Python爬虫Scrapy(二)_入门案例

入门案例
学习目标
- 创建一个Scrapy项目
- 定义提取的结构化数据(Item)
- 编写爬取网站的Spider并提取出结构化数据(Item)
- 编写Item Pipelines来存储提取到的Item(即结构化数据)
一、新建项目(scrapy startproject)
- 在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
scrapy startproject cnblogSpider
- 其中,cnblogSpider为项目名称,可以看到将会创建一个cnblogSpider文件夹,目录结构大致如下:
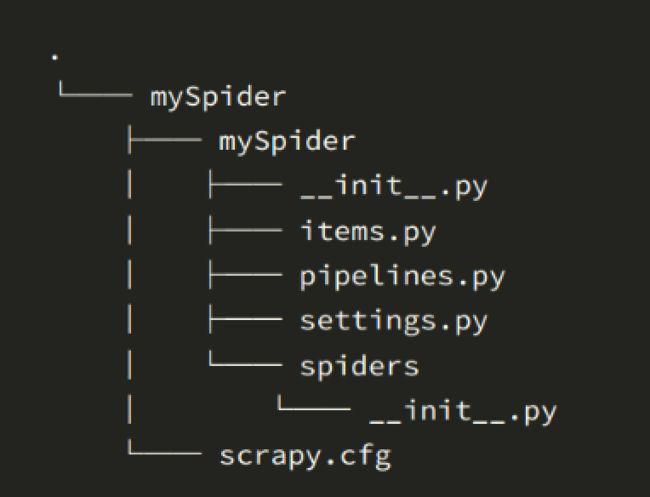
scrapy.cfg:项目部署文件 cnblogSpider/: 该项目的python模块,之后可以在此加入代码 cnblogSpider/items.py: 项目中的item文件。 cnblogSpider/pipelines.py: 项目中的Pipelines文件。 cnblogSpider/settings.py: 项目的配置文件。 cnblogSpider/spiders/: 放置Spider代码的目录。
二、明确目标(mySpider/items.py)
我们打算抓取:“http://www.cnblogs.com/miqi1992/default.html?page=2” 网站里博客地址、标题、创建时间、文本。
- 打开cnblogSpider目录下的items.py
- item定义结构化数据字段,用来保存爬取到的数据,有点像Python中的dict,但是提供了一些额外的保护减少错误。
- 可以通过创建一个scrapy.item类,并且定义类型为scrapy.Field的类属性来定义一个Item(可以理解成类似于ORM的映射关系)。
- 接下来,创建一个CnblogspiderItem类,和模型item模型(model)。 ```python import scrapy
class CnblogspiderItem(scrapy.Item): # define the fields for your item here like: url = scrapy.Field() time = scrapy.Field() title = scrapy.Field() content = scrapy.Field() ```
三、制作爬虫(spiders/cnblogsSpider.py)
爬虫功能主要分两步:
1. 爬数据
- 在当前目录下输入命令,将在
cnblogSpider/spiders目录下创建一个名为cnblog的爬虫,并制定爬取域的范围: scrapy genspider cnblog “cnblogs.com” - 打开
cnblogSpider/spiders目录下的cnblog,默认增加了下列代码: ```python -- coding: utf-8 -- import scrapy
class CnblogSpider(scrapy.Spider): name = ‘cnblog’ allowed_domains = [‘cnblogs.com’] start_urls = [‘http://cnblogs.com/’]
def parse(self, response):
pass
```
其实也可以由我们自行创建cnblog.py并编写上面的代码,只不过使用命令可以免去编写固定代码的麻烦
要建立一个Spider,你必须用scrapy.Spider类创建一个子类,并确定了三个强制的属性和一个方法。
-
name = "": 这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。 -
allow_domains=[]: 是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。 -
start_urls=():爬取的URL元祖/列表。爬虫从这里开始爬取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。 -
parse(self, response):解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:
- 负责解析返回的网页数据(respose.body),提取结构化数据(生成item)
- 生成需要下一页的URL请求
将start_urls的值改为需要爬取的第一个url:
start_urls=("http://www.cnblogs.com/miqi1992/default.html?page=2")
修改parse()方法
def parse(self, response):
filename = "cnblog.html"
with open(filename, 'w') as f:
f.write(response.body)
然后运行一下看看,在cnblogSpider目录下运行:
scrapy crawl cnblog
是的,就是cnblog,看上面代码,它是CnblogSpider类的name属性,也就是scrapy genspider命令的唯一爬虫名。
运行之后,如果打印的日志出现[scrapy]INFO: Spider closed(finished),代表执行完成。之后当前文件夹中就出现了一个cnblog.html文件,里面就是我们刚刚要爬取的网页的全部源代码信息。
#注意,Python2.x默认编码环境是ASCII,当和取回的数据编码格式不一致时,可能会造成乱码;
#我们可以指定保存内容的编码格式,一般情况下,我们可以在代码最上方添加:
import os
reload(sys)
sys.setdefaultencoding('utf-8')
#这三行代码是Python2.x里面解决中文编码的万能钥匙,警告这么多年的吐槽后Python3学乖了,默认编码是Unicode了
2.爬数据
- 爬取整个网页完毕,接下来就是取过程了,首先观察页面源码:
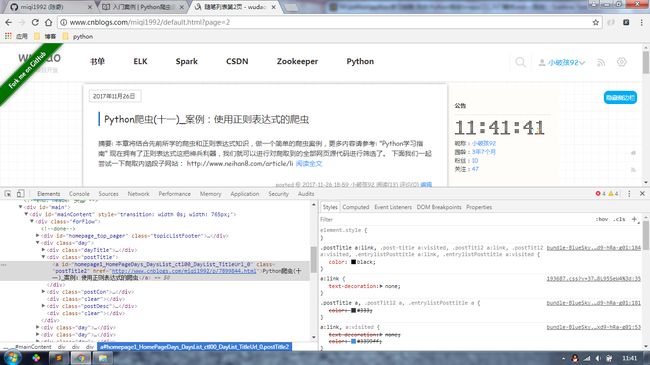
<div class="day">
<div class="dayTitle">...</div>
<div class="postTitle">...</div>
<div class="postCon">...</div>
</div>
- XPath表达式如下:
- 所有文章:.//*[@class=‘day’]
- 文章发表时间:.//*[@class=‘dayTitle’]/a/text()
- 文章标题内容:.//*[@class=‘postTitle’]/a/text()
- 文章摘要内容:.//*[@class=‘postCon’]/div/text()
- 文章链接:.//*[@class=‘postTitle’]/a/@href
是不是一目了然?直接上XPath开始提取数据吧。
- 我们之前在cnblogSpider/items.py里定义了一个CnblogItem类。这里引入进来 from cnblogSpider.items import CnblogspiderItem
- 然后将我们得到的数据封装到一个
CnblogspiderItem对象中,可以保存每个博客的属性: ```python
form cnblogSpider.items import CnblogspiderItem
def parse(self, response): # print(response.body) # filename = “cnblog.html” # with open(filename, ‘w’) as f: # f.write(response.body)
#存放博客的集合
items = []
for each in response.xpath(".//*[@class='day']"):
item = CnblogspiderItem()
url = each.xpath('.//*[@class="postTitle"]/a/@href').extract()[0]
title = each.xpath('.//*[@class="postTitle"]/a/text()').extract()[0]
time = each.xpath('.//*[@class="dayTitle"]/a/text()').extract()[0]
content = each.xpath('.//*[@class="postCon"]/div/text()').extract()[0]
item['url'] = url
item['title'] = title
item['time'] = time
item['content'] = content
items.append(item)
#直接返回最后数据
return items
```
- 我们暂时先不处理管道,后面会详细介绍。
保存数据
scrapy保存信息的最简单的方法主要有四种, -o 输出指定格式的文件,命令如下:
#json格式,默认为Unicode编码
scrapy crawl cnblog -o cnblog.json
#json lines格式,默认为Unicode编码
scrapy crawl cnblog -o cnblog.jsonl
#csv逗号表达式,可用excel打开
scrapy crawl cnblog -o cnblog.csv
#xml格式
scrapy crawl cnblog -o cnblog.xml
思考
如果将代码改成下面形式,结果完全一样
请思考yield在这里的作用:
form cnblogSpider.items import CnblogspiderItem
def parse(self, response):
# print(response.body)
# filename = "cnblog.html"
# with open(filename, 'w') as f:
# f.write(response.body)
#存放博客的集合
# items = []
for each in response.xpath(".//*[@class='day']"):
item = CnblogspiderItem()
url = each.xpath('.//*[@class="postTitle"]/a/@href').extract()[0]
title = each.xpath('.//*[@class="postTitle"]/a/text()').extract()[0]
time = each.xpath('.//*[@class="dayTitle"]/a/text()').extract()[0]
content = each.xpath('.//*[@class="postCon"]/div/text()').extract()[0]
item['url'] = url
item['title'] = title
item['time'] = time
item['content'] = content
# items.append(item)
#将获取到的数据交给pipelines
yield item
#直接返回最后数据,不经过pipelines
#return items
更多Python的学习资料可以扫描下方二维码无偿领取!!!

1)Python所有方向的学习路线(新版)
总结的Python爬虫和数据分析等各个方向应该学习的技术栈。

比如说爬虫这一块,很多人以为学了xpath和PyQuery等几个解析库之后就精通的python爬虫,其实路还有很长,比如说移动端爬虫和JS逆向等等。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然达不到大佬的程度,但是精通python是没有问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

。