Numpy库
Numpy库入门
一维数据:由对等关系的有序或无序数据构成,采用线性方式组织。
二维数据由多个一维数据构成,是一维数据的组合形式。(表格)
多维数据由一维或二维数据在新维度上扩展形成。


Numpy:开源的Python科学计算基础库,是SciPy、Pandas等数据处理或科学计算库的基础. Numpy的引用:import numpy as np
NumPy的数组对象:ndarray(在程序中的别名是array).
np.array( )输出( )里的数据,若( )里由多个数据需要先组织起来,输出成[ ]形式的数组,元素之间由空格分隔。
np.array()与列表类型不同!,列表中元素间用逗号分隔,np.array()数组中元素用空格分隔,但以列表形式组织。
import numpy as np
a = np.array((1.0,2.0,3.0),dtype=int)
print(a.dtype) #int32
print(a) #[1 2 3]
b = np.array([[1,2,3],[4,5,6]])
print(b)
print(b.ndim) #2 #输出维度(秩),如1或2或3……
print(b.shape) #(2,3) #输出数组形状,(m,n)m行n列
print(b.size) #6 #输出元素个数
[[1 2 3]
[4 5 6]]


numpy是表达N维数组的最基础库。把n维数组看成简单的数据对象,可直接进行操作和运算,所以要求数据类型相同,也助于节省运算和存储空间。而列表是逐个读取数据,故列表的数据类型可以不同。
ndarray的属性
!不是方法,直接.属性,不用在后面加()


ndarray的元素类型


comples64:复数类型,实部和虚部都是32位浮点数;complex128:复数类型,实部和虚部都是64位浮点数。
numpy为啥要支持这么多种数据类型?python仅支持整数、浮点数和复数3种类型;科学计算涉及数据多,对存储和性能由较高要求;元素类型的精细定义,利于存储空间及性能优化,助于程序员评估程序规模。在创建ndarray数组时可设定数据类型。
ndarray数组的创建

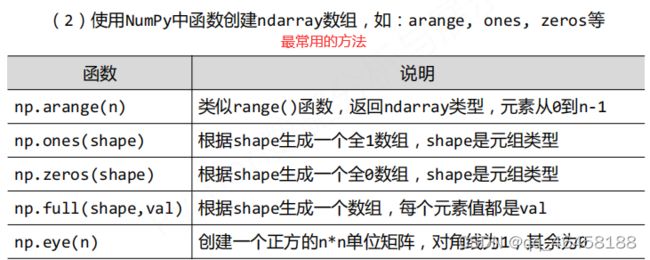


np.ones_like(a):根据数组a的形状生成一个全为1的数组;np.zeros_like(a):根据数组a的形状生成一个全为0的数组;np.full_like(a,val):根据数组a的形状生成一个数组,每个元素值都是val;在科学计算中一般获得的是浮点数(如温度值、声音值)


ndarray数组的变换
维度变换:
.reshape(shape):不改变数组元素,返回一个shape形状的数组,原数组不变;.resize(shape):与前者一致,但修改原数组.swapaxes(ax1,ax2):将数组n个维度中两个维度进行调换;.flatten( ):数组降维,返回折叠后的一维数组,原数组不变。


import numpy as np
a = np.ones((3,4)).reshape(-1,6) #reshape中的-1是指:不知道多少行,但有6列
print(a)
#[[1. 1. 1. 1. 1. 1.]
# [1. 1. 1. 1. 1. 1.]]数据类型变换 .astype( ) 向列表的转换 .tolist( )


ndarray数组的操作
索引:获取数组中特定位置元素的过程;切片:获取数组元素子集的过程[ , ],如果是二维数据,切片中会有两个数。



ndarray数组的运算(一元/二元函数)
对数组的运算就是对数组中每一个元素进行运算

Numpy的一元函数(对一个数组运算的函数)

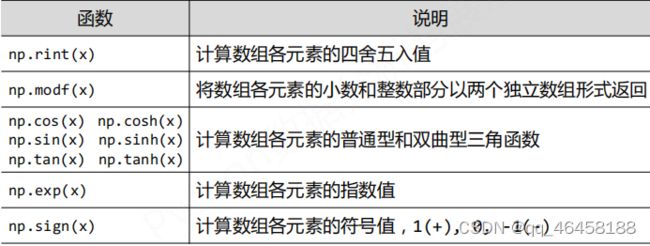

Numpy的二元函数( 对两个数组进行运算的函数)
+ - * / **:两个数组各元素进行对应运算;np.maximum(x,y)、np.minimum(x,y)元素级最大值、最小值计算
np.mod(x,y):元素级的模运算;np.copysign(x,y):将y中各元素值的符号赋值给x对应元素;< > >= != == 算数比较,产生布尔型数组

Numpy数据存储与函数
数据CSV文件存取(一维/二维)


%d:整数;%1f:一位小数的浮点数类型;


np.savetxt('a.csv',a),没有delimiter参数和fmt参数。 np.savetxt('b.csv',a,fmt='%.1f'),没有delimiter参数。
np.savetxt('c.csv',a,fmt='%d',delimiter=' '),delimiter参数为空格;np.savetxt('d.csv',a,fmt='%d',delimiter=',')delimiter参数为,
np.loadtxt('a.csv') ;data = np.loadtxt('a.csv',delimiter=',');data = np.loadtxt('a.csv',delimiter=',',dtype=int)
np.loadtxt默认输出德类型为float,即使没有dtype=float
这种程序无法简单用.loadtxt读取,因为时字符串形式(一个格子里有两个元素),可以csv中先分列 。



CSV文件的局限性:只能有效存储一维和二维数组,np.savetxt()和np.loadtxt()只能有效存储一维和二维数组。
多维数据的存取 a.tofile( )\np.fromfile( )


二进制空间比文本文件占用空间更小,由于看不到内容,只能作为数据备份的方式。
b---二进制;d---十进制;o---八进制;x---十六进制

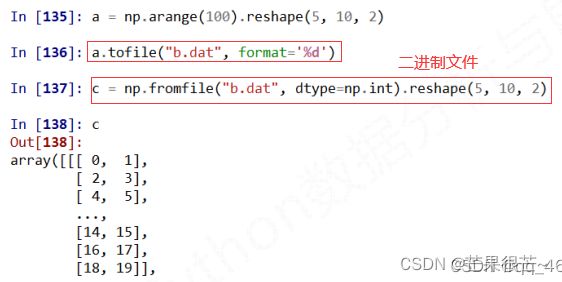
注意: 该方法读取时需要知道文件的数组维度和元素类型。a.tofile( )和np.fromfile( )需配合使用,可通过元组文件来存储额外信息。
NumPy的便捷文件存储 np.save( )\np.savez( )\np.load( )
存储/打开文件是以.npy为扩展名的。 需要用IDE打开


numpy的随机数函数子库random子库。np.random.rand(数组形状)/randn()/randint()/seed()



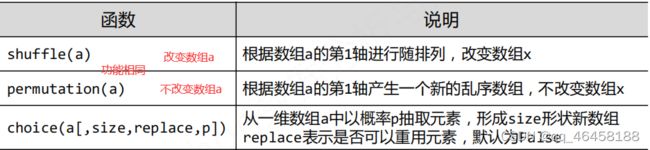
shuffle/permutation:行的随机上下跳动。choice(a,(,),p=):从一个数组中随机抽取,生成特定形状的新数组,抽取数据可有概率。


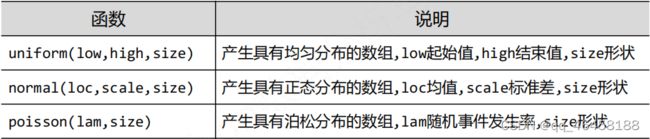

NumPy的统计函数 np.*
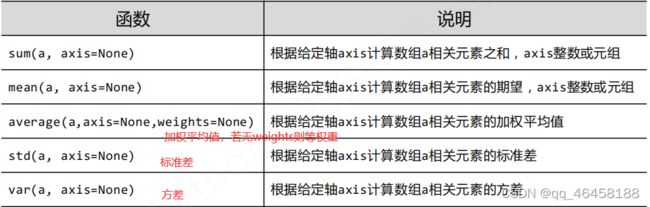
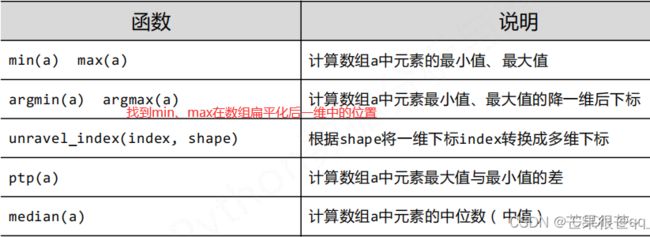


axis=0 : 表示纵轴,进行操作的方向为从上到下;axis=1 : 表示横轴,进行操作的方向为从左到右。
NumPy的梯度函数 np.gradient( )
梯度反映元素的变化率,在图像、声音批量数据处理时,梯度助于发现图像或声音的边缘
np.gradient(f):计算数组f中元素的梯度,当f为多维时,返回每个维度梯度。梯度:连续值之间的变化率(即斜率)。XY坐标轴连续三个X坐标对应的Y轴值:a,b,c,其中b的梯度是(c-a)/2


Numpy、PIL中的图像的手绘效果
图像的数组表示
图像一般都会采用一种模式——RGB色彩模式,即每个像素点的颜色由红(R)、绿(G)、蓝(B)组成。
RGB三个颜色通道的变化和叠加得到各种颜色,R取值范围0-255,G取值范围0-255,B取值范围0-255。包括了视力所能感知的所有颜色。图像是一个三维数组,维度分别是高度、宽度和像素RGB值。
PIL库(Python处理图像的功能库,第三方库)图像是一个由像素组成的二维矩阵,每个元素是一个RGB值。



图像的简单变换
图像可表示为一个数组,而数组是可以运算的,经过运算后的数组可以改变图像的形状。
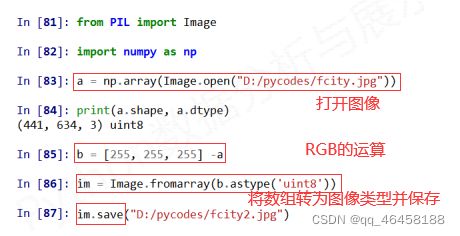


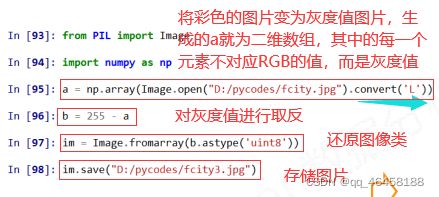
.astype( ):数组类型的转变,先对原始数据进行拷贝。详见Numpy库入门

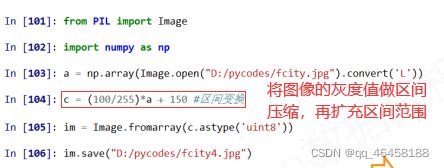



图像的手绘效果
手绘效果的特征:黑白灰色;边界线条较重;相同或相近色彩趋于白色;略有光源效果。在图像灰度化的基础上,由立体效果和明暗效果叠加而成,灰度代表图像的明暗变化,梯度值表示灰度的变化率。通过调整像素的梯度值来间接改变图片的明暗程度。立体效果通过添加虚拟深度值来实现。

from PIL import Image
import numpy as np
a = np.asarray(Image.open('C:/Users/木头目/Desktop/picture.png').convert('L')).astype('float')
depth = 10 #预设深度值为10,取值范围0-100
grad = np.gradient(a)
grad_x,grad_y=grad #提取x和y方向的梯度值
grad_x = grad_x * depth/100
grad_y = grad_y*depth/100 #根据深度调整x和y方向的梯度值(对深度值进行归一化)
A = np.sqrt(grad_x**2 + grad_y**2 + 1)
uni_x = grad_x/A
uni_y = grad_y/A
uni_z = 1/A
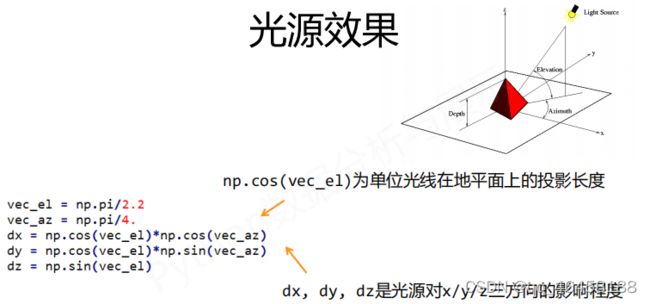
vec_el = np.pi/2.2 #光源的俯视角度,弧度制
vec_az = np.pi/4 #光源的方位角度,弧度制
dx = np.cos(vec_el)*np.cos(vec_az) #np.cos(vec_el)为单位光线在地平面上的投影长度
dy = np.cos(vec_el)*np.sin(vec_az)
dz = np.sin(vec_el) #dx,dy,dz是光源对x/y/z三方向的影像程度
b = 255*(dx*uni_x + dy*uni_y + dz*uni_z) #光源归一化
b = b.clip(0,255)
im = Image.fromarray(b.astype('uint8')) #重构图像
im.save('C:/Users/木头目/Desktop/picture8.png')