地址】的关系就和【钥匙与保险箱】的关系是一个道理,就比如说这个二级指针pp,它就是一把钥匙,它里面存放了一级指针p的地址,所以可以顺利地找p这个箱子,这样的话就可以通过这把钥匙打开这个箱子
- 但是这个箱子里面呢存有一把小钥匙,也就是一级指针p,它里面呢存放有变量a的地址,通过这把钥匙你就可以找到变量a,然后便可以通过新找到的这把钥匙打开变量a这个箱子,里面就有一个数值为10,它就是你要找的那个宝藏【看过极限挑战的读者应该都明白】

2、有关二级指针的运算
对二级指针有了一个初步的了解之后,我们来看看有关二级指针的一些运算
通过对二级指针进行一次解引用,可以获取到一级指针变量,重新改变指向
通过对二级指针进行两次解引用,可以获取到一级指针所存放的变量,重新改变值
- 看到下面这段代码,我新定义了一个变量b,然后可以看到通过
*pp对二级指针进行了一个解引用的操作,这就获取到了一级指针变量p,此时我将变量b的地址存放到它里面去,这也就改变了指针p的指向
int a = 10;
int b = 20;
int* p = &a;
int** pp = &p;
*pp = &b;
- 我们可以通过DeBug调试来看看【上面是变化前,下面是变化后】

- 可以观测到,一级指针变量p存放的地址以及值都发生了改变,而且二级指针pp里所存放的一级指针变量p也发生了变化。这就是一次解引用可以实现的操作
接下去我们来看看通过两次解引用可以做到什么
- 看到如下代码,我通过两次解引用获取到了变量a的值,然后对其做了一个修改
int a = 10;
int* p = &a;
int** pp = &p;
printf("a = %d\n", a);
**pp = 200;
printf("a = %d\n", a);
- 通过运行结果就可以看出a的值确实发生了变化,执行前和执行后的值有所不同

- 通过DeBug调试也是可以看出因为pp里面存放有p的地址,而p里面又存放有a的地址,我们可以将这个二次解引用做一个分解。第一次解引用首先找到一级指针p,然后再进行一个解引用便找到了变量a,此时就有了一个【修改的权限】

通过以上的叙述,相信你对二级指针有了一个初步的认识和理解,在之后的【指针进阶 · 提升篇】 中我还会再详解二级指针
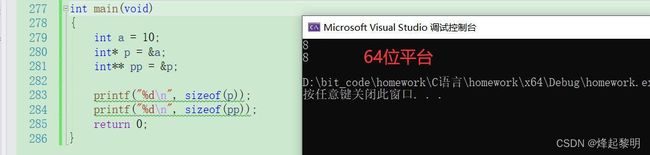
这里补充一点,上面说到只要是指针均为4个字节,那对于二级指针来说呢?也是4个字节吗?
- 可以看到,的确如此,无论是一级指针还是二级指针,其大小并不取决于指针本身的类型,而是取决于当前这段代码所处的平台,在32为平台下均为4个字节,在64位平台下均为8个字节

以上就是有关【指针初阶 · 入门篇】的所有内容,你学废︿( ̄︶ ̄)︿了吗
———————————————【指针进阶 · 提升篇】 ———————————————
学习完了指针初阶后,相信你对指针一定有了一个初步、清晰的认识。下面我们将进入【进阶】部分的学习,难度会逐渐上升↑ Are you ready?
一、字符指针
1、指针存放单字符
在初阶部分,我们有学习到了不同的指针类型,其中就包含一种叫做【字符指针】,我这里再重点拎出来说说
- 所谓字符,也就是这个指针它指向一个字符
char ch = 'w';
char* pc = &ch;
- 那既然这指针指向了这个字符,即存放了这个字符的地址。我就可以通过
*解引用去访问到这个地址中的内容,然后去进行一个修改
*pc = 'x';
运行之后可以看到字符ch的内容确实发生了变化

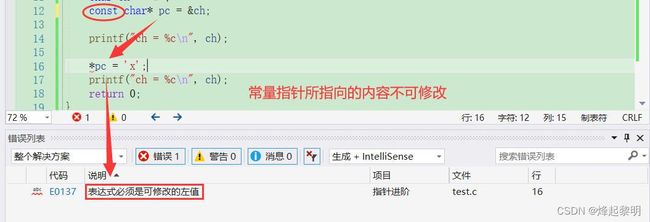
- 但若是我在初始化指针变量
pc的时候在前面加上一个【const】作为修饰,此时还可以像上面这样去修改吗
const char* pc = &ch;
通过运行结果可以看出是不可以的,加上【const】作为修饰后pc就为常量指针,其所指向的内容是不可以修改的,具体可以看看常量指针和指针常量的感性理解
2、指针存放字符串
对于字符来说,不仅接收单个字符,还可以一个字符串的首元素地址,我们来看看
char* ps = "abcdef";
- 可以看到通过
*解引用访问到的是该字符串的首字符,因为指针里面指存放了它的地址,这就和一个整型指针里面存放了一个数组的首元素地址是同样的道理

- 不过有很多通过就会将此理解为把整个字符串
abcdef存放到字符指针ps中,这其实是不对的,我们通过画图的方式来理解一下

不过对于上面这种写法其实还有一种缺陷,因为字符串是一个常量,那对于常量而言是不可修改的,但是我们却将其地址给到了一个字符型指针,那此时就可以通过循环的方式解引用修改整个字符串,这就不合乎逻辑了,所以在初始化字符指针
ps的时候应该在前面带上一个【const】
- 其实就和上面存放单个字符的字符指针是一个意思
const char* ps = "abcdef";
3、一道剑指offer的面试题
- 下面是一道剑指offer中有关【字符指针】的面试题,放在这里作为讲解。接下去我想问:在两组字符串进行比较后输出的结果为多少
int main()
{
char str1[] = "hello bit.";
char str2[] = "hello bit.";
const char* str3 = "hello bit.";
const char* str4 = "hello bit.";
if (str1 == str2)
printf("str1 and str2 are same\n");
else
printf("str1 and str2 are not same\n");
if (str3 == str4)
printf("str3 and str4 are same\n");
else
printf("str3 and str4 are not same\n");
return 0;
}
结果如下:

那有的同学就很疑惑,
str1和str2明明就是一样的,为何输出打印的结果是【are not same】呢?
- 我们在操作符章节有讲到
==这个运算符,若只是两个普通变量之间的比较,用它就可以了,但是对于两个字符串之间的比较,可不能使用这个,而要用库函数中的strcmp,具体的规则可以查看官方文档,后期会出专门的文章做讲解 - 使用
==运算符进行比较的时候并不是比较的两个字符串的内容,而是地址。那它们在定义的时候编译器分别为它们分配了各自的空间,所以它们的空间是独立的,内存地址也是不一样的。
那有同学问:那str3和str4又怎么解释呢?
- 还记得上面讲到过的【字符串是一个常量】这个概念吗,对于常量而言,是存放在内存中的只读数据区,也就是代码段,常量一般都存放在这个区域中,里面还存放有代码编译出来的一些指令,对于指令是不可以修改的,可以看看 C/C++内存分布
- 那对于这些常量字符串来说在内存中只会保存一份,也就是说str3和str4都指向内存中的同一块空间,那它们的地址就是相同的,所以输出的结果就是【are same】
二、指针常量与常量指针
【引入】
- 首先来看看下面这段代码,首先我定义了一个变量num为10,然后又对其进行了一个赋值修改,打印出来之后就是修改之后的值【相信这是最基本的认识】
int main(void)
{
int num = 10;
num = 20;
printf("num = %d\n", num);
return 0;
}

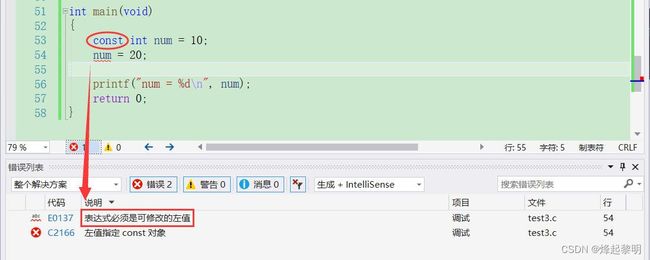
- 但若是我可以修改num值的话,别人也可以修改了,这就没有了安全性。所以我想给它加上一把锁使得它无法被修改,这里介绍一种C语言中的关键字【const】,这个我在初识C语言也有说到过,若是我们在定义变量的时候在前面加上一个
const做修饰,此时这个变量就会变成【常量】 - 这个就和Java中的 final关键字 是一个道理,若是加上了这个关键字做修饰之后,就要在定义的时候对其进行一个初始化,并且后面不能去修改它的值
const int num = 10;
- 可以看到,在加上
const常进行修饰之后,这个变量就无法被修改了,若是有人想要去修改的话编译器就会报出警告⚠
以上均为引言,接下去我们来说说有关【常量指针】和【指针常量】之间的区别
【常量指针】
1、介绍与分析
- 上面看到,因为在定义num的时候前面加上了
const常的修饰,就使得它变成了一个常量,无法被修改,在指针初阶章节,我有介绍过可以将一个指针进行解引用去修改这个指针所指向那块地址的值
int* p = #
*p = 20;
- 可以看到,确实可以对其进行一个修改

- 那此时这个num的安全性就又降低了,所以我想再做制裁,使得指针也无法对其解引用进行一个修改
- 那么又需要使用上面所说的
const修饰符,也是和修饰num一个道理,只需要在前面加上一个【const】作为修饰即可
const int* p = #
- 可以看到,此时我们通过指针解引用的方式也无法对其进行修改❌
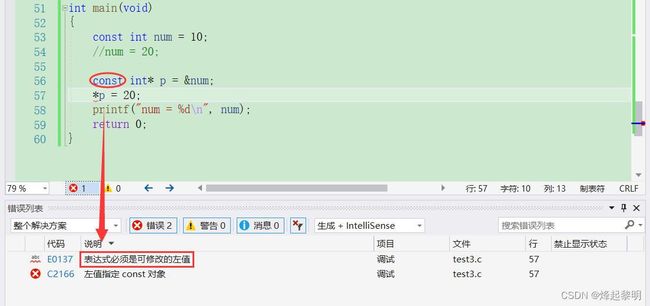
- 虽然是不可以通过指针解引用去修改这个指针所指向的值,但是可以去修改这个指针的指向,令其重新指向一个变量的地址,这是合法的
const int num = 10;
//num = 20;
int num2 = 20;
const int* p = #
//*p = 20; //err
p = &num2;
- 不过原理还是一样的,我们无法通过这个指针进行解引用去修改它所指向的值
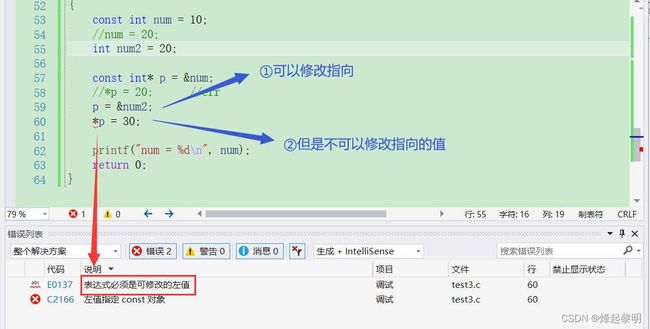
2、小结与记忆口诀
以上所描述的就是【常量指针】,一起来总结一下
- 总结:对于常量指针而言,是将【const】放在
*的左边,表示的是指针所指向的内容不能通过指针来修改,但指针变量本身可修改 - 口诀:常量指针所指向的是一个常量,不能修改;但是指针本身不是常量,可以修改
【指针常量】
知道了什么是【常量指针】,接下去让我们来看看什么是【指针常量】
1、介绍与分析
- 刚才我们将
const放在*的左边,现在我们换个地方,将它放在*的右边试试
int* const p = #
- 此时若再去做这两步操作的时候你就会发现和【常量指针】完全不同,可以通过指针解引同去修改指向的值,但是无法再次修改指针的指向
*p = 20;
p = &num2; //err
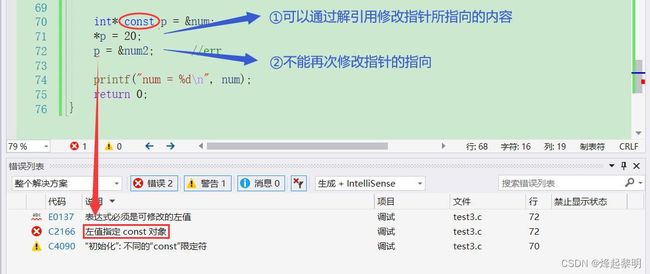
2、小结与记忆口诀
以上所描述的就是【指针常量】,一起来总结一下
- 总结:对于指针常量而言,是将【const】放在
*的右边,表示的是指针变量本身的指向不能修改,但是指针指向的内容可以通过指针来修改 - 口诀:指针常量这个指针本身就是一个常量,不能修改;但是指针所指向的内容不是常量,可以修改
一份凉皮所引发的故事
可能还是有同学对它们之间的关系不太理解。没关系,我们通过一个生活中的场景来介绍一下
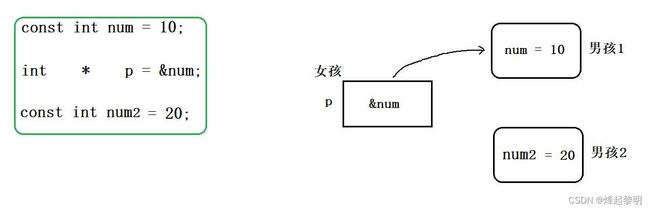
- 现在这里有三行代码,有一个常量num指针p里面保存了它的地址,还有一个常量num2
- 我们假设这个
指针p为一个女孩,num为一个男孩,他是这个女孩的男朋友。有一天男孩陪女孩去逛街,女孩看到路边有人在卖凉皮,所以就想要男孩给他买一份凉皮吃,可是呢男孩身上只有【10块钱】,若是给女朋友买了凉皮自己就没钱用了,于是说:“不行,不给你买,凉皮有什么好吃的”

- 于是这个时候女孩就生气了,就对男孩说:“一份凉皮都不舍得给我买,还算是我男朋友吗?分手!”,于是看另一个男孩还不错,就想去找另一个男孩【他身上有100块钱】
- 于是这个时候男孩就不乐意了,好不容易追到的女朋友(不是靠钱),怎么能说分手就分手呢,不能分。此时它就做了一个动作:在这个操作符
[*]的前面加上了const作为修饰符,我们来回顾一下前面的知识

- 这里的
*p = 0就相当于是指针通过解引同让num = 0,那指的就是让男孩变得身无分文;这里的p = &num2指的就是重新修改指针p的指向,使其指向另一个值的地址。这就是【常量指针】
- 此时男孩意识到事情的严重性,那个男的身上这么有钱,万一被它拐走了。想了想还是去给她买吧,一份凉皮罢了,就和女孩说:“行行行,给你买,但是你不可以换男朋友”。此时他就又做了一个动作:在这个操作符
[*]的后面加上了const作为修饰符,去掉了前面的const

- 同理,这里的
*p = 0就相当于是指针通过解引同让num = 0,那指的就是让男孩变得身无分文;这里的p = &num2指的就是重新修改指针p的指向,也就是换一个男朋友。这就是【指针常量】
建议广大女性读者选择第二种男朋友,若是想下面这样的,就直接分手吧
- 在
[*]的前后都加上了const修饰符,那么既无法通过指针去修改所指向的值,也无法修改指针的指向,虽然这使代码变得非常安全,但在还是没有这个必要╮(╯▽╰)╭ - 要想一个男朋友连吃的都不给你买,而且还不准你换男朋友,强行霸占你这种情况还是赶紧分手吧!
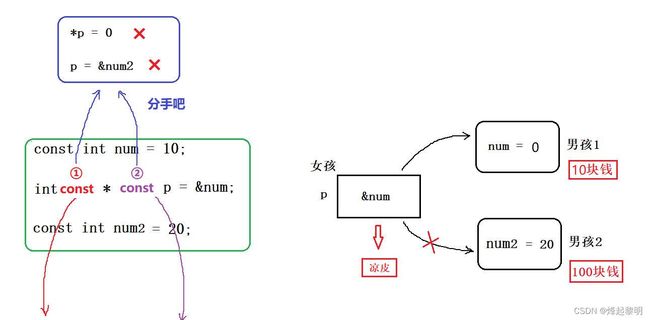
【总结一下】:
- 对于【常量指针】而言,是将const放在
[*]左边的,指针所指向的内容不能通过指针来修改,但指针变量本身可修改 - 对于【指针常量】而言,是将const放在
[*]右边的,指针变量本身的指向不能修改,但是指针指向的内容可以通过指针来修改
三、指针数组与数组指针
本模块我们来介绍指针数组与数组指针之间的区别
【指针数组】
首先我想问你一个问题:指针数组是一个指针还是一个数组呢?
1、概念明细
- 好,解答一下上面的问题,对于【指针数组】来说,它是一个
数组,而不是指针
int arr1[5]; //整型数组 - 存放整数的数组
char arr2[5]; //字符数组 - 存放字符的数组
int* arr3[5]; //指针数组 - 存放指针的数组
- 来看一下上面这三个数组的定义
- 对于
arr1,他是一个整型数组,它里面存放的都是整数; - 对于
arr2,他是一个字符数组,它里面存放的都是字符; - 对于
arr3,他是一个指针数组,它里面存放的都是指针;
- 对于
- 通过这么的对比相信你对【指针数组】有了一初步的概念,它也是一个数组,里面放的都是指针
下面两个模块我将带你来回顾一下数组中的相关知识
2、数组地址偏移量与指针偏移量
- 首先对于一个数组而言,我们如果可以得到它的首元素地址,然后通过这个地址就可以顺藤摸瓜就可以获取到后面的所有元素
- 但是光这么直接用
arr[0]来访问太累了,不妨我们将数组的首元素地址给到一个指针变量,让它保存下这个地址,然后让它逐步地向后移动。如果对指针还不是很了解的看看这篇文章——> 底层之美,莫过于C【1024,从0开始】先去了解一下什么是指针
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int* p = &arr[0];
- 可以看到,指针变量里面存放着的是数组arr的首元素地址,那我们现在要通过这个指针变量去访问到后面的所有元素该怎么做呢?
- 首先我们考虑先访问到第二个元素,要访问到一个元素首先考虑找到这个元素所在的地址,
p指针第一个元素所在的地址,那么p + 1便是指向2所在元素的地址,那要访问到这个地址上所在的内容,那就要使用到*这个符号,对这块地址进行解引用*(p + 1),此时就可以访问到2这个元素了。那找3,找4也是一样的,只需要让这个指针向后偏移即可,所以我们可以通过循环去找,访问第i个元素便是*(p + i) - 可能有些同学还是不太理解,没关系,我们通过代码来验证一下
for (int i = 0; i < 10; ++i)
{
printf("%p == %p\n", p + i, &arr[i]);
}
printf("\n");

- 可以看到,无论是对于
p + i还是&arr[i],它们每次所访问的地址都是一样的,这其实也就意味着指针变量p在偏移的过程中相当于在代替数组首元素地址向后偏移
有了这些知识作为铺垫,我们就可以去尝试访问数组中的所有内容了
因为一维数组是一块连续的存储空间,所以我们只要得到这个数组的首元素地址。就可以通过p + i这样的方式找到它之后所有元素的地址,并且把他们地址进行解引用便能访问到数组中的所有元素
int main(void)
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int* p = &arr[0];
for (int i = 0; i < 10; ++i)
{
printf("%d ", *(p + i));
}
printf("\n");
return 0;
}
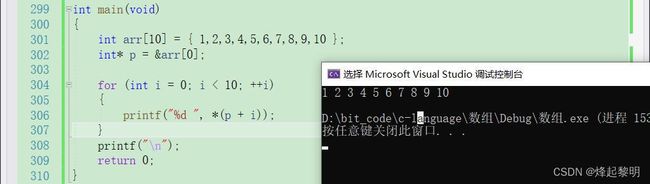
- 可以看到,通过将数组的首元素地址给到指针变量p,然后再使这个指针变量一位一位地向后偏移,每次偏移一个元素即4个字节,第i个元素的地址即为
p + i,而当我们要去访问这个地址的内容时,直接对其进行解引用即可*(p + i),然后便可以看到数组中的十个元素都被打印出来了
3、指针变量与数组名的置换【✔】
- 因为【数组名 = 首元素地址】,那不妨
int* p = &arr[0]便可以写成int* p = arr,Ctrl + F5让代码走起来可以看到结果也是一样的
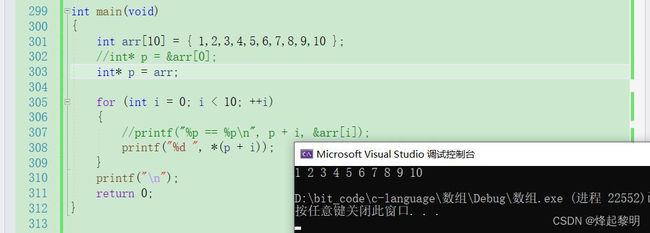
- 那我这么做就相当于是把arr赋给了p,那此时
arr和p也就是一回事,那也可以说【arr <==> p】,所以我们在使用到arr的地方可以换成p,使用到p的地方可以换成arr
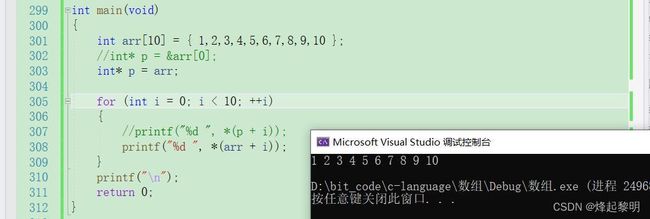
- 那这个时候突然就想到一点我们上面在打印数组元素的时候都是使用
arr[i],那此时是不是可以将arr[i]和*(arr + i)做一个联系呢?当然是可以的
- 因为arr为数组名,数组名表示这个数组的首元素地址。首元素地址向后偏移i个位置之后到达下标为i的那个元素所在的位置,再对其进行解引用就找到下标为i这个地址所对应的元素——这也就是对于【*(arr + i)】的一个解释
- 那对于【arr[i]】又要怎么去解释呢?还记得我一开始讲一维数组的使用时说到
[]是一个数组访问的操作符,那既然是操作符的话就会有操作数,操作数是谁呢?就是【arr】和【i】,那此时当我将arr[i]转换成*(arr + i)的时候,()里面的也就是这两个操作数,根据加法的交换律就可以将【arr】和【i】进行一个交换,那也就变成了*(i + arr)。 - 此时就可以去进行一个类推,因为
*(arr +i)可以写成arr[i]<—— ⭐ - 那么
*(i + arr)是否可以写成i[arr]呢 <——⭐
此时我们通过代码来尝试一下,将推测转化为实际
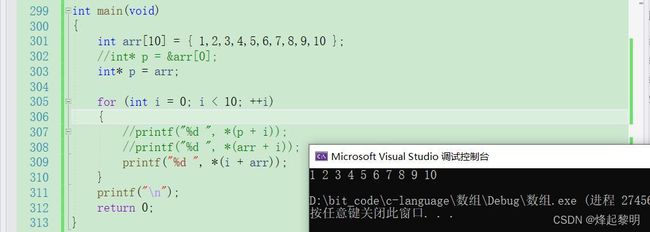
- 可以看到,依旧是可以的w(゚Д゚)不过这种写法了解一下即可,不是很好理解,也不会用到
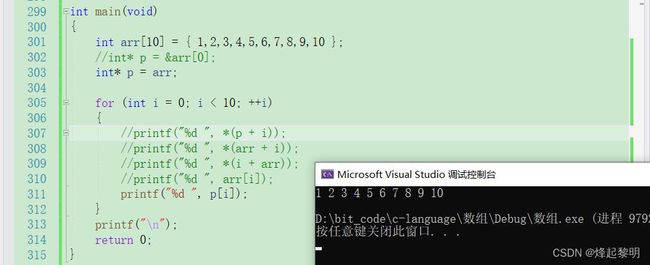
- 刚才有说到
arr和p其实是一回事,那可以写【arr[i]】,是不是也可以写成【p[i]】呢?答案是:当然可以!
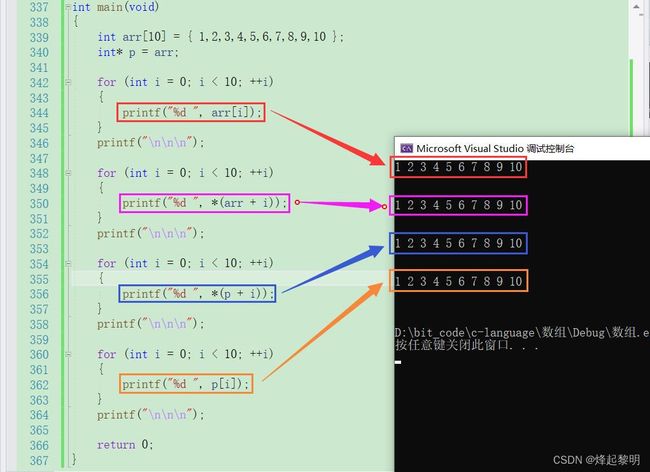
看完上面的这些,相信你已经晕了(((φ(◎ロ◎;)φ))),不过没有关系,将知识点做个总结就可以很清晰了
arr[i] == *(arr + i) == *(p + i) == p[i]
4、实例讲解
回顾了数组的相关知识后,再来看【指针数组】相关内容,就变得易如反掌✋
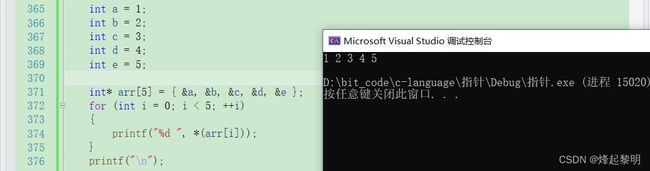
① 指针数组存放地址
- 好,首先来看到第一个案例,我定义了五个变量分别对它们进行了一个初始化,然后定义了一个指针数组,首先你要想到的就是
[指针接受地址]这个概念 - 所以我将这五个变量的地址都存放到了这个【指针数组】中,然后去遍历这个数组便可以访问到这五个变量的地址了
int main(void)
{
int a = 1;
int b = 2;
int c = 3;
int d = 4;
int e = 5;
int* arr[5] = { &a, &b, &c, &d, &e };
for (int i = 0; i < 5; ++i)
{
printf("%d ", *(arr[i]));
}
printf("\n");
return 0;
}
- 接下去你要想到的就是
[解引用]这个知识点,我说到指针其实就是地址,那对地址进行一个解引用其实可以将[*]和[&]进行一个抵消,这也就取到了五个变量的地址,通过下标i控制就遍历到了这五个变量
② 指针数组存放数组
- 好,再来看下面这段代码,我定义了三个整型数组,数组的个数都是5,然后又定义了一个指针数组,将三个整型数组的数组名都存放进去,我们知道
数组名即为首元素地址,所以这是合法的 - 接下去我就要通过这个指针数组访问到这三个整型数组中的所有元素
int arr1[5] = { 1, 1, 1, 1, 1 };
int arr2[5] = { 2, 2, 2, 2, 2 };
int arr3[5] = { 3, 3, 3, 3, 3 };
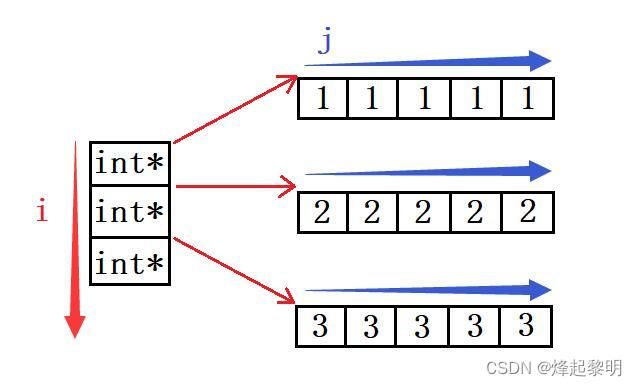
int* parr[3] = { arr1, arr2, arr3 };
for (int i = 0; i < 3; ++i)
{
for (int j = 0; j < 5; ++j)
{
printf("%d ", *(parr[i] + j));
}
printf("\n");
}
- 通过算法图示来看看,外层的遍历,可以访问到这个三个数组的首元素地址,此时我们若还要去访问到每个数组中的元素的话,就要再通过一个内部的循环去遍历每一个数组,这个操作的话相信你看过我的数组文章一定是没问题的
- 这里的
parr[i] + j也就是位于每个数组的首地址向后偏移j个位置,所以访问到的就是下标为j这个位置的地址,但是我们要访问值的话就要加上一个解引用的操作。当然,通过【*】和【()】的规则我们也可以将*(parr[i] + j)转换为*(*(parr + i) + j)或者是parr[i][j]
- 来看一下运行结果
在学习了【指针数组】后,来辨析一下三个数组吧
int* arr1[10];
char* arr2[4];
char** arr3[5];
- 首先第一个arr1,数组大小为10,数组里面存放的都是
int*的整型指针 - 然后第二个arr2,数组大小为4,数组里面存放的都是
char*的字符指针 - 最后第三个arr3,数组大小为5,数组里面存放的都是
cahr**的二级字符指针
【数组指针】
讲完指针数组后,我们就来讲讲它的双胞胎兄弟 —— 【数组指针】
首先还是这个问题,数组指针是指针?还是数组?
1、数组指针的定义
- 我们通过指针初阶中所学习的整型指针和字符指针来做一个对比
int a = 10;
char ch = 'x';
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int* pa = &a; —— 整型指针 - 存放整型地址的指针
char* pc = &ch; —— 字符指针 - 存放字符地址的指针
int(*parr)[10] = &arr; —— 数组指针 - 存放数组地址的指针
- 也是一样来分析一下这三个指针
- 对于
pa,它是一个整型指针,里面存放的是一个整型的地址 - 对于
pc,它是一个字符型指针,里面存放的是一个字符的地址 - 对于
parr,它是一个数组指针,里面存放的是一个数组的地址
- 对于
- 通过这么的对比相信你对【数组指针】有了一初步的概念,它也是一个指针,它所指向的是一个数组的地址
然后就来仔细介绍一下数组指针
- 下面有一个arr数组,数组里面有5个元素,每个元素都是一个
int类型。那现在我要将这个数组的地址存起来,那肯定需要一个指针来接收,那既然是一个指针的话我们肯定会想要用*做修饰,不过这还不够,因为接收的是一个数组的地址,所以我们还会想要再加上[10],而且这个10还不能像我们定义数组的可以省略调用,一定要加上 - 但是像下面这样真的可以吗?或许你应该去了解一下运算符优先级,因为
[]的优先级是最高的,所以这个【pa】会首先和[]结合,而不是先和*,那么它就是一个数组,而不是指针了!
int arr[5] = { 1,2,3,4,5 };
int* pa[10] = &arr;
- 若是想要【pa】和这个
*先结合的话,在它们的外面加上一个()即可,如下所示
int (*pa)[10] = &arr;
这才是一个完整又正确的【数组指针】
2、&数组名VS数组名
对于数组名是首元素地址这个说法我们已经是耳熟于心了,不过上面看到了一个新的写法
&数组名,这和数组名存在着什么关联呢?本模块我们就来探讨一下这个
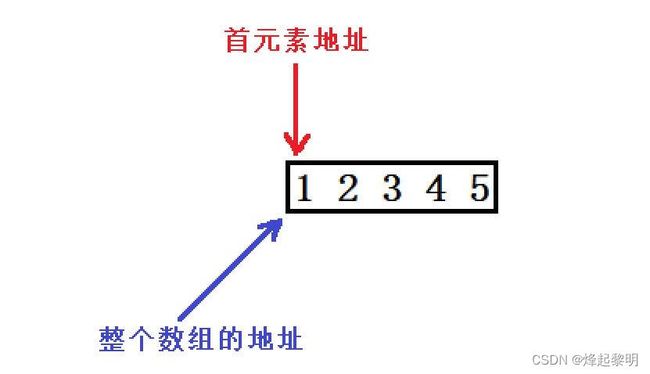
- 可以看到,在下面我分别打印了三种情形,那可以预测第一种和第二种是一样的,而第三种可能就不一样
int arr[5] = { 1,2,3,4,5 };
printf("%p\n", arr);
printf("%p\n", &arr[0]);
printf("%p\n", &arr);
但是从运行结果可以看到它们都是一样的,这是为什么呢?

- 在数组章节我就有讲到过
&数组名值得是取出整个数组的地址,而&arr[0]则是数组首元素的地址。不过从下图可以看,它们的位置是一样的,所以打印出来的地址就是一样的
那有同学说:难道它们就完全相同吗,那&数组名还有什么意义呢?
- 但此时我将当前取到的地址再去 + 1的话,会有什么变化呢?
printf("%p\n", arr);
printf("%p\n", arr + 1);
puts("---------------");
printf("%p\n", &arr[0]);
printf("%p\n", &arr[0] + 1);
puts("---------------");
printf("%p\n", &arr);
printf("%p\n", &arr + 1);
puts("---------------");
可以看到,最后一个&数组名和上面两个的结果不同
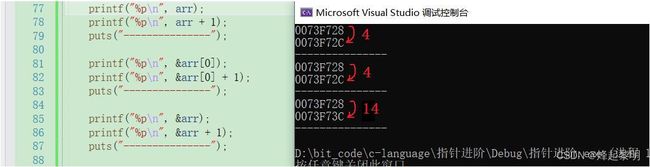
- 对于
arr和&arr[0]都一样,取到的是首元素的地址,这是一个整型数组,首元素是一个int类型的数据,那么其地址就是int*类型,那在【指针初阶部分】我有讲到过一个int*的指针一次可以访问4个字节的大小,那在这数组中每个元素都占4个字节,所以 + 1就会跳过一个元素也就是4个字节 - 对于
&arr来说,取出的是整个数组的大小,虽然它的位置和首元素地址是一样的,但是它 + 1跳过的确是整个数组的大小,上面说到过一个数组的地址给到【数组指针】来接收int (*parr)[5] = &arr;,此时去掉它的变量名后这个指针的类型就是int(*)[10],上面我们也有讲过一个指针一次可以访问的字节取决于它的类型
具体可以看看这张图

在知晓了这一点后许多同学就明白了这个地址的偏移为何是这样,但是仔细一算好像也不对呀,整个数组所占的字节数不是20吗,这里是14呀?
- 要知道,编译器对于一块地址的表示形式是以十六进制的形式,所以我们计算出的差值应该再转换为十进制才对,那么14转换为十进制后刚好就是20,不清楚规则的同学可以去了解一下十六进制转十进制
3、数组指针的使用【⭐】
讲了这么多后,这个数组指针到底有什么用呢?
1.数组指针在一维数组的使用场景
- 之前我们在使用函数封装一个打印数组时有着下面两种写法,一个就是使用数组做接收,一个则是使用指针做接收。因为外界所传入的都是数组名,数组名就是首元素地址
void print1(int arr[], int n)
{
int i = 0;
for (i = 0; i < n; ++i)
{
printf("%d ", arr[i]);
}
printf("\n");
}
void print2(int* arr, int n)
{
int i = 0;
for (i = 0; i < n; ++i)
{
printf("%d ", arr[i]);
}
printf("\n");
}
print1(a, sz);
print2(a, sz);
- 那在学习了【数组指针】后,我们还可以把形参写成下面这种样子
void print3(int (*p)[5], int n)
{
int i = 0;
for (i = 0; i < n; ++i)
{
printf("%d ", (*p)[i]); //a[i]
}
}
- 实参就要以下面这种形式进行传递,那此时形参p接收到的就是整个数组的地址,那么此时
*p也就取到了这个一维数组的数组名,那我们平常用数组名来访问数组中的每个元素时,都是用的arr[i]这样的形式,那么用解引用后的数组指针来访问就可以写成(*p)[i]
print3(&a, sz);
但这样不是很别扭吗?传进来数组的地址,然后再解引用获取到数组名,还不如直接传递数组名呢
- 是的,一般数组指针我们不会用在一维数组的情况下,但是我们一般直接会用数组名或者指针来接收。但数组指针在二维数组中使用的还是比较的多的
2.数组指针在二维数组的使用场景
- 下面是我们之前在使用函数封装二维数组打印的时候所需要的传参
void print4(int arr[3][5], int row, int col)
{
int i = 0;
for (i = 0; i < row; i++)
{
int j = 0;
for (j = 0; j < col; j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
}
int a[3][5] = { {1,2,3,4,5}, {2,3,4,5,6}, {3,4,5,6,7} };
print4(a, 3, 5);
- 那采用【数组指针】的写法也是像上面这样,但是有同学却疑惑说:传进来的不是一个二维数组吗?
void print5(int (*p)[5], int row, int col)
{
int i = 0;
for (i = 0; i < row; i++)
{
int j = 0;
for (j = 0; j < col; j++)
{
printf("%d ", *(*(p + i) + j));
}
printf("\n");
}
}
- 这一块的话我就来重点分析一下了:首先你要知道知道对于一维数组而言,它的首元素地址即为数组中第一个元素的地址,那么二维数组的首元素地址相当于什么呢?如果你仔细看过数组章节的话就可以知道为第一行的地址,此时形参
p接收到的即为第一行的地址。对于二维数组把每一行看做是一个元素,那么对于这个数组来说三行就有三个元素,那么要如何访问到每一行呢?那就是使用p + i,随着【i】的不断变化就可以取到每一行的地址 - 但是我们要访问的是二维数组中的每一个元素,那取到这一行的地址后还不够,因为我们访问数组中元素时使用的都是数组名,此时
*(p + i)也就拿到了当前的这一行的数组名,假设现在要访问第一行,那它的数组名那就是a[0],或者是*(a + 0),以此类推后面的几行数组名就是a[1]、a[2]。那数组名我们知道,意味着首元素地址,现在先访问第一行中的每个元素,那么首先拿到的就是【1】的地址,那要访问到后面的每一个元素首先要对地址进行一个偏移,*(p + i) + j就可以拿到每个元素的地址,那此时就简单了,再解引用*(*(p + i) + j)也就取到了当前行中的每个元素,根据数组名和指针的转换规则,即为p[i][j]
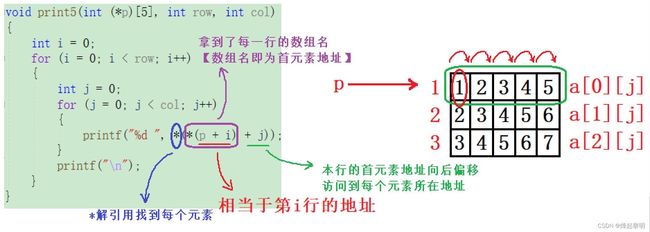
来看一下运行结果
在学习了【指针数组】和【数组指针】后,来看一下这四个指针 or 数组?
int arr[5];
int *parr1[10];
int (*parr2)[10];
int (*parr3[10])[5];
- 第一个【arr】首先和
[]结合,表明它是是一个数组,数组有五个元素,每个元素都是int类型的,说明这是一个一维数组 - 第二个【parr】首先和
[]结合,表明它是一个数组,数组的每个元素都是一个int类型的指针,说明这是一个指针数组 - 第三个【parr2】首先和
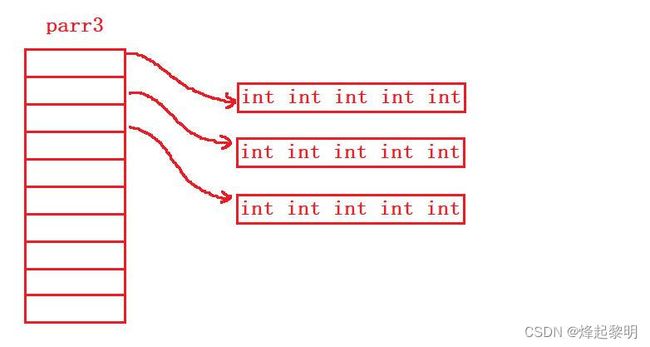
*结合,表明它是一个指针,然后往后一看,它指向一个数组,该数组有10个元素,每个元素都是int类型,说明这是一个数组指针 - 第四个【parr3】首先和
[]结合,表明它是一个数组,数组有十个元素,把parr3[10]去掉后就可以看出它的类型,是int(*)[5],说明数组中存放着的都是数组指针,每个数组指针都指向一个存有5个元素,每个元素都是int类型的数组。最后我们判定其为数组指针数组
第四个的图示如下:
【数组传参与指针传参】
相信有很多同学对于数组传参、指针传参都是搞的稀里糊涂的
1、 一维数组传参
代码:
/*一维数组传参*/
void test(int arr[]) //ok?
{}
void test(int arr[10]) //ok?
{}
void test(int* arr) //ok?
{}
int main()
{
int arr[10] = { 0 };
test(arr);
}
解析:
- 首先来看一维数组的传参,test传进来一个arr数组名,那第一个利用
arr[]接收这是我们最常见的,没有问题✔ - 第二个和第一个类似,只是在
[]里加上了一个10,不过我们知道对于一维数组里面的数组大小声明是可以省略的,所以没有关系 - 第三个是采用
*arr的方式进行接收,那传递进来的arr为数组名,数组名是首元素地址,那给到一个指针作为接收也没什么问题
代码:
void test2(int* arr[20]) //ok?
{}
void test2(int** arr) //ok?
{}
int main()
{
int* arr2[20] = { 0 };
test2(arr2);
}
解析:
- 接下去看到我向test2传递了一个指针数组,那使用
* arr[20]合情合理 ✔ - 那么第二个
** arr是都可以呢?这点我们可以通过画图来分析,因为arr2是一个指针数组,而且里面存放的每个元素都是int类型的, 那我们传递【指针数组】的数组名过去的话,那其实就是首元素地址,即这个一级指针int*的地址,那么形参部分使用二级指针来接收也是正确的 ✔
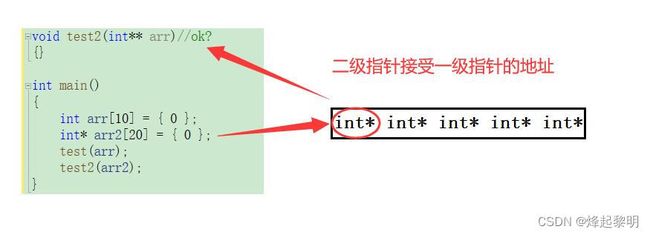
总结:
最后总结一下一维数组传参形参可以是哪些内容
- 形参可以是数组
- 形参可以是指针
- 形参可以是一个二级指针,指针数组的地址可以给到二级指针做接收,因为指针数组里面存放的都是一级指针
2、 二维数组传参
代码:
/*二维数组传参*/
void test(int arr[3][5])//ok?
{}
void test(int arr[][])//ok?
{}
void test(int arr[][5])//ok?
{}
int main()
{
int arr[3][5] = { 0 };
test(arr);
}
解析:
- 接下去我们再来看看二维数组的传参,第一个无需多说。第二个的话形参这种写法是不可以的,因为二维数组必须确定它的列,也就是每行有多少个元素,但是有多少行可以不用知道❌
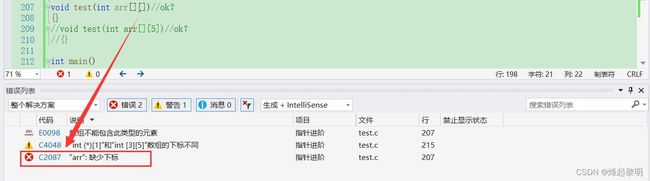
- 那对于第三个来说就是正确的,虽然省略了第一个
[]的数组,但是指明了列的个数,就没有关系 ✔
代码:
void test2(int* arr)//ok?
{}
void test2(int* arr[5])//ok?
{}
void test2(int(*arr)[5])//ok?
{}
void test2(int** arr)//ok?
{}
int main()
{
int arr[3][5] = { 0 };
test2(arr);
}
解析:
- 上面的代码是采取形参部分指针进行接收,上面我们有分析到,二维数组的数组名是首行的地址,那可以使用一个一级指针来接收吗?很显然是不可以的❌
- 第二个
int* arr[5]可以吗?首先你要分析看它是个什么,我们传递过来的是一个地址,那地址就要使用指针来进行接收,但是可以看到这很明显是一个指针数组,因为arr和[]先结合了,所以也是错误的❌ - 那么第三个呢?通过观察可以判断出它是一个数组指针, 接收一个二维数组第一行的地址,那肯定是不会有问题的 ✔
- 最后是一个二级指针,但是二级指针只能接收一个一级指针的地址,不过我们传递过来的是一个二维数组中某一行的地址,根本牛头不对马嘴❌
总结:
最后总结一下二维数组传参形参可以是哪些内容
- 直接用二维数组做接收
- 二维数组的数组名是首行的地址,是一个一维数组的地址,要使用数组指针来接收
3、 一级指针传参
代码:
void print(int* p, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d\n", *(p + i));
}
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9 };
int* p = arr;
int sz = sizeof(arr) / sizeof(arr[0]);
//一级指针p,传给函数
print(p, sz);
return 0;
}
解析:
- 接下去我们来看看一级指针的传参,那其实这很明确,在main函数中指针指向arr数组的首元素地址,传递过去后形参部分的p也指向这个地址,那么通过解引用就访问到了数组中的每一个元素
思考:
当一个函数的参数部分为一级指针的时候,函数能接收什么参数?
- 可以直接是一个变量的地址
- 可以是一级指针
- 一维数组的数组名(数组名是首元素地址,数组中的每一个元素都是一个变量)
4、 二级指针传参
代码:
void test(int** ptr)
{
printf("num = %d\n", **ptr);
}
int main()
{
int n = 10;
int* p = &n;
int** pp = &p;
test(pp);
test(&p);
return 0;
}
解析:
- 接下去我们来看看一级指针的传参,那其实这很明确,在main函数中指针指向arr数组的首元素地址,传递过去后形参部分的p也指向这个地址,那么通过解引用就访问到了数组中的每一个元素
思考:
当一个函数的参数部分为二级指针的时候,函数能接收什么参数?
- 可以直接是一个一级指针的地址
- 可以是二级指针
- 指针数组的数组名(数组名是首元素地址,数组中的每一个元素都是一个一级指针)
四、指针函数与函数指针
【指针函数】
1、定义
指针函数,简单的来说,就是一个返回指针的函数,其本质是一个函数,而该函数的返回值是一个指针
【格式】:返回类型* 函数名(参数表)
- 指针函数还是很好理解的,通过基本的函数来做个对比
int func(int x, int y)
int* func(int x, int y)
- 很清楚地可以看出,【指针函数】就是普通的一个函数,只是它的返回值类型为一个指针罢了
2、示例
下面展示一个指针函数的相关案例
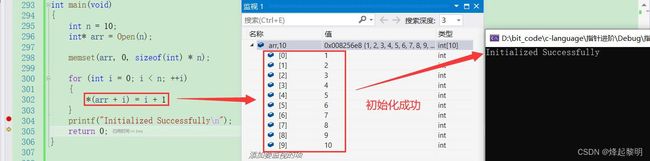
Open()函数从外界接收一个值,用于在函数内部开辟出一块大小为n的空间,然后return返回,返回类型为int*,此时外界使用int*来进行接收,就获取到了函数内部开辟出这个数组的首元素地址,然后通过循环为数组中n个元素初始化- 这里无需担心在函数内部开辟的这块空间的地址,因为它存放在堆上,而不是在栈上,所以不会随着函数栈帧的销毁而消亡,所以这里在举例的时候我专门去堆上面申请空间然后返回,若是返回函数中局部变量的地址,就会有很大的风险!
int* Open(int n)
{
int* a = (int*)malloc(sizeof(int) * n);
if (NULL == a)
{
perror("fail malloc");
exit(-1);
}
return a;
}
int main(void)
{
int n = 10;
int* arr = Open(n);
memset(arr, 0, sizeof(int) * n);
for (int i = 0; i < n; ++i)
{
*(arr + i) = i + 1;
}
printf("Initialized Successfully\n");
return 0;
}
通过运行结果可以看出确实可以起到初始化数组的效果
【函数指针】
讲完指针函数,我们也来说说它的双胞胎兄弟 —— 函数指针
1、概念理清
经过上面所讲的字符指针、数组指针,相信你马上就能类比出函数指针:没错,它就是一个指针,所指向的就是一个函数
- 在【数组指针】中我有讲到过
数组名和&数组名的区别,虽然它们都指向数组的首元素地址,但是在它们往后偏移时,访问的字节数却不同;既然一个数组可以取出它的地址,那么函数是否可以取出它的地址呢?一起来看看

- 从打印结果可以看出无论是
函数名还是&函数名,它们的地址都是相同的,这是为什么呢?这就是语法规定的,一个函数名取不取地址都是这个函数的地址,因为对于函数来说也没有什么首函数的地址,是吧
对于数组的地址,我们可以用数组指针保存起来,那函数可以吗?当然可以,使用到的就是【函数指针】
- 那我现在想问,下面那种形式可以将函数的地址存放起来呢
//下面pfun1和pfun2哪个有能力存放test函数的地址?
void (*pfun1)();
void *pfun2();
答案揭晓,就是第二个,解析如下
- 回忆我们数组指针的写法,为了不让指针变量和
[]先结合,所以在*和指针变量外加了一(),其实对于函数指针也是一样的, 若是不加这个括号的话,就会变成* pf(),pf就会优先和后面的()结合,那么这会被编译器当成是一个函数的声明 - 加上括号后,
(*pf)就会是一个指针,向外一看有个(),说明它指向一个函数,这个函数的参数就是Add形参部分两个参数的类型 - 最后是它的返回类型,也就是这个函数的返回类型
int
所以Add函数的函数指针应该写成下面这种形式
int (*pf)(int, int) = &Add;
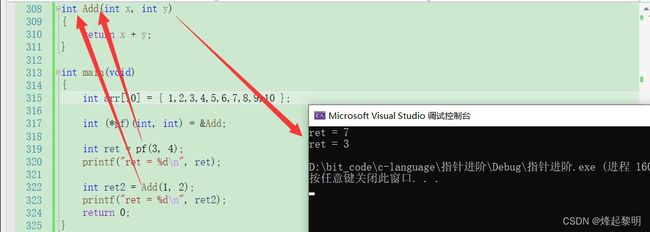
2、如何调用函数指针?
清楚了函数该如何去声明后,那既然有了这个指针,而且它指向一个函数,是否可以通过这个指针去调用这个函数呢?
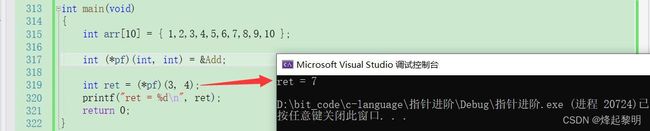
- 调用函数肯定得传参,那我们为刚才声明的形参部分传入两个参数试试,然后再拿返回值接收一下
- 可以看到确实可以调用Add函数进行求和计算
- 不过这个编译器到底是怎么根据这个函数指针来判断去调用的Add函数,我们来对比一下
int ret = (*pf)(3, 4);
printf("ret = %d\n", ret);
int ret2 = Add(1, 2);
printf("ret = %d\n", ret2);
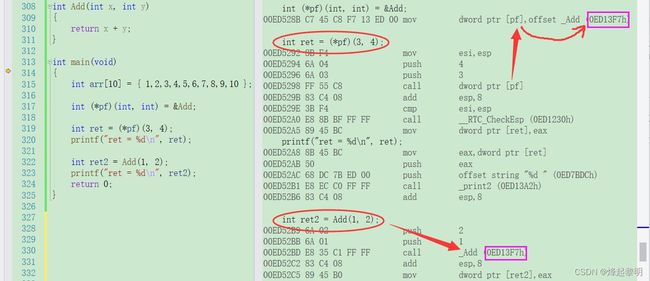
通过调试来观察可以发现,编译器很智能,确实是通过函数指针的指向去找到函数的地址
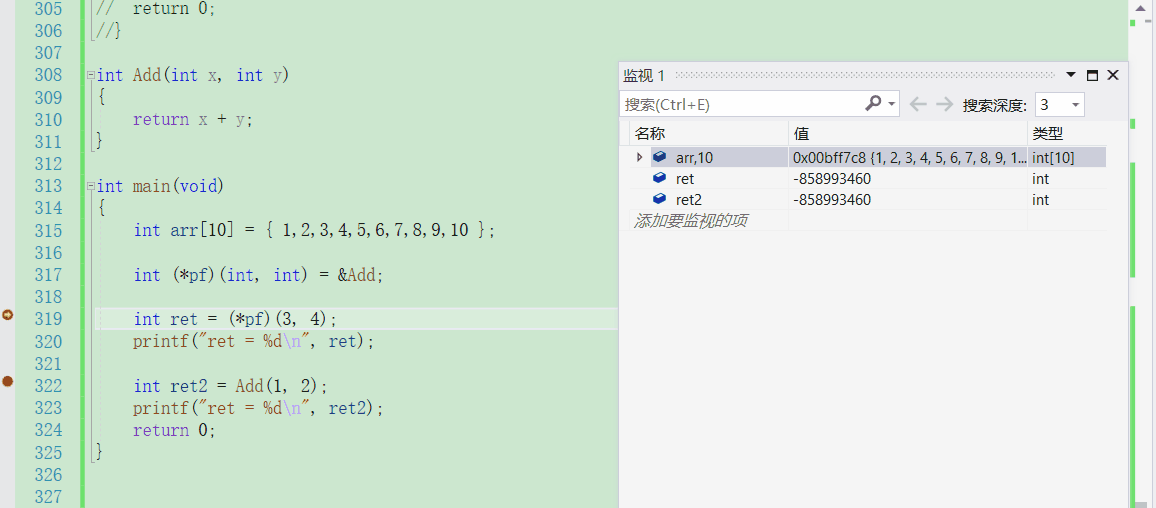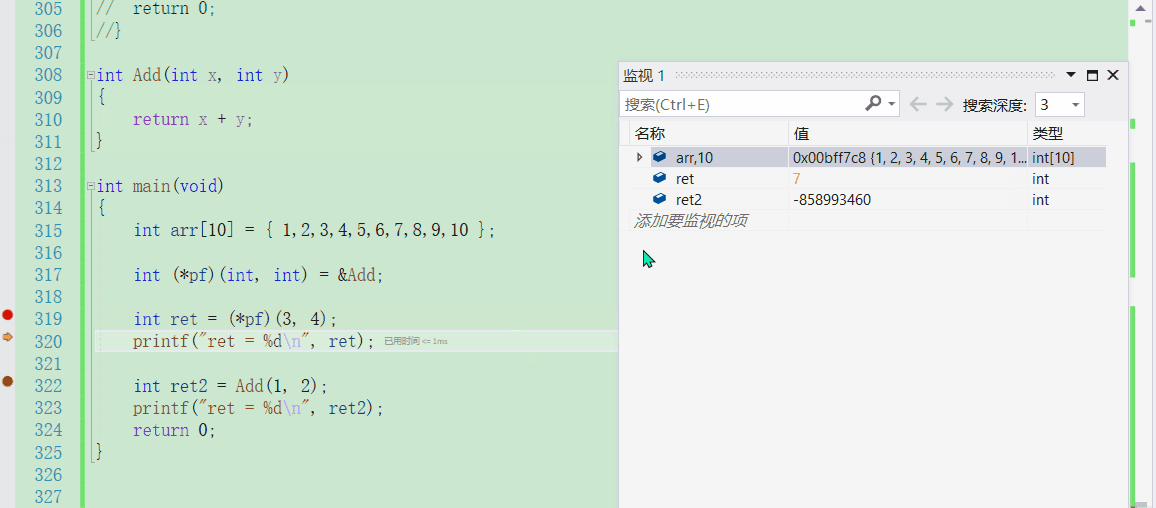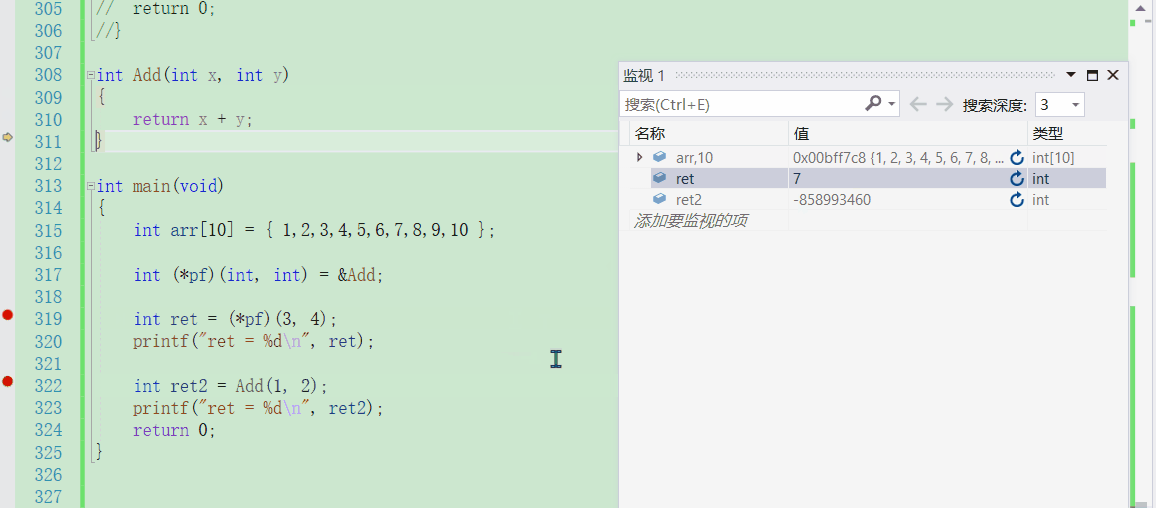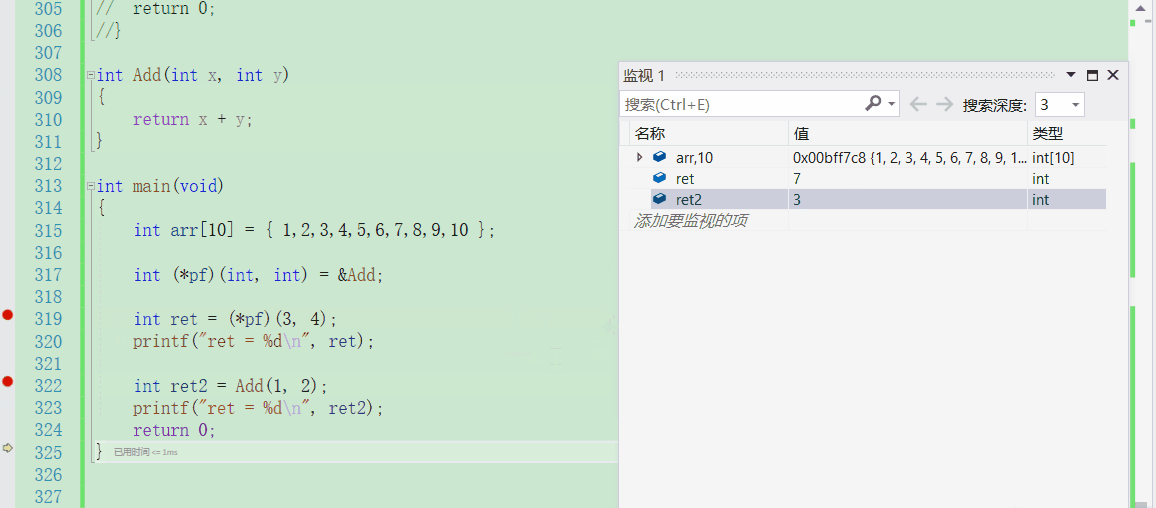
也可以通过汇编来看,很清晰地看出它们都去call了这个函数的地址
- 上面说到无论是
函数名还是&函数名,它们所取到的地址都是一样的,所以我们可以将函数指针的声明写成下面这种形式,读者可以自己去试一下,效果也是一样的
int (*pf)(int, int) = Add;
- 那观察上面这样的声明形式,把指针变量单独抽离出来其实就是把
Add赋给了pf,然后调用的时候在前面加上一个*作为解引用,取到这个函数,那其实Add和pf就是一样的,所以我们可以像pf(1, 2)这样去调用函数,具体如下
//int ret = (*pf)(3, 4);
int ret = pf(3, 4);
int ret2 = Add(1, 2);
通过运行可以发现效果也是一样的,所以前面的*其实是可以省略的,甚至你多加几个像(****pf)(3, 4)都是可以的
3、两道“有趣”的代码题O(∩_∩)O
通过函数指针的学习,我们来看看下面两道很有趣的代码
下面两题均来自《C陷阱与缺陷》
< 第一题 >
代码:
(*(void (*)())0)();
解析:
如果你是头一次看上面这段代码的话,心里一定是一个大大的问号???现在我就来解释一下
- 本题的突破口在于这个0,仔细观察可以发现,0前面有一个括号
(),括号里面的这种形式若是你自己去看的话就是一个函数指针,那相当于就是对0进行一个强制类型转换,把它变成一个函数地址,然后前面的*我们刚才讲过,就是对这个函数进行解引用,获取到这个函数。那么最后一步便是去调用这个函数
具体的分解可以看看下图
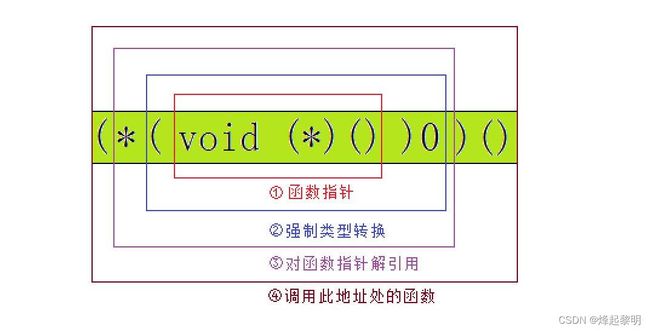
分步细说:
void (*)()—— 》一个没有形参,返回类型为void的函数指针
(void (*)())0——》 对0进行强制类型转换,使其被解释成为一个函数的地址
*(void (*)())0——》对0地址处的函数进行解引用,获取到这个函数
(*(void (*)())0)()——》调用0地址处的函数
原文现身:

< 第二题 >
代码:
void (*signal(int, void(*)(int)))(int);
解析:
同理,若是第一次见一定会被它绕晕了了
- 本题真的可以说是在套娃了,首先你看到的一定是
signal,它呢是C语言中的一个信号函数,有兴趣可以去了解一下,我们知道()的优先级高于*,所以signal会和后面的内容先结合,那其实已经可以看出这是一个函数声明了。进到里面再来看看这个函数有两个参数,一个是int,一个是函数指针,那么外层的又是什么呢? - 仔细看下图,我将内部的signal()函数声明抽离了出来,只剩下了头和尾,你可以做一个视觉上的合并,那其实又是一个
void (*)(int)的函数指针,其实这就是signal函数的返回类型,是一个函数指针

同样地,我们再来捋一遍
分步细说:
void (*)(int)—— 》是一个函数指针,为signal函数的形参
signal(int, void(*)(int))——》 是一个函数声明,signal与右侧的()率先结合,内部有两个形参
void (*)(int)——》也是一个函数指针,不过是作为signal函数返回类型
优化:
对于上面的这种写法你是否觉得很冗余,其实可以再度进行一个优化,那么你可能很快就看得懂了
- 因为
void (*)(int)是出现了两次,之前我们在C语言中有学习过typedef这个关键字,可以用来对一个很长的数据类型或者变量进行重命名,那么在这里我们也可以这样做 - 不过呢,你要把重命名后的名字放在
(*)里面,因为语法这么规定了,去掉变量名后就是它的类型
typedef void(*ptr_t)(int);
- 于是这句代码就可以简化为下面这种形式注意解引用那个
*不要了,函数指针这里是可以省略的
//void (*signal(int, void(*)(int)))(int);
ptr_t signal(int, ptr_t);
原文现身:

4、函数指针数组
指针可以存放在一个数组中,那函数指针可以吗?来看看【函数指针数组】吧
概念明细
- 还记得我们学习完【数组指针】后的这道练习题吗,最后我们判定它的类型为数组指针数组,它是一个数组,里面存放的都是数组指针
int (*parr3[10])[5];
- 那对于函数指针来说,和这个其实存在异曲同工之妙,只需要把后面的
[]改为()即可,当然你也可以改个名字
int (*pfArr[10]();
- 再来对比我们前面学习过的【函数指针】,你有发现区别在哪吗?没错,就是多了个
[10],因为[]的优先级较高,所以pArr会和它先结合,那其实就可以肯定它为一个数组了
int (*pfArr)();
声明知道了,那具体怎么使用呢?怎么去接收多个函数的地址呢?再来看看
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int main(void)
{
int (* pfArr[2])(int, int) = {Add, Sub};
int ret1 = pfArr[0](5, 3);
int ret2 = pfArr[1](5, 3);
printf("ret1 = %d\n", ret1);
printf("ret2 = %d\n", ret2);
return 0;
}
- 很简单,上面有Add和Sub两个加与减的函数,那将它们存放到一个数组中,首先用花括号把它们括起来
{Add, Sub},然后还是和函数指针一样的声明,只需要在指针变量后加上一个[2]即可,那么这就是一个【函数指针数组】 - 接着去调用的话其实和要结合函数和数组的调用形式,既要控制数组的下标,还要考虑调用函数时传入相应的参数,如下所示

对于【函数指针数组】,我想你应该感受到了它的强大,竟然可以存放多个数组的地址然后根据不同的下标索引找到不同的函数进行调用,如果使用得当,那一定可以事半而功倍
具体引用:转移表✔
对于函数指针数组而言,有一个很经典的应用就是转移表,简单来说就是计算器
- 首先我使用分支循环实现了简易的功能计算,代码如下
void menu()
{
printf("**************************\n");
printf("***** 1.Add 2.Sub *****\n");
printf("***** 3.Mul 4.Div *****\n");
printf("***** 5.Cls 0.Exit*****\n");
printf("**************************\n");
}
int main(void)
{
int input = 0;
int x = 0, y = 0;
int ret = 0;
do {
menu();
printf("请输入你的选择:>");
scanf("%d", &input);
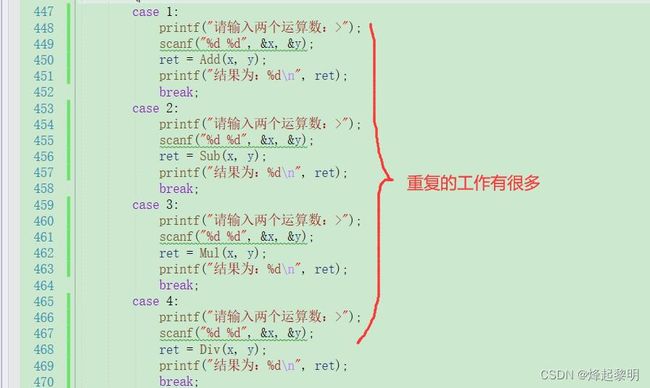
switch (input)
{
case 1:
printf("请输入两个运算数:>");
scanf("%d %d", &x, &y);
ret = Add(x, y);
printf("结果为:%d\n", ret);
break;
case 2:
printf("请输入两个运算数:>");
scanf("%d %d", &x, &y);
ret = Sub(x, y);
printf("结果为:%d\n", ret);
break;
case 3:
printf("请输入两个运算数:>");
scanf("%d %d", &x, &y);
ret = Mul(x, y);
printf("结果为:%d\n", ret);
break;
case 4:
printf("请输入两个运算数:>");
scanf("%d %d", &x, &y);
ret = Div(x, y);
printf("结果为:%d\n", ret);
break;
case 5:
system("cls");
break;
case 0:
break;
default:
printf("请输入正确的内容:");
break;
}
} while (input);
return 0;
}
但是仔细观察可以发现,每一条case语句中,都有重复的工作,就显得很冗余,为什么每个case里都要放一个输入呢,这是我后来发现的问题,若是把这个输入放在外面的话,就会造成按下0想要退出的时候还会出现输入运算数的情况,因为这是处于一个do…while的循环之中
但是此处我若是利用函数指针数组的话,就会很方便了
- 函数声明如下,将这四个加、减、乘、除的函数的地址放到数组中存起来,通过下标的方式来进行访问
int (*pfArr[5])(int, int) = {0, Add, Sub, Mul, Div};
- 于是内部的逻辑就可以写成下面这样,通过去判断输入的
input来实现不同的功能,只有当input >= 1 && input <= 4时,才进行运算,此时把输入操作符的逻辑放在这里即可,便不会影响其他功能了
do {
menu();
printf("请输入你的选择:>");
scanf("%d", &input);
int (*pfArr[5])(int, int) = {0, Add, Sub, Mul, Div};
if (input == 0)
{
break;
}
if (input >= 1 && input <= 4){
printf("请输入两个运算数:>");
scanf("%d %d", &x, &y);
int ret = pfArr[input](x, y);
printf("结果为:%d\n", ret);
}
else if (input == 5) {
system("cls");
}
else {
printf("输入有误,请重新输入\n");
}
} while (input);
5、指向函数指针数组的指针
学习了函数指针数组后,你是否有联想到取出这个数组的地址再存放到指针里去呢?这不,它来了
- 仿照前面的写法,若现在要是一个指针的话,那你应该想要又需要
*和()了,因为存在优先级的问题,指针变量会和[]相结合,所以我们可以取出函数指针数组的地址,给到一个指针作为接收,这个指针即为ptr

- 分解着来细说一下,首先说明一下,有些同学直接拿函数指针的
*作为指针符,这是不对的, 那是用来对函数指针所指向函数的地址进行解引用的,可不能混淆,所以我们要另外再加一个*,与ptr进行结合 - 那么此时ptr就一定是一个指针,然后朝外一看有一个数组,那它便指向一个数组,这个数组的有5个元素,每个元素的类型我们只需要拿到数组名即
(*ptr)[5]即可,便发现里面存放的都是函数指针。这么分析下来这个【ptr】确实是一个指向函数指针数组的指针

再来看一组练习巩固一下
- 【pfun】是一个指针,它指向一个形参类型为
const char*,返回类型为void的函数 - 【pfunArr】是一个数组,数组大小为5,里面存放的均是指向指向一个形参类型为
const char*,返回类型为void的函数指针 - 【ppfunArr】是一个指针,它指向一个数组,数组里面的都是函数指针。。。同上
void test(const char* str)
{
printf("%s\n", str);
}
int main()
{
//函数指针pfun
void (*pfun)(const char*) = test;
//函数指针的数组pfunArr
void (*pfunArr[5])(const char* str);
pfunArr[0] = test;
//指向函数指针数组pfunArr的指针ppfunArr
void (*(*ppfunArr)[5])(const char*) = &pfunArr;
return 0;
}
研究到这块就可以了,如果上面的这些你全搞懂了的话,那么指针这一块相当于学得还可以了,不过缺乏实战, 【炼狱篇】会有大量的实战,虽然题量很多而言很难,但这是提升自己最好的机会!
五、回调函数
1、回调函数的概念
回调函数就是一个通过【函数指针】调用的函数。如果你把函数的指针(
地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
2、为什么要使用回调函数?
最大的一个目的,就是为了实现:解耦!
-
在主入口程序中,把回调函数像参数一样传入库函数。这样一来,只要我们改变传进库函数的参数,就可以实现不同的功能,且不需要修改库函数的实现,变的很灵活,这就是解耦
-
主函数和回调函数是在同一层的,而库函数在另外一层。如果库函数对我们不可见,我们修改不了库函数的实现,也就是说不能通过修改库函数让库函数调用普通函数那样实现,那我们就只能通过传入不同的回调函数了,这也就是在日常工作中常见的情况
注:使用回调函数会有间接调用,因此,会有一些额外的传参与访存开销,对于MCU代码中对时间要求较高的代码要慎用
3、回调函数使用场景
场景一:模拟计算器的加减乘除
- 在函数指针章节,我有介绍了如何使用【函数指针数组】去模拟计算器的加减乘除,现在我们使用回调函数来试试
功能与菜单
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void menu()
{
printf("**************************\n");
printf("***** 1.Add 2.Sub *****\n");
printf("***** 3.Mul 4.Div *****\n");
printf("***** 5.Cls 0.Exit*****\n");
printf("**************************\n");
}
主程序与回调函数
void calc(int (*p)(int, int))
{
int x = 0, y = 0;
printf("请输入两个运算数:>");
scanf("%d %d", &x, &y);
int ret = p(x, y);
printf("结果为:%d\n", ret);
}
int main(void)
{
int input = 0;
do {
menu();
printf("请输入你的选择:>");
scanf("%d", &input);
switch (input)
{
case 1:
calc(Add);
break;
case 2:
calc(Sub);
break;
case 3:
calc(Mul);
break;
case 4:
calc(Div);
break;
case 5:
system("cls");
break;
case 0:
break;
default:
printf("请输入正确的内容:\n");
break;
}
} while (input);
return 0;
}
通过画图来看一下是如何通过函数指针来实现的回调

- 可以看出,回调函数它不会自己调用,而是将自己的函数名传递给到另一个函数(此处的Add和Sub即为回调函数),然后在这个函数内部通过函数指针去调用这个函数。就是这样函数指针会接收来自不同函数的地址,继而实现计算器的加、减、乘、除各种功能
场景二:模拟qsort函数【⭐】
学习过数据结构的同学一定接触过【快速排序】,即QuickSort。不了解的可以看看 数据结构 | 十大排序超硬核八万字详解
1、qsort函数解读
- 在C语言中,也有一个关于快速排序的库函数,叫做qsort,来看一下官方文档是怎么说的

- 清楚了这个函数的基本作用后,那最想知道的就是它如何使用,既然是函数的话就需要传递参数,给个特写
base—— 待排序元素的起始地址,类型为【void】表示可以传递任何类型的数组num—— 表示待排序数据的元素个数size—— 表示数组中每个元素所占的字节数int (*compar)(const void*, const void*)—— 函数指针,用于接收回调函数

2、用用qsort
首先我们用它来排下整型数组试试
cmp_int(const void* e1, const void* e2)
{
return *(int*)e1 - *(int*)e2;
}
void test1()
{
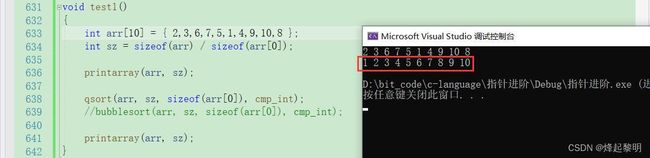
int arr[10] = { 2,3,6,7,5,1,4,9,10,8 };
int sz = sizeof(arr) / sizeof(arr[0]);
printarray(arr, sz);
qsort(arr, sz, sizeof(arr[0]), cmp_int);
printarray(arr, sz);
}
运行结果:
解析:
cmp_int(const void* e1, const void* e2)
{
return *(int*)e1 - *(int*)e2;
}
- 主要来讲一下这个函数,这就是本文要讲解的回调函数,为什么它的形参是一个
void*的指针呢?这种类型的指针一般被我们称作为【垃圾桶】,那垃圾桶我们平常都在用,不考虑垃圾分类的话,可以接收任何种类的垃圾,那么在这里就是可以接收任何类型的数据,即整型、字符型、浮点型,甚至是自定义类型它都可以接受 - 但是呢我们在使用的时候还是要去进行一个转换,此处就要使用到【强制类型转换】,将其转换为
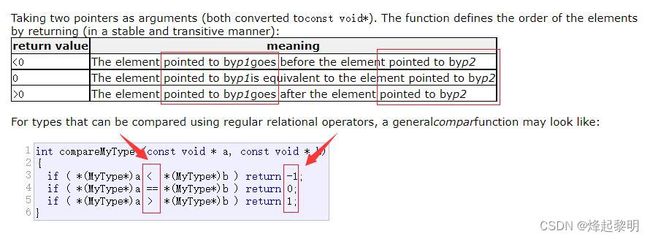
int *的指针,那么它就指向了我们要待排序的数组。但是要怎么比较和交换两个数据呢,这就要看qsort()函数内部的实现了,它是基于快速排序的思想,如果你懂快速排序的话,脑海里立马就能浮现出它们的比较的场景 - 还是来看一下官方文档,其实下面的这种比较思路很常见,像字符串函数
[strcmp]也是这样的:- 前一个比后一个小,返回
-1 - 前一个和后一个相等返回,返回
0 - 前一个比后一个大,返回
1
- 前一个比后一个小,返回
当然,除了上面这种内置类型外,自定义类型的数据也是可以比较的,接下去我们来比较一下两个学生的信息
- 下面是结构体的初始化和定义,以及qsort函数的调用
typedef struct stu {
char name[20];
int age;
}stu;
void test2()
{
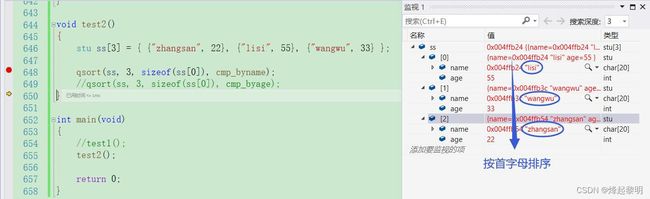
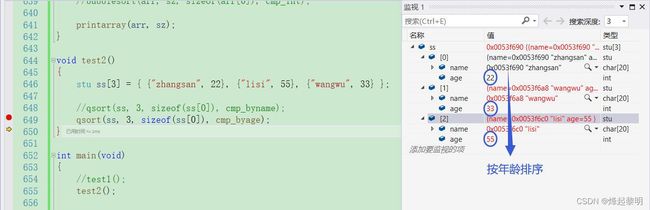
stu ss[3] = { {"zhangsan", 22}, {"lisi", 55}, {"wangwu", 33} };
qsort(ss, 3, sizeof(ss[0]), cmp_byname);
//qsort(ss, 3, sizeof(ss[0]), cmp_byage);
}
- 下面是两个回调函数的实现,在看了第一个后相信你已经很熟悉了,形参还是
void*类型的指针,但是在比较的时候要转换为结构体指针,否则就无法访问到成员了。对于【姓名】的比较是按照首字母的ASCLL码值来的,这里我们直接使用库函数strcmp即可,比较的规则和qsort()是一致的
Cmp_ByName(const void* e1, const void* e2)
{
return strcmp(((stu*)e1)->name, ((stu*)e2)->name);
}
Cmp_ByAge(const void* e1, const void* e2)
{
return ((stu*)e1)->age - ((stu*)e2)->age;
}
首先来看按照名字排序的结果
然后是按照年龄排序的结果
3、使用冒泡排序模拟qsort
- 普通的冒泡排序的话相信是个大学生应该都会写,这里就不解释了,如果不会的话看看我的排序文章
void BubbleSort(int* a, int n)
{
for (int i = 0; i < n - 1; ++i)
{
for (int j = 0; j < n - 1 - i; ++j)
{
if (a[j] > a[j + 1])
{
int t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
}
}
}
}

但此时我若是要用这个冒泡排序去排任意类型的数据呢?该如何进行修改
- 此时就需要使用到刚才所学习的
qsort()函数了。我们可以仿照着它的参数来写写看
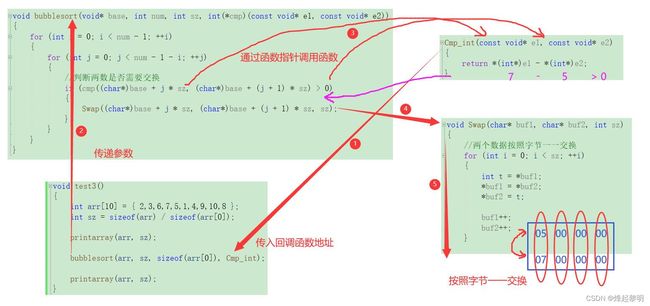
void bubblesort(void* base, int num, int sz, int(*cmp)(const void* e1, const void* e2))
- 既然参数做了,那么函数体内部我们也需要做一个大改动。例如对数组中的两个数据进行比较的时候,就不能单纯地使用关系运算符
>、>、==了,此处函数指针就派上了用场,我们可是使用函数指针去接收不同的回调函数,继而去实现不同的类型数据的比较,也就是上面所写的Cmp_int、Cmp_ByName、Cmp_ByAge - 而且对于内部的交换逻辑我们也要单独去实现,不同数据的交换方式是不一样的

那现在,我们就来实现一下上面说到的这两块内部逻辑
- 首先就是
j和j + 1这两个位置上的值要如何进行比较的问题,那既然base指向首元素地址,那有同学说不妨让它进行偏移,但是它的类型是void*,虽然这种类型的指针可以接收各种各样的数据地址, 但是却无法进行偏移,因为它也不知道要偏移多少字节,所以我上面在回调函数内部对两个形参进行了强转才可以进行比较

- 我们知道,对于
char类型的字符,在内存中只占有1个字节的大小,那么char*的指针每次后移便会偏移一个字节,那既然在形参我们传入了数组中每个元素在内存中所占字节数的话,就可以使用起来了,和char*的指针去做一个配合
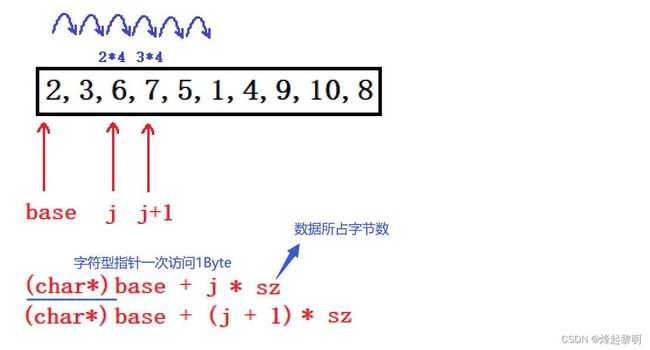
- 所以两数比较的逻辑就可以写成下面这样
//判断两数是否需要交换
if (cmp((char*)base + j * sz, (char*)base + (j + 1) * sz) > 0)
{
//两数据交换的逻辑
}
接下去就来实现两数交换的逻辑
- 因为我们是使用的
char*指针一个字节一个字节去访问数据的,所以交换的时候也需要按照字节来交换。单独封装一个Swap()函数,把要交换两个数的地址和单个数据所占的字节数传入
声明:
void Swap(char* buf1, char* buf2, int sz)
调用:
Swap((char*)base + j * sz, (char*)base + (j + 1) * sz, sz);
内部逻辑就是单个数据的交换【记住,这只是单个数据,所以循环sz次】
void Swap(char* buf1, char* buf2, int sz)
{
//两个数据按照字节一一交换
for (int i = 0; i < sz; ++i)
{
int t = *buf1;
*buf1 = *buf2;
*buf2 = t;
buf1++;
buf2++;
}
}
具体交换细节可以看下图

测试一下:
- 可以看到,整数类型的数据排序成功了

- 再看看内置类型


4、原理分析
仔细看一下这张图,你就清楚整个调用过程了
场景三:模拟任务下载进度
本代码来自我的Linux基础入门篇之进度条小程序,也很好地展现了回调函数的魅力之所在
processBar.h
1 #include <stdio.h>
2 #include <unistd.h>
3 #include <string.h>
4
5 #define TOP 100
6 #define BODY '='
7 #define RIGHT '>'
8
9 extern void processBar(int rate);
10 extern void initBar();
processBar.c
1 #include "processBar.h"
2
3 const char* label = "|/-\\";
4 char bar[TOP];
5
6 void initBar()
7 {
8 memset(bar, '\0', sizeof(bar));
9 }
10
11 // 单次的进度推进
12 void processBar(int rate)
13 {
14 if(rate < 0 || rate > 100) return;
15
16 int len = strlen(label);
17 printf("[%-100s][%d%%][%c]\r", bar, rate, label[rate % len]);
18 fflush(stdout); // 刷新缓冲区
19 bar[rate++] = BODY;
20 if(rate < 100)
21 bar[rate] = RIGHT;
22 else
23 initBar();
24 }
main.c
1 #include "processBar.h"
2
3 // 函数指针类型
4 typedef void (callback_t)(int rate);
5
6 // 模拟一种安装或下载的场景(回调函数)
7 void downLoad(callback_t cb)
8 {
9 int total = 1000; // 1000B
10 int curr = 0; // 0B
11
12 while(curr <= total)
13 {
14 /* 进行某种下载任务 */
15 usleep(50000); // 模拟下载时间
16
17 // 计算下载速率
18 int rate = curr * 100 / total;
19 cb(rate); // 通过函数指针去调用对应的函数
20
21 // 循环下载了一部分
22 curr += 10;
23 }
24 printf("\n");
25 }
26
27 int main(void)
28 {
29 // 将所需要的调用的函数地址传递给回调函数
30 printf("download 1:\n");
31 downLoad(processBar);
32
33 printf("download 2:\n");
34 downLoad(processBar);
35
36 printf("download 3:\n");
37 downLoad(processBar);
38 }

场景四:模拟文件下载模块
我们为什么要用回调函数呢?
记得在一次C++开发面试的时候被被一位主面官问到过这个问题,现在再回答一遍。
-
我们对回调函数的使用无非是对函数指针的应用,函数指针的概念本身很简单,但是把函数指针应用于回调函数就体现了一种解决问题的策略,一种设计系统的思想。
-
在解释这种思想前我想先说明一下,回调函数固然能解决一部分系统架构问题但是绝不能再系统内到处都是,如果你发现你的系统内到处都是回调函数,那么你一定要重构你的系统。回调函数本身是一种破坏系统结构的设计思路,回调函数会绝对的变化系统的运行轨迹,执行顺序,调用顺序。回调函数的出现会让读到你的代码的人非常的懵头转向。
-
那么什么是回调函数呢,那是不得以而为之的设计策略,想象一种系统实现:在一个下载系统中有一个文件下载模块和一个下载文件当前进度显示模块,系统要求实时的显示文件的下载进度,想想很简单在面向对象的世界里无非是实现两个类而已。但是问题恰恰出在这里,显示模块如何驱动下载进度条?显示模块不知道也不应该知道下载模块所知道的文件下载进度(面向对象设计的封装性,模块间要解耦,模块内要内聚),文件下载进度是只有下载模块才知道的事情,解决方案很简单给下载模块传递一个函数指针作为回调函数驱动显示模块的显示进度。
下面是模拟实现这个文件下载模块的代码,仅供参考【C++实现】
#include ———————————————【指针进阶 · 炼狱篇】 ———————————————
一、再谈指针大小
在【指针初阶】的一开始,我就有讲到过对于指针的大小在32为平台下均为4个字节,在64位平台下均为8个字节上面在学习了各种指针的进阶操作后,我们再来看看
代码:
- 首先给出接下去我要进行对比的代码
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int* Open(int n)
{
int* a = (int*)malloc(sizeof(int) * n);
if (NULL == a)
{
perror("fail malloc");
exit(-1);
}
return a;
}
int main(void)
{
int a = 10;
int* p = &a;
int** pp = &p;
double f = 3.14;
double* ff = &f;
double** fff = &ff;
char ch = 'c';
const char* pc = &ch;
char* const pc2 = &ch;
int a1 = 1;
int b1 = 2;
int c1 = 3;
int d1 = 4;
int e1 = 5;
int* parr[5] = { &a1, &b1, &c1, &d1, &e1 };
int b[5] = { 1,2,3,4,5 };
int(*pb)[5] = &b;
int n = 10;
int* arr = Open(n);
int (*pf)(int, int) = Add;
int (*pfArr[2])(int, int) = { Add, Sub };
int (*(*ppfArr)[2])(int, int) = &pfArr;
printf("%d\n", sizeof(p));
printf("%d\n", sizeof(pp));
printf("%d\n", sizeof(ff));
printf("%d\n", sizeof(fff));
printf("%d\n", sizeof(pc));
printf("%d\n", sizeof(pc2));
printf("%d\n", sizeof(parr));
printf("%d\n", sizeof(pb));
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(pf));
printf("%d\n", sizeof(pfArr));
printf("%d\n", sizeof(ppfArr));
return 0;
}
运行结果:
- x86环境下运行的结果如下

- x64环境下运行的结果如下

【总结一下】:
- 所以,一个指针的大小完全不是取决于它的类型,而是取决于平台,无论你是一级指针、二级指针、指针数组、数组指针等等,只要它在32位平台下,那么均为4个字节。因为在32位平台下,有32个地址总线,那么32位就可以表示【232】的寻址范围,即任何一个值都需要用32个1或0来表示
- “指针需要多大空间,取决于地址的存储需要多大空间”,每一个数据的表示都是32位,1B又等于8b,因此每一块地址都需要【4B】的空间去容纳,又因为在内存中地址值得其实就是指针,这也就是为何在32位平台下指针均为4个字节

二、难题攻坚战
接下去是我在日常学生的作业题里跳出来的一些难题,放在这里与读者一同讨论一番
第一题【指针运算】
下面关于指针运算说法正确的是:( C )
A.整形指针+1,向后偏移一个字节
B.指针-指针得到是指针和指针之间的字节个数
C.整形指针解引用操作访问4个字节
D.指针不能比较大小
解析:
注意:此题说法不明确,整型指针的类型不一定就是int*,可能还有长整型、短整型
A. 错误,因为整型指针的类型为int*,所以 + 1会向后偏移4个字节
B. 错误,两个指针相减,指针必须指向一段连续空间,减完之后的结构代表两个指针之间相差元素的个数
C. 正确,整型指针指向的是一个整型的空间,解引用操作访问4个字节
D. 错误,指针中存储的是地址,地址可以看成一个数据,因此是可以比较大小的
第二题【指针偏移】
下面代码的结果是:( B )
int main()
{
int arr[] = { 1,2,3,4,5 };
short* p = (short*)arr;
int i = 0;
for (i = 0; i < 4; i++)
{
*(p + i) = 0;
}
for (i = 0; i < 5; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
A.1 2 3 4 5
B.0 0 3 4 5
C.0 0 0 0 5
D.1 0 0 0 0
解析:
但就从代码来看,你可以在脑海中模拟一下试试最后的结果会是多少
- 马上我们就来分析洗一下,首先看到一个arr数组,数组里面有5个元素,每个元素的类型都是
int,然后取到arr的数组名,【数组名为首元素地址】,那么它的类型就是int*,但是呢此时我将它的地址转换为short*,即短整型指针,给到对应的指针变量p,接下去通过for循环内部指针的偏移来访问到数组中的内容,对数组的值去进行一个修改,那此时会有几个值发生变化呢?
for (i = 0; i < 4; i++)
{
*(p + i) = 0;
}
- 在【指针初阶】我就有讲过对于指针的类型来说决定了一次可以访问多少个字节,那看到前面是
short,对于短整型来说一次就可以访问两个字节的数据,又因为arr是一个整型数组,里面的每个元素在内存中所占的字节数都是4,那么这个for循环执行了4次后,就访问了8个字节的数据,即前两个数组元素被改成了【0】
真的是这样的吗?我们可以通过【内存】来看看

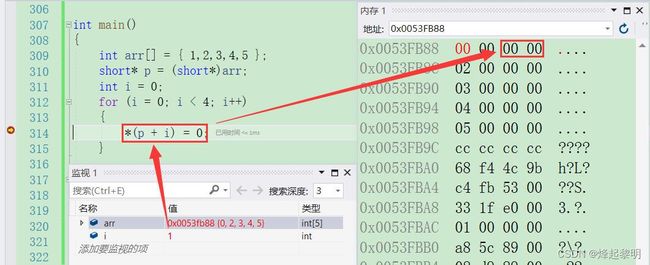


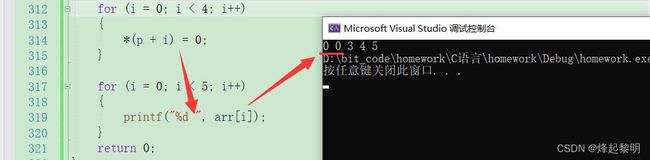
- 通过上面这四张图所对应的for循环四次执行过程,相信你一定明白了为什么访问四次只能改变两个数组元素,就在于
short*类型的指针一次能访问的也就只有2个字节,访问4次是8个字节,那也刚好是2个数组元素的大小
运行结果:
第三题【指针访问字节数】
在小端机器中,下面代码输出的结果是:( C )
int main()
{
int a = 0x11223344;
char *pc = (char*)&a;
*pc = 0;
printf("%x\n", a);
return 0;
}
A.00223344
B.0
C.11223300
D.112233
解析:
- 本题其实和第二题比较类似,变量a是一个十六进制的整数,
&a取出它的地址后类型即为int*,然后将其强转为char*后令指针pc指向这块地址,但是指针pc却无法访问到变量a中所有的数据,因为char*类型的指针解引用一次只能访问1个字节
*pc = 0;
一样,我们还是可以通过观察【内存】来看看*pc究竟修改了多少内容
- 以下我是使用一行显示一个字节,这样可以方便观察修改的情况,因为VS是小端存放的,因此可以观察到原本的
11223344放到内存中变成了44332211

- 可以看到,通过
*pc我们访问到了变量a的第一个字节,并且将其修改为【0】

- 不过这个是在内存中的样子,此时若是要显示打印在屏幕上的话还要将其再做一个转换,所以最后显示的结果便是
11223300

第四题【指针数组】
下面哪个是指针数组:( A )
A.int* arr[10];
B.int* arr[];
C.int **arr;
D.int (*arr)[10];
解析:
- 本题你可能会觉得很简单,完全没有比较讲,但是我在看同学们做下来的情况后,却发现这题也错得蛮多的,所以专门放在这里讲解一下
A. 这个没问题,是最标准的指针数组,arr和[]先结合,表明它是一个数组,数组有10个元素,每个元素都是一个int*类型的指针
B. 你可能会觉得它也是一个指针数组,但是放到VS中去编译一下是编不过的,报出了不允许使用不完整的类型的错误,如果你看不明白这一点的话,说明C语言数组不过关,可以再回去看看,若是在定义数组的时候,没有指定数组大小的话,就一定要为其进行初始化,也就是要给出数组具体的内容,否则编译器都不知道要分配多少空间给他
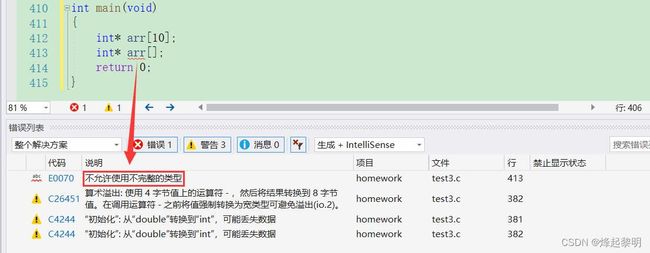
C. 这是一个二级指针,并不是指针数组
D. 对于int (*arr)[10]来说,arr与*相结合了,所以它是一个指针,什么指针呢?朝外一看有一个[],表明这个指针指向一个数组的地址,数组里面有10个元素,每个元素都是的类型都是int。那很明显这就是一个【数组指针】
第五题【数组指针 + 函数指针】
声明一个指向含有10个元素的数组的指针,其中每个元素是一个函数指针,该函数的返回值是int,参数是int*,正确的是( C )
A.(int *p[10])(int*)
B.int [10]*p(int *)
C.int (*(*p)[10])(int *)
D.int ((int *)[10])*p
解析:
A. 错误,()加的地方不对,编译报错,应该是这样int(*p[10])(int*);此时的p为一个数组,数组里面存放都是指针,而且均为函数指针,该函数指针指向的函数返回值是int,参数是int*。但是不符合题意,题面意思是p要为一个指针
B/D. []只能在标识符右边,双双排除
C. p首先和*结合,表明它是一个指针,指针朝外一看,它指向一个数组,数组有10个元素,去掉数组名后,可以看到每个元素的类型,为int(*)(int*),都是一个函数指针,并其他们都指向一个返回值是int,参数是int*的函数。即这是一个【指向函数指针数组的指针】,符合题目意思
三、指针和数组笔试题解析✒
本模块,我将通过
sizeof()与strlen()在指针与数组上的映射,来带你更加深入地理解它们在内存的分布
- 不了解sizeof的可以先了解一下 链接
- 不了解strlen的可以先了解一下 链接
- 数组相关可以先看看这篇文章 链接
sizeof() 是操作符,不是函数,它是用来计算对象或者类型创建的对象所占内存空间的大小
1、简易一维数组
首先第一个先简单一点,来个一维数组练练手 (doge),请你仅通过草稿纸验算的方式,计算出每个结果
代码:
int main(void)
{
//一维数组
int a[] = { 1,2,3,4 };
printf("%d\n", sizeof(a));
printf("%d\n", sizeof(a + 0));
printf("%d\n", sizeof(*a));
printf("%d\n", sizeof(a + 1));
printf("%d\n", sizeof(a[1]));
printf("%d\n", sizeof(&a));
printf("%d\n", sizeof(*&a));
printf("%d\n", sizeof(&a + 1));
printf("%d\n", sizeof(&a[0]));
printf("%d\n", sizeof(&a[0] + 1));
return 0;
}
解析:
算出来了嘛,我们来一一分析一下
- 首先第一点你要知道的就是数组名即为首元素地址,不过有两个例外
sizeof(数组名)—— 数组名表示整个数组,计算的是整个数组的大小,单位是字节&数组名—— 数组名表示数组名表示整个数组,取出的是整个数组的地址,取出的是整个数组的地址
- 除了以上两点外直接出现数组名即为首元素地址
- 首先第一个,a作为数组名单独放在
sizeof内部,此时计算的是数组的总大小,单位是【字节】,数组中有4个元素,每个元素的类型都是int,即4个字节,那结果就是 16
printf("%d\n", sizeof(a));
- 接下去第二个,此时a是并不是单独放在
sizeof内部,而且也没有&,所以数组名a指的就是首元素地址,对于一个地址来说我们在指针初阶部分讲了在内存中就是指针,那对于指针来说即为 4 / 8,在32位平台下运行就是4个字节,在在32位平台下运行就是8个字节
printf("%d\n", sizeof(a + 0));
- 然后第三个,通过观察可以发现,并没有出现
sizeof(数组名)和&数组名这两种形态,所以a就是首元素地址,类型是int*那么*a就是对其进行解引用,获取到的便是【首元素】,类型是int,那一个整型的大小是多少呢?没错,就是 4个字节
printf("%d\n", sizeof(*a));
- 第四个,
a指的是首元素地址,a + 1向后偏移了一个整型,即为第二个元素的地址,那就和第二个一样计算的是一个地址的大小,即指针的大小,为 4 / 8
printf("%d\n", sizeof(a + 1));
- 第五个很简单,就是计算数组中第二个元素的大小,那很简单,就是 4个字节
printf("%d\n", sizeof(a[1]));
- 第六个
&a即为&数组名,取出是整个数组的地址,这个其实我在上面初讲指针的时候有提到过,整个数组的地址其实和数组的首元素的地址是一样的,那么整个数组的地址它也是一个地址,那只要是地址即为 4 / 8个字节
printf("%d\n", sizeof(&a));

- 通俗一些来说,其实地址就像是门牌号一样,那数组中每个元素的地址和整个数组的地址并没有高低贵贱之分,而是,不是说数组的地址就来得高大上一些,它们一视同仁

- 小插曲,我们再来看第七个,第一眼就看到
&a,那么还是一样取出的是整个数组的地址,那对整个数组的地址进行解引用得到的便是整个数组,因为数组的地址是存到到数组指针中的,它的类型即为int (*)[5]- 对一个整型指针解引用获取到的是一个整型
- 对一个字符型指针解引用获取到的是一个字符
- 对一个数组指针解引用获取到的是一个数组
- 那么此时计算的便是一个数组的大小,即为 16,其实你也可以这么去看,
&是取到这个数组的地址,*又对进行解引用,通过这个地址找到找到这里面所存放的内容,这么一来一去就产生了抵消,最后也就变成了sizeof(a),那便是我们上面说到过的,这种sizeof(数组名)的形式,计算的也是整个数组的大小
printf("%d\n", sizeof(*&a));
- 我先说第九个:很明显,就是去计算数组首元素地址的大小,为 4 / 8
printf("%d\n", sizeof(&a[0]));
- 好,下面两个一起说,好做一个对比,
&a[0]上面讲过了,是取出数组首元素的地址,它的类型是int*,那对于一个整型指针来说,以此可以访问的字节数是4个字节,即数组中的一个元素,那么此时它就指向了2这个元素的地址处,它就等价于&a[1];对于&a来说,取出的是整个数组的地址,其类型为int (*)[4],那么它一次性可以访问的字节数即为整个数组的所有元素之和,此时它就指向了4后面的这块地址
printf("%d\n", sizeof(&a[0] + 1));
printf("%d\n", sizeof(&a + 1));
- 可以看到,无论是指向哪里,它们都是一个地址,一个地址的大小就为 4 / 8字节

运行结果:
- 首先在32(x86)为平台下运行试试【指针大小为4个字节】

- 然后在64(x64)为平台下运行试试【指针大小为8个字节】

好,看完整型数组后,我们来看看字符数组
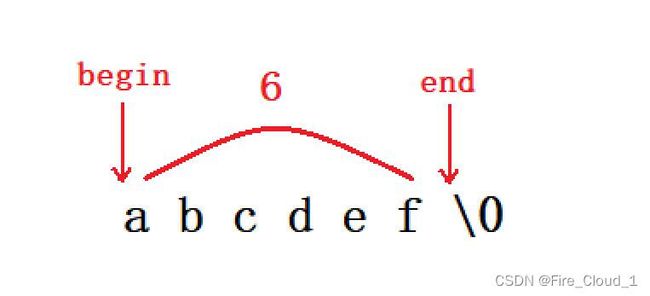
2、不带 ‘\0’ 的字符数组
- 首先你要明确的一点就是这个数组里面有几个元素,在数组章节我就有着重讲到过,若是将一个字符数组定义成如下形式的话,末尾是不会带
\0的,数组会根据初始化的内容来确定它里面的元素个数,所以下面这个数组的数组元素是6个而不是7个
代码:
int main(void)
{
//字符数组
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr + 0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr + 1));
printf("%d\n", sizeof(&arr[0] + 1));
return 0;
}
解析:
- 首先第一个:很明显就是我们上面所提到的特殊模式。因此
sizeof(数组名)计算的就是整个数组的大小,数组有6个元素,每个元素都是char类型的,在内存中占1个字节,那结果就是 6
printf("%d\n", sizeof(arr));
- 第二个:arr并不是单独放在
sizeof中的,那它就是数组名,数组名即为首元素地址,此时计算的就是第一个元素的地址,但只要地址的话即为 4 / 8字节
printf("%d\n", sizeof(arr + 0));
- 第三个:arr既没有单独放在
sizeof中,也没有&,那么它就是首元素地址,对首元素地址进行*解引用,此时获取到的就是首元素,数组的首元素是[a],类型是【char】,那大小即为 1
printf("%d\n", sizeof(*arr));
- 第四个很简单,就是计算数组arr中第一个元素的大小,那也是 1个字节
printf("%d\n", sizeof(arr[1]));
- 那下面这个呢? 很明显看到
&数组名,那么取出的就是整个数组的地址,上面说过了,它还是一个地址,那么就是 4 / 8字节
printf("%d\n", sizeof(&arr));
- 一样的,
&arr取到整个数组的地址,因为其类型是一个数组指针,那么 + 1就跳过一个数组的大小,此时它就指向了字符[f]后面的这个地址,那既然是地址的话也还是 4 / 8字节
printf("%d\n", sizeof(&arr + 1));
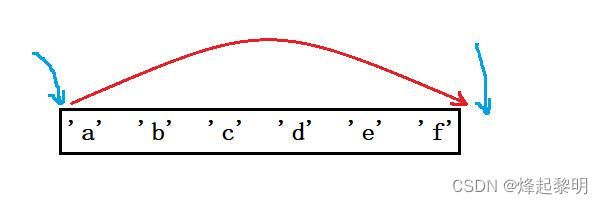
- 最后,
&arr[0]取到的是数组首元素的地址,它的类型是int*,+ 1可以访问4个字节的大小,即为&arr[1],此时它算的还是一个地址的大小,那请说出答案!: 4 / 8字节
printf("%d\n", sizeof(&arr[0] + 1));
运行结果:
- 首先在32(x86)为平台下运行试试【指针大小为4个字节】

- 然后在64(x64)为平台下运行试试【指针大小为8个字节】

看完
sizeof()之后,我们再来看看strlen()
strlen() 是函数,它是用来求字符串长度的,计算的是字符串之前 ‘\0’ 出现的字符个数,如果没有看到 ‘\0’ 会继续往后找
代码:
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr + 0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr + 1));
printf("%d\n", strlen(&arr[0] + 1));
解析:
- 首先来看一下它的内存分布,可以看到它是内存中一块连续的空间,但是因为这个字符数组并没有
\0,所以我们无法确定它的结束标志

- 那么我们首先来看第一个,
arr放在strlen()内部,注意这里并不是sizeof()内部,而且也没有&数组名,所以arr表示的是数组的首元素地址,就是从字符a这个位置开始往后计算这个字符数组的长度,上面说过了,strlen()会向后查找直到\0为止,但是呢又因为这个字符数组内部本身并不存在\0,那它就会继续往后查找,可是对于arr数组后面的这块位置是随机的,是否具有\0是不确定的,因此最终的结果是 随机值
printf("%d\n", strlen(arr));
- 好,接下去第二个其实和第一个是一样的,因为arr是首元素地址,+ 0之后的结果还是一样的,为 随机值
printf("%d\n", strlen(arr + 0));
- arr依旧是首元素地址,那对首元素地址进行解引用获取到的就是【首元素】,首元素就是字符
a,类型是char,但是strlen()要为其传入的是类型为char*的地址,所以strlen就会将a的ASCLL码值97当做地址进行传入
printf("%d\n", strlen(*arr));
- 对于ASCLL码我们它是美国国家标注协会ISO所定义的标准,那在我们C语言中就是已经存在了的,它是属于内存中的一块固定地址,这块地址我们是无法去使用的,内存也不会将其分配给我们,所以此时我们使用strlen()去访问这块地址的时候其实属于非法访问,调试一下看看

- 可以看到我标出的位置
0x00000061这个位置发生了冲突,这是在内存中以十六进制的形式来表示地址,将其转换为十进制表示即为97,那正好对应了我们上面所分析的为strlen()传入了字符a的ASCLL码值97,所以可以看出这块地址确实是无法访问的
- 那如果你清楚了上面这个,其实对于下面的这个也是一样的,
arr[1]这个数组元素也不是一个地址,而是一个字符,此时会将b的ASCLL码值98传入strlen(),那此时我们去访问这块地址的时候也是属于非法访问
printf("%d\n", strlen(arr[1]));
可以看到,最后结果也是 err,通过进制转换可以发现正好与b的ASCLL码值98相对应

- 可以看到,出现了
&数组名的情况,那此时我们就获取到了整个数组的地址,那整个数组的地址和数组首元素的地址是一样的,都位于字符a这个位置,那么从这个位置向后找\0,就和第一题一样是不确定的,字符数组本身不具备\0,其他地址处也可能没有\0,因此最终的结果为 随机值
printf("%d\n", strlen(&arr));

- 在上一题中,
&arr取出了整个数组的地址,它的类型为int (*)[6],是一个数组指针,那一个数组指针 + 1就跳过了整个数组,来到了字符f后面的这块地址处,接着向后查找,去找\0,但结果我们知道,还是一个 随机值,不过这个随机值会比上面的这个随机值少6,因为要减去已经跳过的6个数组元素
printf("%d\n", strlen(&arr + 1));

- 好接下去最后一个,首先取到的是数组的首元素地址,它的类型是
char*,那么 + 1就会跳过一个数组的元素,来到&arr[1]这个为止,即字符b所在的地址处,此时继续向后查找还是一个 随机值,这个随机值会比上面的这个随机值少1,因为要减去已经跳过的1个数组元素a
printf("%d\n", strlen(&arr[0] + 1));

运行结果:
- 这里没有指针,我就直接在32为平台下运行了,将两个结果为err的注释掉后,最终的结果和我们上面分析的是一样的

看完了上面这些,你是否对指针和数组的理解又有了进一步的理解呢坐稳了,下一班车即将到达
3、带 ‘\0’ 的字符数组
好,看完了不带
\0的字符数组后,我们再来看看带\0的字符数组
代码:
- 首先你要清楚的一点是,这个字符数组中有几个元素,可以看到,后面的
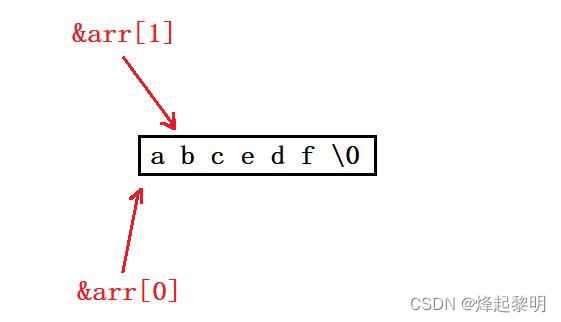
“abcdef”是字符串,对于字符串来说末尾是自带\0的,这个我之前也有通过调试带同学们看过,所以这个数组中有7个元素
int main(void)
{
char arr[] = "abcdef";
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr + 0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr + 1));
printf("%d\n", sizeof(&arr[0] + 1));
return 0;
}
解析:
- 好,首先来看第一个,出现了我们数组的
sizeof(数组名),那么此刻求出的便是整个数组的大小,那上面说到过了这个数组中有7个元素。每个元素都是char类型,所以最后的结果就是 7
printf("%d\n", sizeof(arr));
- 接下去
arr既没有单独出现在sizeof()内部,也没有取地址,那么它指的就是首元素地址,看到如下图所示,一个地址的大小便是 4 / 8个字节
printf("%d\n", sizeof(arr + 0));

- 看到第三个,此时
arr还是代表首元素地址,对其*解引用访问到的就是首元素【a】那么一个char类型的元素在内存中所占的字节数即为 1
printf("%d\n", sizeof(*arr));
- 第四个其实也是一样的,字符数组的第二个元素为【b】,所占的字节数也为 1
printf("%d\n", sizeof(arr[1]));
- 终于看到
&数组名了,此时取出的是整个数组的地址,只要是地址的话即为 4 / 8个字节
printf("%d\n", sizeof(&arr));
- 一样,取出整个数组的地址后,接着向后偏移的话就会跳过一整个数组,那取到的便是
\0后面的这块地址,既然是地址的话,请说出它的大小: 4 / 8个字节
printf("%d\n", sizeof(&arr + 1));

- 最后,也是一样 ,偏移一个字节后来到了字符【b】的位置,其地址的大小也为 4 / 8个字节
printf("%d\n", sizeof(&arr[0] + 1));
运行结果:
- 首先在32(x86)为平台下运行试试【指针大小为4个字节】
- 然后在64(x64)为平台下运行试试【指针大小为8个字节】

看完
sizeof()后,再来看看strlen()是怎样的情况
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr + 0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr + 1));
printf("%d\n", strlen(&arr[0] + 1));
- 首先
arr并没有单独放在sizeof()内部,也没有&,所以数组名代表首元素地址,那从首元素地址往后找\0,最后的结果即为 6
printf("%d\n", strlen(arr));

- 那么首元素地址向后偏移0个字节,还是一样的结果,为 6
printf("%d\n", strlen(arr + 0));
- 下面两个一起来说,过程不再赘述,所传入strlen()都是数组的元素,但是因为strlen()只能接收一个地址,因此会出现非法访问
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));


- 取出整个数组的地址,向后去找
\0,那答案也很明显就是 6
printf("%d\n", strlen(&arr));
&arr取出了整个数组的地址,+ 1 跳过了整个数组,根据上面所讲其为 随机值,而且这个随机值的大小会是原本的减去7,因为跳过了整个数组的所有元素
printf("%d\n", strlen(&arr + 1));
- 从首元素地址向后偏移一个字节,就是
&arr[1],向后遍历碰到\0为止,结果便是 5
printf("%d\n", strlen(&arr[0] + 1));
运行结果:

4、字符指针【⭐】
终于把数组讲完了,接下去我们来“玩玩指针”
代码:
- 首先你要知道的是,这个字符指针p里面存放的是什么?前面我们在【指针进阶·提高篇】中有讲到过,若是将一个字符串给到一个字符指针做接收,那么这个字符指针里面存放的便是字符串中第一个字符的地址

int main(void)
{
char* p = "abcdef";
printf("%d\n", sizeof(p));
printf("%d\n", sizeof(p + 1));
printf("%d\n", sizeof(*p));
printf("%d\n", sizeof(p[0]));
printf("%d\n", sizeof(&p));
printf("%d\n", sizeof(&p + 1));
printf("%d\n", sizeof(&p[0] + 1));
return 0;
}
解析:
- 既然p里面存放的是一个字符的地址,那它也是一个地址,既然是地址的话,就为 4 / 8个字节
printf("%d\n", sizeof(p));
- 因为这个指针p的类型是
char*,所以 + 1会跳过一个char类型的数据,此时就指向了字符串中的第二个字符所在的地址,那也是一样为 4 / 8个字节
printf("%d\n", sizeof(p + 1));
- 接下去两个一起说,对指针p进行解引用,此时就访问到了这块地址中所存放的内容【a】,那么一个
char类型的数据在内存中占1个字节;第二个其实就是【a】,那它们的结果都是一样的,均为 1
printf("%d\n", sizeof(*p));
printf("%d\n", sizeof(p[0]));
来仔细地分析一波它们的原理
- 在数组章节其实有提到过,对于下面这样
int* p = arr;其实【p】与【arr】是等价的,所以在通过for循环访问数组元素的有四种形式 ⇒arr[i] == *(arr + i) == *(p + i) == p[i]
int arr[5] = {1,2,3,4,5};
int* p = arr;
那其实上面的也可以类似地这么去解释 ⇒ *p == *(p + 0) == p[0],它们其实都是等价的
- 好,接下去再来看这个,对指针p再去进行取地址
&的操作,那我们【指针初阶】的时候时候讲二级指针时有说到过,一个一级指针可以接收普通变量的地址,一个二级指针则是可以接收一级指针的地址。那么此刻我对一个一级指针去取地址,它的类型就从char*转变成了char**
printf("%d\n", sizeof(&p));
- 上面我有讲到过,一个指针在【解引用】或者【向后访问】的时候看得是它的指针类型,通过下面这张进行对比就可以很清晰地看出p在进行
&取地址操作后就变成了一个二级字符指针,每次可以访问的数据个数即为一个char*类型。不过最后的结果还是一个地址的大小为 4 / 8个字节

可以再看看这张图

- 看了上面的这些后,相信下面这个你也是手到擒来,因为
&p是一个二级指针类型,+ 1便跳过了一个一级指针的大小,即一个char*的距离,那其实也就是这个字符串,到达了\0的后头,可它还是一个地址,只要是一个地址,大小即为 4 / 8个字节
printf("%d\n", sizeof(&p + 1));
- 但是下面这个就不一样了,因为p指向的是这个字符串的首字符,那
&p[0]就是取出它所在的地址,类型为char*,那么 + 1便跳过了一个char类型的数据,来到了第二个字符的地址处,所以结果还是 4 / 8个字节
printf("%d\n", sizeof(&p[0] + 1));
运行结果:
- 首先在32(x86)为平台下运行试试【指针大小为4个字节】

- 然后在64(x64)为平台下运行试试【指针大小为8个字节】

看完了sizeof(),那一定少不了strlen(),继续发车
代码:
- 首先它的内存布局没有更换,还是上面的这个
printf("%d\n", strlen(p));
printf("%d\n", strlen(p + 1));
printf("%d\n", strlen(*p));
printf("%d\n", strlen(p[0]));
printf("%d\n", strlen(&p));
printf("%d\n", strlen(&p + 1));
printf("%d\n", strlen(&p[0] + 1));
解析:
- 因为p是指向这个字符串的首元素地址,那我们就从这里朝后面找
\0,很明显一下子就找到了,那么最后的结果就是 6
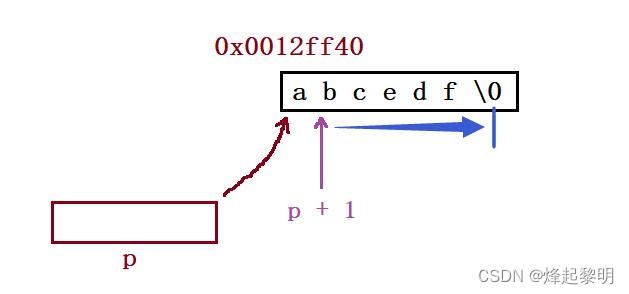
printf("%d\n", strlen(p));

- 那p的类型是
char*,+ 1跳过的就是一个char类型的数据,来到了字符【b】的地址处,向后找\0的话就最后的结果即为 5
printf("%d\n", strlen(p + 1));
- 下面两个也一起说了,如果你上面看得认真的话这里一定很快就能反应过来,
*p取到的就是字符【a】,那我们知道,给strlen()是不可以传入地址之外的其他数,那么这里就会产生非法访问
printf("%d\n", strlen(*p));
printf("%d\n", strlen(p[0]));
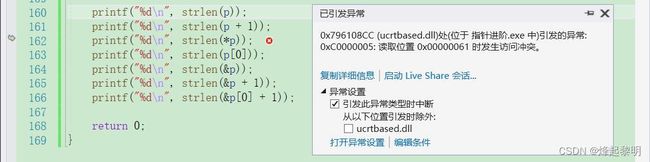

- 接下去,我们来看看
&p,这里一定要看清楚取到的谁的地址,这里并不是字符串的地址,而是指针p自己的地址,但是这个指针p只是存放了字符串首元素的地址,但是并不知道它里面有没有\0,所以在向后遍历的时候并不知何时结束,所以它的结果就是 随机值
printf("%d\n", strlen(&p));

- 然后再来看看
&p + 1,上面说到指针p的类型是char*,在&取地址后它的类型就变成了char**,+ 1便会跳过一个char*类型的数据,那也就是这个字符指针,此时便指向了它末尾的这个位置,从这里向后去进行寻找\0的话还是存在一个不确定的因素,所以最后的结果还是 随机值
printf("%d\n", strlen(&p + 1));
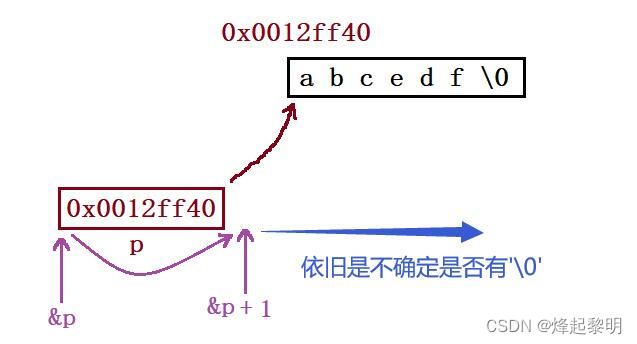
那我现在想问一个问题:上面这个&p和&p + 1所查找的随机值是否存在联系?
- 那有同学说,指针p在内存中占了4个字节嘛,64位就是8个字节,那这不就求出来了吗?其实这样算是有问题的,指针p里面存的什么你知道吗?万一在中间突然出现一个
\0呢,因此这也是不确定的,它们之间并不存在联系
- 第六个其实和第二个是一样的,p里面存放的是【a】的地址,
&p[0]那也是这块地址,+ 1后便指向【b】这块地址了,具体可以参照第二题的图示,最后的结果还是 5
printf("%d\n", strlen(&p[0] + 1));
运行结果:

5、二维数组
最后,我们再来看看比较难以理解的二维数组
- 首先你要清楚下面这个二维矩阵是几行几列的,很明显是三行四列的

- 然后我们再一一来讲说代码
代码:
int main(void)
{
//二维数组
int a[3][4] = { 0 };
printf("%d\n", sizeof(a));
printf("%d\n", sizeof(a[0][0]));
printf("%d\n", sizeof(a[0]));
printf("%d\n", sizeof(a[0] + 1));
printf("%d\n", sizeof(*(a[0] + 1)));
printf("%d\n", sizeof(a + 1));
printf("%d\n", sizeof(*(a + 1)));
printf("%d\n", sizeof(&a[0] + 1));
printf("%d\n", sizeof(*(&a[0] + 1)));
printf("%d\n", sizeof(*a));
printf("%d\n", sizeof(a[3]));
return 0;
}
解析:
- 首先第一个就遇到了我们熟悉的
sizeof(数组名),那计算的就是整个数组的大小,那这是一个二维数组,数组是三行四列的,总共十二个元素,每个元素的类型是int,为4个字节,那么总的大小就是 48
printf("%d\n", sizeof(a));
- 接下去第二个,
a[0][0]代表的是数组第一行第一列的元素,那这很简单,每个元素都是 4个字节
printf("%d\n", sizeof(a[0][0]));
- 这个第三题,为了让读者可以很好地理解,我打算从一维数组开始讲起
- 首先对于下面的一维数组arr,使用
arr[0]、arr[1]、arr[2]便可以访问到数组中的每个元素,因为arr此时就是数组名

那对于二维数组呢?此时想去找到它里面的每个元素该怎么找,这个其实我在数组章节也有说起过
- 我们可以将二维数组的每一行当做它的一个元素,那么下面这个数组就有三个元素,那要去访问到每一行中的每列元素该怎么做呢?此时我们需要使用到数组名,看到右侧的
a[0][j]、a[1][j]、a[2][j],通过对【j】去进行一个控制从而可以访问到每一列上的具体元素,那我们可以将前面的a[0]、a[1]、a[2]看作是一个整体,那它们即为每一行的数组名

- 此时再来看下面这道题就很简单了,因为
a[0]为第一行的数组名,而且它是单独放在sizeof()内部的,所以计算的便是第一行这一整行的大小,里面有4个元素,每个元素都是4个字节,那么结果即为 16
printf("%d\n", sizeof(a[0]));
- 接下去再来看下一个,此时
a[0]并不是单独放在sizeof()内部,所以它指的就是首元素地址,即&a[0][0]这个地址,它的类型是int*,+ 便跳过了一个整型元素,来到了&a[0][1]的位置,那此时计算的就是一个地址的大小,即为 4 / 8个字节
printf("%d\n", sizeof(a[0] + 1));
- 下面这个就是对上一题所取到的
&a[0][1]的地址进行解引用,此时取到的便是这个地址上的元素,去计算一下它的大小便是 4
printf("%d\n", sizeof(*(a[0] + 1)));
- 然后再来分析一下这个,
a并没有单独放在sizeof()内部,也没有进行取地址的操作,所以它指的便是二维数组首元素的地址,那对于一个二维数组来说的首元素是什么呢?也就是第一行,那此时a取到的便是第一行的地址,因为需要存放一个数组的地址,所以它的类型便是一个数组指针类型即int (*)[4],那么一个数组指针 + 1跳过的便是一个数组,此时就来到了二维数组的第二行,取到的便是第二行的地址,但它终究还是个地址,只要是个地址的话大小即为 4 / 8个字节
printf("%d\n", sizeof(a + 1));
- 接下去便是对这一行的地址去进行解引用,那么也就得到了第二行这一整行,此时计算便是这一整行的大小,便为 16
printf("%d\n", sizeof(*(a + 1)));
- 不过呢,对于上面这个其实有另一种思路,那就是我在上面讲字符指针时所说的指针解引用
*与数组[]的转换公式,对于*(a + 1)可以转换为a[1],那这个我在上面有讲到过,即为二维数组第二行的数组名,那将其单独放在sizeof()内部形成sizeof(数组名),计算的也是第二行这整一行的大小
- 好接下去又出现我们前面所提的
&数组名,因为a[0]为第一行的数组名,所以对它进行取地址就取到了这一整行的地址,它的类型也为一个数组指针int (*)[4],那 + 1的话也会跳过整个数组,此时也就来到了第二行,那么取到的便是第二行的地址,地址的大小即为 4 / 8个字节
printf("%d\n", sizeof(&a[0] + 1));
- 讲了这么多,我们这里可以来做一个小总结,如果再去自己观察的话可以发现下面这三个取到的都是二维数组第二行的地址
&a[1]a + 1&a[0] + 1
- 好,接下去我们来看下面这个,这也就是对第二行的地址进行解引用,此时也就取到了第二行,通过上面的总结,你可以将其看做是
sizeof(*&a[1]),那么此时【*】和【&】就可以进行相互抵消变为sizeof(a[1]),这样来看的话其实更加清晰了,因为a[1]是第二行的数组名,sizeof(数组名)计算的便是整个第二行这个一维数组的大小,那结果就是 16
printf("%d\n", sizeof(*(&a[0] + 1)));
- 接下去再来看这个,此时
a并没有单独放在sizeof()内部,也没有进行取地址的操作,那么a所代表的就是首元素地址,即第一行的地址,如果你举得有点难以理解的话可以把*a看作是*(a + 0),那便可以将其转换为a[0],也就是第一行的数组名,sizeof(a[0])计算的便是第一行的大小,结果为 16
printf("%d\n", sizeof(*a));
- 好,来看最后一个,看到下面这个
a[3]有些同学可能会疑惑,这个二维数组不是只有三行吗,第三行的数组名为a[2],那a[3]岂不是越界了!
如果用正常的数组思维确实是这样,但是这个
a[3]放在sizeof()内部却不会出现任何问题,接下去我来讲讲为什么
- 要知道,对于任何一个表达式来说具有2个属性,一个是【值属性】,一个是【类型属性】,例如
3 + 5 = 8,最后的这个8它的值属性就是数字8,类型属性即为int但对于【sizeof()】来说,它在计算的时候只需要知道【类型属性】就可以了,类似我们之前写过的sizeof(int)、sizeof(char)等等,对这些内置类型就可以计算出它的大小,并没有去实际地创造出空间 - 那么对于下面这个
a[3]来说,虽然看上去存在越界,但是sizeof()并不关心你有没有越界,而是知道你的类型即可,那么a[3]便是二维数组的第四行,虽然没有第四行,但是类型是确定的,那么大小就是确定的,计算sizeof(数组名)计算的是整个数组的大小,结果便是 16
printf("%d\n", sizeof(a[3]));
运行结果:

延伸拓展:
对于上面所讲到的
sizeof(),我们再来拓展一下,之前在操作符章节有详细讲过,要时刻sizeof()它并不是一个函数,而是一个操作符!
- 看下面的这段代码,定义了一个
short短整型的变量num,还有一个整型变量a,然后在printf()打印语句中计算了num = a + 5,那最后它的结果会是多少呢?
int main(void)
{
short num = 20;
int a = 1;
printf("%d\n", sizeof(num = a + 5));
printf("%d\n", num);
return 0;
}
- 通过运行结果可以看到,第一个结果是2,第二个结果是20。可能对于这两个结果你都有些诧异,但若是你知道一些规则的话就不会感到奇怪了,对于
sizeof()内部的表达式是不会进行计算的,所以num = a + 5在sizeof()里头根本就不起作用,最后的结果计算的还是num在内存中所占的字节大小,那么对于short短整型来说在内存中所占的字节数为【2】
那可能还是有刨根问底的同学,我再讲得详细一些
-
在程序的编译链接章节有讲过一个
.c到.exe中间会经过【编译】+【链接】,最后才到【运行】,那对于num = a + 5这个表达式来说,是在最后的运行阶段才会去进行计算的,但是sizeof()在计算处理的时候确实在【编译】的环节,此时里面的表达式早就被忽略了,因此最后的值计算的还是变量num

-
那既然这里面的表达式没有执行的话,最后的结果就还是num一开始初始化的样子

四、指针相关历年笔试真题汇总【更新中…】✍
笔试题1
代码:
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int *ptr = (int *)(&a + 1);
printf("%d,%d", *(a + 1), *(ptr - 1));
return 0;
}
//程序的结果是什么?
解析:
来分析一下本题该如何进行计算
- 首先创建了一个整型数组a,里面有5个元素,每个元素都int类型,接着看到下面
&a取出了整个数组的地址,类型为一个数组指针int (*)[5],对它 + 1跳过整个数组来到【5】后面的这块地址处,接着将这个地址强制类型转换为int*,然后由指针ptr指向它 - 然后我们来看输出打印语句,
*(a +1)其实就是a[1],这里要注意,上面只是让ptr指向(int)(&a + 1)的这个地址,然后a并有动,现在的a代表的就是首元素地址,即&a[0],那么 + 1跳过四个字节便指向了数组元素2所在的这块地址,最后解引用便访问到了这块地址上的内容 - 最后的话就是这个
*(ptr - 1),因为其类型为一个整型指针,所以 +/- 1会跳过4个字节,那此时它就指向了数组元素5所在的这块地址,*解引用便访问到了【5】
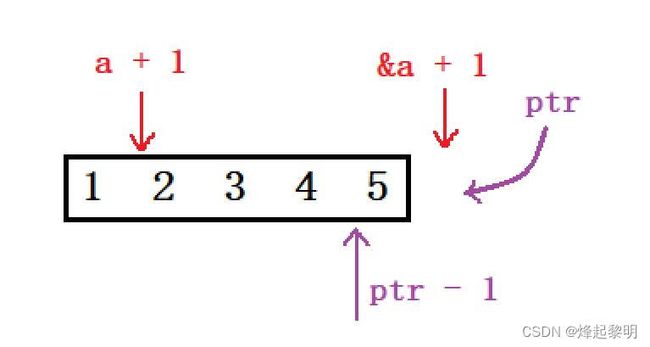
运行结果
- 最后打印结果来看一下

笔试题2
代码:
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
//假设p 的值为0x100000。 如下表表达式的值分别为多少?
//已知,结构体Test类型的变量大小是20个字节
int main()
{
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}
//程序的结果是什么?
解析:
来分析一下本题该如何进行计算
- 首先是给到了一个结构体,然后使用这个结构体定义出来一个结构体指针p,对其进行偏移的操作,那既然是结构体的话,就要先知道其大小,这里题目就给出了为20个字节,如果不懂的同学可以看看校招热门考点 —— 结构体内存对齐
- 相信很多同学一看到这个
0x1就懵了,不知道这是什么东西,0x的话代表一个十六进制,在内存中我们表示地址一般用的都是十六进制。那么题目给出条件说p的值为0x100000,我们知道进制之间是可以相互转换,其实这就是一个整型数值,那p是一个结构体,则怎么能指向一个整型地址呢,于是在三条打印语句的前面,我们还应该加上这句话,将这个地址强制类型转换成一个【结构体指针】类型
p = (struct Test*)0x100000;
- 那接下去我们就来分析一下三条打印语句最后会输出的结果是什么
- 首先是
p + 0x1,对于0x1上面讲到过了是一个十六进制,那它就是十进制的1,这个表达式相当于就是p + 1,此时对一个结构体指针 + 1的话跳过的便是一个结构体,那结构体的大小我们刚才算了是20个字节,转换成十六进制变为【14】,所以最后的结果就是0x100014 - 接下去第二个
(unsigned long)p + 0x1,这里将这个结构体指针p强转成一个无符号的长整型,那么现在这个p就不再是一个指针类型了,它就是一个整型,0x1也是整型,两个整型相加也就是我们小学就学过的计算题,最后的结果便是0x100001 - 最后第三个
(unsigned int*)p + 0x1,这里将这个结构体指针p强转成一个整型指针,然后再 + 1,那指针 + 1我们知道取决于它所指向的元素类型为int,那么 + 1便跳过了4个字节,最后的结果便是0x100004
- 首先是
运行结果
- 最后打印结果来看一下【十六进制会将前面的
0x转换为00】

笔试题3
代码:
int main()
{
int a[4] = { 1, 2, 3, 4 };
int* ptr1 = (int*)(&a + 1);
int* ptr2 = (int*)((int)a + 1);
printf("%x, %x", ptr1[-1], *ptr2);
return 0;
}
解析:
来分析一下本题该如何进行计算
- 本题和第一题其实很类似,也是
&a取到了整个数组的地址,然后 + 1跳过整个数组,再将其强转为int*类型的地址,便可以让ptr1指向这块地址 - 第二个的话就有点新奇了,首先
a既没有单独放在sizeof()内部,也没有&数组名,因此其代表的就是首元素的地址,那有同学就感到很奇怪,把一个地址强转为int,也就整型,真的可以吗?
这当然是可以的,地址我们都是使用十六进制来表示的,强转为整型那其实就是转为十进制
- 我们可以假设它的地址为
0x00000015,强转之后就变成了 21,接下去再对这个整数 + 1那就变成了22,然后看到外面又有一个强制类型转换,转为int*,那也就是再把它转换成一个地址的形式,以十六进制来进行表示,即0x00000016 - 如上你去对比一下上面这两个地址就可以知道,它们之间相差了一个字节的大小,那其实这样的操作使得ptr2指向了数组首元素地址的往后一个字节
光这么说说太抽象了,我们一起来画个图理解一下
- 可以看到,这里我画出了这个数组在内存中的布局,因为放到内存中数组里面的每个数一定是以十六进制的形式来进行存放,即
0x 00 00 00 01、0x 00 00 00 02这样,又因为数组元素在内存中都是连续存放的,所以我们可以将它们放在并排的位置上,而且对于VS来说是以【小端】的形式进行存放,因此可以看出我是倒着画的 - 首先ptr2上面有分析过了,- 1的话往前访问4个字节的数据,那么也就刚好来到了
04这个地方;而对于ptr1来说,它指向的位置则是01向后数一个字节,即00这个位置。又因为这两个指针的类型都是int*,所以在打印的时候可以访问4个字节的数据
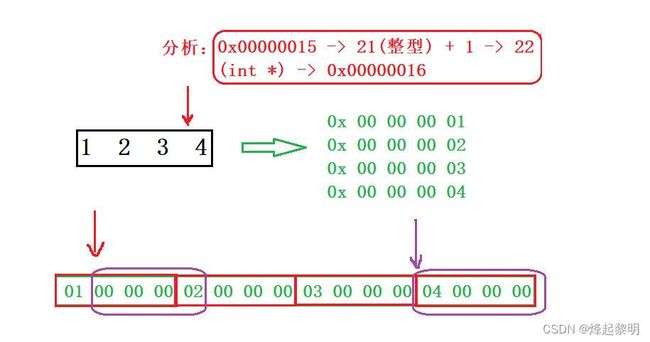
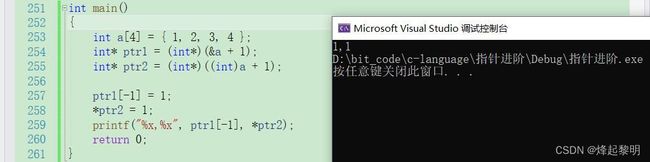
printf("%x, %x", ptr1[-1], *ptr2);
- 现在要使用
printf()将结果打印在屏幕上了,那既然我们以小端的形式倒着存入内存中,拿出来也要以小端的形式倒着拿,那么拿出来后,前者便是02 00 00 00,后者便是00 00 00 04。打印在屏幕上的话就为【200000】和【4】,会自动去除前导的0

运行结果
- 最后打印结果来看一下

延伸拓展【汇编观察】
- 我们在打印语句中加上这两句代码,通过
ptr1和ptr2去修改数组中的一些内容
ptr1[-1] = 1;
*ptr2 = 1;
- 通过汇编可以查看到,数组a在内存中的存放形式,就是将我上图所画的内容分为四行即可

- 接下去可以看到,通过
ptr[-1] = 1这句代码,将数组中第四个元素改成了01 00 00 00,那么从内存中取出来便是00 00 00 01,那也就是【1】

- 那对于ptr2来说,对其进行解引用便可以向后访问四个字节,可以看到数组第一个元素所占的后三个字节和数组第二个元素所占的第一个字节发生了修改【看红色标记】。我也将其改为了1,此时ptr2就实现了指定的字节访问并修改对应数据的操作

来看看最终的结果验证一下,确实就是像我分析的那样
笔试题4
代码:
int main()
{
int a[3][2] = { (0, 1), (2, 3), (4, 5) }; //逗号表达式
int* p; //*p一次访问四个字节
p = a[0];
printf("%d", p[0]); //*(p + 0)
return 0;
}
//程序的结果是什么?
解析:
来分析一下本题该如何进行计算
- 首先可以看到,定义并初始化了一个3行2列的二维数组,然后声明了一个指针,将二维数组的首元素地址即第一行的地址赋给指针p,最后打印
p[0] - 那是否看出哪里有问题呢?其实在第一行代码就出现了问题,仔细观察数组初始化的大括号
{},里面的(0, 1), (2, 3), (4, 5)是二维数组的初始化吗? 如果忘了就在看看数组章节的内容吧,正确的初始化方式应该是{{0, 1}, {2, 3}, {4, 5}};外面是大括号,里面的每行也是大括号
那有同学问:那这个里面的小括号()是什么呢?数组有初始化吗?
- 还记得我们在操作符章节介绍的【逗号】表达式吗?忘了就再去看一下,对于
(0, 1)编译器会将其当做是一个表达式,这整个表达式最后的结果是最后一个逗号后面的表达式,也就是【1】,那对于后面的也是一样,所以数组最后的初始化结果应该是{1, 3, 5}
我们通过画图来理解一下
- 下面就是这个二维初始化完后的样子,因为每行只有2个元素,所以5初始化的就是第二行的第一列。此时再往下看到
p = a[0],那么p就指向了这个二维数组第一行的地址,其实也就是&a[0][0]
p = a[0];

- 此刻再去访问
p[0]的话其实就是访问&a[0][0]这块地址上的内容,它也可以转换成*(p + 0),最后的结果就是【1】
printf("%d", p[0]);
运行结果
- 最后打印结果来看一下

笔试题5
代码:
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}
//程序的结果是什么?
解析:
来分析一下本题该如何进行计算
- 首先声明了一个五行五列的二维数组,还有一个数组指针,这个数组指针指向一个有4个元素,每个元素都是int的数组。接下去把
a赋值给到指针p,a是单独出现的,因此表示的就是首元素地址,即第一行的地址。但是细心的同学一定发现二维数组的每一列都是5个元素,但是数组指针却只能存放有4个元素的一维数组
那这不是乱套了吗?
- 我们通过打印来看看,确实可以看出编译器报出了类型不兼容的问题,但是这不会有很大的影响,既然p只能存放4个元素的一维数组,那最后一个不要不就好了
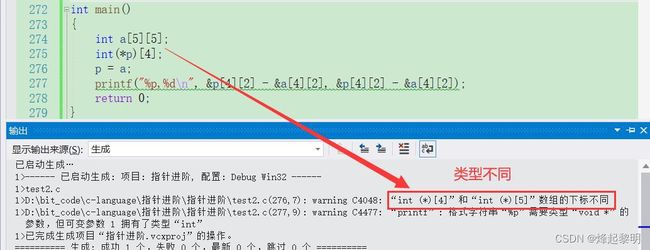
所以其实可以初步感受到本题不是那么容易,接下去我通过画图来进行分析
- 首先看到打印语句中的
&a[4][2],其为a数组第5行第2列的元素所在的地址,在下面我也整个二维数组画成了并排的样子,这其实就是它在内存中真实存放的样子,那我们很快就可以定位到a[4][2]这个元素,然后取到它所在的这块地址 - 那
&p[4][2]呢?刚才我们分析到了指针p只能存放元素个数为4的数组,那在【指针初阶】的时候有讲到过数组指针的类型决定了它所能访问的字节个数,去掉指针名后,我们可以看出它类型是int (*)[4],所以 + 1可以一次向后访问4个字节,那么 + 2,+ 3呢?看看下图就一目了然了

- 接下去我们要去取到
&p[4][2],当数组指针p进行了4次偏移后,我们可以找到p + 4的位置,那根据指针和数组的转换公式可以得知*(p + 4)就可以取到这一行,那*(*(p + 4) + 2)就相当于p[4][2],具体可以看上图,那么对这个数组元素取地址&也就取到了它所在的这块地址
- 最后,我们就要去打印
&p[4][2] - &a[4][2]的结果了,分别是以【%p】和【%d】的形式来进行打印
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
- 那在内存中我们知道,左边是低地址,右边是高地址,那么通过图示就可以看出
&p[4][2]的地址其实是要比&a[4][2]来得小的,那么前者 - 后者的话就会是一个负数,二者都是地址,地址在内存中其实就是指针,那根据前面所学过的知识,两个指针相减计算的是它们之间所相差的元素个数,那么从图中很明显可以看出它们之间相差的元素个数即为 4 - 那么使用
%d进行打印的时候最后的结果就是【-4】

那使用%p进行打印呢?会是什么样子
- 上面也有讲到过,若是使用
%p进行打印的话最后就是以十六进制的形式显示,如果你有自己自己看做数据在计算机内部的存储,那可以知道在计算机内部都是二进制,而且都是以补码的形式在进行计算,不过输出到外设(显示器)上都是以原码的形式 - 所以对于这个【-4】来说,我们要将其以
%p也就是地址的形式打印出来,不过地址不讲究什么原、反、补的概念,所以它会将放到计算机内部的这个补码当做是地址进行打印,那我们还要将一串的二进制序列4位为一组转换成十六进制才可以,那最后的结果便是【FFFFFC】
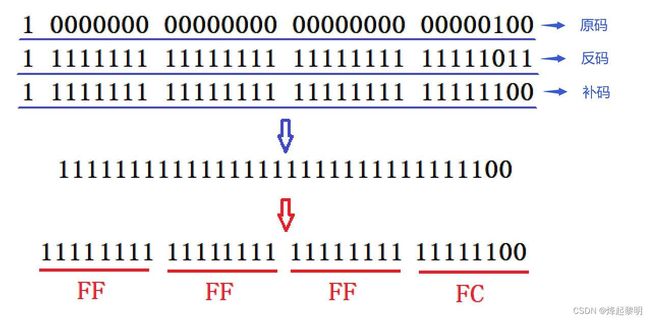
运行结果
- 最后打印结果来看一下

笔试题6
代码:
int main()
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int* ptr1 = (int*)(&aa + 1);
int* ptr2 = (int*)(*(aa + 1));
printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}
//程序的结果是什么?
解析:
来分析一下本题该如何进行计算
- 首先这还是一个二维数组,我依旧是把它画成了内存并排的样子,也是为了能够让读者更加清楚数组在内存中的布局,首先第一个ptr上面也有讲到过很多了,这里便不再赘述;然后是ptr2,
aa即为数组首元素地址,那也就是第一行的地址,其类型为int (*)[5],+ 1跳过一整行,此时也是指向了第二行的地址,再对其进行*解引用也就访问到了第二行,最后再将其转换为int*类型赋给ptr2 - 那么打印语句就很好理解了,
ptr1 - 1指针往前偏移了4个字节,指向了数组元素10所在的这块地址,*解引用也就拿到了【10】,ptr2 - 1也是同理,因为二维数组在内存中也是连续存放的,所以6前面的元素即为5,此时拿到了数组元素【5】

运行结果
- 最后打印结果来看一下

笔试题7
代码:
int main()
{
char* a[] = { "work","at","alibaba" };
char** pa = a;
pa++;
printf("%s\n", *pa);
return 0;
}
//程序的结果是什么?
解析:
来分析一下本题该如何进行计算
- 首先看到有一个数组a,它是一个【指针数组】,数组里面存放的每一个元素都是
char*,从下图可以看来,数组里面的三个指针分别存放三个字符串的首元素地址。接下去又取出这个数组的首元素地址,使pa指向它,此时二级指针pa的类型即为char**,这第一颗*是在告诉我们pa所指向的类型是一个【char*】的地址,这后一个*则是在告诉我们pa它是一个指针

- 那么此时
pa++就跳过了一个【char*】的元素,指向了该指针数组a的第二个元素所在地址,然后又通过*pa解引用找到了第二个元素中的内容,然后一看它也指向一块地址,于是呢就顺着这个地址找到了"at"的【a】在内存中的地址,因为字符串在内存中的空间是连续的,所以最后使用%s就打印出了"at"这个字符串
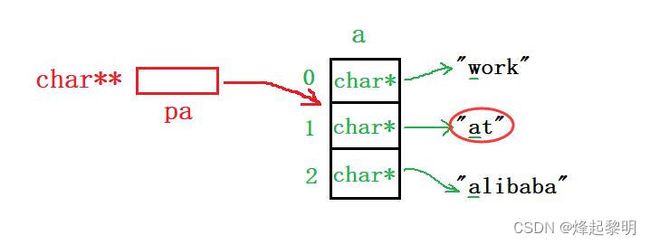
运行结果
- 最后打印结果来看一下

笔试题8【⭐】
最后来一道压轴题,看看你对指针的掌握是否真的透彻了!
代码:
int main()
{
char* c[] = { "ENTER","NEW","POINT","FIRST" };
char** cp[] = { c + 3,c + 2,c + 1,c };
char*** cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *-- * ++cpp + 3);
printf("%s\n", *cpp[-2] + 3);
printf("%s\n", cpp[-1][-1] + 1);
return 0;
}
//程序的结果是什么?
解析:
本题由于比较复杂,所以我全程通过图示来讲解,准备上车
- 首先看到,还是和上题一样,有一个指针数组分别存放了四个字符串的首字符地址,然后接下去,又有一个二级指针数组存放了这个指针数组每一行的地址,而且是倒着存放的,即cp的第一行存放的是c数组第四行的地址,cp的第四行存放的是c数组第一行的地址
- 接下去呢又有一个三级字符指针指向了二级指针数组cp的首元素地址,即第一行的地址
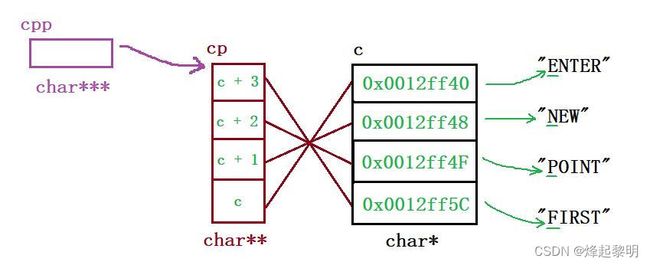
- 首先来看到第一个打印语句,首先
++cpp,那么cpp就会向后访问一个一个char*的元素,来到了cp数组的第二行,接下去第一个*解引用就拿到了c + 2这个地址,那么就顺着这个地址找到了c数组所在的这行地址,然后第二个*解引用则是拿到了c数组这一行的地址中所存放的内容,一看是一个地址,便顺着这个地址找到了P,然后使用%s进行打印最终的结果便是【POINT】
printf("%s\n", **++cpp);
可以看一下动图演示

好,接下去再来看第二个,这句的话应该算是最复杂了,不过我们一一分析也不是什么难事
- 首先看到
++cpp的优先级最高,那么它就来到了cp数组的第三个位置,接下去进行*解引用,就拿到了这一行数组中的内容,即c + 1,接下去又进行了一个操作是--,那也就是对我们取出的c + 1进行运算即c + 1 - 1 = c,那么此时里面存放的就不再是c + 1这块地址,而是c这块地址,顺藤摸瓜找到了这块地址后再对其进行解引用,此时也就找到了E所在的地址,最后再 + 3即向后偏移3个字节也就是3个字符,就来到了后面的E所在的位置,使用%s进行打印便打印出了后面的【ER】
printf("%s\n", *-- * ++cpp + 3);
看一下动图演示

好,接下去第三句打印,我们再来看看
- 首先对于下面的表达式可以写成这种形式
* *(cpp - 2) + 3,意思就是先让cpp向前偏移2个char**的位置,然后找到这个地址中所存放的值为c + 3,顺着这个地址找到了数组c这一行所在的地址,可以看到最前面还有一个*解引用,那么就获取到了字符F的地址,最后再 + 3然后以%s的形式打印,结果便是【ST】
printf("%s\n", *cpp[-2] + 3);
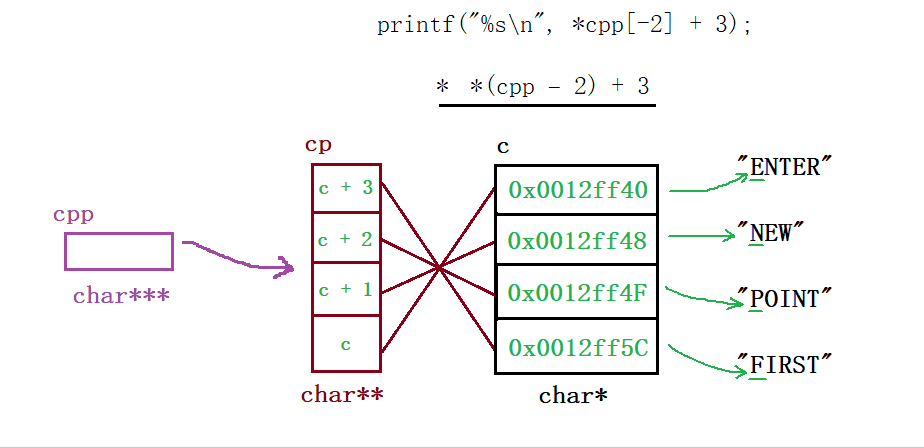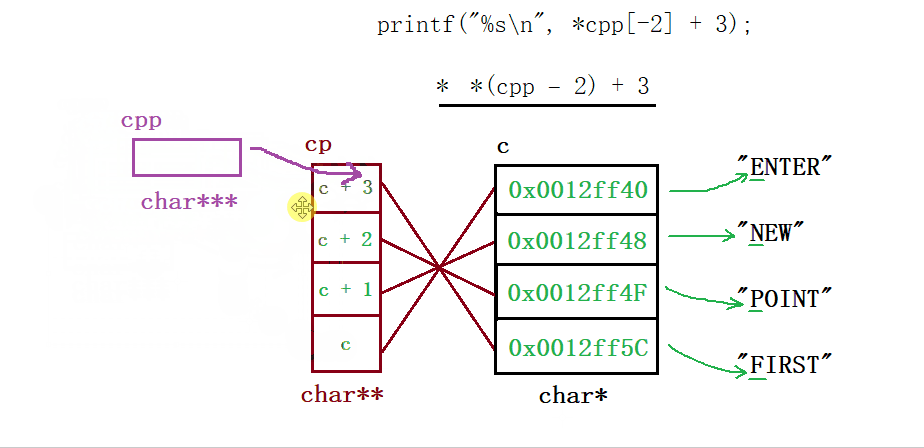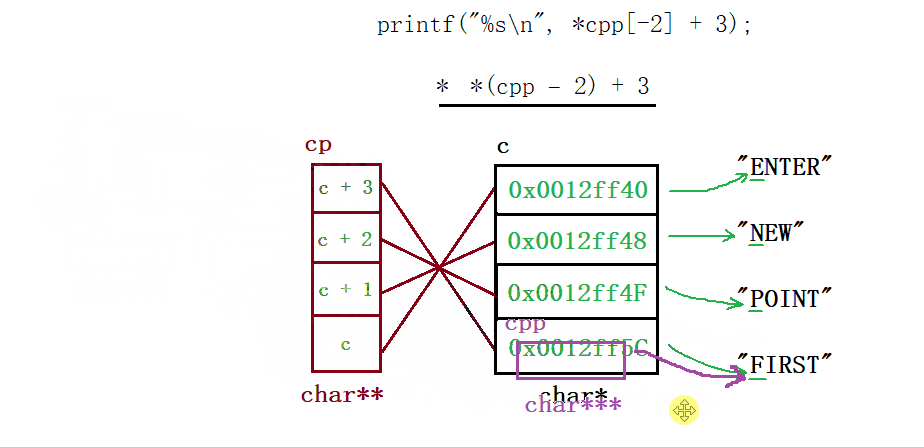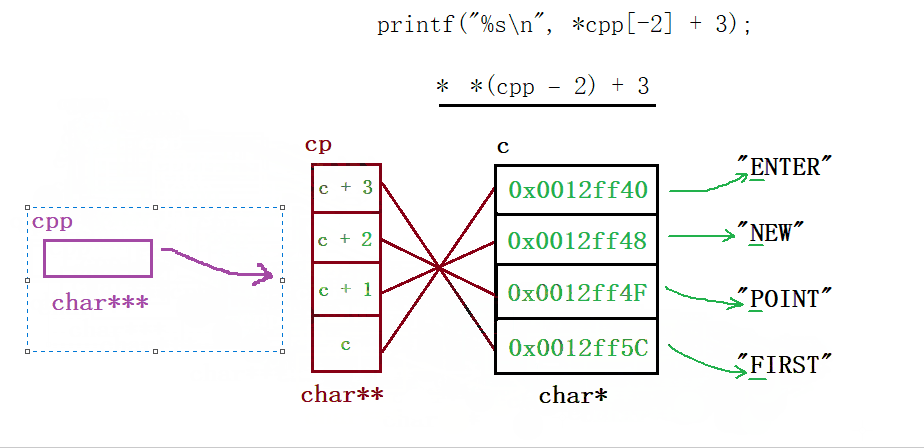
来看最后一个,对指针的功底也要很深厚✒
- 对于下面的表达式可以写成
*(*(cpp - 1) - 1) + 1,那么首先就是将cpp向前偏移一个char**的位置【注意上一题cpp的移动不会影响此题】,然后对其进行*引用拿到cp数组第二行的内容,为c + 2,接下去对这个内容再 - 1,即为c + 2 - 1 = c + 1,那么此时它便指向了数组c中c + 1的这块,然后别忘了最前面还有一个*解引用,那么此时就拿到了c + 1这块地址中所存放的内容,是一个地址,继续顺藤摸瓜便找到了N,但是最后还有一个 + 1,那么就偏到了E,以%s进行打印最后的结果即为【EW】
printf("%s\n", cpp[-1][-1] + 1);
运行结果
- 最后打印结果来看一下【全体起立!!!】
视频解说
这里附上这道题的视频讲解版,上传到b站了,同学们可自己配合文章观看学习
图解指针笔试题【步步教学,通俗易懂】
—————————————————【总结篇】 —————————————————
✍总结与提炼
好,来总结一下本文学习到的内容
【指针初阶 · 入门篇】
在初阶篇中我们初步认识了什么是指针,主要照顾到对指针不够了解的同学,可以先有一个基本的概念
- 首先我们了解了什么是指针,知道了【指针】、【地址】、【内存】三者之间的关系,清楚了内存中的指针和我们口头上所说的指针有和区别。还记得一个指针是几个字节吗❓
- 初步认识指针后我们进一步加深了对指针的理解,明白了不同类型的指针所存在的意义:1.访问字节的范围 2.类型决定步长。然后我们就来谈了谈【野指针】,知道了在写代码的时候为何会产生野指针,也明白了如何对野指针去进行一个规避
- 对指针有了一个理解后便开始上手操作指针,使用指针去进行一个运算。当然也清楚了指针和数组之间的关联
- 最后呢我们浅浅地谈了谈二级指针,知道了什么是二级指针,以及它和指针与普通变量之间的区别;
【指针进阶 · 提升篇】
在进阶篇中我们对指针有了进一步的认识,清楚了字符指针的作用,辨析了指针常量与常量指针、指针数组与数组指针、指针函数与函数指针
- 对于字符指针而言,它既可以指向单个字符,也可以指向一个字符串,其保存的便是这个字符串首字符的地址。有了这些基础知识后,我们就做了一道【剑指offer】的题目,还记得常量字符串的地址在内存中保存几份吗
- 听说
*和const也会擦出火花 对于指针常量来说,指针自己就是一个常量,不可以修改它的指向,但却可以修改其所指向地址中的内容,例:int* const p;对于常量指针来说,其所指向的地址中的内容是一个常量,不可修改,但却可以去修改它的指向,例:const int* p。有记忆口诀后相信很快分清它们之间的区别了。最后,还记得为了买一份凉皮而分手的情侣吗 - 指针还是数组真是傻傻分不清 对于指针数组来说,它是一个【数组】,数组里面存放的每一个元素都是指针,例:
int* arr[5];对于数组指针来说,它是一个【指针】,这个指针所指向的是一个数组的地址,例:int (*p)[5]- 有了这些基础知识后,将指针与数组同函数去进行一个结合,实现一个传参,最好每一个下去都自己思考着想一遍,应该传递什么样的实参,形参又用什么来接受,是一级指针呢,还是二级指针?是指针数组呢,还是数组指针?
- 接下去,真正地将指针融入到了函数中。首先我们讲了简单一些的指针函数,它就是一个普通的函数,只是返回类型是一个指针。不过要小心,我们不可以返回函数内部所申请的临时空间,因为它除了当前函数的作用域就销毁了,因此我特意在堆上去申请空间。例:
int* Open(int, int) - 然后就是较难理解的函数指针了,它本质是一个指针,所指向的是一个函数的地址,例:
int (*p)(int, int) = &Add当然你在把函数的一直给到指针的时候也可以不加&,那也就相当于是【赋值】了,因此在使用函数指针我们可以不加前面的*,原本的调用形式是(*p)(3, 4),但你也可以写成p(3, 4)。 - 有了上面的基础知识后,我讲解了两道《C陷阱与缺陷》中的代码题,听完我的分析后你还对它们存在恐惧吗
(*(void (*)())0)();void (*signal(int, void(*)(int)))(int); - 指针和数组又碰到一起了,原来还有存放函数指针的数组,这简直是太奇妙了。有了它,在面对多个函数逻辑的时候,我们不需要再写一个庞大的switch…case语句,而是直接使用【函数指针数组】存放这些函数的地址,这样就可以通过数组下标的控制去访问对应的函数了,例:
int (* pfArr[2])(int, int) = {Add, Sub};还记得我们实现的 转移表 吗? - 那既然有数组指针这个东西,可以存放一个数组的地址,那我们上面所说的函数指针数组的地址也可以存放到一个指针中去,它就叫做【指向函数指针数组的指针】,既然它是一个指针,就要和
*先结合,我们不需做太大的改动,只需要在函数指针数组的基础上给指针名ppfunArr前面加上一个*即可,不过为了防止其和[]先结合记得加上()哦。例:void (*(*ppfunArr)[5])(const char*) = &pfunArr; - 提升篇的末尾,我又讲了一个东西叫做【回调函数】,它是函数指针的一个经典应用,在实际开发的场景中也是被广泛地使用。我们可以将一个函数的地址传递给另一个函数,那这就需要另一个函数提供一个函数指针的参数。在这个函数内部,如是在某种特定条件成立的情况下,我们便可以通过这个函数指针去找到这个函数的地址,那么此时这个被调用的函数就被称为回调函数。知道了这些后,还记得回调函数使用的三种场景吗?
- [ 场景一 ]:模拟计算器的加减乘除。这里我们没用用到函数指针数组,而是将一开始的计算器做了一个修改
- [ 场景二 ]:模拟qsort函数。这个场景尤为重要,我画了大量的精力进行讲解,配合图示,希望读者可以理解回调函数被调用的整个流程
- [ 场景三 ]:模拟文件下载模块。这个算是拓展模块,如果有学习过C++的同学可以看看,是一家公司某年的面试题
【指针进阶 · 炼狱篇】
在炼狱篇中我们对指针有了更加深层次的一个理解,主要是围绕指针与数组混搭的一些笔试题来进行学习
- 首先的话我们又去看了看指针的大小,此时不仅仅是一开始的整型指针、字符型指针,我们还去观察了指针常量、常量指针、指针数组、数组指针、指针函数、函数指针以及二级指针等等,同是在32位平台下进行运行,它们的大小均为4个字节
- 有了上面这些基础后,我们就可以进行大量的练习了,首先我给出了作业题中错的多而且需要经过一定的思考才可以做出来的一些题目,若是你仔细地看了这几道题的话,对指针运算、指针偏移、指针访问字节数、指针数组、数组指针以及函数指针的理解一定又能更上一层楼
- 接下去,我们就进入了笔试题的学习,首先的话我们通过【数组与指针】的混合来辨析
sizeof()和strlen()之间的区别,通过回顾了前面的字符指针、字符数组、一维数组、二维数组,来很好地明确指针的大小是多少、一个数组元素的大小是多少、一个数组的大小又是多少,以及指针 + 1可以跳过几个字节,可以访问到后面的多少数据 - 最后的话,我们就来到了指针相关历年笔试真题的学习,通过八道笔试真题的演练,相信你也清楚了指针在实际的校招中是如何去进行考察的,若是没有像我这样一步步地分析、画图、调试,想要解出来这些题目还是比较困难的,尤其是最后一题,涉及到三级指针,因此我专程录了一个视频做讲解,希望读者可以理解
推荐书籍阅读
第一本:《C和指针》
本书给出了很多编程技巧和提示,每章后面有针对性很强的练习,对初学指针的同学非常友好,推荐先行阅读

第二本:《C陷阱与缺陷》
本书分别从词法分析、语法语义、连接、库函数、预处理器、可移植性缺陷等几个方面分析了C编程中可能遇到的问题,适合有一定开发基础的C程序员进行阅读

第三本:《深入理解C指针》
本书专门研究指针,旨在提供比其他图书更全面和深入的C 指针和内存管理知识,适合进阶阅读学习

以上就是本文要阐述的所有内容,我花了两个月的时间整理了本文,诣在帮助广大读者可以真正学懂指针,了解指针,知道指针其实并不是那么可怕的,只要你去学会去理解、通过画图思考分析,总能够明白一些 你,也是可以学好指针的
非常感谢您对本文的阅读,如果疑问可于评论区提出或者私信我
