10月31日到12月04日学习总结
在虚拟机上调试输入法
在自己电脑(win10 2004 专业版)上可以运行,但是到了虚拟机(win7 x86 sp1专业版)上不能运行。
参考《VS远程调试虚拟机中的程序》,在虚拟机上调试输入法步骤如下:
- 虚拟机设置为桥接模式,复制物理机网络状态。

- 然后选择连接。(这里主要是为了避免win10在虚拟机中自动更新的问题。)
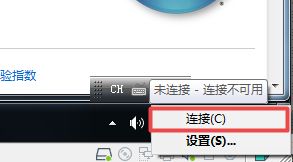
- 查看网络共享 => 本地连接 =>状态 => 详细信息,获取虚拟机的IP地址。
- 设置VS项目属性 => 调试页:

- 将VS所在目录下的远程调试工具复制到虚拟机, 我的是
D:\Microsoft Visual Studio\2019\Enterprise\Common7\IDE\Remote Debugger
目录下有3个文件夹,复制对应操作系统位数的文件夹即可。比如我这里复制x86这个文件夹。 - 运行虚拟机中 Remote Debugger目录下的msvsmon.exe 然后点击选项 => 无身份验证,运行任何用户进行调试。
最长空闲时间可以改大点: 100000000000000000 - 右键项目 => 调试 => 启动新实例调试。
之后就可以看见,在虚拟机里面启动了一个记事本程序。
ITfUIElementMgr::BeginUIElement:
文字服务在显示UI之前,需要先调用ITfUIElementMgr::BeginUIElement。根据返回的数值来判断UI界面时候需要显示。
ComRegisterFunctionAttribute
ComRegisterFunctionAttribute 使你能够添加任意注册代码以满足 COM 客户端的要求。 例如,你可以使用命名空间中的注册函数更新注册表 Microsoft.Win32 。 如果提供了注册方法,还应将应用 System.Runtime.InteropServices.ComUnregisterFunctionAttribute 于注销方法,这会反转注册方法中完成的操作。
.NET Framework: 公共语言运行时使用此属性调用方法,方法是将其包含的程序集注册 (直接或间接) 使用 Regasm.exe (程序集注册) 工具) 或通过 RegistrationServices.RegisterAssembly 方法。
.Net Core: 当公共语言运行时通过 RegSvr32.exe 工具注册了包含程序集的 COM 主机时,公共语言运行时将调用具有此特性的方法。
此属性只能应用于具有以下特征的方法:
- 范围:任何 (public、private 等) 。
- 键入:
static。 - 参数:接受单个 Type 参数或 String 参数类型。
- 返回类型:
void。
CA1416警告:平台兼容性问题
来源:https://docs.microsoft.com/zh-cn/dotnet/core/compatibility/code-analysis/5.0/ca1416-platform-compatibility-analyzer
.NET code analyzer rule CA1416 is enabled, by default, starting in .NET 5.0. It produces a build warning for calls to platform-specific APIs from call sites that don’t verify the operating system.
在.NET5上,开始默认启动CA1416警告。
你可以在IF语句中,使用 任意一个Is 方法来判断:
public void PlayCMajor()
{
if (OperatingSystem.IsWindows())
{
Console.Beep(261, 1000);
}
}
或者你不喜欢在运行的时候使用一个IF语句来判断,你可以调用Debug.Assert(Boolean) 来代替:
public void PlayCMajor()
{
Debug.Assert(OperatingSystem.IsWindows());
Console.Beep(261, 1000);
}
如果你是一个库的作者,你可以给你的API添加特殊平台标记。在这种情况下,确认平台的任务就交给了调用者。你可以将其标记在一个方法或者一个整个程序集上。
[SupportedOSPlatform("windows")]
public void PlayCMajor()
{
Console.Beep(261, 1000);
}
ITfInputProcessorProfileMgr interface (msctf.h)
The ITfInputProcessorProfileMgr interface is implemented by the TSF manager and used by an application or text service to manipulate the language profile of one or more text services.
不同于 ITfInputProcessorProfiles, ITfInputProcessorProfileMgr可以同时管理按键布局和文字服务程序集。在 Windows Vista下, it is recommended to use this interface instead of using the following methods:
- ITfInputProcessorProfiles::Register
- ITfInputProcessorProfiles::Unregister
- ITfInputProcessorProfiles::AddLanguageProfile
- ITfInputProcessorProfiles::RemoveLanguageProfile
- ITfInputProcessorProfiles::EnumInputProcessorInfo
- ITfInputProcessorProfiles::ActivateLanguageProfile
- ITfInputProcessorProfiles::GetActiveLanguageProfile
- ITfInputProcessorProfiles::EnumLanguageProfiles
HKL
HKL:键盘布局,最初的含义就是单纯的键盘布局,能够将键盘的扫描码转换成设备无关的虚键码。现在HKL的含义更广泛,表示本地化标识符。
HKL名字:键盘布局编号,设备码和语言代码组成。前四位是设备码,后四位是语言码。注册表项HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Keyboard Layouts中列出了所有键盘布局。项名就是HKL名称。
“00000804” 表示 中文(简体) - 默认键盘
“E0220804” 表示 中文(简体) - 搜狗输入法
“E0230804” 表示 中文(简体) – 必应Bing输入法
LoadKeyboardLayout
函数功能:该函数给系统中装入一种新的键盘布局,可以同时装入几种不同的键盘布局,任一时刻仅有一个进程是活动的,装入多个键盘布局使得在多种布局间快速切换。
函数原型:HKL LoadKeyboardLayout(LPCTSTR pwszKLID,UINT Flags);
参数:
pwszKLID:缓冲区中的存放装入的键盘布局名称,名称是由语言标识符(低位字)和设备标识符(高位字)组成的十六进制值串,例如 U.S.英语对应的语言标识符为DX0409,则基本的U.S.英语键盘布局命名为“0000409”。U.S.英语键盘布局的变种(例如Dvorak布局)命名为“00010409”,“00020409”等。
Flags:指定如何装入键盘布局,该参数可以是如下的值。
KLF_ACTIVATE:若指定布局尚未装入,该函数为当前线程装入并激活它。
KLF_NOTELLSHELL:当装入新的键盘布局时,禁止一个ShellProe过程接收一个HSHELL_LANGUAGE代码。
当应用程序依次装入多个键盘布局时,对除最后一个键盘布局外的所有键盘布局使用该值,将会延迟Shell的处理直到所有的键盘布局均己被装入。
KLF_RECOROER:将指定键盘布局移动到布局表的头部,使得对于当前线程,该布局的活动的。若不提供DLF_ACTIVATE值,则该值记录键盘布局表。
KLF_REPLACE_LANG:Windows NT 4.0或Windows 95以上支持,若新布局与当前布局有同样的语言标识符,那么新布局替代当前布局作为那种语言的键盘布局,若未提供该值,而键盘布局又有同样的标识符,则当前布局不被替换,函数返回NULL值。
KLF_SUBSTITUTE_OK:用用户喜欢的键盘布局来替换给定布局,系统初始时设置该标志,并且建议始终设置该标志,仅当在注册HKEY_CURRENT_USER/Keyboard Layout/Substitate下定义了一个替代布局时,才发生替换。例如,在名为00000409的部分中有一个多于00010409的值,则设置该标志装入U.S.英语键盘布局会导致Dvorak US.英语键盘布局的装入。系统引导时使用该参数,建议在所有应用程序装入键盘布局时使用该值,以确保用户喜欢的键盘布局被选取。
KLF_SETFORPROCESS:Windows NT 5.0该位仅法与KLF_ACTIVATE一起使用时才有效,为整个进程激活指定键盘布局,且发送WM_INPUTLANGCHANGE消息以当前进程的所有线程。典型的LoadKeyboardLayWut仅为当前线程激活一个键盘布局。
KLF_UNLOADPREVIOS:WindowsNT5.0,Windows95,Windows98都不支持,仅当与KLF_ACTIVATE一起使用时才有效,仅当装入且激活指定键盘布局成功,先前的布局才能被卸载,建议使用unLoadKeyboardLayout函数。
返回值:若函数调用成功,返回与要求的名字匹配的键盘布局句柄。若没有匹配的布局,则返回NULL。
备注:应用程序可以通过仅定义语言标识符的串来装入该语言的IME向缺省键盘布局。若应用程序想装入IME的指定键盘布局,就必须读注册信息以确定传递给LoadKeyboardLayout返回的键盘布局句柄来激活。
Windows 95和Windows 98:若装载与原先键盘布局使用同种语言的布局,且KLF_REPLACELANG标志未被设置,则函数调用失败,仅有一个键盘布局可与给定语言相关联。(对于装载与同一语言相关的多IME也是可接受的)。
速查:Windows NT:3.1及以上版本;Windows:95及以上版本;Windows CE:不支持;头文件:winuser.h;库文件:user32.lib;Unicode:在Windows NT上实现为Unicode和ANSI两种版本。
net5 failed to load the dll from [C:\Users\ZMK\Desktop\publish\coreclr.dll] HRESULT 0x80070057
解决方案:https://developercommunity.visualstudio.com/content/problem/805039/net-core-30-failed-to-load-dll.html
需要下载KB2533623 补丁。下载地址:http://www.3h3.com/soft/119473.html
Windows 7 / Vista / 8.1 / Server 2008 R2 / Server 2012 R2
如果您在以下系统安装.NET SDK或者运行环境的话,需要添加依赖::
- Windows 7 SP1 ESU
- Windows Vista SP 2
- Windows 8.1
- Windows Server 2008 R2
- Windows Server 2012 R2
需要安装以下依赖:
- Microsoft Visual C++ 2015 Redistributable Update 3.
- KB2533623
C++ Windows库函数末尾添加“A”和“W”的意义
Windows API函数对字符处理有3种格式:
- Windows一般代码格式(Windows code page),用
A来指代ANSI。 - Unicode格式,用
W来指代宽字符(Wide)。 - 通常大部分版本均会编译为Windows一般代码格式或者Unicode格式。
一些最新的方法只有Unicode版本。更多信息请参考函数原型的约定.
以ModifyMenu(...)函数为例,其宏定义如下:
#ifdef UNICODE
#define ModifyMenu ModifyMenuW
#else
#define ModifyMenu ModifyMenuA
#endif // !UNICODE
如上代码段即可知,若是定义了UNICODE则在函数末尾添加W,若是没有定义,则添加A。
参考:https://www.cnblogs.com/ChYQ/p/6394065.html https://docs.microsoft.com/zh-cn/windows/win32/intl/unicode-in-the-windows-api?redirectedfrom=MSDN
获取输入法名字
参考来源:https://www.geek-share.com/detail/2680786863.html
我设置在输入法切换,会显示输入法的名称
输出结果: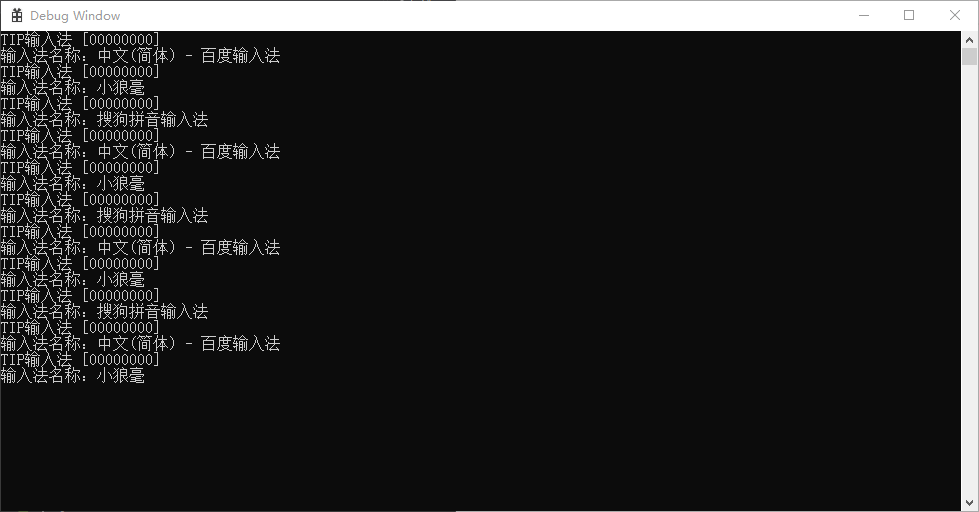
代码如下:
TsfApp.h:
#pragma once
#define _CRT_SECURE_NO_DEPRECATE
#includeTsfApp.cpp
#define _CRT_SECURE_NO_DEPRECATE
#include "TsfApp.h"
#include 调用方法:
TsfApp* app= new TsfApp();
app->SetupSinks();
// 主窗口事件循环。
app->ReleaseSinks(); //释放注册
输出均在命令行,如果未开启命令行可以使用以下代码开启命令行:
HANDLE hOutput;
void console_init(void)
{
AllocConsole();
SetConsoleTitle(L"Debug Window");
SetConsoleCtrlHandler(NULL, true);
freopen("CONOUT$", "w", stdout);
//FreeConsole();
}
记得最后关闭命令行窗口:
FreeConsole();
C++11
auto
自动类型推导。
// c++03
float f = 3.141592f;
_m128 acc =_mm_setzero_ps();
std::map<std::string, std::int32_t>::const_iterator it = myMap.begin();
// c++11
auto f = 3.141592f;
auto acc = _mm_setzero_ps();
auto it = myMap.begin();
nullptr
空指针。它是类型std::nullptr_t的实例。
foreach
for (const auto& pair : myMap)
{
print("%s\n",pair.first.c_str());
// 注:cout比print满的多。如果注意性能的话,建议使用print。
}
override和final
override指定符表示该函数会覆盖一个积累现有的虚函数,而final指定符表示该虚函数不能再被子类覆盖。
强类型的enum
指明枚举类型。
enum class Color : std::int8_t {Red, Green, Blue, White, Black };
Color c= Color::Red;
智能指针
ps: 这里书上讲的不够仔细,没理解。添加新的参考资料:详解C++11智能指针 - WindSun - 博客园 https://www.cnblogs.com/WindSun/p/11444429.html
C++里面的四个智能指针: auto_ptr, unique_ptr,shared_ptr, weak_ptr 其中后三个是C++11支持,并且第一个已经被C++11弃用。
智能指针主要用于管理在堆上分配的内存,它将普通的指针封装为一个栈对象。当栈对象的生存周期结束后,会在析构函数中释放掉申请的内存,从而防止内存泄漏。C++ 11中最常用的智能指针类型为shared_ptr,它采用引用计数的方法,记录当前内存资源被多少个智能指针引用。该引用计数的内存在堆上分配。当新增一个时引用计数加1,当过期时引用计数减一。只有引用计数为0时,智能指针才会自动释放引用的内存资源。对shared_ptr进行初始化时不能将一个普通指针直接赋值给智能指针,因为一个是指针,一个是类。可以通过make_shared函数或者通过构造函数传入普通指针。并可以通过get函数获得普通指针。
- unique_ptr:
unique_ptr实现独占式拥有或严格拥有概念,保证同一时间内只有一个智能指针可以指向该对象。 - shared_ptr:
shared_ptr实现共享式拥有概念。多个智能指针可以指向相同对象,该对象和其相关资源会在“最后一个引用被销毁”时候释放。 - weak_ptr:
share_ptr虽然已经很好用了,但是有一点share_ptr智能指针还是有内存泄露的情况,当两个对象相互使用一个shared_ptr成员变量指向对方,会造成循环引用,使引用计数失效,从而导致内存泄漏。
lambda
auto pos = std::find_if(std::begin(v),std::end(v),[](int){return (n % 2 == 1); });
移动语义与右值引用
c++11之前,避免不必要的拷贝:
void MultiplyAllValues(std::vector<float>& output,const std::vectro<float>& input,float multiplier)
{
output.resize(0);
output.reserver(input.size());
// Copy input to output.
}
c++11以后。。。没搞懂
左值:在计算机寄存器或内存中的实际存储位置。
右值:临时数据对象。
IEEE
有限精度和机器的epsilon的概念对游戏软件有实质影响。游戏持续运行,加上1/30秒以后,游戏的绝对时间维持不变为12.9日。
SIMD类型
矢量处理器提供一种并行处理方式,名为单指令多数据。单个SIMD指令可以并行地对多个数据进行运算。
先来段代码对比:
代码功能为
r e s = ( a 2 + b 2 ) res = \sqrt{(a^2 + b^2)} res=(a2+b2)
* 其中:a,b,res均为数组。
void normal(float data1[], float data2[], int len, float out[])
{
int i;
for (i = 0; i < len; i++)
{
out[i] = sqrt(data1[i]* data1[i] + data2[i] * data2[i]);
}
}
void simd(float *data1, float *data2, int len, float out[])
{
assert(len % 4 == 0);
__m128 *a,*b,*res,t1,t2,t3;// = _mm256_set_ps(1, 1, 1, 1, 1, 1, 1, 1);
int i,tlen = len/4;
a = (__m128*)data1;
b = (__m128*)data2;
res = (__m128*)out;
for (i = 0; i < tlen; i++)
{
t1 = _mm_mul_ps(*a, *a);
t2 = _mm_mul_ps(*b, *b);
t3 = _mm_add_ps(t1, t2);
*res = _mm_sqrt_ps(t3);
a++;
b++;
res++;
}
}
void simd256(float* data1, float* data2, int len, float out[])
{
assert(len % 8 == 0);
__m256* a, * b, * res, t1, t2, t3;// = _mm256_set_ps(1, 1, 1, 1, 1, 1, 1, 1);
int i, tlen = len / 8;
a = (__m256*)data1;
b = (__m256*)data2;
res = (__m256*)out;
for (i = 0; i < tlen; i++)
{
t1 = _mm256_mul_ps(*a, *a);
t2 = _mm256_mul_ps(*b, *b);
t3 = _mm256_add_ps(t1, t2);
*res = _mm256_sqrt_ps(t3);
a++;
b++;
res++;
}
}
问题规模:16*10000000
| 函数 | 运行时间(s) |
|---|---|
| normal | 1.414000 |
| simd | 0.357000 |
| simd256 | 0.119000 |
本来我在这里想用__m512,结果报错:Illegal Instruction。原因为缺少AVX512指令。桌面端缺少AVX512指令,只有服务器上才有。
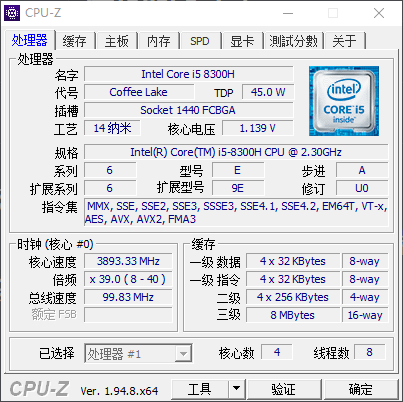
这里使用CPUZ软件检测,笔者电脑上支持的指令集为MMX,SSE,SSE2,SSE3,SSE3,SSE4.1,SSE4.2,EM64T,VT-X,AES,AVX,AVX2,FMA3
CentOS输入cat /proc/cpuinfo即可查看CPU信息。以下是我腾讯云服务器信息。
SIMD(single-instruction, multiple-data)是一种使用单道指令处理多道数据流的CPU执行模式,即在一个CPU指令执行周期内用一道指令完成处理多个数据的操作。

支持指令fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm art rep_good nopl extd_apicid eagerfpu pni pclmulqdq ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw retpoline_amd vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 arat
指令集架构类型
CISC的产生、发展和现状
一开始,计算机的指令系统只有很少一些基本指令,而其他的复杂指令全靠软件编译时通过简单指令的组合来实现。
举个最简单的例子:一个a乘以b的操作就 可以转换为a个b相加来做,这样就用不着乘法指令了。当然,最早的指令系统就已经有乘法指令了,这是为什么呢?因为用硬件实现乘法比加法组合来得快得多。
由于那时的计算机部件相当昂贵,而且速度很慢,为了提高速度,越来越多的复杂指令被加入了指令系统中。
但是,很快又有一个问题:一个指令系统的指令数是受指令操作码的位数所限制的,如果操作码为8位,那么指令数最多为256条(2的8次方)。
那么怎么办呢?指令的宽度是很难增加的,聪明的设计师们又想出了一种方案:操作码扩展。前面说过,操作码的后面跟的是地址码,而有些指令是用不着地址码或只用少量的地址码的。那么,就可以把操作码扩展到这些位置。
举个简单的例子:如果一个指令系统的操作码为2位,那么可以有00、01、10、11四条不同的指令。现在把11作为保留,把操作码扩展到4位,那么 就可以有00、01、10、1100、1101、1110、1111七条指令。其中1100、1101、1110、1111这四条指令的地址码必须少两位。
然后,为了达到操作码扩展的先决条件:减少地址码,设计师们又动足了脑筋,发明了各种各样的寻址方式,如基址寻址、相对寻址等,用以最大限度的压缩地址码长度,为操作码留出空间。
就这样,慢慢地,CISC指令系统就形成了,大量的复杂指令、可变的指令长度、多种的寻址方式是CISC的特点,也是CISC的缺点:因为这些都大大 增加了解码的难度,而在现在的高速硬件发展下,复杂指令所带来的速度提升早已不及在解码上浪费点的时间。除了个人PC市场还在用x86指令集外,服务器以 及更大的系统都早已不用CISC了。x86仍然存在的唯一理由就是为了兼容大量的x86平台上的软件。
在CISC微处理器中,程序的各条指令是按顺序串行执行的,每条指令中的各个操作也是按顺序串行执行的。顺序执行的优点是控制简单,但计算机各部分的利用率不高,执行速度慢。
RISC的产生、发展和现状
RISC(Reduced Instruction Set Computing,精简指令集)。
1975年,IBM的设计师John Cocke研究了当时的IBM370CISC系统,发现其中占总指令数仅20%的简单指令却在程序调用中占了80%,而占指令数80%的复杂指令却只有20%的机会用到。由此,他提出了RISC的概念。
复杂的指令系统必然增加微处理器的复杂性,使处理器的研制时间长,成本高。并且复杂指令需要复杂的操作,必然会降低计算机的速度。基于上述原因,20世纪80年代RISC型CPU诞生了,相对于CISC型CPU ,RISC型CPU不仅精简了指令系统,还采用了一种叫做“超标量和超流水线结构”,大大增加了并行处理能力(并行处理并行处理是指一台服务器有多个CPU同时处理。并行处理能够大大提升服务器的数据处理能力。部门级、企业级的服务器应支持CPU并行处理技术)。也就是说,架构在同等频率下,采用RISC架构的CPU比CISC架构的CPU性能高很多,这是由CPU的技术特征决定的
RISC体系结构和设计思想是80年代初出现的,RISC与CISC指令系统是完全不同,完全决裂的指令系统。
它的基本思路是:抓住CISC指令系统指令种类太多(其中80%以上都是程序中很少使用的指令)、指令格式不规范、寻址方式太多的缺点(例如,VAX 780的指令操作类型超过1000种,而Alpha只有不到50种指令),通过减少指令种类、规范指令格式和简化寻址方式,大量利用寄存器间操作,大大简化处理器的结构、优化VLSI器件使用效率,从而大幅度地提高处理器性能、并行处理能力和性价比。
到80年代后期,RISC技术已经发展成为支持高端服务器系统的主流技术,各厂商纷纷推出了32位RISC微处理器。(如:IBM的PowerPC和Power2,Sun的SPARC,HP的PA-RISC 7000和MIPS的R系列等。)
基于32位RISC芯片的产品在取得了很大的成功,应用日益广泛、软件大量积累、在市场上也产生巨大的影响。
后来,Alpha作为64位RISC技术的领头羊,开创了64位RISC计算的新时代。
各主要厂商也都在90年代先后推出了自己的64位RISC微处理器(包括:IBM的Power和PowerPC系列、HP的PA-RISC 8000系列、Sun的UltraSPARC系列和MIPS的R10K系列等)。在此期间,Alpha始终保持了性能领先的地位。
由于RISC指令集自身的优势,64位RISC微处理器主要在高端服务器领域和高端企业市场上运用。
事实证明,RISC是成功的。80年代末,各公司的RISC CPU如雨后春笋般大量出现,占据了大量的市场。到了90年代,Intel推出了Pentium处理器,从Pentium pro构架开始,也开始使用一种混合的CISC/RISC构架(注意:这里X86架构上有改变,但仍然是IA-32,是32位处理器,直到AMD推出了X86-64及Intel跟随推出IA-32e之后,才有64位技术)。
RISC的最大特点是指令长度固定,指令格式种类少,寻址方式种类少,大多数是简单指令且都能在一个时钟周期内完成,易于设计超标量与流水线,寄存器 数量多,大量操作在寄存器之间进行。
IA-64(EPIC)产生、发展和现状
IA-64 (Intel Architechure-64,英特尔64位体系架构)
EPIC (EPIC–Explicitly Parallel Instruction Computing;显性并行指令计算)
到90年代末,32位芯片的“霸主”Intel宣布与HP合作推出64位IA-64体系结构的处理器。
Inter和HP从1994年开始合作开发新型的64位芯片,它们选择了一个与大多数RISC微处理器大不相同的方向,推出了一种新的64位指令系统体系结构IA-64。它们把这一体系结构称为EPIC(显性并行指令计算)。
EPIC既不是RISC也不是CISC,它实质上是一种吸收了两者长处体系结构。IA-64的EPIC体系结构又在这两者教训基础上另辟蹊径。
EPIC与Cydrome公司(一个80年代走向失败的小巨型机公司)的VLIW体系结构 (Very Long Instruction Word,超长指令集架构)有一定程度的相象之处。
IA-64(EPIC)架构的处理器,目前只应用在Intel的Itanium(安腾)处理器(目前最高端的处理器)上,基于它专为要求苛刻的企业和技术应用而设计,是瞄准高端企业市场的。
Intel 和HP合作开发的IA-64 EPIC体系结构安腾系列的先进性和开放性以及发展潜力,它将要取代64位RISC芯片成为未来系统设计和企业应用的主流平台。
RISC与 IA-64(EPIC)相比
64位RISC和IA-64(EPIC)架构的CPU,主要是应用在要求苛刻的技术应用和企业的高端服务器平台上。
IA-64CPU(安腾)可以说是目前最高端的处理器,基于IA-64先进性和开放性以及发展潜力,它必将要取代64位RISC芯片成为未来系统设计和企业应用的主流平台。
但这向CPU历史上的技术革命,基于其技术架构、成本等各方面的因素,发展到主流民用市场的话,还有非常长的路要走。
【来源】:https://blog.csdn.net/gftygff/article/details/86769126
指令集介绍
一、X86
是微处理器执行的计算机语言指令集,指一个intel通用计算机系列的标准编号缩写,也标识一套通用的计算机指令集合,属于CISC。
1.1、简介
X86指令集是美国Intel公司为其第一块16位CPU(i8086)专门开发的,美国IBM公司1981年推出的世界第一台PC机中的CPU i8088(i8086简化版)使用的也是X86指令,同时电脑中为提高浮点数据处理能力而增加的X87芯片系列数学协处理器则另外使用X87指令,以后就将X86指令集和X87指令集统称为X86指令集。虽然随着CPU技术的不断发展,Intel陆续研制出更新型的i80386、i80486直到今天的Pentium Ⅲ(以下简为PⅢ)系列,但为了保证电脑能继续运行以往开发的各类应用程序以保护和继承丰富的软件资源,所以Intel公司所生产的所有CPU仍然继续使用X86指令集,所以它的CPU仍属于X86系列。 另外除Intel公司之外,AMD和Cyrix等厂家也相继生产出能使用X86指令集的CPU,由于这些CPU能运行所有的为Intel CPU所开发的各种软件,所以电脑业内人士就将这些CPU列为Intel的CPU兼容产品。由于Intel X86系列及其兼容CPU都使用X86指令集,所以就形成了今天庞大的X86系列及兼容CPU阵容。当然在目前的台式(便携式)电脑中并不都是使用X86系列CPU。
1.2、特点
x86 是一种为了便于编程和提高记忆体访问效率的芯片设计体系,包括两大主要特点:一是使用微代码,指令集可以直接在微代码记忆体里执行,新设计的处理器,只需增加较少的电晶体就可以执行同样的指令集,也可以很快地编写新的指令集程式;二是拥有庞大的指令集,x86拥有包括双运算元格式、寄存器到寄存器、寄存器到记忆体以及记忆体到寄存器的多种指令类型,为实现复杂操作,微处理器除向程序员提供类似各种寄存器和机器指令功能外,还通过存于只读存储器(ROM)中的微程序来实现极强的功能,微处理器在分析完每一条指令之后执行一系列初级指令运算来完成所需的功能。
1.3、优缺点
优点:x86指令体系的优势体现在能够有效缩短新指令的微代码设计时间,允许实现CISC体系机器的向上兼容,新的系统可以使用一个包含早期系统的指令集合。另外微程式指令的格式与高阶语言相匹配,因而编译器并不一定要重新编写。
缺点:
- 通用寄存器规模小,x86指令集只有8个通用寄存器,CPU大多数时间是在访问存储器中的数据,影响整个系统的执行速度。而RISC系统往往具有非常多的通用寄存器,并采用了重叠寄存器窗口和寄存器堆等技术,使寄存器资源得到充分的利用
- 解码器影响性能表现,解码器的作用是把长度不定的x86指令转换为长度固定的类似于RISC的指令,并交给RISC内核。解码分为硬件解码和微解码,对于简单的x86指令只要硬件解码即可,速度较快,而遇到复杂的x86指令则需要进行微解码,并把它分成若干条简单指令,速度较慢且很复杂。
- 寻址范围小,约束用户需要。
- 单个指令长度不同,运算能力强大,不过相对来说结构复杂,很难将CISC全部硬件集成在一颗芯片上。
1.4、汇编指令
- 数据传送指令
- 数据传送指令
- 逻辑运算指令
- 串操作指令
- 控制转移指令
- 处理器控制指令
- 保护方式指令
二、X64
又叫“x86-64”,简称为“x64”,是64位微处理器架构及其相应指令集的一种,也是Intel x86架构的延伸产品,也是属于CISC。
2.1、简介
“x86-64”1999由AMD设计,AMD首次公开64位集以扩充给IA-32,称为x86-64(后来改名为AMD64)。其后也为英特尔所采用,现时英特尔称之为“Intel 64”,在之前曾使用过Clackamas Technology (CT)、IA-32e及EM64T。外界多使用"x86-64"或"x64"去称呼此64位架构,从而保持中立,不偏袒任何厂商。
2.2、特点
主要是与X86兼容,既有支持64位通用暂存器、64位整数及逻辑运算,以及64位虚拟地址。设计人员也为架构作出不少改进,部份重大改变如下:新增暂存器,地址阔度加长,“禁止运行”比特 (NX-bit): AMD64其中一个特色是拥有“禁止运行”(No-Execute, NX)的比特,可以防止蠕虫病毒以缓冲器满溢的方式来进行攻击(也称:缓存溢出攻击,Buffer Overflow)。
2.3、优缺点
由于源自X86,都是CSIC,所以具有X86差不多的缺点,跟X86比较,有如下优势:
- 64位寻址空间
- 扩展的寄存器组
- 开发者熟悉的命令集
- 可以在64位结构的操作系统上运行32位程序
- 可以直接使用32位操作系统
2.4、汇编指令
基本跟X86一样,大多数X86指令在X64的64位模式下是有效的。在64位模式不常使用的指令不在支持。如:BCD码算术指令。
三、ARM
曾称进阶精简指令集机器(Advanced RISC Machine)更早称作Acorn RISC Machine,是一个32位精简指令集(RISC)处理器架构。还有基于ARM设计的派生产品,重要产品包括Marvell的XScale架构和德州仪器的OMAP系列。ARM家族占比所有32位嵌入式处理器的75%,成为占全世界最多数的32位架构。是为了提高处理器运行速度而设计的芯片体系,它的关键技术在于流水线操作即在一个时钟周期里完成多条指令。属于RISC。
3.1、简介
一颗主要用于路由器的Conexant ARM处理器是Acorn电脑公司(Acorn Computers Ltd)于1983年开始的开发计划。这个团队由Roger Wilson和Steve Furber带领,着手开发一种新架构,类似进阶的MOS Technology 6502处理器。Acorn有一大堆建构在6502架构上的电脑,因此能设计出一颗类似的芯片即意味着对公司有很大的优势。团队在1985年时开发出ARM1 Sample版,而首颗"真正"的产能型ARM2于次年量产。ARM2具有32位的数据总线、26位的寻址空间,并提供64 Mbyte的寻址范围与16个32-bit的暂存器。这些暂存器其中有一颗做为(word大小)程式计数器,其前面6 bits和后面2 bits用来保存处理器状态标记(Processor Status Flags)。ARM2可能是全世界最简单实用的32位微处理器,其仅容纳了30,000个晶体管(相较于Motorola六年后的68000其包含了70,000颗)。主要应用于工控/嵌入式和手持设备等领域。
3.2、特点
ARM指令集架构的主要特点:一是体积小、低功耗、低成本、高性能;二是大量使用寄存器且大多数数据操作都在寄存器中完成,指令执行速度更快;三是寻址方式灵活简单,执行效率高;四是指令长度固定,可通过多流水线方式提高处理效率。
3.3、优缺点
- 体积小,低功耗,低成本,高性能;
- 支持 Thumb ( 16 位) /ARM ( 32 位)双指令集,能很好的兼容 8 位 /16 位器件; 大量使用寄存器,指令执行速度更快;大多数数据操作都在寄存器中完成;
- 寻址方式灵活简单,执行效率高;
- 指令长度固定;
- 流水线处理方式
- Load_store结构:在RISC中,所有的计算都要求在寄存器中完成。而寄存器和内存的通信则由单独的指令来完成。而在CSIC中,CPU是可以直接对内存进行操作的。
3.4、汇编指令
- 算数和逻辑指令
- 比较指令
- 跳转指令
- 移位指令
- 程序状态字访问指令存
- 储器访问指令
3.5 主要的指令集体系结构版本:
-
ARMv1:该版本的原型机是ARM1,没有用于商业产品。
-
ARMv2:对V1版进行了扩展,包含了对32位结果的乘法指令和协处理器指令的支持。
-
ARMv3:ARM公司第一个微处理器ARM6核心是版本3的,它作为IP核、独立的处理器、具有片上高速缓存、MMU和写缓冲的集成CPU。
-
ARMv4:当前应用最广泛的ARM指令集版本。
ARM7TDMI、ARM720T、ARM9TDMI、ARM940T、ARM920T、Intel的StrongARM等是基于ARMv4T版本。 -
ARMv5:ARM9E-S、ARM966E-S、ARM1020E、ARM 1022E以及XScale是ARMv5TE的。ARM9EJ-S、ARM926EJ-S、ARM7EJ-S、ARM1026EJ-S是基于ARMv5EJ的。ARM10也采用。
其中后缀意义如下:
E:增强型DSP指令集。包括全部算法和16位乘法操作。
J:支持新的Java。 -
ARMv6:采用ARMv6核的处理器是ARM11系列。
ARM1136J(F)-S基于ARMv6主要特性有SIMD、Thumb、Jazelle、DBX、(VFP)、MMU。
ARM1156T2(F)-S基于ARMv6T2 主要特性有SIMD、Thumb-2、(VFP)、MPU。
ARM1176JZ(F)-S基于ARMv6KZ 在 ARM1136EJ(F)-S 基础上增加MMU、TrustZone。
ARM11 MPCore基于ARMv6K 在ARM1136EJ(F)-S基础上可以包括1-4 核SMP、MMU。 -
ARMv7:Cortex-A,Cortex-M,Cortex-R
ARMv7提供了三个概要文件:ARMv7-A :
- 实现具有多种模式的传统ARM体系结构。
- 支持基于内存管理单元(MMU)的虚拟内存系统体系结构(VMSA)。
- ARMv7-A实现可以称为VMSAv7实现。支持ARM和Thumb指令集。
ARMv7-R :实时配置文件
- 实现具有多种模式的传统ARM体系结构。
- 支持基于内存保护单元(MPU)的受保护内存系统体系结构(PMSA)。
- ARMv7-R实现可以称为PMSAv7实现。支持ARM和Thumb指令集。
ARMv7-M :在ARMv7-M体系结构参考手册中描述的 微控制器配置文件:
- 实现一个为低延迟中断处理设计的程序员模型,使用寄存器的硬件堆栈和对用高级语言编写中断处理程序的支持。
- 实现ARMv7 PMSA的变体。
- 支持ARM和Thumb指令集。
-
ARMv8:ARMv8架构包含两个执行状态:AArch64和AArch32。AArch64执行状态针对64位处理技术,引入了一个全新指令集A64;而AArch32执行状态将支持现有的ARM指令集。ARMv7架构的主要特性都将在ARMv8架构中得以保留或进一步拓展,如:TrustZone技术、虚拟化技术及NEON advanced SIMD技术,等。
-
ARMv9:???
ARM处理器内核
| 架构 | 处理器家族 |
|---|---|
| ARMv1 | ARM1 |
| ARMv2 | ARM2、ARM3 |
| ARMv3 | ARM6、ARM7 |
| ARMv4 | StrongARM、ARM7TDMI、ARM9TDMI |
| ARMv5 | ARM7EJ、ARM9E、ARM10E、XScale |
| ARMv6 | ARM11、ARM Cortex-M |
| ARMv7 | ARM Cortex-A、ARM Cortex-M、ARM Cortex-R |
| ARMv8 | Cortex-A35、Cortex-A50系列[14]、Cortex-A72、Cortex-A73 |
| 家族 | 架构 | 内核 | 特色 | 缓存 (I/D)/MMU | 常规 MIPS 于 MHz | 应用 |
|---|---|---|---|---|---|---|
| ARM1 | ARMv1 | ARM1 | 无 | |||
| ARM2 | ARMv2 | ARM2 | Architecture 2 加入了MUL(乘法)指令 | 无 | 4 MIPS @ 8MHz | Acorn Archimedes,Chessmachine |
| ARMv2a | ARM250 | Integrated MEMC (MMU),图像与IO处理器。Architecture 2a 加入了SWP和SWPB(置换)指令。 | 无,MEMC1a | 7 MIPS @ 12MHz | Acorn Archimedes | |
| ARM3 | ARMv2a | ARM2a | 首次在ARM架构上使用处理器缓存 | 均为4K | 12 MIPS @ 25MHz | Acorn Archimedes |
| ARM6 | ARMv3 | ARM610 | v3 架构首创支援定址32位元的内存(针对26位元) | 均为4K | 28 MIPS @ 33MHz | Acorn Risc PC 600,Apple Newton |
| ARM7 | ARMv3 | |||||
| ARM7TDMI | ARMv4T | ARM7TDMI(-S) | 三级流水线 | 无 | 15 MIPS @ 16.8 MHz | Game Boy Advance,Nintendo DS,iPod |
| ARM710T | 均为8KB, MMU | 36 MIPS @ 40 MHz | Acorn Risc PC 700,Psion 5 series,Apple eMate 300 | |||
| ARM720T | 均为8KB, MMU | 60 MIPS @ 59.8 MHz | Zipit | |||
| ARM740T | MPU | |||||
| ARMv5TEJ | ARM7EJ-S | Jazelle DBX | 无 | |||
| StrongARM | ARMv4 | |||||
| ARM8 | ARMv4 | |||||
| ARM9TDMI | ARMv4T | ARM9TDMI | 五级流水线 | 无 | ||
| ARM920T | 16KB/16KB, MMU | 200 MIPS @ 180 MHz | Armadillo,GP32,GP2X(第一颗内核), Tapwave Zodiac(Motorola i. MX1) | |||
| ARM922T | 8KB/8KB, MMU | |||||
| ARM940T | 4KB/4KB, MPU | GP2X(第二颗内核) | ||||
| ARM9E | ARMv5TE | ARM946E-S | 可变动,tightly coupled memories, MPU | Nintendo DS,Nokia N-Gage Conexant 802.11 chips | ||
| ARM966E-S | 无缓存,TCMs | ST Micro STR91xF,包含Ethernet [1] | ||||
| ARM968E-S | 无缓存,TCMs | |||||
| ARMv5TEJ | ARM926EJ-S | Jazelle DBX | 可变动,TCMs, MMU | 220 MIPS @ 200 MHz | 移动电话:Sony Ericsson(K, W系列),明基西门子(x65 系列和新版的) | |
| ARMv5TE | ARM996HS | 无振荡器处理器 | 无缓存,TCMs, MPU | |||
| ARM10E | ARMv5TE | ARM1020E | (VFP),六级流水线 | 32KB/32KB, MMU | ||
| ARM1022E | (VFP) | 16KB/16KB, MMU | ||||
| ARMv5TEJ | ARM1026EJ-S | Jazelle DBX | 可变动,MMU or MPU | |||
| XScale | ARMv5TE | 80200/IOP310/IOP315 | I/O处理器 | |||
| 80219 | 400/600MHz | Thecus N2100 | ||||
| IOP321 | 600 BogoMips @ 600 MHz | Iyonix | ||||
| IOP33x | ||||||
| IOP34x | 1-2核,RAID加速器 | 32K/32K L1, 512K L2, MMU | ||||
| PXA210/PXA250 | 应用处理器,七级流水线 | Zaurus SL-5600 | ||||
| PXA255 | 32KB/32KB, MMU | 400 BogoMips @ 400 MHz | Gumstix,Palm Tungsten E2 | |||
| PXA26x | 可达 400 MHz | Tungsten T3 | ||||
| PXA27x | 800 MIPS @ 624 MHz | HTC Universal、Zaurus SL-C1000、3000、3100、3200、Dell Axim x30、x50和 x51 系列 | ||||
| PXA800(E)F | ||||||
| Monahans | 1000 MIPS @ 1.25 GHz | Mavell PXA300/PXA310/PXA320, Max frequency : PXA300@624Mhz, PXA310/PXA320@806Mhz | ||||
| PXA900 | Blackberry 8700, Blackberry Pearl (8100) | |||||
| IXC1100 | Control Plane Processor | |||||
| IXP2400/IXP2800 | ||||||
| IXP2850 | ||||||
| IXP2325/IXP2350 | ||||||
| IXP42x | NSLU2 | |||||
| IXP460/IXP465 | ||||||
| ARM11 | ARMv6 | ARM1136J(F)-S | SIMD, Jazelle DBX, (VFP),八级流水线 | 可变动,MMU | ?? @ 532-665MHz (i.MX31 SoC) | Nokia N93,Zune,Nokia N800 |
| ARMv6T2 | ARM1156T2(F)-S | SIMD, Thumb-2, (VFP),九级流水线 | 可变动,MPU | |||
| ARMv6KZ | ARM1176JZ(F)-S | SIMD, Jazelle DBX, (VFP) | 可变动,MMU+TrustZone | |||
| ARMv6K | ARM11 MPCore | 1-4核对称多处理器,SIMD, Jazelle DBX, (VFP) | 可变动,MMU | |||
| Cortex-A (32 bit) | ARMv7-A | Cortex-A7 | 1.75 DMIPS/MHz 1 GHz到1.2GHz | 全志a31、MediaTek MT6589,MT6572 | ||
| Cortex-A8 | Application profile, VFP, NEON, Jazelle RCT, Thumb-2, 13-stage pipeline | 可变动 (L1+L2), MMU+TrustZone | 2.0 DMIPS/MHz 从600 MHz到超过1 GHz | Texas Instruments OMAP3、Apple A4 | ||
| Cortex-A9 | 2.50 DMIPS @ 1GHz | Apple A5、Apple A5X、MediaTek MT6577,MT6575、Rockchip RK3088,RK3188, VIA Elite-E1000 | ||||
| Cortex-A12 | 大约3.00 DMIPS @ 1.4GHz 28nm | 预估等同Apple A6、Apple A6X水平。 | ||||
| Cortex-A15 | Thumb-2 TrustZone® NEON DSP & SVFPv4 | 从3.50 DMIPS到超过4.0 DMIPS @ 从1.4MHz到超过2.5GHz | Tegra 4 Exynos5250 | |||
| Cortex-A9 MPCore | ||||||
| Cortex-R | ARMv7-R | Cortex-R4(F) | Embedded profile, (FPU) | 可变动缓存,MMU可选配 | 600 DMIPS | Broadcom is a user |
| Cortex-M | ARMv7-M | Cortex-M3 | Microcontroller profile | 无缓存,(MPU) | 120 DMIPS @ 100MHz | Luminary Micro[2] 微控制器家族 |
| ARMv6-M | Cortex-M0 | |||||
| Cortex-M1 | ||||||
| ARMv7-ME | Cortex-M4 | Optional 8 region MPU with sub regions and background region | 1.25 DMIPS/MHz |
四、SSE指令集
Streaming SIMD Extensions
由于MMX指令并没有带来3D游戏性能的显著提升,1999年Intel公司在[Pentium III](https://baike.baidu.com/item/Pentium III)CPU产品中推出了数据流单指令序列扩展指令(SSE)。SSE兼容MMX指令,它可以通过SIMD(单指令多数据技术)和单时钟周期并行处理多个浮点来有效地提高浮点运算速度。在MMX指令集中,借用了浮点处理器的8个寄存器,这样导致了浮点运算速度降低。而在SSE指令集推出时,Intel公司在Pentium III CPU中增加了8个128位的SSE指令专用寄存器。而且SSE指令寄存器可以全速运行,保证了与浮点运算的并行性。
五、SSE2指令集
在Pentium 4 CPU中,Intel公司开发了新指令集SSE2。这一次新开发的SSE2指令一共144条,包括浮点SIMD指令、整形SIMD指令、SIMD浮点和整形数据之间转换、数据在MMX寄存器中转换等几大部分。其中重要的改进包括引入新的数据格式,如:128位SIMD整数运算和64位双精度浮点运算等。为了更好地利用高速缓存。另外,在Pentium 4中还新增加了几条缓存指令,允许程序员控制已经缓存过的数据。
六、SSE3指令集
相对于SSE2,SSE3又新增加了13条新指令,此前它们被统称为pni(prescott new instructions)。13条指令中,一条用于视频解码,两条用于线程同步,其余用于复杂的数学运算、浮点到整数转换和SIMD浮点运算。
七、SSE4指令集
SSE4又增加了50条新的增加性能的指令,这些指令有助于编译、媒体、字符/文本处理和程序指向加速。
SSE4指令集将作为Intel公司未来“显著视频增强”平台的一部分。该平台的其他视频增强功能还有Clear Video技术(CVT)和统一显示接口(UDI)支持等,其中前者是对ATi AVIVO技术的回应,支持高级解码、后处理和增强型3D功能。
八、3D Now!扩展指令集
2010年AMD官方宣布放弃3DNow!指令集!
1996年,Intel Pentium处理器率先加入了MMX指令集,极大地提高了多媒体处理能力,但仅支持整数运算,浮点运算仍然要使用传统的x87协处理器指令。随后在1998年,AMD推出了包含21条新指令的3DNow!指令集*(据说是3D No Waiting!的缩写)*,并用于其K6-2处理器,使之成为第一个能够执行浮点SIMD指令的x86处理器,实现了x86架构下最快的浮点单元,四倍于x87协处理器。
3DNow!指令集赢得了业界的广泛支持,包括微软DX7都对其进行了优化,AMD处理器的游戏性能得以第一次超越Intel,K6-2和随后的K6-III成为市场上的热门产品。
1999年,AMD Athlon处理器发布,3DNow!指令集也增加了5条新指令,成为扩展3DNow!,但是同年Intel又推出了SSE指令集,在提供3DNow!几乎所有功能的同时大大提高了单精度浮点处理速度,还完全支持IEEE754标准,3DNow!优势不再。
之后主流操作系统和软件都开始支持SSE指令集并为其优化,AMD 2000年的新款Athlon处理器(代号雷鸟)中也加入了SSE。之后的时间里,AMD开始致力于AMD64架构的开发,SIMD指令集方面则跟随Intel,连续添加了SSE2、SSE3,不再改进3DNow!。
九、EM64T指令集
Intel公司的EM64T(Extended Memory 64 Technology)即64位内存扩展技术。该技术为服务器和工作站平台应用提供扩充的内存寻址能力,拥有更多的内存地址空间,可带来更大的应用灵活性,特别有利于提升音频视频编辑、CAD设计等复杂工程软件及游戏软件的应用。常说的64位指的是AMD公司出的64位CPU,而EM64T则是Intel公司按照自己的意思理解出来的64位,也就是和AMD公司的64位对应的另一种叫法。
十、RISC指令集
RISC指令集是以后高性能CPU的发展方向。它与传统的CISC(复杂指令集)相对。相比而言,RISC的指令格式统一,种类比较少,寻址方式也比复杂指令集少。使用RISC指令集的体系结构主要有ARM、MIPS。
十一、3DNow!+指令集
在原有的指令集基础上,增加到52条指令,其中包含了部分SSE指令,该指令集主要用于新型的AMD CPU上。
十二、AVX指令集
Intel AVX指令集在SIMD计算性能增强的同时也沿用了的MMX/SSE指令集。不过和MMX/SSE的不同点在于增强的AVX指令,从指令的格式上就发生了很大的变化。x86(IA-32/Intel 64)架构的基础上增加了prefix(Prefix),所以实现了新的命令,也使更加复杂的指令得以实现,从而提升了x86 CPU的性能。
AVX并不是x86 CPU的扩展指令集,可以实现更高的效率,同时和CPU硬件兼容性也更好,并且也有着足够的扩展空间,这都和其全新的命令格式系统有关。更加流畅的架构就是AVX发展的方向,换言之,就是摆脱传统x86的不足,在SSE指令的基础上AVX也使SSE指令接口更加易用。
针对AVX的最新的命令编码系统,Intel也给出了更加详细的介绍,其中包括了大幅度扩充指令集的可能性。比如Sandy Bridge所带来的融合了乘法的双指令支持。从而可以更加容易地实现512bits和1024bits的扩展。而在2008年末到2009年推出的meniikoaCPU“Larrabee(LARAB)”处理器,就会采用AVX指令集。从地位上来看AVX也开始了Intel处理器指令集的新篇章。
Intel指令手册地址:https://software.intel.com/sites/landingpage/IntrinsicsGuide/
static_cast、dynamic_cast、reinterpret_cast、const_cast
static_cast (expression) 静态转换
静态转换是最接近于C风格转换,很多时候都需要程序员自身去判断转换是否安全。
double d=3.14159265;
int i = static_cast<int>(d);
dynamic_cast (expression) 动态转换
dynamic_cast运算符的主要用途:将基类的指针或引用安全地转换成派生类的指针或引用,并用派生类的指针或引用调用非虚函数。如果是基类指针或引用调用的是虚函数无需转换就能在运行时调用派生类的虚函数。
前提条件:当我们将dynamic_cast用于某种类型的指针或引用时,只有该类型至少含有虚函数时(最简单是基类析构函数为虚函数),才能进行这种转换。否则,编译器会报错。
reinterpret_cast (expression) 重解释转换
reinterpret_cast用在任意指针(或引用)类型之间的转换;以及指针与足够大的整数类型之间的转换;从整数类型(包括枚举类型)到指针类型,无视大小。
new_type a = reinterpret_cast <new_type> (value)
const_cast (expression) 常量向非常量转换
const_cast转换符是用来移除变量的const或volatile限定符。
const int constant = 21;
const int* const_p = &constant;
int* modifier = const_cast<int*>(const_p);
*modifier = 7;
C++函数名后加上const
函数尾添加从const表示他不修改类成员对象。
class MainWindow : public QMainWindow
{
Q_OBJECT
public:
MainWindow(QWidget *parent = nullptr);
~MainWindow();
bool addRecentProjectsActions(QMenu *menu) const;
private:
Ui::MainWindow *ui;
};
字节序
小端处理器:将多个字节值的最低有效字节存储于较低的内存位置。
大端处理器:将多个字节值的最高有效字节储存于较低的内存位置。

- Windos(x86,x64)和Linux(x86,x64)都是Little Endian操作系统
- 在ARM上,我见到的都是用Little Endian方式存储数据。
- C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的。
- JAVA编写的程序则唯一采用Big Endian方式来存储数据。
- 所有网络协议也都是采用Big Endian的方式来传输数据的。所以有时我们也会把Big Endian方式称之为网络字节序。
参考:https://blog.csdn.net/humanking7/article/details/51155778
为什么会有小端字节序?
答案是,计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。
但是,人类还是习惯读写大端字节序。所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
参考:https://www.ruanyifeng.com/blog/2016/11/byte-order.html
字节序转换
inline U16 swapU16(U16 value)
{
return ((value & 0x00FF) << 8 ) | ((value & 0xFF00) >> 8);
}
inline U32 swapU32(U32 value)
{
return ((value & 0x000000FF) << 24)
| ((value & 0x0000FF00) << 8)
| ((value & 0x00FF0000) >> 8)
| ((value & 0xFF000000) >> 24);
}
// 浮点字节序转换,简便的方法就是使用union
union U32F32
{
U32 m_asU32;
F32 m_asF32;
};
inline F32 swapF32(F32 value)
{
U32F32 u;
u.m_asF32 = value;
// 使用整数方式来转换字节序
u.m_asU32 = swapU32(u.m_asU32);
return u.m_asF32;
}
链接
若内联函数要提供多于一个翻译文件使用, 则该内联函数必须置于头文件。
static关键字可以把定义改为内部链接。
// foo.cpp
// 外部链接
U32 gExternalVariable;
// 内部链接
static U32 gInternalVariable;
C/C++内存布局
- 代码段:可自行机器码。
- 数据段:初始化的全局以及静态变量。
- BSS端:未初始化全局变量和静态变量。
- 只读数据段:又称为rodata端,包含程序中定义的只读(常量全局变量。注意:编译器通常吧整数常量视为明示常量,并且直接把明示常量插入机器码中(代码段的存储空间)。
全局变量按照是否被初始化来决定储存在数据段还是BSS段。(被初始化的储存在数据段)函数静态变量和文件域静态变量一样。
static关键字
- 文件作用域:
static表示只有本文件才能使用该变量或函数。 - 函数作用域:
static表示全局非自动,只有本函数可见。 - 用于
struct或class声明,static表示全局变量。(类声明内的类静态变量并不占用内存。必须在一个.cpp文件内定义静态变量以分配内存。