KNN算法
1.原理版
import numpy as np
import operator
def DataSet():
group = np.array([[3,104],[2,100],[1,81],[101,10],[99,5],[98,2]])
labels = ['爱情片','爱情片','爱情片','动作片','动作片','动作片']
return group,labels
def KNN(in_x,x_labels,y_labels,k): #in_x是要预测的数据,x_labels是训练数据,y_labels是训练数据的标签,k为k近邻
x_labels_size = x_labels.shape[0] #获得行数 6
distances = (np.tile(in_x,(x_labels_size,1)) - x_labels)**2 #np.tile的作用是把in_x弄成6行1列的数组,然后对应位置相加减再平方
ad_distances = distances.sum(axis=1) #按列相加求和
sq_distances = ad_distances ** 0.5 #开方,得到欧式距离
ed_distances = sq_distances.argsort() #对欧式距离排序,返回索引,就像按学号公开成绩排名
classdict = {}
for i in range(k):
voteI_label = y_labels[ed_distances[i]] #得到排序对应的标签值
classdict[voteI_label] = classdict.get(voteI_label,0) + 1 #计数,统计前k个里爱情片和动作片的数量
sort_classdict = sorted(classdict.items(),key=operator.itemgetter(1),reverse=True) #对classdict.items()进行排序,运用到了operator库
return sort_classdict[0][0]
if __name__ == '__main__':
group,labels = DataSet()
test_x = [18,99]
print('输入数据所对应的类别是:{}'.format(KNN(test_x,group,labels,3)))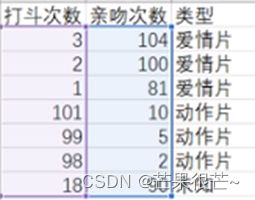
2.代码版
def load_data(folder,domain):
from scipy import io
import os
data = io.loadmat(os.path.join(folder,domain + '_fc6.mat'))
return data['fts'],data['labels']
def knn_classify(Xs,Ys,Xt,Yt,k=1):
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
model = KNeighborsClassifier(n_neighbors=k)
Ys = Ys.ravel() #ravel()是 NumPy 数组的方法,用于将多维数组展平为一维数组。
Yt = Yt.ravel()
model.fit(Xs,Ys) #基于训练数据Xs,Ys拟合model
Yt_pred = model.predict(Xt) #用训练好的model对测试数据 Xt预测
acc = accuracy_score(Yt,Yt_pred) #accuracy_score 是一个用于计算分类准确率的函数,预测正确的样本数与总样本数之间的比例
print('Accuracy using kNN :{:.2f}%'.format(acc * 100))
if __name__ == "__main__":
folder = './dataset/office31-decaf'
src_domain = 'amazon' #包括两个表格,一个名称为fts,一个表格名称为labels
tar_domain = 'webcam'
Xs,Ys = load_data(folder,src_domain)
Xt,Yt = load_data(folder,tar_domain)
print('Source:',src_domain,Xs.shape,Ys.shape)
print('Target:',tar_domain,Xt.shape,Yt.shape)
knn_classify(Xs,Ys,Xt,Yt)